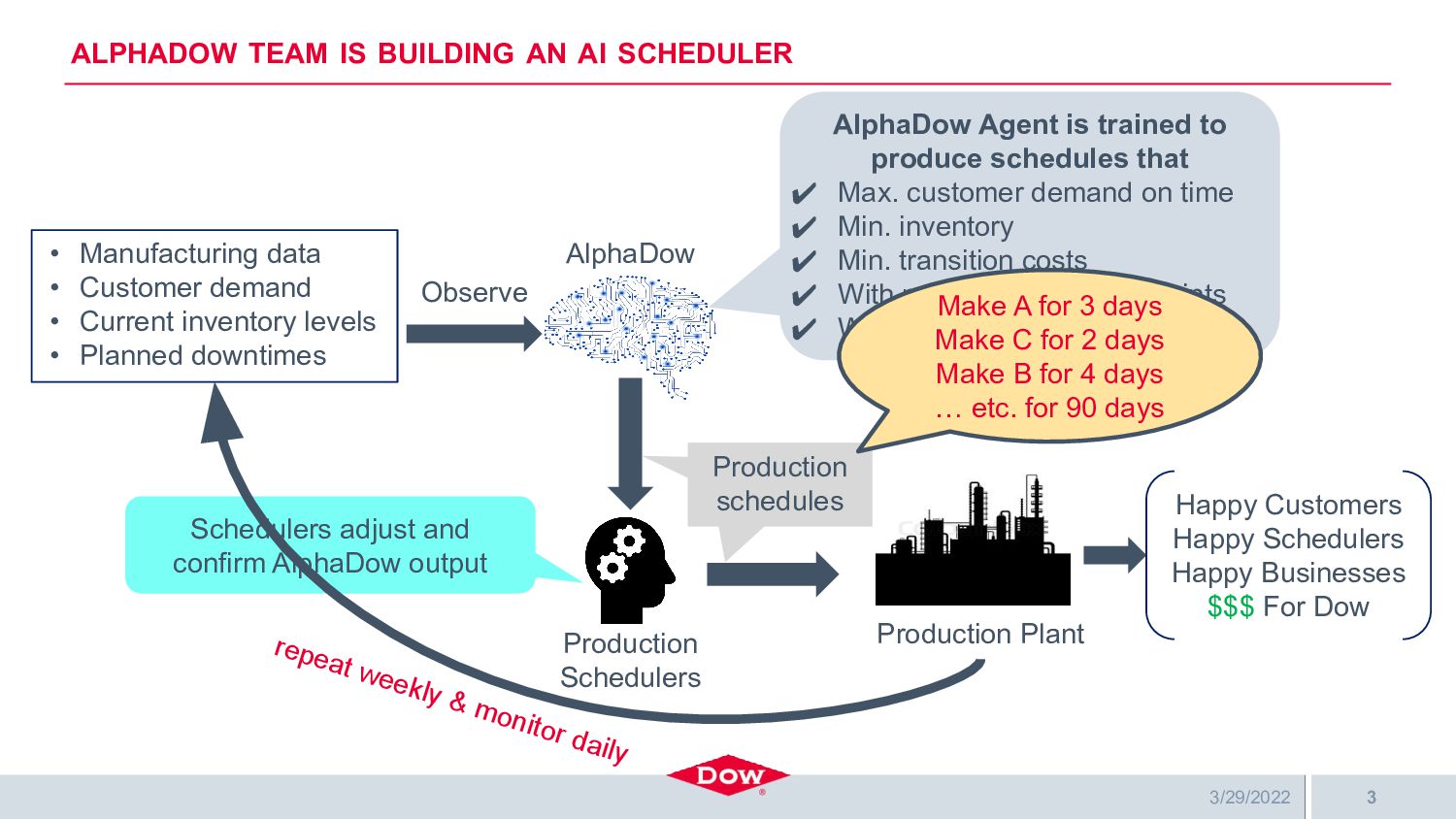
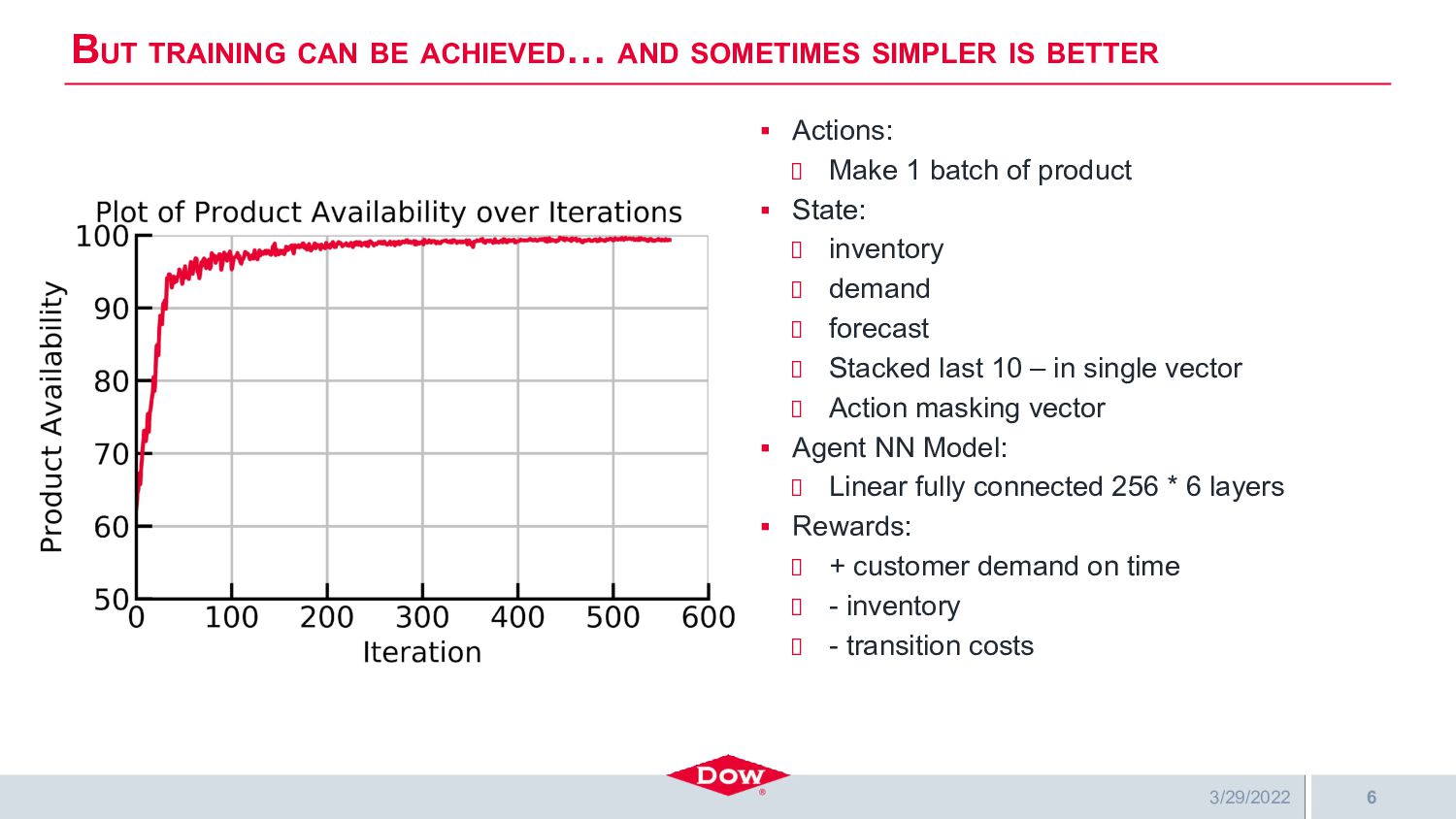
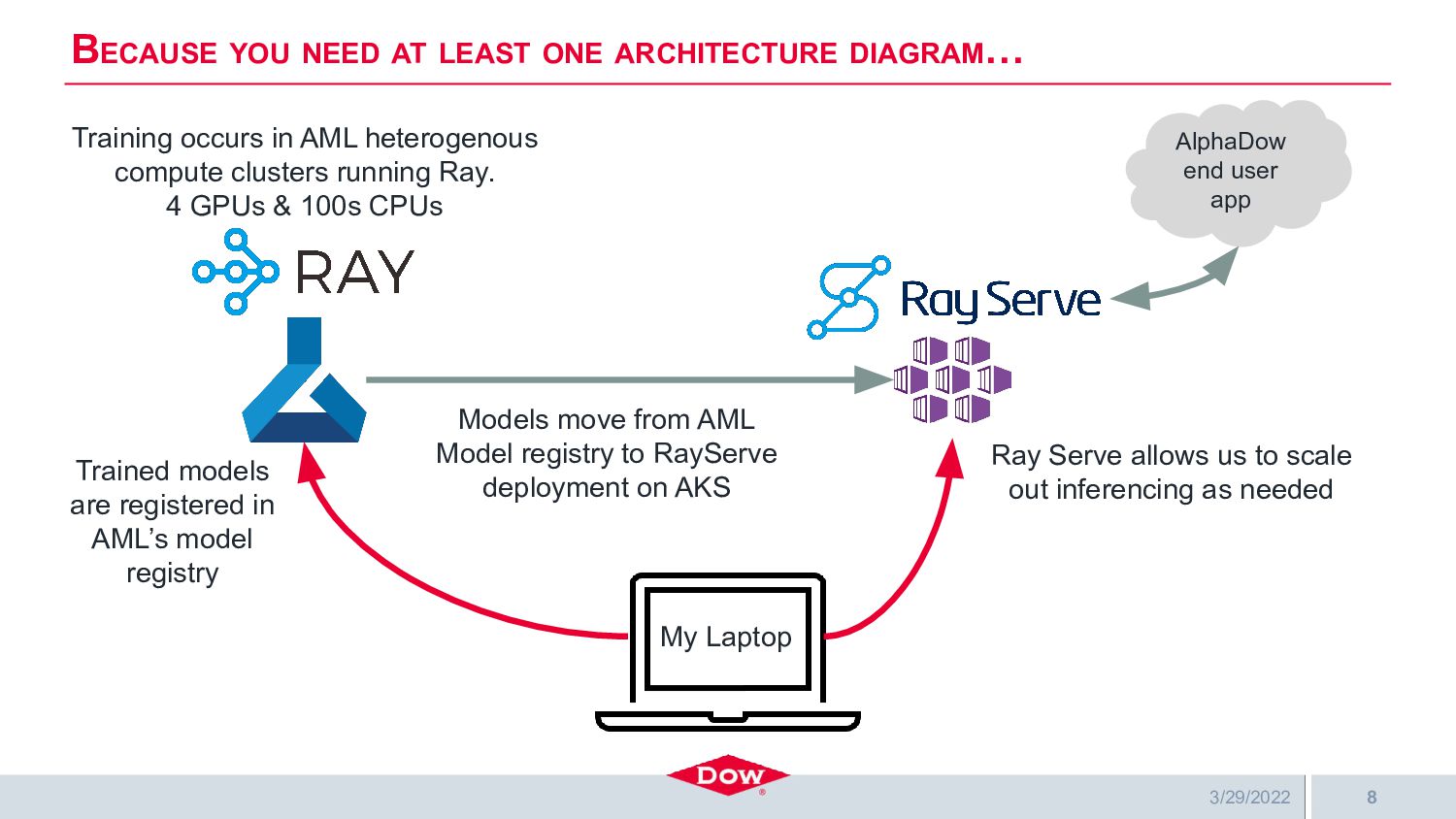
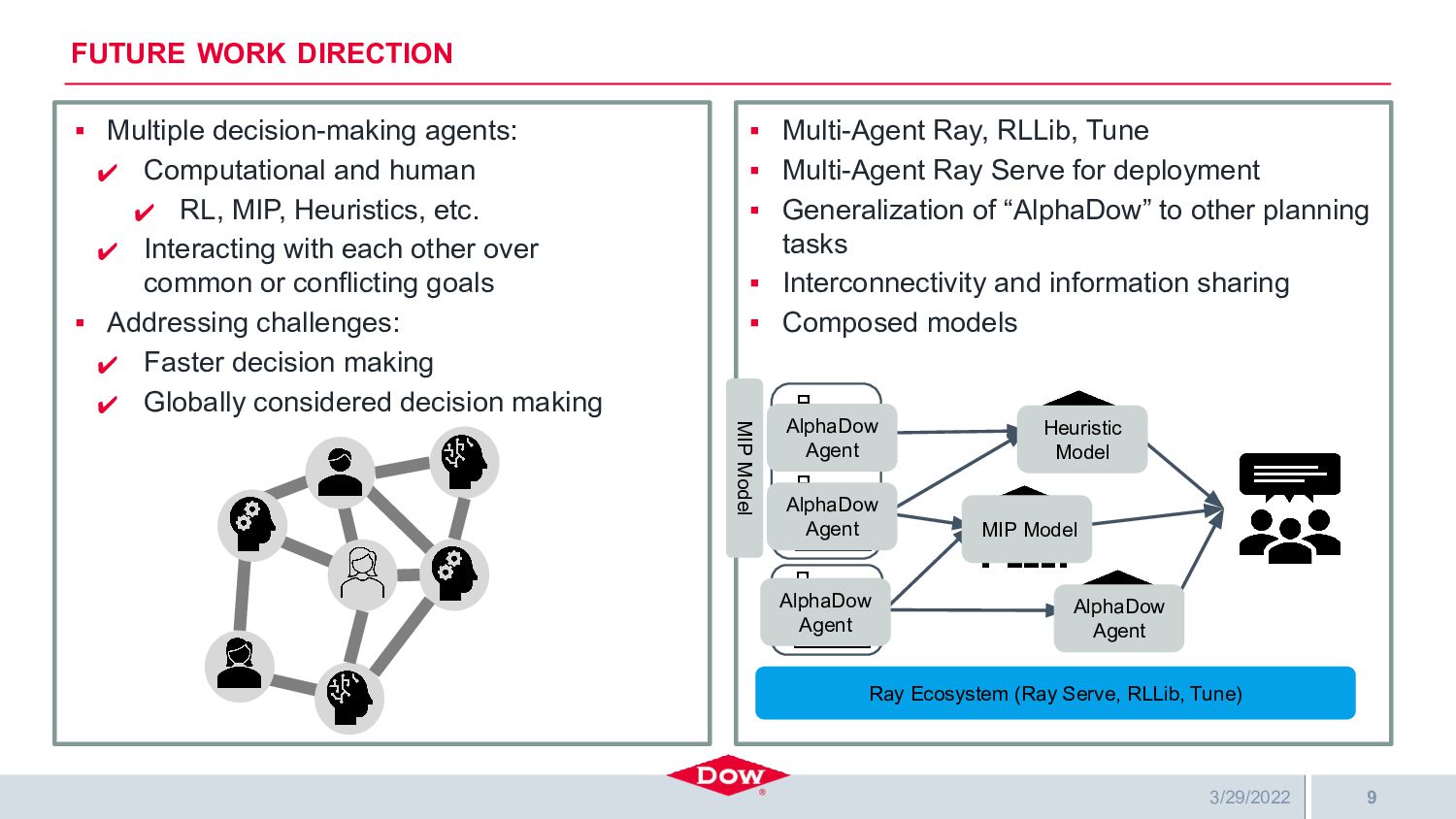
Dow is building a highly automated and intelligent multi-agent digital supply chain where many agents (RL, ML, MIP, and human) interact seamlessly to make better and faster decisions that positively impact customers, financial performance, and shareholders. Several of the digital agents are deployed using Ray Serve, which significantly simplifies their deployment, scaling, and interaction with each other. One of these agents is Dow’s project AlphaDow, which creates reinforcement learning-based agents for production scheduling — a non-trivial daily problem for all of Dow’s many facilities. AlphaDow agents are trained on in-house simulation models using RLLib and Ray Tune running on Azure compute clusters where Ray’s implementation of Population-Based Bandits is used to great effect for hyperparameter tuning. Once trained, these agents are deployed on Dow’s AKS cluster running Ray and Ray Serve.
AlphaDow’s success (thanks in part to Ray) has been the catalyst for accelerating progress towards Dow’s AI strategy and vision. In this talk, Adam will highlight several of the challenges of deploying such advanced models into a legacy industrial setting, as well as how Ray has helped overcome some of these challenges and accelerated deployments in general at Dow.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![General Business BUT THE ANYSCALE ECOSYSTEM [RLLIB, TUNE] ARE HERE](https://files.speakerdeck.com/presentations/13abc624013b4e48a3245befb9299209/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}