論文紹介[ICLR2025 Poster]
PhiNets: Brain-inspired Non-contrastive Learning Based on Temporal Prediction Hypothesis
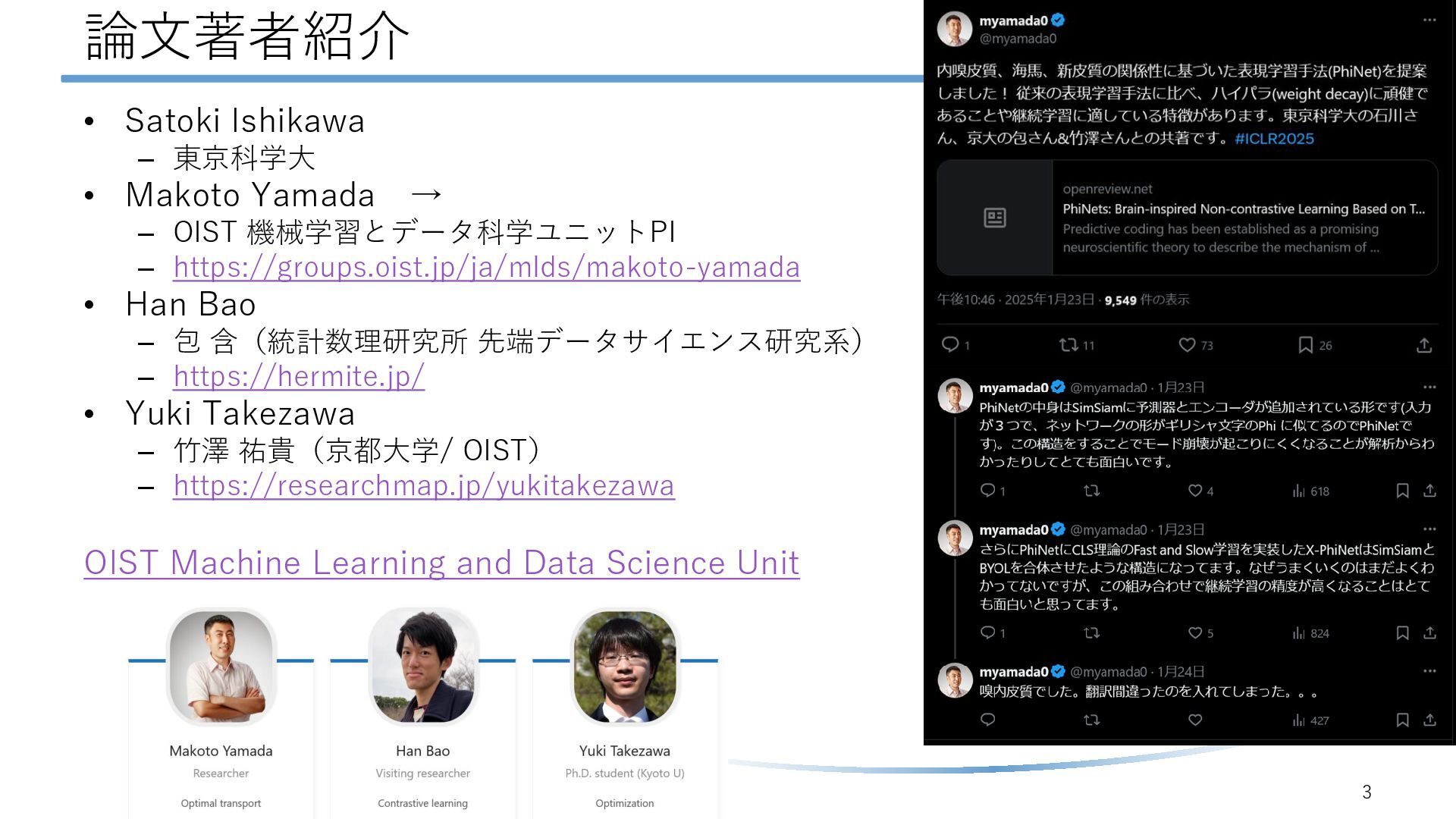
著者:Satoki Ishikawa, Makoto Yamada, Han Bao, Yuki Takezawa
https://arxiv.org/abs/2405.14650
https://openreview.net/forum?id=5tjdRyqnSn
第20回BIIセミナー(オンライン)2025/06/11
![紹介者: 立命館大学 情報理工学部 講師 谷口 彰 第20回BIIセミナー(オンライン)2025/06/11 論文紹介 [ICLR2025 Poster]](https://files.speakerdeck.com/presentations/b4227f7576eb47889c6421f5e170c1a7/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
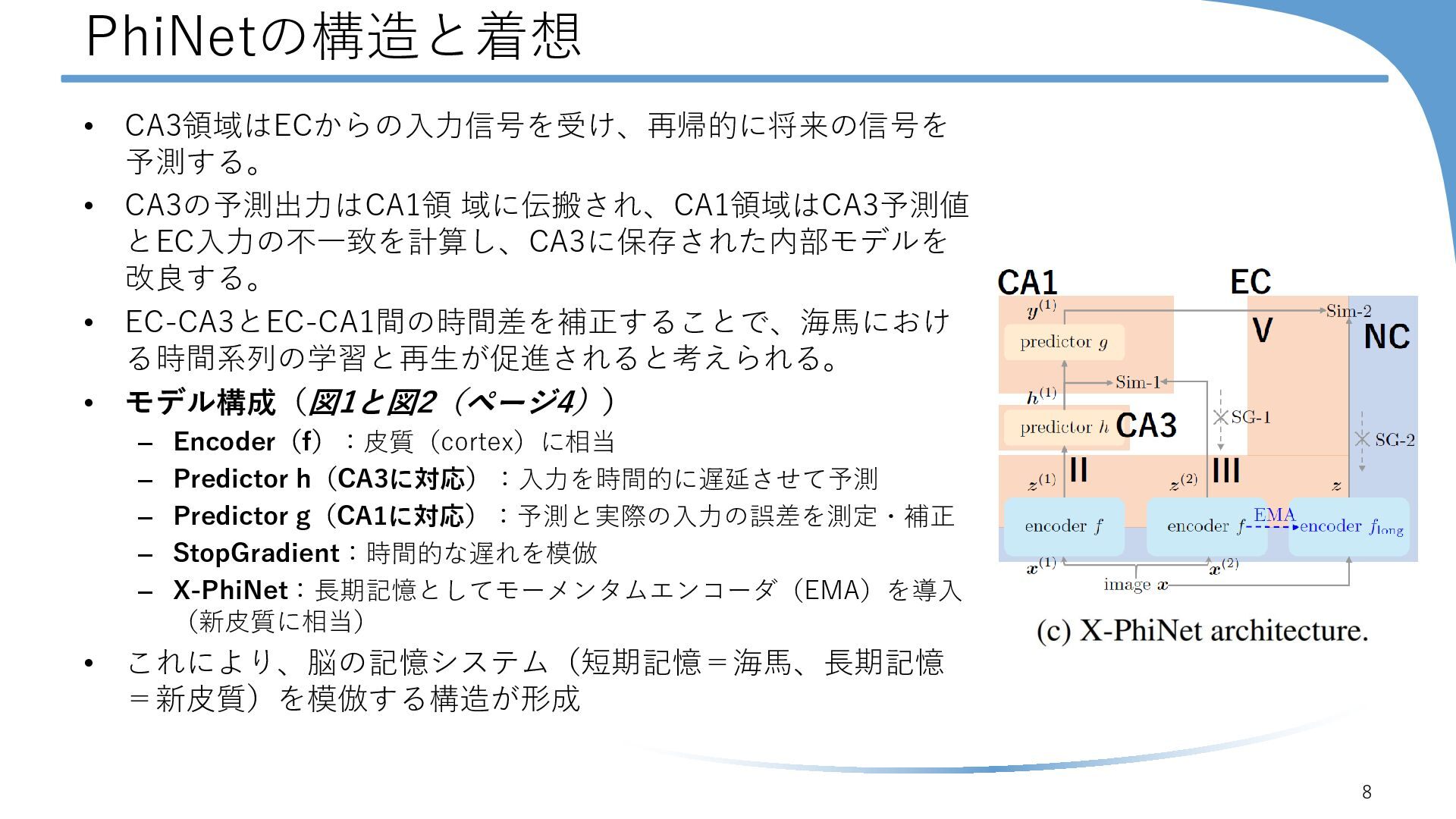{kind=link}
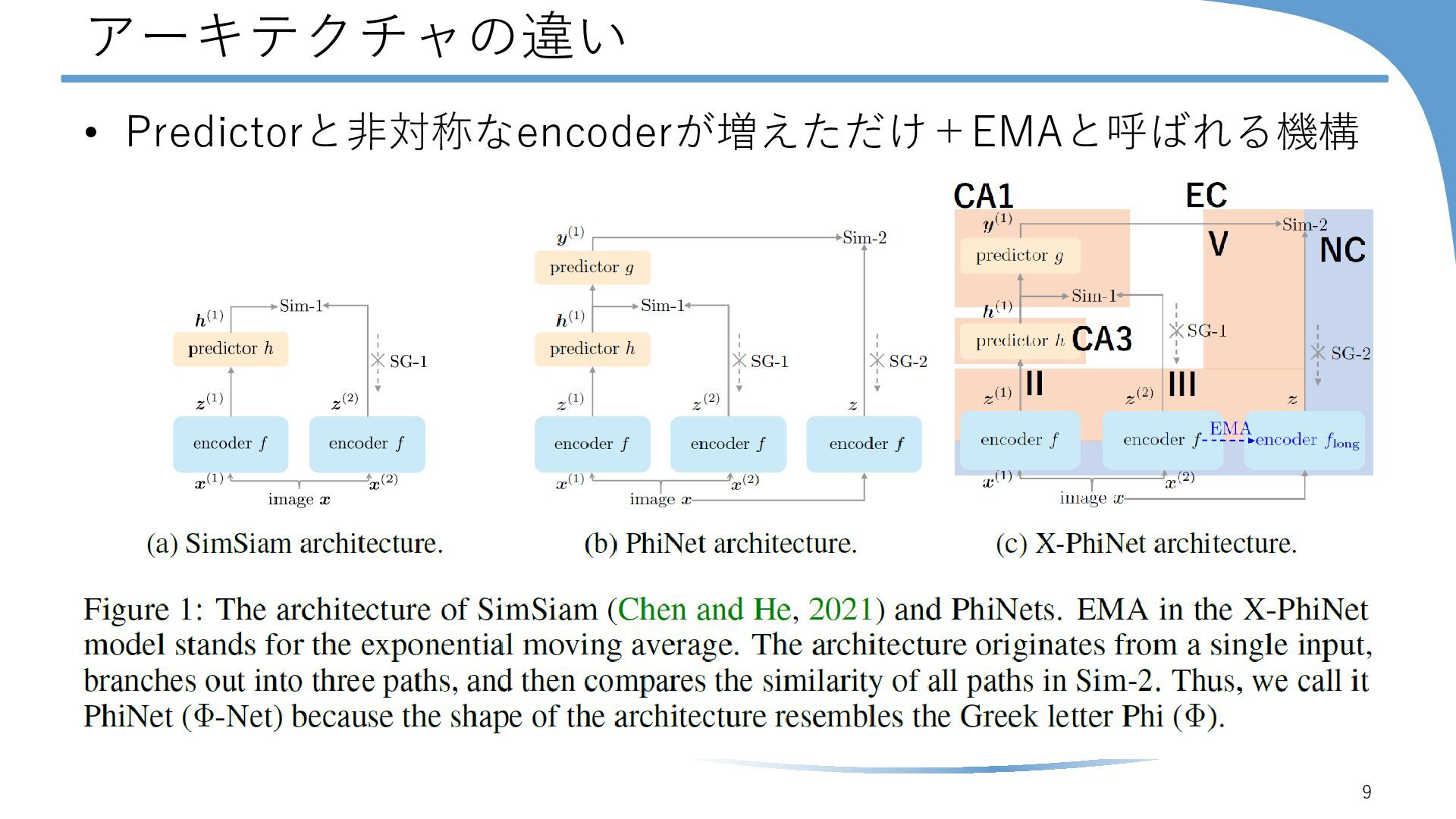{kind=link}
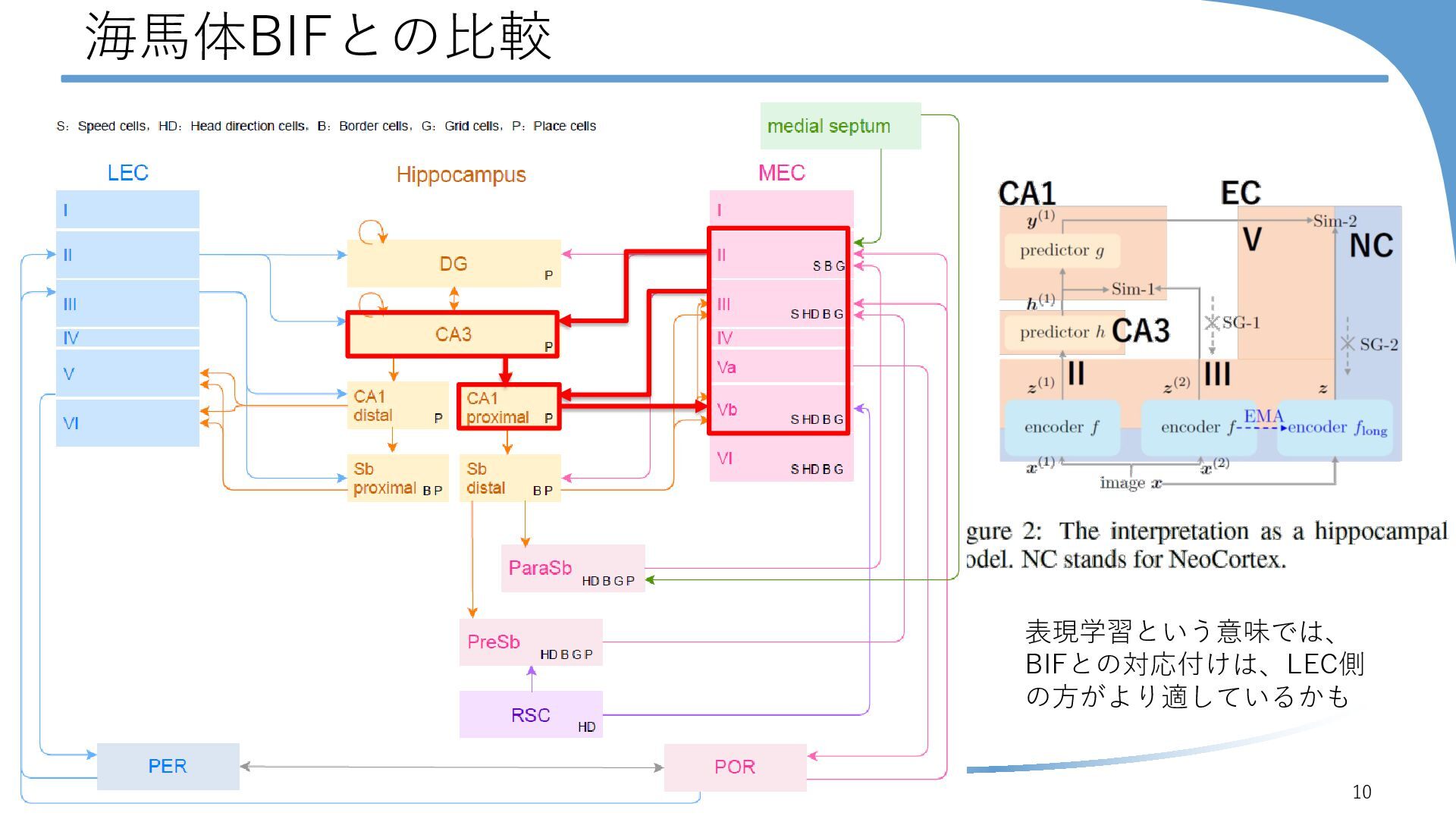{kind=link}
{kind=link}
{kind=link}
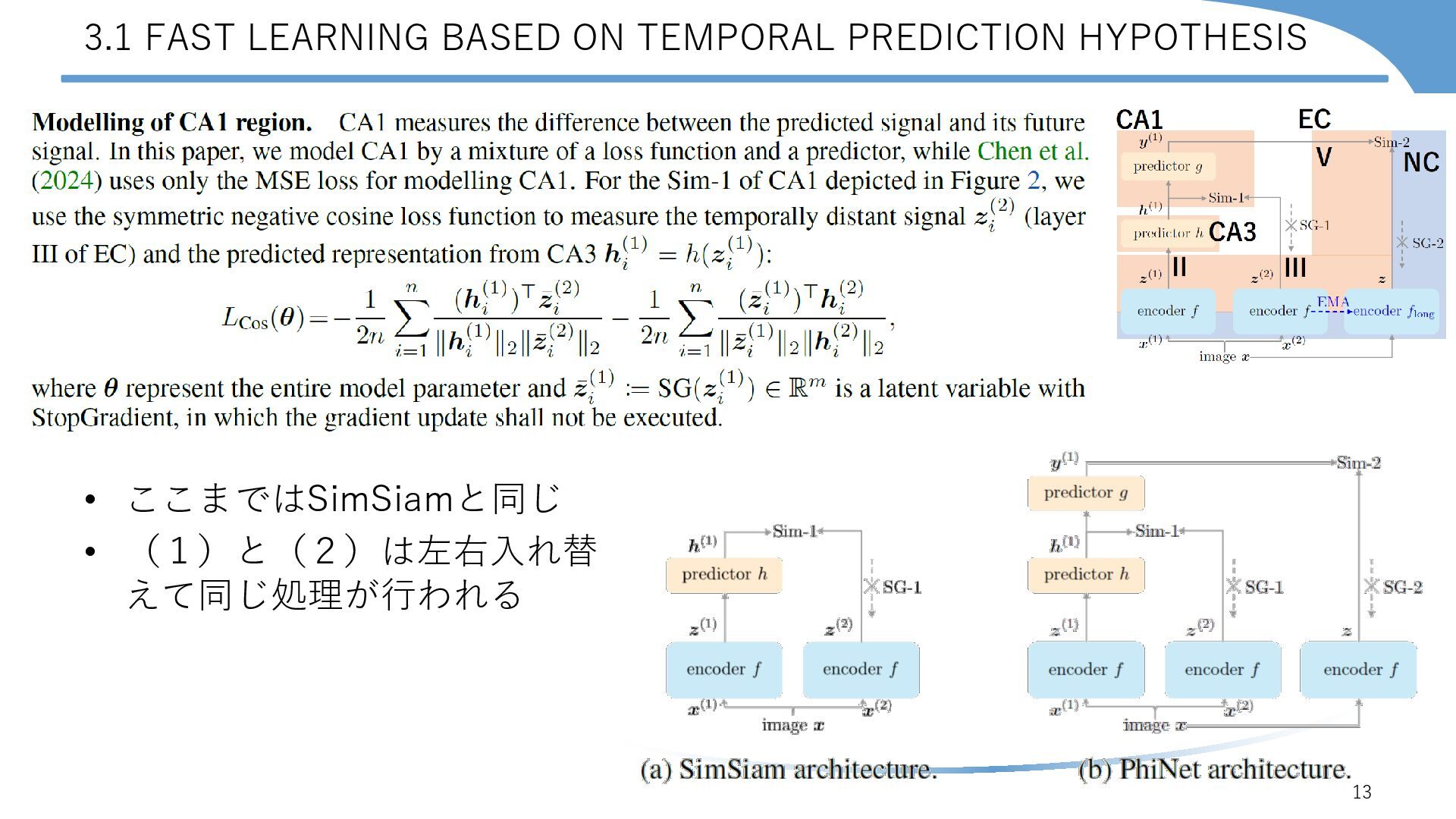{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
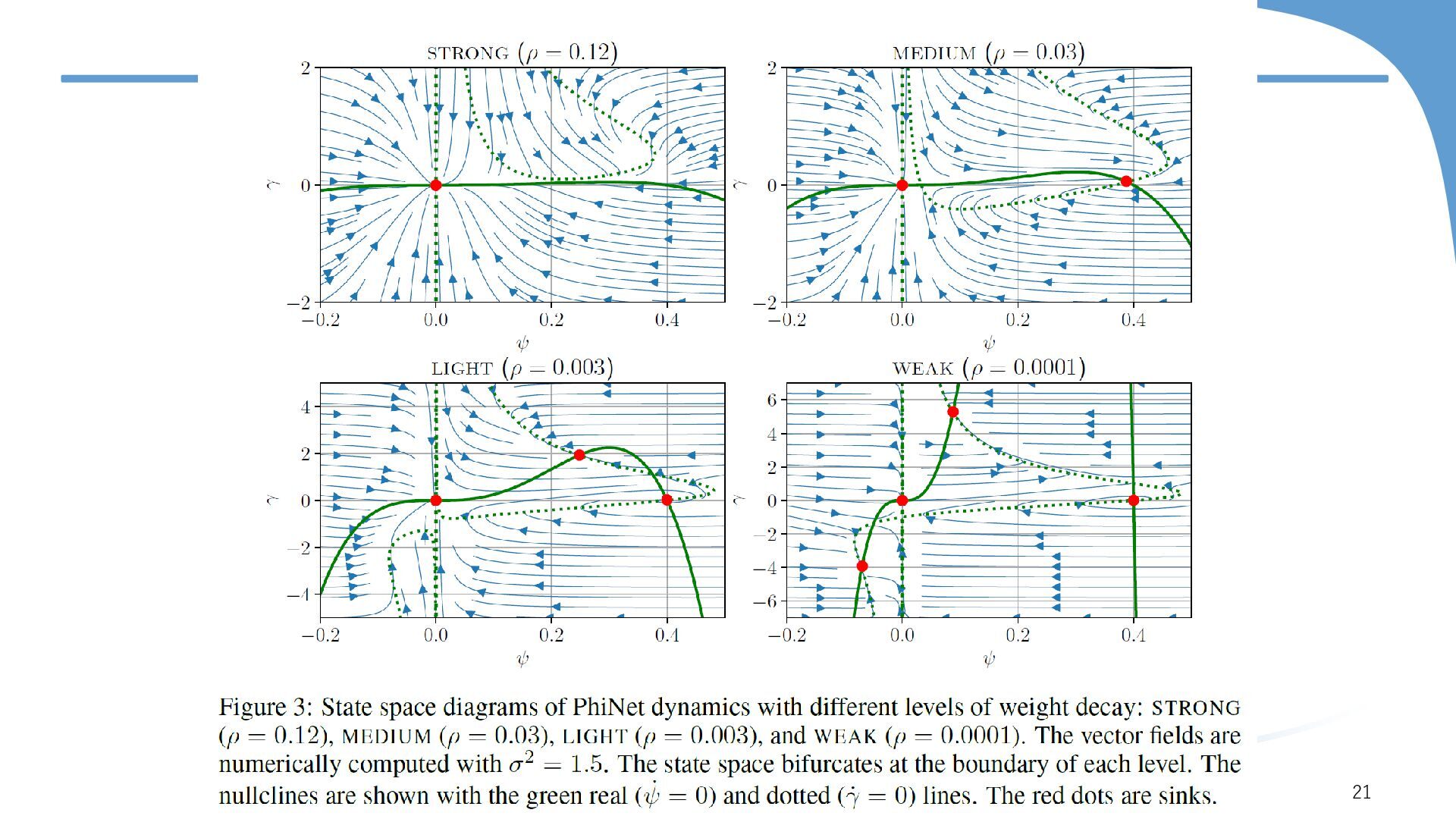{kind=link}
{kind=link}
{kind=link}
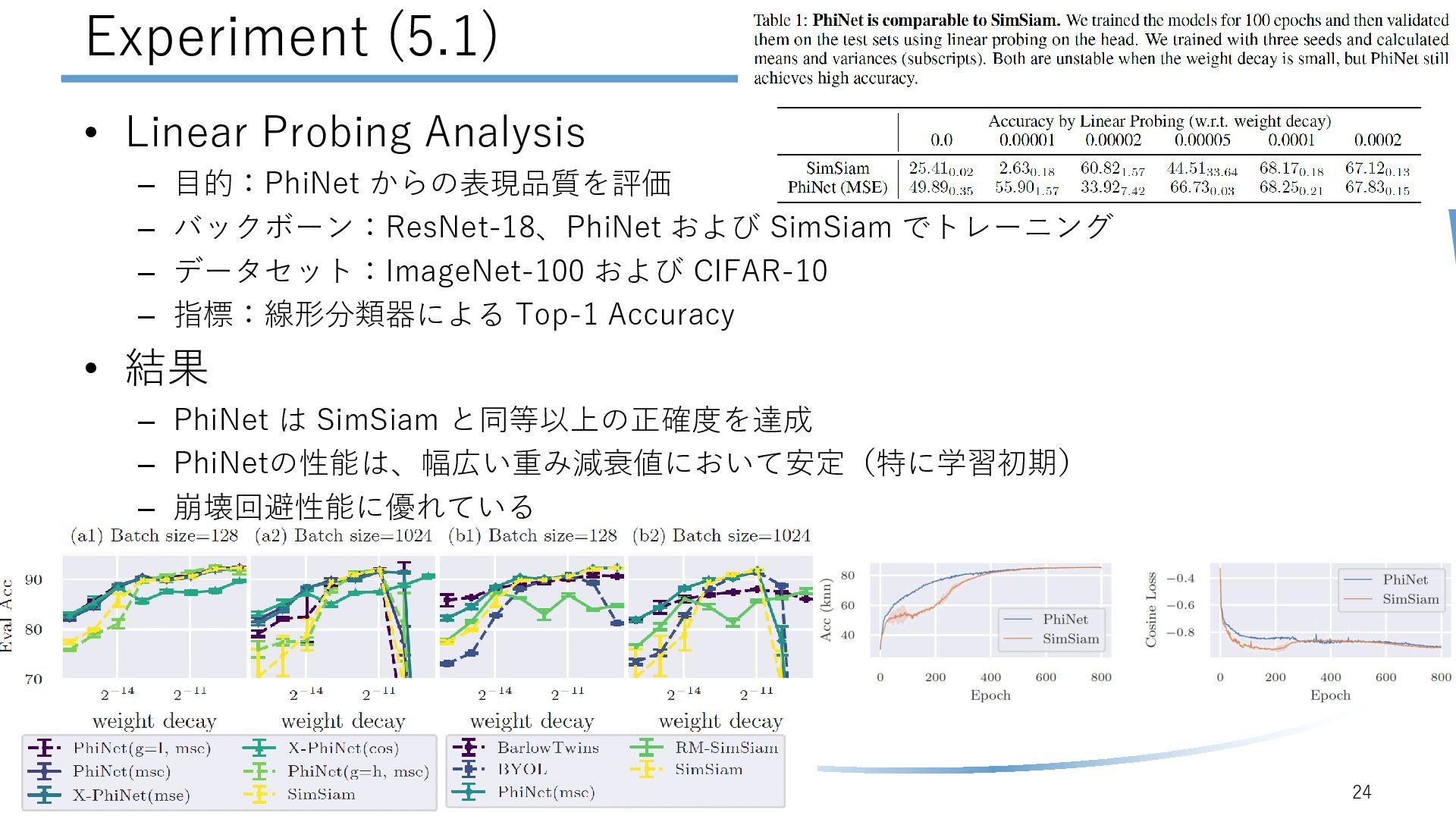{kind=link}
{kind=link}
{kind=link}
{kind=link}
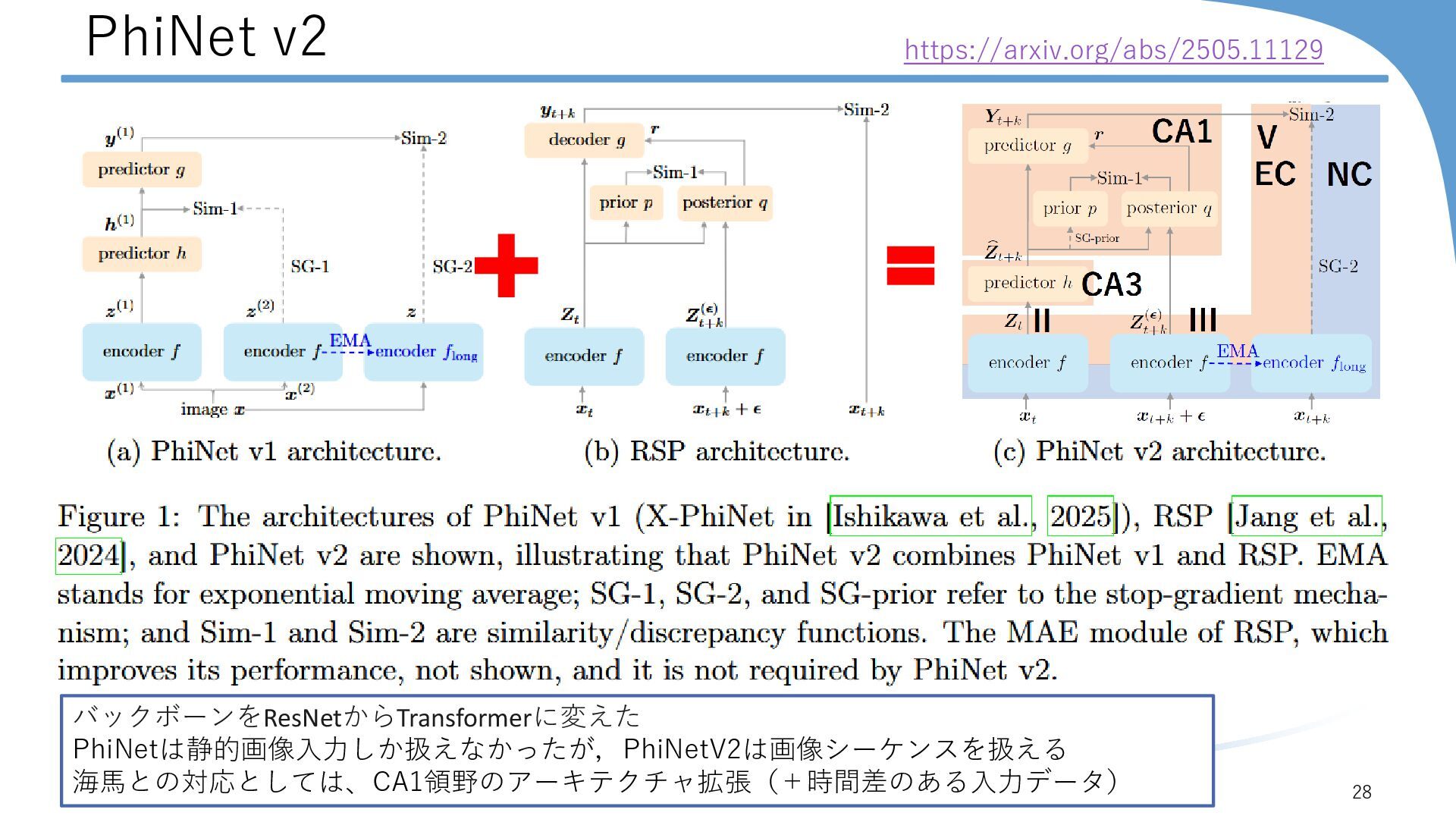{kind=link}
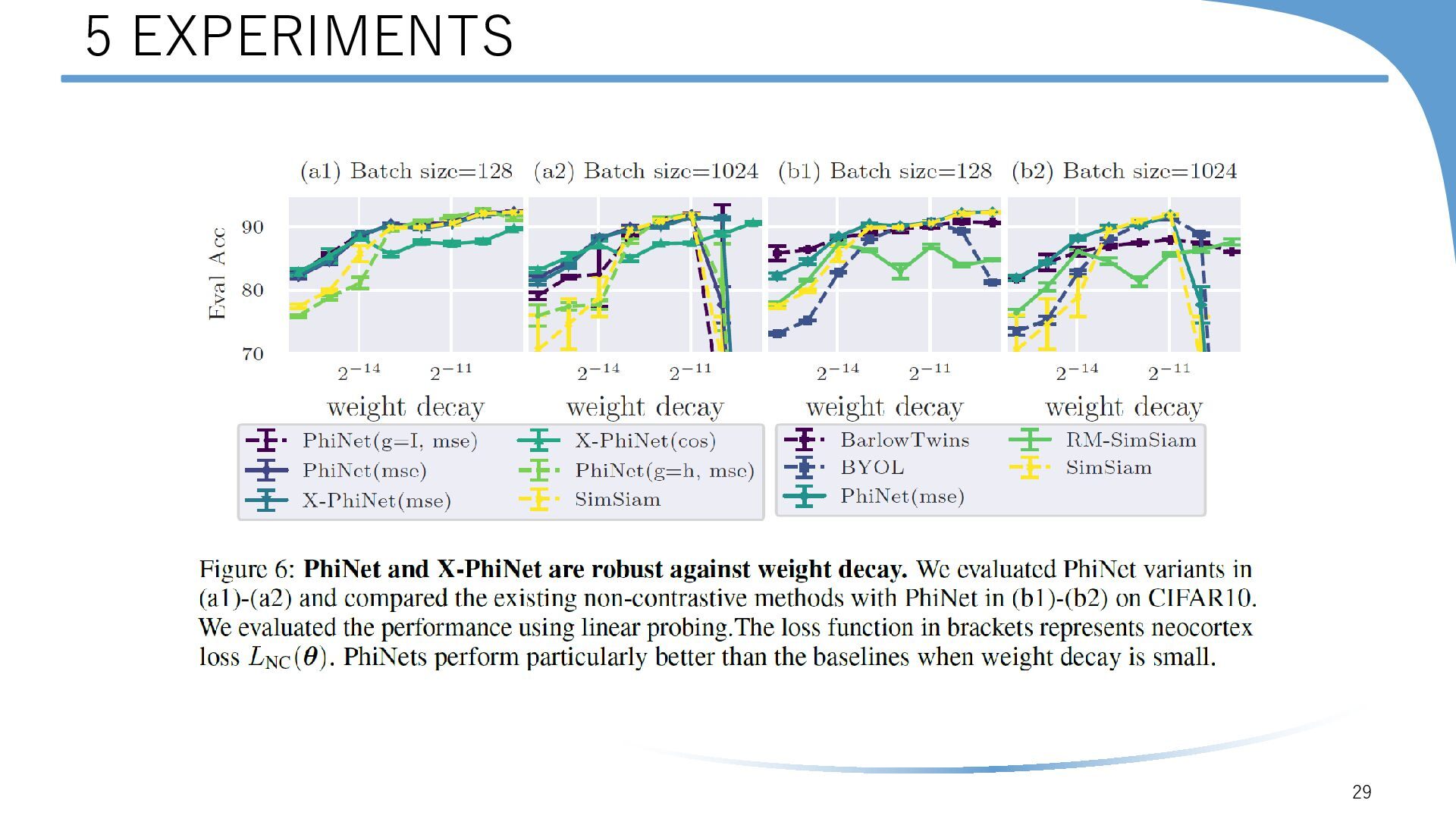{kind=link}
{kind=link}
{kind=link}
{kind=link}