Algebra Subprograms (BLAS) -線型代数計算を実行するライブラリの標準仕様 Linear Algebra PACKage (LAPACK) -BLAS上に構築された固有値計算などの高位な線形代数計算ライブラリ 現在様々なBLAS実装が公開されている Intel MKL … MATLABはコレ 有償 すごく速い・高い・安心! ATLAS … 自動チューンのBLAS BSD 速い GotoBLAS2 … 後藤和茂氏作成のBLAS BSD かなり速い 開発停止 OpenBLAS … xianyi氏によるGotoBLAS2の後継BLAS BSD すごく速い (MATLAB, R, Octave, numpy …) 計算が遅い時、4つのどれかの導入すると幸せになれるかも? ・ ・ ・
{kind=link}
{kind=link}
{kind=link}
{kind=link}
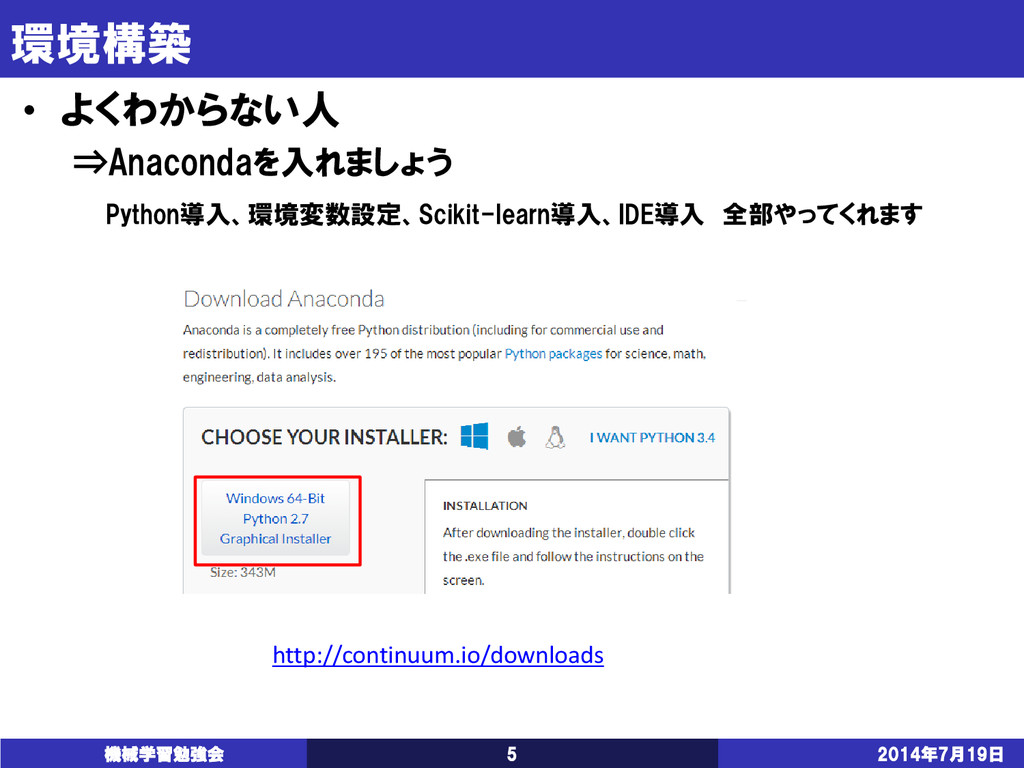{kind=link}
{kind=link}
{kind=link}
{kind=link}
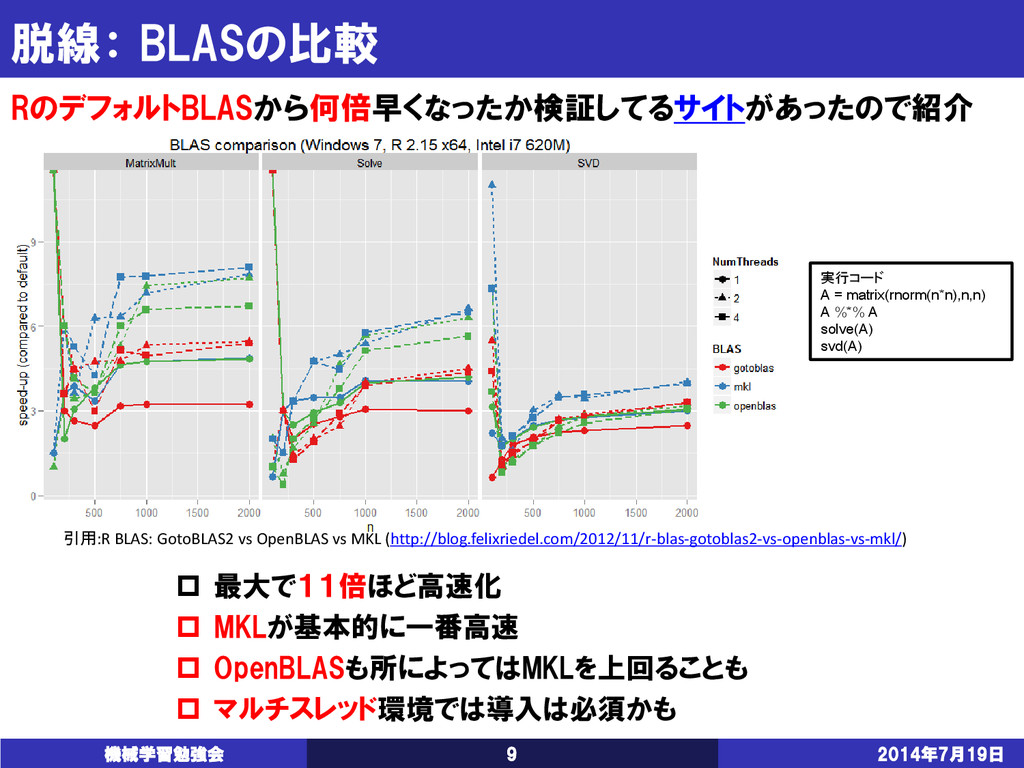{kind=link}
{kind=link}
{kind=link}
{kind=link}
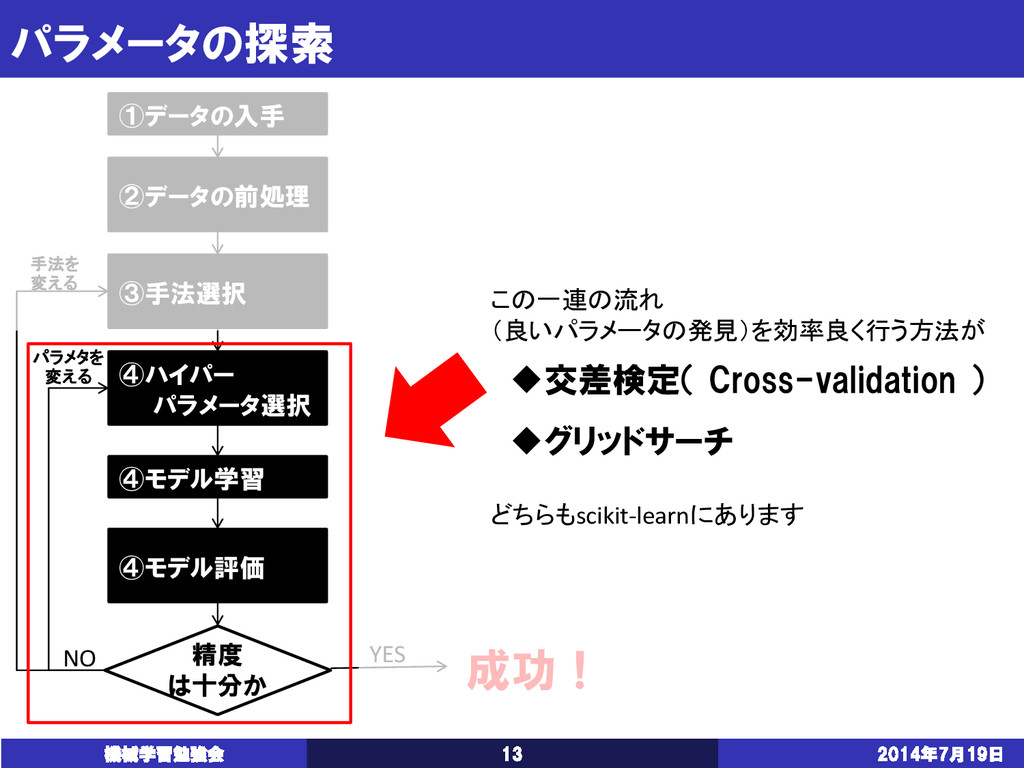{kind=link}
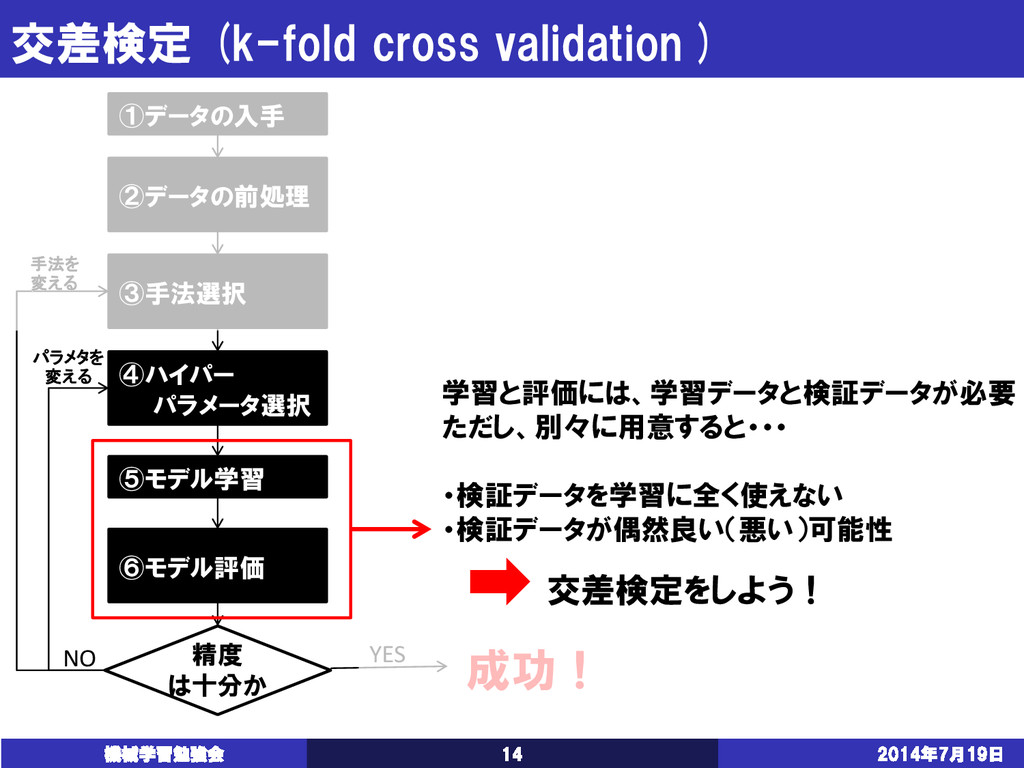{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
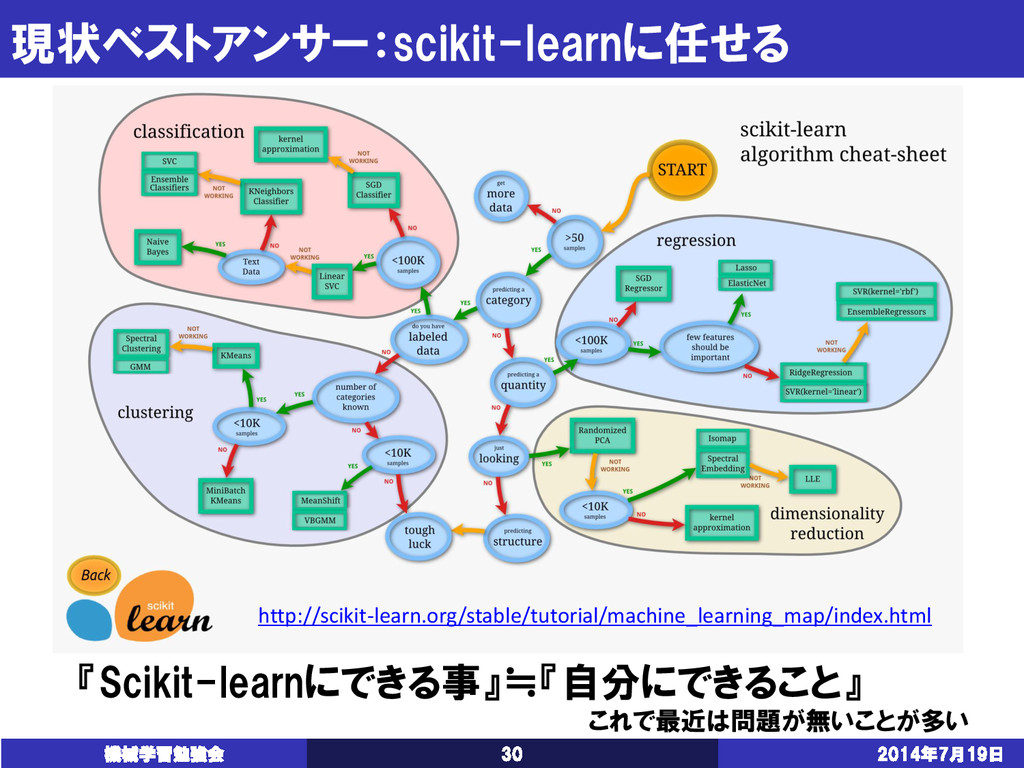{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}