understand Presto using a Hands-On Lab Environment • Start by creating a 1-node cluster on your desktop/laptop • Move to a production-ready, fully managed, containerized, kubernetes environment in the Cloud • Query SQL and object data sources using ANSI SQL • Run federated queries/joins across multiple sources combining data in S3 and RDS/MYSQL Objective for Today 3
-20 mins) 2) Understand the Technology (15-20 mins) a) What is Presto? b) What is Ahana Cloud? 3) Getting your hands dirty (60 mins) 4) Summary and Close Out (5 mins) 4
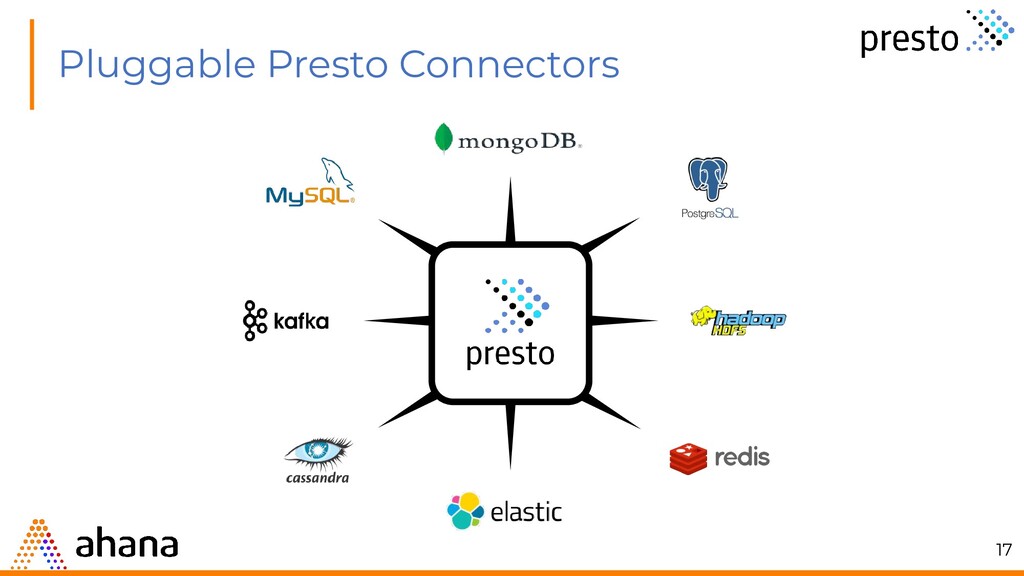
engine • Query in Place • Federated Querying • ANSI SQL Compliant • Designed ground up for fast analytic queries against data of any size • Originally developed at Facebook • Proven on petabytes of data • SQL-On-Anything • Federated pluggable architecture to support many connector • Opensource, hosted on github • https://github.com/prestodb 8
Data Analytics Business Needs • Data-driven decision making • Businesses need more data to iterate over Technology Trends • Disaggregation of Storage and Compute • The rise of data lakes 10
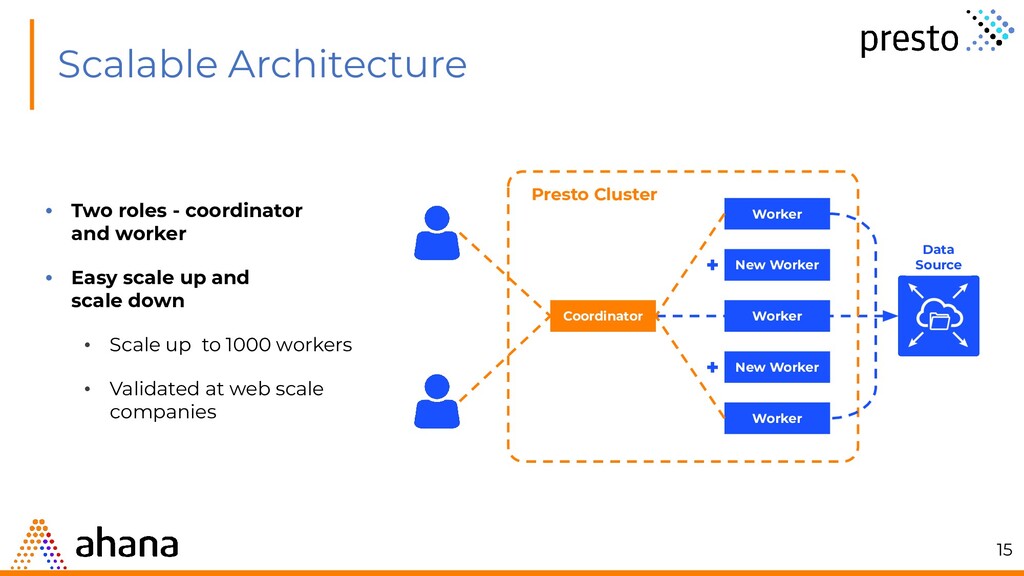
Easy scale up and scale down • Scale up to 1000 workers • Validated at web scale companies New Worker New Worker Worker Worker Worker Coordinator Data Source Presto Cluster 15
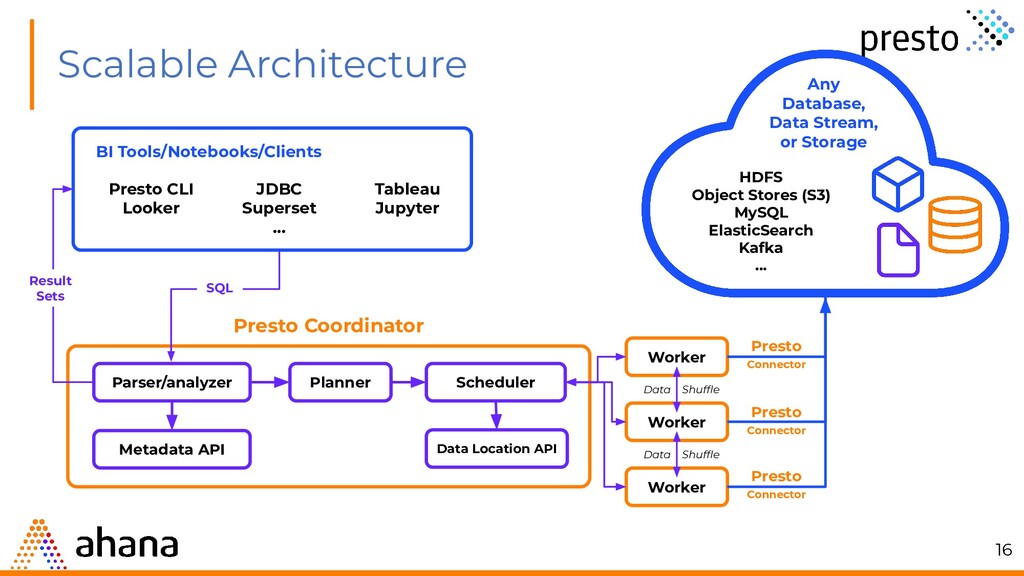
Data Location API Data Shuffle Data Shuffle Presto Connector Presto Coordinator BI Tools/Notebooks/Clients Presto CLI Looker JDBC Superset ... Tableau Jupyter Result Sets SQL Any Database, Data Stream, or Storage HDFS Object Stores (S3) MySQL ElasticSearch Kafka ... Presto Connector Presto Connector 16
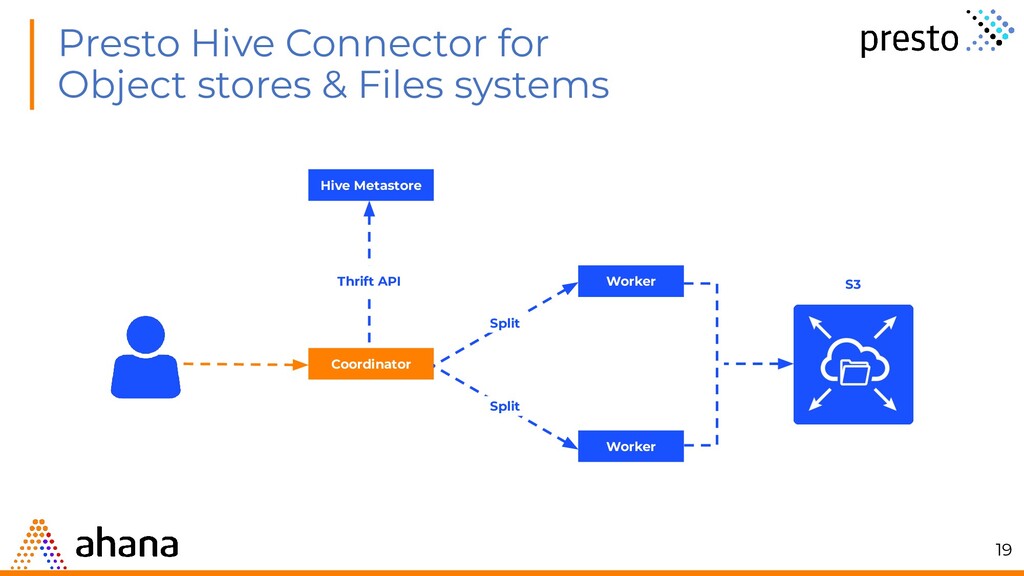
source. • Example: HDFS, AWS S3, Cassandra, MySQL, SQL Server, Kafka • Catalog: Contains schemas from a data source specified by the connector • Schemas: Namespace to organize tables. • Tables: Set of unordered rows organized into columns with types. 18
▪ /etc/presto/jvm.config Many hidden parameters – difficult to tune Just the query engine ▪ No built-in catalog – users need to manage Hive metastore or AWS Glue ▪ No data lake S3 integration Poor out-of-box perf ▪ No tuning ▪ No high-performance indexing ▪ Basic optimizations for even for common queries 24
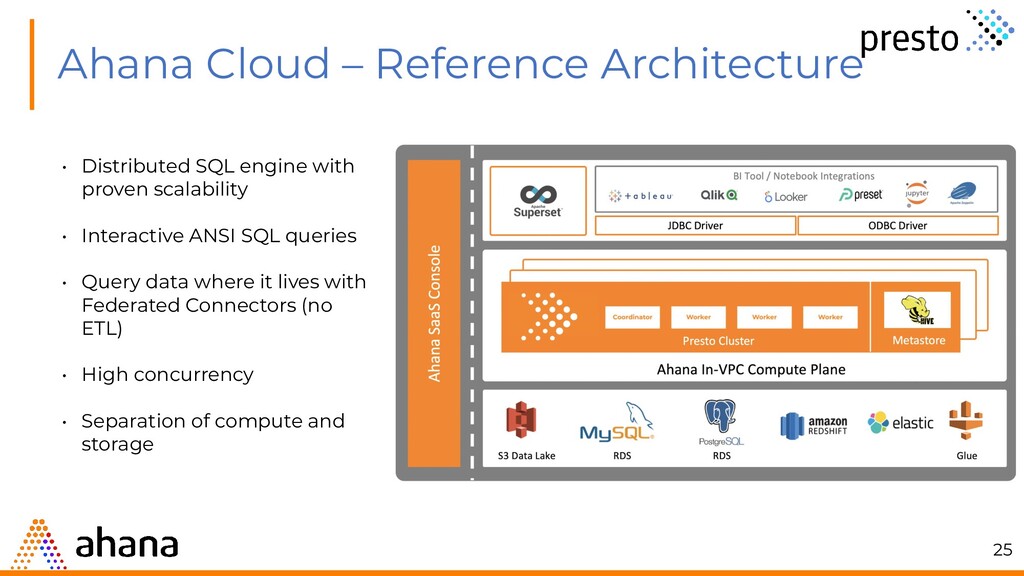
proven scalability • Interactive ANSI SQL queries • Query data where it lives with Federated Connectors (no ETL) • High concurrency • Separation of compute and storage 25
ACCESS BILLING & SUPPORT In-VPC Presto Clusters (Compute Plane) AD HOC CLUSTER 1 TEST CLUSTER 2 PROD CLUSTER N Glue S3 RDS Elasticsearch Ahana Cloud Account Ahana console oversees and manages every Presto cluster Customer Cloud Account In-VPC orchestration of Presto clusters, where metadata, monitoring, and data sources reside Ahana Cloud for Presto 26
in user account Start, stop, restart, resize, terminate – end-to-end cluster life cycle management Amazon sources: S3, RDS/MySQL, RDS/Postgres, Elasticsearch, Redshift Highly available & scalable running in containers on Kubernetes across AZs Flexible analytics stack with BYO - metadata, data source, BI tool or notebook Ahana Cloud Summary Ahana Cloud for Presto Point & Query Cloud Service Gives you Presto as a Cloud Data Warehouse in an open, disaggregated stack 27
your cluster’s PrestoDB Console when running SQL 3. Try queries with more/less workers; how does performance change? 4. Try queries using Parquet format instead of ORC 5. Delete your cluster Things to try later... 38
Presto and Ahana Cloud 2. Effortlessly created and managed Presto clusters 3. Run fast SQL federated queries combining datasets from S3 and MySQL using a BI tool 4. Evaluated Ahana’s flexibility to scale out and scale in based on demand, stop and start clusters, and change data sources. 39
prestodb.slack.com Write a blog for prestodb.io! prestodb.io/blog Join the virtual meetup group & present! meetup.com/prestodb Contribute to the project! github.com/prestodb 42
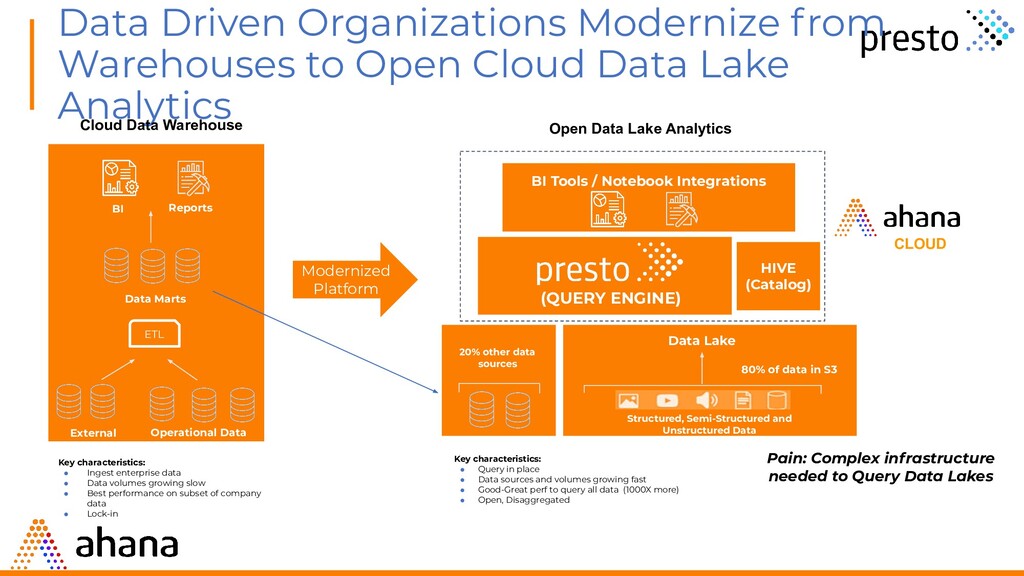
Lake Analytics Key characteristics: • Query in place • Data sources and volumes growing fast • Good-Great perf to query all data (1000X more) • Open, Disaggregated Pain: Complex infrastructure needed to Query Data Lakes Open Data Lake Analytics CLOUD Data Lake Structured, Semi-Structured and Unstructured Data 80% of data in S3 20% other data sources (QUERY ENGINE) HIVE (Catalog) Cloud Data Warehouse Key characteristics: • Ingest enterprise data • Data volumes growing slow • Best performance on subset of company data • Lock-in Modernized Platform BI Tools / Notebook Integrations BI Reports Data Marts ETL External Data Operational Data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}