低次元空間でサンプリングするため,効率的 ◼ 例:𝑧をサンプリングし, 𝜃を積分する→𝜃はマルコフ連鎖に参加しない ◼ Rao-Blackwell化 ◼ Theorem 24.2.1 (Rao-Blackwell) 𝑧,𝜃を従属確率変数とし、 𝑓 𝑧, 𝜃 をスカラー関数とすると、 𝑣𝑎𝑟𝑧,𝜃 [𝑓 𝑧, 𝜃 ] ≥ 𝑣𝑎𝑟𝑧 [𝔼𝜃 𝑓 𝑧, 𝜃 z ] →𝜃を解析的に積分したときの推定値の分散が,直接MC推定値の分散より も常に低くなる →積分を迅速に実行できる場合にのみ行う価値があります。そうでない場 合は、単純な方法ほど 1 秒あたりに多くのサンプルを生成できません。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
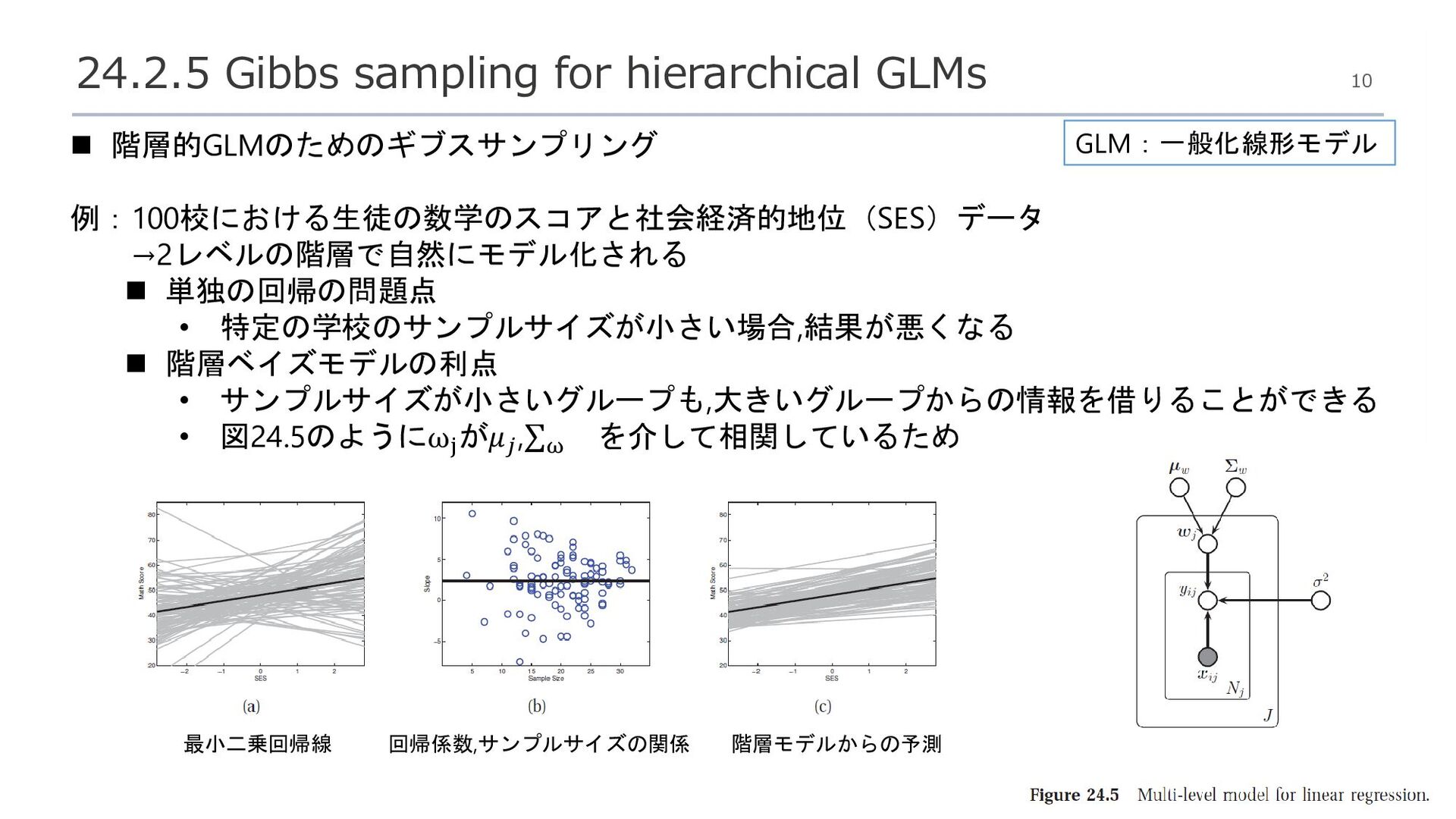{kind=link}
{kind=link}
{kind=link}
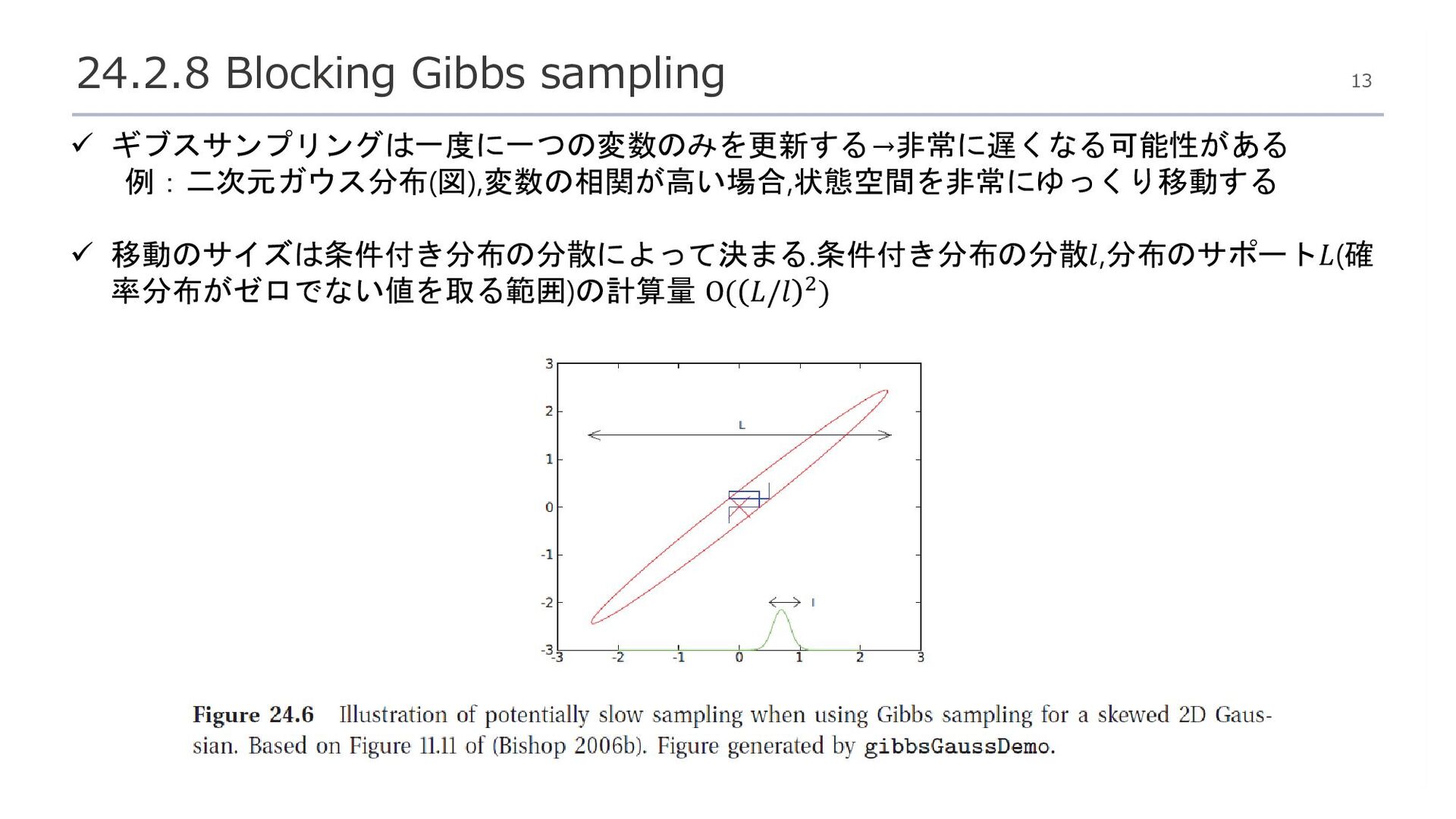{kind=link}
{kind=link}
{kind=link}
{kind=link}
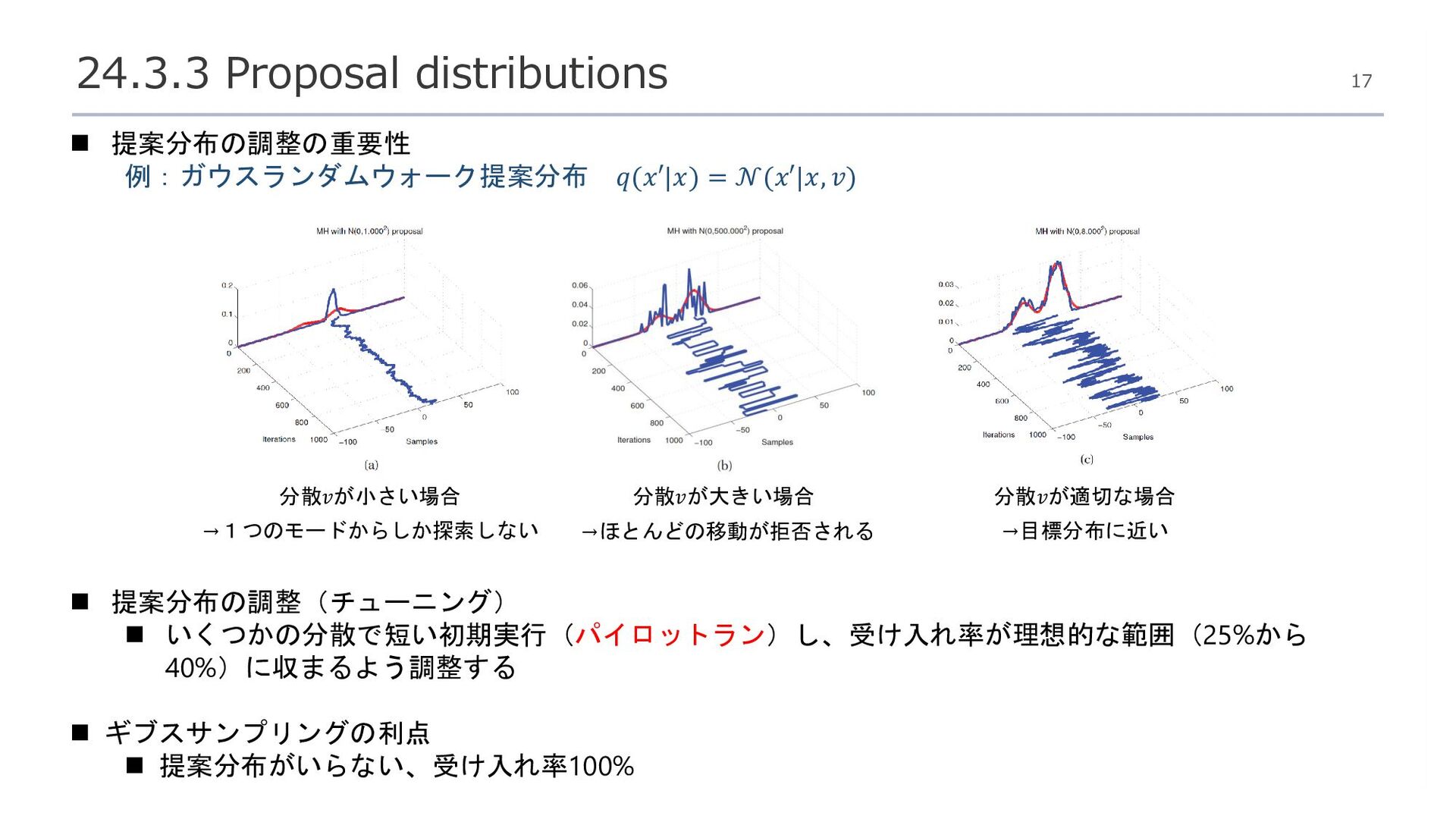{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
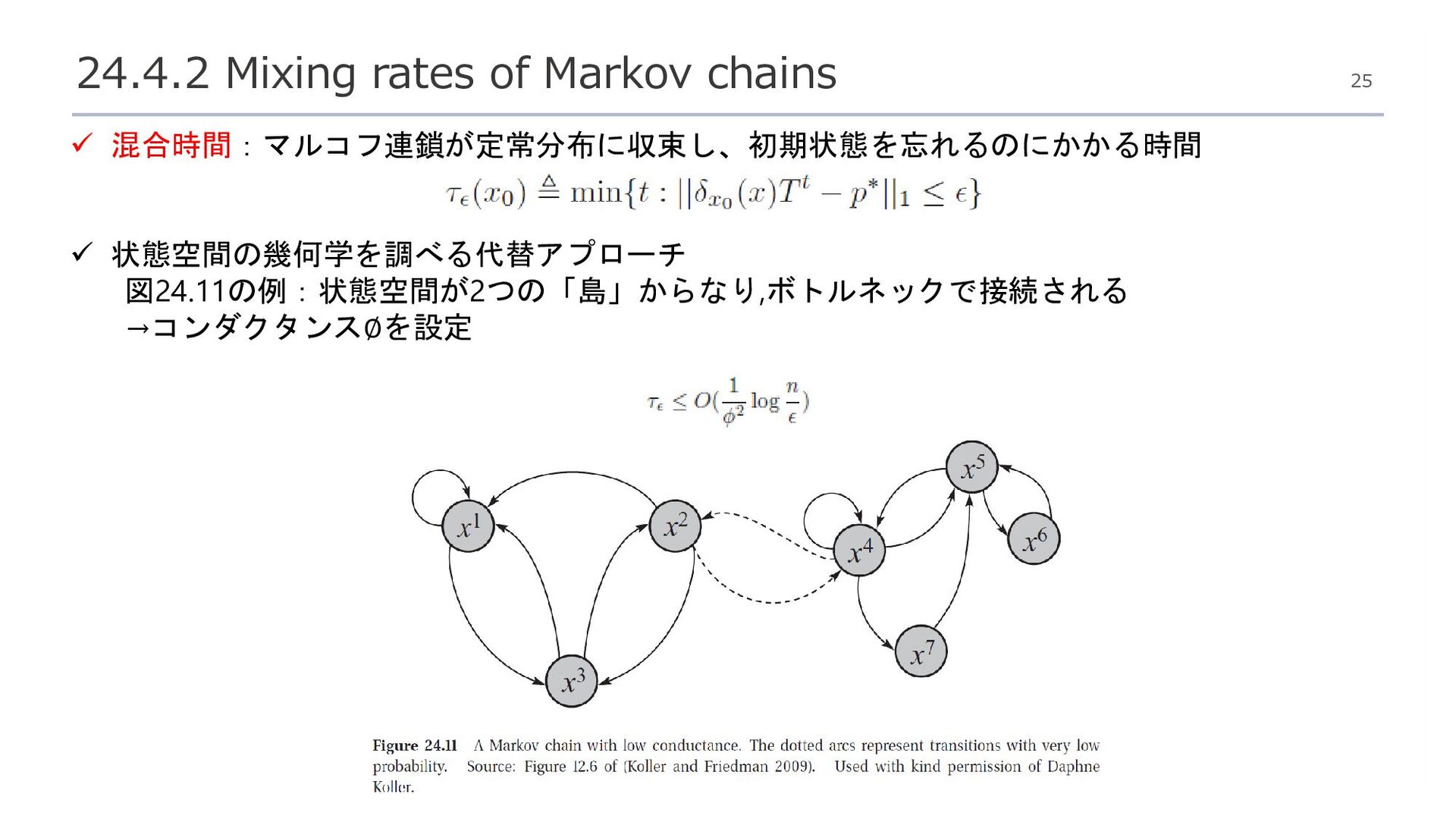{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}