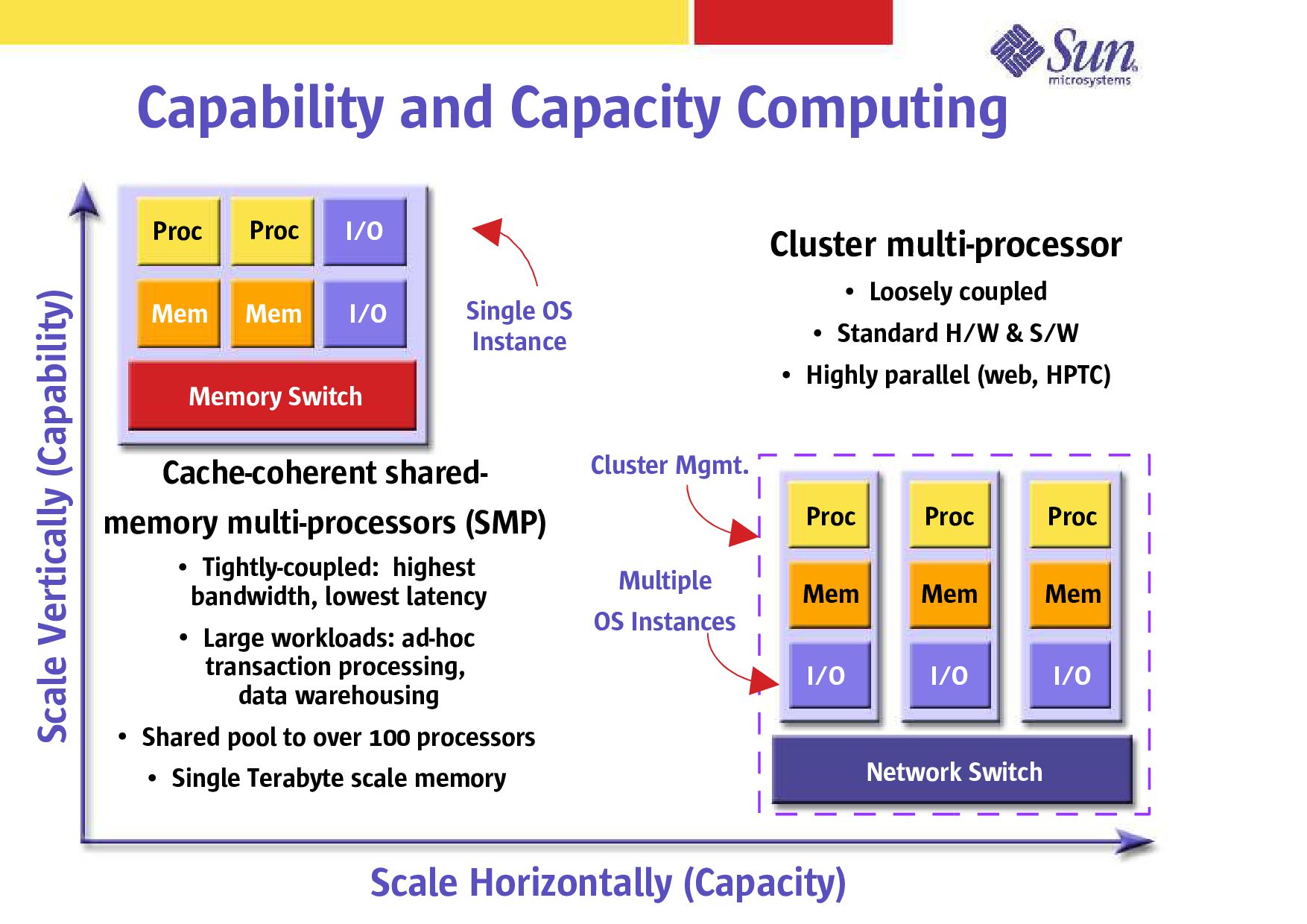
Mem I/O Proc Network Switch Proc Mem I/O Mem I/O Proc Mem I/O Cache-coherent shared- memory multi-processors (SMP) Tightly-coupled: highest bandwidth, lowest latency Large workloads: ad-hoc transaction processing, data warehousing Shared pool to over 100 processors Single Terabyte scale memory Cluster multi-processor Loosely coupled Standard H/W & S/W Highly parallel (web, HPTC) Scale Vertically (Capability) Single OS Instance Multiple OS Instances Scale Horizontally (Capacity) Cluster Mgmt.
System interconnect latency & bandwidth Network and storage I/O Operating system scalability Visualization performance and quality Optimized applications Network service availability #1 issue for real world cluster performance and scaling
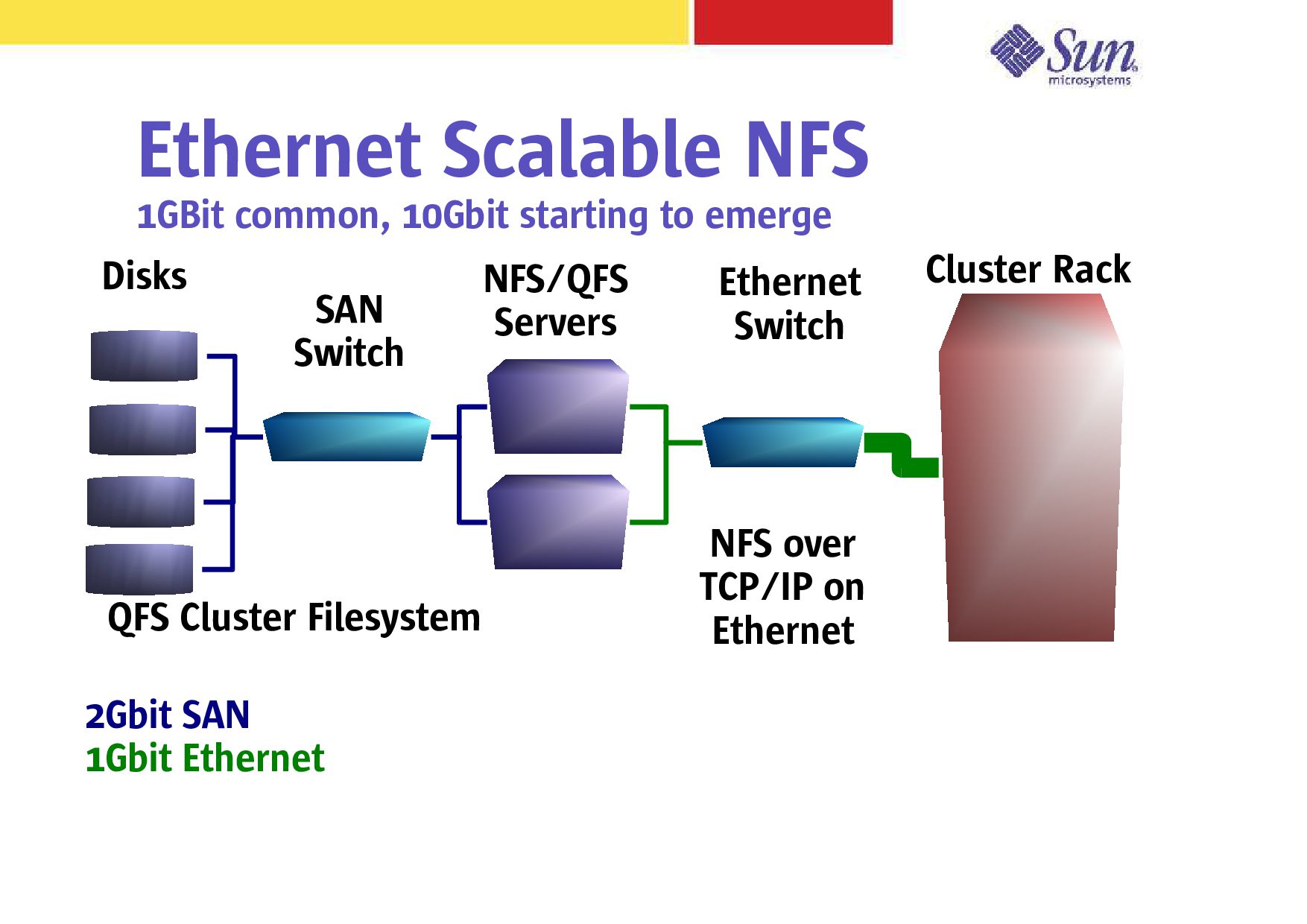
– Solaris now (finally) does Jumbo frames! – 10GigE Bandwidth is I/O bus limited by PCI-X Latency improvements on the way – 100us typical Solaris MPI over TCP/IP – 40-60us MPI over TCP/IP for simpler Linux stack – 10us MPI over TCP/IP with user-mode stack – 5us MPI over raw 1Gbit Ethernet (no switch) – Buffered switch latency 1-25us, 3-6us typical
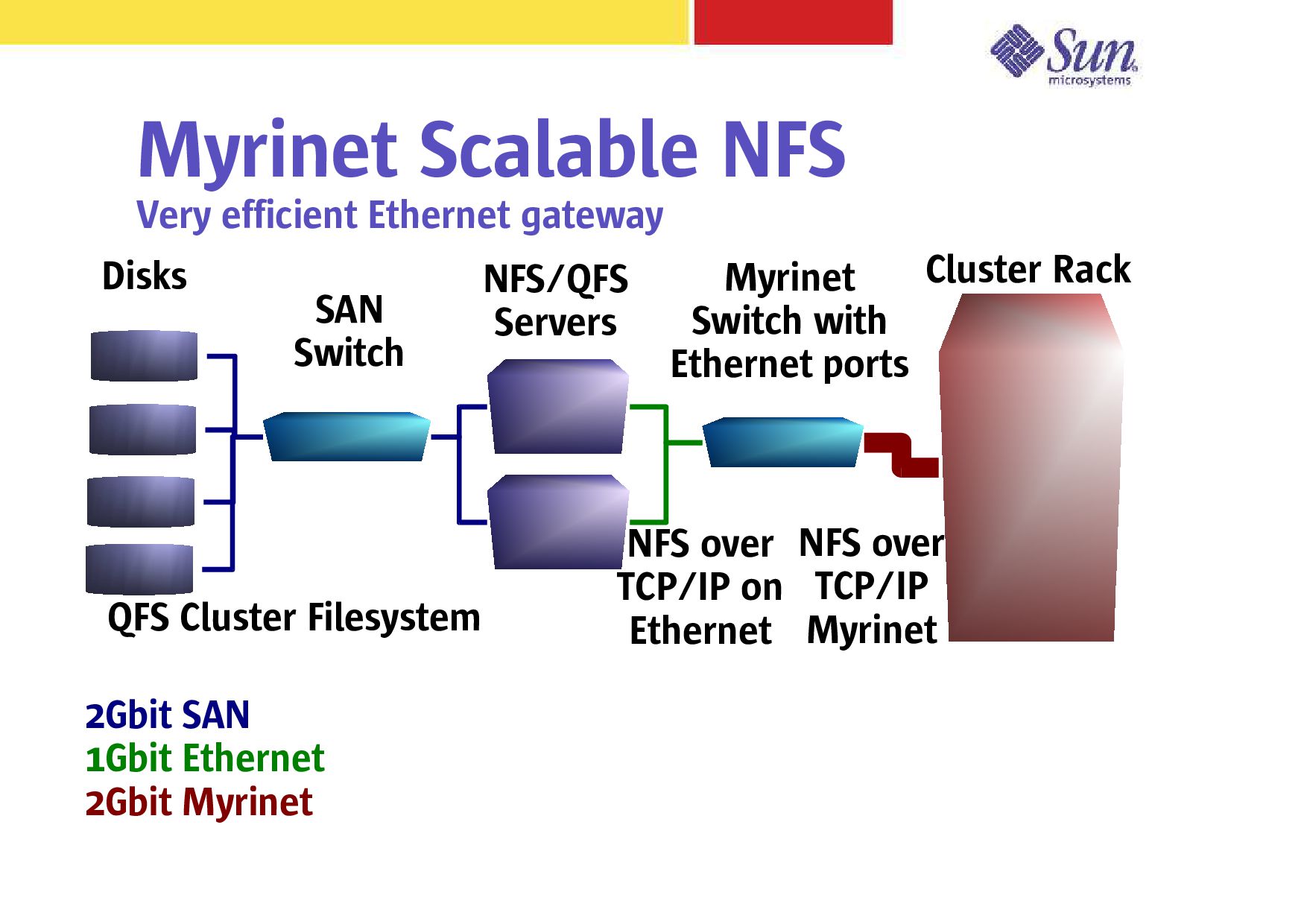
D) – 7us typical Opteron/Linux MPI (rev D) – 5us with latest rev E interface and GM software – 3.5us with new MX software (Oct 03 announce) – Non-Buffered low latency 128 way switch Bandwidth limited by 2Gbit fiber – Dual port rev E card supports 4Gbit each way – Full duplex reaches PCI-X limit of 900 MB/s
Myrinet Switch with Ethernet ports SAN Switch Cluster Rack QFS Cluster Filesystem NFS over TCP/IP Myrinet NFS over TCP/IP on Ethernet 2Gbit SAN 1Gbit Ethernet 2Gbit Myrinet
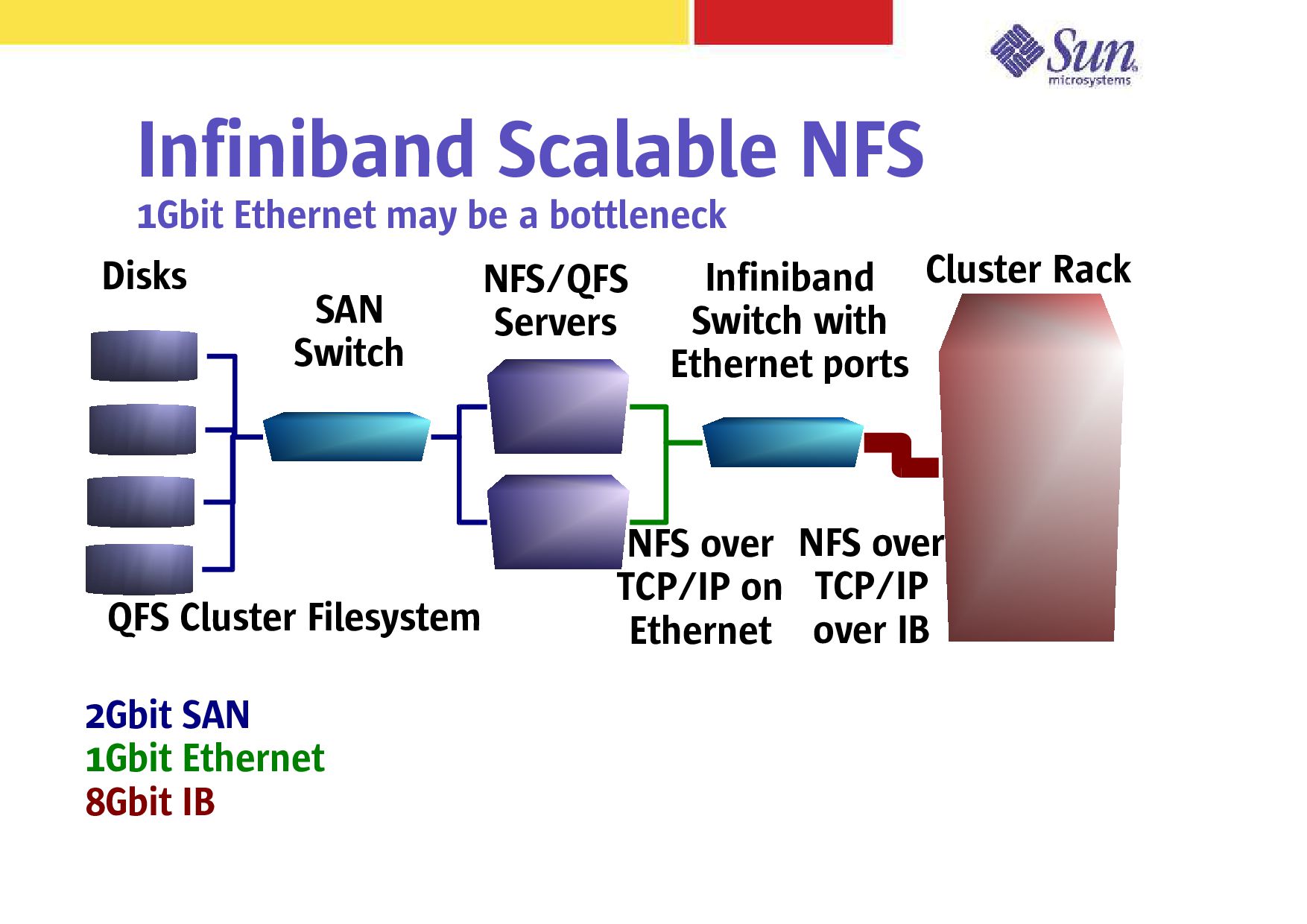
Solaris Express (S10beta) Latency – 5.5us Opteron/Linux MPI – Non-Buffered 24port switch latency 200ns – Larger switches still under 1us Bandwidth limited by PCI-X – IBx4 carries 8Gbits of data on 10Gbit wire – Current limit about 825MBytes/s – Dual IBx4 over PCI-Express x8 chipset announced
– Emulate an 8Gbit Ethernet with NFS/TCP/IP/IB – Emulate an 8Gbit Ethernet with iSCSI/TCP/IP/IB NFS over RDMA – Reduce overhead with direct NFS/IB SRP - SCSI over RDMA Protocol – Reduce overhead with direct SCSI/IB SDP – Sockets Direct Protocol – Reduce overhead with socket library/IB
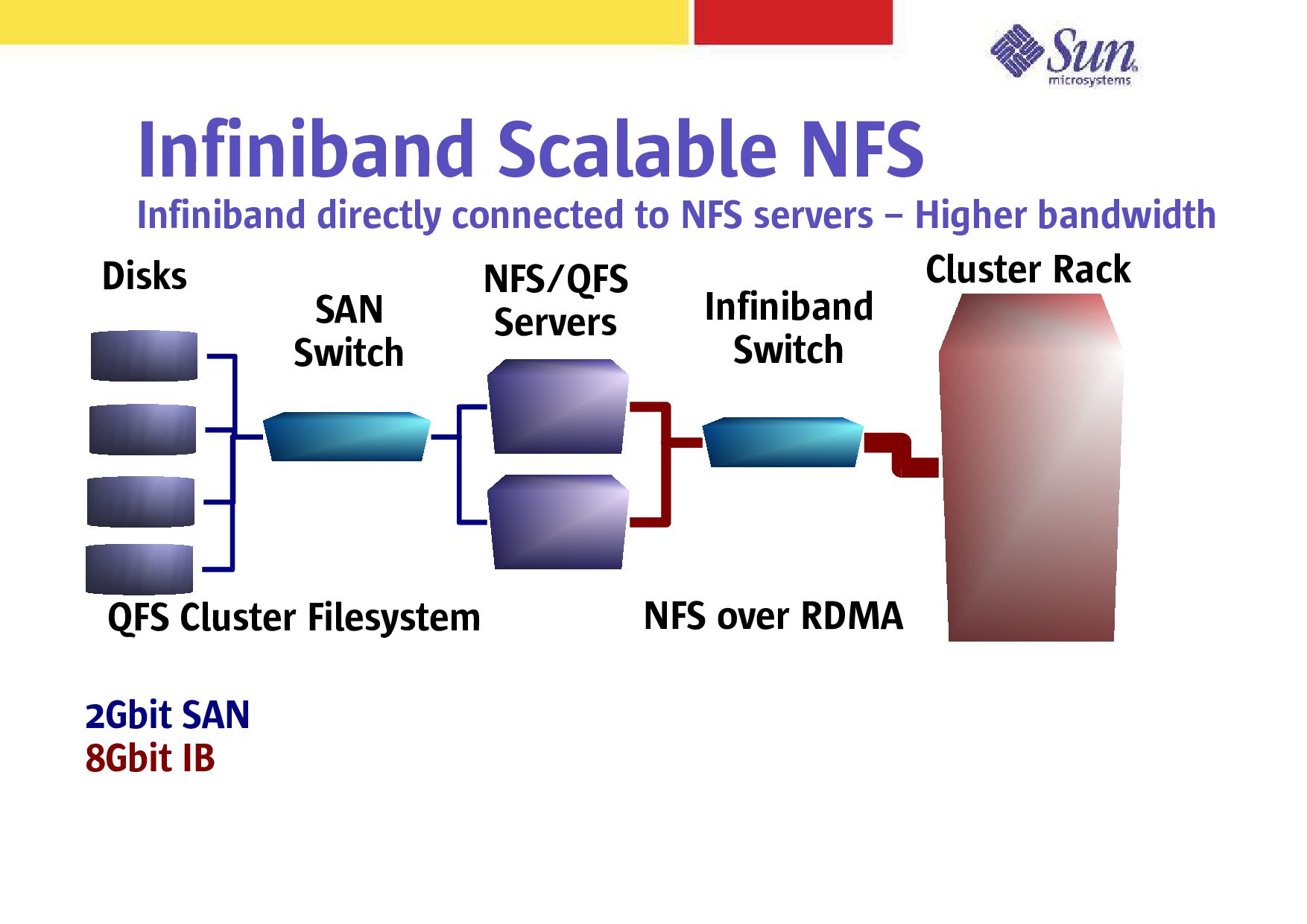
NFS/QFS Servers Infiniband Switch with Ethernet ports SAN Switch Cluster Rack QFS Cluster Filesystem NFS over TCP/IP over IB NFS over TCP/IP on Ethernet 2Gbit SAN 1Gbit Ethernet 8Gbit IB
– Adding 8/64/128 way options Latency – 1.8us Opteron/Linux MPI (Feb 2004 data) – Large Non-Buffered very low latency switch – Low contention fat tree with dynamic routing Bandwidth limited by PCI-X – Current limit about 850 MBytes/s
at 56ns for single Opteron – 100-200ns at 2-4 CPU Opteron or USIIIi – 270-550ns for 16-144 core SMP US IV systems Bandwidth limited by coherency – Global coherency 9.6-57 GB/s with USIII-USIV – Distributed coherency adds bandwidth
up to 400MBytes/s – Older generation Myrinet and Quadrics PCI-X 64bits wide, 133MHz – Current V60x (Xeon) and V20z (Opteron) – Current generation Myrinet and Quadrics – All Infiniband adaptors – Runs up to about 850 Mbytes/s
layer to Infiniband – Each wire at 2.5GHz, carries 2Gbits/s of data – Common usage expected is 8 wires each way – Bandwidth is 16 Gbits/s, 2 Gbytes/s each way Interconnect limitations – Enough capacity for full speed 10Gbit Ethernet – Enough capacity for full speed Infiniband x4 – Limits Infiniband x12 to 66% of capacity
needs – High capacity storage? – A single global filespace? – Low latency MPI? – Large scale SMP with threaded OpenMP? Help is on its way from HPTC@Sun – More partnering, testing, support... – Reference architecture solutions – Professional Service practice guides
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.sun.com/hptc www.sun.com/grid Adrian Cockcroft [email protected]](https://files.speakerdeck.com/presentations/571054cf2bed4fa0bf8e7bad7680dbb5/slide_25.jpg){kind=link}