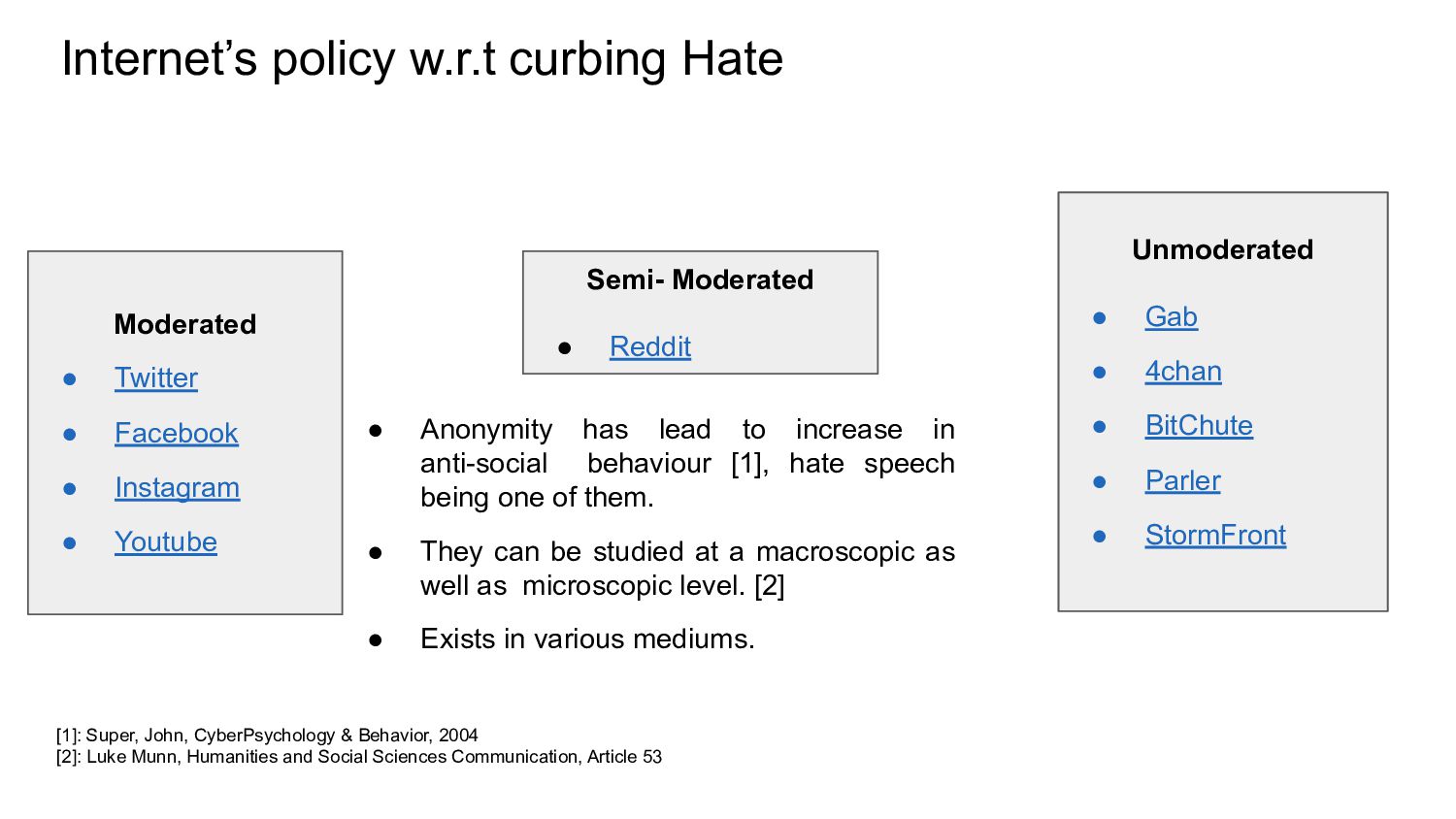
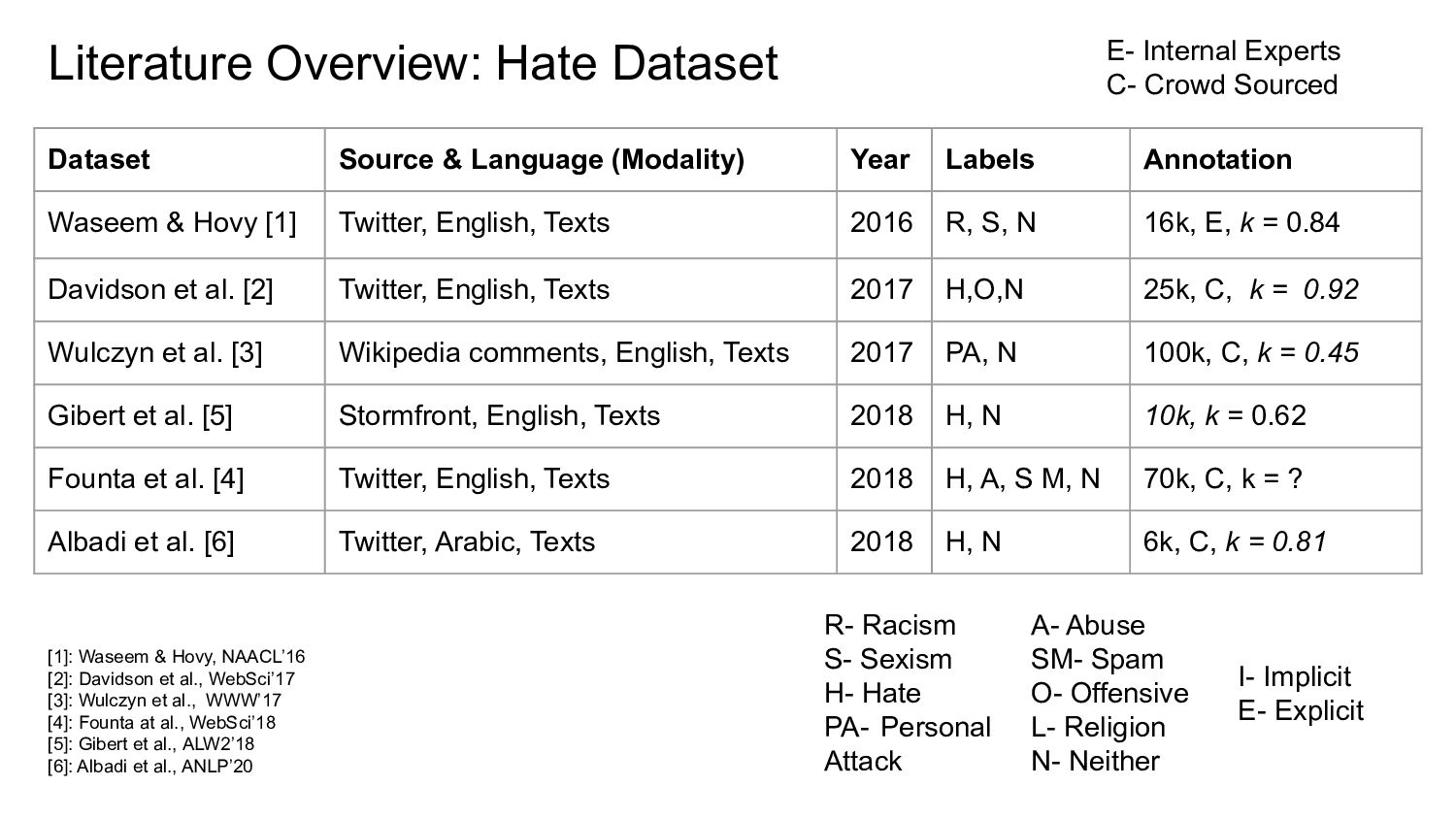
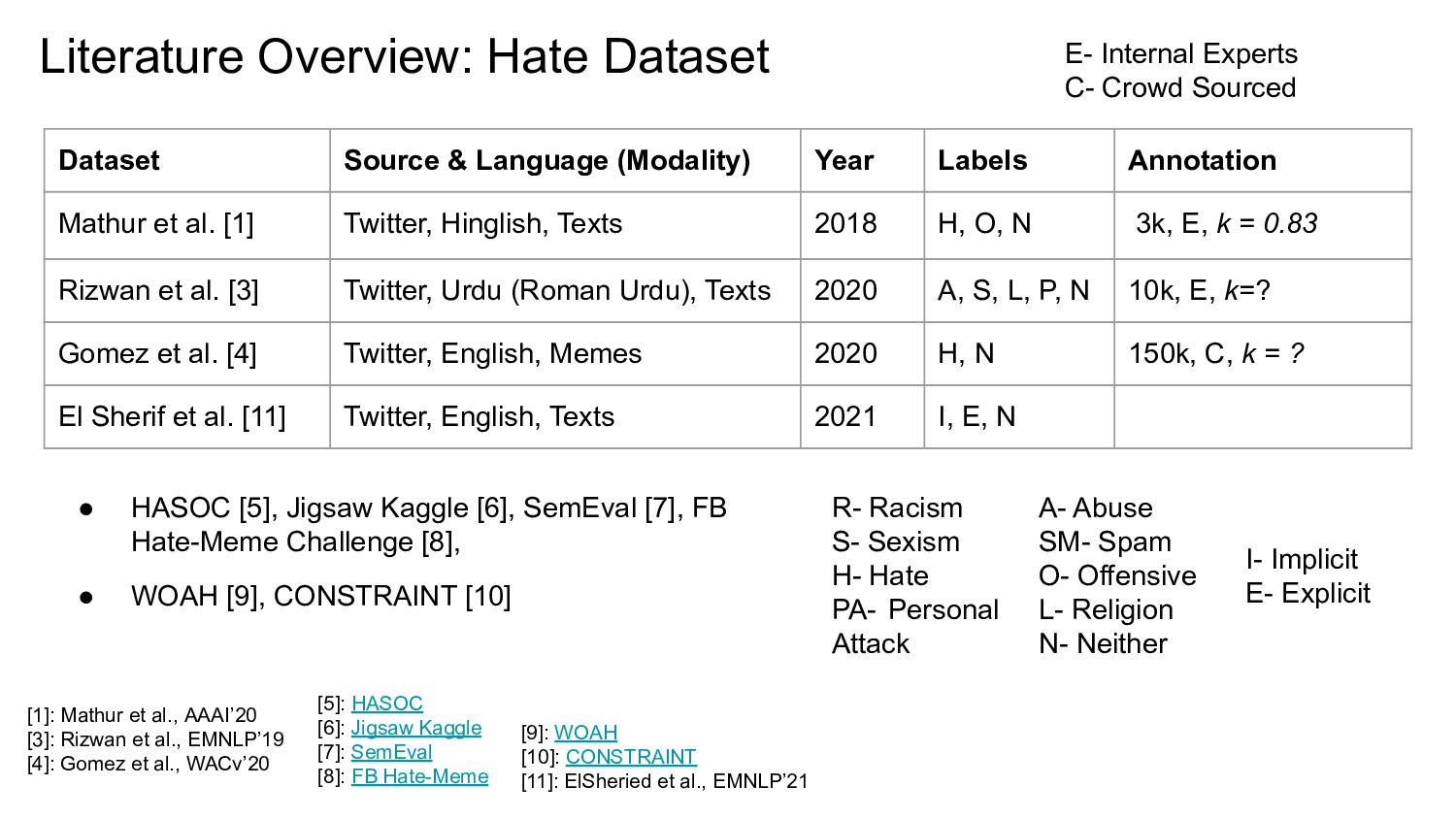
Labels Annotation Waseem & Hovy [1] Twitter, English, Texts 2016 R, S, N 16k, E, k = 0.84 Davidson et al. [2] Twitter, English, Texts 2017 H,O,N 25k, C, k = 0.92 Wulczyn et al. [3] Wikipedia comments, English, Texts 2017 PA, N 100k, C, k = 0.45 Gibert et al. [5] Stormfront, English, Texts 2018 H, N 10k, k = 0.62 Founta et al. [4] Twitter, English, Texts 2018 H, A, S M, N 70k, C, k = ? Albadi et al. [6] Twitter, Arabic, Texts 2018 H, N 6k, C, k = 0.81 R- Racism S- Sexism H- Hate PA- Personal Attack A- Abuse SM- Spam O- Offensive L- Religion N- Neither I- Implicit E- Explicit [1]: Waseem & Hovy, NAACL’16 [2]: Davidson et al., WebSci’17 [3]: Wulczyn et al., WWW’17 [4]: Founta at al., WebSci’18 [5]: Gibert et al., ALW2’18 [6]: Albadi et al., ANLP’20 E- Internal Experts C- Crowd Sourced
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Workflow for Analysing and Mitigating Hate Speech [1]: Tanmoy and](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
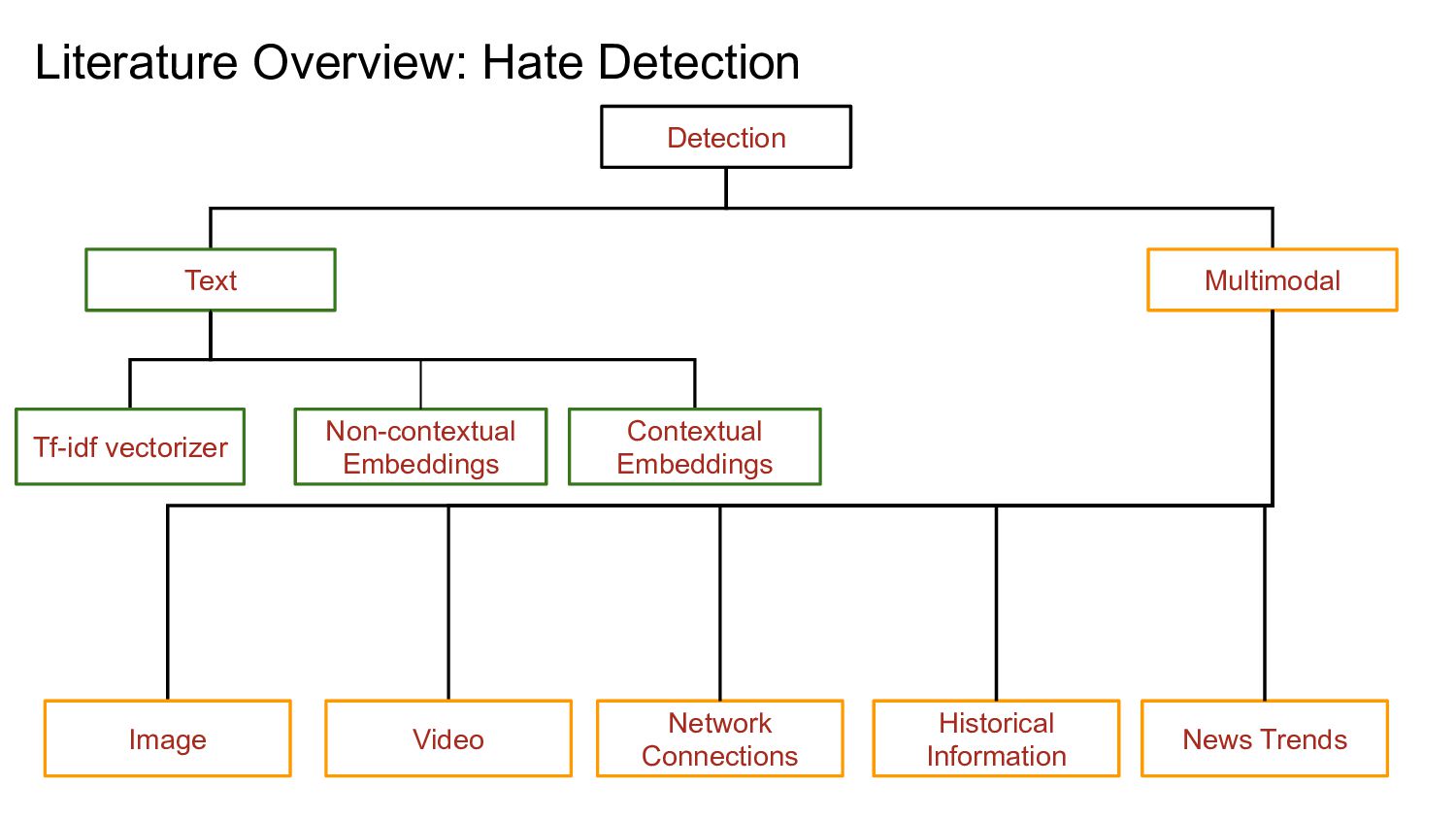
![Literature Overview: Hate Detection • N-gram Tf-idf + LR/SVM [1,2]](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_12.jpg){kind=link}
{kind=link}
![• Dictionaries based detection of explicitly hateful content. [1] •](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_14.jpg){kind=link}
![Linguistic Features • Davidson’s HS Detection was motivated by [2]:](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_15.jpg){kind=link}
![Non-Contextual Embedding [1]: Barjatiya et al., WWW’17 • Using W&H](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Transformer Inspired Prompting [1]: https://www.inovex.de/de/blog/prompt-engineering-guide/ Fig 1: Obtaining Sentiment Label](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_20.jpg){kind=link}
![Transformer Inspired Prompting Zero-Shot [1] One-shot [1] Few-shot [1] [1]:](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1]: Gomez et al., WACV’20 • Proposed a collection of](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_26.jpg){kind=link}
{kind=link}
![Non-English Hate Speech Detection [1]: Rizwan et.al, EMNLP’20 • Codemixed](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_28.jpg){kind=link}
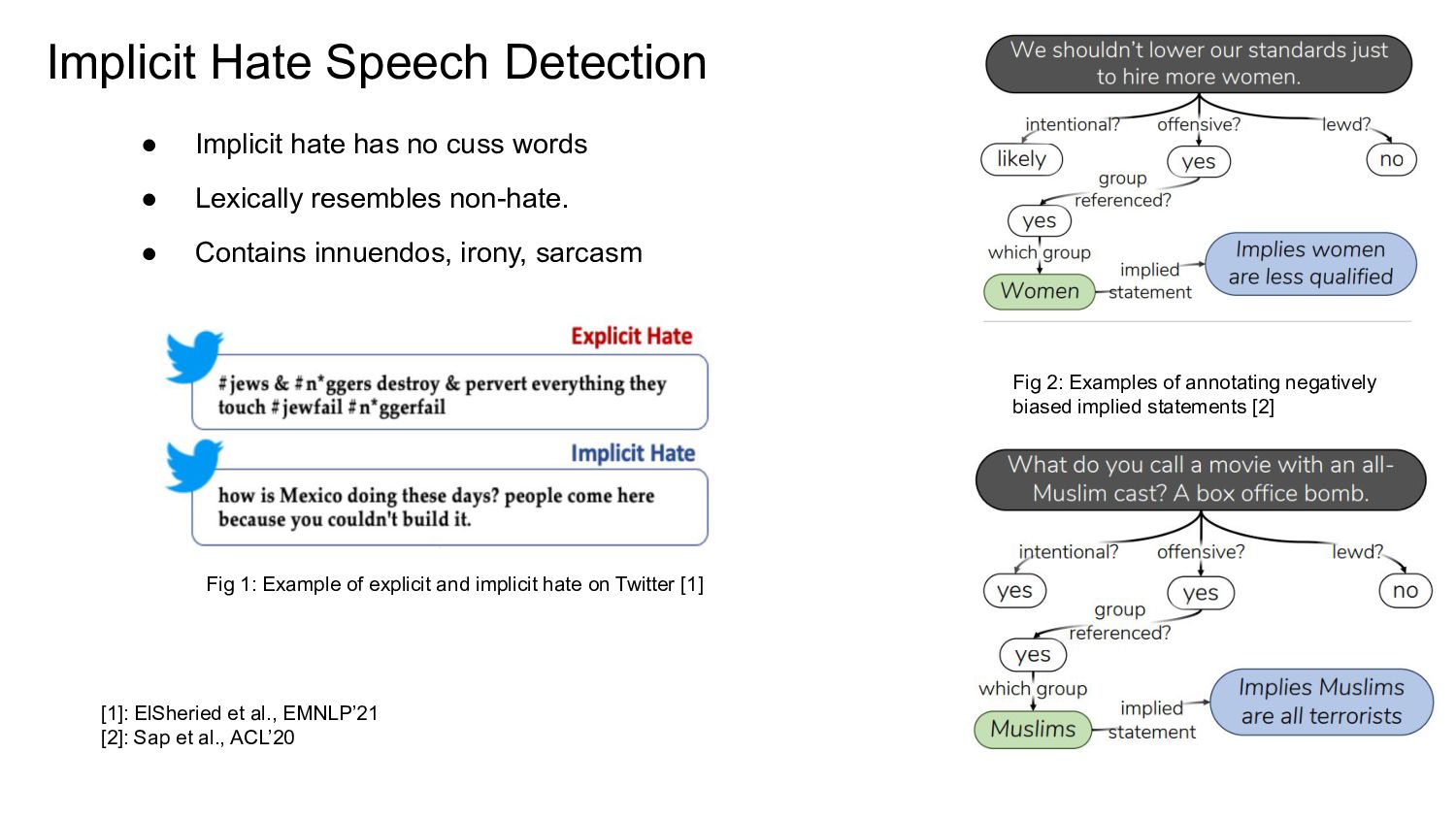{kind=link}
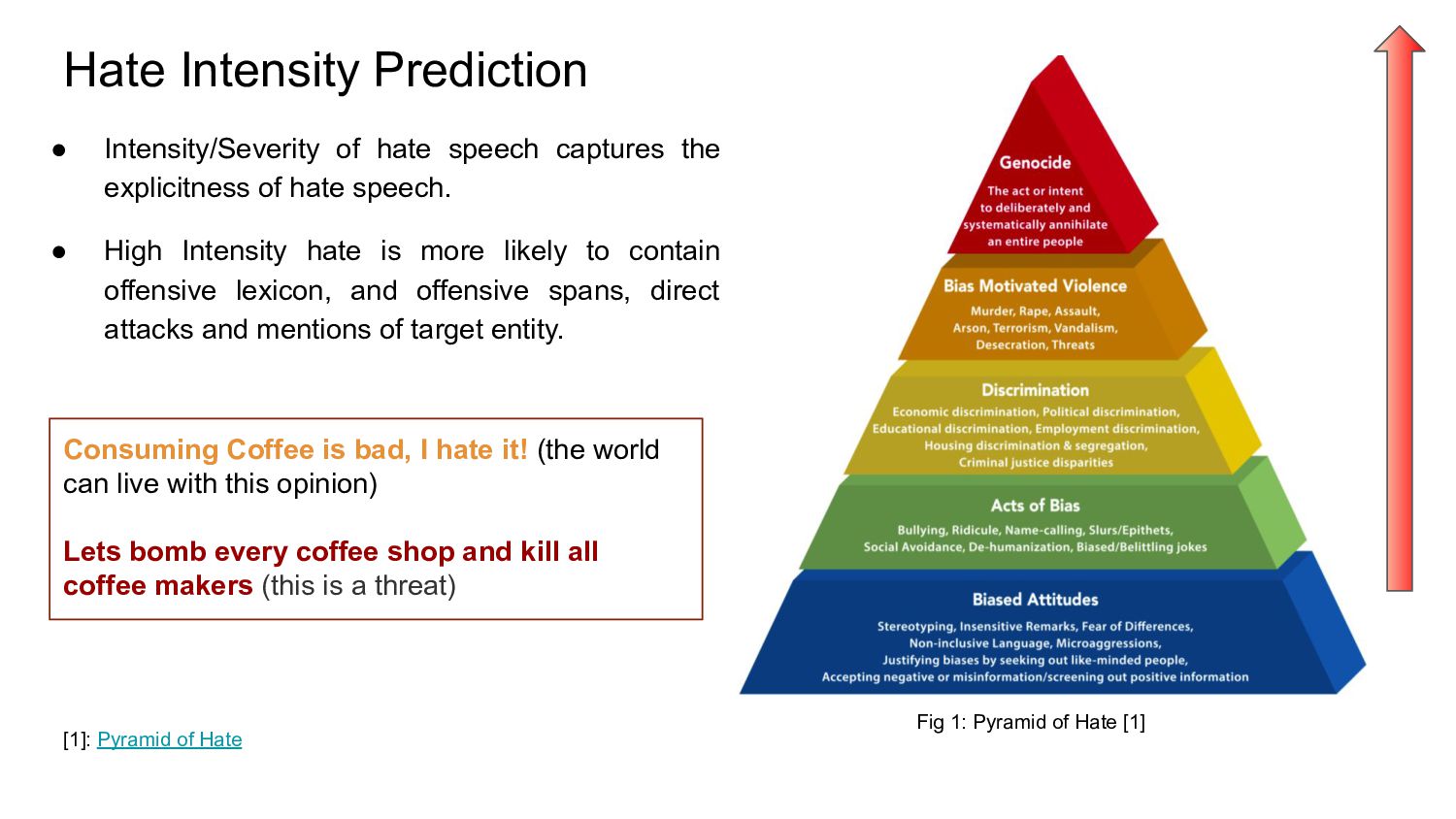{kind=link}
{kind=link}
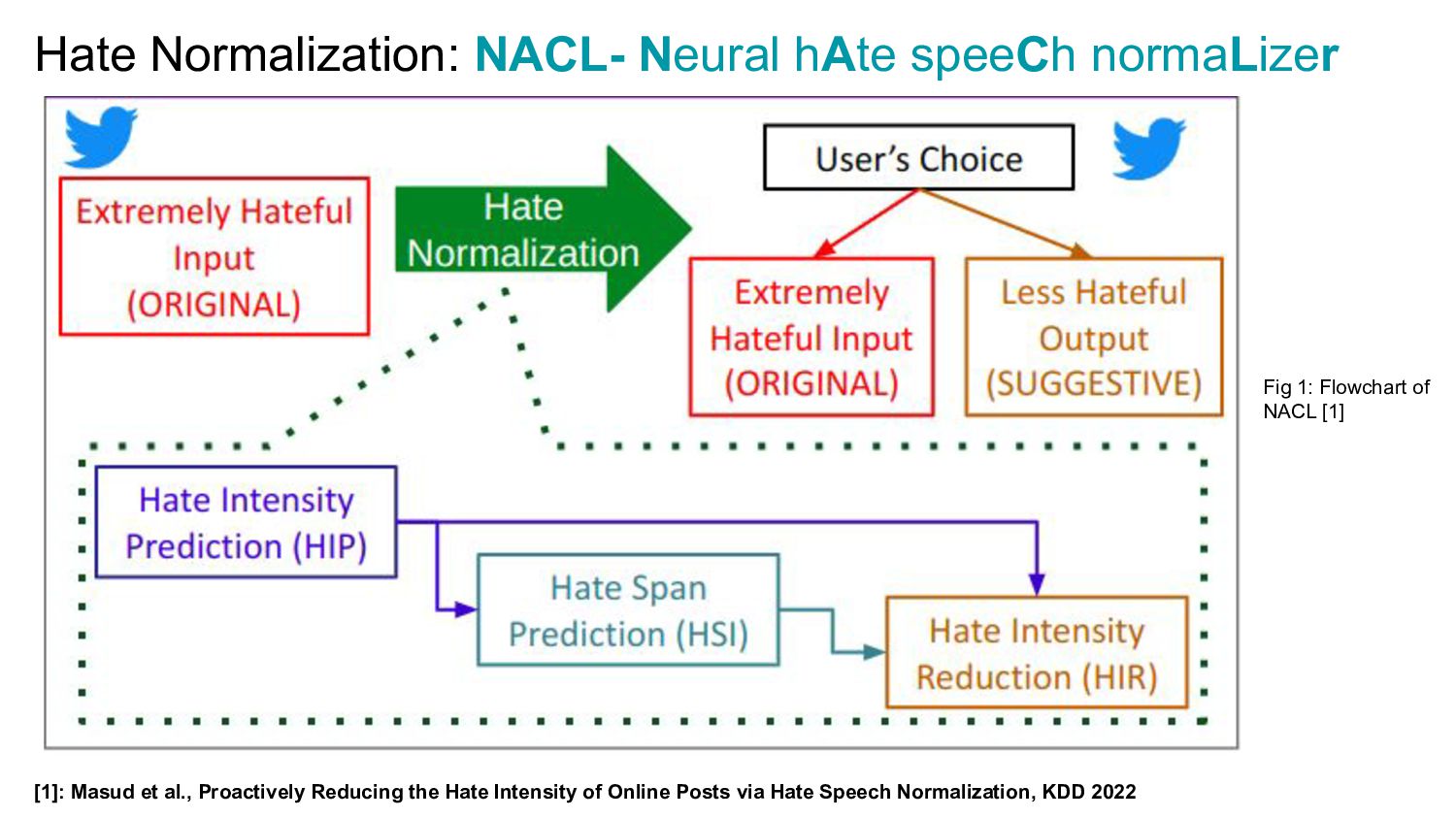{kind=link}
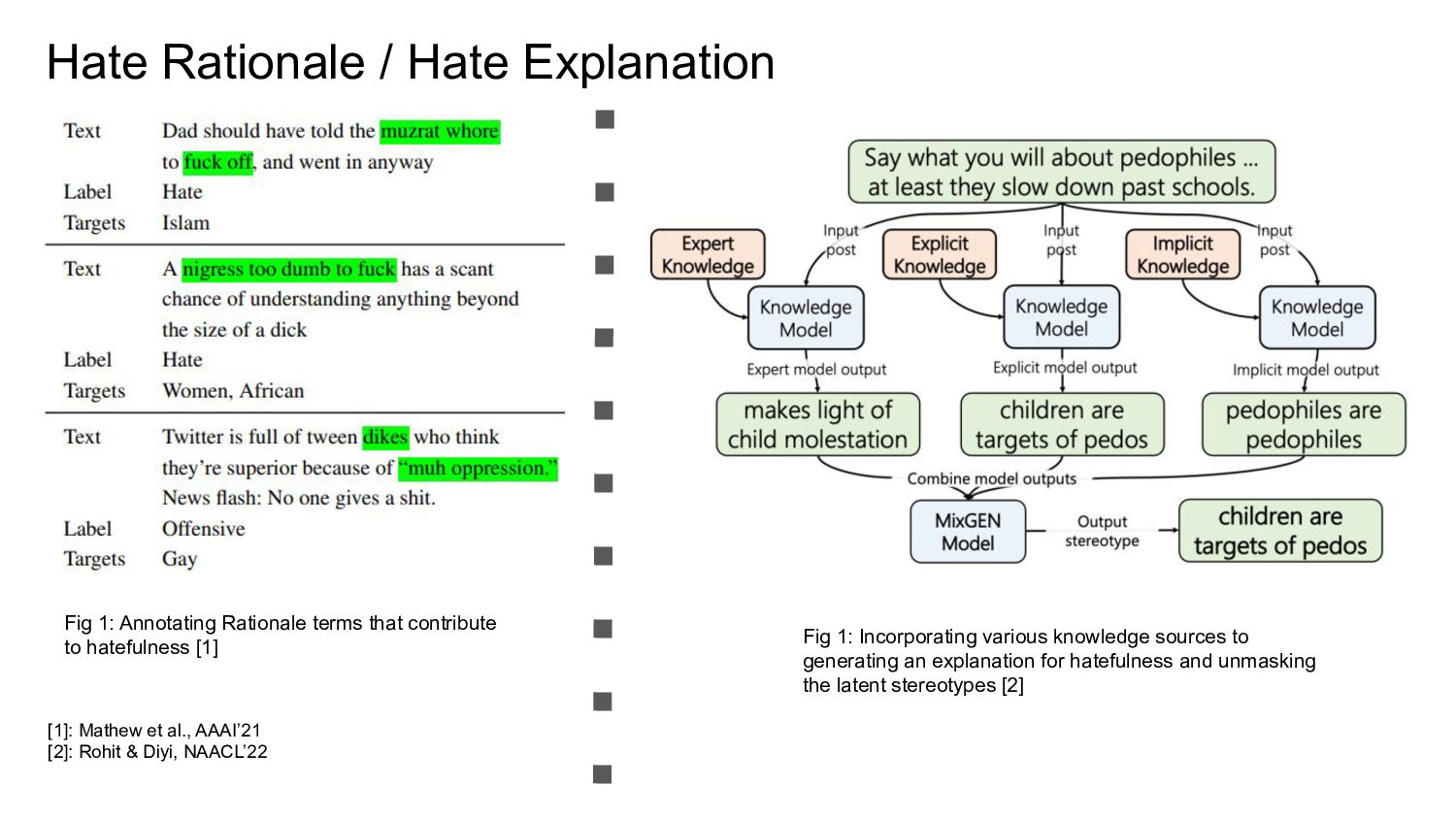{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Public Profile Website: sara-02.github.io Contact Official Email: [email protected] Twitter Profile:](https://files.speakerdeck.com/presentations/12ffb7bfa077483bb982d13c3d742b8b/slide_38.jpg){kind=link}
{kind=link}