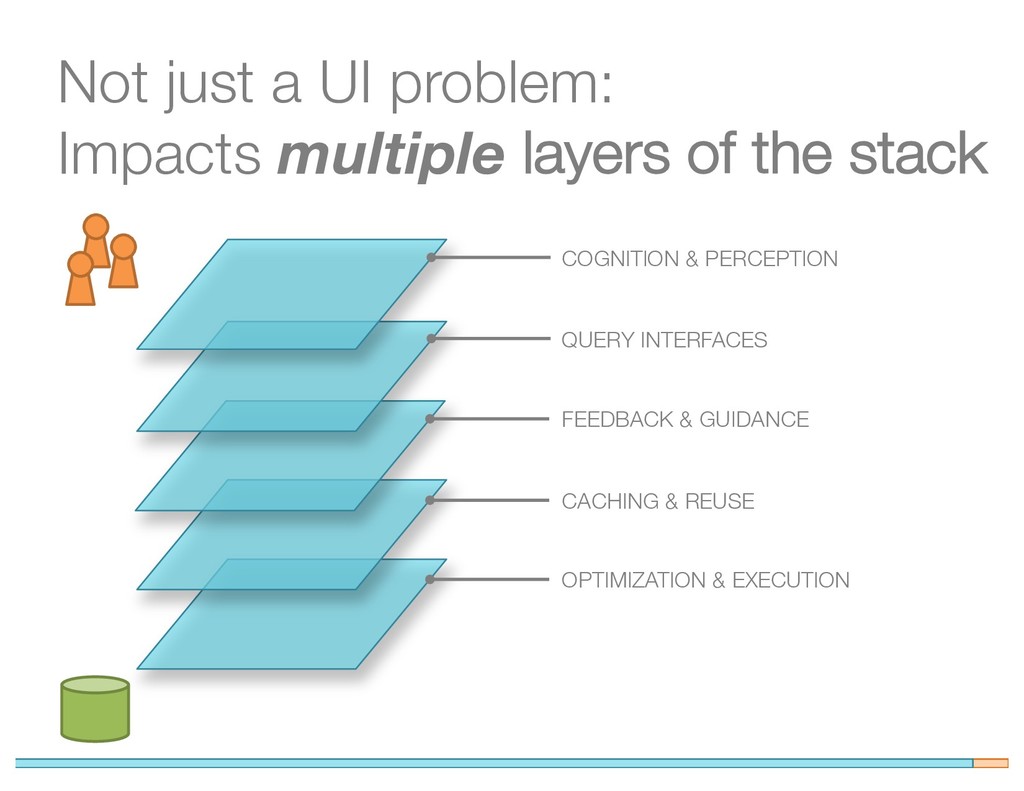
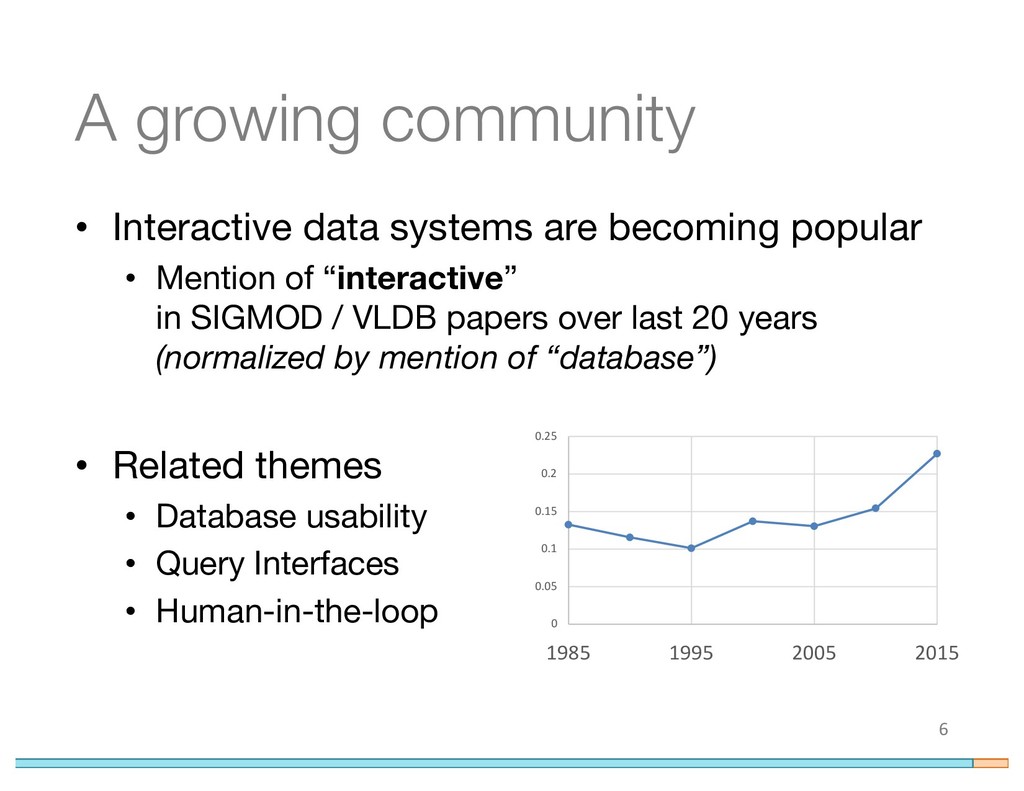
Highly interactive query interfaces have become a popular tool for ad-hoc data analysis and exploration. Compared with traditional systems that are optimized for throughput or batched performance, ad-hoc exploration systems focus more on user-centric interactivity, which poses a new class of performance challenges to the backend. Further, with the advent of new interaction devices (e.g., touch, gesture) and different query interface paradigms (e.g., sliders, maps), maintaining interactive performance becomes even more challenging. Thus, when building and evaluating interactive data systems, there is a clear need to articulate the evaluation space.
In this paper, we describe unique characteristics of interactive workloads for a variety of user input devices and query interfaces. Based on a survey of literature in data interaction, we catalog popular metrics for evaluating such systems, highlight their deficiencies, and propose complementary metrics that allow us to provide a complete picture of interactivity. We motivate the need for behavior-driven optimizations of these interfaces and demonstrate how to analyze and employ user behavior for system enhancements through three scenarios that cover multiple device and interface combinations. Our case studies can inspire guidelines to help system designers design better interactive data systems, and can serve as a benchmark for evaluating systems that use these interfaces.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Some of our attempts Data Tweening [VLDB 17] Perceptually-aware Visualizations](https://files.speakerdeck.com/presentations/eb704941496a4395b34dc1d8d2874a7f/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
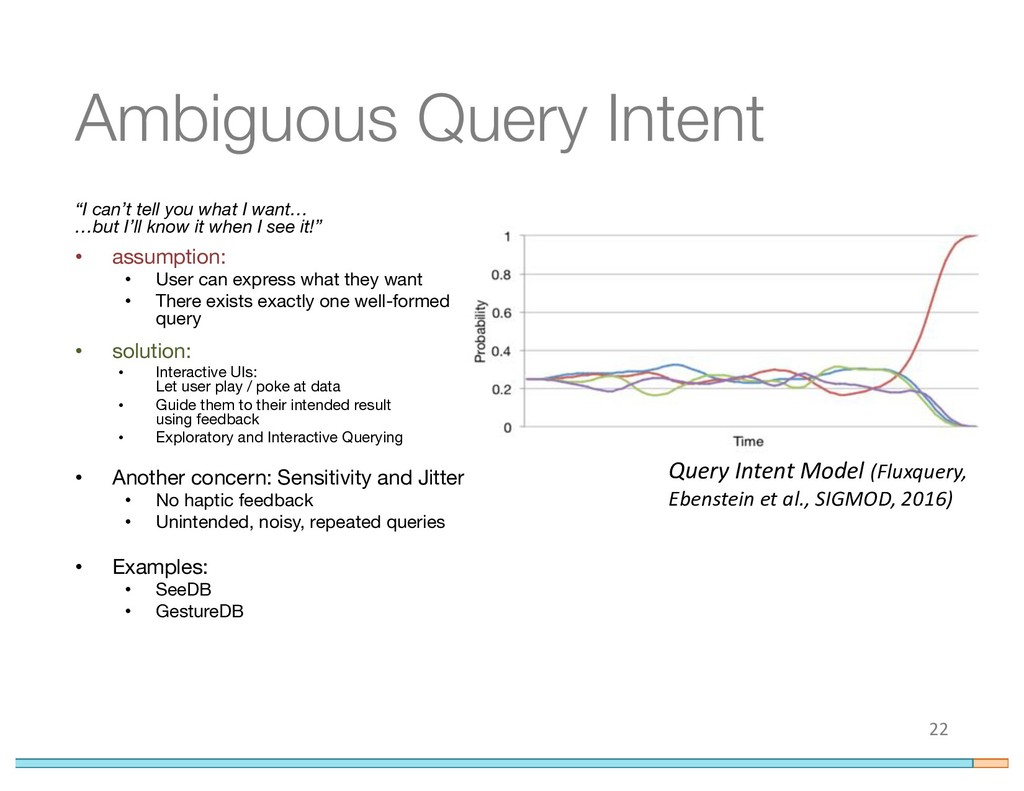{kind=link}
{kind=link}
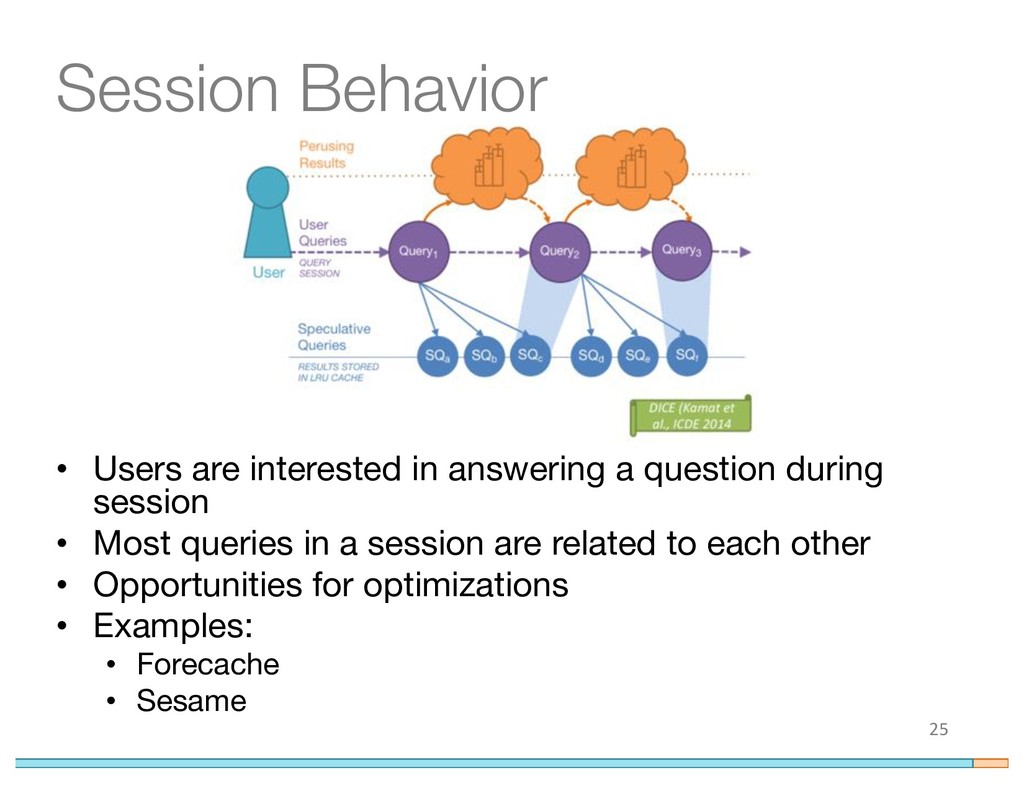{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
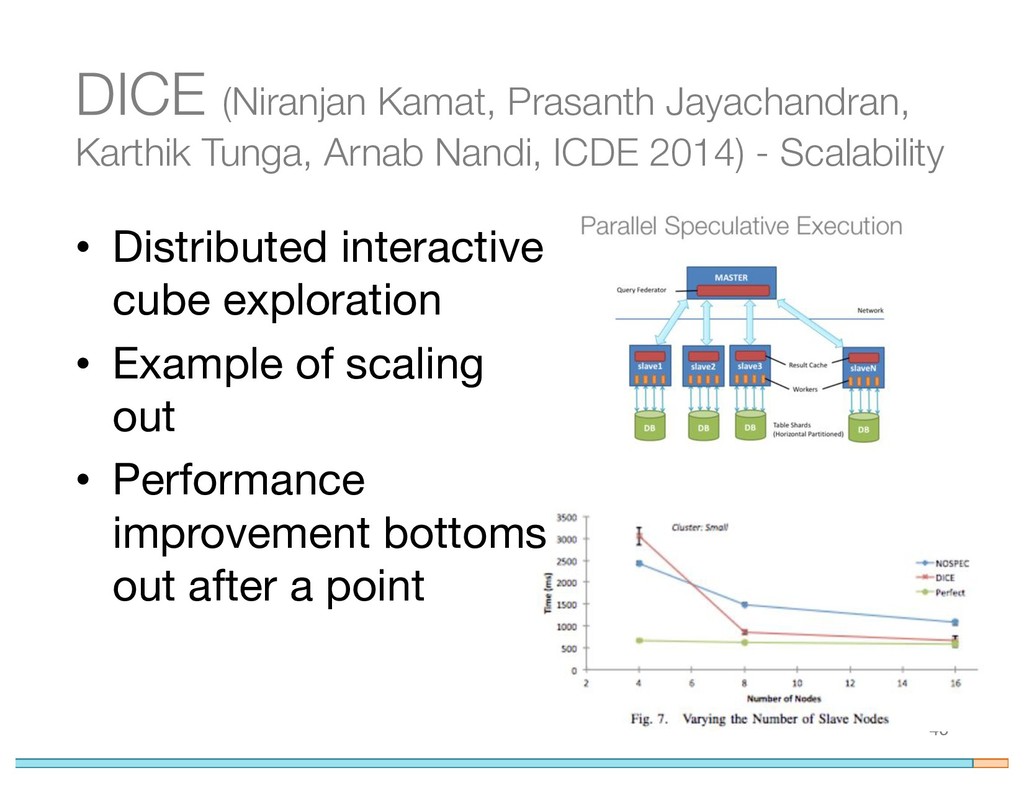{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
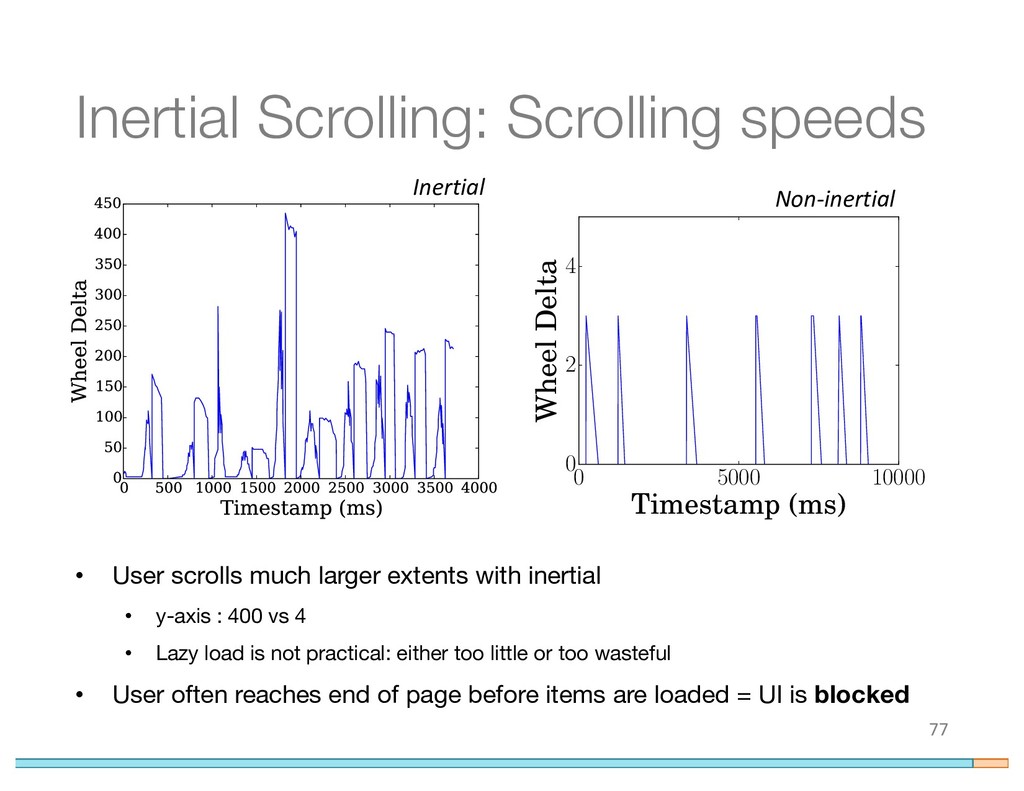{kind=link}
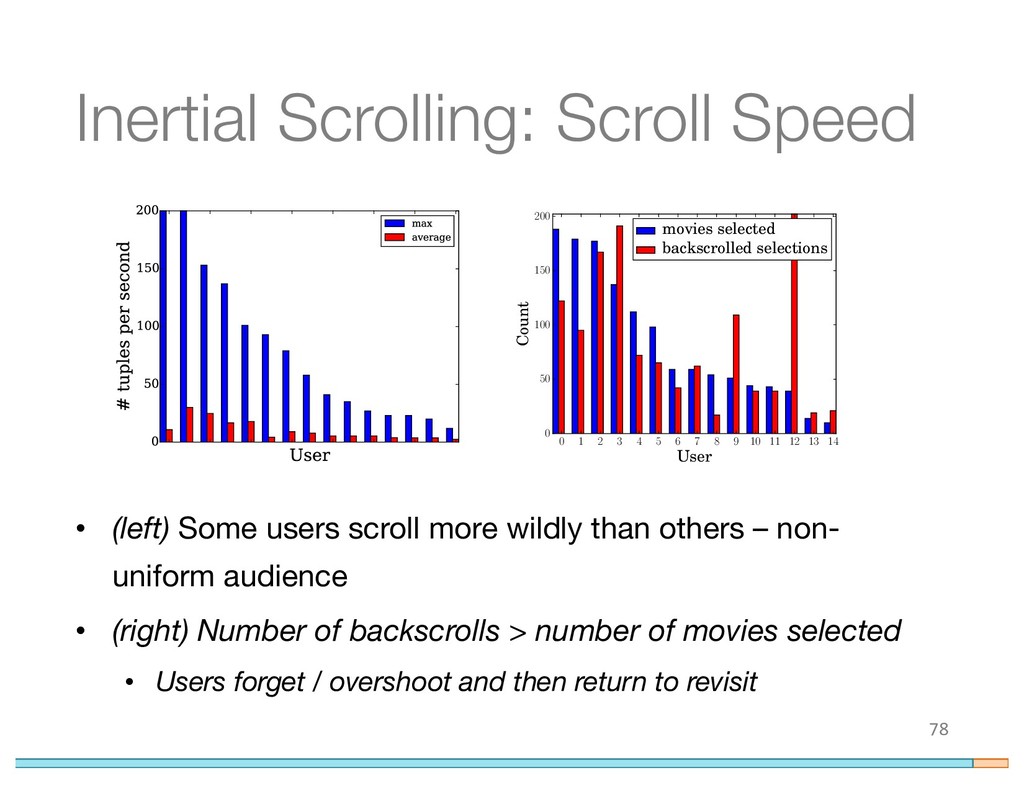{kind=link}
{kind=link}
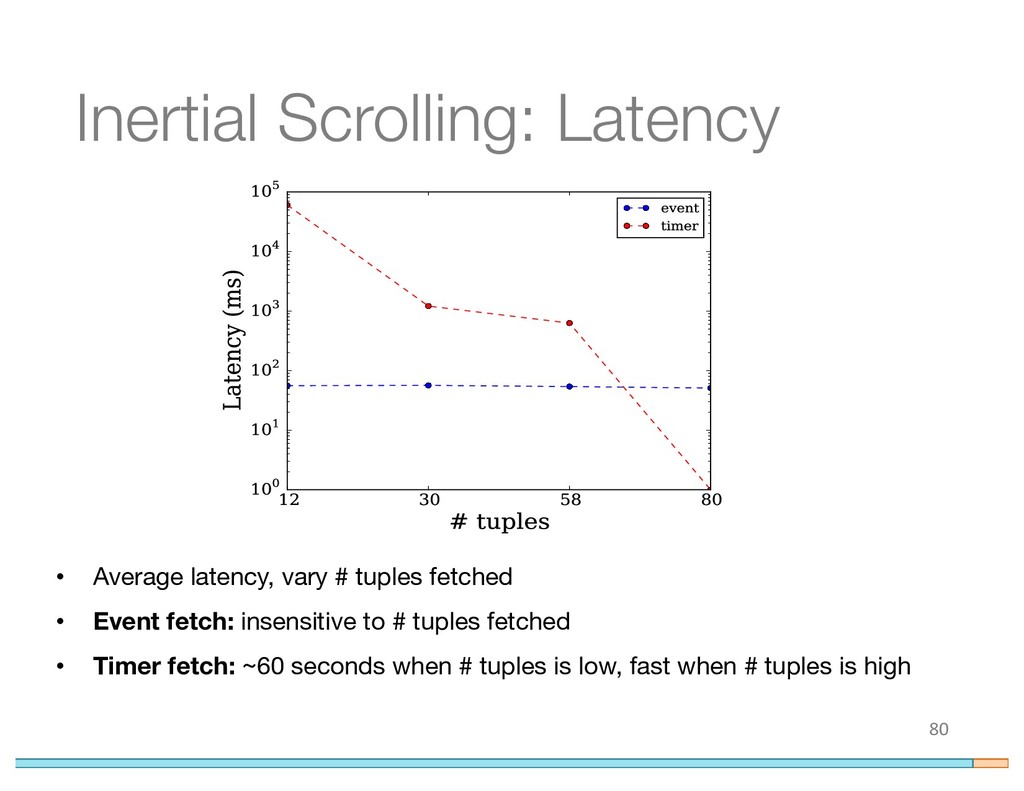{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
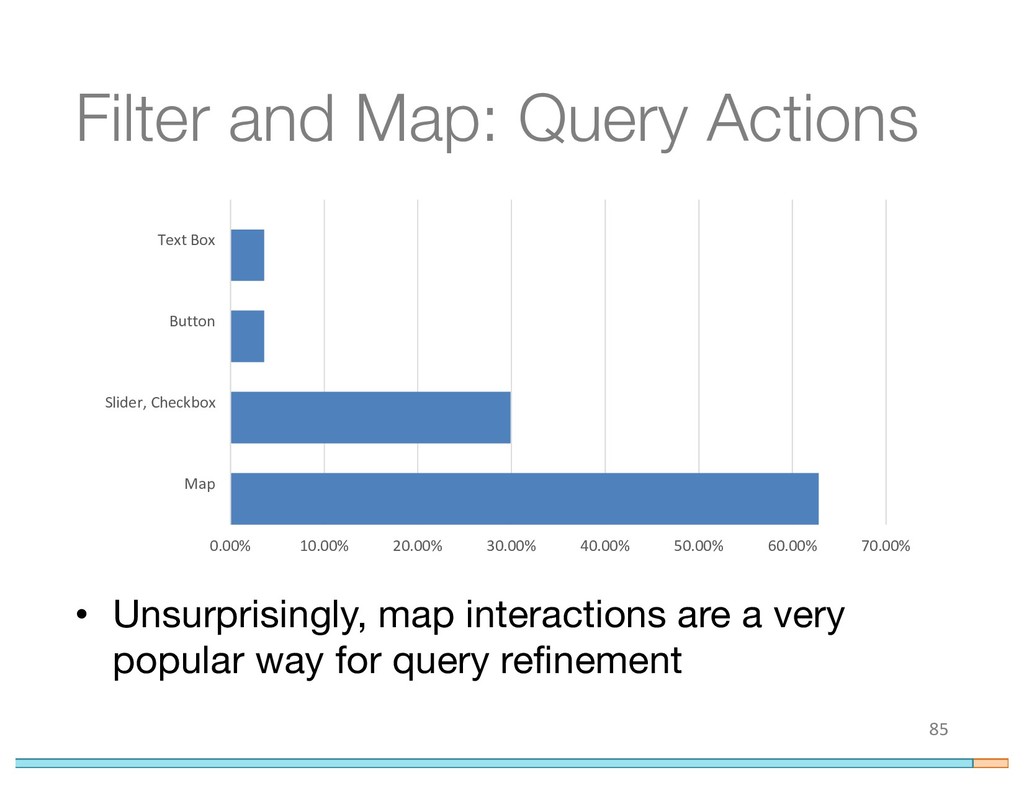{kind=link}
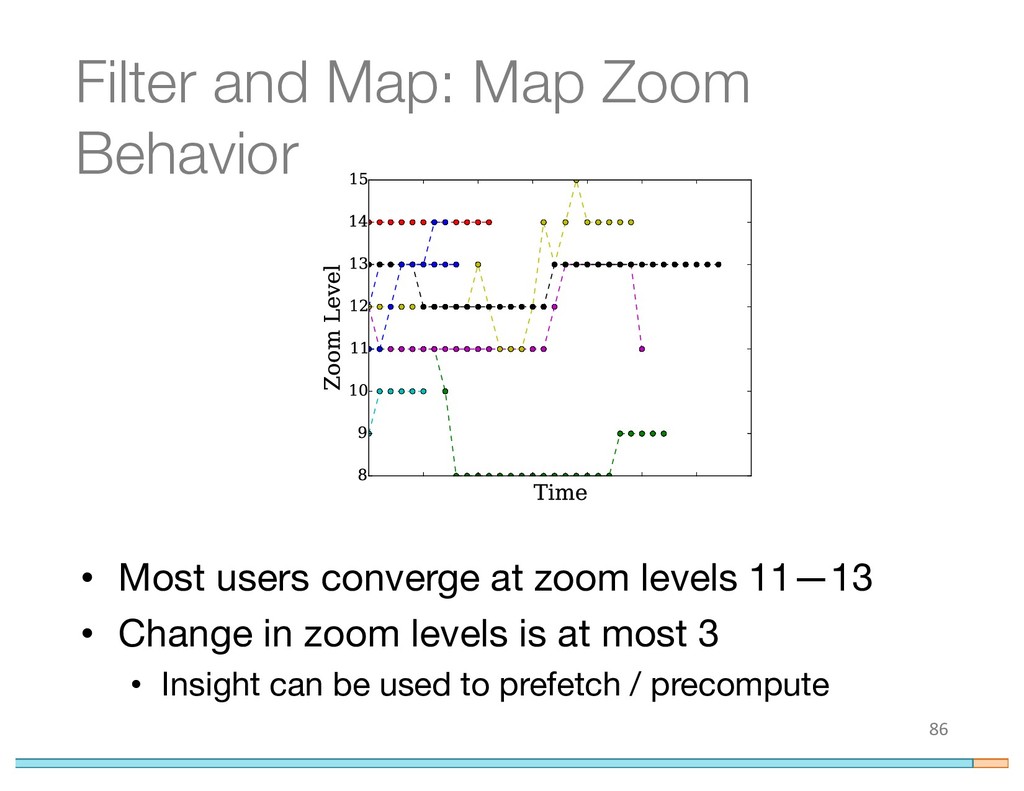{kind=link}
{kind=link}
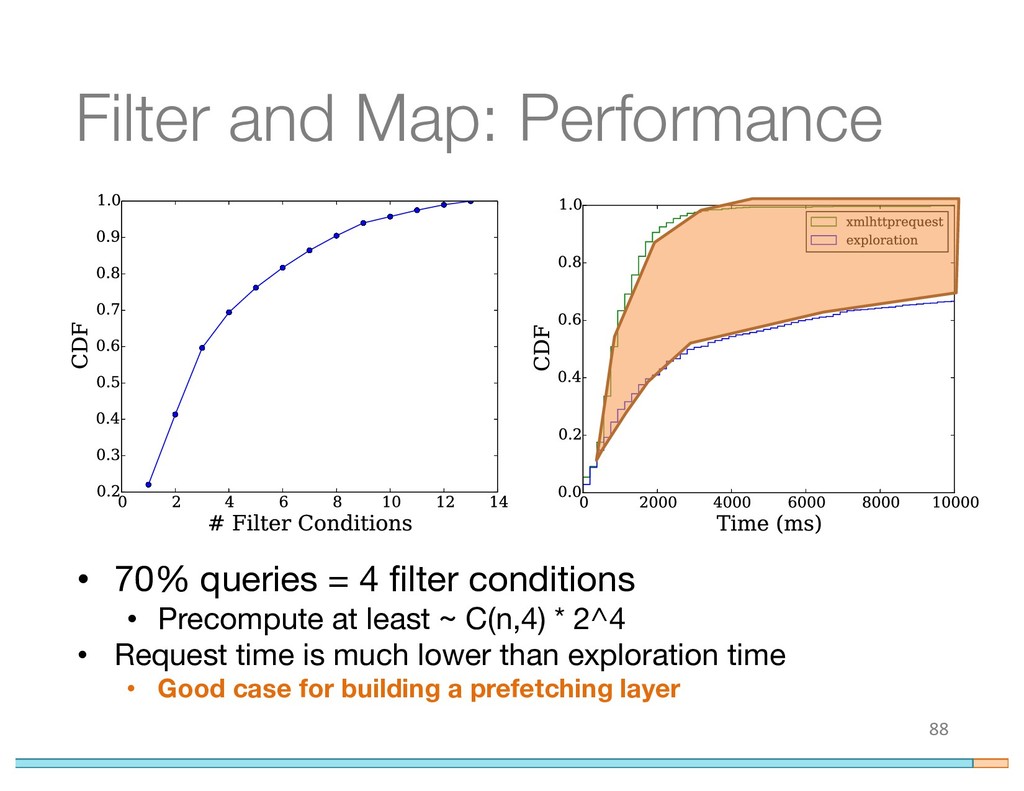{kind=link}
{kind=link}
{kind=link}
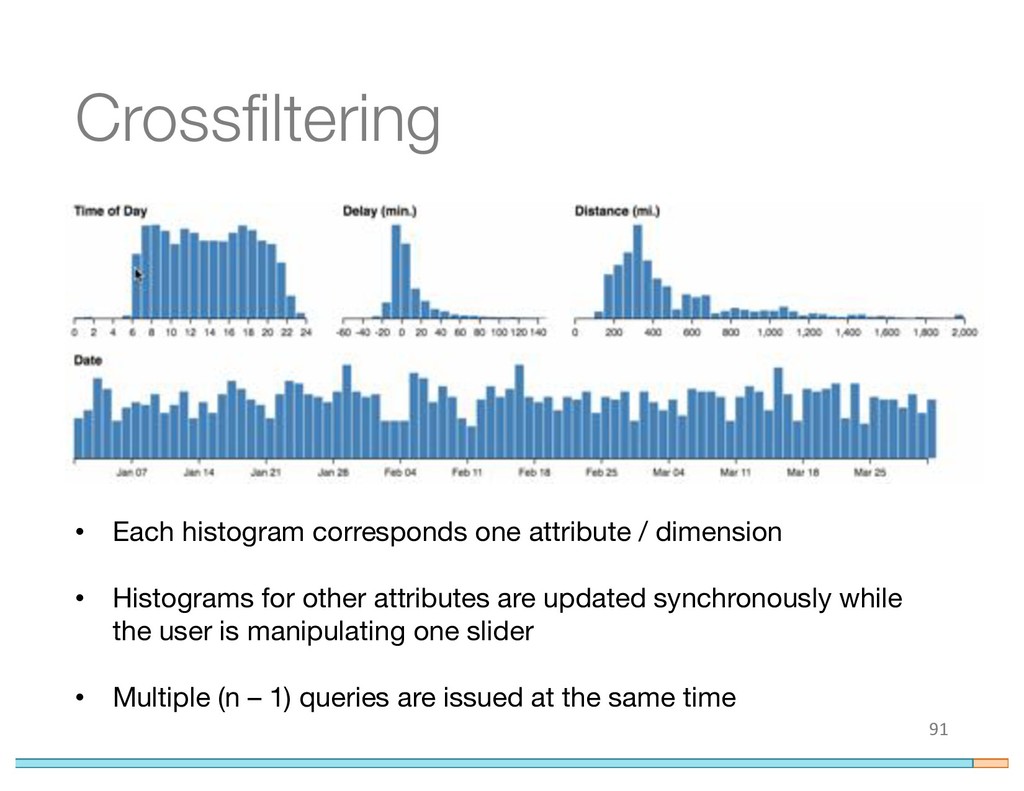{kind=link}
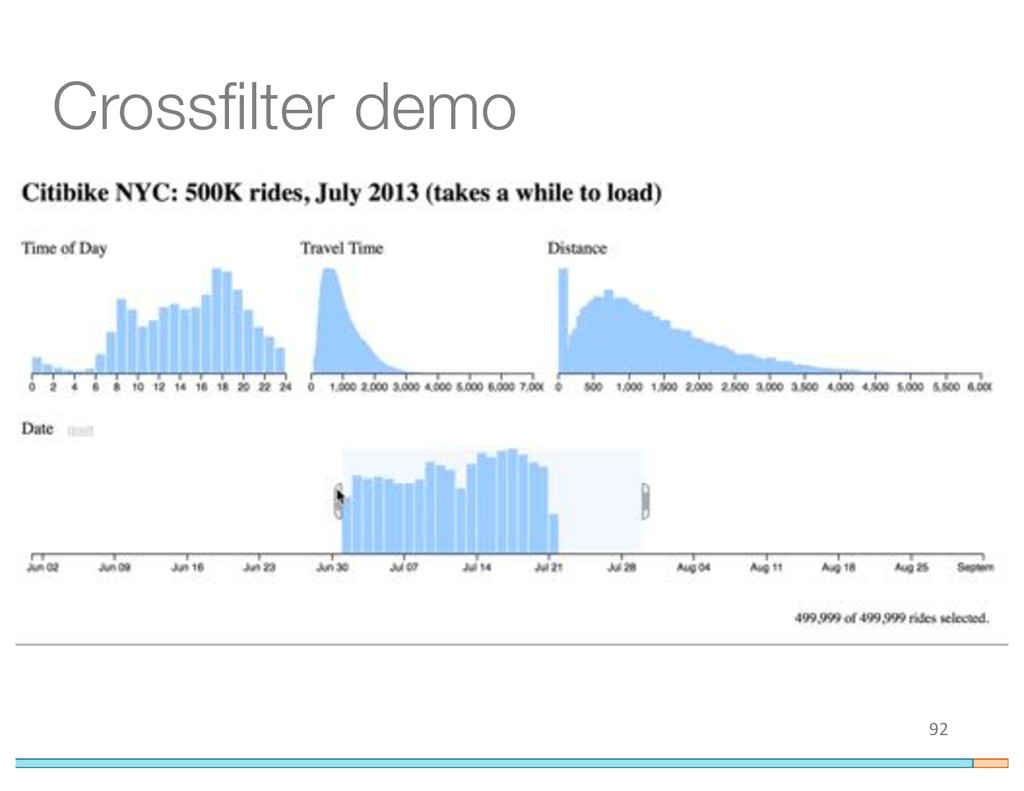{kind=link}
{kind=link}
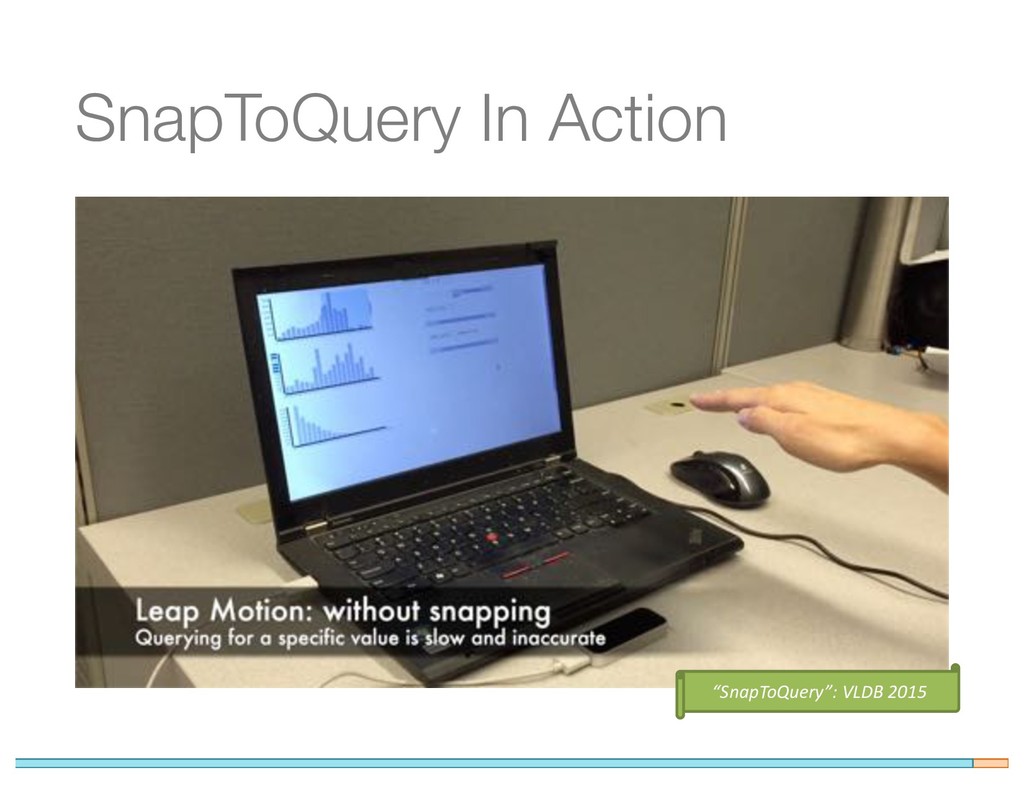{kind=link}
{kind=link}
{kind=link}
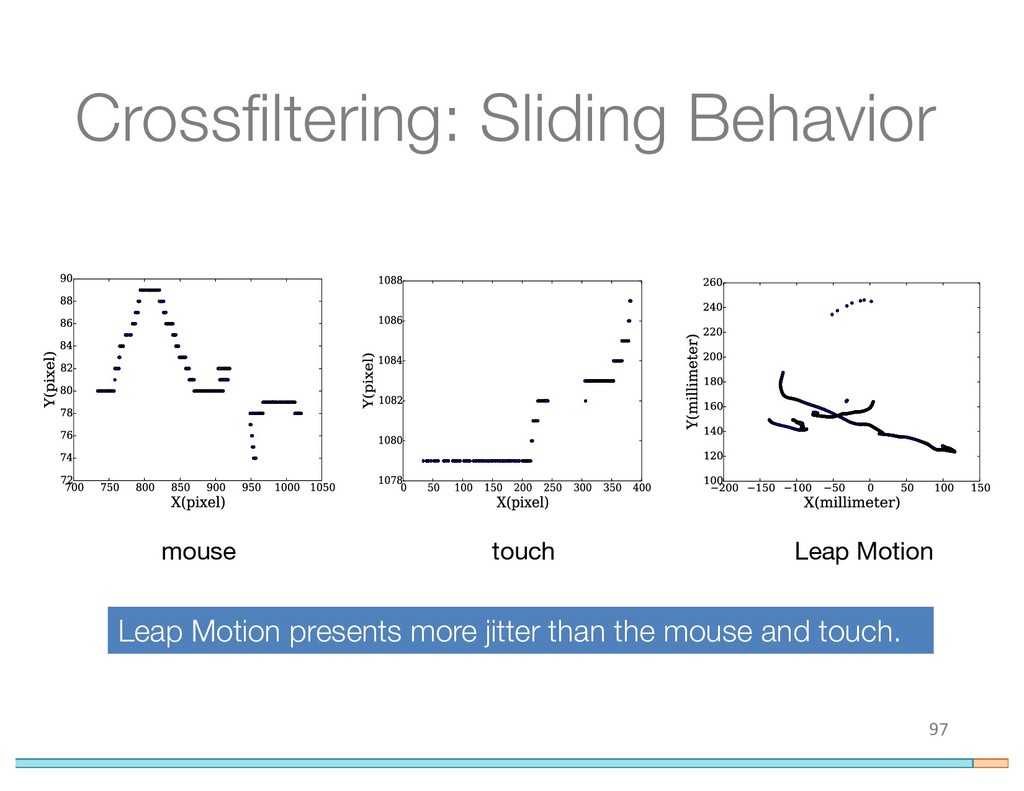{kind=link}
{kind=link}
{kind=link}
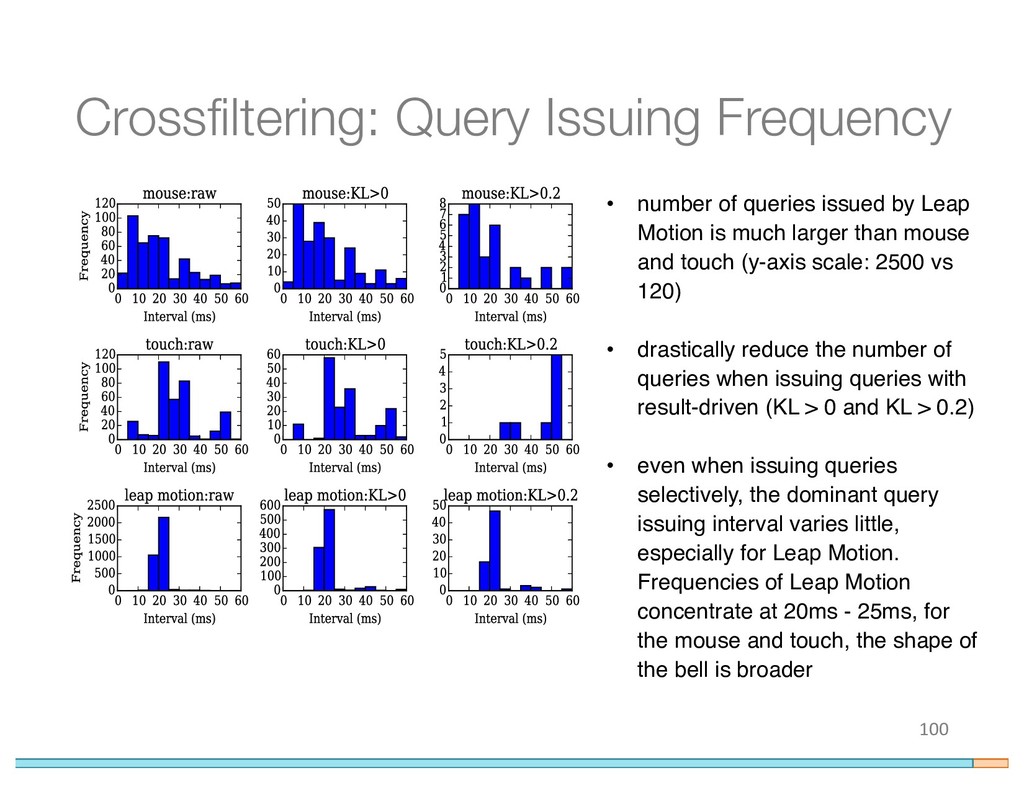{kind=link}
{kind=link}
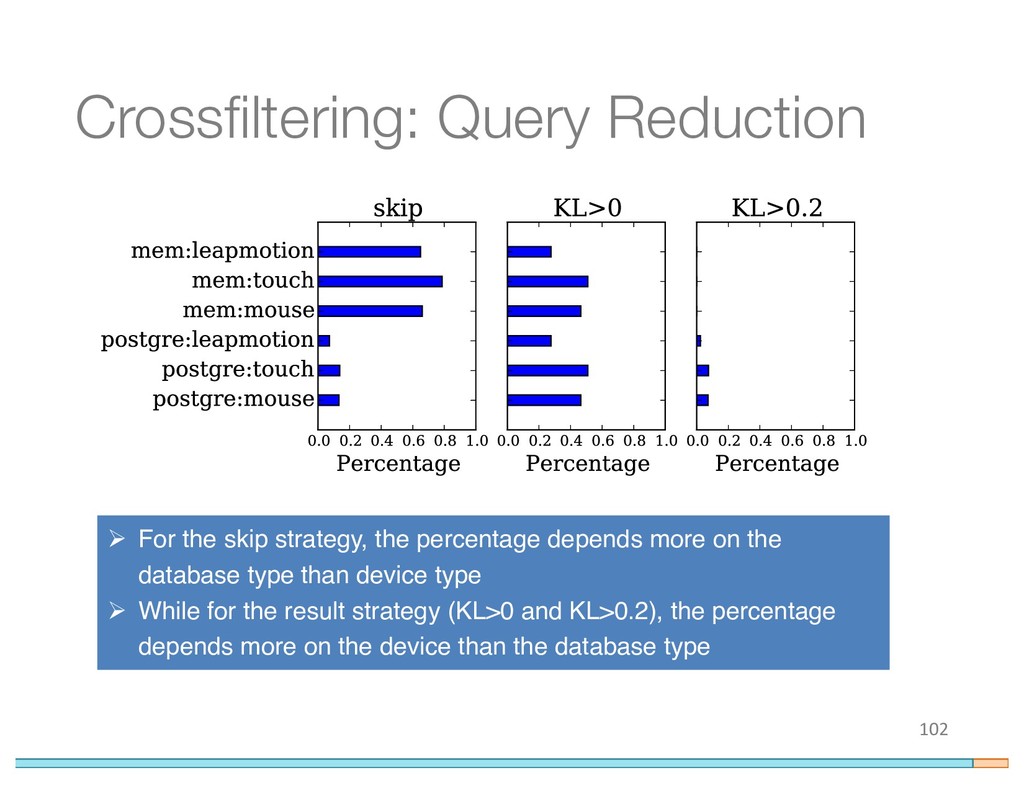{kind=link}
{kind=link}
{kind=link}
{kind=link}
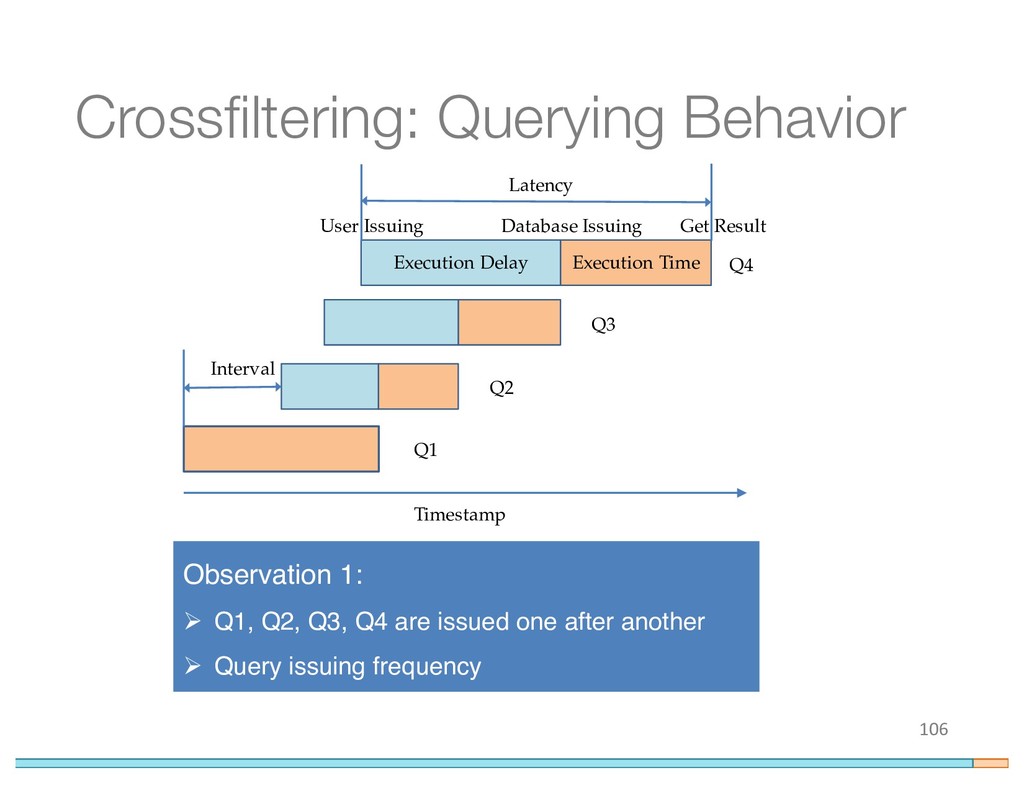{kind=link}
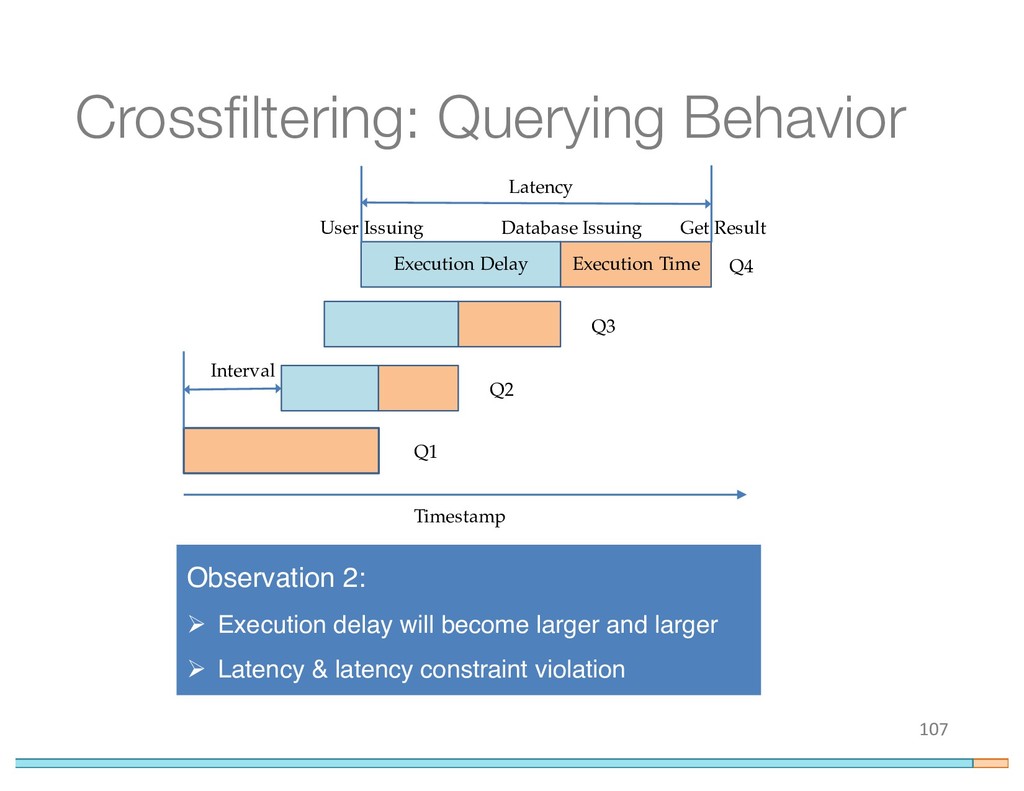{kind=link}
{kind=link}
{kind=link}
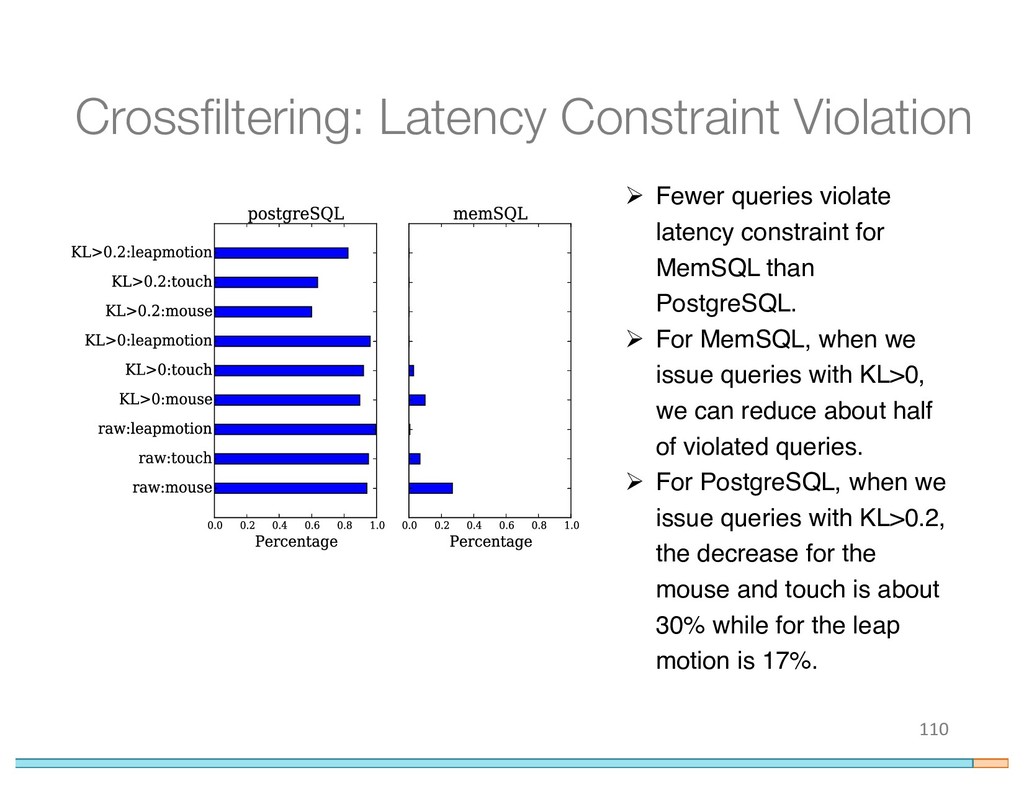{kind=link}
{kind=link}
{kind=link}
{kind=link}
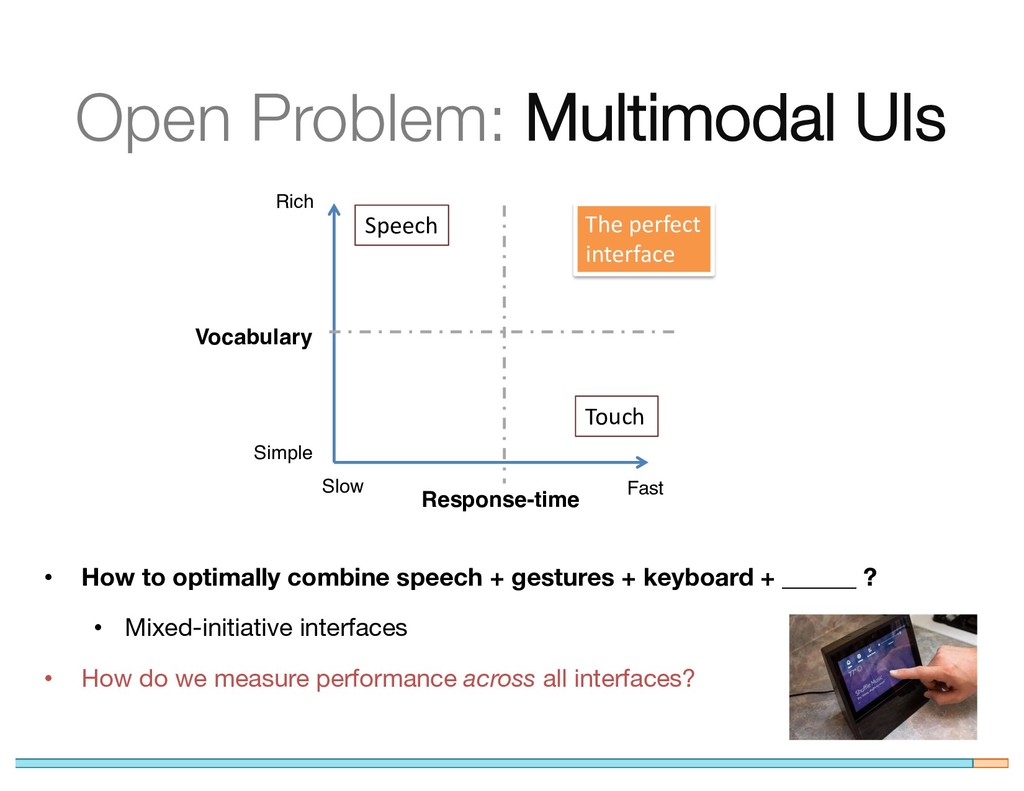{kind=link}
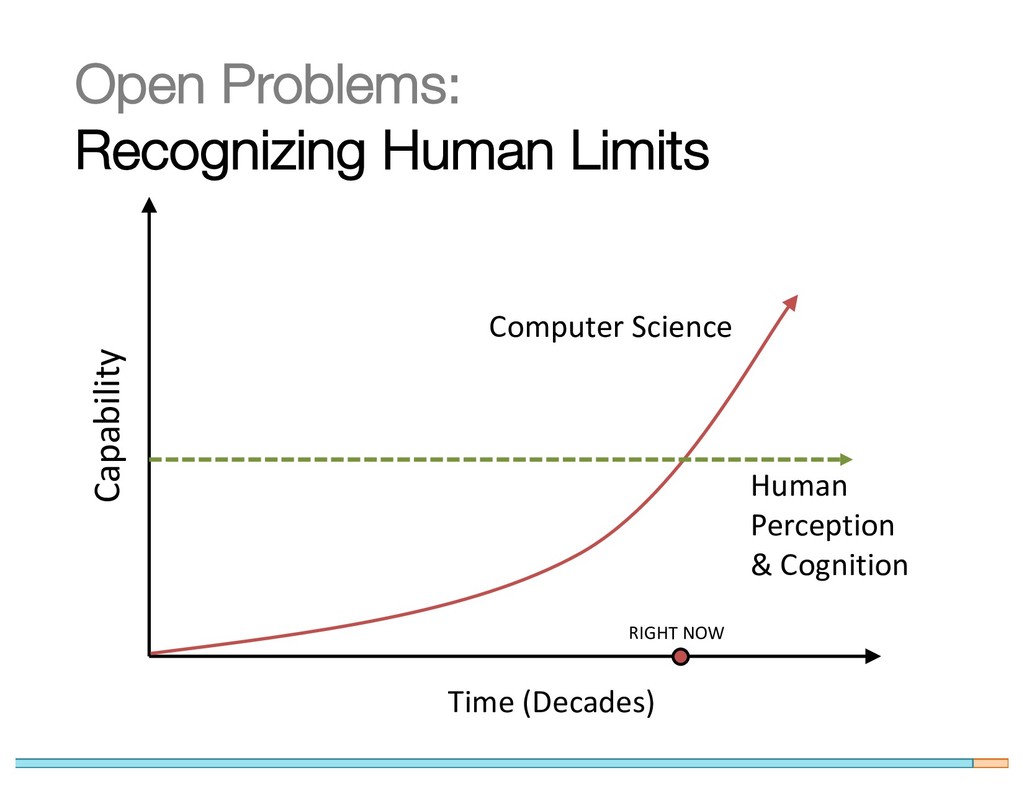{kind=link}
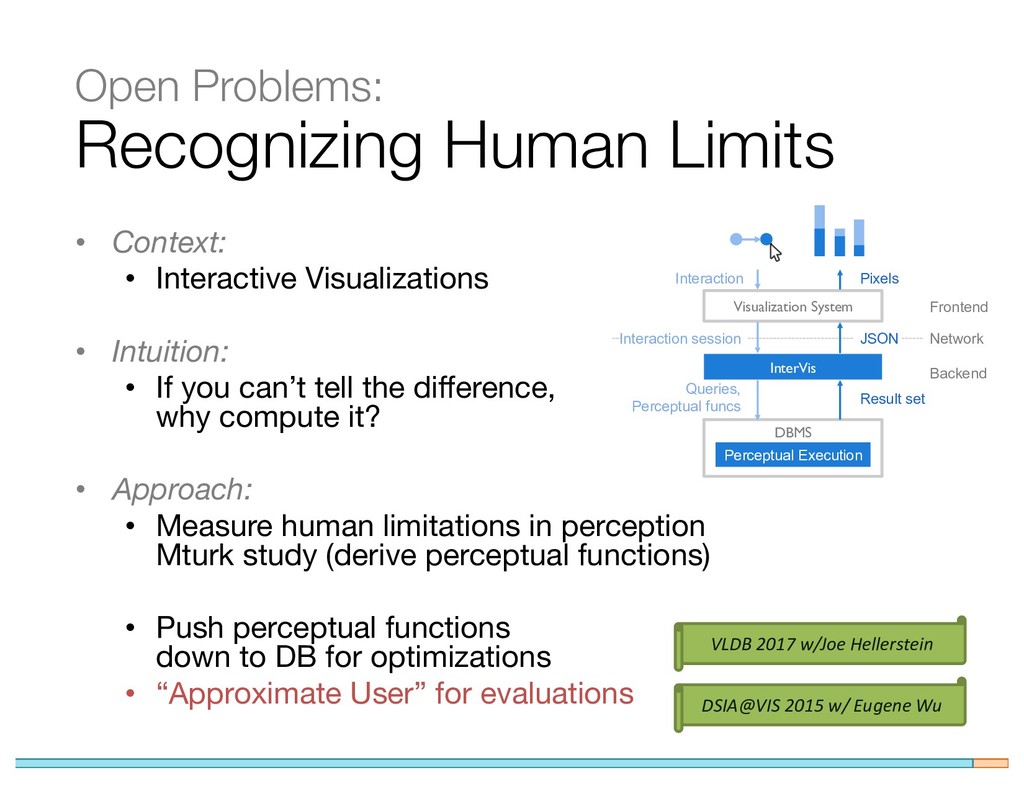{kind=link}
{kind=link}
{kind=link}
{kind=link}