Individual Units in a Deep Neural Network) ② 効率的な変圧器調査 (原⽂: Efficient Transformers: A Survey) ③ テキスト⽣成のための現代的な⽅法 (原⽂: Modern Methods for Text Generation) ④ ディープニューラルネットワークを⽤いた継続学習の全体像. 忘れられた教訓とアクティブでオープンワールドの学習への橋渡し (原⽂: A Wholistic View of Continual Learning with Deep Neural Networks: Forgotten Lessons and the Bridge to Active and Open World Learning) ⑤ ExGAN: 極端なサンプルの逆襲的⽣成 (原⽂: ExGAN: Adversarial Generation of Extreme Samples) ⑥ フローエッジガイド動画完成 (原⽂: Flow-edge Guided Video Completion) ⑦ ベイズパーセプトロン:完全ベイズニューラルネットワークを⽬指して (原⽂: Bayesian Perceptron: Towards fully Bayesian Neural Networks) ⑧ ワンショット 3D 写真 (原⽂: One Shot 3D Photography) ⑨ MEAL V2: バニラ ResNet-50 をトリックなしで ImageNet 上で 80% 以上の Top-1 精度にブースト (原⽂: MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks) ⑩ 地に⾜のついた⾔語学習を速くゆっくりと (原⽂: Grounded Language Learning Fast and Slow)
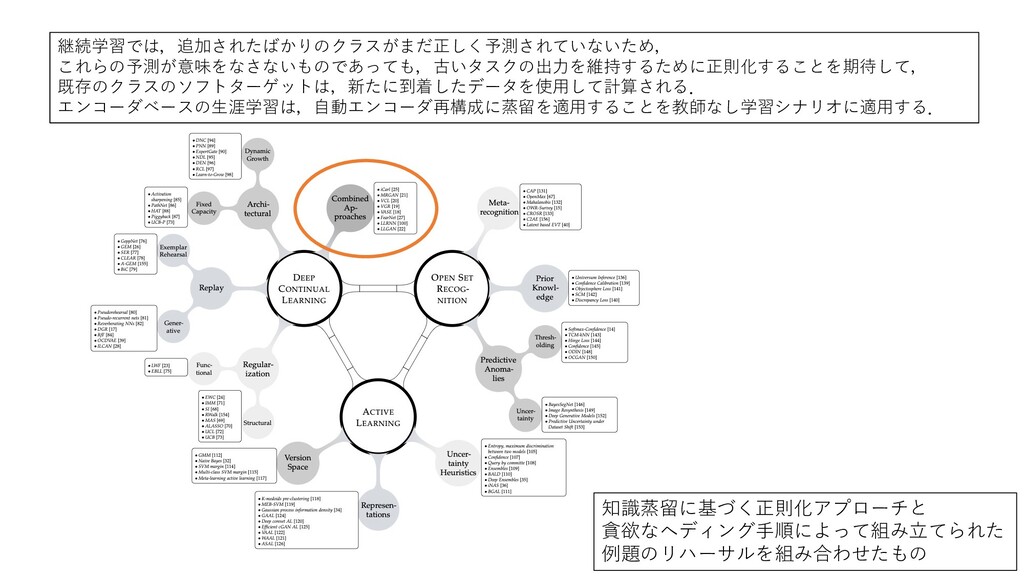
with Deep Neural Networks: Forgotten Lessons and the Bridge to Active and Open World Learning) • 現在の深層学習研究はベンチマーク評価が主流である. • 専⽤のテストセットで経験的に良好な結果が得られれば, その⼿法は好ましいものとみなされる. • この考え⽅は,ベンチマークデータの連続的なセットが 研究されている継続学習の分野にもシームレスに反映されている. • (継続学習の) 中⼼的な課題は反復的なパラメータ更新により, 以前に取得した表現が壊滅的に忘却しないように保護することだが, 個々の⼿法の⽐較は,現実世界でのアプリケーションとは切り離して 扱われ,⼀般的には蓄積されたテストセットの性能を監視することで 判断されるクローズドワールドの仮定が依然として優勢であり, モデルが訓練に使⽤されたのと同じ分布に由来するデータに 遭遇することが保証されていることを前提としている. http://arxiv.org/abs/2009.01797v2 (クローズドワールド: 限られた数のオブジェクトが存在すると仮定された空間) 1/3
with Deep Neural Networks: Forgotten Lessons and the Bridge to Active and Open World Learning) • ニューラルネットワークは未知のインスタンスに対して過信した 誤った予測を⾏い,破損したデータに直⾯して故障することが よく知られており,⼤きな課題となっている. • 本研究では,観測されたデータセットの外で統計的に乖離した データを識別 (オープンセット認識),そして期待される性能向上が 最⼤になるようにデータを段階的に照会する能動学習の 隣接分野からの注⽬すべき教訓が,ディープラーニング時代には しばしば⾒落とされていると主張. • これらの⾒落とされた教訓に基づいて,我々はディープニューラル ネットワークでの継続学習,能動学習,オープンセット認識を 橋渡しする統合的な視点を提案する. http://arxiv.org/abs/2009.01797v2 2/3
Compiler for Deep Learning) ② ハードウェア宝くじ (原⽂: The Hardware Lottery) ③ フローエッジガイド動画完成 (原⽂: Flow-edge Guided Video Completion) ⇒ Recent #.6 ④ AI を発掘する「発掘AI」。ギャラリーの中の象 (原⽂: Excavating "Excavating AI": The Elephant in the Gallery) ⑤ ディープニューラルネットワークを⽤いた継続学習の全体像。 忘れられた教訓とアクティブでオープンな世界の学習への橋渡し (原⽂: A Wholistic View of Continual Learning with Deep Neural Networks: Forgotten Lessons and the Bridge to Active and Open World Learning) ⇒ Recent #.4 ⑥ Brain2Word.⾔語⽣成のためのデコード脳活動 (原⽂: Brain2Word: Decoding Brain Activity for Language Generation) ⑦ テキスト⽣成のための現代的な⽅法 (原⽂: Modern Methods for Text Generation) ⇒ Recent #.3 ⑧ 効率的な変圧器調査 (原⽂: Efficient Transformers: A Survey) ⇒ Recent #.2 ⑨ 地に⾜のついた⾔語学習を速くゆっくりと (原⽂: Grounded Language Learning Fast and Slow) ⇒ Recent #.10 ⑩ ⾃動定理証明のための⽣成的⾔語モデリング (原⽂: Generative Language Modeling for Automated Theorem Proving)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}