are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.
(regression, classification, anomaly detection, clustering, recommendation…) • Can a human do it? (with the same amount of data) • Are there successful similar projects?
(regression, classification, anomaly detection, clustering, recommendation…) • Can a human do it? (with the same amount of data) • Are there successful similar projects? • Do you have the data for it?
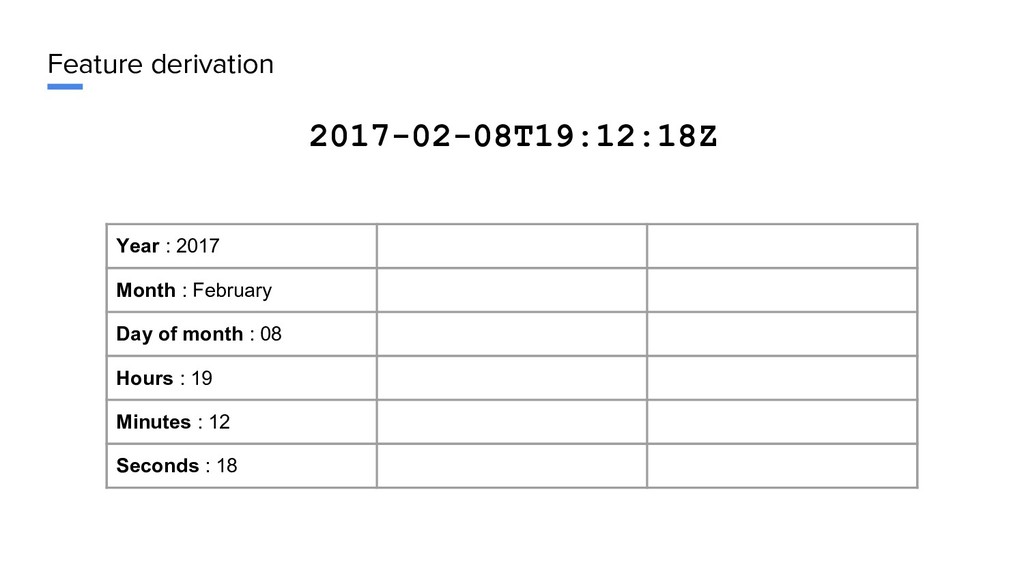
Wednesday Zone A vacation : no Month : February Week of year : 6 Zone B vacation : no Day of month : 08 Holiday ? : no Zone C vacation : yes Hours : 19 Daylight saving ? : no Weather : Cloudy Minutes : 12 Strike ? : no Seconds : 18 Pollution : normal
are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.
are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data. But algo + data is not enough : there is a third piece
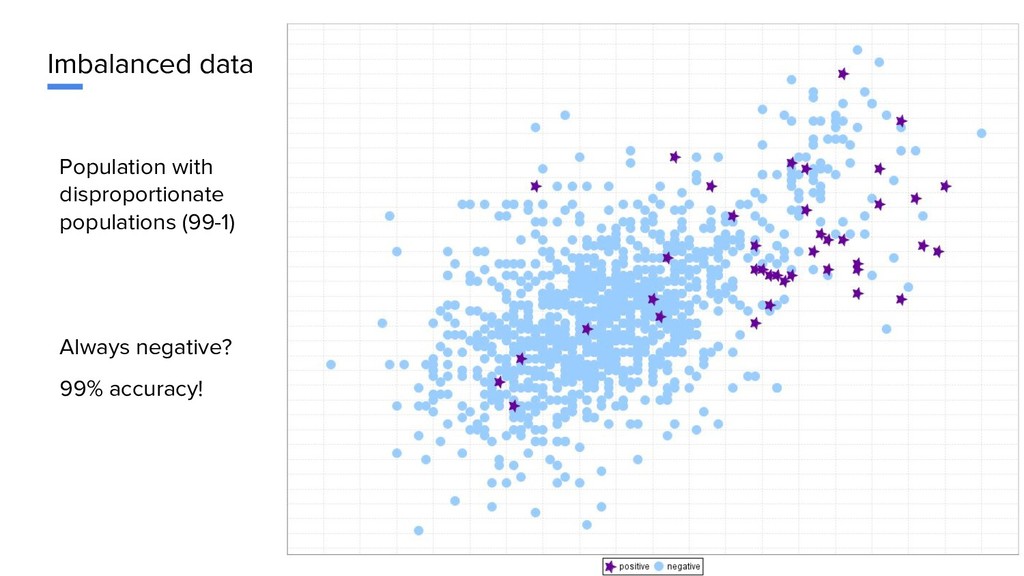
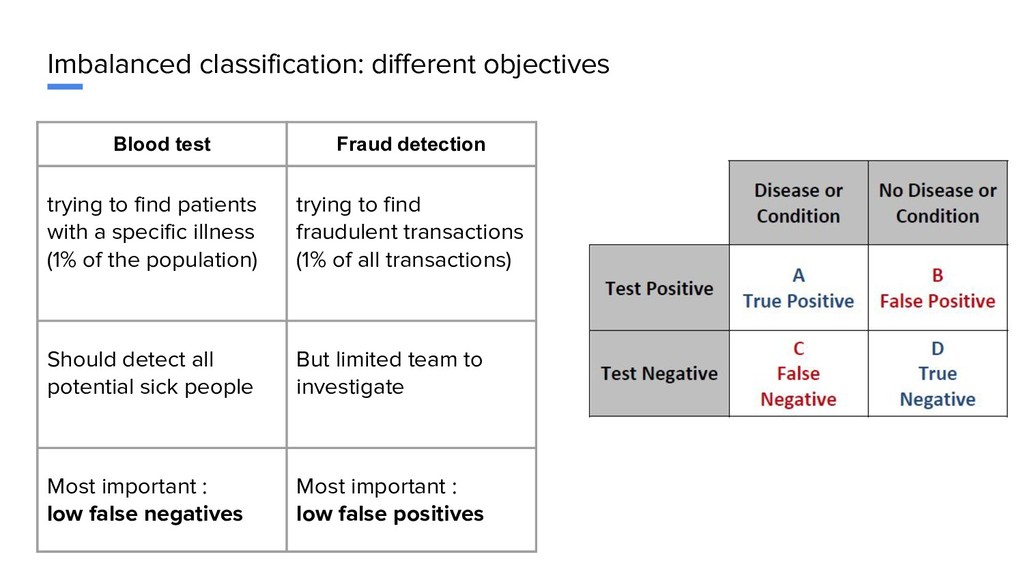
find patients with a specific illness (1% of the population) trying to find fraudulent transactions (1% of all transactions) Should detect all potential sick people But limited team to investigate Most important : low false negatives Most important : low false positives
find patients with a specific illness (1% of the population) trying to find fraudulent transactions (1% of all transactions) Should detect all potential sick people But limited team to investigate Most important : low false negatives Most important : low false positives
find patients with a specific illness (1% of the population) trying to find fraudulent transactions (1% of all transactions) Should detect all potential sick people But limited team to investigate Most important : low false negatives Most important : low false positives Use anomaly detection, not classification
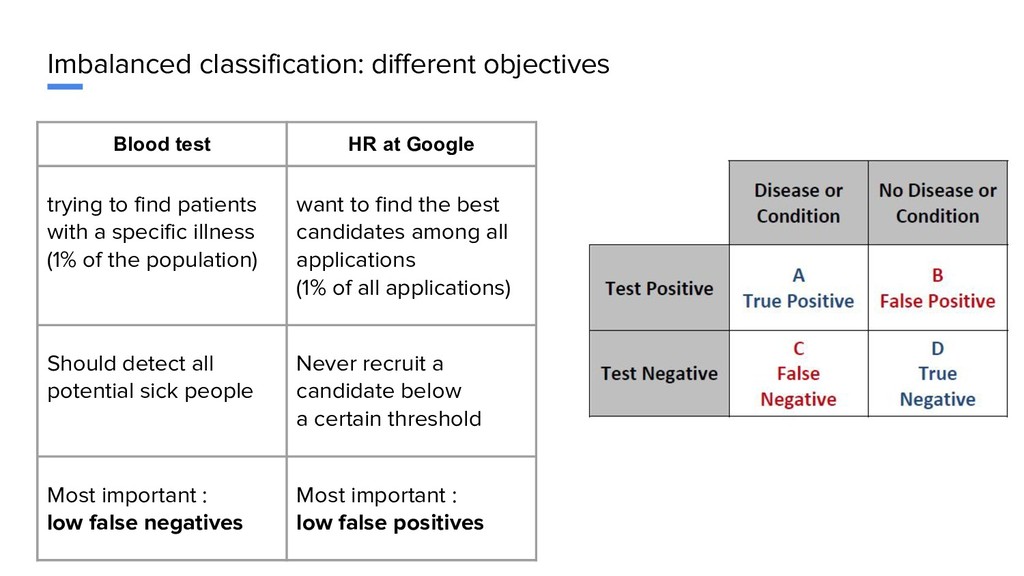
to find patients with a specific illness (1% of the population) want to find the best candidates among all applications (1% of all applications) Should detect all potential sick people Never recruit a candidate below a certain threshold Most important : low false negatives Most important : low false positives
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}