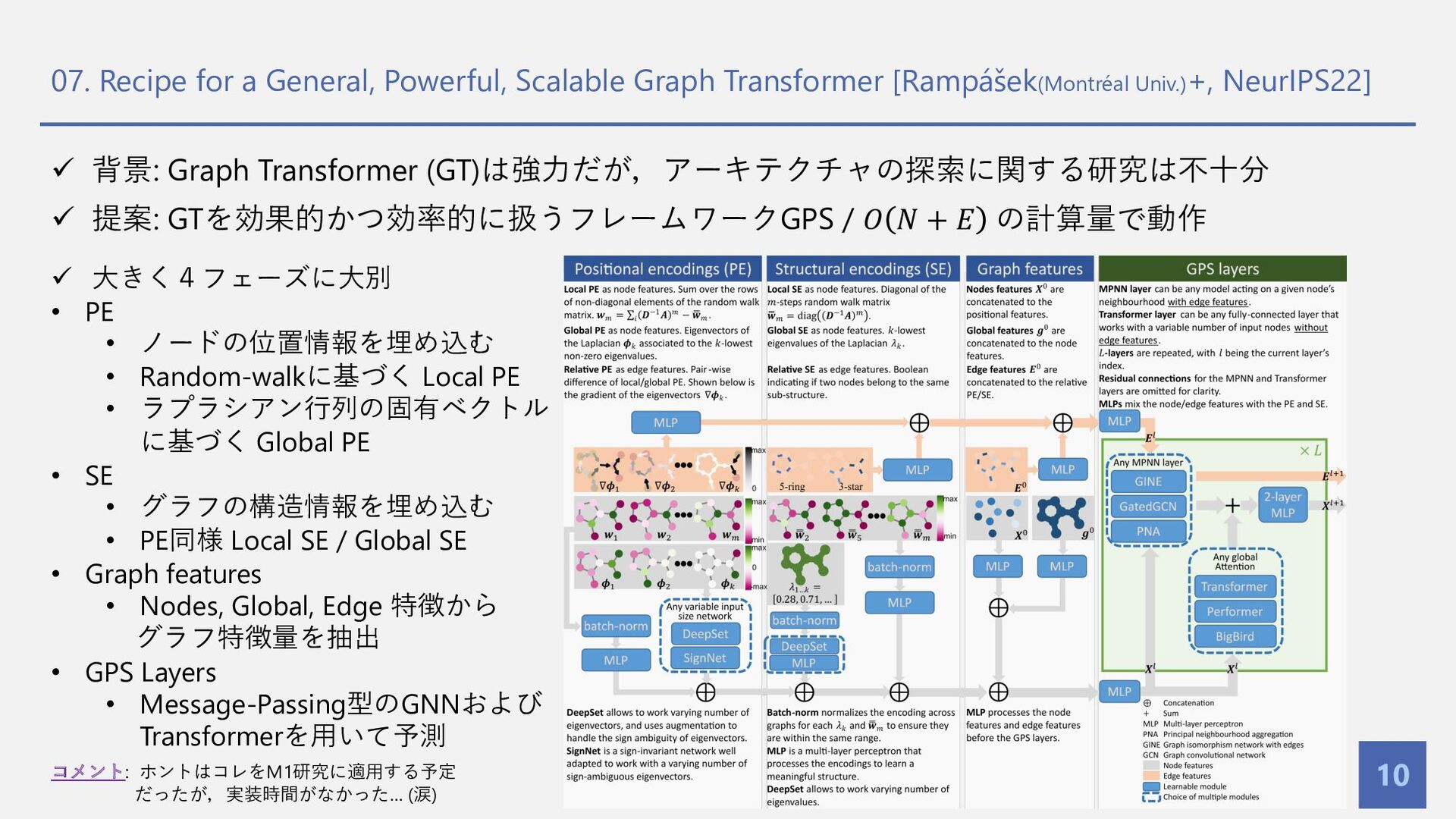
Univ.)+, NeurIPS22] 10 ü 背景: Graph Transformer (GT)は強⼒だが,アーキテクチャの探索に関する研究は不⼗分 ü 提案: GTを効果的かつ効率的に扱うフレームワークGPS / 𝑂 𝑁 + 𝐸 の計算量で動作 ü ⼤きく4フェーズに⼤別 • PE • ノードの位置情報を埋め込む • Random-walkに基づく Local PE • ラプラシアン⾏列の固有ベクトル に基づく Global PE • SE • グラフの構造情報を埋め込む • PE同様 Local SE / Global SE • Graph features • Nodes, Global, Edge 特徴から グラフ特徴量を抽出 • GPS Layers • Message-Passing型のGNNおよび Transformerを⽤いて予測 コメント: ホントはコレをM1研究に適⽤する予定 だったが,実装時間がなかった… (涙)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
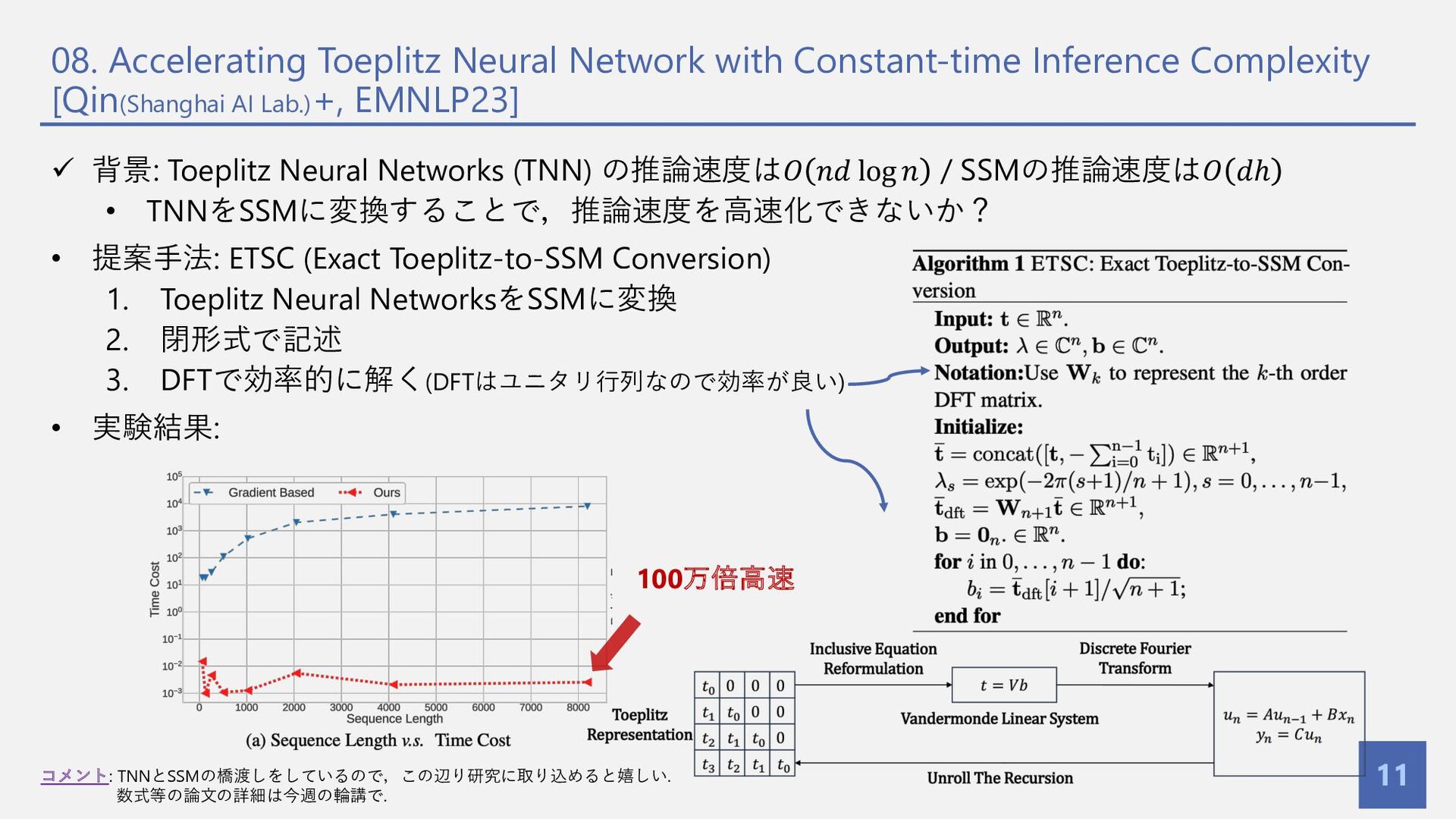{kind=link}
{kind=link}
{kind=link}
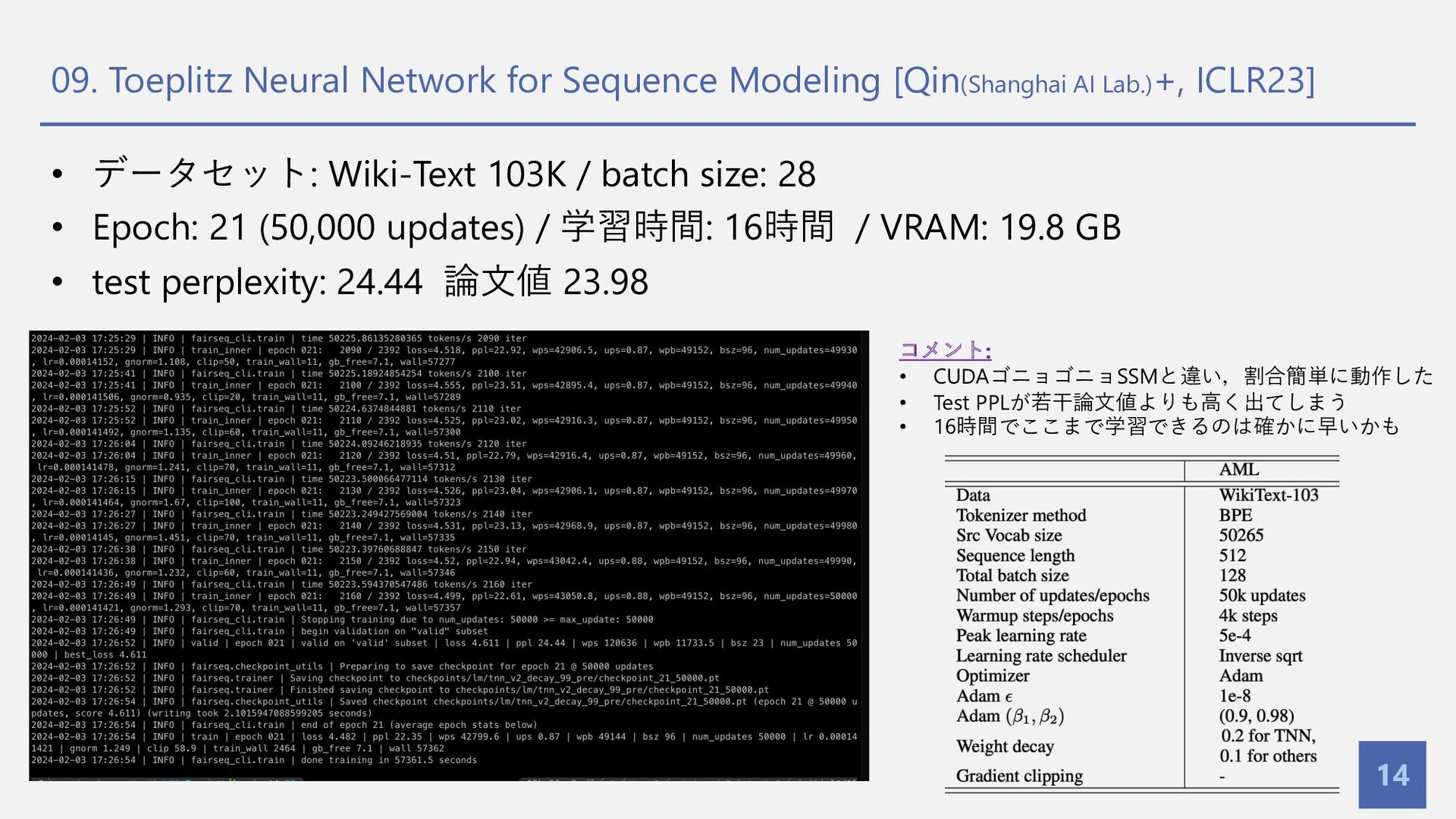{kind=link}
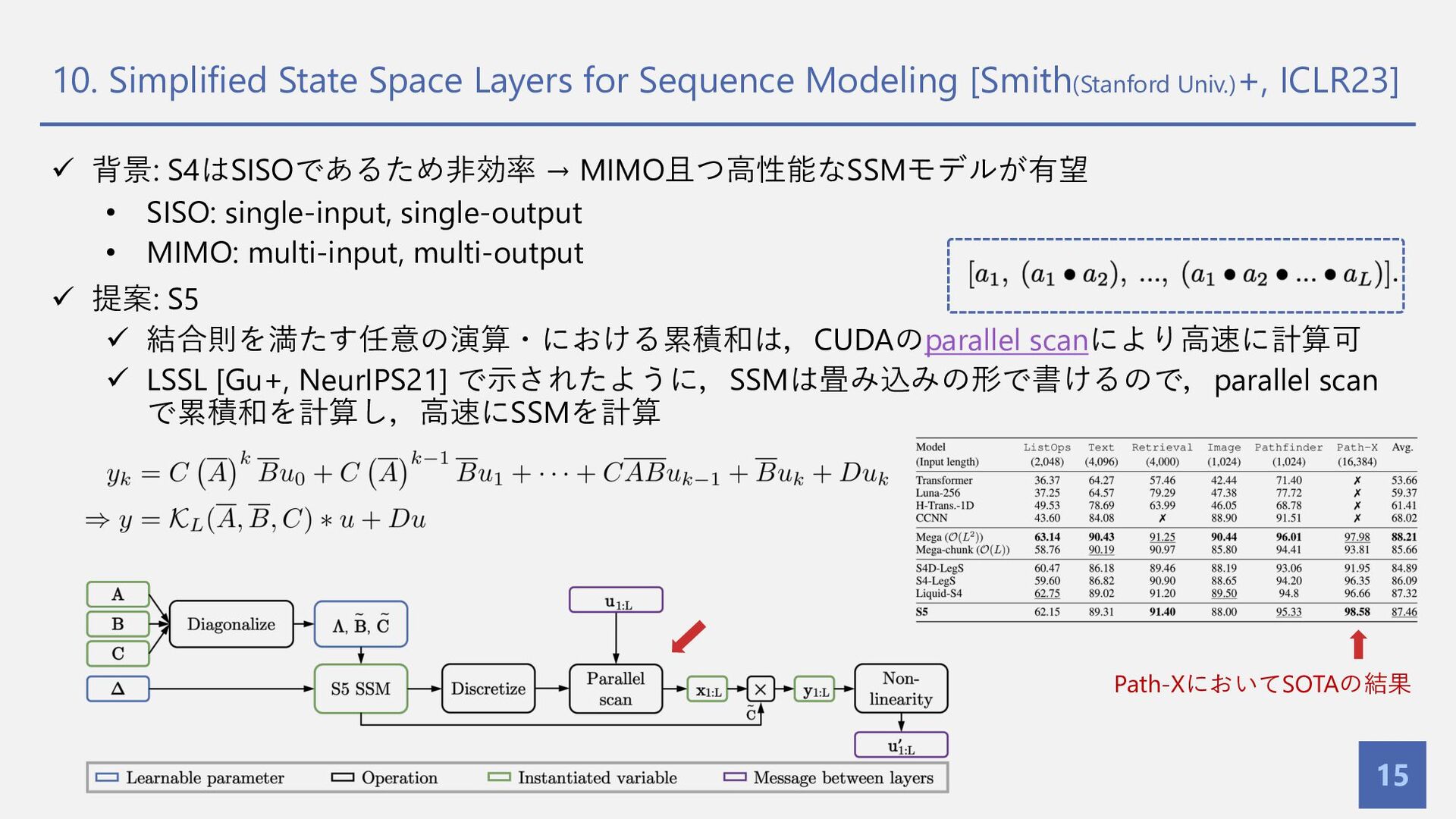{kind=link}
{kind=link}
{kind=link}
![11. DEMETR: Diagnosing Evaluation Metrics for Translation [Karpinska(UMass Amherst)+, EMNLP22]](https://files.speakerdeck.com/presentations/4b344471ca2d460c86860a507076ed01/slide_17.jpg){kind=link}
{kind=link}
![13. Visual Instruction Tuning [Liu(Univ. of Wisconsin–Madison)+, NeurIPS23] 20 ü](https://files.speakerdeck.com/presentations/4b344471ca2d460c86860a507076ed01/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![19. VMamba: Visual State Space Model [Liu(UCAS)+, 2024] 28 ü](https://files.speakerdeck.com/presentations/4b344471ca2d460c86860a507076ed01/slide_27.jpg){kind=link}
![19. VMamba: Visual State Space Model [Liu(UCAS)+, 2024] 29 •](https://files.speakerdeck.com/presentations/4b344471ca2d460c86860a507076ed01/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
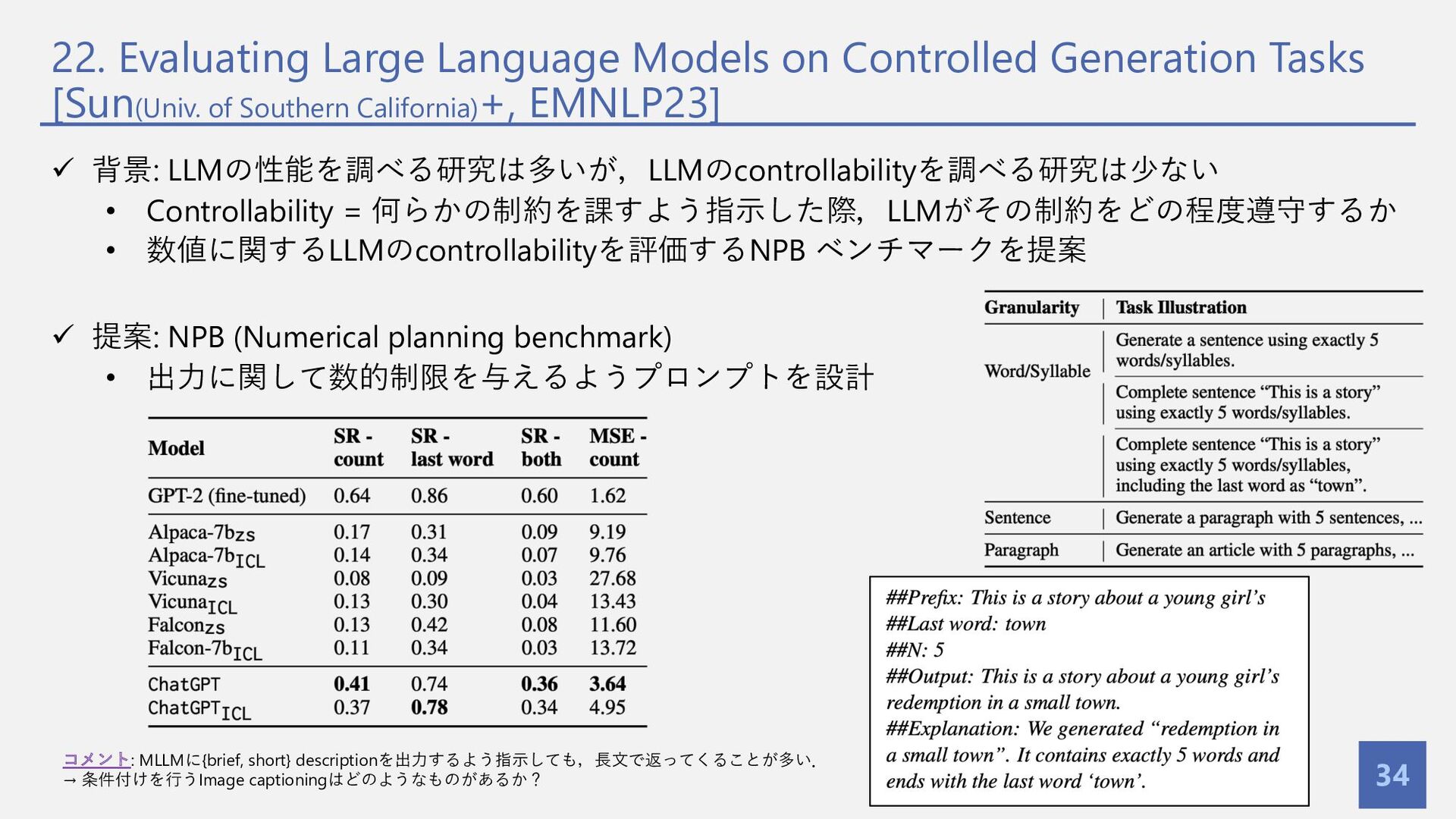{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
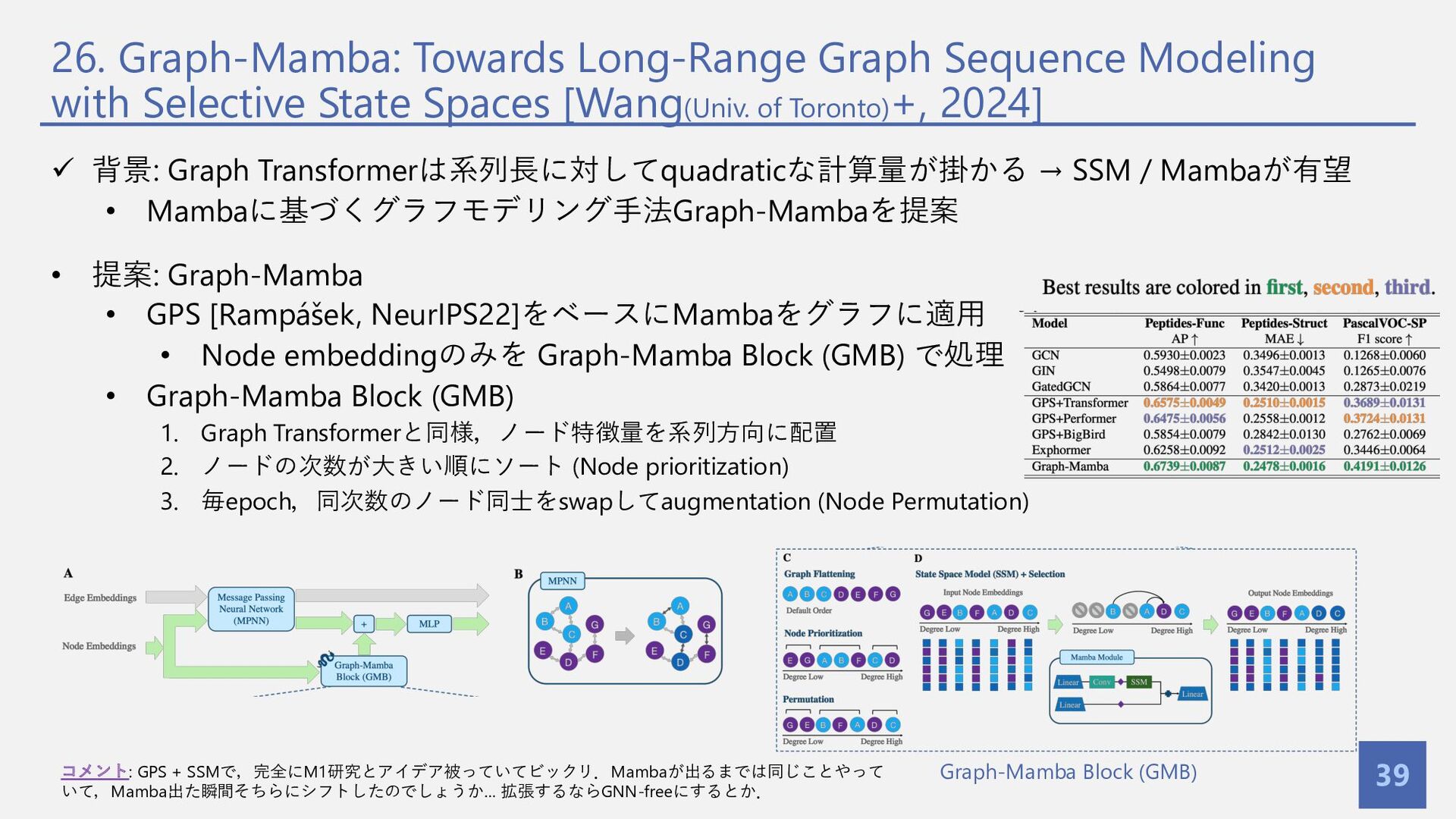{kind=link}
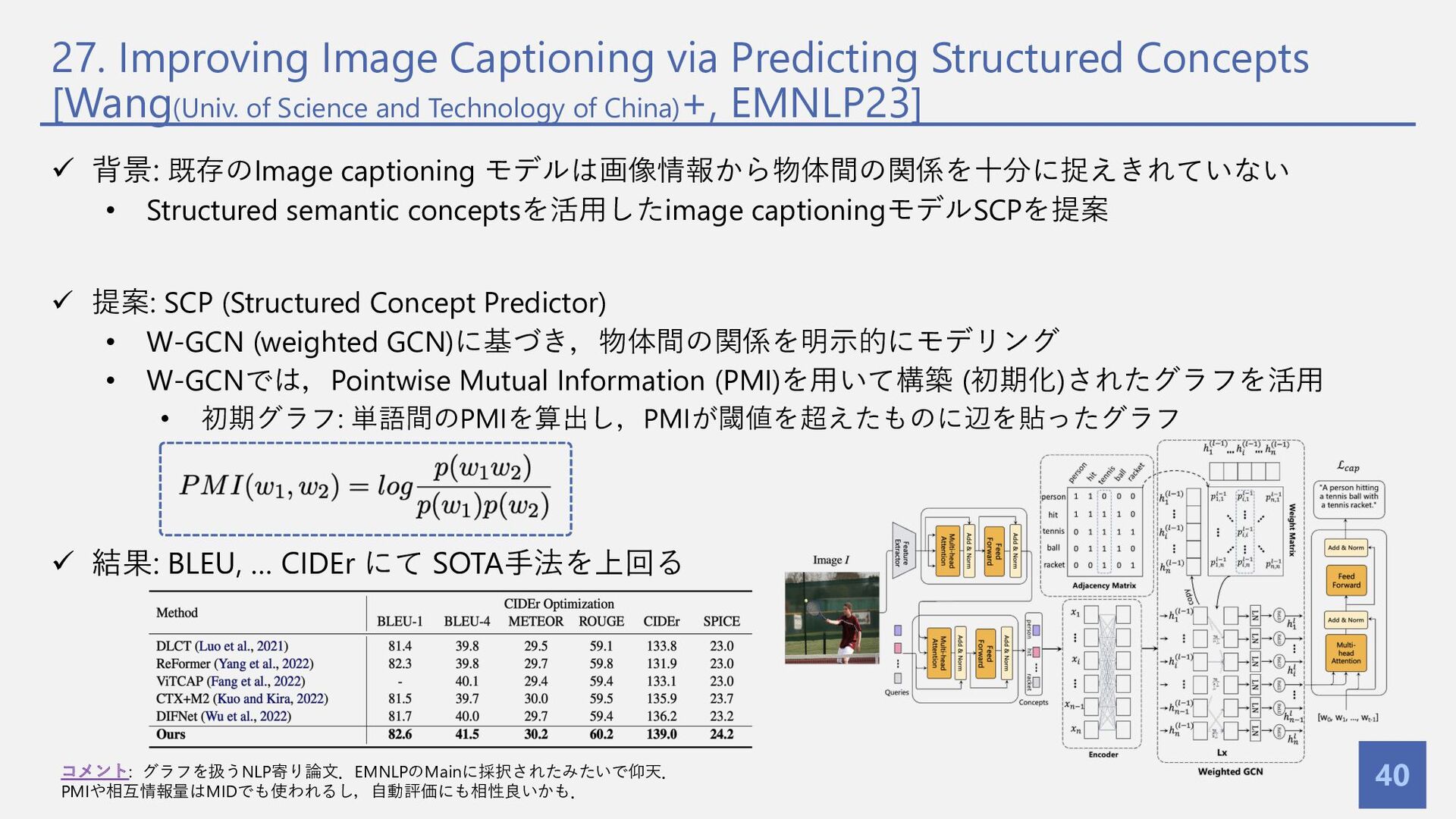{kind=link}
{kind=link}
{kind=link}
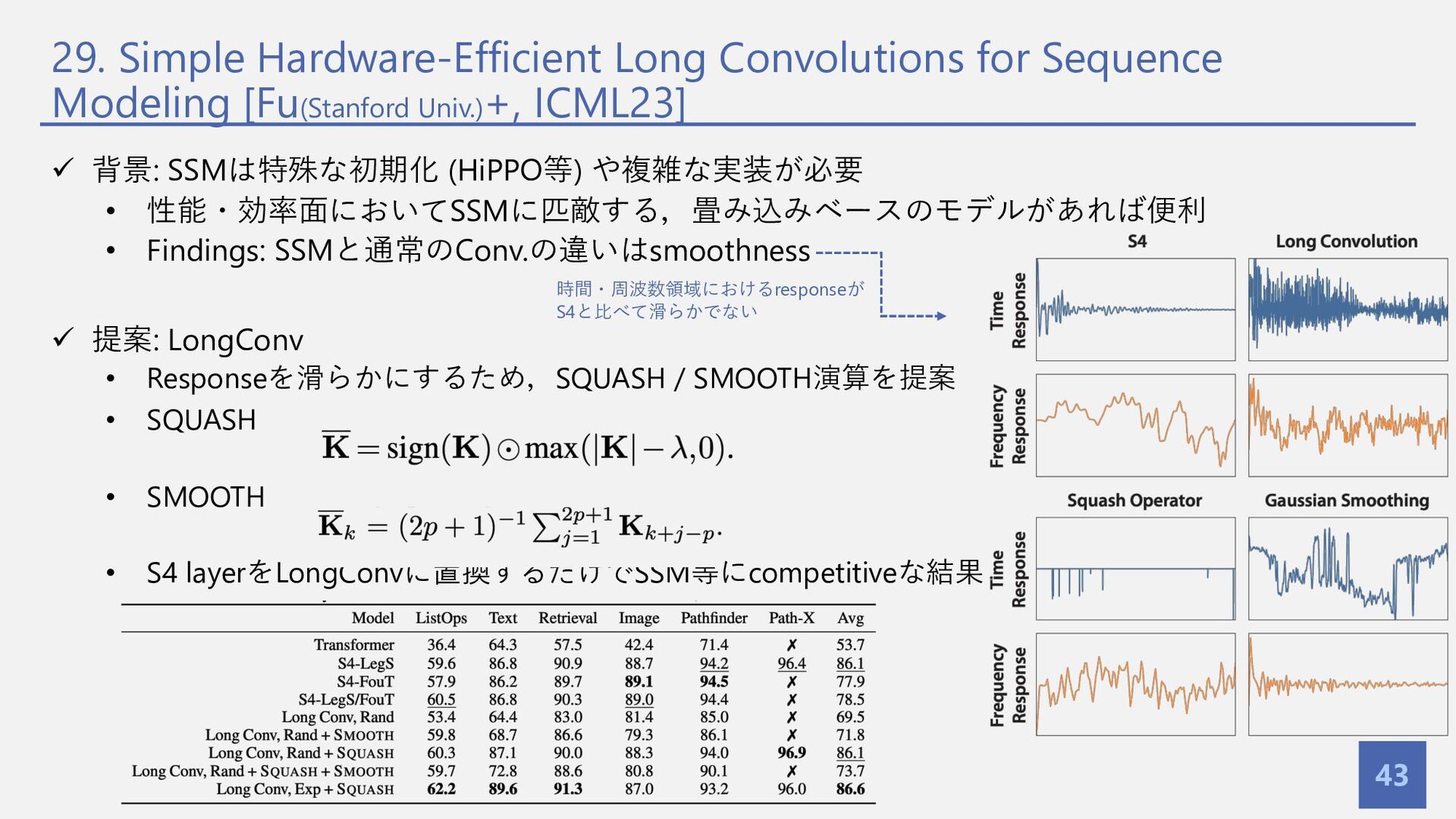{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![31. Metagenomic Binning using Connectivity-constrained Variational Autoencoders [Lamurias(Aalborg Univ.)+, ICML23]](https://files.speakerdeck.com/presentations/4b344471ca2d460c86860a507076ed01/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![36. Transformers Meet Directed Graphs [Geisler(Technical Univ. of Munich)+,ICML23] 54](https://files.speakerdeck.com/presentations/4b344471ca2d460c86860a507076ed01/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![40. A Generalization of ViT/MLP-Mixer to Graphs[He(Univ. of Singapore)+, ICML23]](https://files.speakerdeck.com/presentations/4b344471ca2d460c86860a507076ed01/slide_59.jpg){kind=link}
![40. A Generalization of ViT/MLP-Mixer to Graphs[He(Univ. of Singapore)+, ICML23]](https://files.speakerdeck.com/presentations/4b344471ca2d460c86860a507076ed01/slide_60.jpg){kind=link}