…, 0, 1, 0, … , 0, 1 , 0, …, 0, 1, 0, …., 0 ] ants get you aardvak zyxst ['this', 'is', 'how', 'you', 'get', 'ants'] HashingVectorizer tokenizer Sparse matrix encoding hashing [hash('this'), hash('is'), hash('how'), hash('you'), hash('get'), hash('ants')] = [832412, 223788, 366226, 81185, 835749, 173092]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![29 Basic API estimator.fit(X, [y]) estimator.predict estimator.transform Classification Preprocessing Regression](https://files.speakerdeck.com/presentations/5b866b5a9d354b939d1f6010ed0354da/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
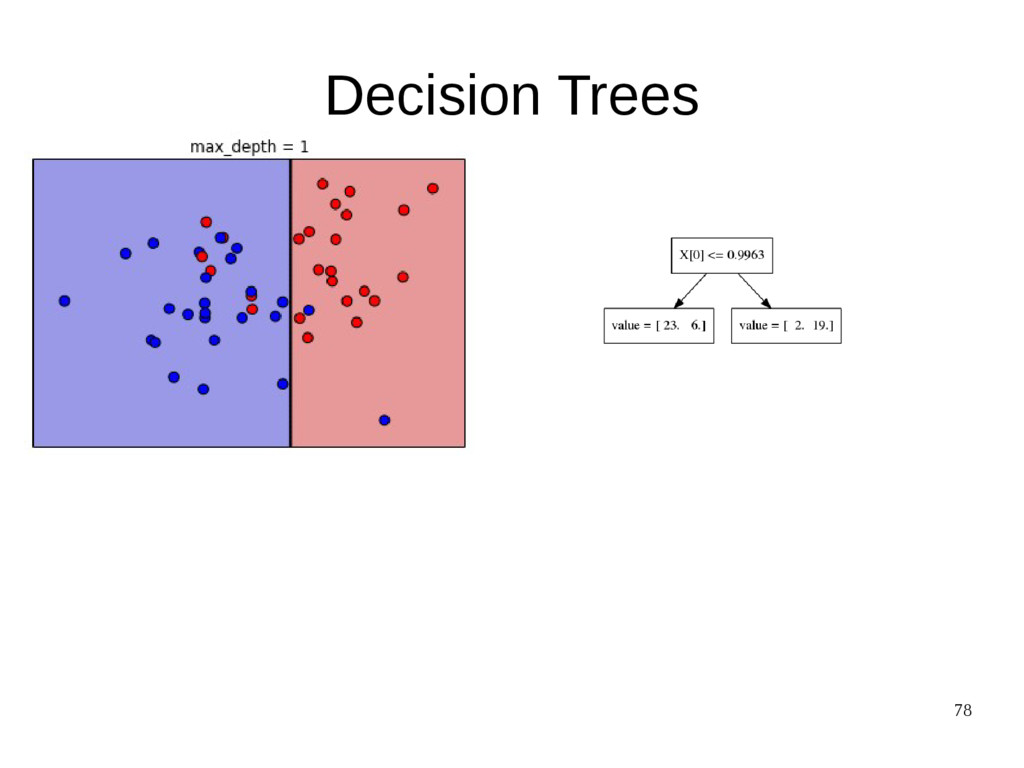{kind=link}
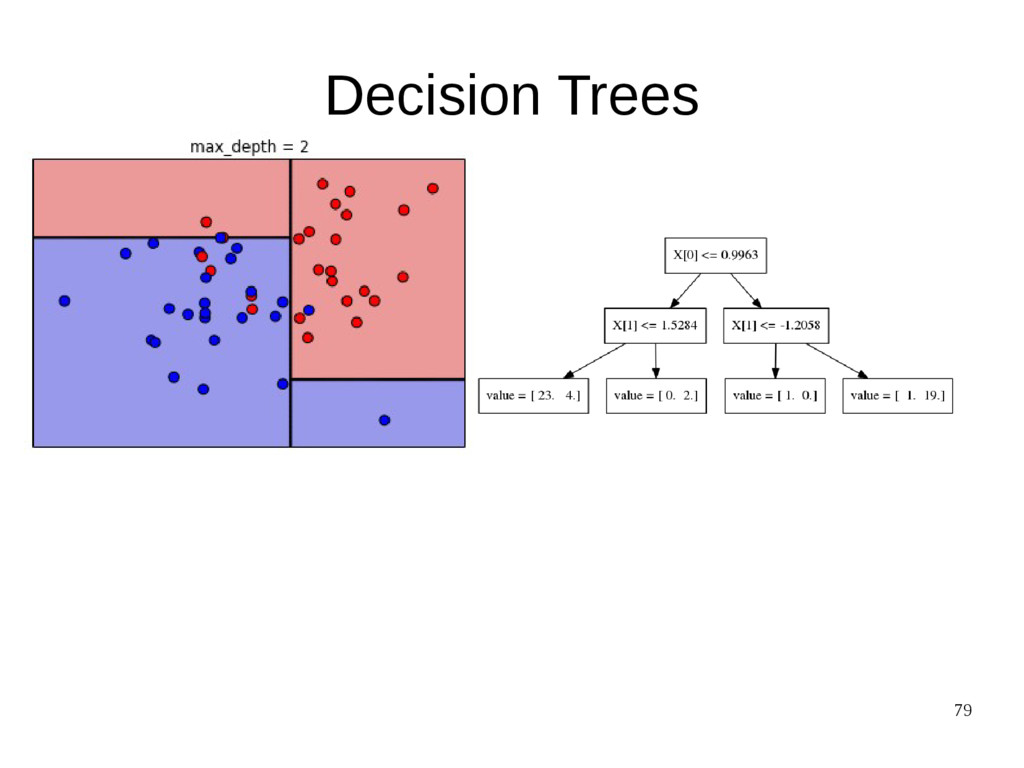{kind=link}
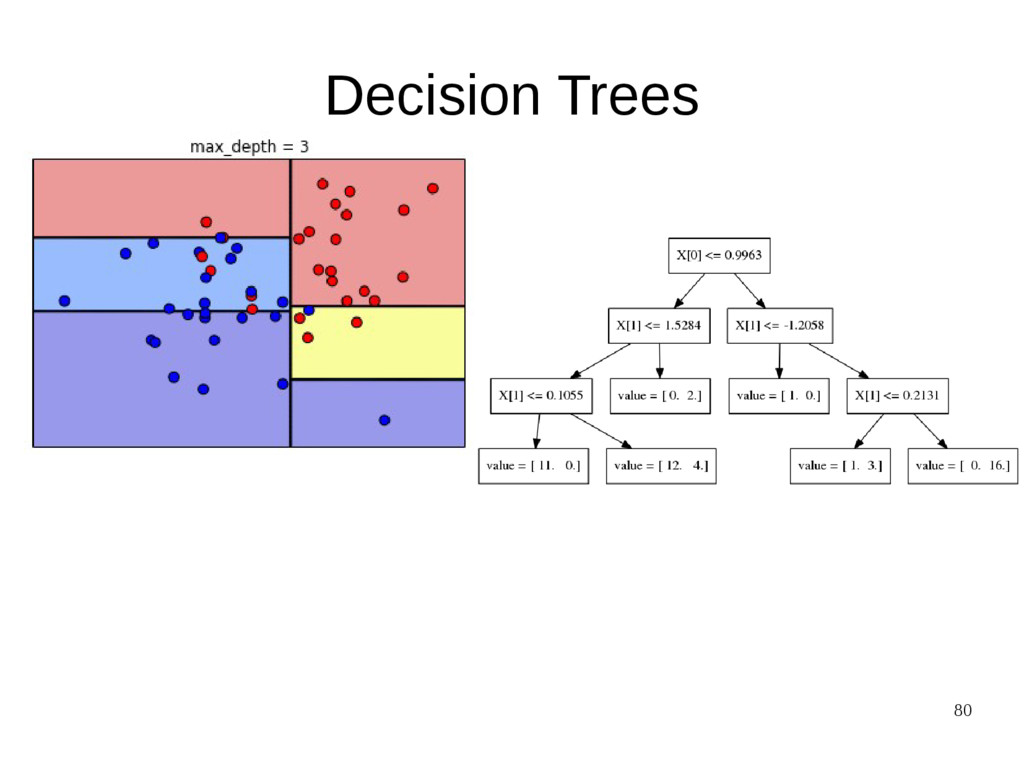{kind=link}
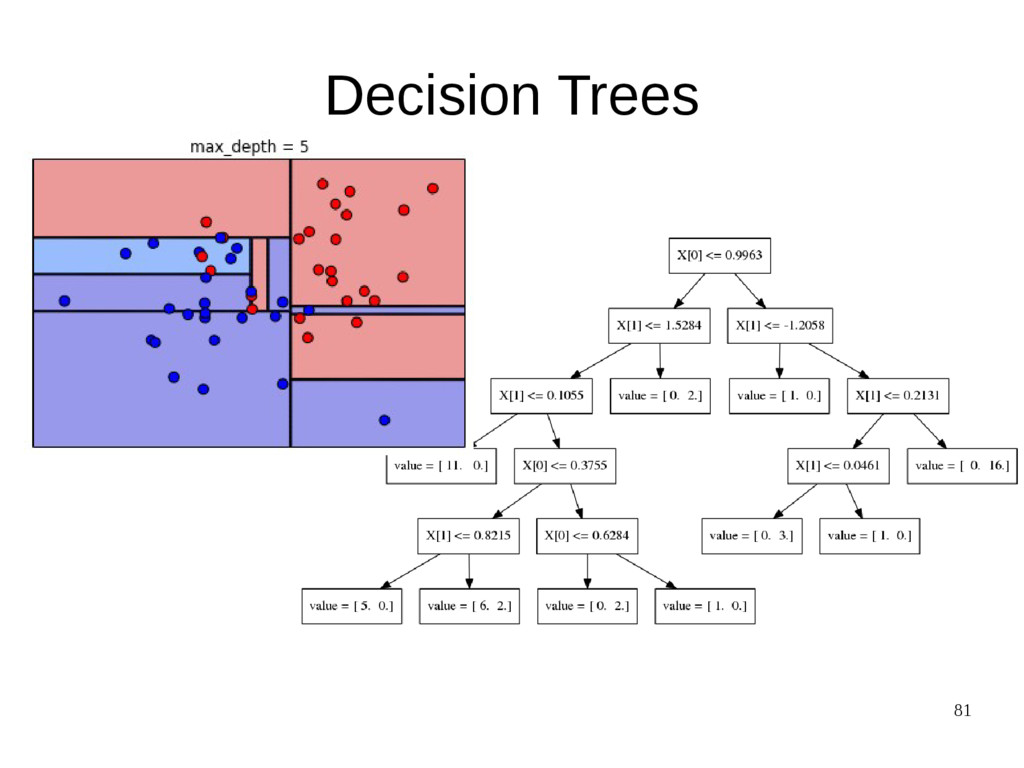{kind=link}
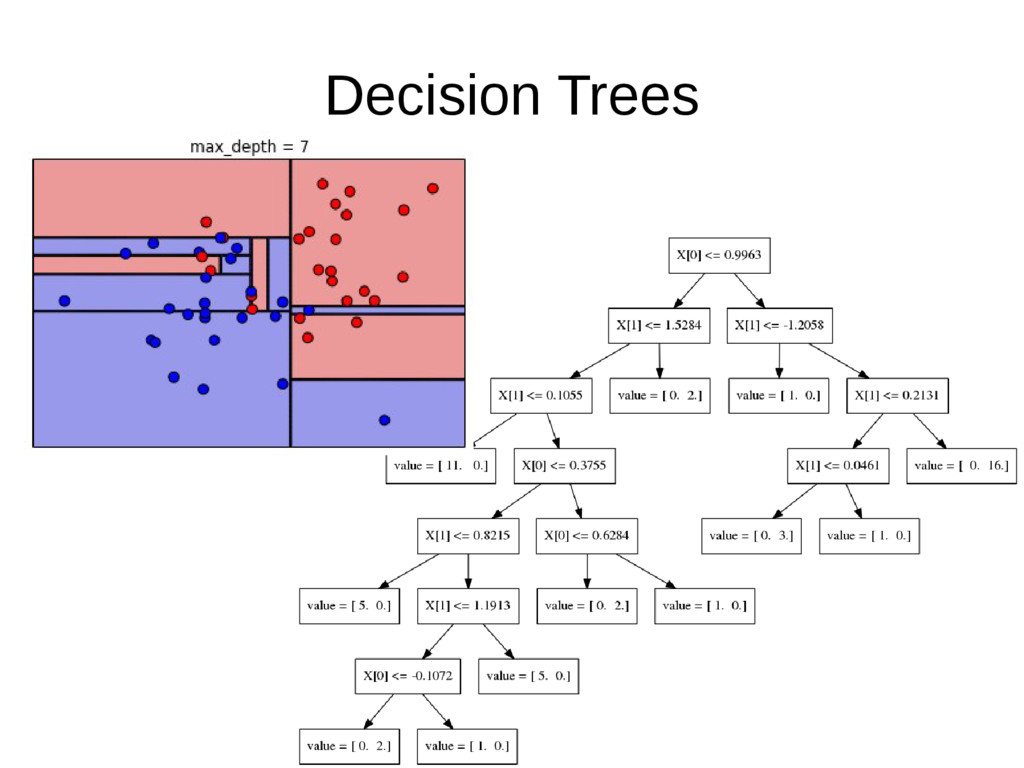{kind=link}
{kind=link}
{kind=link}
{kind=link}
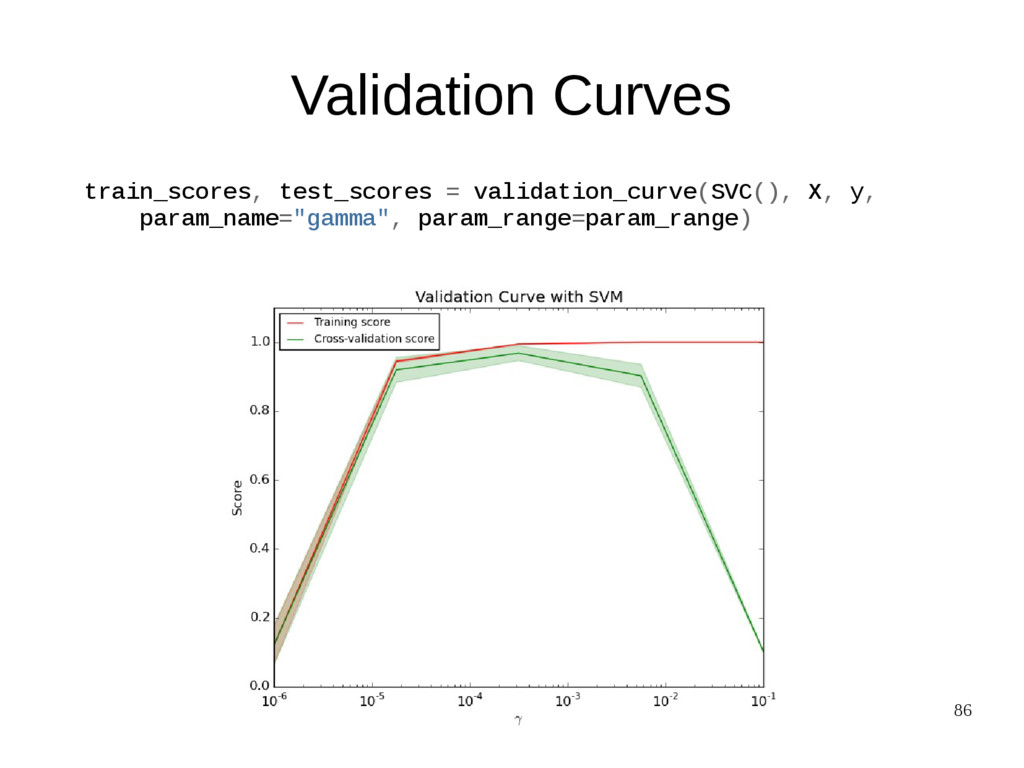{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
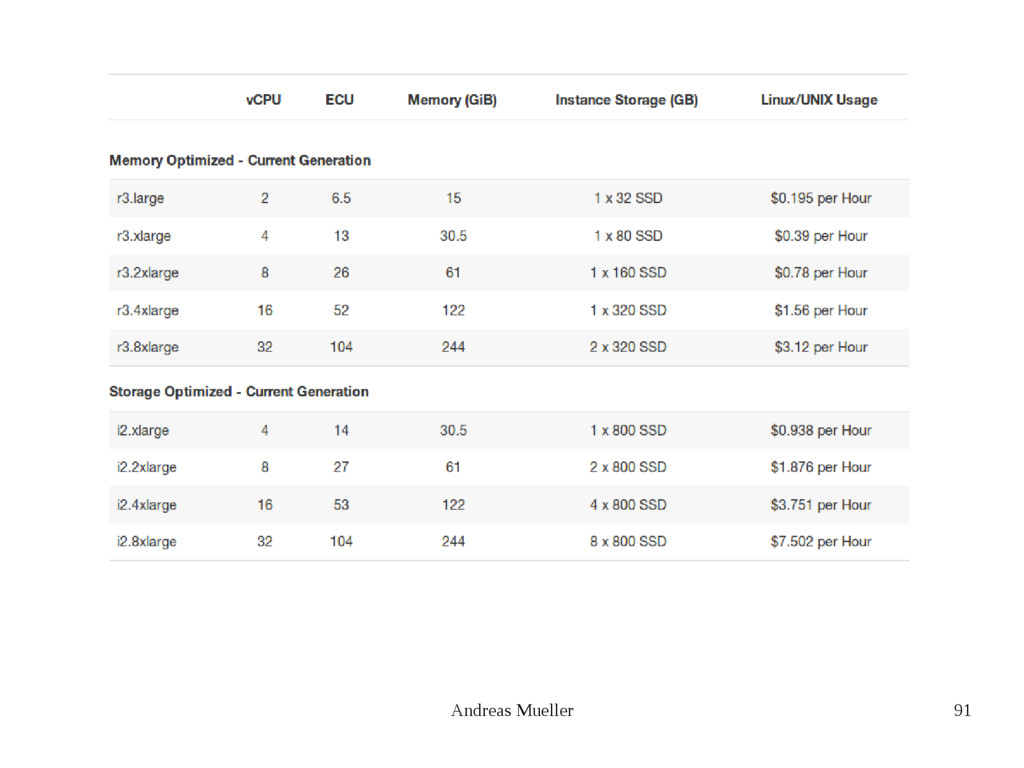{kind=link}
{kind=link}
{kind=link}
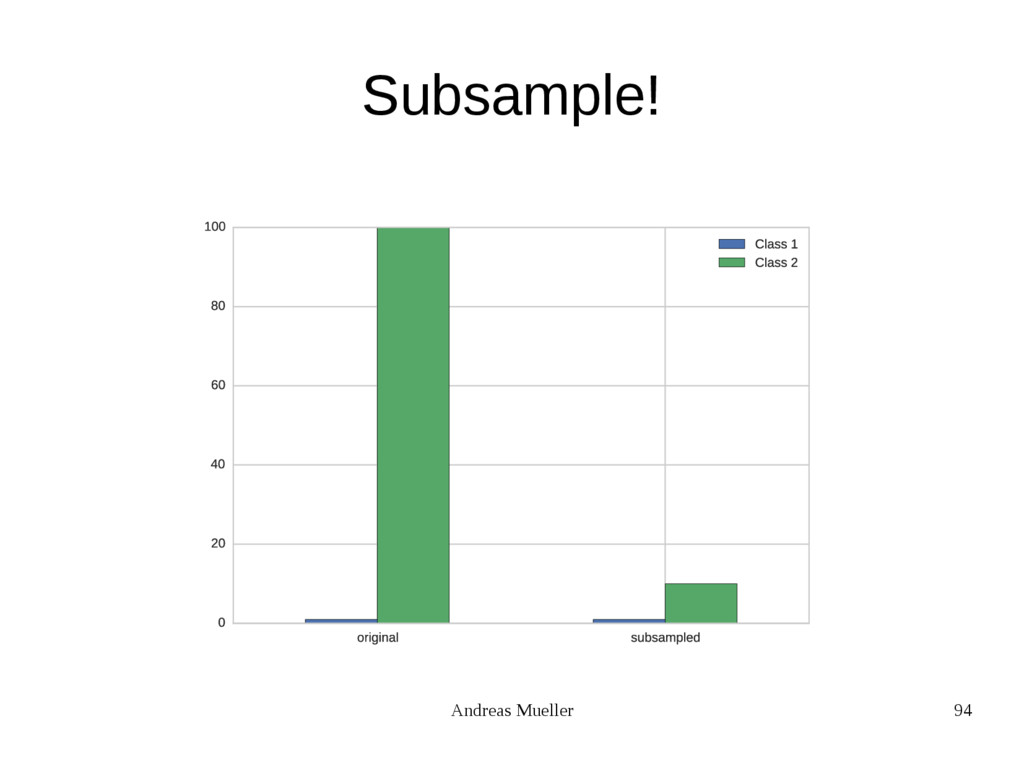{kind=link}
{kind=link}
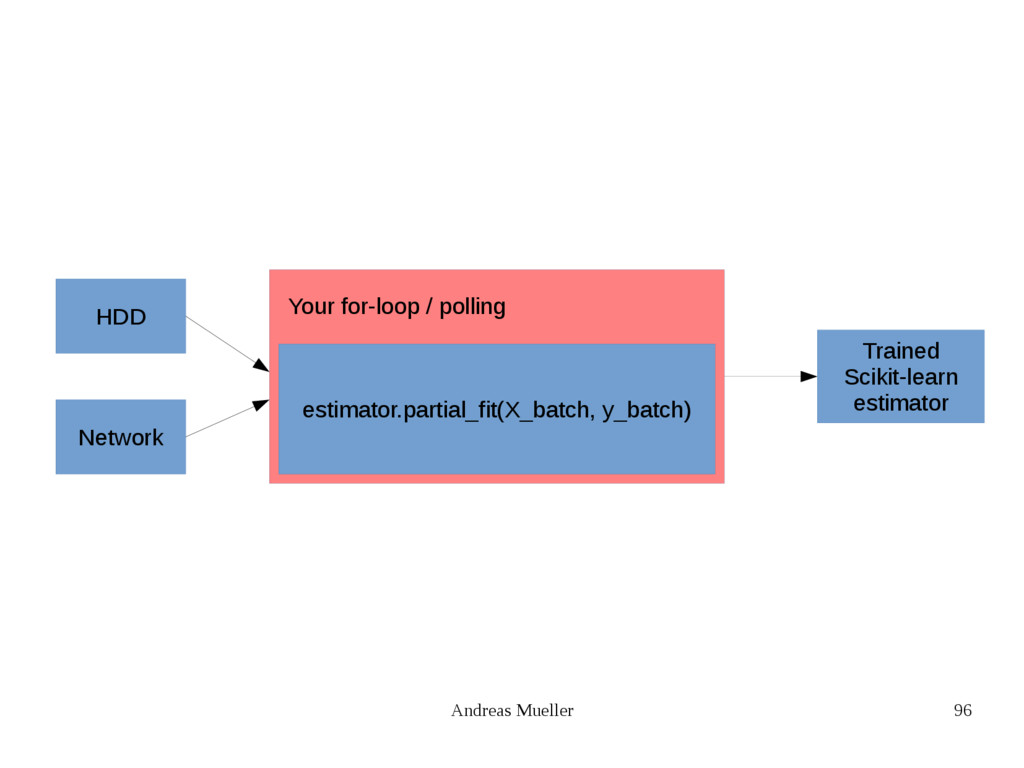{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![105 Thank you for your attention. @t3kcit @amueller [email protected] http://amueller.github.io](https://files.speakerdeck.com/presentations/5b866b5a9d354b939d1f6010ed0354da/slide_104.jpg){kind=link}