of code on a Sinclair ZX80 in 1984. Over the years, he has been programming in C/C++, Java and C#, and also did quite some database development. Today he is Development Lead at Dynatrace (APM vendor).
some DB development) Introduction (1989): Phoenix DB (Atari ST, storage: 3.5” floppy) Learning (1992 - 1996): University (80% ER modelling, 20% SQL, 0% DB internals *sighs*), Contract work Oracle 5 (DOS), MS Access, 4th Dimension Professional Phase 1 (1997 - 2001, still learning): Internet Banking, Business Banking Oracle 7 (DEC Alpha), Sybase Professional Phase 2 (2002 - today, still learning): Hospital Information Systems, Finance/Accounting Software, APM Oracle 8/9 (Linux), SQL Server 2000/2005/2008/2012, Postgres Most concepts presented here are vendor-independent, but with "SQL Server flavour"
Relational Model of Data for Large Shared Data Banks". 1974: Raymond Boyce and Donald Chamberlin (IBM) write "SEQUEL: A Structured English Query Language". 1974 - 1977: IBM implements System/R, UBC creates Ingres (later: Postgres), the first two RDBMS. 1976: Larry Ellison founds Oracle. Oracle's approach is based on Codd's IBM papers. 1977: Oracle 1 runs on PDP-11, using 128k memory (never officially released). 1978: IBM adds SQL to System/R. System/R eventually morphs into DB2. 1979: Oracle releases the first commercially available SQL database.
SQL Server, row data on local client, 256 bytes per row, choose your table design, provider, API. Now guess! On a highly-tuned setup (SSIS, split load / parallelization, special hw): 1,000,000s of rows / sec On your off-the shelf notebook (bulk insert, heap table or suited clustered index): 10,000s of rows / sec Worst case I ever encountered on a production system (thousands of roundtrips for thousands rows within one transaction, poor clustered index choice and table design): 15 rows / sec
execute. Table design given (no major flaws) Original query: Joined every table that appears in the where clause, which led to cartesian product (lots of duplicates on to-N associations); applied "distinct" to get rid of duplicates again in resultset Datatype conversion (e.g. datetime => varchar), prevented index application Invoked non-deterministic user defined function on every row (results can't be cached) Did not take advantage of existing indices (although possible) Refactored query: Replaced join duplicates / distinct by subqueries, ensured index seeks, fixed non- deterministic UDFs Query now finishes in 200 ms, speedup 5,400-fold
In many (trivial) cases: yes, but they can backfire on write operations. Indices speed up data retrieval (no need to scan every row) at the cost of additional writes and storage space. Also provide ordering, and can help to prevent locking. Implemented as B-Trees (self-balanced, logarithmic access time), nodes usually match operating system I/O page size (e.g. 8k)
where clauses and applied in group-by, order-by and join expressions, which contain selective data (e.g. there is no sense in indexing a "gender" column with two possible values), or which are used for referential integrity checks. Consider creating composite indices for columns queried together. The index column order is decisive for what can be looked up, e.g. phonebook: idx(lastname, firstname) will allow seeking by "lastname = ... AND firstname = ...", by "lastname = ...", but not by "firstname = ...". Multiple single-column indices in contrast require multiple separate lookups and merging the results. Make your index unique if that fits your data model. This helps to furthermore optimize query execution. Indices should be kept small. Indexing a larger varchar column is probably not a good idea.
in nodes to avoid frequent node splits), typically between 70% (high insert rate) and 90% (low insert rate). Fill factors are applied on index rebuilds. Index rebuilds must be scheduled by the DBA. Each table has zero or one clustered index definition (by default: the primary key). The clustered index is a b-tree that contains the actual row data in its leaves. If there is no clustered index, we talk about a heap table where rows are simply appended at the end.
on an index over and over during a query, it may decide to do one index scan instead of many index seeks. Index seeks can not be applied on type <> 3 -- negative search lastname like '%...' -- '%' prepended lastname + ' ' + firstname = '...' -- concatenation -- col expr idx helps CAST(FLOOR(CAST(date AS FLOAT)) AS DATETIME) > ... -- function / cast An index contains the clustered index columns for quick lookup of actual data in clustered index. So this is one indirection, except for... ... if an index contains all columns the query needs, the clustered index is not required for retrieval.
must be written on inserts, updates, deletes, this can cost dearly. The choice of the clustered index is an essential factor for performance, as too many node splits should be prevented, esp. on huge bulk inserts and updates. Autoinc values or a growing date are good choices for clustered indices as they only fill up the final leaf. Guids are bad as they spread all over the index. SQL Server introduced newsequentialid() for creating sequential Guids and preventing excessive node splitting. Each single row insert leads to a clustered index insert and N non-clustered index inserts. Only create indices that are absolutely necessary for query performance. Prefer one composite index to multiple single-columns indices where applicable. Superfast insert approach: Insert into a temporary heap table first (no indices, not even clustered => always appended at the end), then issue an "insert-into-select" from the heap table into the target table, ordering by target table clustered index.
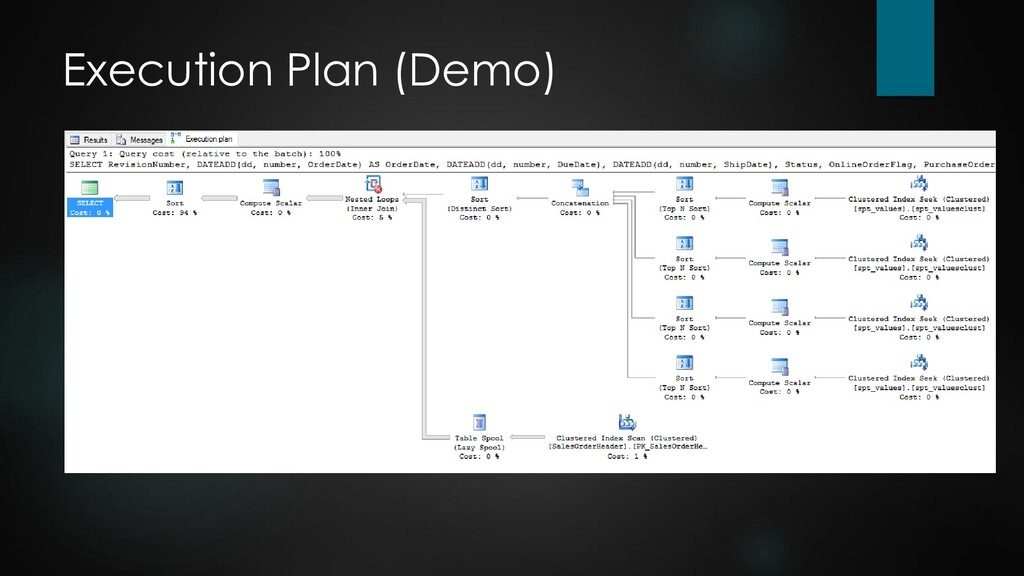
to-N associations where not required for the resultset. Often joins can be replaced by subqueries, e.g.: where exists (select 1 from ...) Prevent the N+1 query problem on to-N associations. Typically caused by applying OR-mappers the wrong way, but sometimes even implemented explicitly. Never run a query within a loop. Keep queries simple. If a query is overly complicated, chances are its execution is complicated too. Sometimes it's advisable to not pack everything into one single query, but issue two or three consecutive queries. One possibility to pass data between queries is by using temp tables. Have a look at the execution plan and verify it looks as expected, e.g. how indices are applied. Hint: an "index scan" is not the same as an "index seek".
On an expression like this (selectiveness of a parameter varies heavily) reusing the same plan can kill performance: where (lastname = @lastname or @lastname is null) Query optimizer uses table statistics to choose an execution plan. Table statistics contain metadata on column value distribution, etc. Not every column has statistic data by default, but indices do. Statistic updates usually happen during index rebuild, or can be scheduled by the DBA. Go sure table statistics are up to date.
of work performed against a database, and treated in a coherent and reliable way independent of other transactions. There is always a transaction running. Statements without having an explicit transaction are executed within a "single-statement" transaction. ACID is a set of properties that guarantee that database transactions are processed reliably. Locks are a means to implement ACID. Different operations require different kinds of locks (simplified: shared (read), update (potential write), exclusive (write)). They are acquired and released depending on the isolation level (serializable, repeated read, read committed, read uncommitted), and only granted if the current lock state allows for it. Otherwise the execution blocks until the lock can be obtained. Locks are applied on a row-, page- or table-level, and on indices.
as this reduces lock contention. Always commit or rollback transactions immediately. Never wait for external input (worst case: waiting for user interaction). Ensure that indices are being used. An index seek is more likely to prevent locking (row locks can be bypassed, and index locks have much less contention). Statements can provide specific lock hints (e.g. "with nolock") in case the default locking behaviour can be mitigated. As far as possible, put queries at the beginning and inserts/updates/deletes at the end. Start with the least congested tables, and end with the most congested ones. Deadlock prevention: Try to access resources in the same order. DBs can detect deadlocks, and will choose one deadlock victim transaction for rollback. The DB keeps a transaction log for rollbacks, handling ungraceful shutdowns and incremental backups. The transaction log should be on a dedicated physical disk (separate from data files), with an optimized setup.
for speed, e.g. for complex join constructs on huge tables and/or a lot of aggregated data. Radical? But what if the DB would guarantee data consistency on such de- normalized tables? Actually that functionality exists: Indexed Views (Materialized Views) to the rescue! By creating a unique clustered index on a view, the view gets "materialized", having its flat data redundantly stored to the DB. One can then add more indices to the view. Modifications made to base tables trigger modifications in the indexed view. This leads to a similar drawback as with indices: Indexed views are fast for queries, but come at a performance penalty for write operations, and require additional storage space. Hint: Put an index on the base tables' primary key columns on the indexed view for quick lookup on updates and deletes.
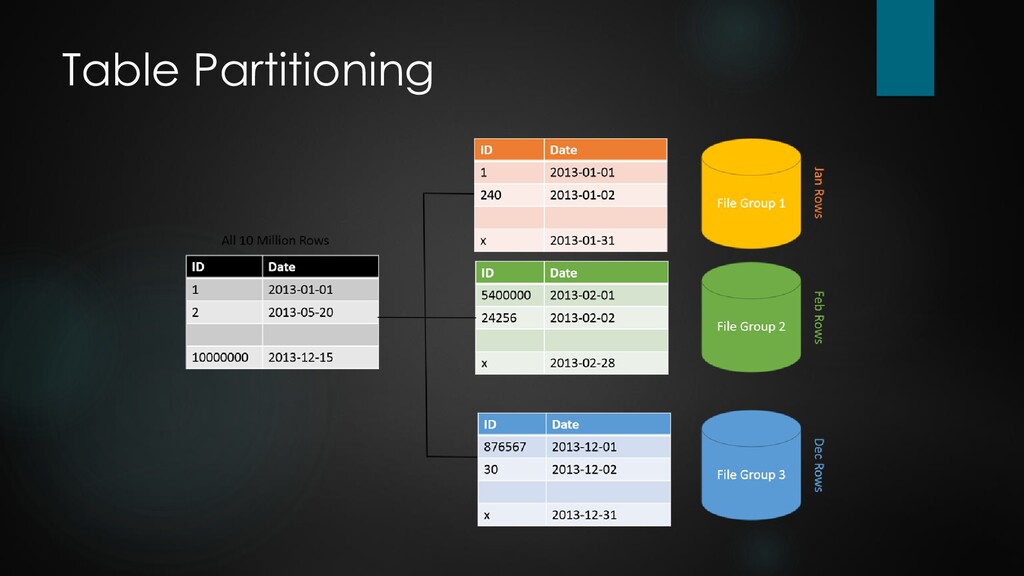
be spread across multiple nodes / filegroups / disks. This allows more parallel processing and improves I/O performance. The partitioned table is treated as a single logical entity when queries or updates are performed. A common approach is to use an autoinc primary key or a growing date column as partition criteria. This often helps to have read and write operations occur on different data ranges, hence different partitions. Maintenance operations like index rebuilds or purging old data are also faster when running on a per-partition basis. Only makes sense for really large tables with certain data growth, and where queries are of a kind to benefit from partitioning.
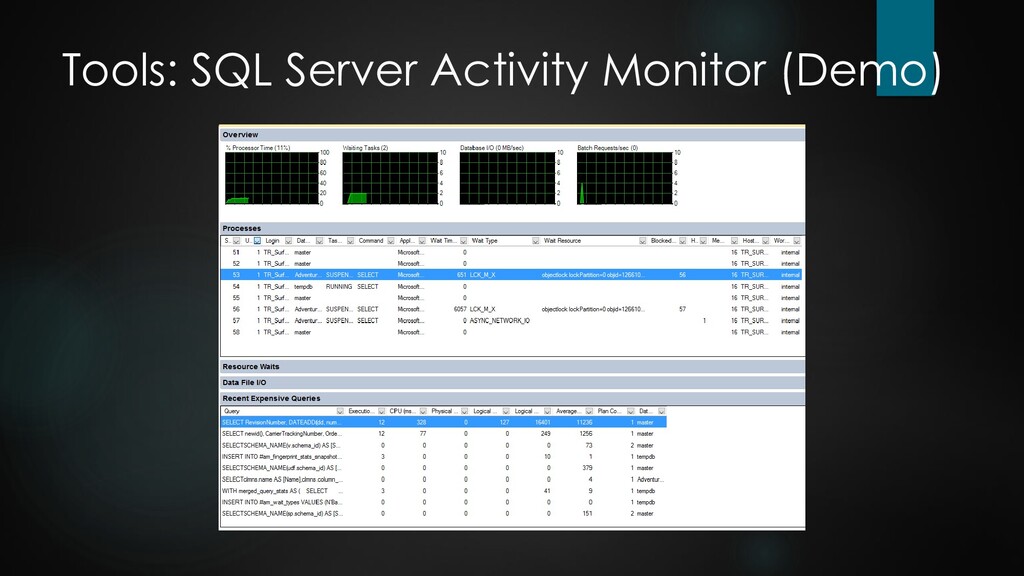
order to avoid unnecessary server roundtrips. Prefer to move data within the database (e.g. temp tables, insert-into-select) instead of back and forth from the client. Implement and invoke stored procedures (sometimes questionable from a design perspective). Use Activity Monitor, Profiler, Tuning Advisor, dynamic management views / dynamic performance views and other monitoring tools. Put data files, tempdb files and transaction logs on separate physical disks, if necessary even single heavily-used tables. Historically most RDBMs provided clustering mainly for failover via mirroring / data replication. Several cluster solutions have since been extended to improve scalability as well, e.g. Oracle RAC. On these scaling cluster systems nodes still share the same storage (node sync requires fast cluster interconnect).
due to joins along two or more parallel to-many associations; use Exists-subqueries, multiple queries or fetch="subselect" instead - whatever is most appropriate in the specific situation. Join duplicates are already pretty bad in plain SQL, but things get even worse when they occur within Hibernate, because of unnecessary mapping workload and child collections containing duplicates. Define lazy loading as the default association loading strategy, and consider applying fetch="subselect" rather than "select" resp. "batch-size". Configure eager loading only for special associations, but join-fetch selectively on a per-query basis. In case of read-only services with huge query resultsets, use projections and fetch into flat DTOs (e.g. via AliasToBean-ResultTransformer), instead of loading thousands of mapped objects into the Session.
and Criteria, when objects will never be modified. Consider clearing the whole Session after flushing, or evict on a per-object basis, once objects are not longer needed. Define a suitable value for jdbc.batch_size (resp. adonet.batch_size). Use Hibernate Query-Cache and Second Level Caching where appropriate (but go sure you are aware of the consequences). Set hibernate.show_sql to "false" and ensure that Hibernate logging is running at the lowest possible loglevel (also check log4j/log4net root logger configuration).
it depends heavily how much "hot data" is moved around, and on query load. Do your math and plan, measure KPIs (e.g. via SQL Server Perfcounters) and adjust accordingly. RAM: it's cheap, get as much as you can. I/O often is a bottleneck, e.g. misconfigured SANs can kill performance. Use HW RAID. CPU: Enterprise editions can take advantage of as much as the OS CPU core maximum. Let's have a look at a real life example - stackoverflow.com: SQL Server failover cluster, 2 nodes (plus one identical setup at another data center for even more redundancy) Dell R730xd server 768GB RAM (the complete data can be held in memory) 6TB PCIe SSD 16 cores
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}