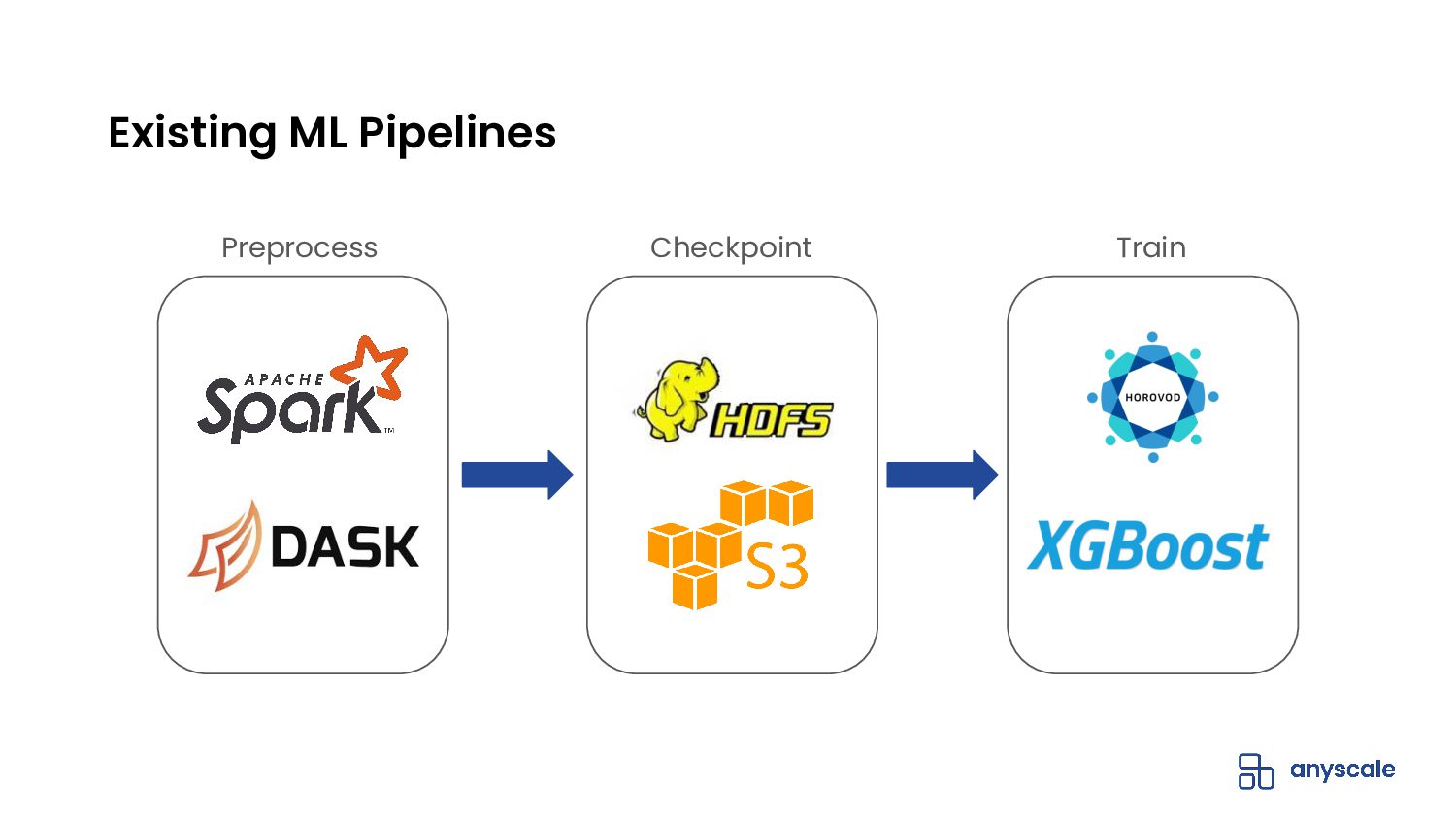
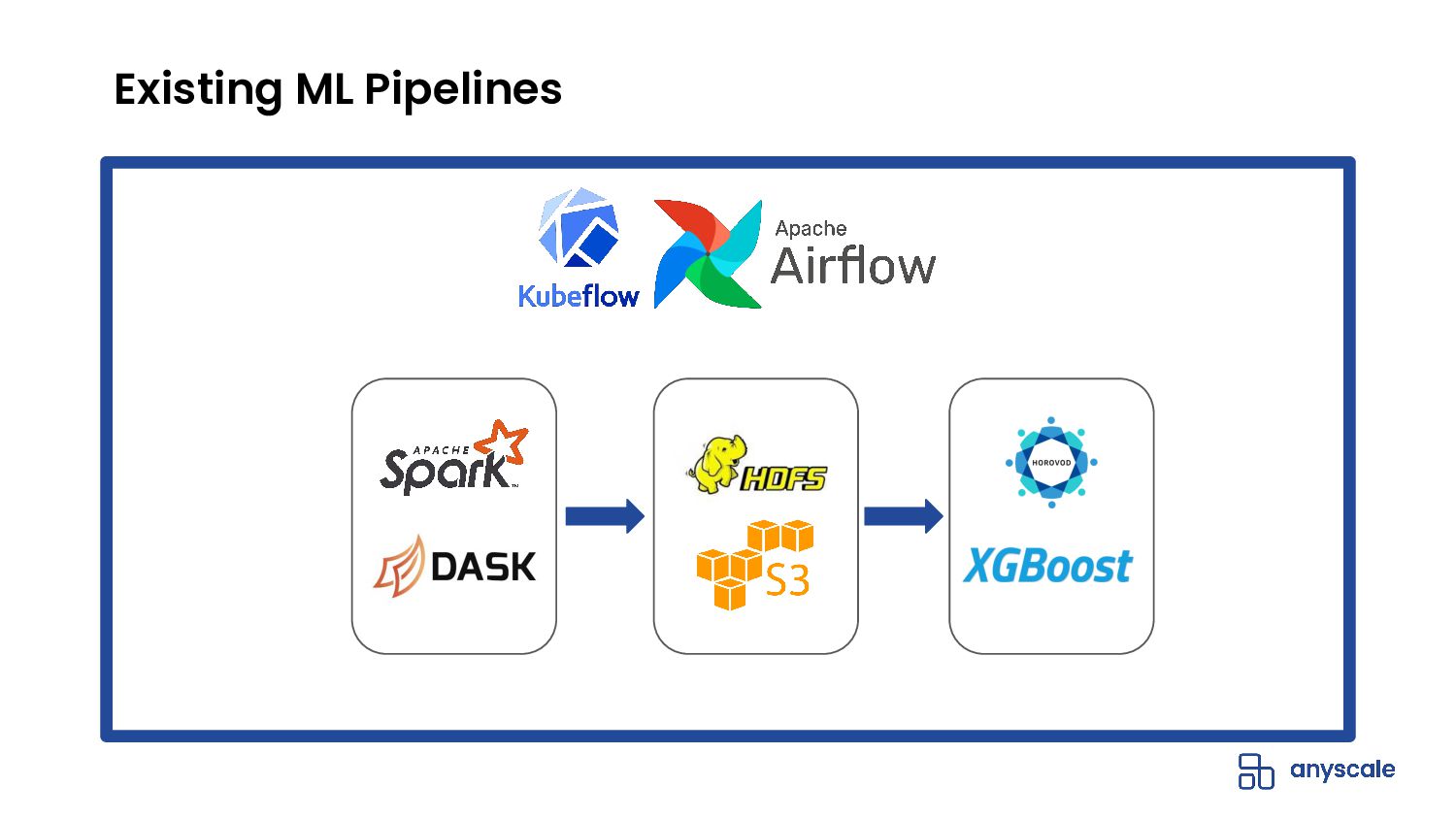
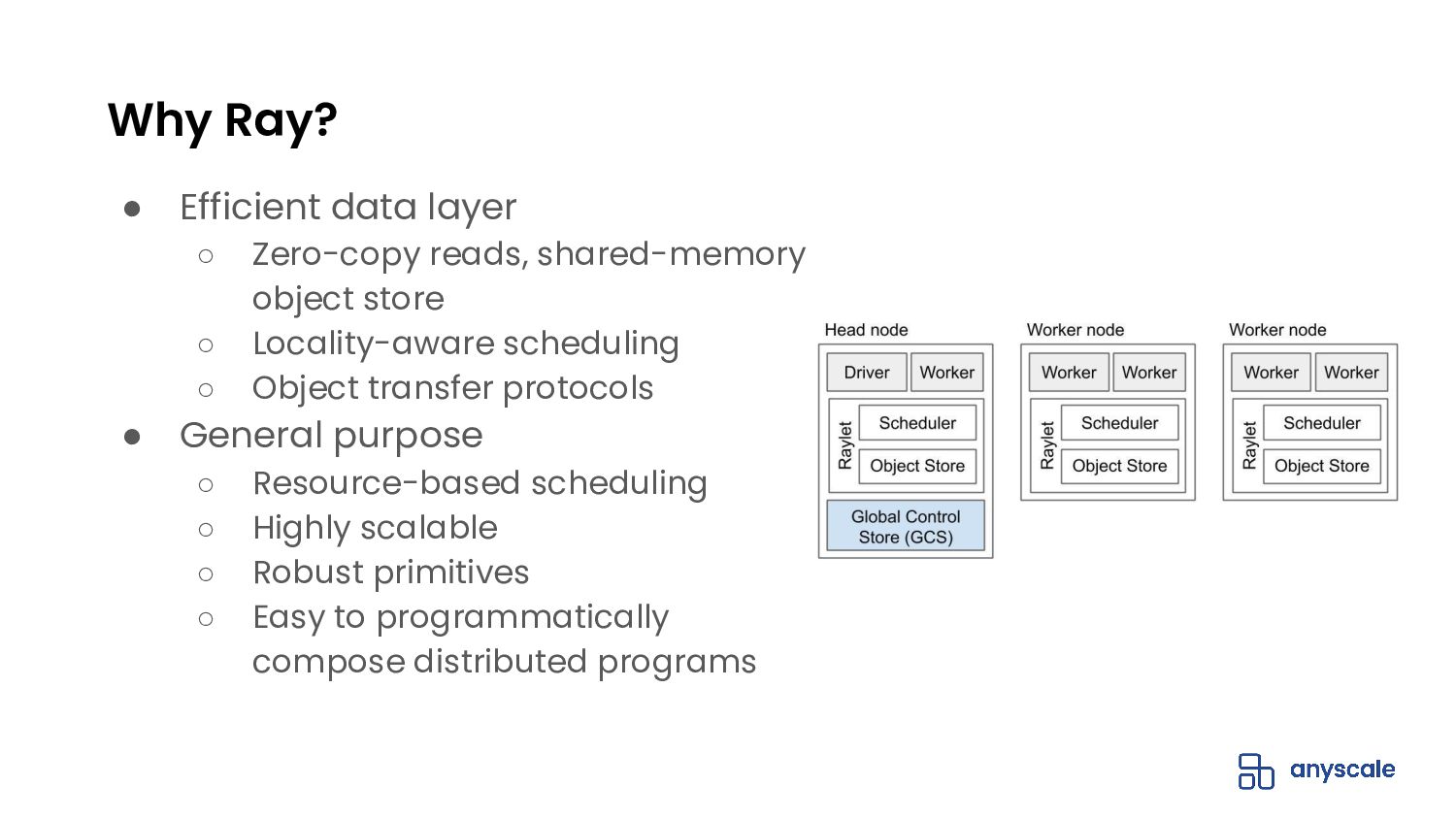
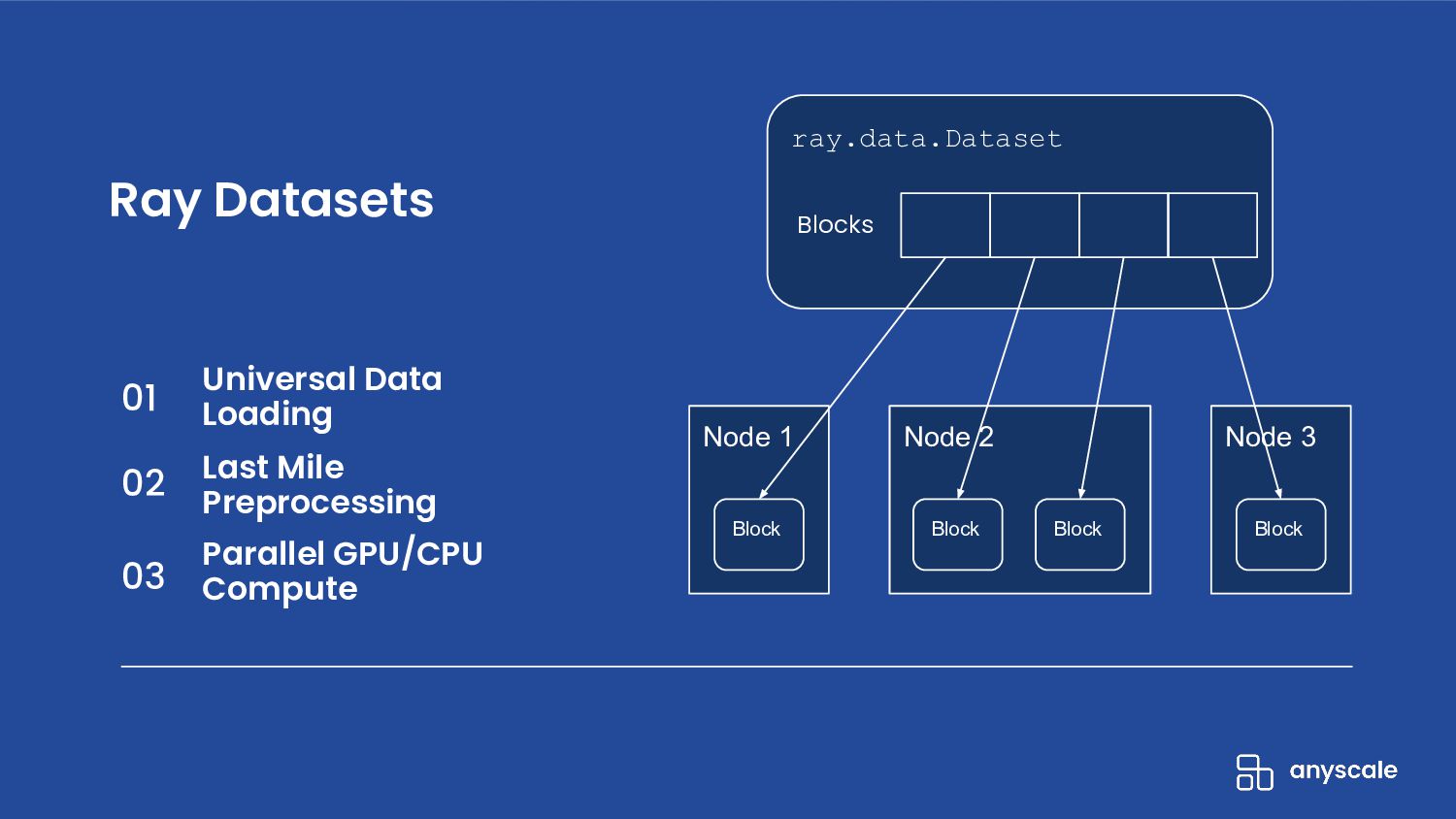
ML tasks such as distributed training and batch inference stretch the abstractions of modern data processing systems. In this talk, we’ll discuss the wide-ranging problems that the Python community faces when building large-scale preprocessing and training pipelines. Some of these problems are caused by the complexity of stitching together distributed systems that weren’t designed to be compatible. For example, creating a pipeline with Dask and Horovod that can efficiently use the CPUs and GPUs in a cluster. Other problems -- like per-epoch dataset shuffling, show a gap between what operations ML practitioners want and what data processing libraries are capable of doing efficiently. We’ll also introduce Ray Datasets, a simple, scalable, and pythonic way of solving these problems.
![Unifying Data preprocessing and training with Ray Datasets [PUBLIC] Alex](https://files.speakerdeck.com/presentations/3cd6c1ae47f045b4a1d3a36fb9d95b49/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
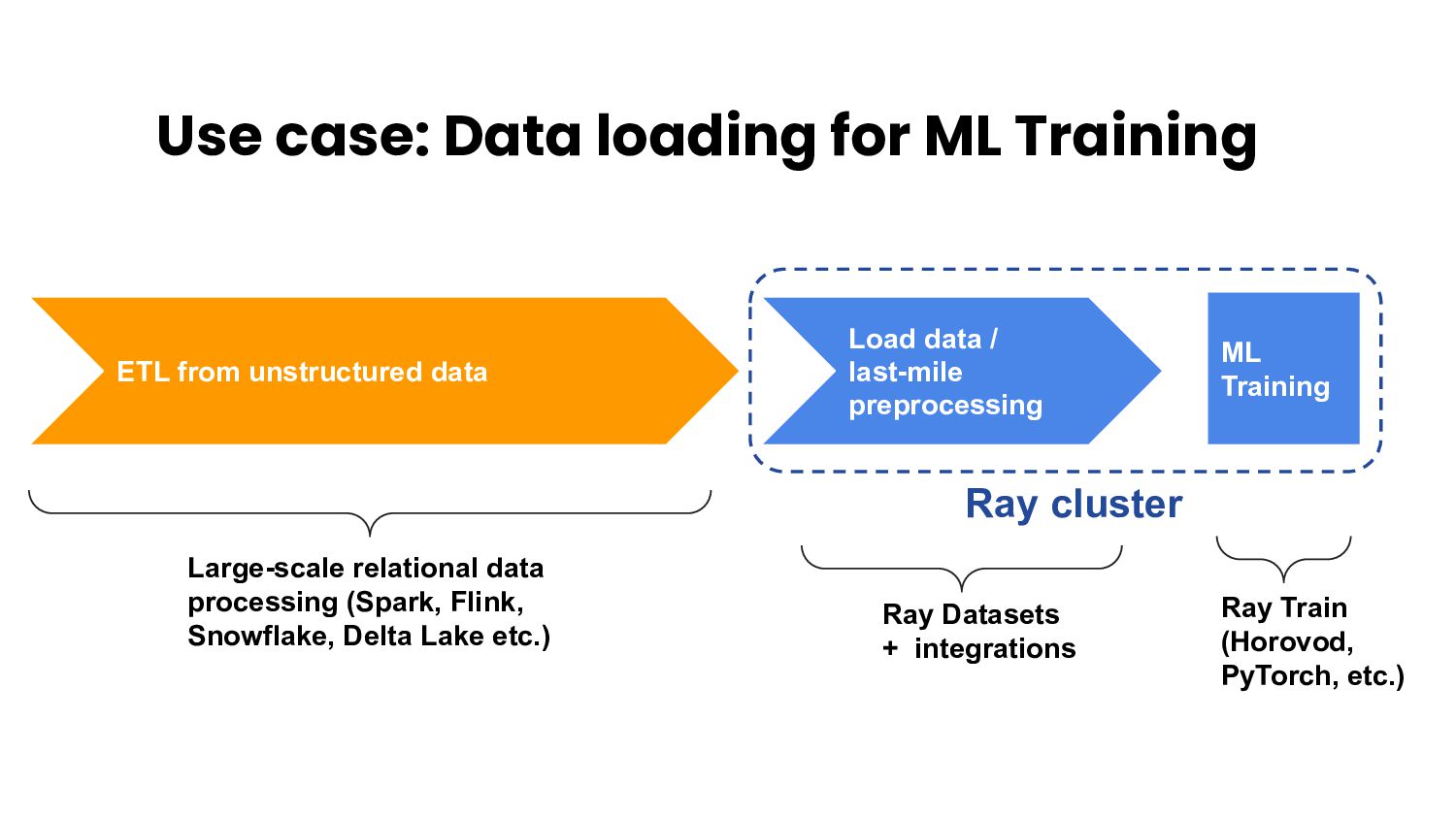{kind=link}
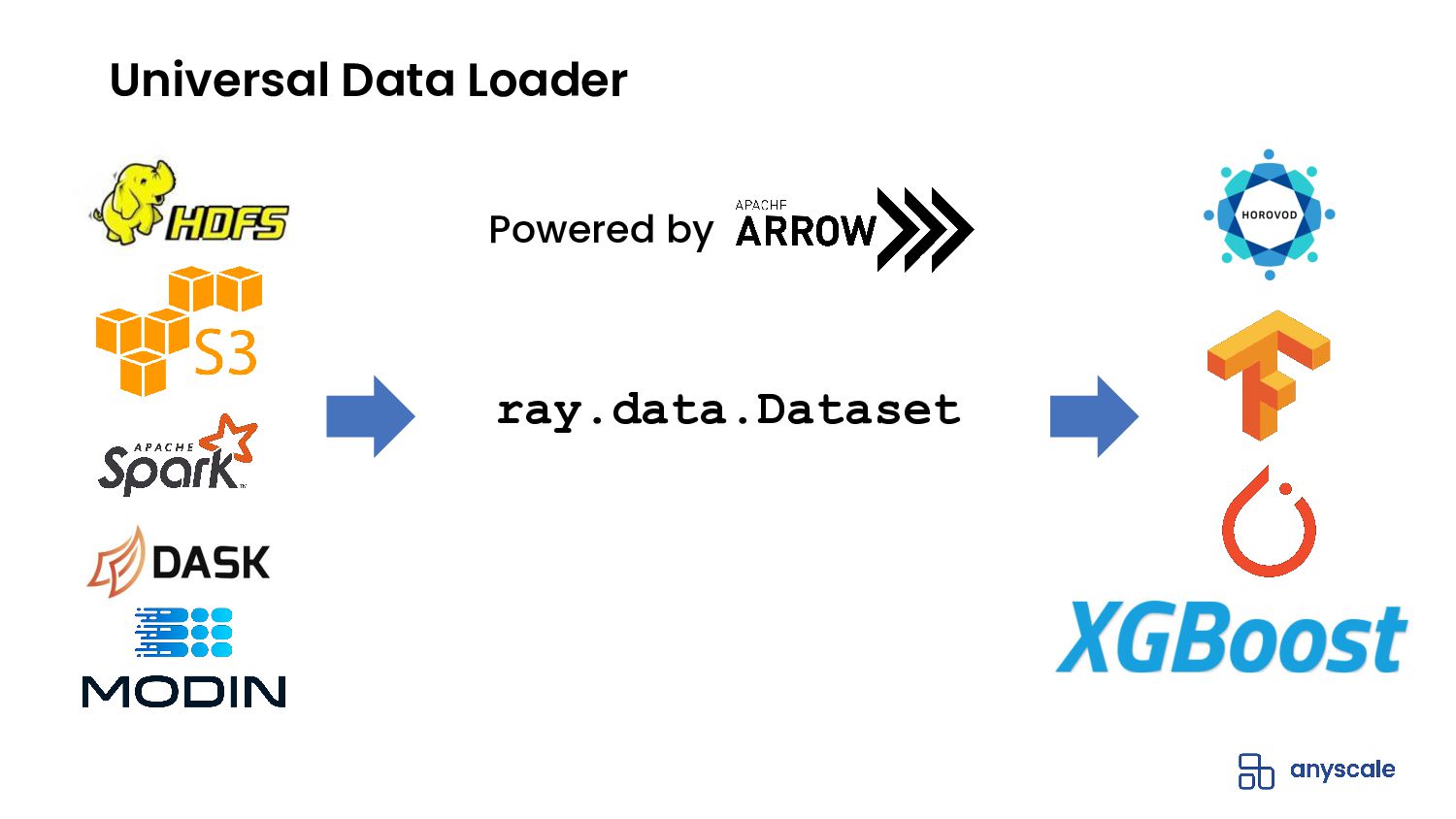{kind=link}
{kind=link}
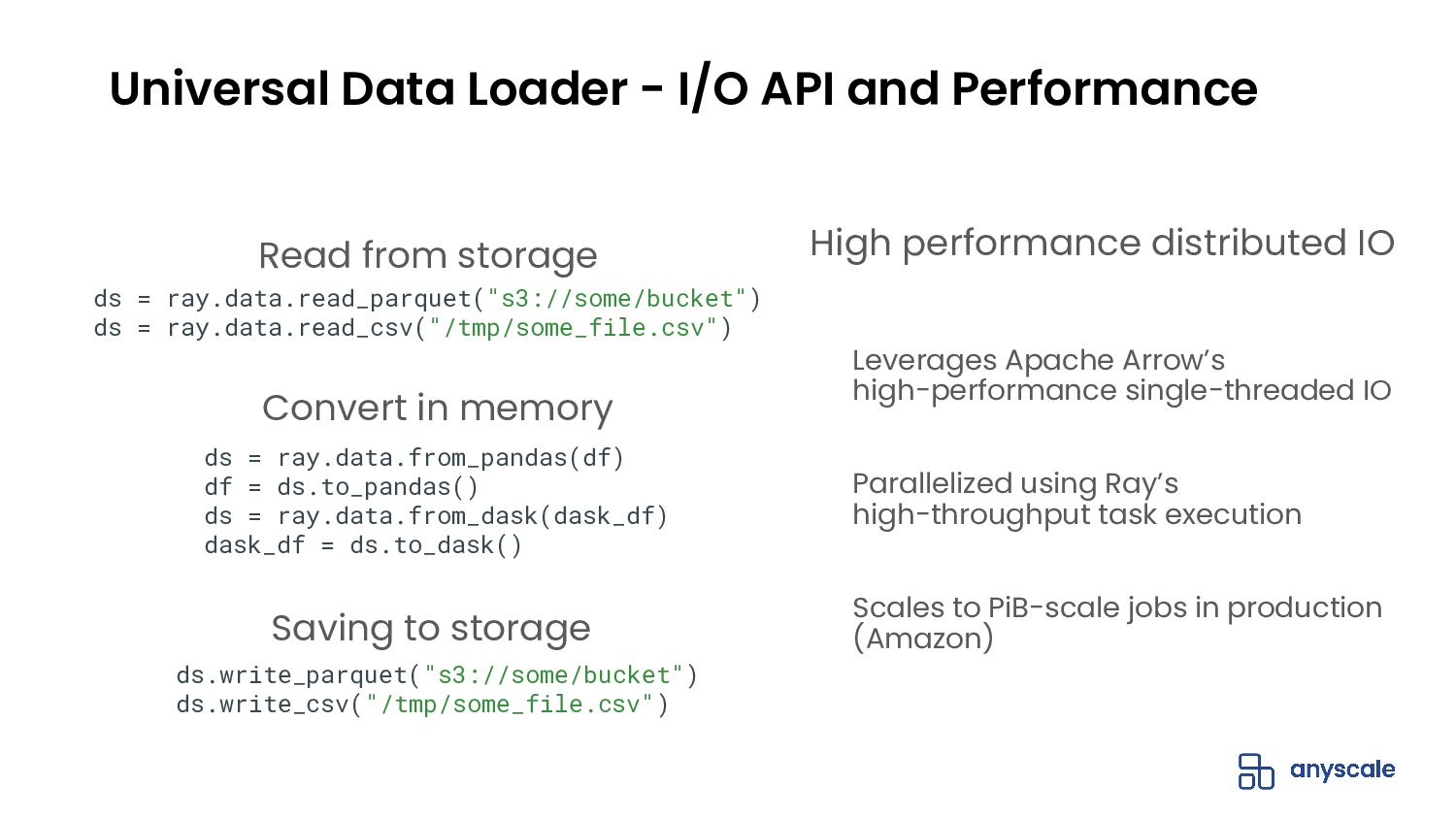{kind=link}
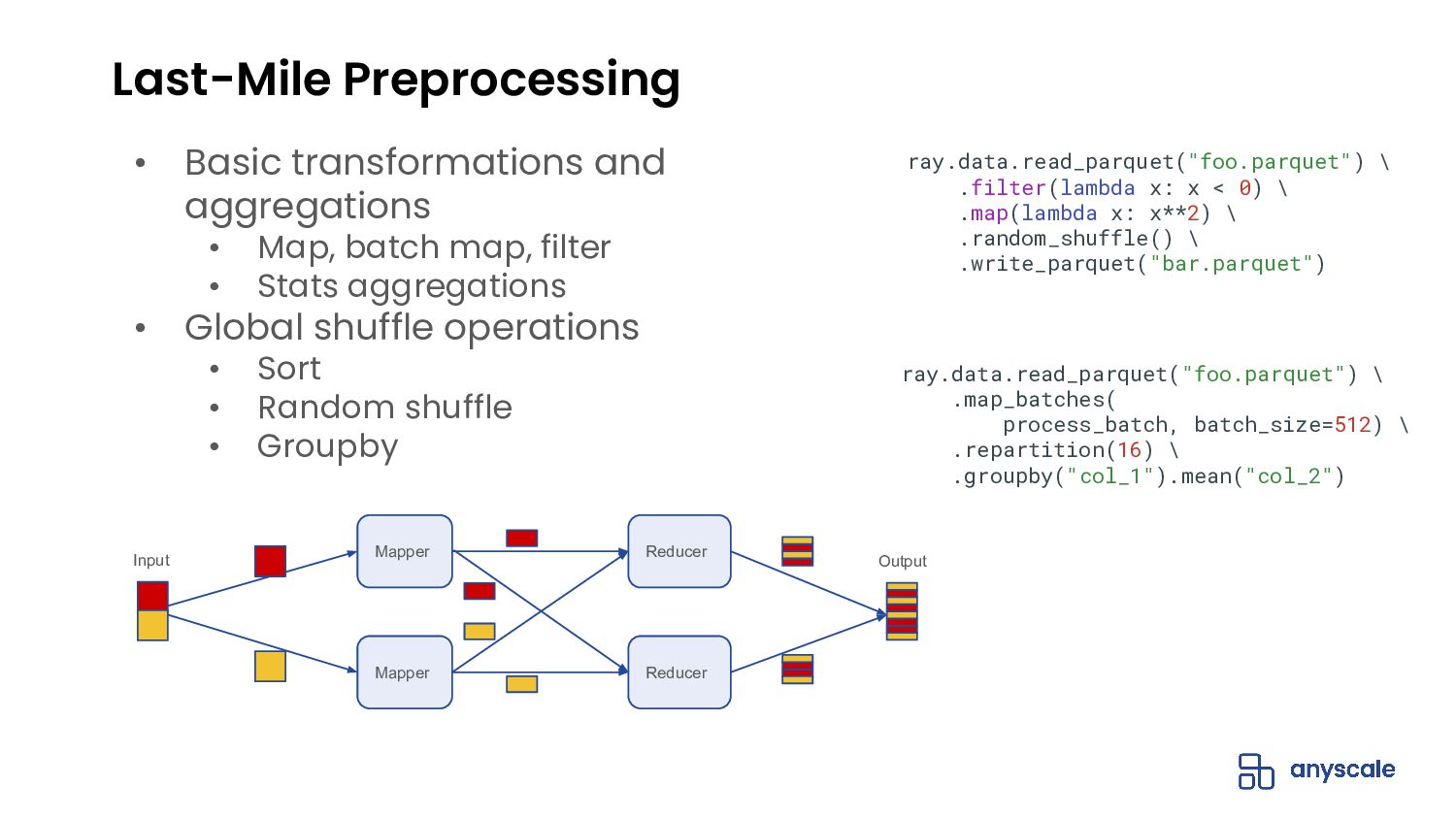{kind=link}
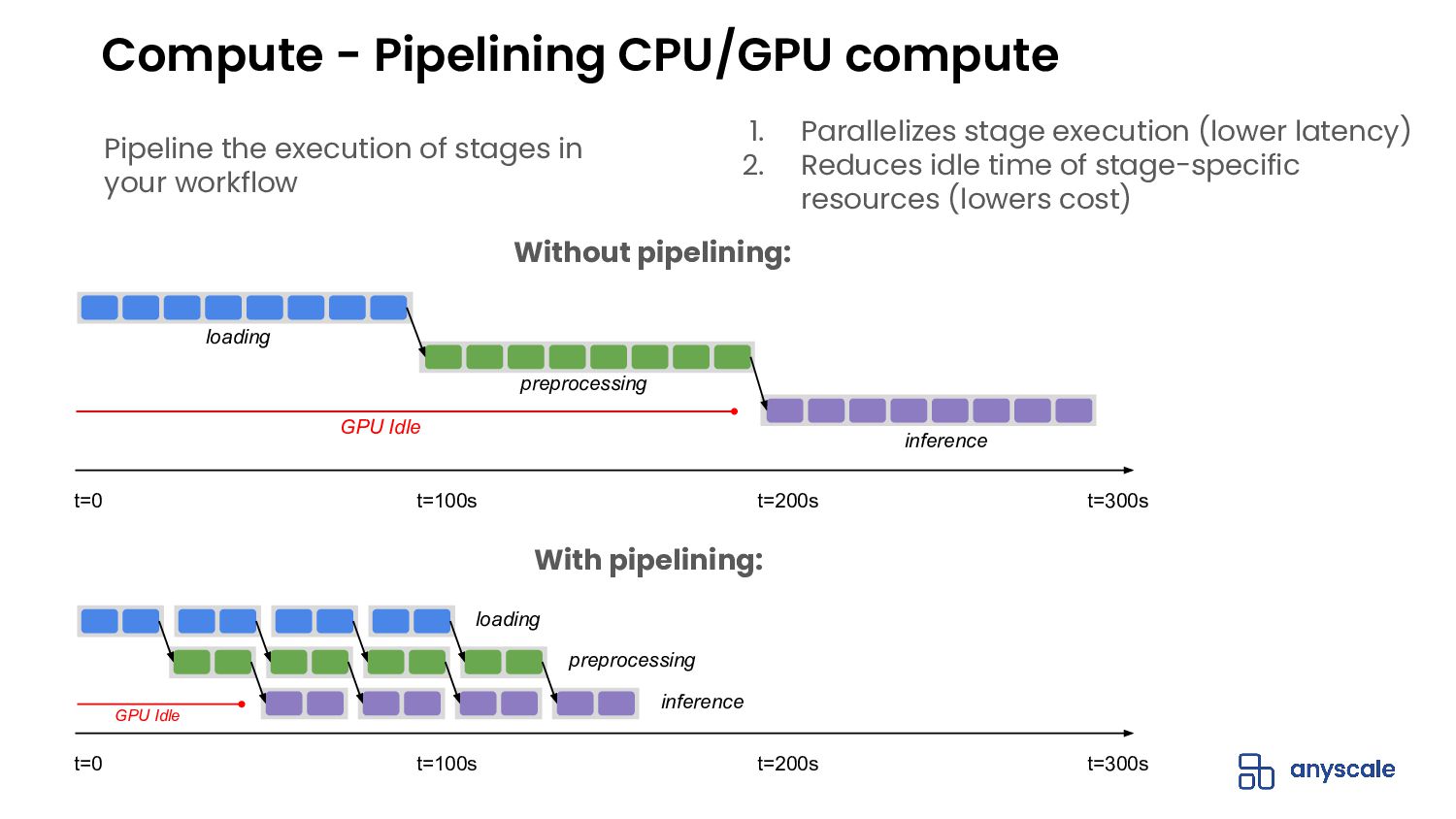{kind=link}
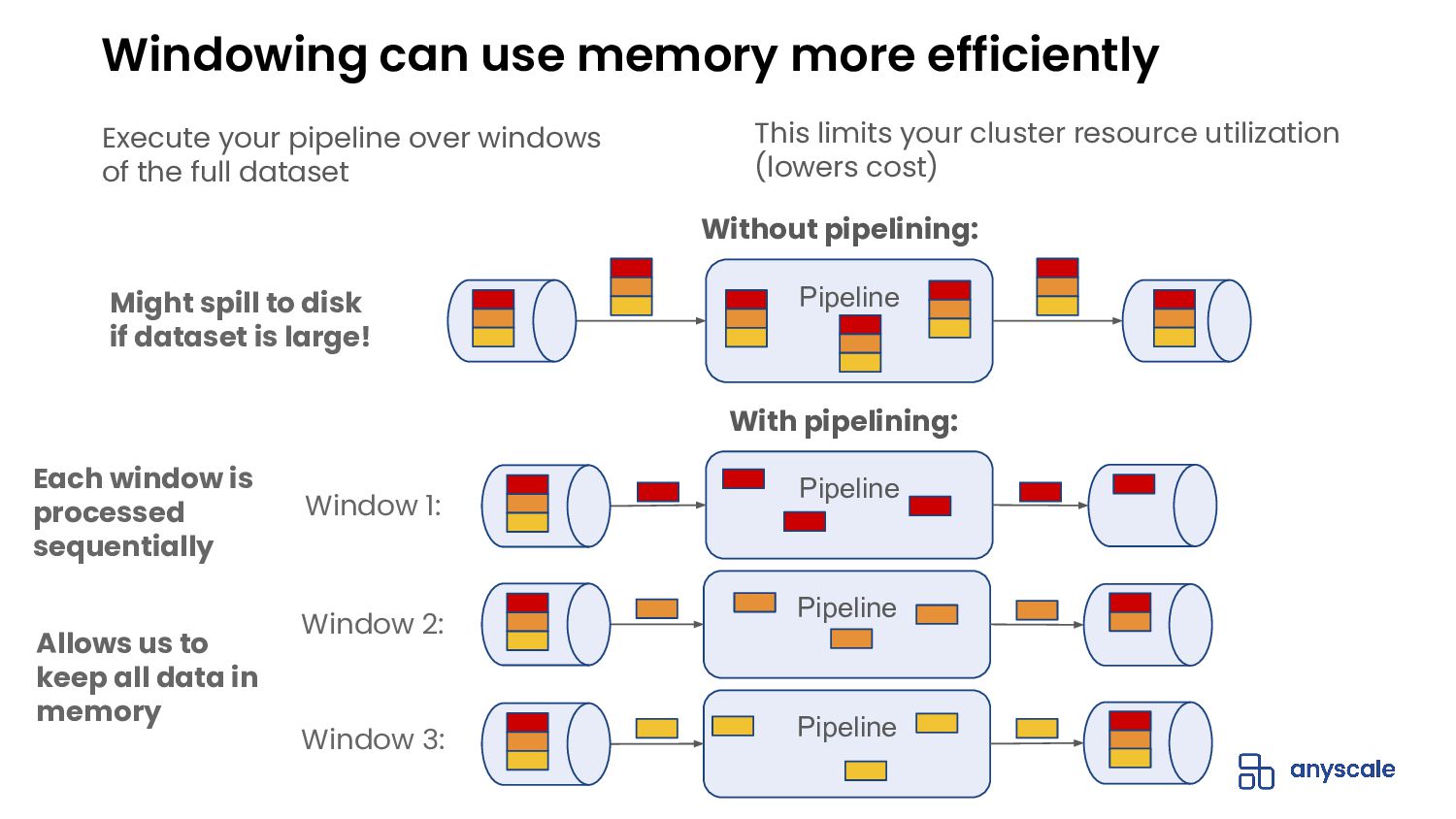{kind=link}
{kind=link}
{kind=link}
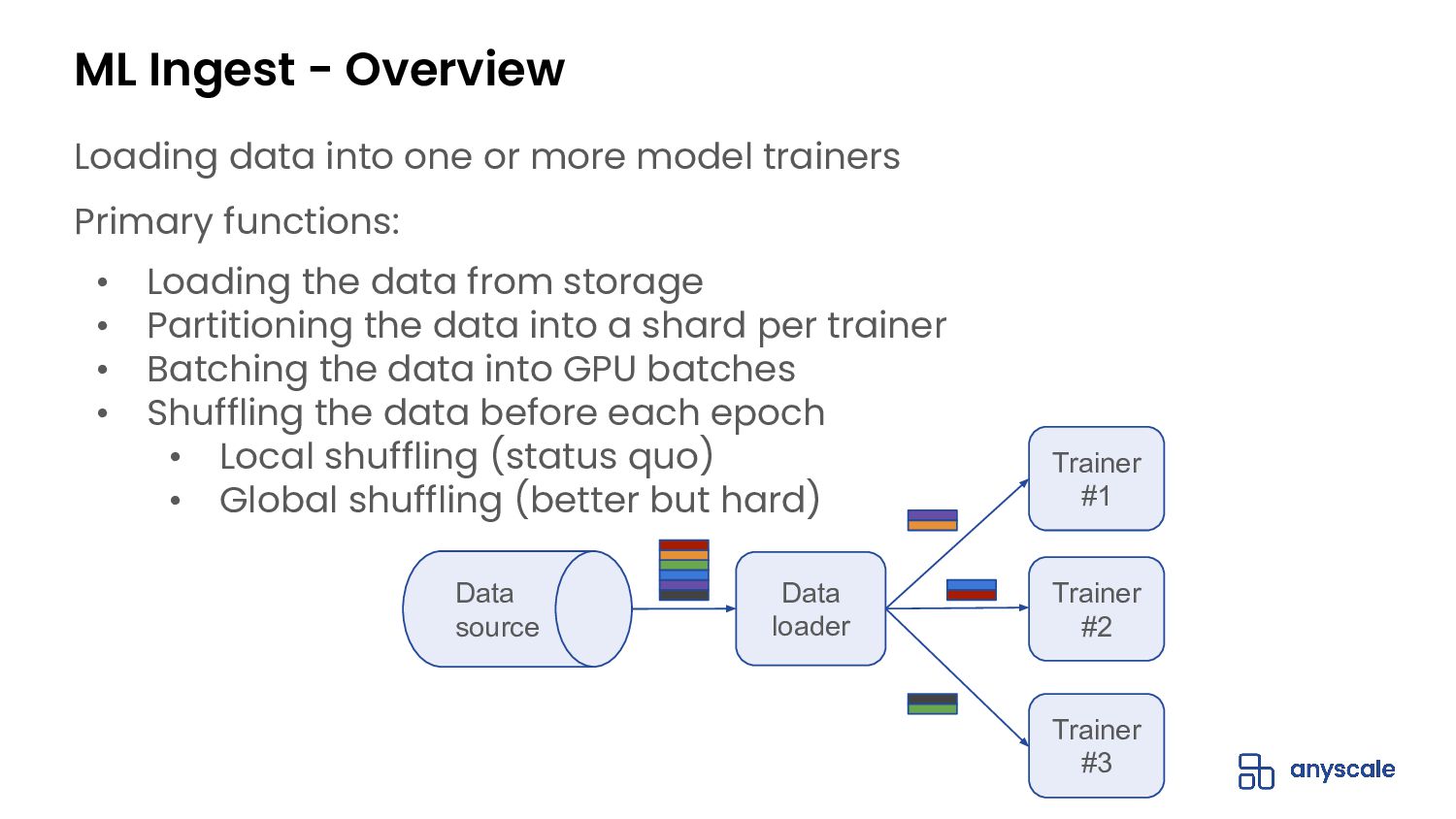{kind=link}
{kind=link}
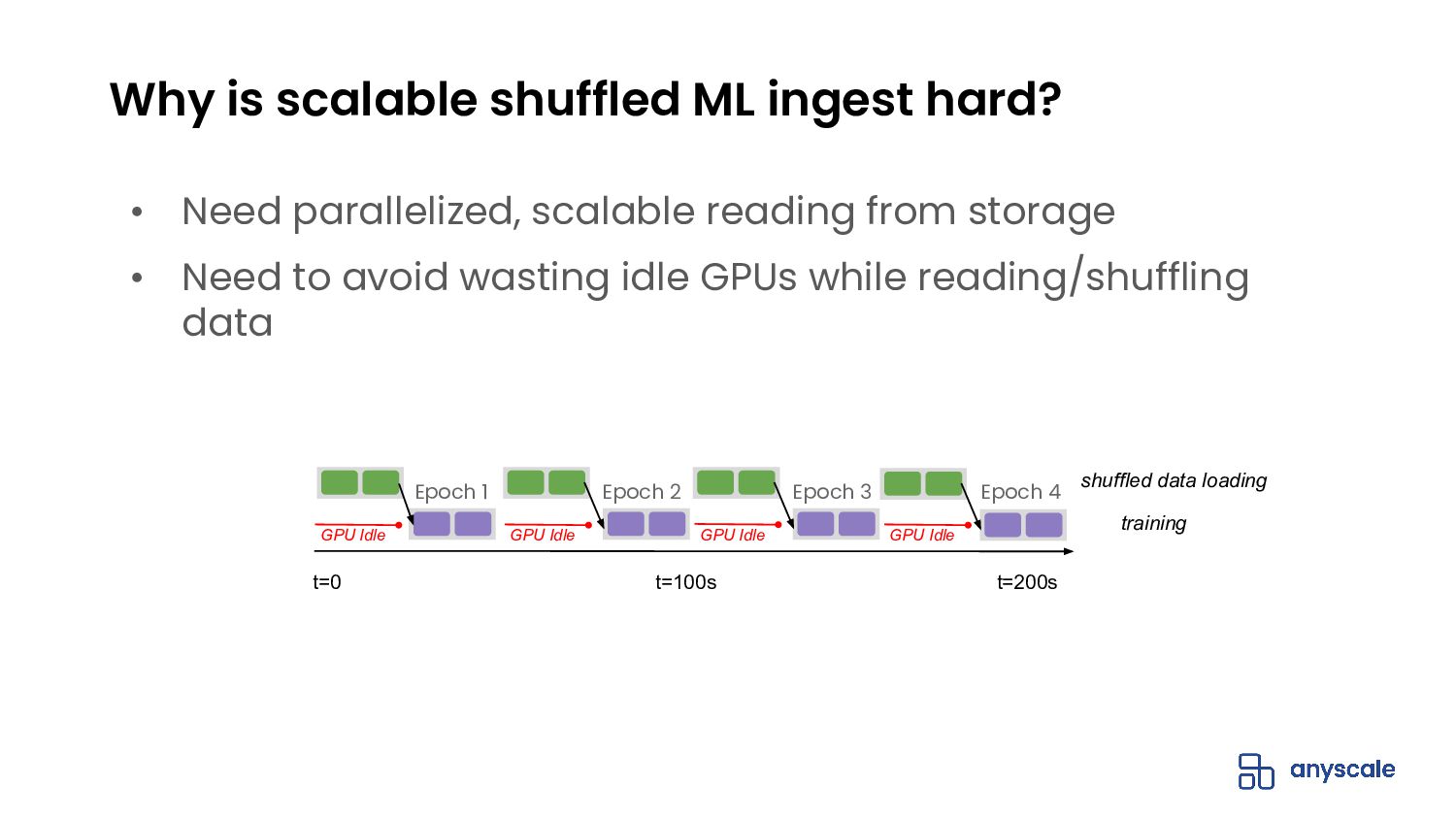{kind=link}
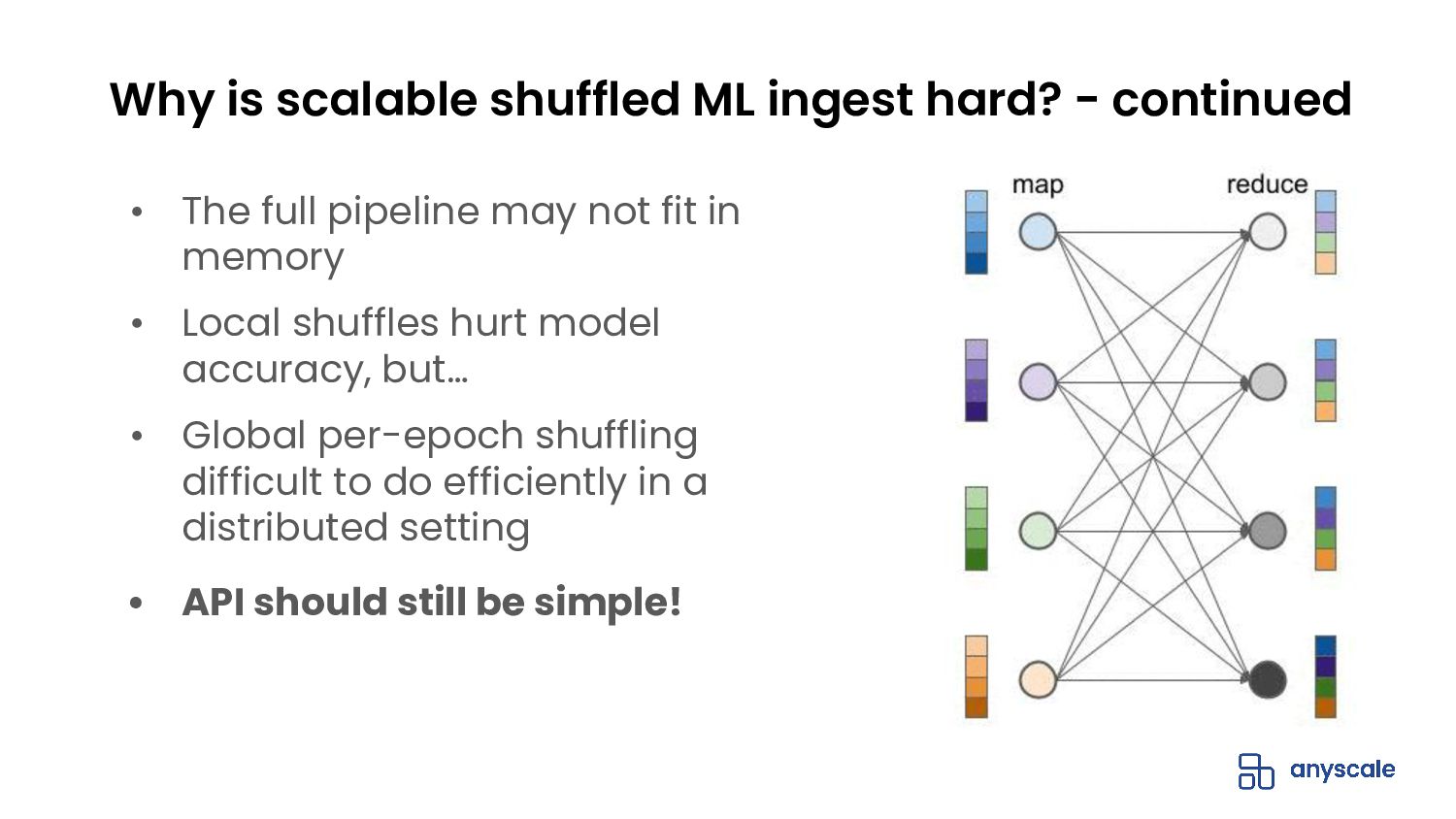{kind=link}
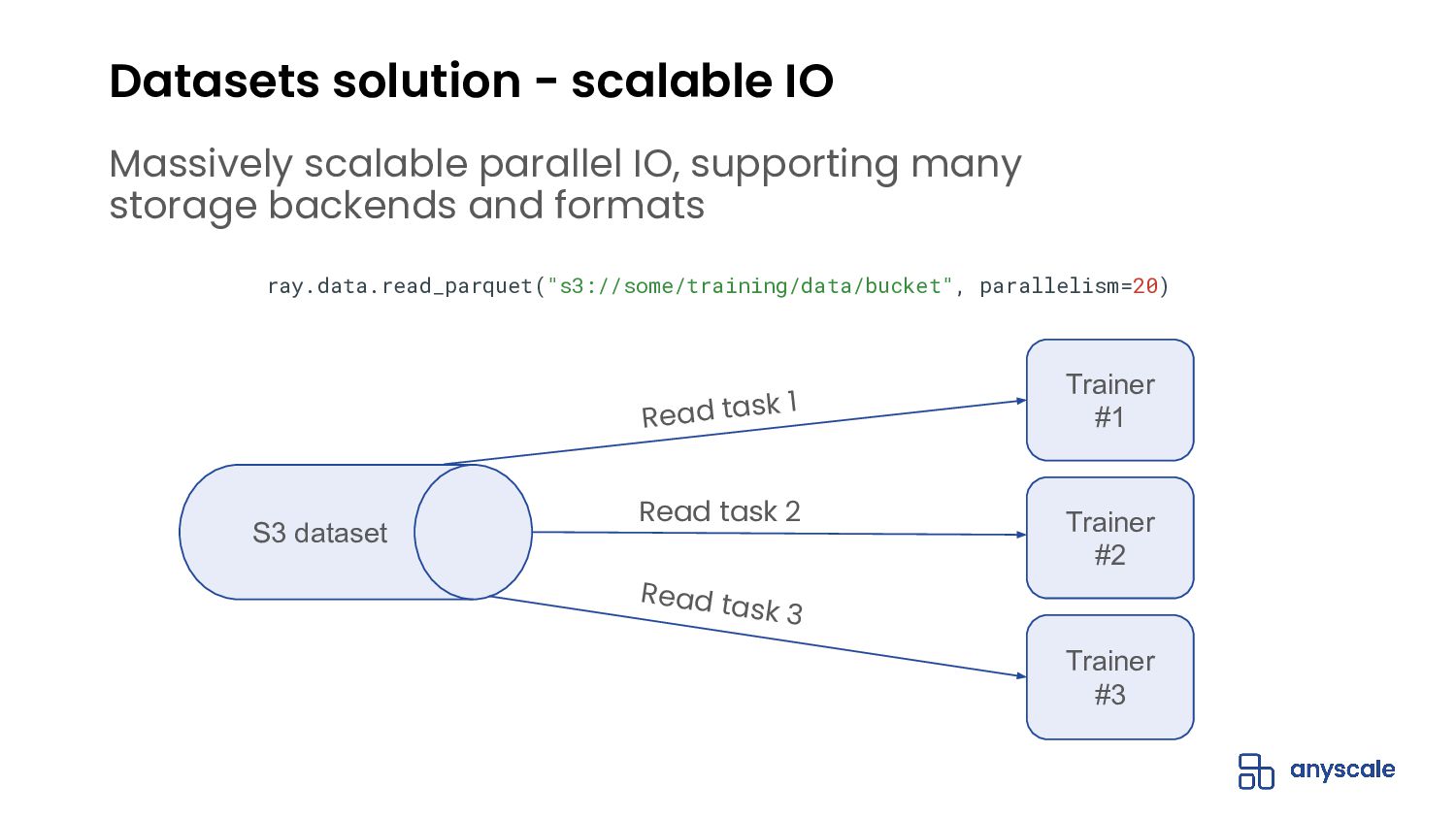{kind=link}
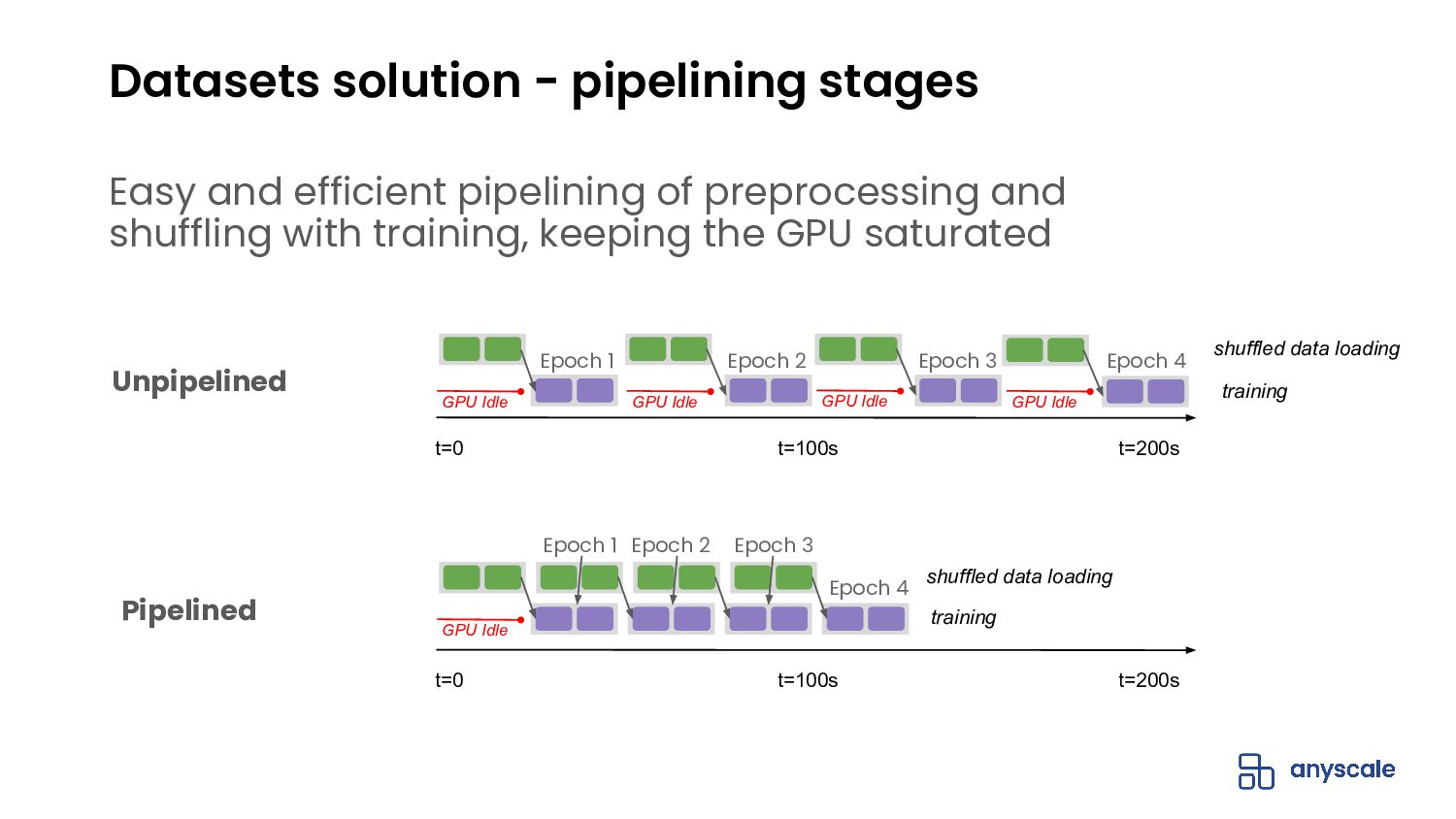{kind=link}
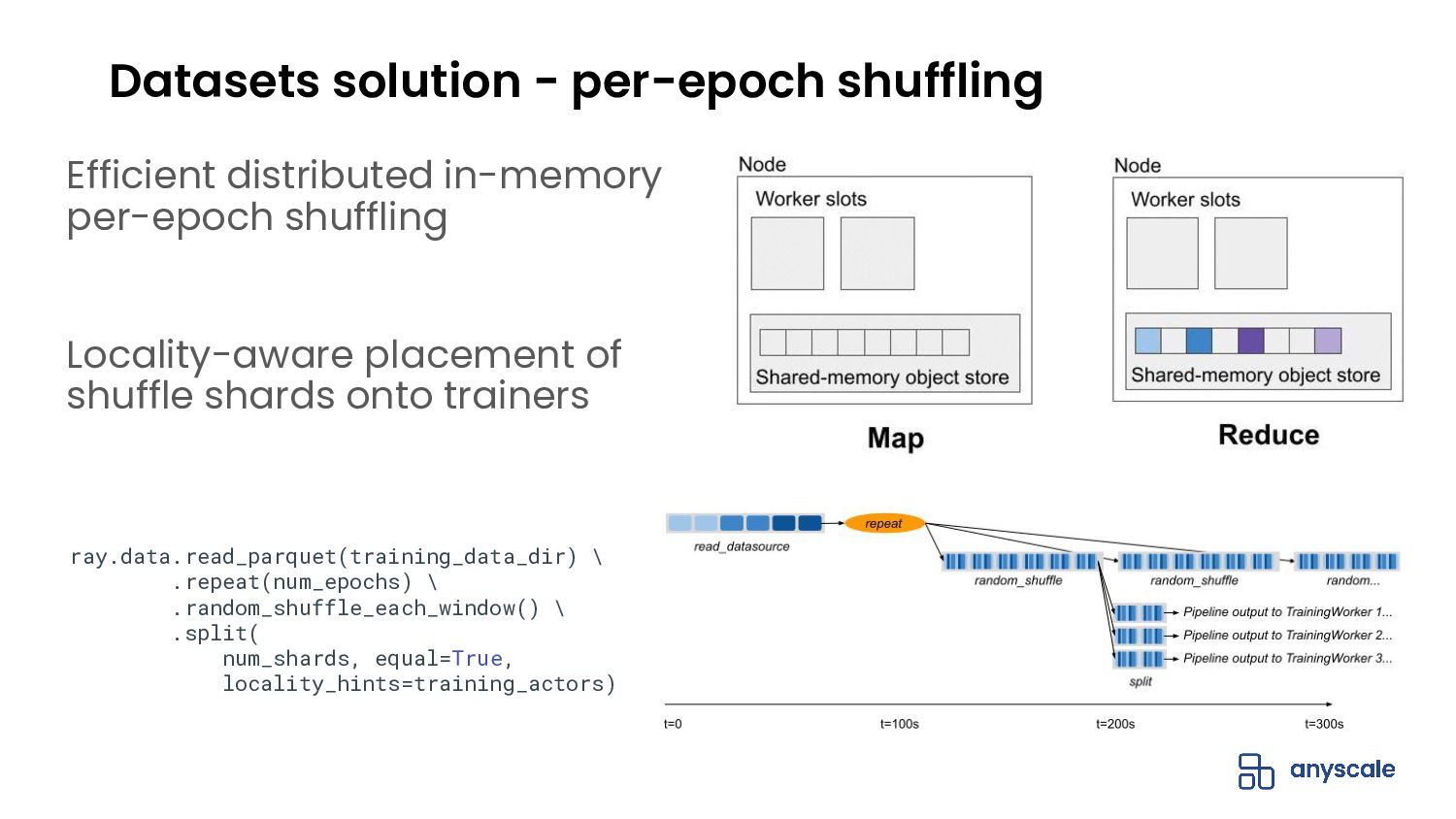{kind=link}
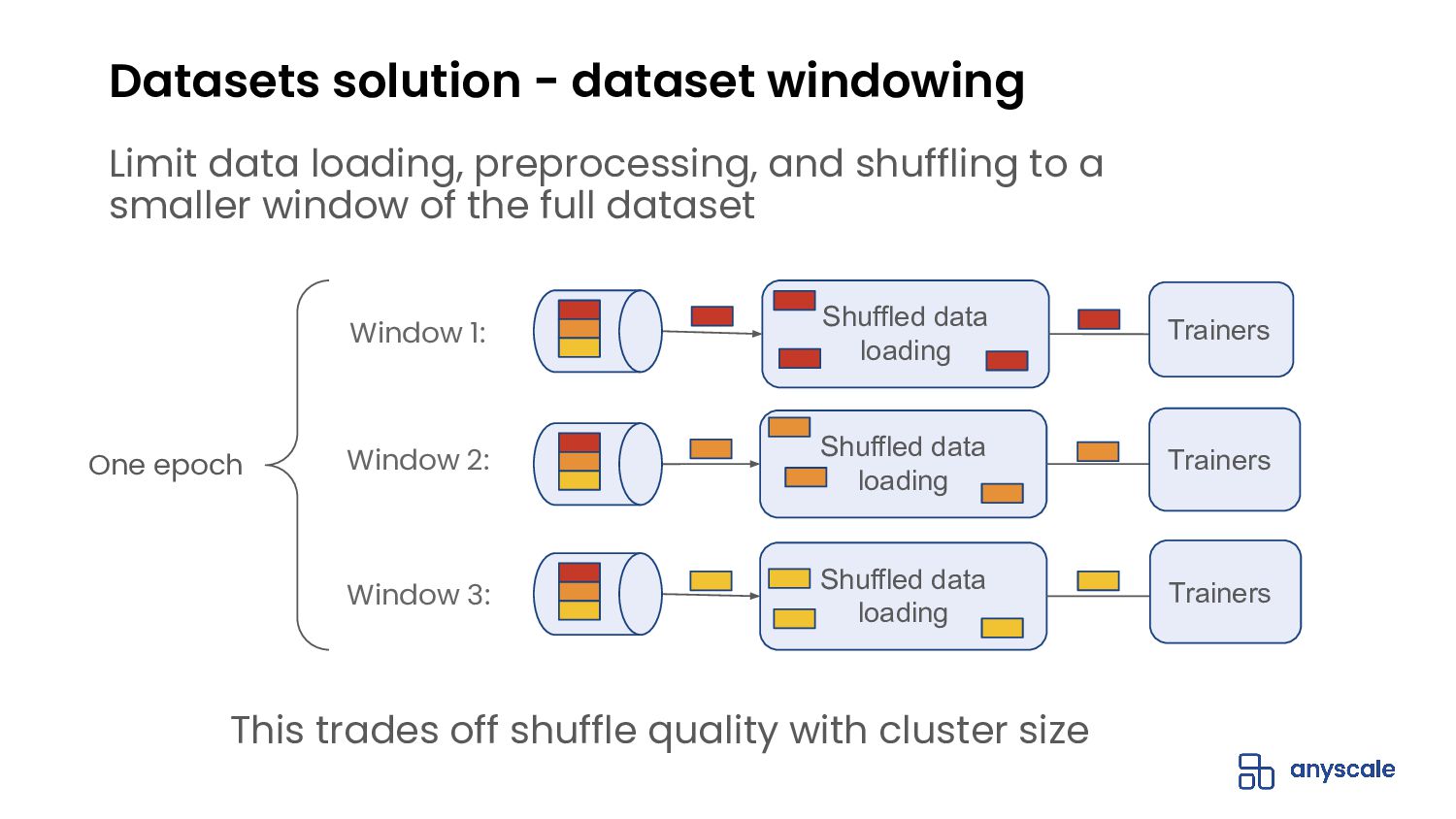{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
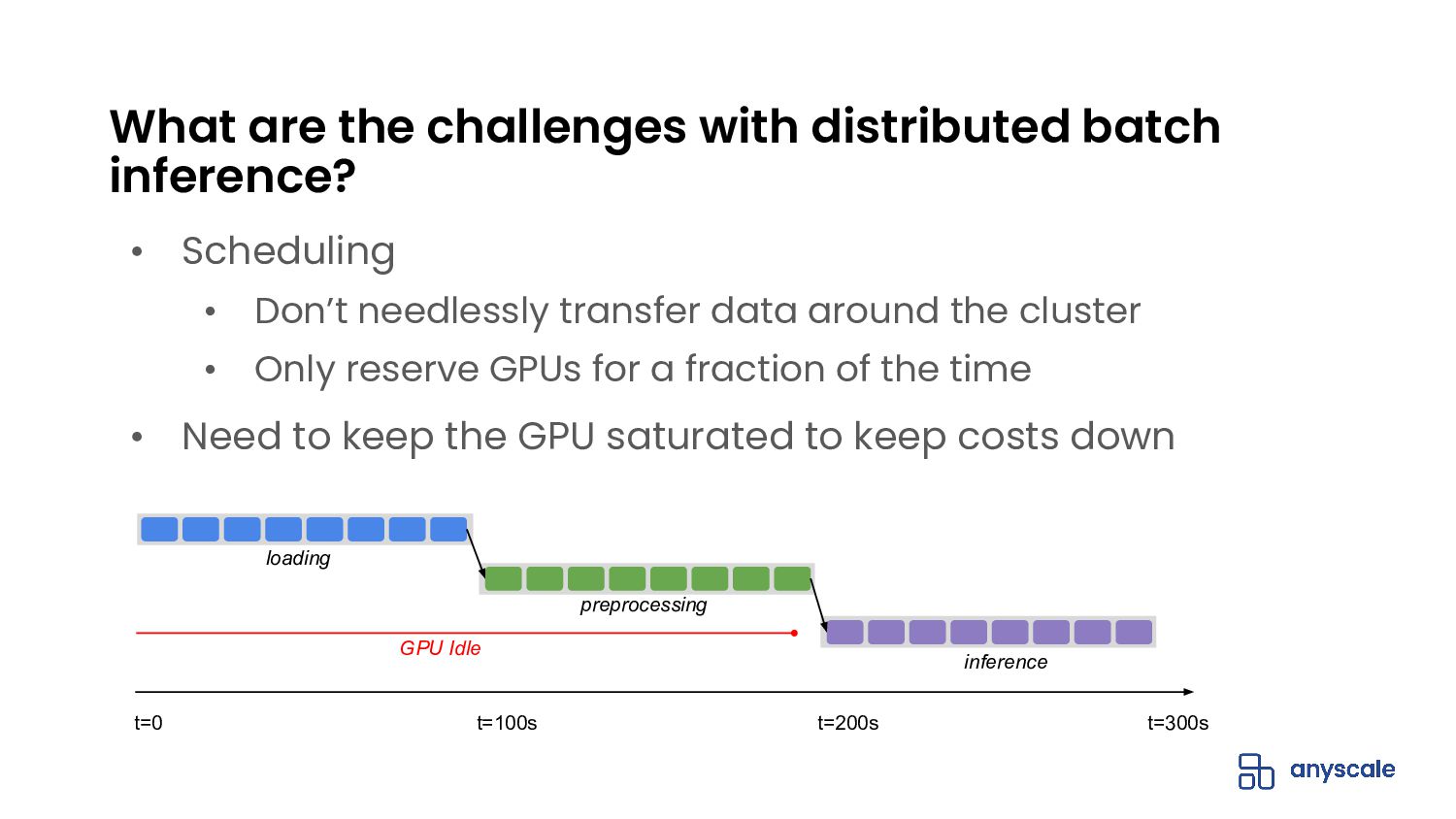{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
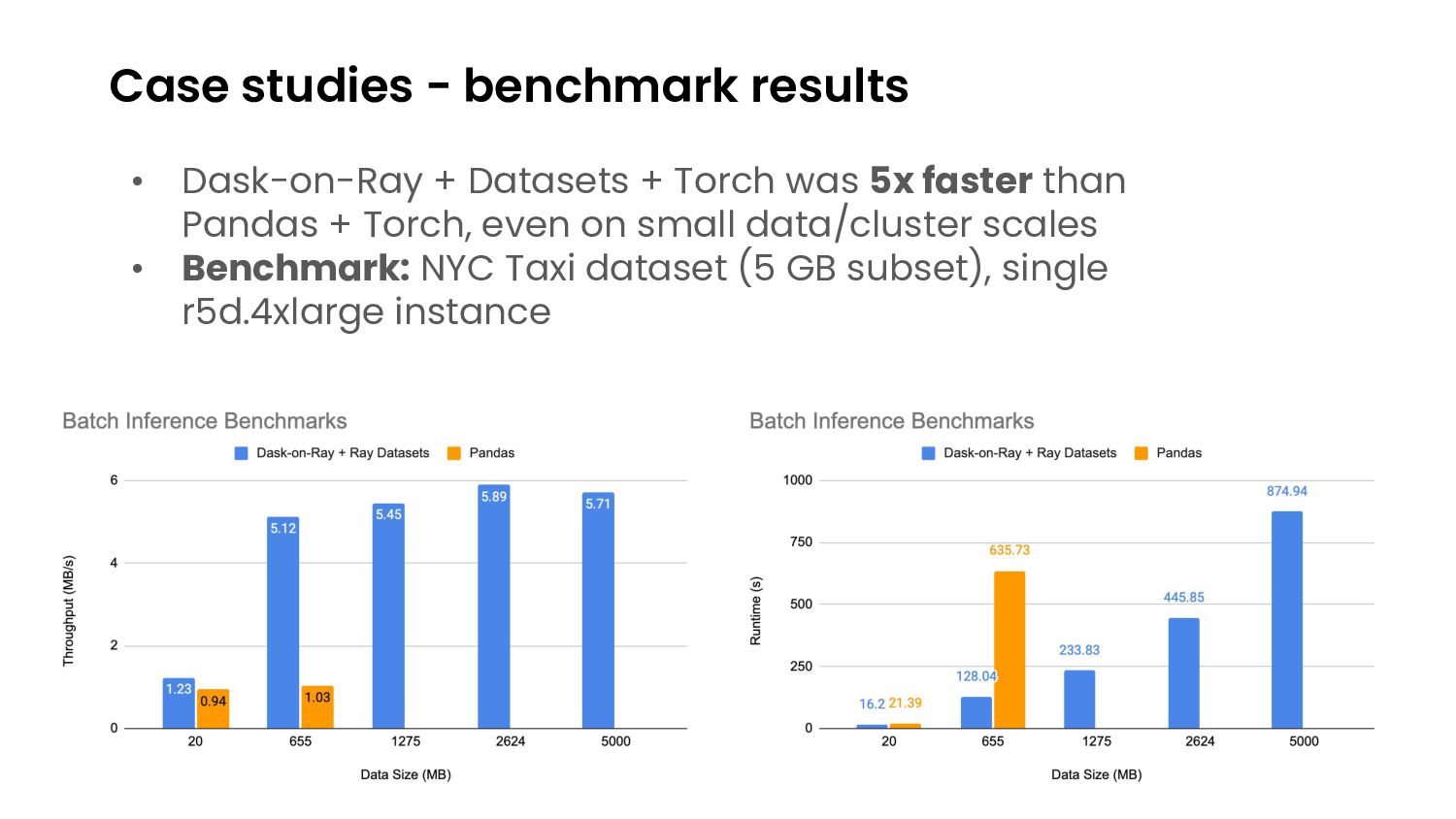{kind=link}
{kind=link}
{kind=link}
{kind=link}