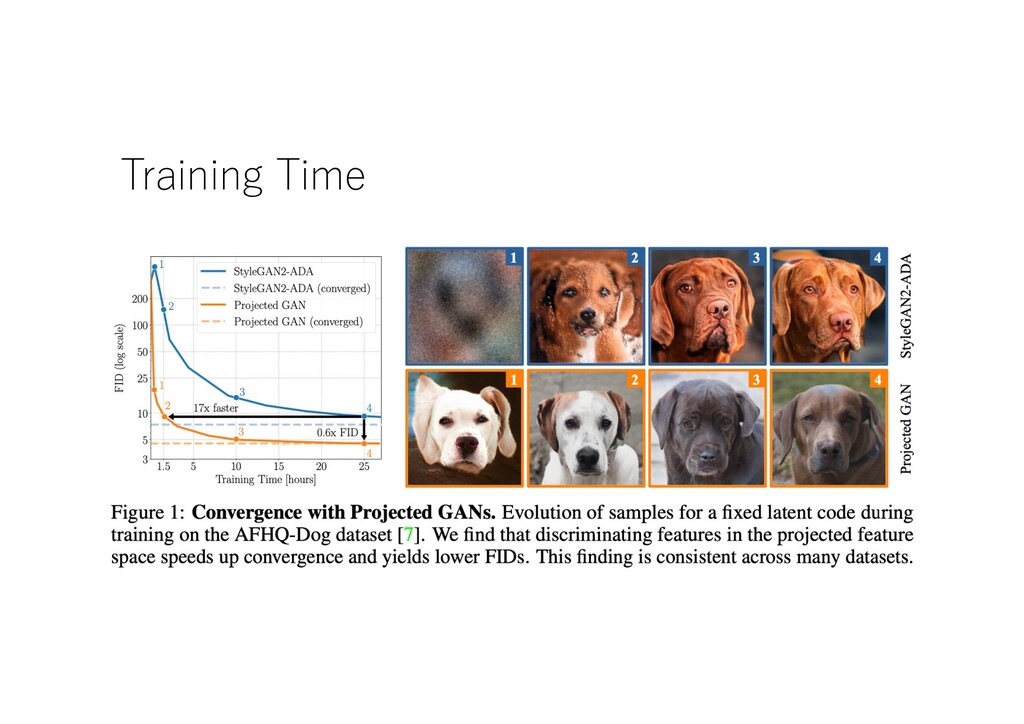
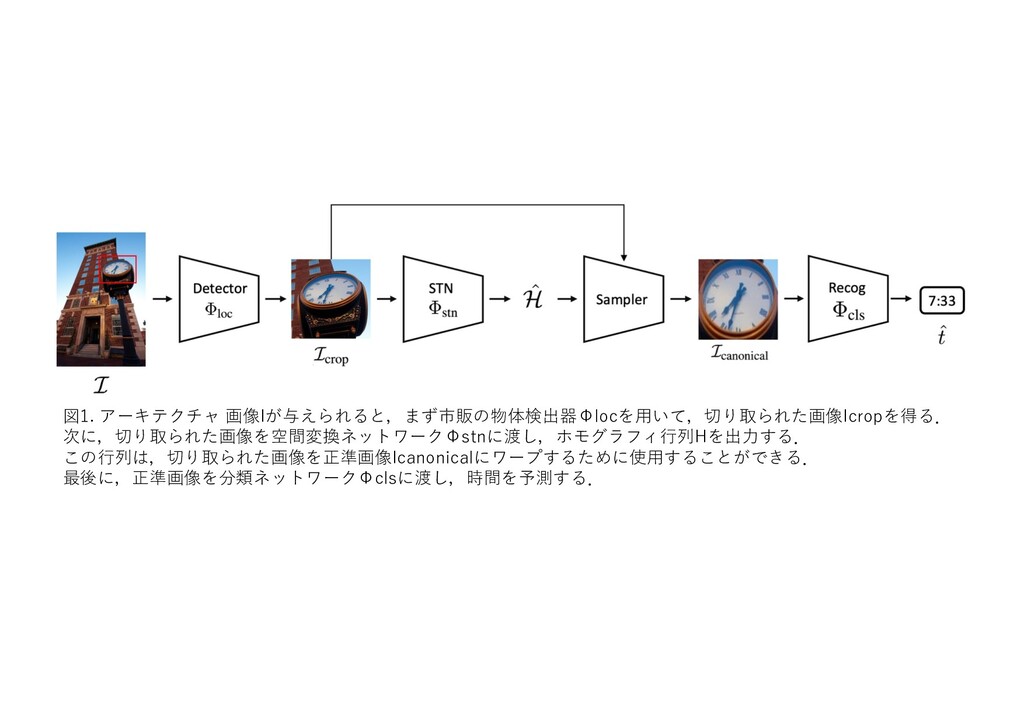
2. Implicit MLE: Backpropagating through Discrete Exponential Family Distributions (原⽂: Implicit MLE: Backpropagating Through Discrete Exponential Family Distributions) 3. Laplace Redux -- エフォートレス・ベイジアン・ディープ・ラーニング (原⽂: Laplace Redux -- Effortless Bayesian Deep Learning) 4. グラデーションだけではない (原⽂: Gradients are Not All You Need) top recent #.5 5. パレットイメージからイメージへの拡散モデル (原⽂: Palette: Image-to-Image Diffusion Models) top recent #.9 6. Audacityのための深層学習ツール.研究者がアーティストのツールキットを拡張するのに役⽴つ (原⽂: Deep Learning Tools for Audacity: Helping Researchers Expand the Artistʻs Toolkit) 11 ⽉ Top Hypo #.8 7. そろそろ時間だ:野⽣でのアナログ時計の読み⽅ (原⽂: It's About Time: Analog Clock Reading in the Wild) 8. StyleAlign:アライメントされたStyleGANモデルの分析と応⽤ (原⽂: StyleAlign: Analysis and Applications of Aligned StyleGAN Models) 11 ⽉ Top Hypo #.7 9. マスクド・オートエンコーダーはスケーラブルな視覚学習器である (原⽂: Masked Autoencoders Are Scalable Vision Learners) top recent #.1 10. 深層強化学習における⼀般化の調査 (原⽂: A Survey of Generalisation in Deep Reinforcement Learning) • Transformer • GAN • Survey • Math
画像と⾔語は性質の異なる信号であり,この違いには注意が必要. • 画像は光を記録したものであり,⾔葉のように意味的に分解されていな い. • オブジェクトを取り除くのではなく,意味的なセグメントを 形成していない可能性の⾼いランダムなパッチを再移動させます. • MAE はピクセルを再構成しますが,これは意味的な本質ではないが, MAE は複雑で全体的な再構成を⾏っていることから, MAE は数多くの視覚的概念を学習していると考えられる. • MAE の中に隠された豊かな表現があるために起こる現象だと考えられ る.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
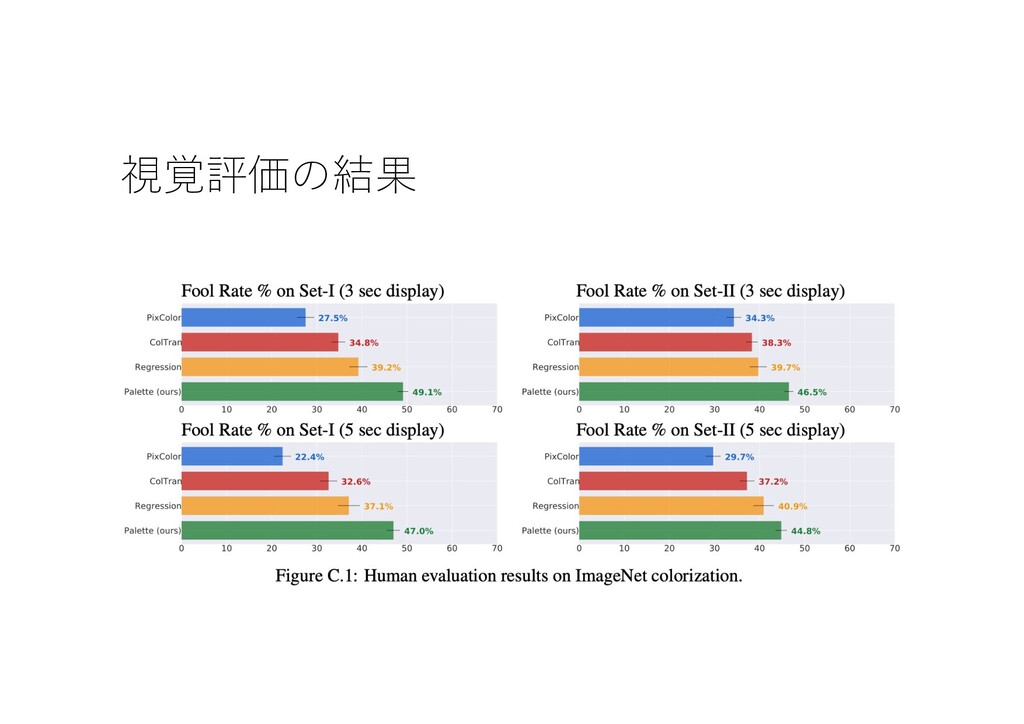{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
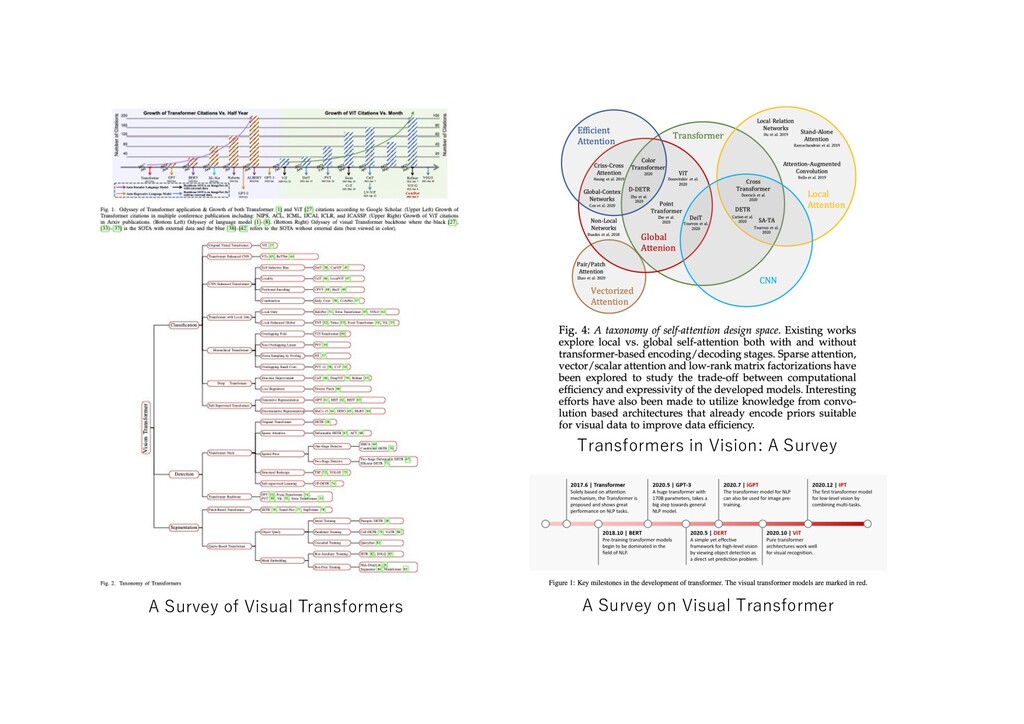{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
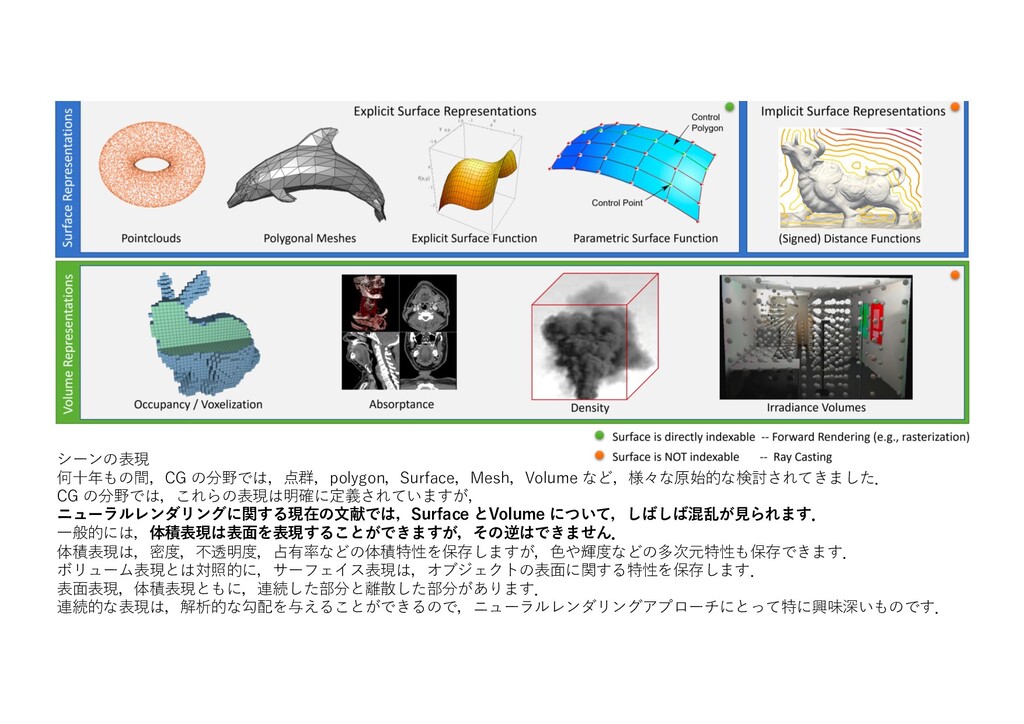{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
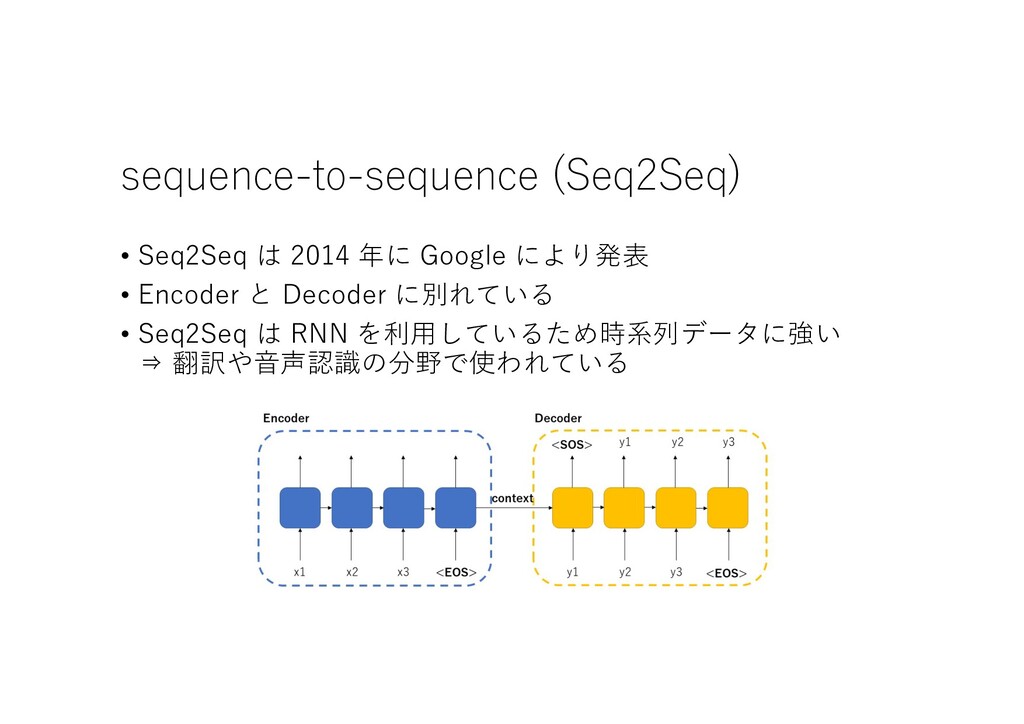{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}