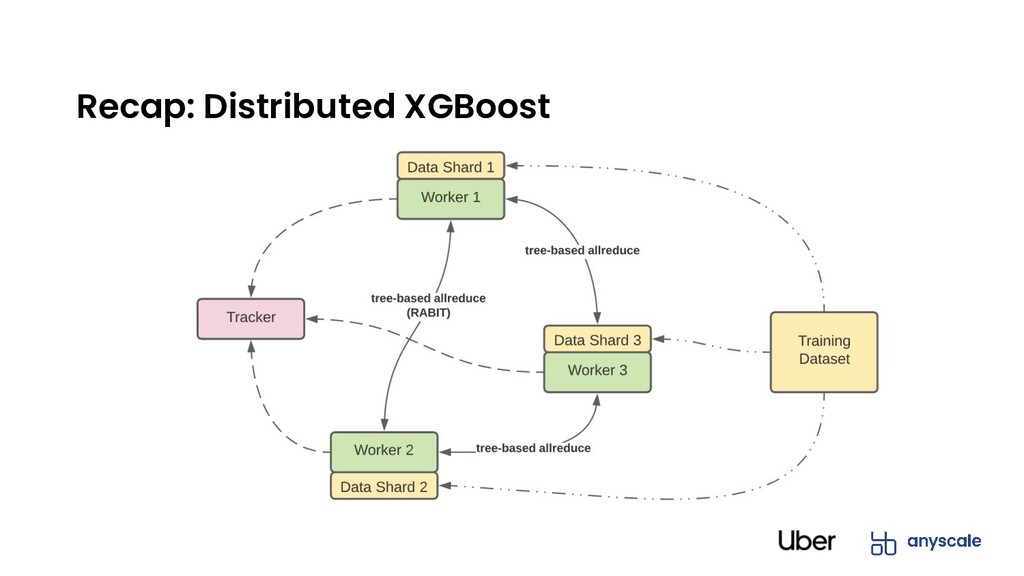
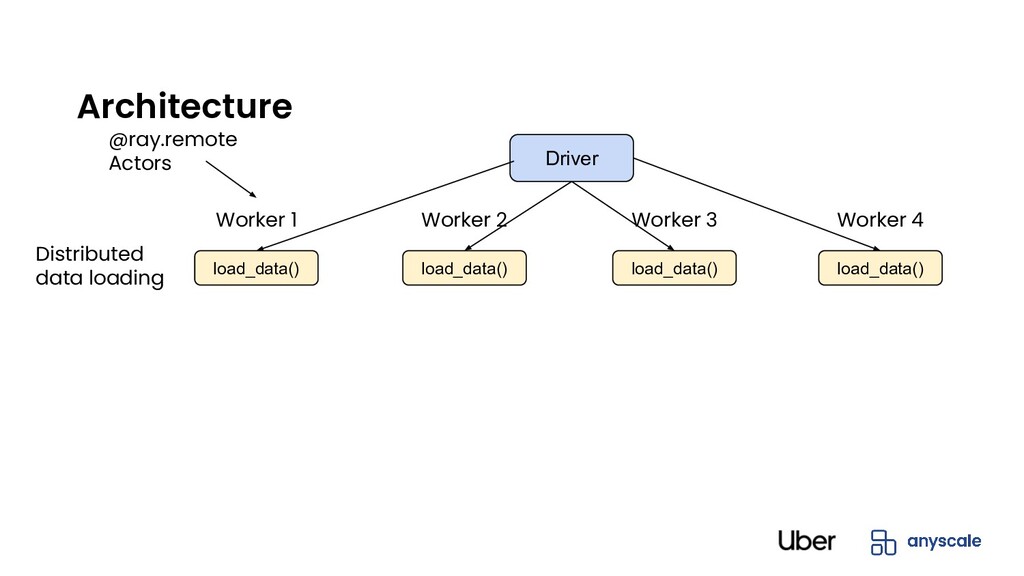
• Architecture • DIstributed Data loading • Fault-Tolerance • Hyperparameter Optimization Part 2: Ray and XGBoost-Ray at Uber • Distributed ML and DL Challenges at Scale • Ray and Distributed XGBoost on Ray at Uber • Next Steps
E.g. Spark, Dask, Kubernetes • But most existing solutions are lacking • Dynamic computation graphs • Fault tolerance handling • GPU support • Integration with hyperparameter tuning libraries
• Trees or linear models • Each step try to fit the residuals using loss gradients • (XGBoost: 2nd order Taylor approximations) Tree 1 Tree 2 Tree 3 + + + ... Recap: XGBoost
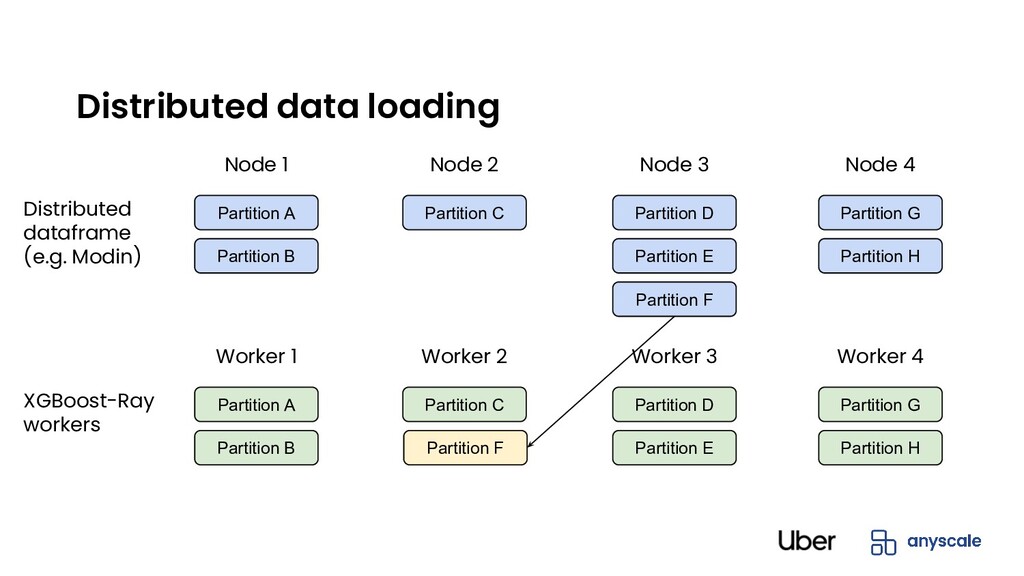
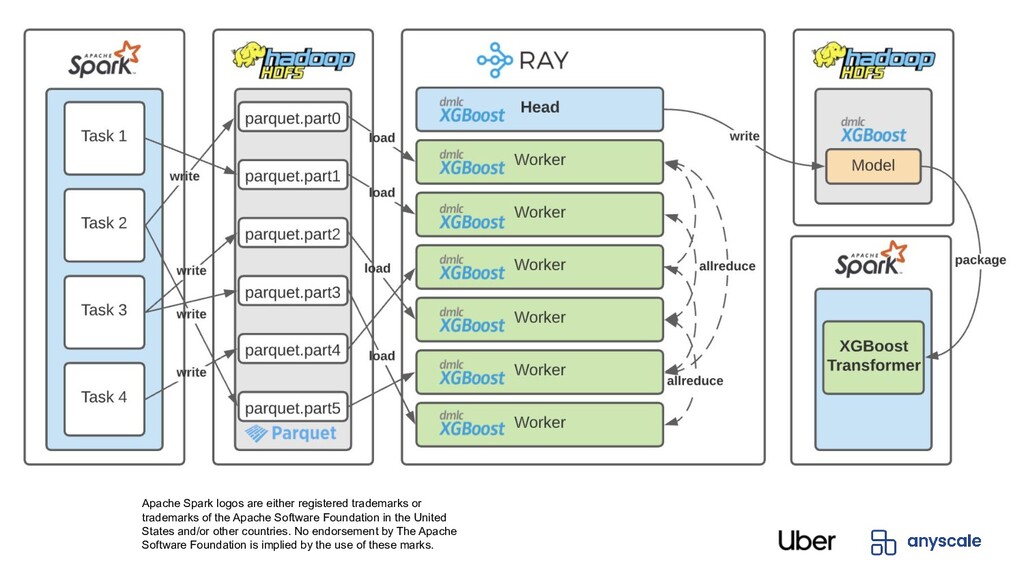
Partition B Partition C Partition F Partition D Partition E Partition G Partition H Partition A Worker 1 Worker 2 Worker 3 Worker 4 Partition B Partition C Partition F Partition D Partition E Partition G Partition H Distributed dataframe (e.g. Modin) XGBoost-Ray workers Distributed data loading
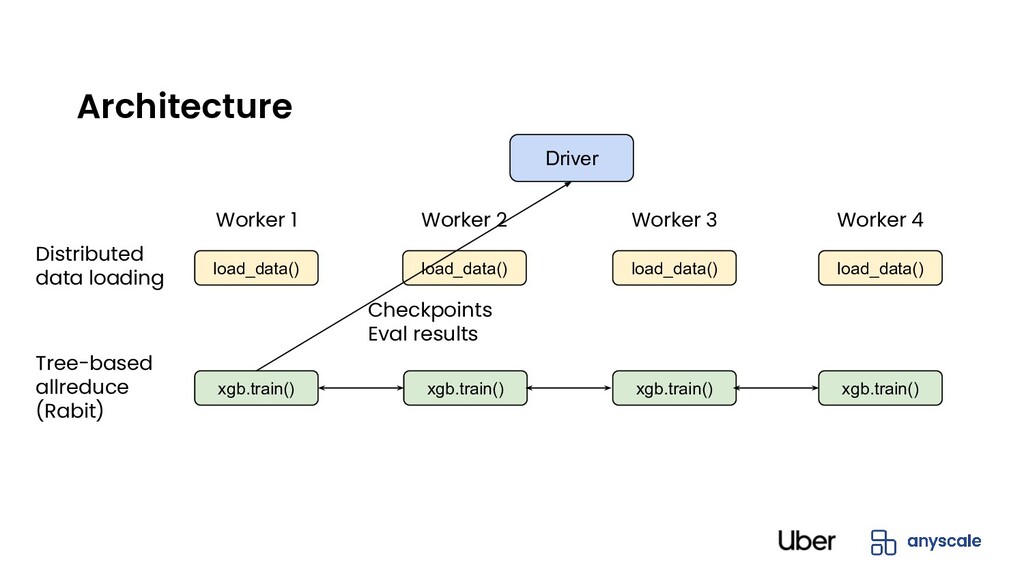
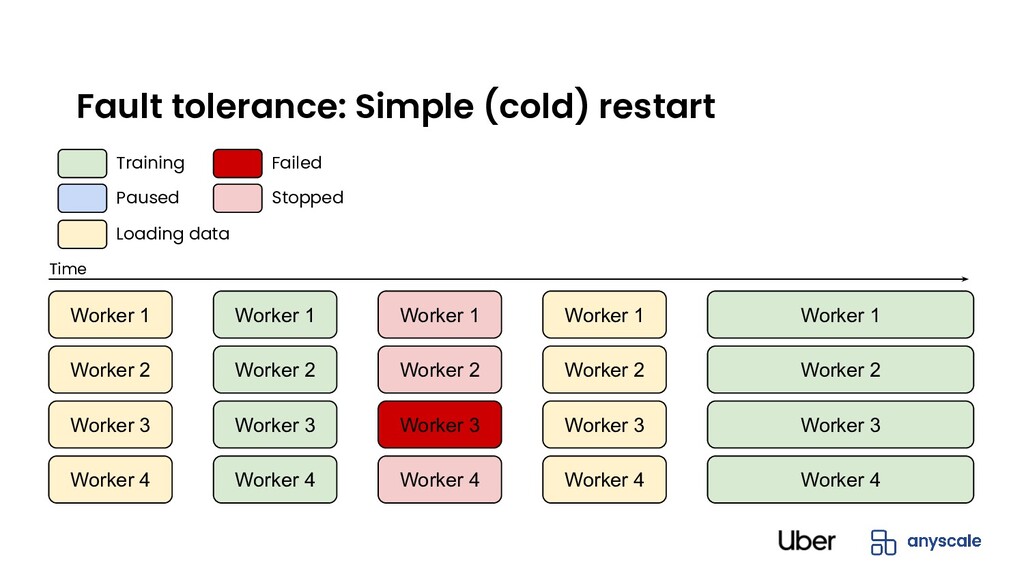
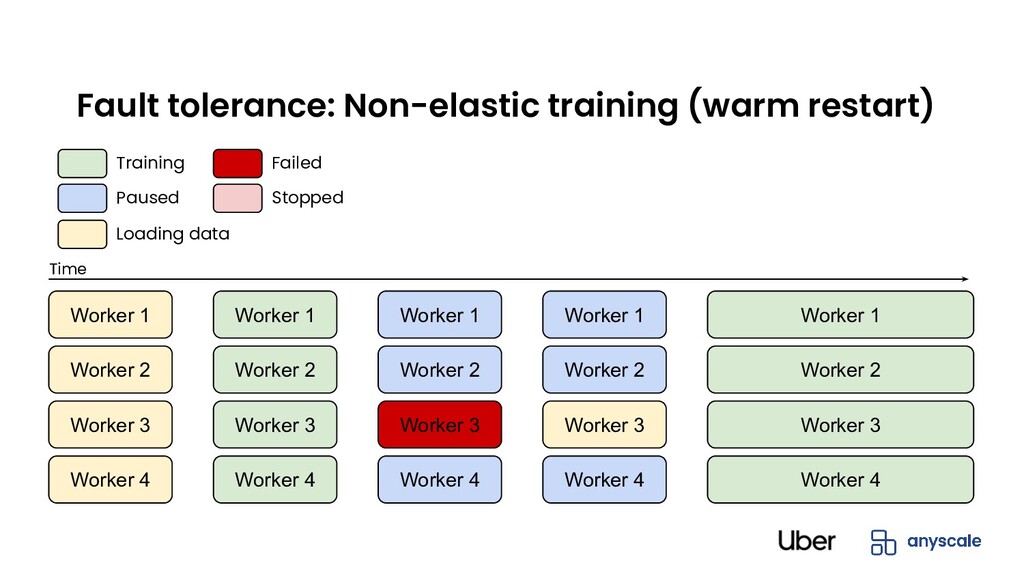
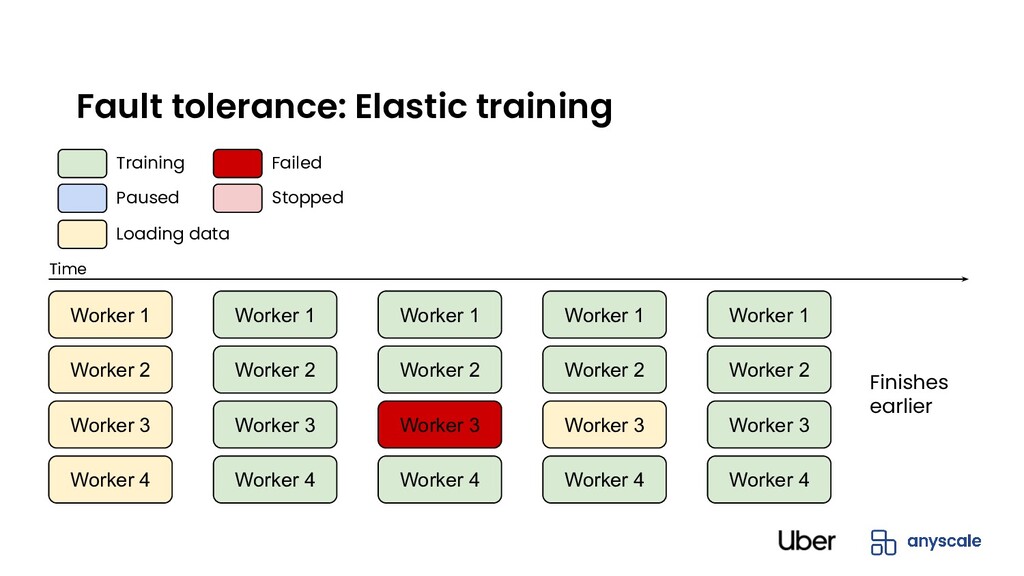
fail eventually • Default: Simple (cold) restart from last checkpoint • Non-elastic training (warm restart): Only failing worker restarts • Elastic training: Continue training with fewer workers until failed actor is back Fault tolerance
• Architecture • DIstributed Data loading • Fault-Tolerance • Hyperparameter Optimization Part 2: Ray and XGBoost-Ray at Uber • Distributed ML and DL Challenges at Scale • Ray and Distributed XGBoost on Ray at Uber • Next Steps
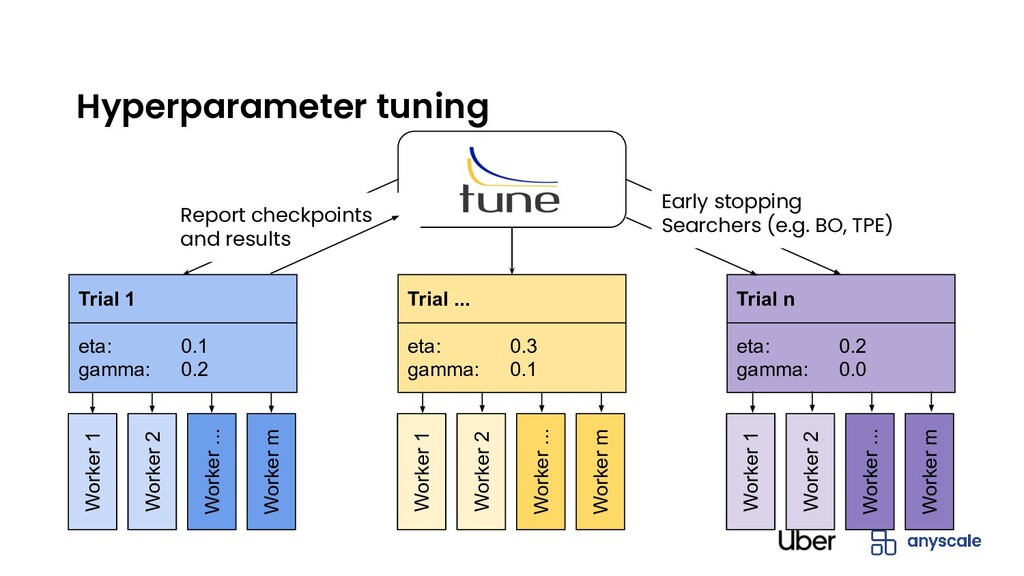
source b. Run anywhere 2. Set of general distributed compute primitives a. Fault-Tolerance / Auto-Scaling b. Dynamic task graph and actors (stateful API) c. Shared memory 3. Rich ML ecosystem a. Distributed Hyperparameter Search: RayTune
• XGBoost or Horovod + Ray • Unified backend for Distributed Hyperparameter Search • XGBoost or Horovod + Ray Tune • General-purpose compute backend for ML Workflows • XGBoost or Horovod + Ray Tune + Dask on Ray Elastic Horovod on Ray (2021): https://eng.uber.com/horovod-ray/
combine distributed training on Ray with Apache Spark? Apache Spark logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
well-suited to distributed training 2. Spark applications typically run on CPU, distributed training on GPU Spark • Jobs typically easy to fan out with cheap CPU machines • Transformations do not benefit as much from GPU acceleration Distributed Training • Compute bound, not data bound • Computations easy to represent with linear algebra
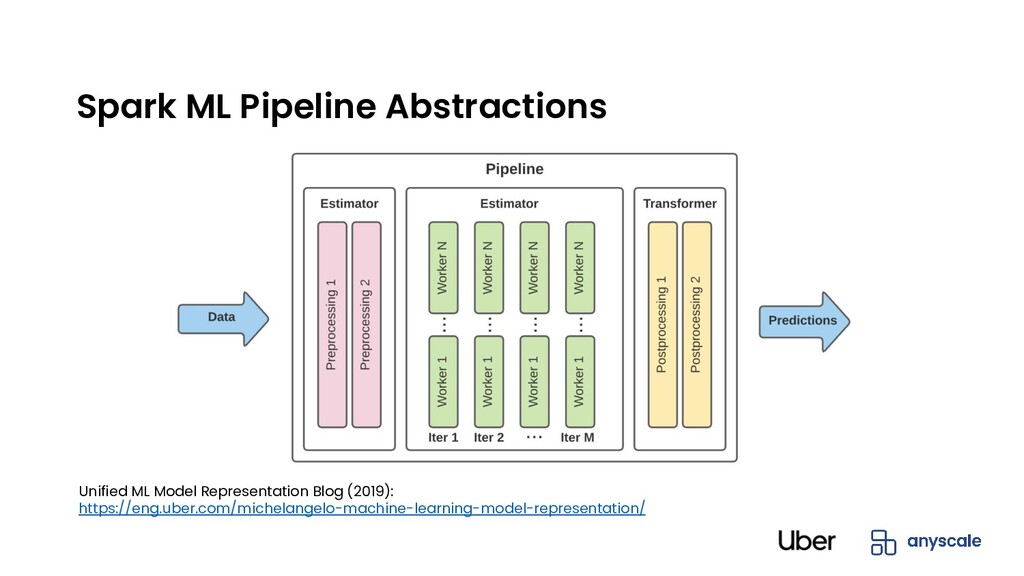
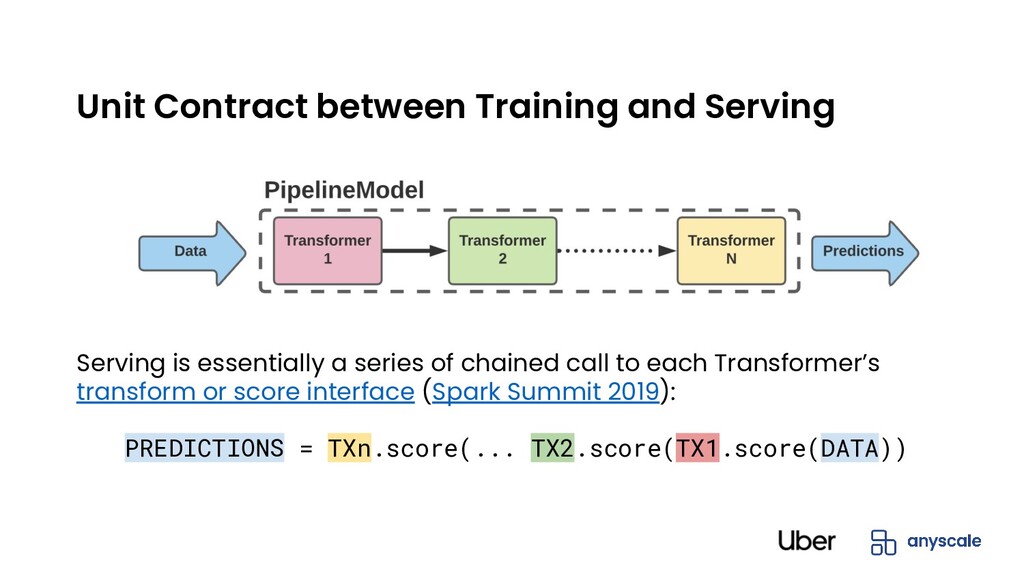
Train/Test Split. Fit the data transformation Pipeline to generate the data transformer (train_df, test_df) = train_test_split(spark_dataframe, split_ratio=0.1) data_pipeline = data_processing_pipeline.fit(train_df) # Transform the original train/test data set with the fitted data transformer transformed_train_data = data_pipeline.transform(train_df) transformed_test_data = data_pipeline.transform(test_df)
# Create the Ray Estimator xgboost_estimator = RayEstimator(remote_fn=train, ray_params=RayParams(num_actors=10), config={“eta”:0.3, “max_depth”: 10}, ...) # Create Spark Pipeline with Ray Estimator pipeline = Pipeline(stages=[...,xgboost_estimator,...]) # Fit the entire Pipeline on Train dataset and do batch serving trained_pipeline = pipeline.fit(train_df) pred_df = trained_pipeline.transform(test_df)
the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Moving towards: • Ray Tune + Horovod on Ray for DL auto-scaling training + hyperopt • Ray Tune + XGBoost on Ray for ML auto-scaling training + hyperopt • Dask on Ray for preprocessing • No need to maintain / provision separate infra resources • No need to materialize preprocessed data to disk • Leverage data locality • Colocation and shared memory Elastic Horovod on Ray (2021): https://eng.uber.com/horovod-ray/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Preparation with Spark data_processing_pipeline = Pipeline(stages=[ StringToFloatEncoder(...), StringIndexer(...)]) #](https://files.speakerdeck.com/presentations/a6a406825ecb48f2b2e3e4a3f0dea47e/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}