Presentation video: https://www.youtube.com/watch?v=U2Bm-Fs3b7Q
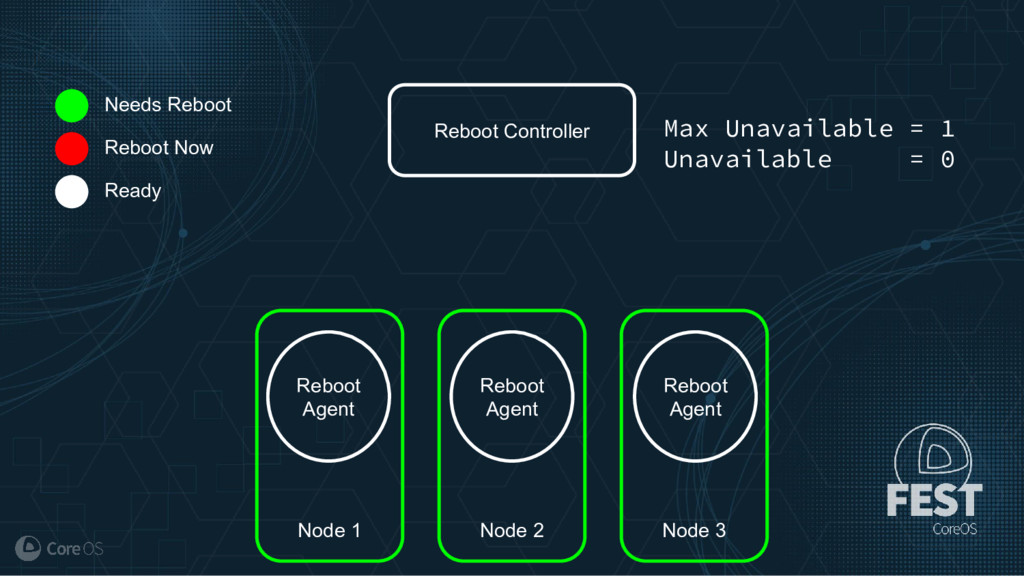
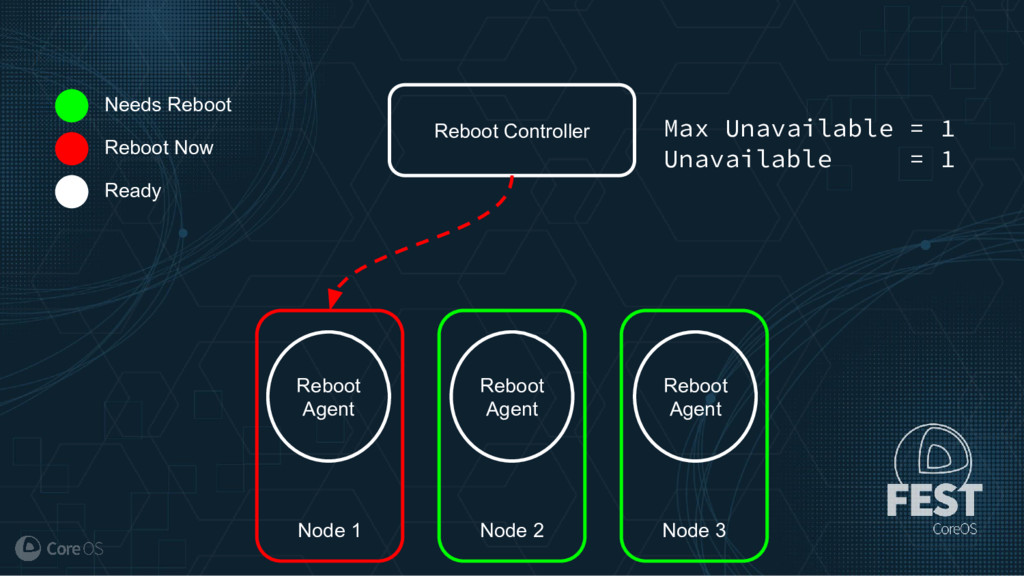
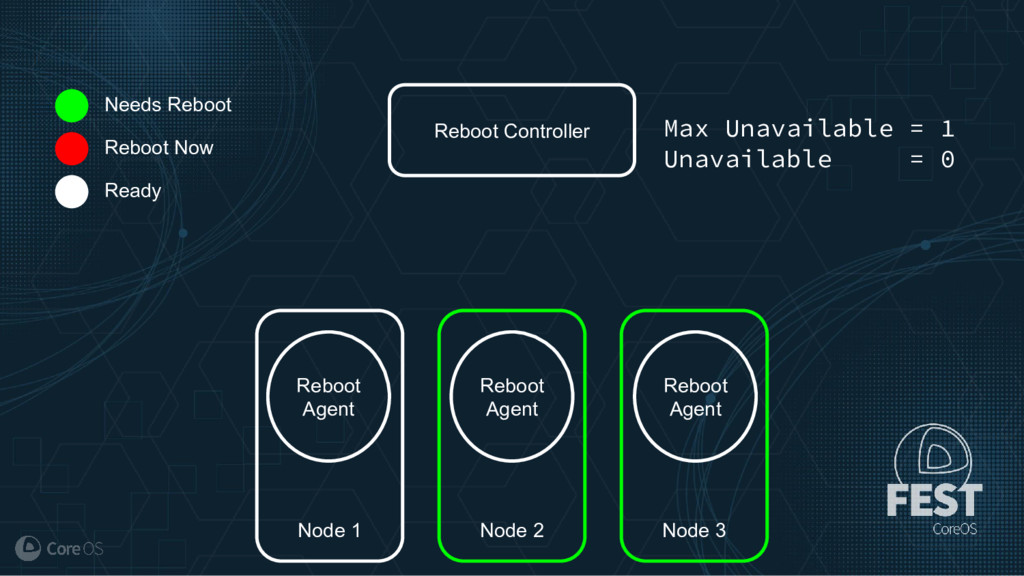
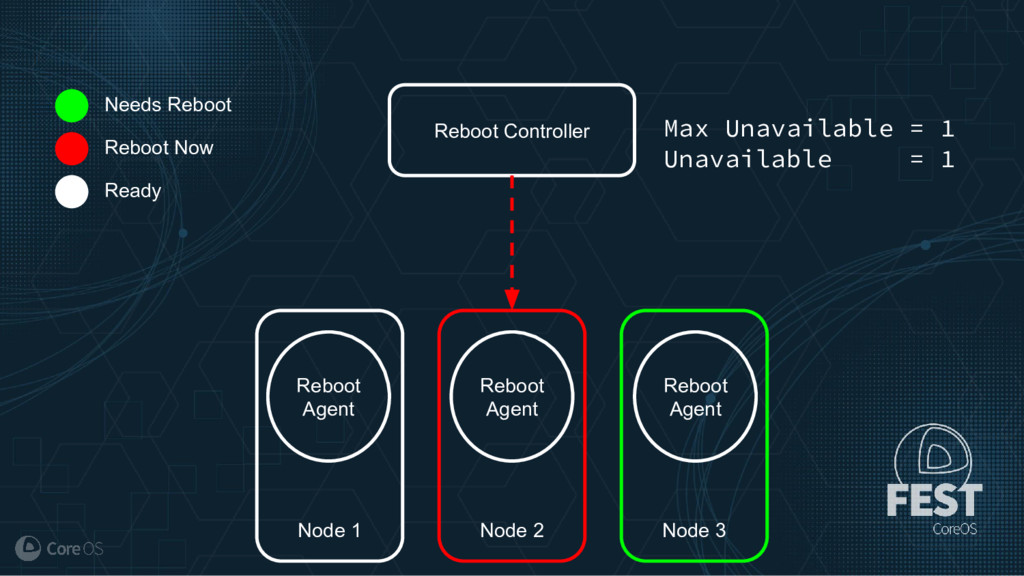
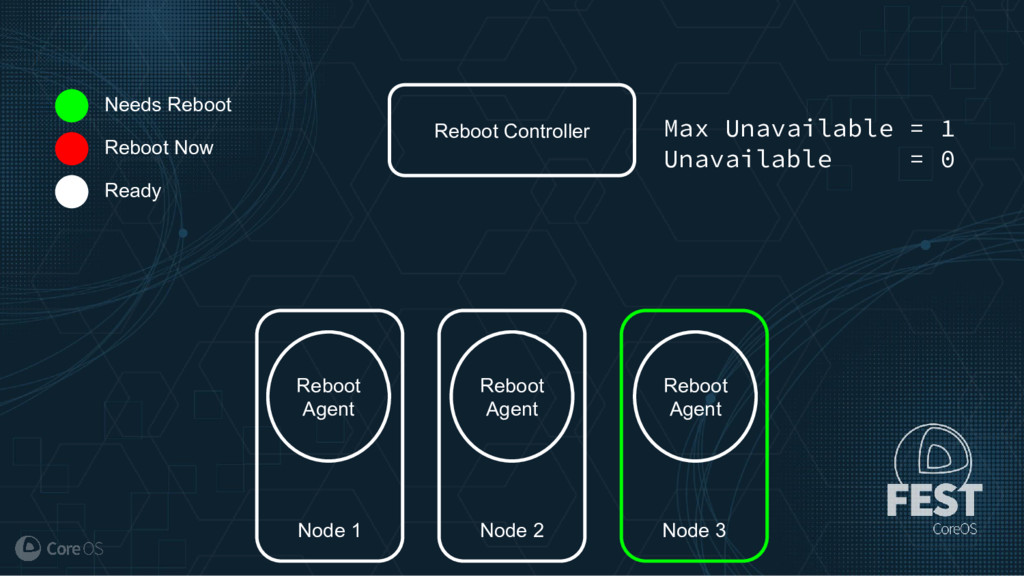
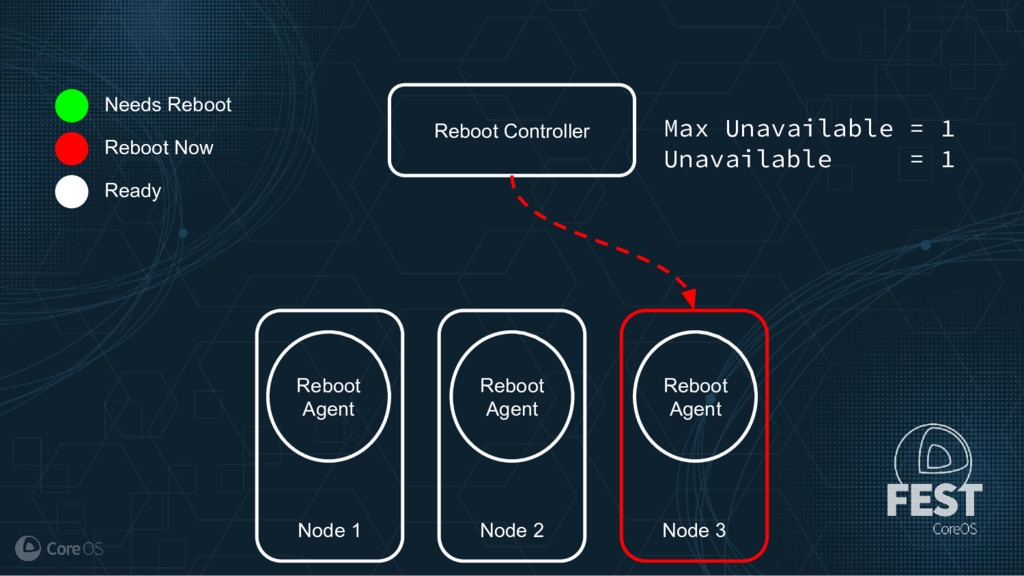
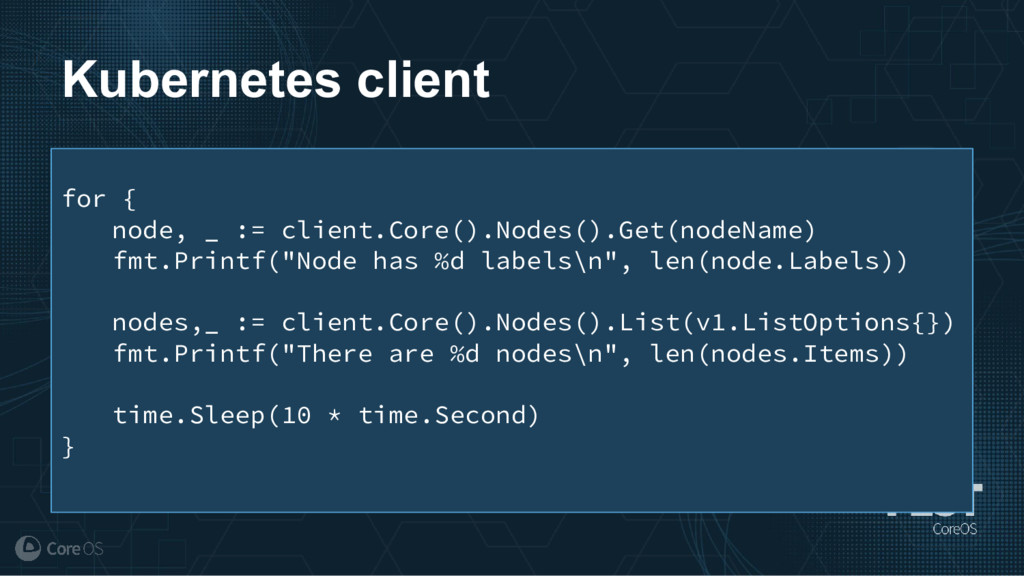
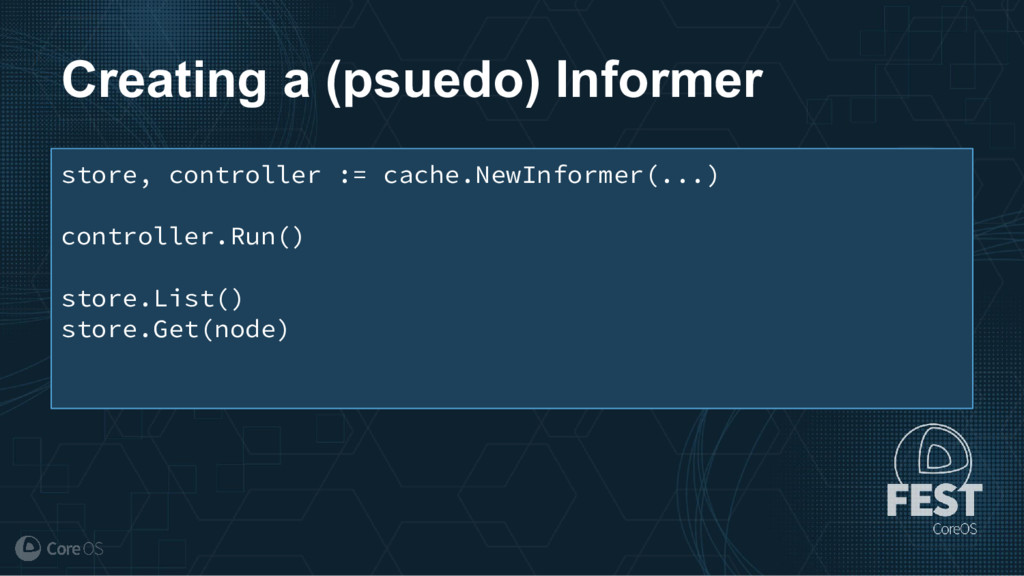
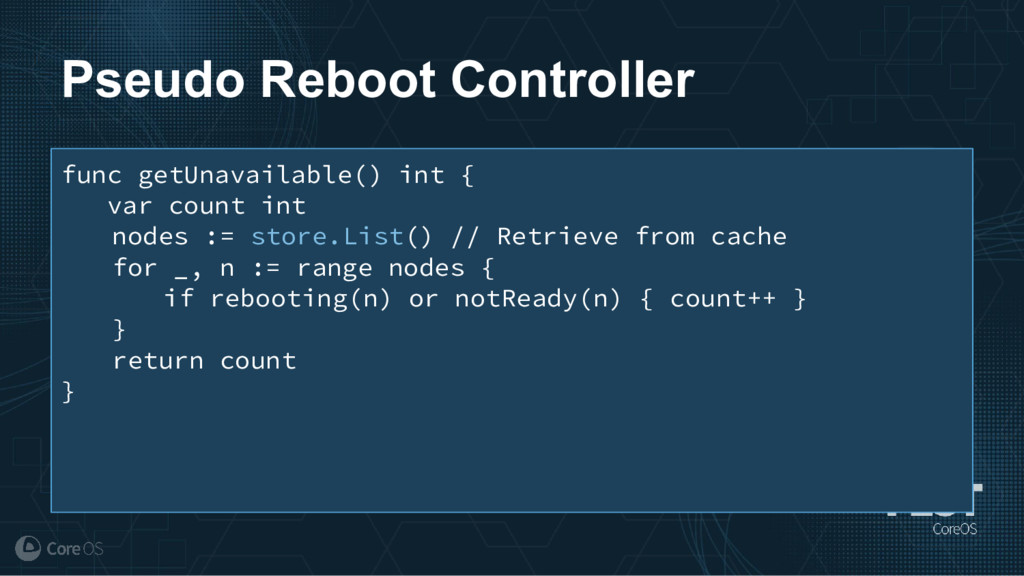
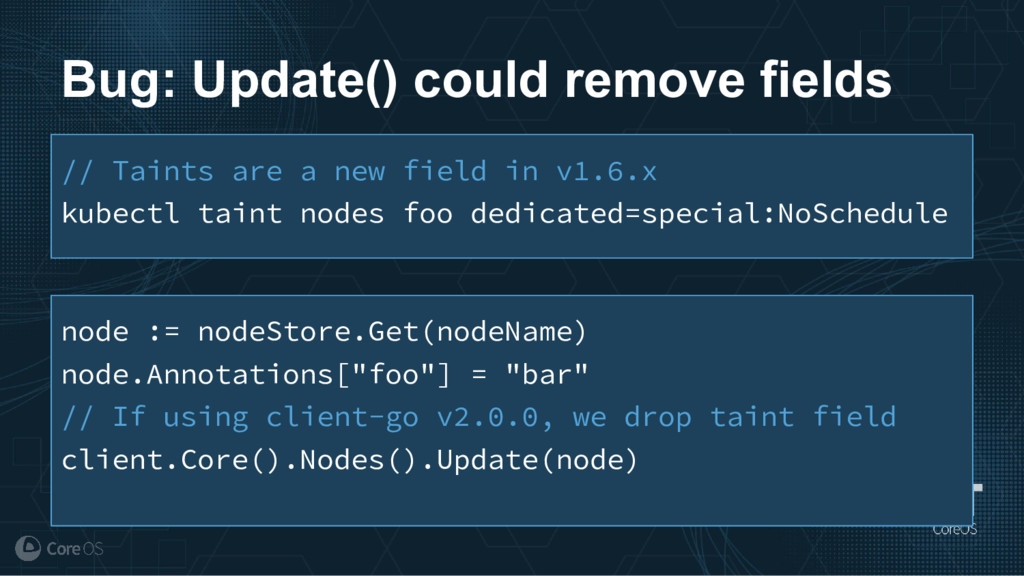
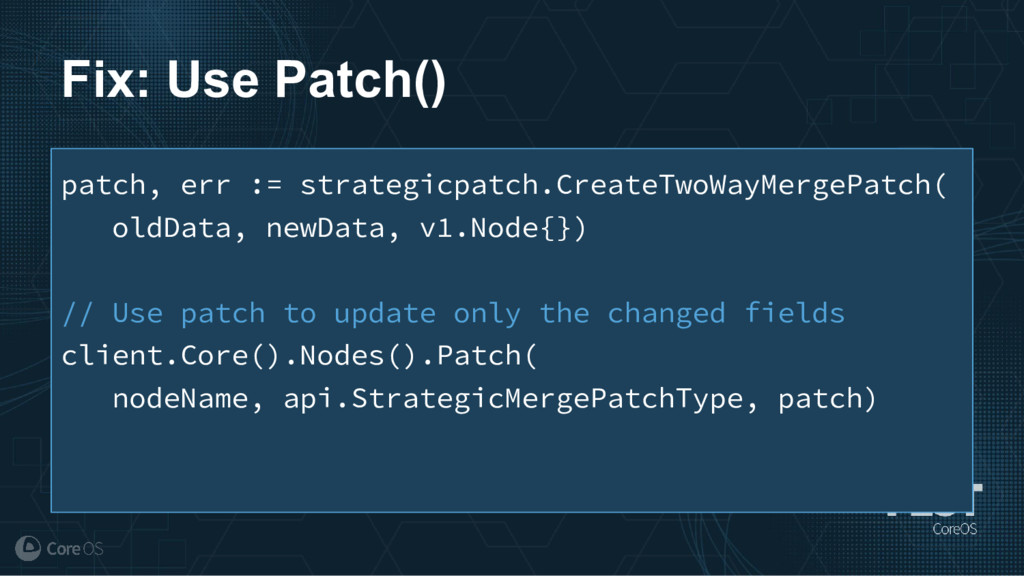
Much of the functionality in a Kubernetes cluster is managed by a reconciliation pattern within "controllers". The node, service, or deployment controllers (just to name a few) watch for changes to objects, then act on those changes to drive your cluster to a desired state. This same pattern can be used to implement custom logic, which can be used to extend the functionality of your cluster without ever needing to modify Kubernetes itself.
This talk will cover how to implement your own custom controller, from contacting the Kubernetes API to using existing libraries to easily watch, react, and update components in your cluster. By building on existing functionality and following a few best practices, you can quickly and easily implement your own custom controller.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks You! Questions? [email protected] Github / Slack: @aaronlevy Twitter: @aaronjlevy](https://files.speakerdeck.com/presentations/fcef1bb644d14fe98c9581af06398092/slide_57.jpg){kind=link}