Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【輪講】Ray: A Distributed Framework for Emerging ...
Search
Tomoya Ishizaki
June 21, 2019
Programming
300
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【輪講】Ray: A Distributed Framework for Emerging AI Applications
Tomoya Ishizaki
June 21, 2019
More Decks by Tomoya Ishizaki
See All by Tomoya Ishizaki
Chompyらくとく便のこれまでとこれから
zaq1tomo
0
2.2k
xv6 chapter5 first
zaq1tomo
0
280
xv6 chapter1 first
zaq1tomo
1
170
Hybrid Casper FFG
zaq1tomo
3
710
Other Decks in Programming
See All in Programming
The Bowling Game - From Imperative to Functional Programming - Part 1
philipschwarz
PRO
0
340
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
410
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
150
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
160
jsmini JavaScript Engine を作ってみた話
yosuke_furukawa
PRO
0
190
PHPだって関数型したい 〜できること、できないこと〜 / fp-in-php
jsoizo
1
240
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
190
生成AI導入の「期待外れ」を乗り越える ー 開発フロー改革が目指す、真の組織変革
starfish719
0
1.8k
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
150
Terraform標準の組織で AWS CDKをどう使うか
mu7889yoon
1
350
Claude Team Plan導入・ガイド
tk3fftk
0
220
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
150
Featured
See All Featured
GitHub's CSS Performance
jonrohan
1033
470k
Believing is Seeing
oripsolob
1
170
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Faster Mobile Websites
deanohume
310
32k
Building Applications with DynamoDB
mza
96
7.1k
Statistics for Hackers
jakevdp
799
230k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
270
A Tale of Four Properties
chriscoyier
163
24k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Transcript
Ray: A Distributed Framework for Emerging AI Applications Tomoya Ishizaki
2019/06/19
リファレンス • Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov,
Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica, UC Berkeley • 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’18)
背景(1)ビックデータとAI / ML • ビックデータの時代 ◦ 大規模データの分散処理のために様々なフレームワークが開発 ▪ MapReduce ▪
Apache Spark • AI / MLの分野の発展 ◦ 教師あり機械学習のために様々なフレームワークが開発 ▪ TensorFlow ▪ PyTorch ▪ Apatch MXNet
背景(2)強化学習 • 強化学習が様々な分野で大きな成果 • 強化学習とは ◦ ある「環境」内でエージェントが、現在の「状態」を観測、次に取るべき「行動」を選択し、環境から得 られる「報酬」を最大化する「方策」を学習する、機械学習の一種
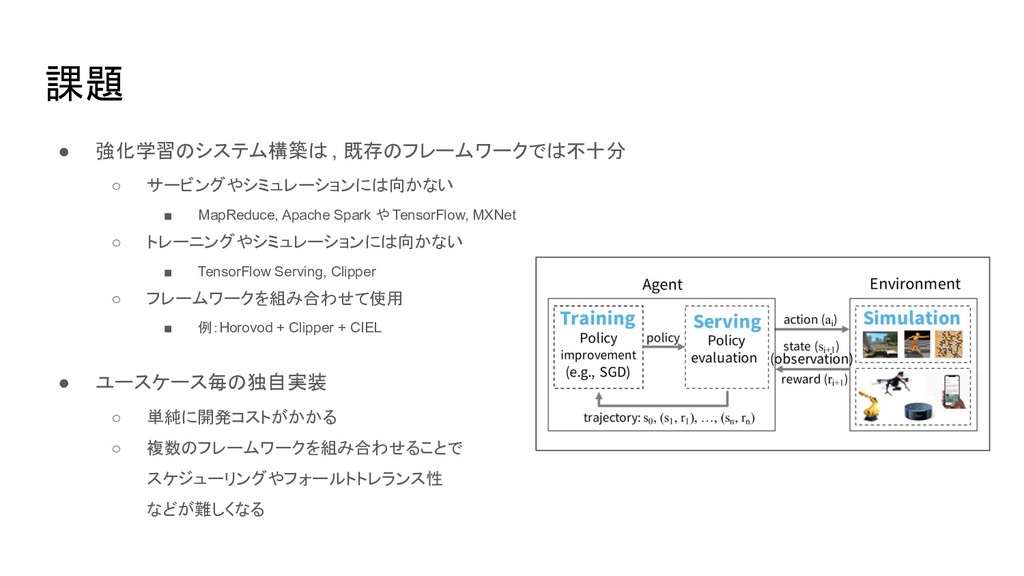
課題 • 強化学習のシステム構築は , 既存のフレームワークでは不十分 ◦ サービングやシミュレーションには向かない ▪ MapReduce, Apache
Spark や TensorFlow, MXNet ◦ トレーニングやシミュレーションには向かない ▪ TensorFlow Serving, Clipper ◦ フレームワークを組み合わせて使用 ▪ 例:Horovod + Clipper + CIEL • ユースケース毎の独自実装 ◦ 単純に開発コストがかかる ◦ 複数のフレームワークを組み合わせることで スケジューリングやフォールトトレランス性 などが難しくなる
提案 • Ray ◦ 汎用クラスタコンピューティングフレームワーク • 強化学習のワークロードをサポート ◦ 処理を二種類に抽象化 ◦
ステートレスなタスク ◦ ステートフルなアクター • スケーラビリティとフォールトトレランス性を実現 ◦ グローバルコントロールストア ◦ ボトムアップ分散スケジューラー
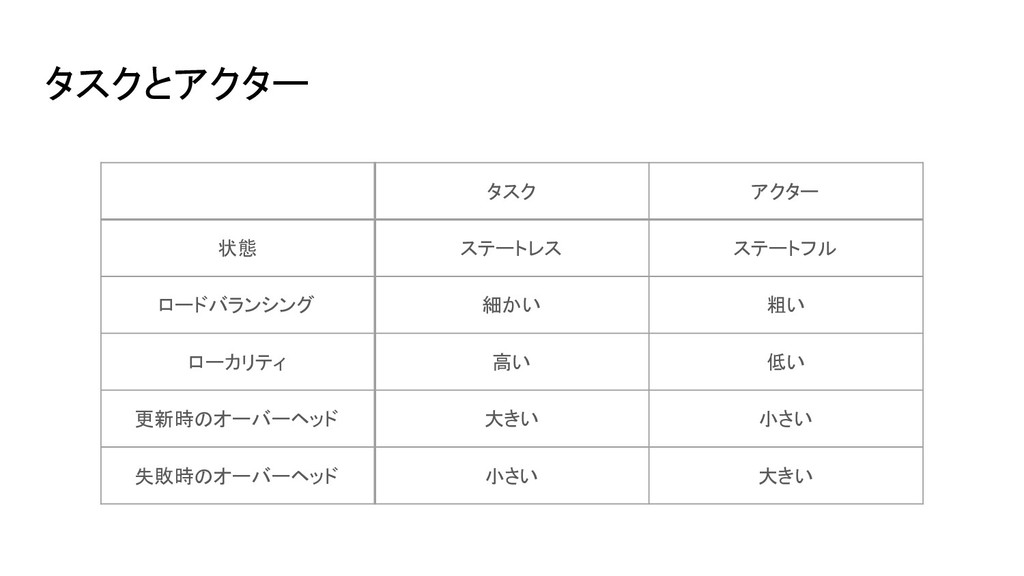
タスクとアクター タスク アクター 状態 ステートレス ステートフル ロードバランシング 細かい 粗い ローカリティ
高い 低い 更新時のオーバーヘッド 大きい 小さい 失敗時のオーバーヘッド 小さい 大きい
Ray API usage ray.remote() futures = f.remote(args) actor = Class.remote(args)
futures = actor.method.remote(args) ray.get() objects = ray.get(futures) ray.wait() ready_futures = ray.wait(futures, k, timeout)
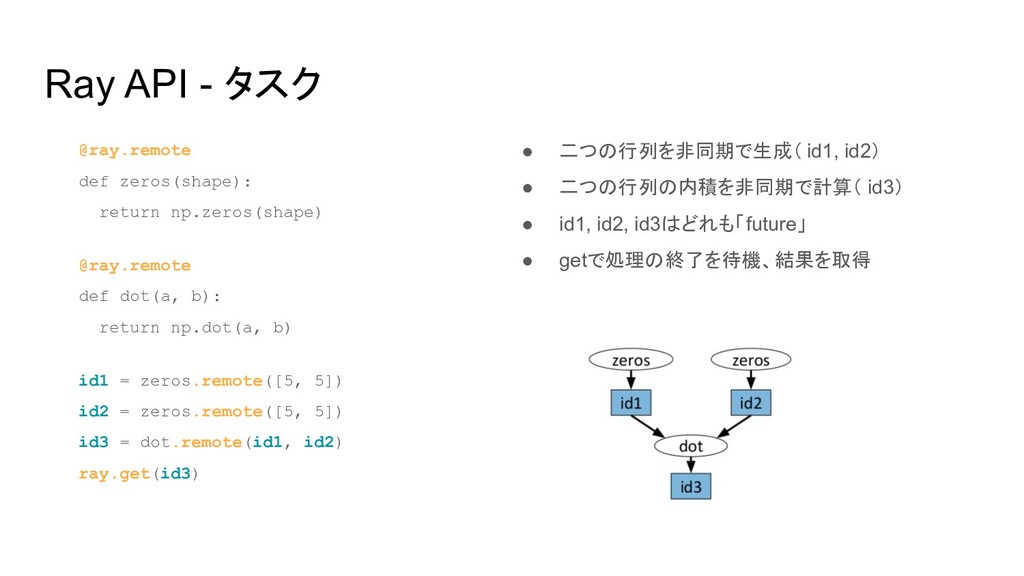
Ray API - タスク @ray.remote def zeros(shape): return np.zeros(shape) @ray.remote
def dot(a, b): return np.dot(a, b) id1 = zeros.remote([5, 5]) id2 = zeros.remote([5, 5]) id3 = dot.remote(id1, id2) ray.get(id3) • 二つの行列を非同期で生成( id1, id2) • 二つの行列の内積を非同期で計算( id3) • id1, id2, id3はどれも「future」 • getで処理の終了を待機、結果を取得
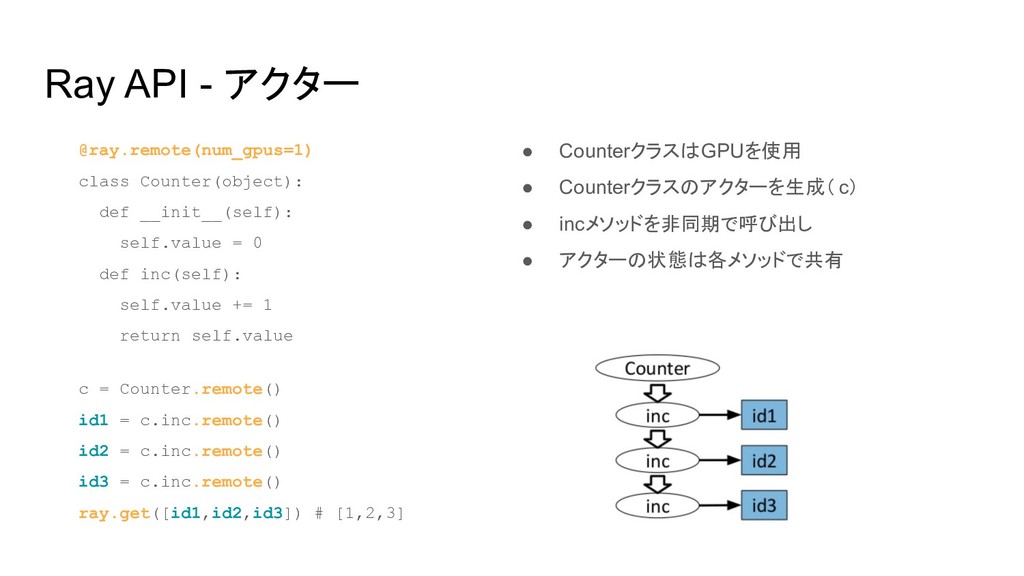
Ray API - アクター @ray.remote(num_gpus=1) class Counter(object): def __init__(self): self.value
= 0 def inc(self): self.value += 1 return self.value c = Counter.remote() id1 = c.inc.remote() id2 = c.inc.remote() id3 = c.inc.remote() ray.get([id1,id2,id3]) # [1,2,3] • CounterクラスはGPUを使用 • Counterクラスのアクターを生成( c) • incメソッドを非同期で呼び出し • アクターの状態は各メソッドで共有
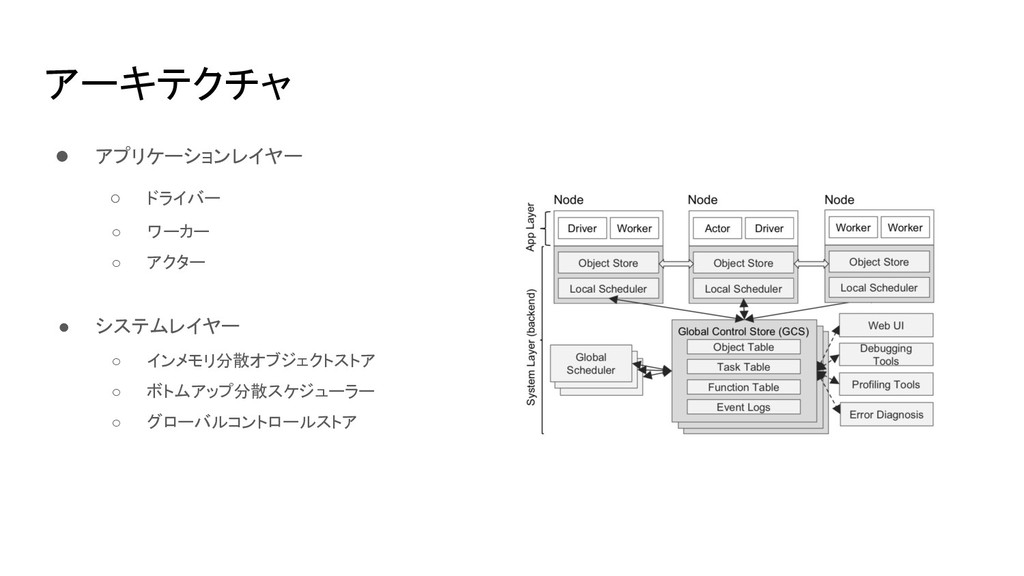
アーキテクチャ • アプリケーションレイヤー ◦ ドライバー ◦ ワーカー ◦ アクター •
システムレイヤー ◦ インメモリ分散オブジェクトストア ◦ ボトムアップ分散スケジューラー ◦ グローバルコントロールストア
ドライバー, ワーカー, アクター • アプリケーションレイヤーを構成する 三種類のプロセス • ドライバー ◦ ユーザープログラムを実行
• ワーカー ◦ ステートレスな処理を実行 • アクター ◦ ステートフルな処理を実行
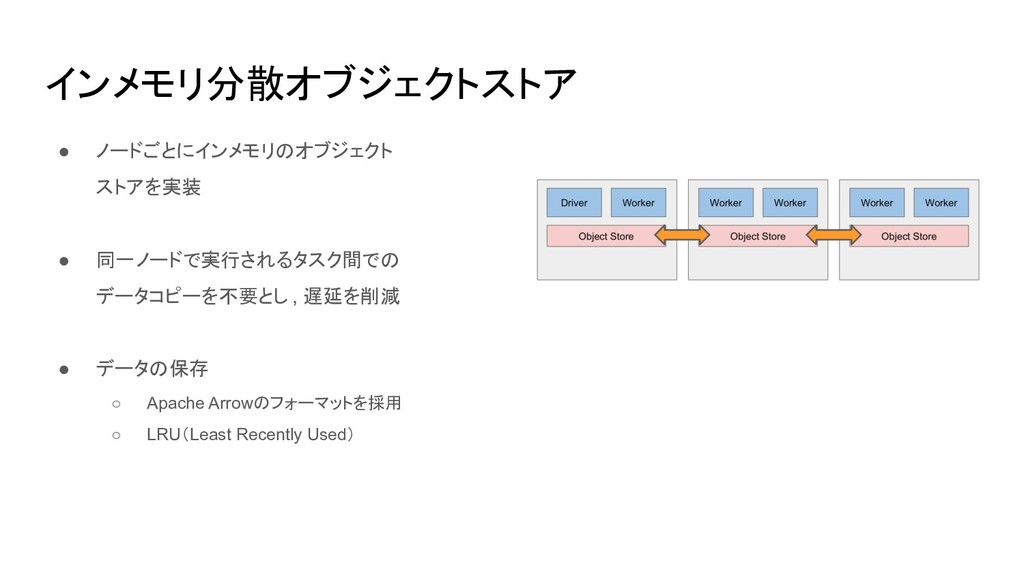
インメモリ分散オブジェクトストア • ノードごとにインメモリのオブジェクト ストアを実装 • 同一ノードで実行されるタスク間での データコピーを不要とし , 遅延を削減 •
データの保存 ◦ Apache Arrowのフォーマットを採用 ◦ LRU(Least Recently Used)
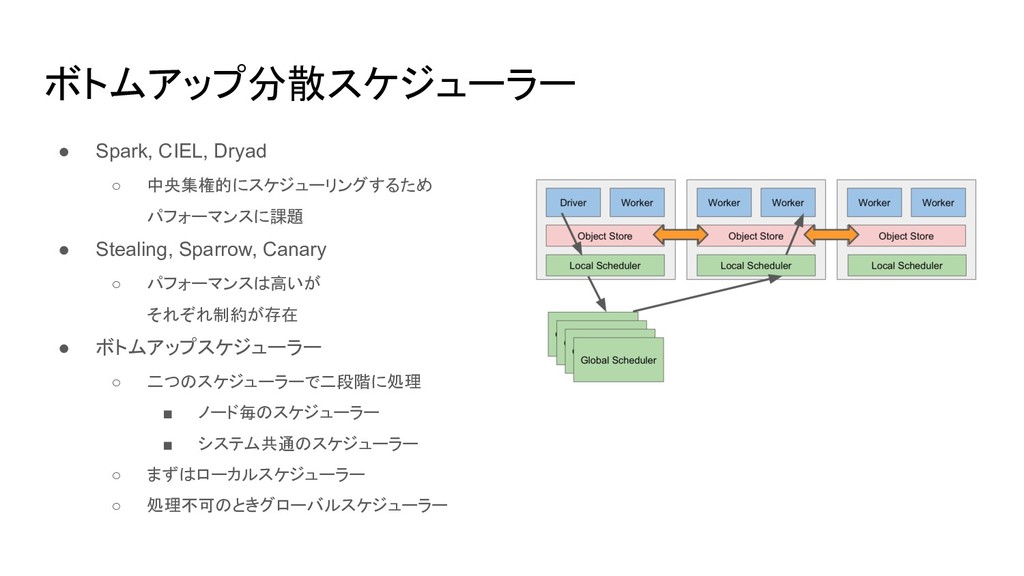
ボトムアップ分散スケジューラー • Spark, CIEL, Dryad ◦ 中央集権的にスケジューリングするため パフォーマンスに課題 • Stealing,
Sparrow, Canary ◦ パフォーマンスは高いが それぞれ制約が存在 • ボトムアップスケジューラー ◦ 二つのスケジューラーで二段階に処理 ▪ ノード毎のスケジューラー ▪ システム共通のスケジューラー ◦ まずはローカルスケジューラー ◦ 処理不可のときグローバルスケジューラー
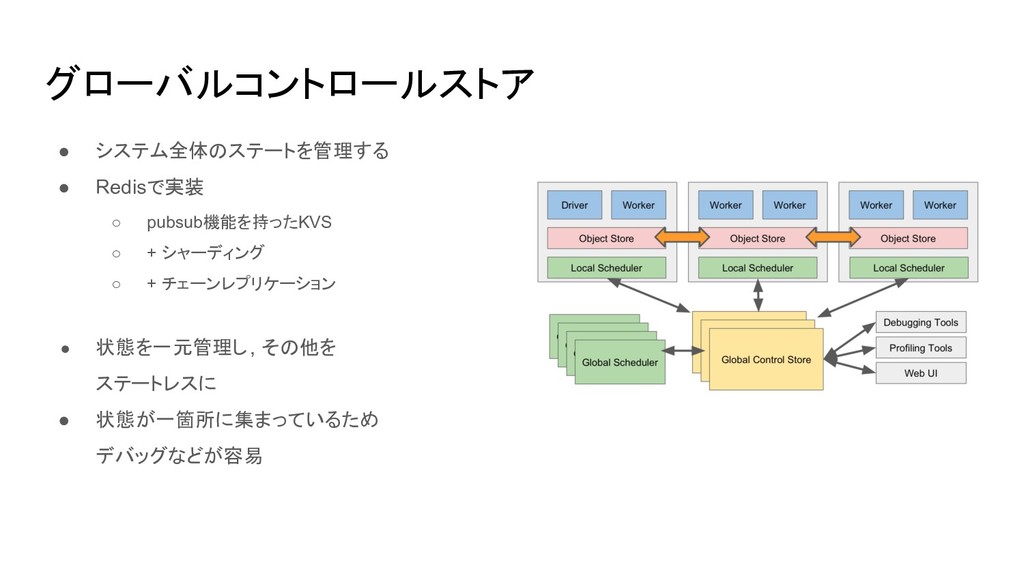
グローバルコントロールストア • システム全体のステートを管理する • Redisで実装 ◦ pubsub機能を持ったKVS ◦ + シャーディング
◦ + チェーンレプリケーション • 状態を一元管理し, その他を ステートレスに • 状態が一箇所に集まっているため デバッグなどが容易
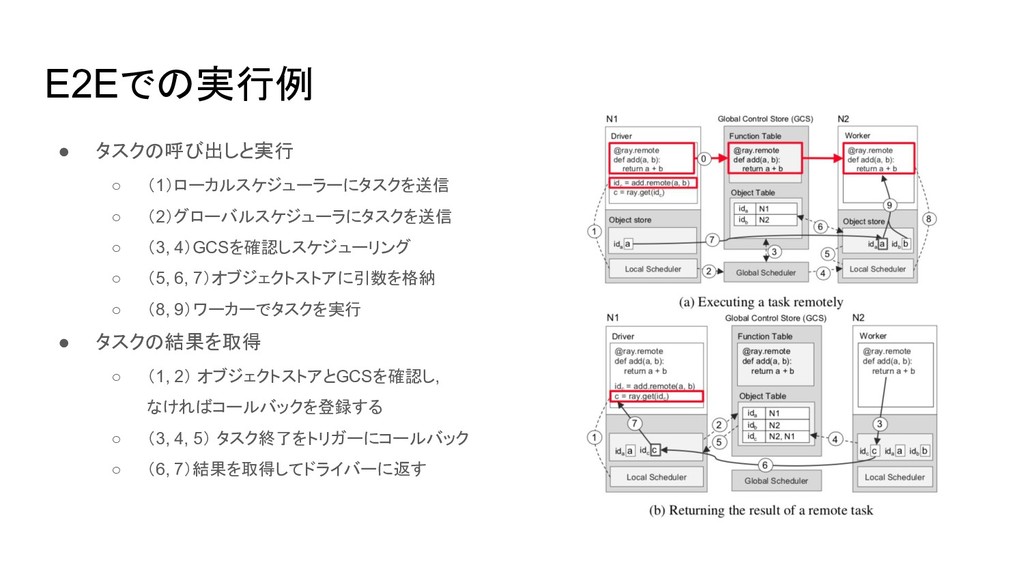
E2Eでの実行例 • タスクの呼び出しと実行 ◦ (1)ローカルスケジューラーにタスクを送信 ◦ (2)グローバルスケジューラにタスクを送信 ◦ (3, 4)GCSを確認しスケジューリング
◦ (5, 6, 7)オブジェクトストアに引数を格納 ◦ (8, 9)ワーカーでタスクを実行 • タスクの結果を取得 ◦ (1, 2) オブジェクトストアとGCSを確認し, なければコールバックを登録する ◦ (3, 4, 5) タスク終了をトリガーにコールバック ◦ (6, 7)結果を取得してドライバーに返す
実験環境 CPU m4.16xlarge GPU p3.16xlarge Ethernet 25Gbps • Amazon Web
Servicesを使用
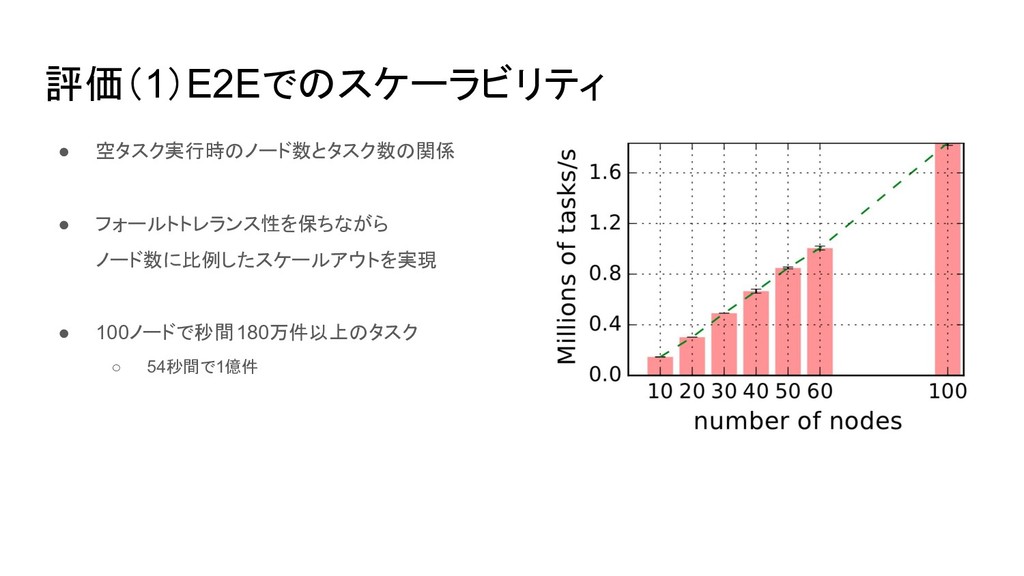
評価(1)E2Eでのスケーラビリティ • 空タスク実行時のノード数とタスク数の関係 • フォールトトレランス性を保ちながら ノード数に比例したスケールアウトを実現 • 100ノードで秒間180万件以上のタスク ◦ 54秒間で1億件
評価(2)既存フレームワークとの比較 • トレーニング ◦ ResNet-101 ◦ OpenMPI 3.0, TF 1.8,
NCCL2 ◦ Horovod+TF以上, Distributed TFの90%以上 • サービング ◦ 4KBと100KBのインプット ◦ Ray >> Clipper • シミュレーション ◦ Pendulum-v0 ◦ 256CPUのとき1.8倍のスループット
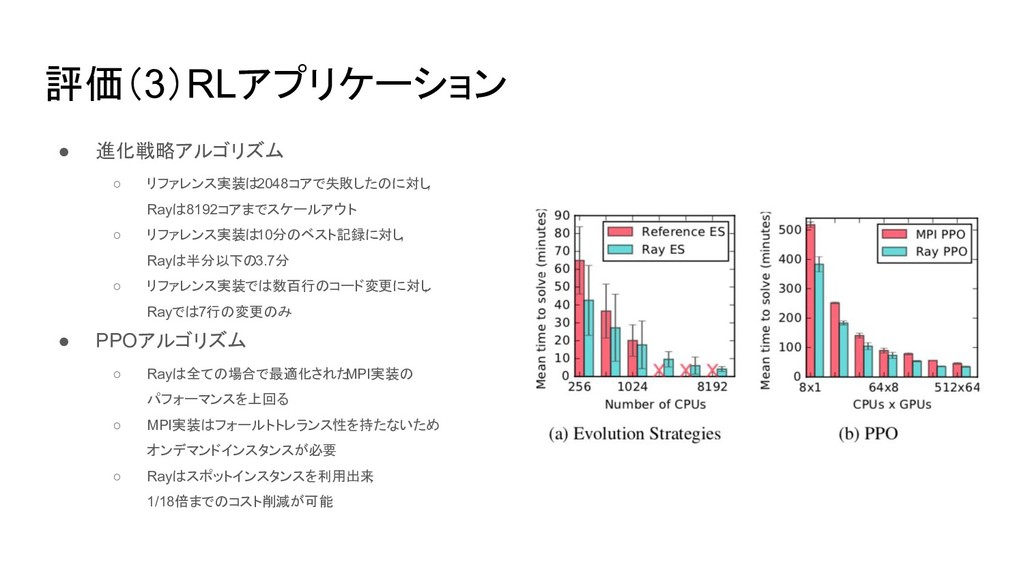
評価(3)RLアプリケーション • 進化戦略アルゴリズム ◦ リファレンス実装は2048コアで失敗したのに対し , Rayは8192コアまでスケールアウト ◦ リファレンス実装は10分のベスト記録に対し ,
Rayは半分以下の3.7分 ◦ リファレンス実装では数百行のコード変更に対し , Rayでは7行の変更のみ • PPOアルゴリズム ◦ Rayは全ての場合で最適化された MPI実装の パフォーマンスを上回る ◦ MPI実装はフォールトトレランス性を持たないため オンデマンドインスタンスが必要 ◦ Rayはスポットインスタンスを利用出来 , 1/18倍までのコスト削減が可能
関連研究 • ダイナミックタスクグラフ ◦ CIEL: a universal execution engine for
distributed data-flow computing ▪ Murray, Derek G., et al. 8th ACM/USENIX Symposium on Networked Systems Design and Implementation. 2011. ▪ Rayと同様にリネージベースのフォールトトレランス性をサポート ▪ ステートフルな処理やマスターノードの分散化はサポートしていない • スケジューリング ◦ Omega: flexible, scalable schedulers for large compute clusters ▪ Schwarzkopf, Malte, et al. ▪ Rayと同様にグローバルな共有ステートを用いてスケジューリング ◦ Sparrow: Distributed, Low Latency Scheduling ▪ Ousterhout, Kay, et al. Twenty-Fourth ACM Symposium on Operating Systems Principles. ACM, 2013. ▪ 一般的なクラスタコンピューティングシステムでは中央集権的なスケジューラー
結論 • 既存のフレームワークは強化学習のシステムに必要な 「トレーニング」「サービング」「シミュレーション」を 十分にサポートできていなかった • Rayは「タスク」「アクター」と「グローバルコントロールストア」 「ボトムアップ分散スケジューラー」によってこれを実現 • Rayでは柔軟なAPIを使用して秒間180万タスクまでスケール可能な
スケーラビリティとフォールトトレランス性をもった 強化学習アプリケーションを簡単に構築可能
ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}