Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
標本調査法の基礎と実践
Search
Daiki Nakamura
September 14, 2022
Science
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
標本調査法の基礎と実践
標本調査法2022
「標本調査法の基礎と実践」
2022年9月5日, 12日
@オンライン
全82枚+
Daiki Nakamura
September 14, 2022
More Decks by Daiki Nakamura
See All by Daiki Nakamura
諸外国の理科カリキュラムにおけるビッグアイデアの構造比較
arumakan
0
890
国際調査ROSESの標本調査設計および調査実施の工夫
arumakan
0
84
適切な回帰推定量の使用が学力調査の推定精度を向上させる効果の検討
arumakan
0
120
Developing a Diverse Interests Scale for STEM Learners: Based on the ROSES Survey in Japan
arumakan
0
120
条件制御能力を測定するコンピュータ適応型テストの開発
arumakan
0
310
科学教育の読書会を中心とした新しい研究活動の展開
arumakan
0
300
The Value of Science Education in an Age of Misinformation
arumakan
1
400
教育研究における研究倫理問題の論点整理
arumakan
0
720
TIMSS 2019 環境認識尺度に関する日本人学習者の特徴
arumakan
0
510
Other Decks in Science
See All in Science
なぜエネルギーは保存する? 〜自由落下でわかる“対称性”とネーターの定理〜
syotasasaki593876
0
210
[NLP2026 参加報告会] AI for Science まとめ / NLP2026
lychee1223
0
1.9k
【論文紹介】Is CLIP ideal? No. Can we fix it?Yes! 第65回 コンピュータビジョン勉強会@関東
shun6211
5
2.5k
フィードフォワードニューラルネットワークを用いた記号入出力制御系に対する制御器設計 / Controller Design for Augmented Systems with Symbolic Inputs and Outputs Using Feedforward Neural Network
konakalab
0
160
(CVPR2026) Back to Basics: Let Denoising Generative Models Denoise
shumpei777
0
220
Utiliser Bitcoin sans Internet
rlifchitz
0
300
AIPシンポジウム 2025年度 成果報告会 「因果推論チーム」
sshimizu2006
3
560
Understanding CVP Waveforms: Interpretation and Clinical Implications in Anesthesiology
taka88
0
680
JSAI2026企画セッションKS-14 インタビュー集『⼈⼯知能と哲学と四つの問い』が提起する⼈⼯知能のこれからの課題 趣旨説明 / JSAI2026 Special Session: A Collection of Interviews, “Artificial Intelligence, Philosophy, and Four Questions”
ykiyota
0
380
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.3k
Tensor Factorization Meets Deformed Information Geometry: Convex Relaxation under Deformed Algebra
gkazunii
0
120
機械学習 - K近傍法 & 機械学習のお作法
trycycle
PRO
1
1.6k
Featured
See All Featured
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Scaling GitHub
holman
464
140k
Optimizing for Happiness
mojombo
378
71k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
Why Our Code Smells
bkeepers
PRO
340
58k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Being A Developer After 40
akosma
91
590k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
320
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
380
Transcript
標本調査法の基礎と実践 中村 大輝(広島大学) 2022年9月5日, 12日 @オンライン 全82枚+ 資料ダウンロード https://drive.google.com/drive/folders/1iqX983r d-BRIaqYaUXAlkjRi_J_oMKRq?usp=sharing
自己紹介 2 中村 大輝(Daiki Nakamura) ◼ 所属 広島大学 教育学部 特任学術研究員(数理・データサイエンス・AI教育プログラム担当)
◼ 専門 科学教育、理科教育、教育心理学 ◼ 研究テーマ 科学的思考力、教育測定、メタ分析、研究方法論 ◼ 論文 • 中村大輝, 山根悠平, 西内舞, 雲財寛. (2019). 理数科教育におけるテクノロジー活用の効果―メタ分析を 通した研究成果の統合―. 科学教育研究, 43(2), 82-91. 10.14935/jssej.43.82 • 中村大輝・田村智哉・小林誠…・松浦拓也(2020)「理科における授業実践の効果に関するメタ分析- 教育センターの実践報告を対象として-」『科学教育研究』44(4), 215-233. 10.14935/jssej.44.215 • 中村大輝・雲財寛・松浦拓也(2021)「理科における認知欲求尺度の再構成および項目反応理論に基づ く検討」『科学教育研究』45(2), 215-233. 10.14935/jssej.45.215 • 中村大輝・原田勇希・久坂哲也・雲財寛・松浦拓也(2021)「理科教育学における再現性の危機とその 原因」『理科教育学研究』62(1), 3-22. 10.11639/sjst.sp20016 • 中村大輝, 堀田晃毅, 西内舞, 雲財寛 (2022). 社会認知的キャリア理論に基づくSTEMキャリア選択の要因 と性差の検討 ―PISA2015データの二次分析を通して―. 日本教育工学会論文誌, 46(2), 303-312. https://doi.org/10.15077/jjet.45098 #Twitter @d_nakamuran #E-mail
[email protected]
#HP https://www.nakamu ra-edu.com/
本勉強会の目標とスケジュール 3 ⚫ 勉強会を通しての目標 ✓ 基本的な標本抽出法を理解する ✓ 推定量の種類と特徴を理解する ✓ Rを用いた分析を実行できるようになる
⚫ スケジュール(予定) • 第1回(9月5日 21:00-) • 標本調査法の基礎 • Rの基礎 • 単純無作為抽出法 • 第2回(9月12日 21:00-) • 確率比例抽出法 • 層化抽出法 • 集落抽出法 • 確率比例集落抽出法 • 層化確率比例集落抽出法 ◼ チャットで随時、質問や感想を受け付けます
諸連絡 4 • RとRStudioというソフトウェアを使用しますので、あらかじめインストールしてお いていただけるとスムーズです。 • 欠席者用に録画を行います。録画は欠席者のみに共有し、外部には公開しません。 • 発表担当者は統計の専門家ではないため、その内容的正確さを保証できません。 •
ハラスメント行為など、許容できない迷惑行為が見られた場合には強制的に退出して いただく場合があります。 https://www.rstudio.com/products /rstudio/download/ https://cran.ism.ac.jp/
文献紹介 5 土屋隆裕(2009)「概説 標本調査法」朝倉書店. 内容紹介 標本調査理論の最新成果をふまえ体系的に理解。付録にR例。 〔内容〕基礎/線形推定量/単純無作為抽出法/確率比例抽 出法/比推定量/層化抽出法/回帰推定量/集落抽出法/多 段抽出法/二相抽出法/関連の話題/クロス表/回帰分析 https://www.asakura.co.jp/detail.php?book_code=12791
➢ この本の内容に準拠して解説を行います。 ➢ スライドでページ数が出てきたらこの本のページ数に対応します。
標本調査法の基礎 Basics of Sample Survey Methods 6
標本調査の特徴 7 ⚫ 全数調査と標本調査 • 全数調査:母集団の対象すべてを調査する – 例)国勢調査、全国学力学習状況調査 • 標本調査:母集団から一部の対象を抽出して調査し、その結果から母集団の状況を推定する
– 例)労働力調査、学校保健統計調査、PISA、TIMSS ⚫ 標本調査のメリット(Kish, 1979; Kish & Verma, 1983)p.2 • 全数調査に比べ、費用・時間・労力を節約できる • 母集団が大きすぎて全数調査が実施不可能な時でも、標本調査は実施可能 • 調査の管理や容易となり、管理が行き届いた調査が実施できる ⚫ 標本調査の基礎(p.3) • 母集団から抽出された標本を用いて 母数(真の値)を推定する • 推定には標本の選択による誤差が伴う
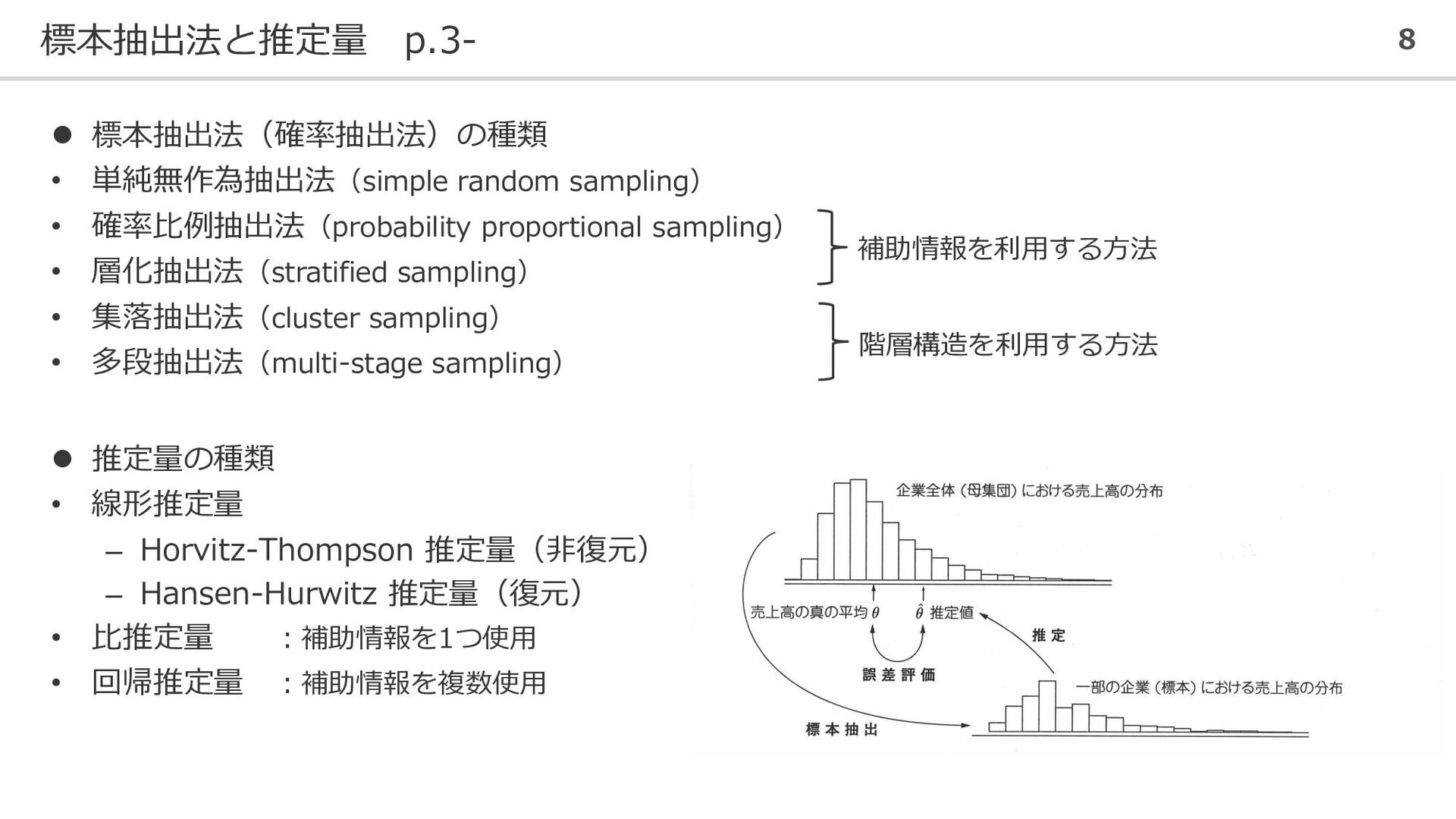
標本抽出法と推定量 p.3- 8 ⚫ 標本抽出法(確率抽出法)の種類 • 単純無作為抽出法(simple random sampling) •
確率比例抽出法(probability proportional sampling) • 層化抽出法(stratified sampling) • 集落抽出法(cluster sampling) • 多段抽出法(multi-stage sampling) 階層構造を利用する方法 補助情報を利用する方法 ⚫ 推定量の種類 • 線形推定量 – Horvitz-Thompson 推定量(非復元) – Hansen-Hurwitz 推定量(復元) • 比推定量 :補助情報を1つ使用 • 回帰推定量 :補助情報を複数使用
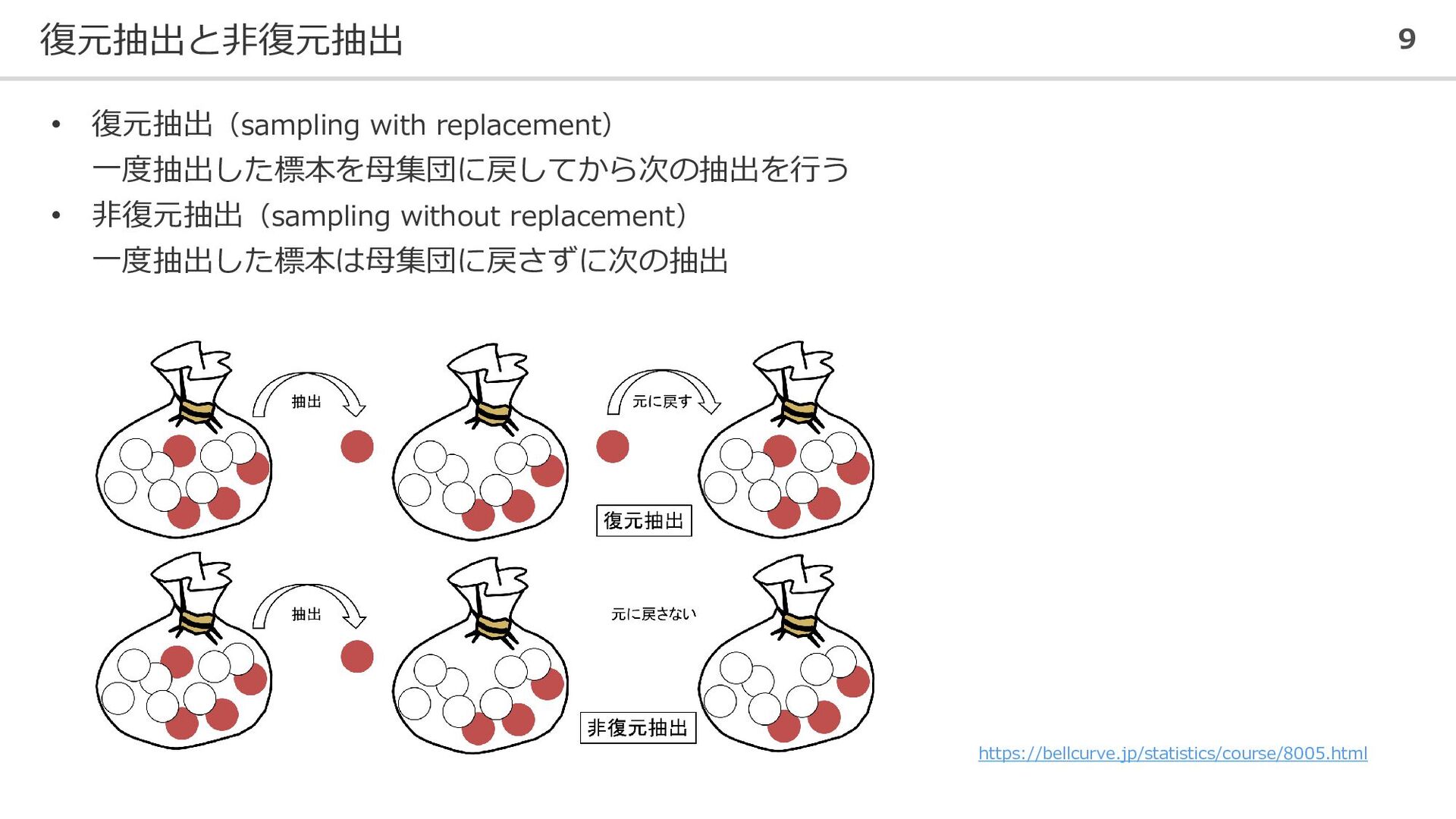
復元抽出と非復元抽出 9 • 復元抽出(sampling with replacement) 一度抽出した標本を母集団に戻してから次の抽出を行う • 非復元抽出(sampling without
replacement) 一度抽出した標本は母集団に戻さずに次の抽出 https://bellcurve.jp/statistics/course/8005.html
母数(母集団特性値)の定義 pp.6-7 10 ⚫ 有限母集団における変数 要素 変数 𝑦 補助変数 𝑥
1 𝑦1 𝑥1 2 𝑦2 𝑥2 ⋮ ⋮ ⋮ 𝑖 𝑦𝑖 𝑥𝑖 ⋮ ⋮ ⋮ 𝑁 𝑦𝑁 𝑥𝑁 ⚫ 母集団特性値𝜃の計算式 母総計: 𝜏𝑦 = Σ𝑦𝑖 母平均: 𝜇𝑦 = 1 𝑁 𝜏𝑦 母分散: 𝜎𝑦 2 = 1 𝑁−1 σ 𝑦𝑖 − 𝜇𝑦 2 母標準偏差: 𝜎𝑦 = 𝜎𝑦 2 母共分散: 𝜎𝑦𝑥 = 1 𝑁−1 σ yi − 𝜇𝑦 𝑥𝑖 − 𝜇𝑥 母相関: 𝜌𝑦𝑥 = 𝜎𝑦𝑥 𝜎𝑦𝜎𝑥 母比率: 𝑝𝑖 = 1 𝑁 σ 𝑦𝑖 = 𝜇𝑦 母集団比: 𝑅 = 𝜏𝑦 𝜏𝑥 𝑁 はどんなに大きくても有限とする ⇒ 有限母集団(finite population) 要素 変数 𝑦 補助変数 𝑥 1 576 47 2 380 31 3 74 25 4 292 34 5 94 22 例) 𝑁 = 5 𝜏𝑦 = 1416 𝜏𝑥 = 159 𝜇𝑥 = 31.8 𝑅 = 8.906
全ての可能な標本 p.10- 11 𝑁 = 5の有限母集団から標本 𝑛 = 3 を抽出する際のすべての可能な標本のパターンを
考えてみる。非復元抽出の場合、組み合わせの数は以下の式で計算できる。 𝑁 𝐶𝑛 = 𝑁! 𝑛! 𝑁 − 𝑛 ! 5 𝐶3 = 5! 3! 5 − 3 ! = 5 × 4 × 3 × 2 × 1 (3 × 2 × 1) × (2 × 1) = 10通り 標本 要素 各標本が選ばれる確率 累積確率 (確率比例抽出) 単純無作為抽出 確率比例抽出 1 1, 2, 3 𝑝(1) = .100 𝑝(1) = .108 .108 2 1, 2, 4 𝑝(2) = .100 𝑝(2) = .117 .225 3 1, 2, 5 𝑝(3) = .100 𝑝(3) = .105 .330 4 1, 3, 4 𝑝(4) = .100 𝑝(4) = .111 .441 5 1, 3, 5 𝑝(5) = .100 𝑝(5) = .099 .540 6 1, 4, 5 𝑝(6) = .100 𝑝(6) = .108 .648 7 2, 3, 4 𝑝(7) = .100 𝑝(7) = .094 .742 8 2, 3, 5 𝑝(8) = .100 𝑝(8) = .082 .824 9 2, 4, 5 𝑝(9) = .100 𝑝(9) = .091 .915 10 3, 4, 5 𝑝(10) = .100 𝑝(10) = .085 1.000 ➢ 各標本が選ばれる確率は、 標本抽出法によって変わる
包含確率 p.14- 12 ⚫ 一次の包含確率(first-order inclusion probability) ある要素𝑖が標本に含まれる確率𝜋𝑖 を一次の包含確率と呼ぶ。 例えば、前ページの表において、要素1が含まれる標本は6つあり、
いずれかの標本が選ばれる確率𝜋1 は、以下の通りである。 𝜋1 = 𝑝(1) + 𝑝(2) + 𝑝(3) + 𝑝(4) + 𝑝(5) + 𝑝(6) = .108 + .117 + .105 + .111 + .099 + .108 = .648 なお、一次の包含確率の母集団総計は、標本サイズ𝑛の期待値に一致する。 𝑈 𝜋𝑖 = 𝐸 𝑛 = 𝑛𝑠 ⚫ 二次の包含確率(second-order inclusion probability) 二つの要素𝑖と𝑗が同時に標本に含まれる確率𝜋𝑖𝑗 を二次の包含確率と呼ぶ。 例えば、要素1と2を同時に含む標本は3つあり、 二次の包含確率𝜋1,2 は、以下の通りである。 𝜋1,2 = 𝑝(1) + 𝑝(2) + 𝑝(3) = .108 + .117 + .105 = .330 標本 要素 確率 累積確率 1 1, 2, 3 𝑝(1) = .108 .108 2 1, 2, 4 𝑝(2) = .117 .225 3 1, 2, 5 𝑝(3) = .105 .330 4 1, 3, 4 𝑝(4) = .111 .441 5 1, 3, 5 𝑝(5) = .099 .540 6 1, 4, 5 𝑝(6) = .108 .648 7 2, 3, 4 𝑝(7) = .094 .742 8 2, 3, 5 𝑝(8) = .082 .824 9 2, 4, 5 𝑝(9) = .091 .915 10 3, 4, 5 𝑝(10) = .085 1.000 𝑛 = 3 のすべての可能な標本の集合 包含確率行列 (確率比例抽出) 1 2 3 4 5 1 .648 .330 .318 .336 .311 2 .597 .284 .303 .278 3 .579 .290 .265 4 .607 .284 5 .569 包含確率行列 (単純無作為) 1 2 3 4 5 1 .600 .300 .300 .300 .300 2 .600 .300 .300 .300 3 .600 .300 .300 4 .600 .300 5 .600
線形推定量(HT推定量) p.26- 13 ⚫ 非復元抽出の場合 以下の式で表される Horvitz-Thompson 推定量(HT)は、母総計𝜏𝑦 の不偏推定量である。 Ƹ
𝜏𝑦 = 𝑆 𝑦𝑖 𝜋𝑖 = 𝑆 𝑤𝑖 𝑦𝑖 ただし、抽出ウェイト 𝑤𝑖 = 1 𝜋𝑖 各標本抽出デザインに対応した包含確率𝜋𝑖 を上式に代入することで、具体的な式を導くことができる。 Ƹ 𝜏𝑦 を𝑁で割れば、母平均の推定量となる。 HT推定量の分散とその推定値は以下のとおりである。 𝑉 Ƹ 𝜏𝑦 = 𝑖∈𝑈 𝑗∈𝑈 (𝜋𝑖𝑗 − 𝜋𝑖 𝜋𝑗 ) 𝑦𝑖 𝜋𝑖 𝑦𝑖 𝜋𝑗 母集団において二次の包含確率がすべて 𝜋𝑖𝑗 > 0 のとき、次式は𝑉 Ƹ 𝜏𝑦 の不偏推定量となる(Horvitz & Thompson, 1952) 。 𝑉 Ƹ 𝜏𝑦 = 𝑖∈𝑆 𝑗∈𝑆 𝜋𝑖𝑗 − 𝜋𝑖 𝜋𝑗 𝜋𝑖𝑗 𝑦𝑖 𝜋𝑖 𝑦𝑖 𝜋𝑗
HT推定の具体例 p.27- 14 ◼ HT推定値 ※標本 1, 2, 5 確率比例抽出の場合
Ƹ 𝜏𝑦 = 𝑆 𝑦𝑖 𝜋𝑖 = 576 .648 + 380 .597 + 94 .569 = 1690 Ƹ 𝜇𝑦 = Ƹ 𝜏𝑦 𝑁 = 1690 5 = 338 ◼ HT推定値の分散の推定値 𝑉 Ƹ 𝜏𝑦 = 𝑖∈𝑆 𝑗∈𝑆 𝜋𝑖𝑗 − 𝜋𝑖 𝜋𝑗 𝜋𝑖𝑗 𝑦𝑖 𝜋𝑖 𝑦𝑖 𝜋𝑗 = .648 − .648 × .648 .648 × 576 .648 × 576 .648 + ⋯ 要素 変数 𝑦 補助変数 𝑥 𝟏 𝟓𝟕𝟔 𝟒𝟕 𝟐 𝟑𝟖𝟎 𝟑𝟏 3 74 25 4 292 34 𝟓 𝟗𝟒 𝟐𝟐 包含確率行列 (確率比例抽出) 1 2 3 4 5 1 .648 .330 .318 .336 .311 2 .597 .284 .303 .278 3 .579 .290 .265 4 .607 .284 5 .569 ➢ 複雑な抽出法で母集団サイズが大きくなると、 二次の包含確率𝜋𝑖𝑗 をすべて計算することは極 めて難しくなる。そこで、復元抽出を便宜的 に仮定して、HH推定量を用いるという方法 が取られることもある。 包含確率行列 (単純無作為) 1 2 3 4 5 1 .600 .300 .300 .300 .300 2 .600 .300 .300 .300 3 .600 .300 .300 4 .600 .300 5 .600 3×3通り
線形推定量(HH推定量) p.30- 15 ⚫ 復元抽出の場合 以下の式で表される Hansen-Hurwitz 推定量(HH)は、母総計𝜏𝑦 の不偏推定量である。 Ƹ
𝜏𝑦 = 1 𝑛 𝑆 𝑦𝑖 𝑝𝑖 = 𝑆 𝑤𝑖 𝑦𝑖 ただし、抽出ウェイト 𝑤𝑖 = 1 𝑛𝑝𝑖 各標本抽出デザインに対応した抽出確率𝑝𝑖 を上式に代入することで、具体的な式を導くこと ができる。 Ƹ 𝜏𝑦 を𝑁で割れば、母平均の推定量となる。 HH推定量の分散とその推定値は以下のとおりである。 𝑉 Ƹ 𝜏𝑦 = 1 𝑛 𝑈 𝑝𝑖 𝑦𝑖 𝑝𝑖 − 𝜏𝑦 𝑉 Ƹ 𝜏𝑦 = 1 𝑛(𝑛 − 1) 𝑆 𝑦𝑖 𝑝𝑖 − Ƹ 𝜏𝑦 2 HT推定値の分散に比べて格段に計 算しやすい。Nが大きい時は復元抽 出と見なしてHH推定量を用いるこ とも考えられる。
HH推定の具体例 p.31- 16 要素 変数 𝑦 抽出確率 𝑝𝑖 𝟏 𝟓𝟕𝟔
. 𝟐𝟗𝟔 2 380 .195 𝟑 𝟕𝟒 . 𝟏𝟓𝟕 4 292 .214 5 94 .138 ◼ HH推定値 ※標本 1, 1, 3 場合 Ƹ 𝜏𝑦 = 1 𝑛 𝑆 𝑦𝑖 𝑝𝑖 = 1 3 576 .296 + 576 .296 + 74 .157 = 1456 Ƹ 𝜇𝑦 = Ƹ 𝜏𝑦 𝑁 = 1456 5 = 291.2 ◼ HH推定値の分散の推定値 𝑉 Ƹ 𝜏𝑦 = 1 𝑛(𝑛 − 1) 𝑆 𝑦𝑖 𝑝𝑖 − Ƹ 𝜏𝑦 2 = 1 3 × (3 − 1) 576 .296 − 1456 2 + ⋯ = 492.72
抽出ウェイト(sampling weight)についての補足 p.33- 17 𝑤𝑖 = 1 𝜋𝑖 , 非復元抽出の場合
1 𝑛𝑝𝑖 , 復元抽出の場合 線形推定量は、変数値𝑦𝑖 と抽出ウェイト𝑤𝑖 による加重標本総計として表せる。 Ƹ 𝜏𝑦 = 𝑆 𝑤𝑖 𝑦𝑖 また、抽出ウェイトの標本総計は、母集団サイズ𝑁の線形推定量である。 S 𝑤𝑖 = 𝑁 このように、抽出ウェイト𝑤𝑖 は、𝑖番目の要素が代表している母集団の要素の数を表し ている。例えば、𝑤𝑖 = 5であれば、その要素は母集団における要素5個(人)分を代表し ている。
比推定量(ratio estimator) p.70- 18 目的変数𝑦と相関の高い補助変数𝑥を利用する方法。 ただし、補助変数𝑥の母総計𝜏𝑥 は既知のものとする。 2つの母総計の線形推定量 Ƹ 𝜏𝑦
と Ƹ 𝜏𝑥 の比 𝑅を利用すると、 Ƹ 𝜏𝑦,𝑅 = 𝜏𝑥 𝑅 = 𝜏𝑥 ො 𝜏𝑦 ො 𝜏𝑥 = 𝜏𝑥 σ𝑆 𝑤𝑖𝑦𝑖 σ𝑆 𝑤𝑖𝑥𝑖 𝑁 = 20, 𝑛 = 3 母総計 線形推定値 目的変数 𝑦 𝜏𝑦 =? ? ? Ƹ 𝜏𝑦 = 8187 補助変数 𝑥1 𝜏𝑥1 = 663 Ƹ 𝜏𝑥1 = 793 補助変数 𝑥2 (𝑥2 = 1) 𝜏𝑥2 = 𝑁 = 20 Ƹ 𝜏𝑥2 = 𝑆 𝑤𝑖 = 𝑁 Ƹ 𝜏𝑦,𝑅 = 𝜏𝑥 𝑅 = 𝜏𝑥 Ƹ 𝜏𝑦 Ƹ 𝜏𝑥 = 663 × 8187 793 = 6844.869 ◼ サイズとの比推定量 Ƹ 𝜏𝑦,𝑁 = 𝑁 Ƹ 𝜏𝑦 𝑁 = 𝑁 σ𝑆 𝑤𝑖 𝑦𝑖 σ 𝑆 𝑤𝑖
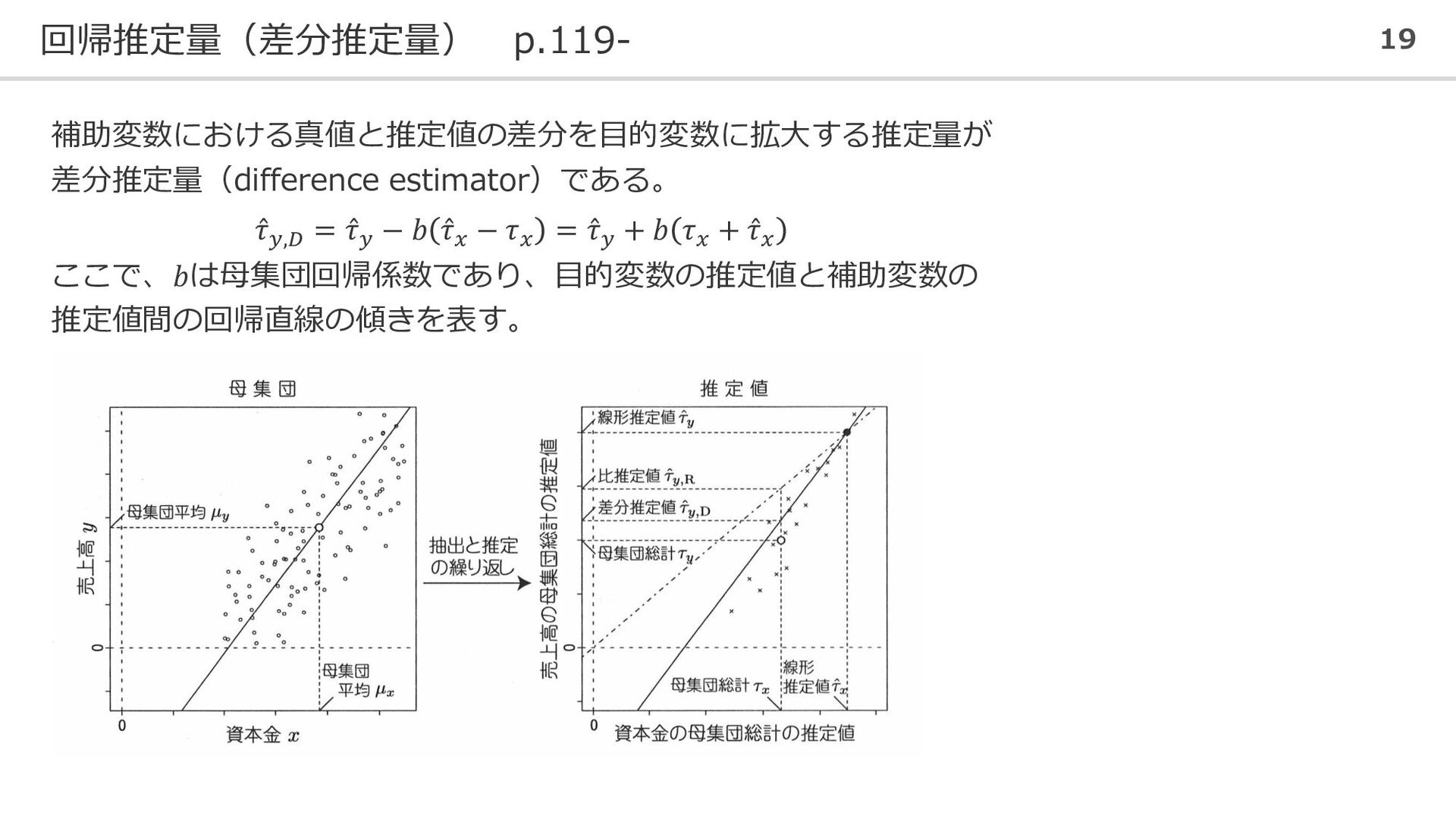
回帰推定量(差分推定量) p.119- 19 補助変数における真値と推定値の差分を目的変数に拡大する推定量が 差分推定量(difference estimator)である。 Ƹ 𝜏𝑦,𝐷 = Ƹ
𝜏𝑦 − 𝑏 Ƹ 𝜏𝑥 − 𝜏𝑥 = Ƹ 𝜏𝑦 + 𝑏 𝜏𝑥 + Ƹ 𝜏𝑥 ここで、𝑏は母集団回帰係数であり、目的変数の推定値と補助変数の 推定値間の回帰直線の傾きを表す。
一般化回帰推定量 p.124- 20 差分推定量は、補助変数が複数の場合にも拡張できる。 これを一般化回帰推定量(generalized regression estimator) と呼ぶ。 Ƹ 𝜏𝑦,𝐺𝑅𝐸𝐺
= Ƹ 𝜏𝑦 + 𝝉𝒙 − ො 𝝉𝒙 ′ 𝒃 ここで、 𝒃 は母集団回帰係数の推定値のベクトルであり、 以下の式で求められる。 𝒃 = 𝑆 𝑤𝑖 𝒙𝒊 𝒙𝒊 ′ 𝑐𝑖 −1 𝑆 𝑤𝑖 𝒙𝒊 𝑦𝑖 𝑐𝑖
練習問題 21 1. 全数調査と比べて標本調査にはどのような利点があるか述べよ 2. 𝑁=5の有限母集団から標本 𝑛=2 を非復元抽出する際のすべての可能な標本の パターンの数を答えよ 3.
要素間で一次の包含確率がすべて等しい標本抽出法は何か答えよ 4. 一次の包含確率の逆数を何と呼ぶか 5. 線形推定量のうち、非復元抽出において用いるのはHT推定量とHH推定量のど ちらか。 6. 標本から得た推定値の精度を表す指標を答えよ
Rの基礎 Basics of Software R 22
RStudioの画面 エディタ (コードを書くところ) コンソール (結果・出力が出るところ) パッケージの管理 図表の出力など ワークスペース (変数の管理)
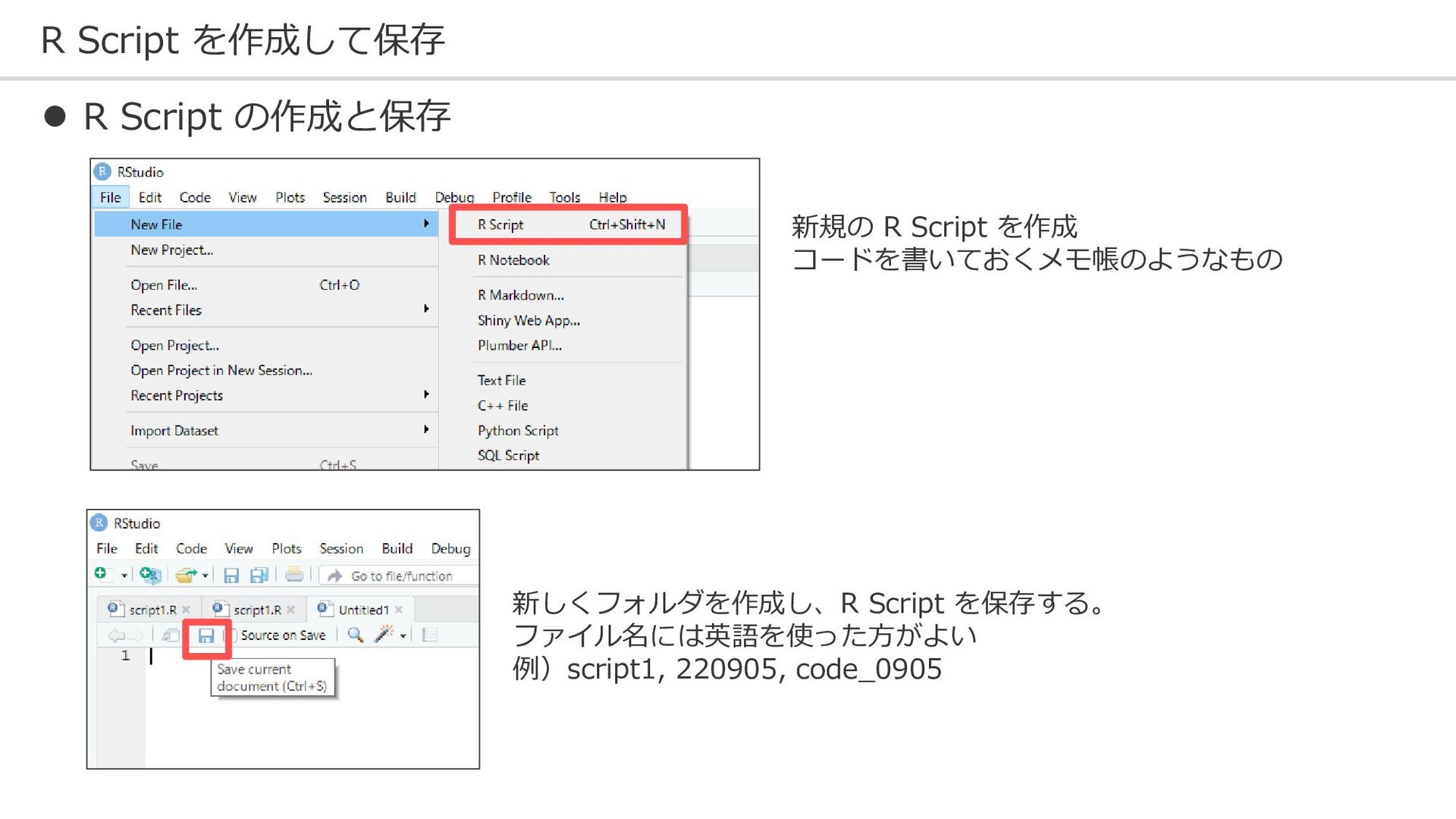
R Script を作成して保存 ⚫ R Script の作成と保存 新しくフォルダを作成し、R Script を保存する。
ファイル名には英語を使った方がよい 例)script1, 220905, code_0905 新規の R Script を作成 コードを書いておくメモ帳のようなもの
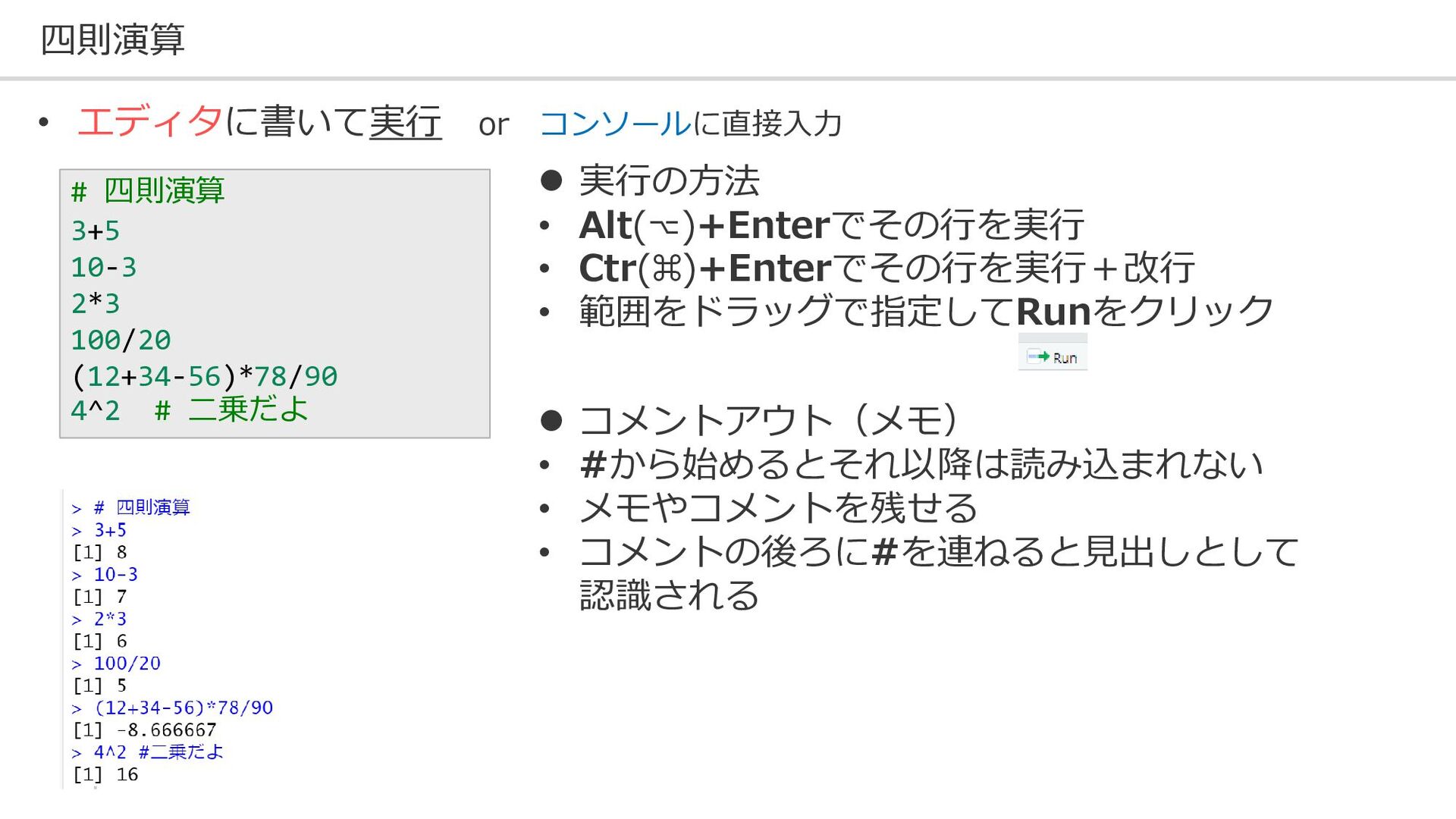
四則演算 # 四則演算 3+5 10-3 2*3 100/20 (12+34-56)*78/90 4^2 #
二乗だよ • エディタに書いて実行 or コンソールに直接入力 ⚫ 実行の方法 • Alt(⌥)+Enterでその行を実行 • Ctr(⌘)+Enterでその行を実行+改行 • 範囲をドラッグで指定してRunをクリック ⚫ コメントアウト(メモ) • #から始めるとそれ以降は読み込まれない • メモやコメントを残せる • コメントの後ろに#を連ねると見出しとして 認識される
変数と代入 • 代入演算子「<-」「=」を使って、変数にオブジェクトを代入することができる • Alt(⌥) + - で、<- が入力できる #
変数と代入 x <- 3+5 y <- 9 z <- x+y z オブジェクト 変数の箱 ※イメージ オブジェクト:データそのもの 変数:オブジェクトを保管する箱 代入:オブジェクトを箱に保管すること スペースは無視して読み込まれる スペースを入れた方が可読性が高い
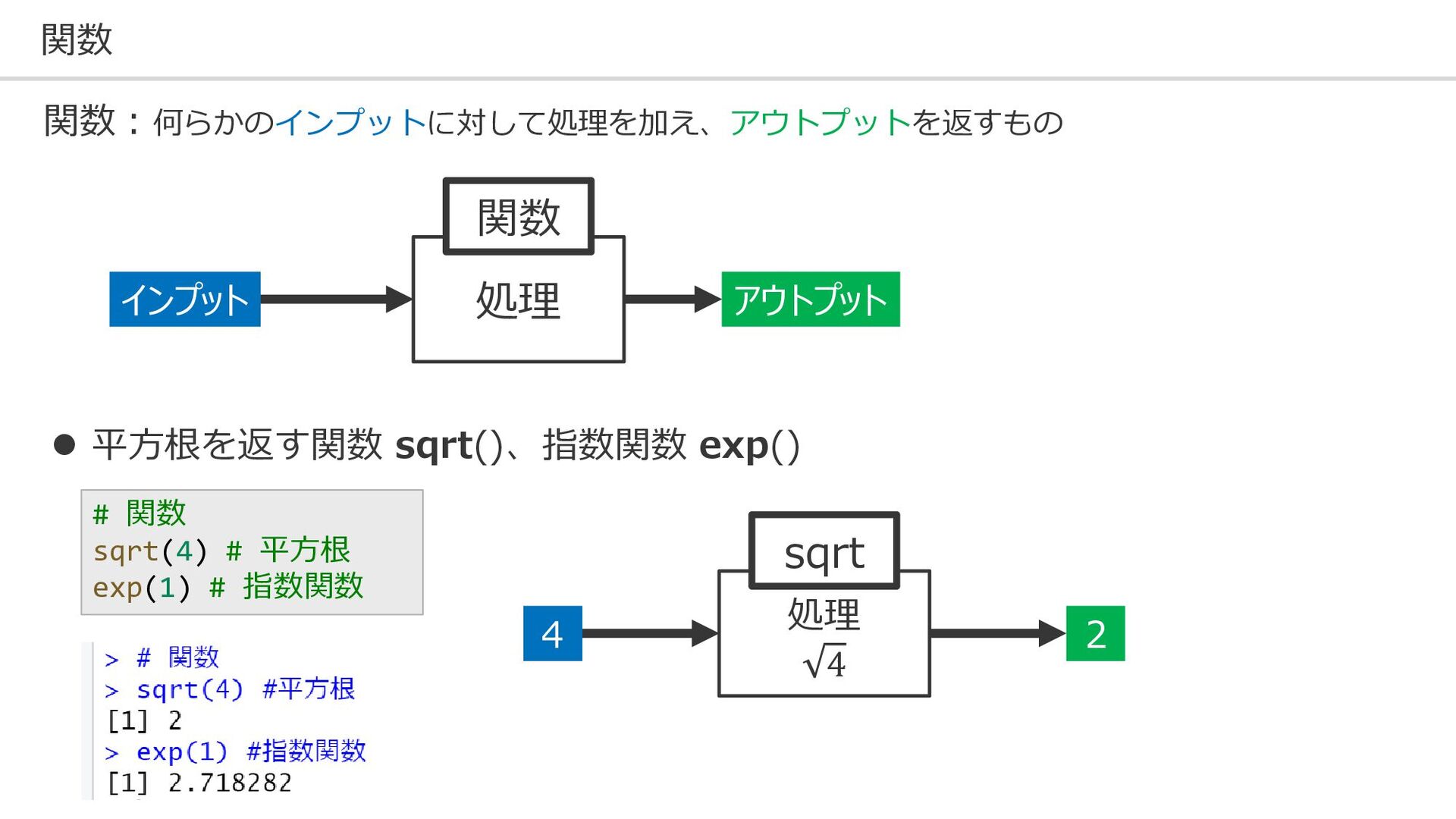
関数 アウトプット インプット 処理 関数 2 4 処理 4 sqrt
# 関数 sqrt(4) # 平方根 exp(1) # 指数関数 ⚫ 平方根を返す関数 sqrt()、指数関数 exp() 関数:何らかのインプットに対して処理を加え、アウトプットを返すもの
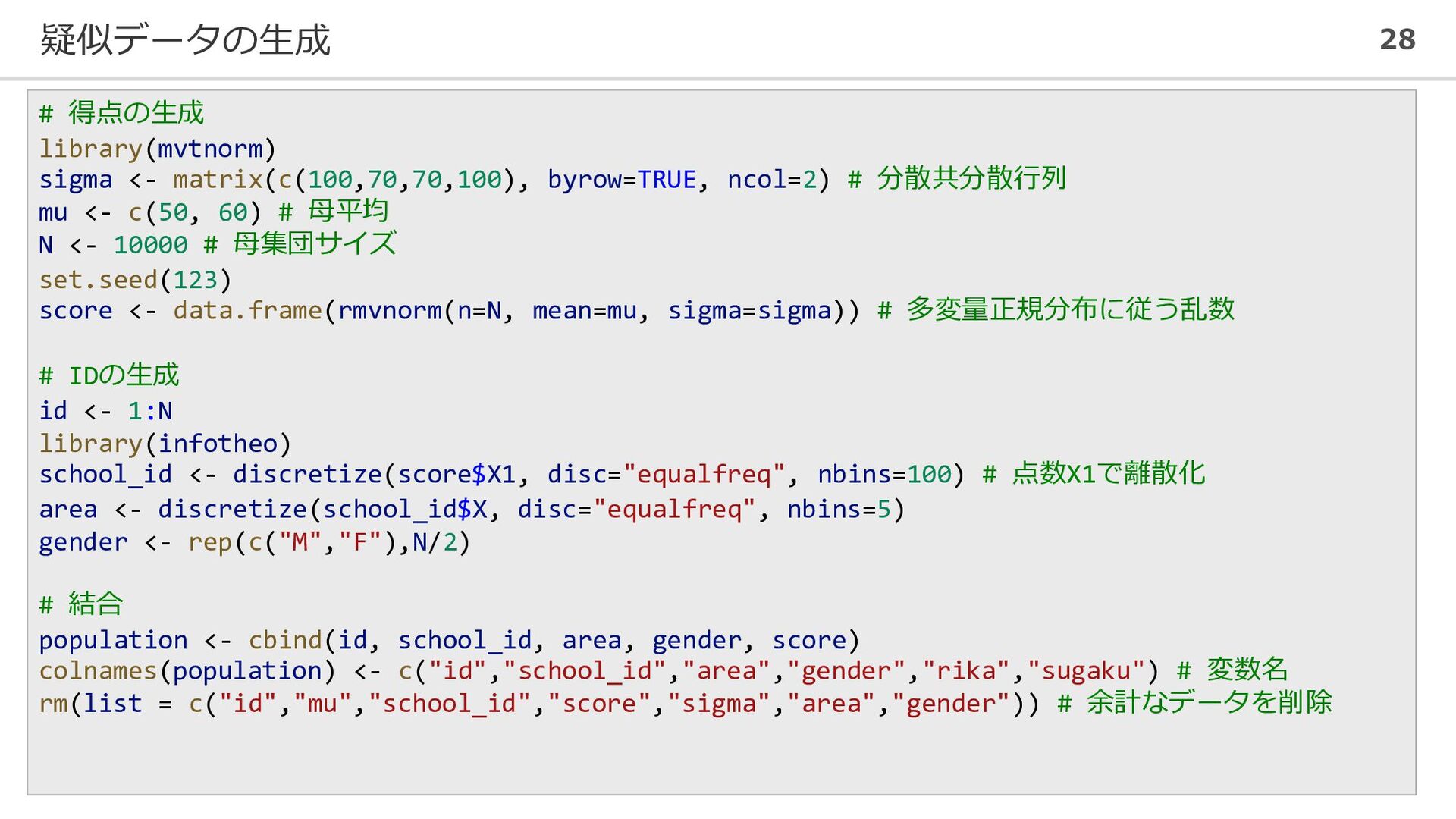
疑似データの生成 28 # 得点の生成 library(mvtnorm) sigma <- matrix(c(100,70,70,100), byrow=TRUE, ncol=2)
# 分散共分散行列 mu <- c(50, 60) # 母平均 N <- 10000 # 母集団サイズ set.seed(123) score <- data.frame(rmvnorm(n=N, mean=mu, sigma=sigma)) # 多変量正規分布に従う乱数 # IDの生成 id <- 1:N library(infotheo) school_id <- discretize(score$X1, disc="equalfreq", nbins=100) # 点数X1で離散化 area <- discretize(school_id$X, disc="equalfreq", nbins=5) gender <- rep(c("M","F"),N/2) # 結合 population <- cbind(id, school_id, area, gender, score) colnames(population) <- c("id","school_id","area","gender","rika","sugaku") # 変数名 rm(list = c("id","mu","school_id","score","sigma","area","gender")) # 余計なデータを削除
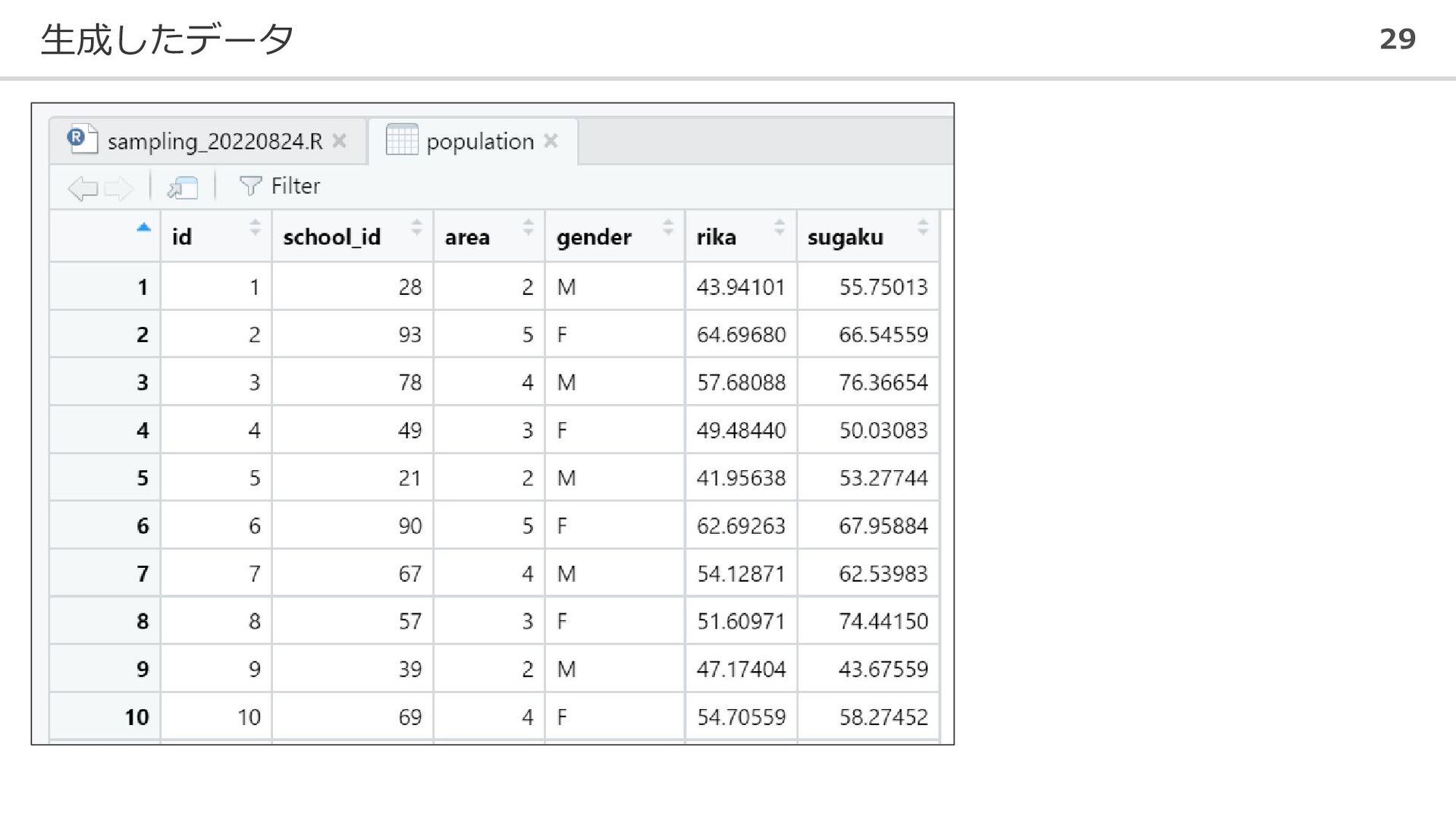
生成したデータ 29
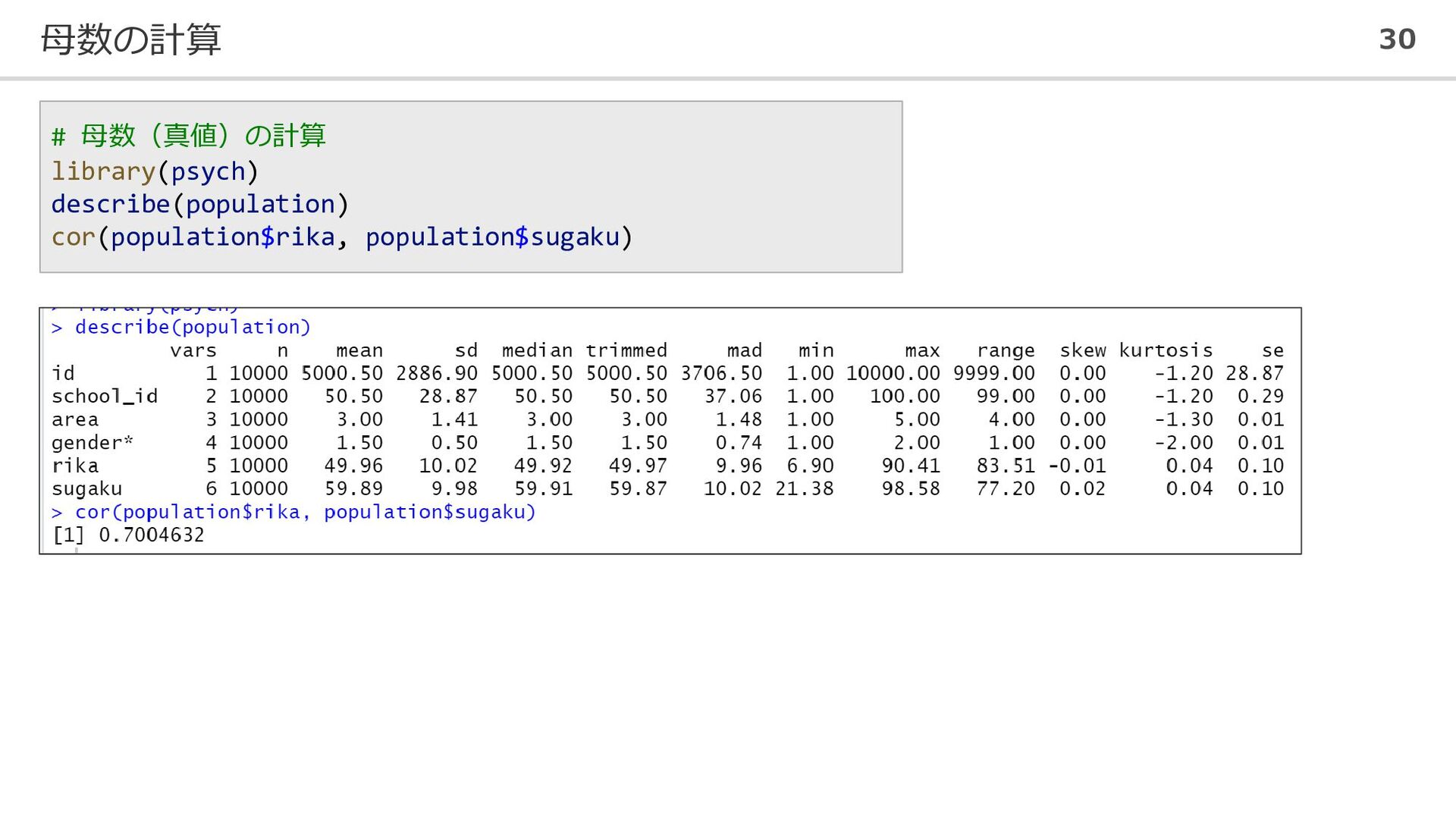
母数の計算 30 # 母数(真値)の計算 library(psych) describe(population) cor(population$rika, population$sugaku)
単純無作為抽出法 simple random sampling 31
単純無作為抽出の方法 p.39- 32 ⚫ 非復元単純無作為抽出の方法 • 逐一法(draw by draw procedure)
• 無作為ソート法(random sorting procedure) • 選出棄却法(selection-rejection procedure) ◼ 無作為ソート法(Sunter, 1977) 1. 母集団の各要素に対し、0と1の間の一様乱数をそれぞれ 独立に与える 2. 与えられた乱数を昇順に並び替える 3. 先頭の𝑛個の要素を標本とする # 単純無作為抽出 n <- 200 library(dplyr) set.seed(123) dat_si <- slice_sample(population, n = n, replace = FALSE) # 無作為ソート法 ID 乱数 1 0.77 2 0.02 3 0.85 4 0.12 5 0.48 ID 乱数 2 0.02 4 0.12 5 0.48 1 0.77 3 0.85 ソート
非復元単純無作為抽出における推定 33 ⚫ 包含確率 一次と二次の包含確率は以下の通り。 𝜋𝑖 = 𝑁−1 𝐶𝑛−1 𝑁
𝐶𝑛 = 𝑛 𝑁 , 𝜋𝑖𝑗 = 𝑛 𝑁 , 𝑖 = 𝑗の場合 𝑛 𝑁 𝑛 − 1 𝑁 − 1 , 𝑖 ≠ 𝑗の場合 ⚫ 線形推定量(HT推定量) Ƹ 𝜏𝑦 = 𝑆 𝑦𝑖 𝜋𝑖 = 𝑁 𝑛 𝑆 𝑦𝑖 = 𝑁ത 𝑦 𝑉 Ƹ 𝜏𝑦 = 𝑖∈𝑆 𝑗∈𝑆 𝜋𝑖𝑗 − 𝜋𝑖 𝜋𝑗 𝜋𝑖𝑗 𝑦𝑖 𝜋𝑖 𝑦𝑖 𝜋𝑗 = 𝑁2 1 − 𝑓 1 𝑛 𝑆𝑦 2 ただし、抽出率𝑓 = 𝑛 𝑁 , 𝑆𝑦 2は標本分散。 ➢ この1 − 𝑓を有限母集団修正項(finite population correction term, fpc)と呼ぶ。
svydesign()による標本抽出デザインの指定 34 ids: 抽出単位。~1と指定すると、クラスターが存在しないことを意味する。 fpc: 有限母集団修正項。抽出率𝑓 = 𝑛 𝑁 か母集団サイズ𝑁のどちらかの変数列を指定する。値
が1を超えるかどうかでどちらが指定されたか自動的に判断される。 w: 抽出ウェイト(重み) dat_si$N <- rep(N, n) # 母集団サイズのベクトル dat_si$w <- dat_si$N / n # 単純無作為抽出の重み library(survey) si <- svydesign(ids = ~1, fpc = ~N, weights = ~w, data = dat_si) # 標本抽出デザイン summary(si)
線形推定量 35 # 線形推定量 svytotal(~rika, si, deff=TRUE) # 総計 coef(svytotal(~rika,
si))/N # 平均 SE(svytotal(~rika, si))/N # 標準誤差 ◼ 真値 𝜏𝑟𝑖𝑘𝑎 = 499560.7 𝜇𝑟𝑖𝑘𝑎 = 49.95607
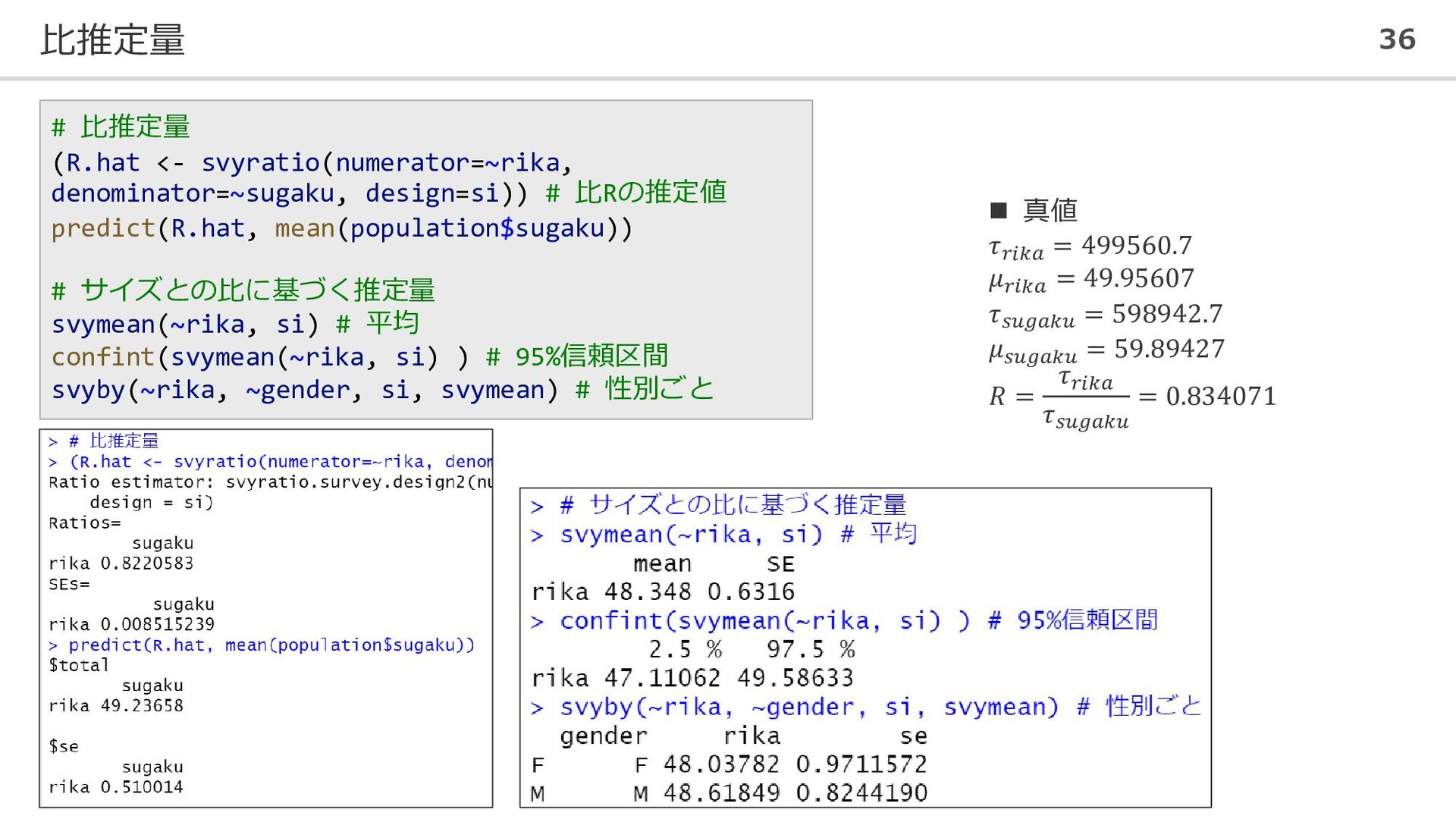
比推定量 36 # 比推定量 (R.hat <- svyratio(numerator=~rika, denominator=~sugaku, design=si)) #
比Rの推定値 predict(R.hat, mean(population$sugaku)) # サイズとの比に基づく推定量 svymean(~rika, si) # 平均 confint(svymean(~rika, si) ) # 95%信頼区間 svyby(~rika, ~gender, si, svymean) # 性別ごと ◼ 真値 𝜏𝑟𝑖𝑘𝑎 = 499560.7 𝜇𝑟𝑖𝑘𝑎 = 49.95607 𝜏𝑠𝑢𝑔𝑎𝑘𝑢 = 598942.7 𝜇𝑠𝑢𝑔𝑎𝑘𝑢 = 59.89427 𝑅 = 𝜏𝑟𝑖𝑘𝑎 𝜏𝑠𝑢𝑔𝑎𝑘𝑢 = 0.834071
一般化回帰推定量 37 # 一般化回帰推定量(サンプルサイズ+数学点数) si.c <- calibrate(si, ~sugaku, c(N, sum(population$sugaku)))
svymean(~rika, si.c) ◼ 真値 𝜏𝑟𝑖𝑘𝑎 = 499560.7 𝜇𝑟𝑖𝑘𝑎 = 49.95607 推定量 推定値 標準誤差 線形推定量 48.348 0.632 比推定量 49.237 0.510 サイズとの比推定量 48.348 0.632 一般化回帰推定量 49.001 0.480 ⚫ 推定量間の精度の比較
分散の推定 38 # 分散の推定 svyvar(~rika, si) svyby(~rika, ~gender, si, svyvar)
# 性別ごと # 性差の検定 tt <- svyttest(rika~gender, si) tt library(effectsize) t_to_d(t = tt$statistic, df_error = tt$parameter)
確率比例抽出法 probability proportional sampling 39
確率比例抽出法の概要 p.51- 40 • 補助変数を標本抽出の際に利用する • 適切な補助変数を利用することで、単純無作為抽出よりも精度が高くなる ➢ 条件:目的変数との高い相関、正の値を持つ変数、母集団の全要素の値が既知 要素
売上高 𝑦𝑖 資本金 𝑥𝑖 要素 売上高 𝑦𝑖 資本金 𝑥𝑖 1 576 47 11 465 51 2 380 31 12 133 15 3 74 25 13 84 15 4 292 34 14 565 54 5 94 22 15 25 19 6 158 19 16 660 52 7 636 57 17 65 19 8 479 42 18 148 15 9 236 36 19 209 28 10 639 60 20 62 22 𝜏𝑦 = 5980, 𝜏𝑥 = 663 赤で示す資本金 𝑥𝑖 > 50 の大企業は、5社で売上高の母 総計𝜏𝑦 の約半分を占めている。 636 + 639 + 465 + 565 + 660 = 2965 このような要素を標本に含めないと過少推定になる。 解決法として、売上高と相関の高い資本金を基準に、資 本金𝑥が高い企業ほど標本に選ばれる確率を高くするこ とを考える。 方法①:確率比例抽出法 包含確率𝜋𝑖 を補助変数𝑥𝑖 に比例させる 𝜋𝑖 ∝ 𝑥𝑖 , (𝑖 ∈ 𝑈) 方法②:層化抽出法 母集団をいくつかの層に分けて、影響の強い層の抽出率を 高くする。 例)大企業と中小企業に分けて、大企業の抽出率を高くする。
確率比例抽出の方法 p.53- 41 ⚫ 包含確率と抽出ウェイト 包含確率𝜋𝑖 を補助変数𝑥𝑖 に比例させると、 𝜋𝑖 =
𝐸 𝑛 𝑥𝑖 𝜏𝑥 = 𝑛𝑥𝑖 𝜏𝑥 ∝ 𝑥𝑖 , 𝑖 ∈ 𝑈 𝑤𝑖 = 1 𝜋𝑖 = 𝜏𝑥 𝑛𝑥𝑖 これを厳密に満たすような抽出を実現するのは難しく、さらには二次の包含確率の計算が難しい ことなどもあり、複数の抽出手続きが考案されている。 ⚫ 非復元確率比例抽出の方法 p.57- • Poisson抽出法(Poisson sampling)※二次の包含確率が計算しやすい一方で、固定サイズデザインにならない • Sunterの方法(Sunter, 1977, 1986)※固定サイズデザインだが、𝑥が小さいと比例条件が満たされなくなる • Sampfordの方法(Sampford, 1967)※固定サイズデザインだが、抽出率n/Nが高いと効率が悪い • Midzunoの方法(Midzuno, 1952)※補助変数𝑥 の分布によっては適用できない • 系統抽出法(systematic sampling)※手順が簡単だが、誤差分散の不偏推定量が無い • Rao-Hartley-Cochranの方法(Rao et al., 1962)※RHC推定量という独自の推定量を使う
系統抽出法による確率比例抽出 42 ⚫ 系統抽出法の手続き 1. 母集団の要素ごとに、補助変数𝑥𝑖 の相対値𝑣𝑖 = 𝑥𝑖 /𝜏𝑥
を求める 2. 要素の並び順に従い、相対値𝑣𝑖 をσ𝑗≤𝑖 𝑣𝑗 と累積する 3. 0と1の間の一様乱数を1つ発生させ、スタート値𝑎とする。相対値の累積が はじめて𝑎を超える要素を1つ目の標本とする。 4. 抽出間隔をdとし、相対値の累積が𝑎 + 𝑛 − 1 𝑑をはじめて超える要素を標本 としていく。 • しかし、この方法では二次の包含確率が𝜋𝑖𝑗 = 0となる要素の組み合わせがあ るため、誤差分散𝑉( Ƹ 𝜏𝑦 )の不偏推定量が求められない。 • 解決法として、手順1の前に要素を無作為に並べ替えておくと、この問題を 回避できる(Goodman & Kish, 1950) • その場合の誤差分散の推定量は以下の式で近似できる(Hartley & Rao, 1962) 𝑉 Ƹ 𝜏𝑦 ≈ 1 2(𝑛 − 1) 𝑖∈𝑠 𝑗∈𝑠 1 − 𝜋𝑖 + 𝜋𝑗 + 1 𝑛 𝑈 𝜋𝑖 2 𝑦𝑖 𝜋𝑖 − 𝑦𝑗 𝜋𝑗 https://bellcurve.jp/statistics/course/8007.html
Sampfordの方法による確率比例抽出 43 ⚫ Sampfordの方法の手続き(Sampford, 1967) 1. 母集団の第𝑖要素に抽出確率𝑝𝑖 = 𝑥𝑖 /𝜏𝑥
を与え、1つの要素を抽出する 2. 手順1で抽出された要素も含めた𝑁個の要素から、以下の抽出確率で𝑛 − 1個の 要素を復元確率比例抽出する。 𝑝𝑖 ′ = 𝑐 𝑥𝑖 𝜏𝑥 − 𝑛𝑥𝑖 , 𝑖 ∈ 𝑈 ただし、𝑐は σ𝑈 𝑝𝑖 ′ = 1 とするための基準化定数 3. 抽出した標本𝑠に重複した要素が含まれていればその標本は破棄し、手順1から 再度抽出を行う。
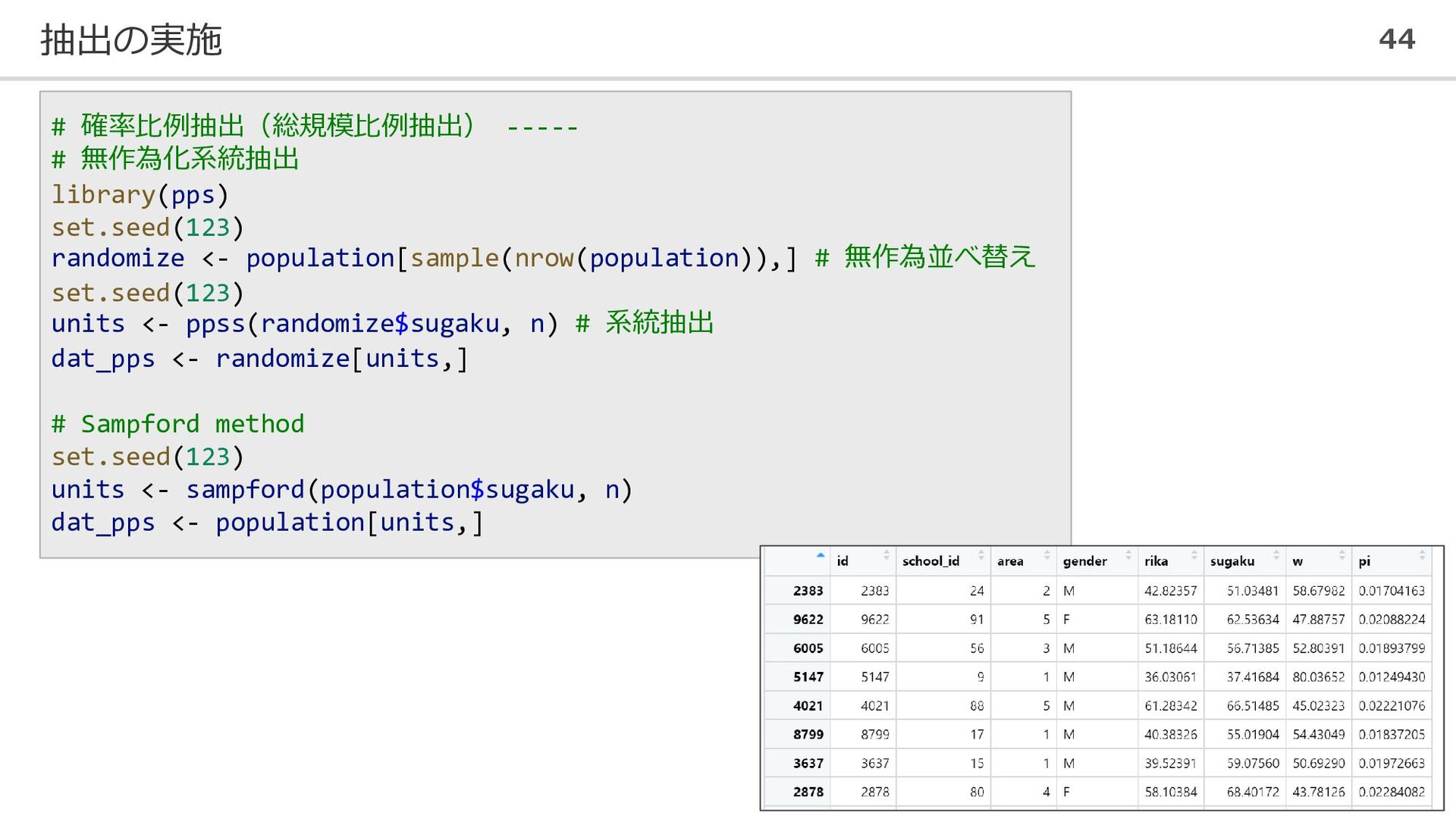
抽出の実施 44 # 確率比例抽出(総規模比例抽出) ----- # 無作為化系統抽出 library(pps) set.seed(123) randomize
<- population[sample(nrow(population)),] # 無作為並べ替え set.seed(123) units <- ppss(randomize$sugaku, n) # 系統抽出 dat_pps <- randomize[units,] # Sampford method set.seed(123) units <- sampford(population$sugaku, n) dat_pps <- population[units,]
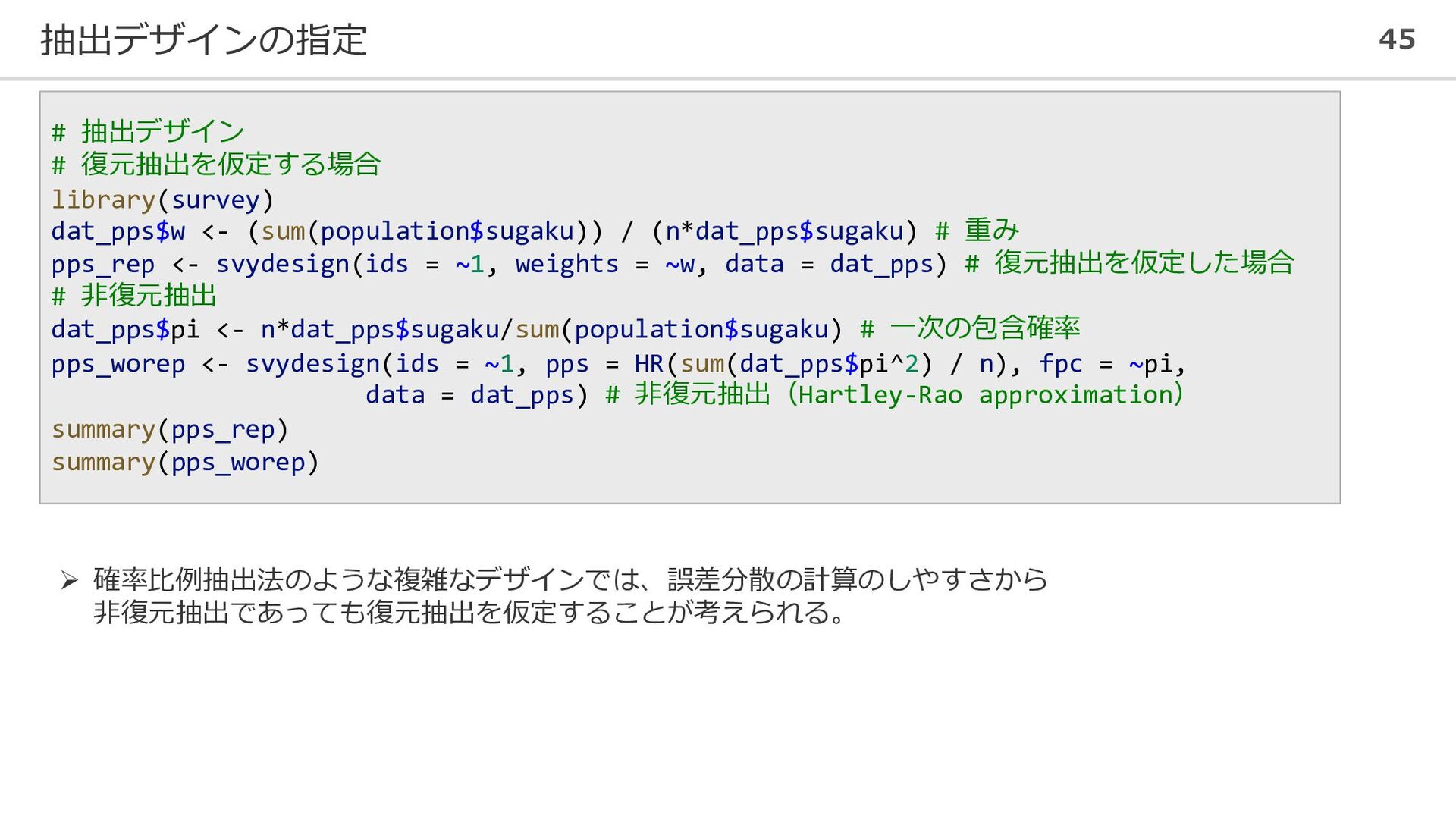
抽出デザインの指定 45 # 抽出デザイン # 復元抽出を仮定する場合 library(survey) dat_pps$w <- (sum(population$sugaku))
/ (n*dat_pps$sugaku) # 重み pps_rep <- svydesign(ids = ~1, weights = ~w, data = dat_pps) # 復元抽出を仮定した場合 # 非復元抽出 dat_pps$pi <- n*dat_pps$sugaku/sum(population$sugaku) # 一次の包含確率 pps_worep <- svydesign(ids = ~1, pps = HR(sum(dat_pps$pi^2) / n), fpc = ~pi, data = dat_pps) # 非復元抽出(Hartley-Rao approximation) summary(pps_rep) summary(pps_worep) ➢ 確率比例抽出法のような複雑なデザインでは、誤差分散の計算のしやすさから 非復元抽出であっても復元抽出を仮定することが考えられる。
デザイン効果と有効標本サイズ 46 ⚫ デザイン効果(design effect) • ある抽出法における推定量の精度が単純無作為抽出法の場合と比べてどの程度の精度 なのかを比較する指標としてデザイン効果がある(kish, 1965) Deff
= ある標本抽出デザインにおける推定量の分散 非復元単純無作為抽出における推定量の分散 • デザイン効果が1よりも大きければ効率が悪い、1よりも小さければ効率が良いこと を意味する。 ⚫ 有効標本サイズ(effective sample size) • デザイン効果に対する標本サイズ𝑛の相対的な大きさを有効標本サイズと呼ぶ(Kish, 1965) 𝑛EFF = 𝑛 Deff • 有効標本サイズは、当該標本抽出デザインにおける推定量と同じ精度の推定量を単純 無作為抽出法で得るために必要な標本サイズの大きさを表す
線形推定量(HH推定量) 47 # 線形推定量 svytotal(~rika, pps_rep, deff=TRUE) # 総計 n
/ 0.5774 # 有効標本サイズ coef(svytotal(~rika, pps_rep))/N # 平均 SE(svytotal(~rika, pps_rep))/N
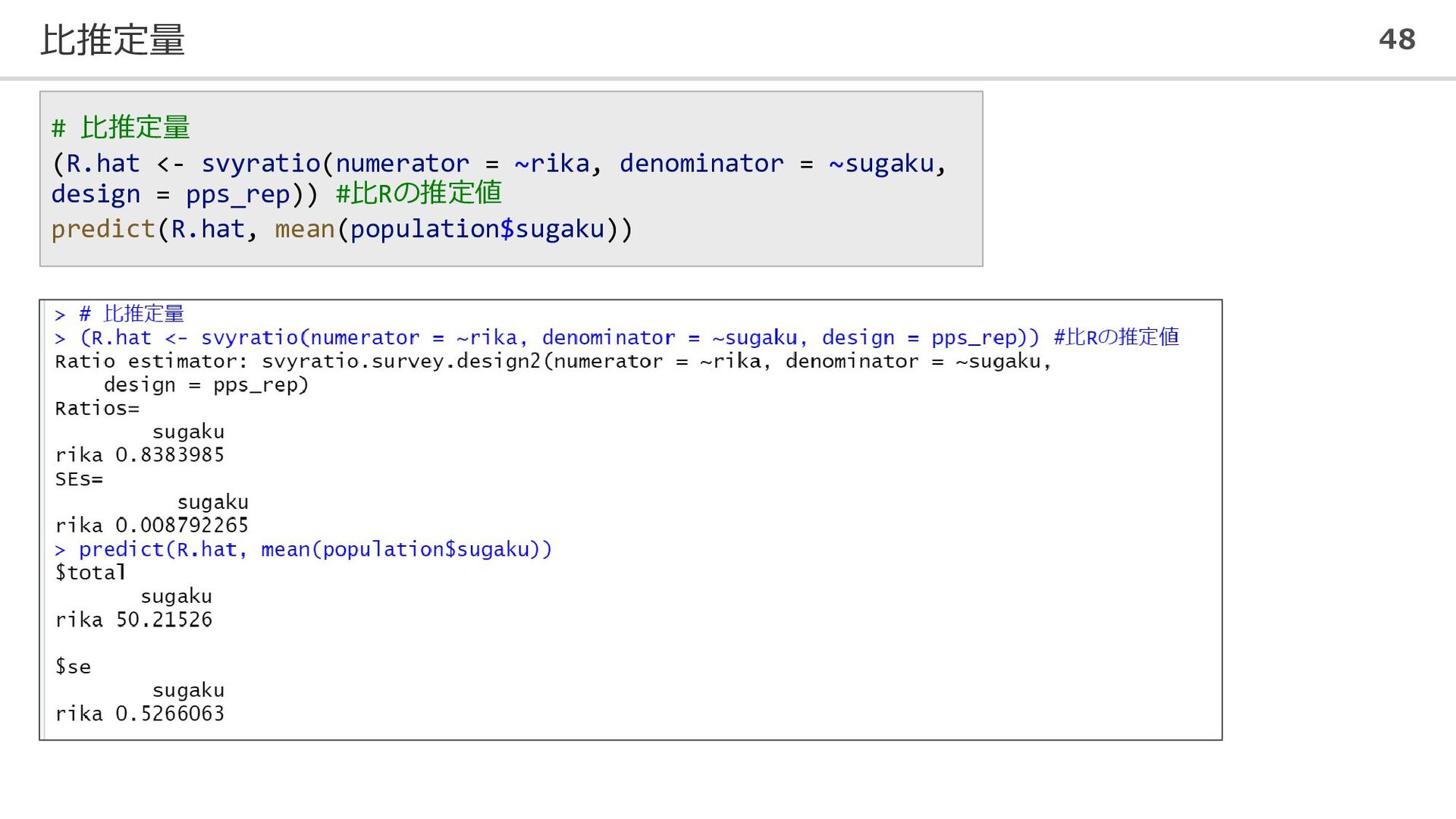
比推定量 48 # 比推定量 (R.hat <- svyratio(numerator = ~rika, denominator
= ~sugaku, design = pps_rep)) #比Rの推定値 predict(R.hat, mean(population$sugaku))
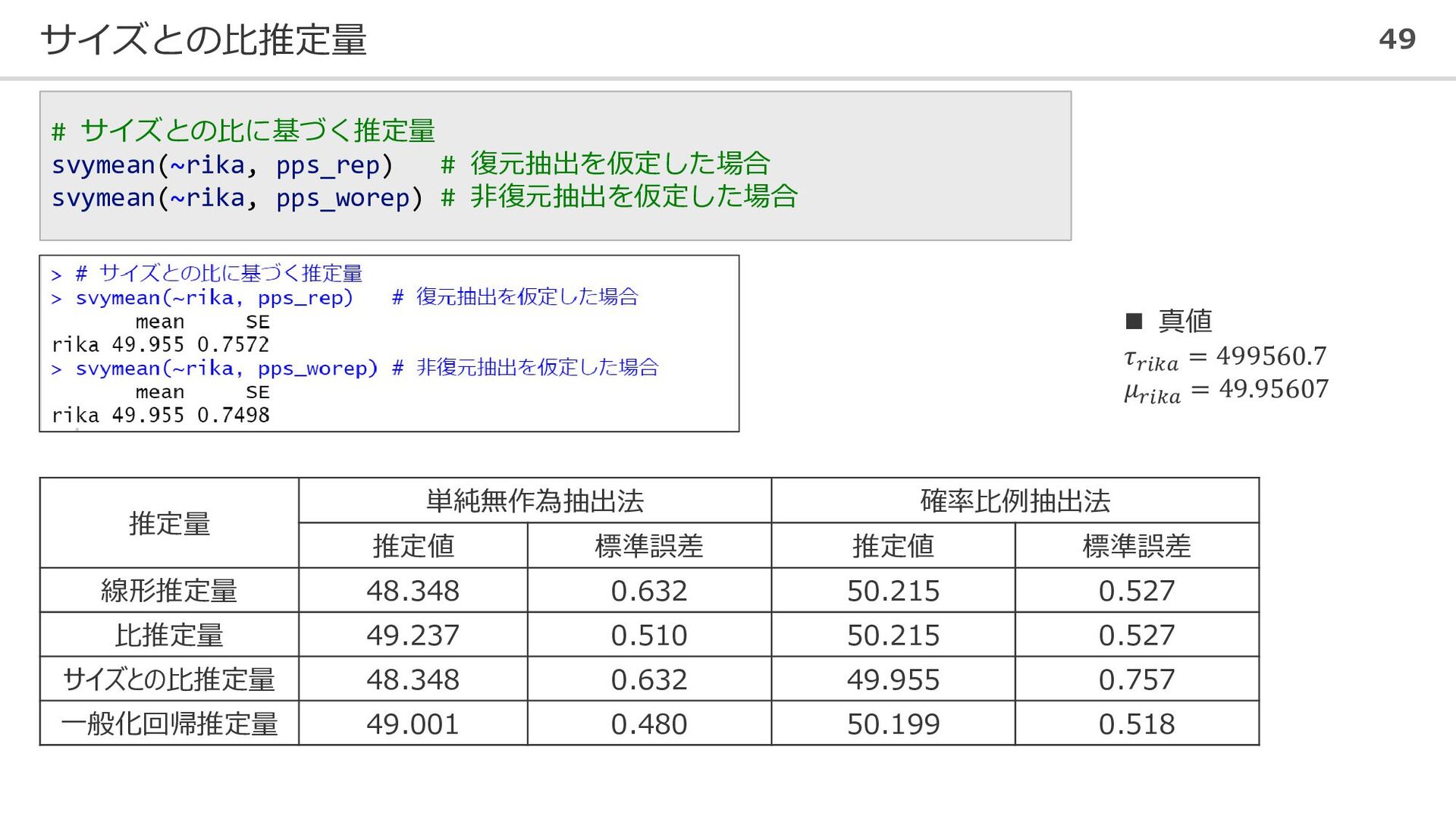
サイズとの比推定量 49 # サイズとの比に基づく推定量 svymean(~rika, pps_rep) # 復元抽出を仮定した場合 svymean(~rika, pps_worep)
# 非復元抽出を仮定した場合 推定量 単純無作為抽出法 確率比例抽出法 推定値 標準誤差 推定値 標準誤差 線形推定量 48.348 0.632 50.215 0.527 比推定量 49.237 0.510 50.215 0.527 サイズとの比推定量 48.348 0.632 49.955 0.757 一般化回帰推定量 49.001 0.480 50.199 0.518 ◼ 真値 𝜏𝑟𝑖𝑘𝑎 = 499560.7 𝜇𝑟𝑖𝑘𝑎 = 49.95607
層化抽出法 stratified sampling 50
層化抽出法の概要 P.97- 51 • 確率比例抽出では連続量の補助変数を利用して推定精度を上げたのに対して、 層化抽出法ではカテゴリカルな補助変数を利用する • 層化抽出法では、母集団𝑈をいくつかの層(stratum)に分割し、各層において 独立に標本を抽出する •
層によって目的変数の大きさが異なる場合、単純無作為抽出だと抽出される要 素が特定の層に偏る可能性があるため、層化抽出法を採用した方が良い
層化抽出の方法 p.98- 52 ⚫ 層化抽出の手続き ①母集団𝑈を互いに排反な𝐻個の層𝑈1 , … , 𝑈𝐻
に分割する。 𝑈 = 𝑈1 ∪ 𝑈2 ∪ ⋯ ∪ 𝑈ℎ ∪ ⋯ ∪ 𝑈𝐻 = ራ ℎ=1 𝐻 𝑈ℎ 第ℎ層に含まれる要素の数(層サイズ)を𝑁ℎ とする。 このとき、母集団サイズ𝑁は𝑁1 , … . 𝑁𝐻 の合計𝑁 = σℎ=1 𝐻 𝑁ℎ である。 𝑁ℎ の相対的な大きさ𝑊ℎ = 𝑁ℎ /𝑁を第ℎ層の層ウェイトと呼ぶ。 第ℎ層の統計量は、第ℎ層に含まれる要素のみで計算する。 𝜏𝑦,ℎ = 𝑈ℎ 𝑦𝑖 , 𝜇𝑦,ℎ = 1 𝑁ℎ 𝜏𝑦,ℎ ②各層において独立に標本抽出を行う。 層の間で抽出方法が異なってもよい(全数、単純無作為、確率比例など) 第ℎ層の標本サイズを𝑛ℎ としたとき、各層の標本サイズの合計は、 𝑛 = ℎ=1 𝐻 𝑛ℎ
層化抽出法における線形推定量 p.100- 53 • 母集団総計𝜏𝑦 の線形推定量 Ƹ 𝜏𝑦 やその分散の推定量
𝑉( Ƹ 𝜏𝑦 )は層ごとの統計量の 合計となる。 Ƹ 𝜏𝑦 = ℎ=1 𝐻 Ƹ 𝜏𝑦,ℎ = ℎ=1 𝐻 𝑠ℎ 𝑤𝑖 𝑦𝑖 = 𝑠 𝑤𝑖 𝑦𝑖 𝑉 Ƹ 𝜏𝑦 = ℎ=1 𝐻 𝑉( Ƹ 𝜏𝑦,ℎ ) ここで、抽出ウェイト𝑤𝑖 は、各層の抽出デザインによって決まる。 単純無作為抽出であれば 𝑤𝑖 = 𝑁ℎ 𝑛ℎ 確率比例抽出であれば 𝑤𝑖 = 𝜏𝑥,ℎ 𝑛ℎ𝑥𝑖
各層への標本サイズの割り当て p.101- 54 ⚫ 各層に割り当てる標本サイズの決め方 • Neyman割当(Neyman allocation; Neyman, 1934)
各層の抽出方法が非復元単純無作為抽出であり、全体の標本サイズ𝑛が決まっているとき、第ℎ層の 標本サイズ𝑛ℎ を次式にすると線形推定量の分散が最小になる。 𝑛ℎ = 𝑛 𝑁ℎ 𝜎𝑦,ℎ σ ℎ=1 𝐻 𝑁ℎ 𝜎𝑦,ℎ これは、層のサイズ𝑁ℎ が大きく、また層標準偏差𝜎𝑦,ℎ が大きい層ほど、標本サイズ𝑛ℎ を大きくする ことを意味する。(そのような層は推定量の分散が大きくなるため。) ※ただし、正確な𝜎𝑦,ℎ は分からないため、類似の調査結果や補助変数𝑥の層標準偏差で代替する。 • 比例割当(proportional allocation) 標本サイズを層サイズに比例させる。これはすべての層標準偏差𝜎𝑦,ℎ が等しい状況での Neyman割当に相当する。最も採用例が多い。 𝑛ℎ = 𝑛 𝑁ℎ 𝑁 • 均等割当(equal allocation) 全ての層の標本サイズを等しくする。 𝑛ℎ = 𝑛 𝐻
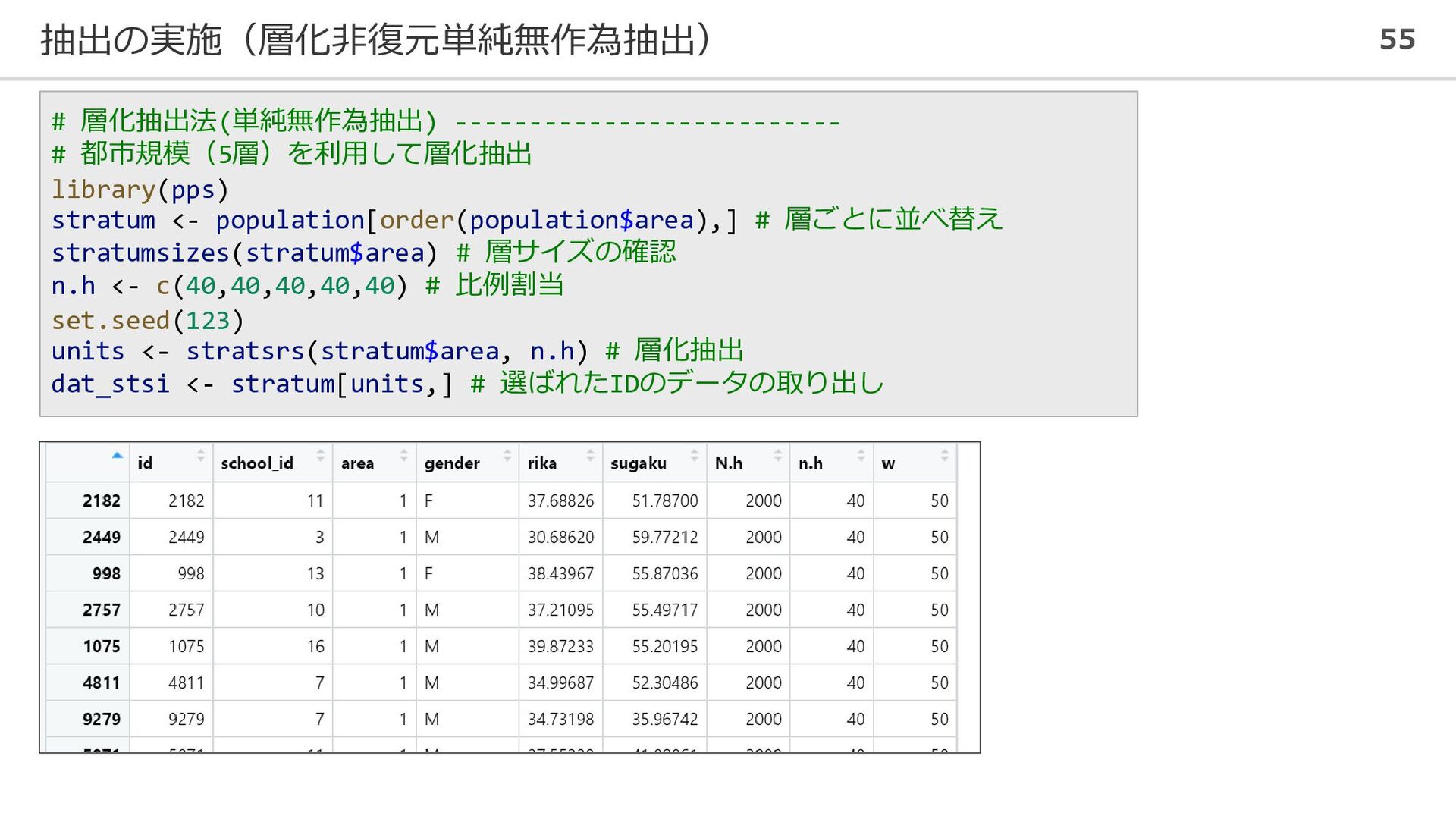
抽出の実施(層化非復元単純無作為抽出) 55 # 層化抽出法(単純無作為抽出) -------------------------- # 都市規模(5層)を利用して層化抽出 library(pps) stratum <-
population[order(population$area),] # 層ごとに並べ替え stratumsizes(stratum$area) # 層サイズの確認 n.h <- c(40,40,40,40,40) # 比例割当 set.seed(123) units <- stratsrs(stratum$area, n.h) # 層化抽出 dat_stsi <- stratum[units,] # 選ばれたIDのデータの取り出し
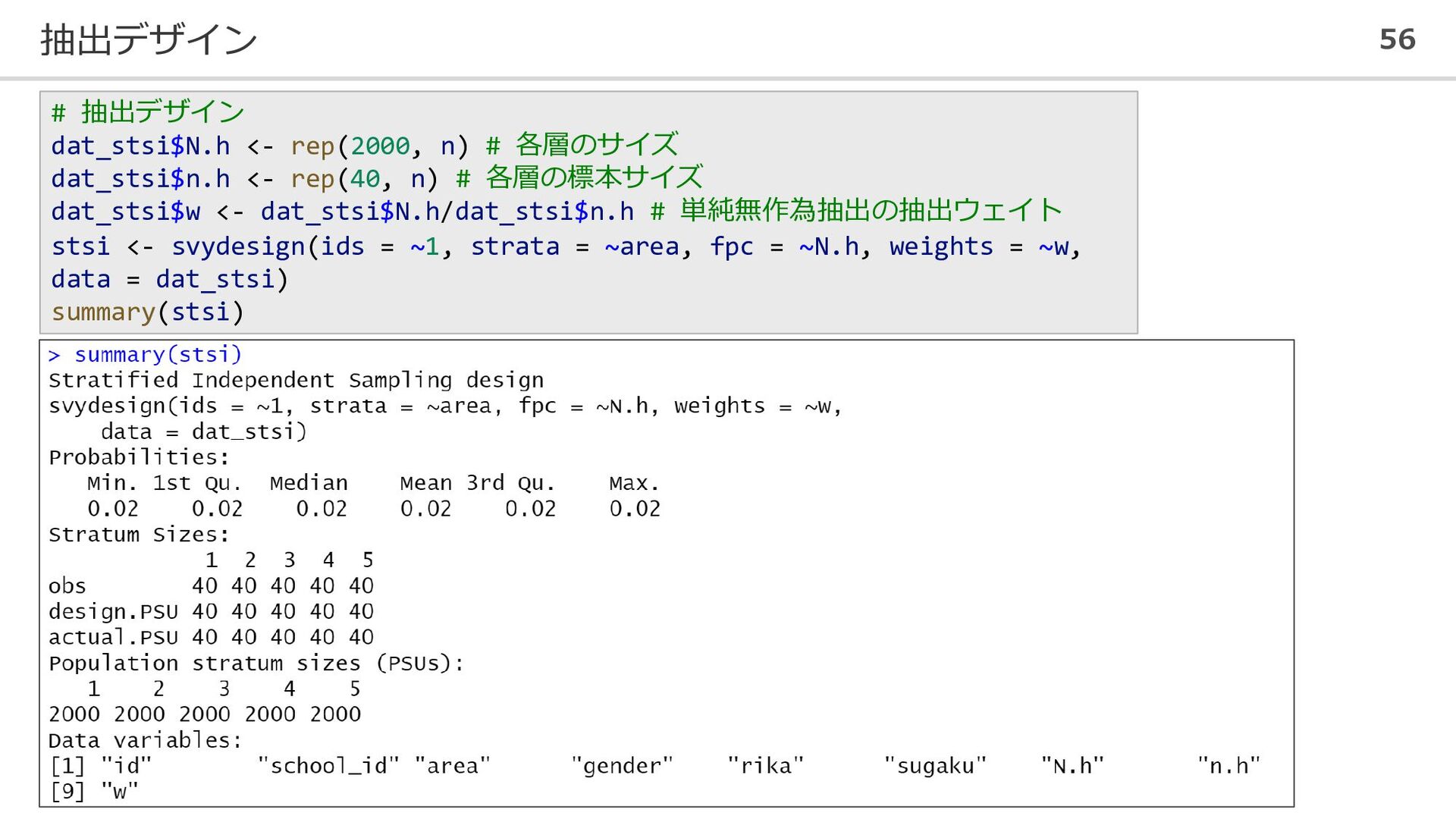
抽出デザイン 56 # 抽出デザイン dat_stsi$N.h <- rep(2000, n) # 各層のサイズ
dat_stsi$n.h <- rep(40, n) # 各層の標本サイズ dat_stsi$w <- dat_stsi$N.h/dat_stsi$n.h # 単純無作為抽出の抽出ウェイト stsi <- svydesign(ids = ~1, strata = ~area, fpc = ~N.h, weights = ~w, data = dat_stsi) summary(stsi)
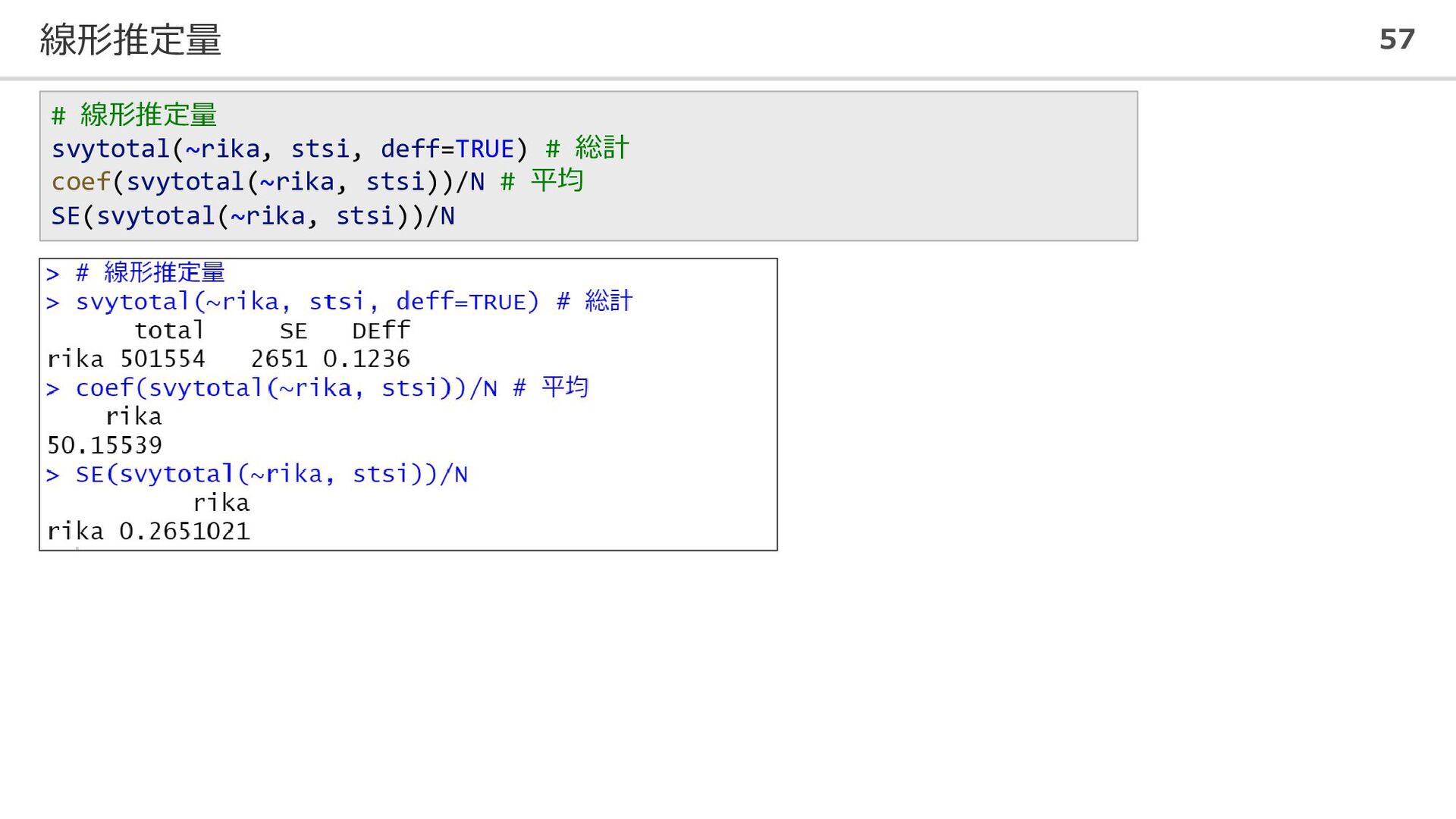
線形推定量 57 # 線形推定量 svytotal(~rika, stsi, deff=TRUE) # 総計 coef(svytotal(~rika,
stsi))/N # 平均 SE(svytotal(~rika, stsi))/N
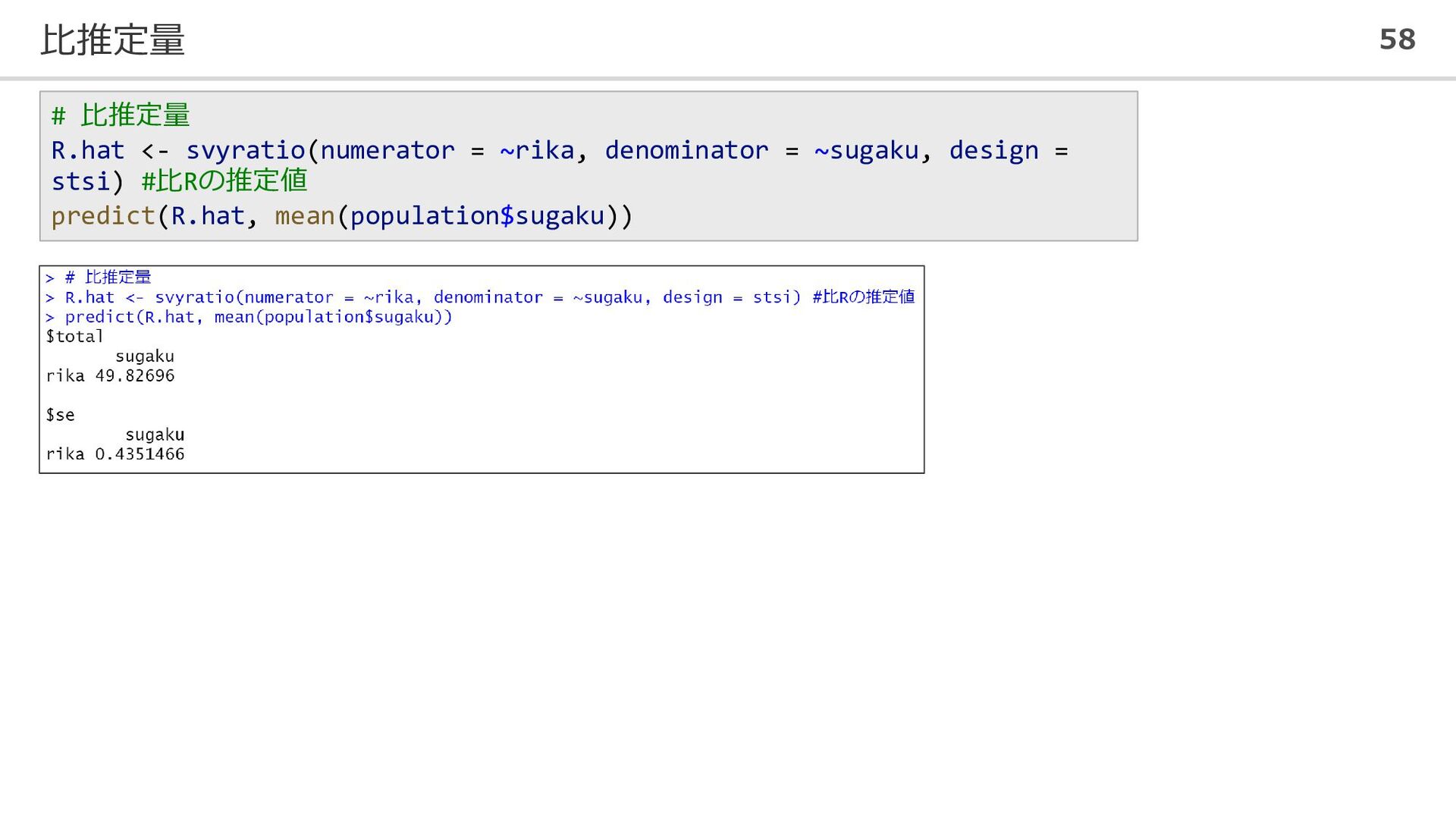
比推定量 58 # 比推定量 R.hat <- svyratio(numerator = ~rika, denominator
= ~sugaku, design = stsi) #比Rの推定値 predict(R.hat, mean(population$sugaku))
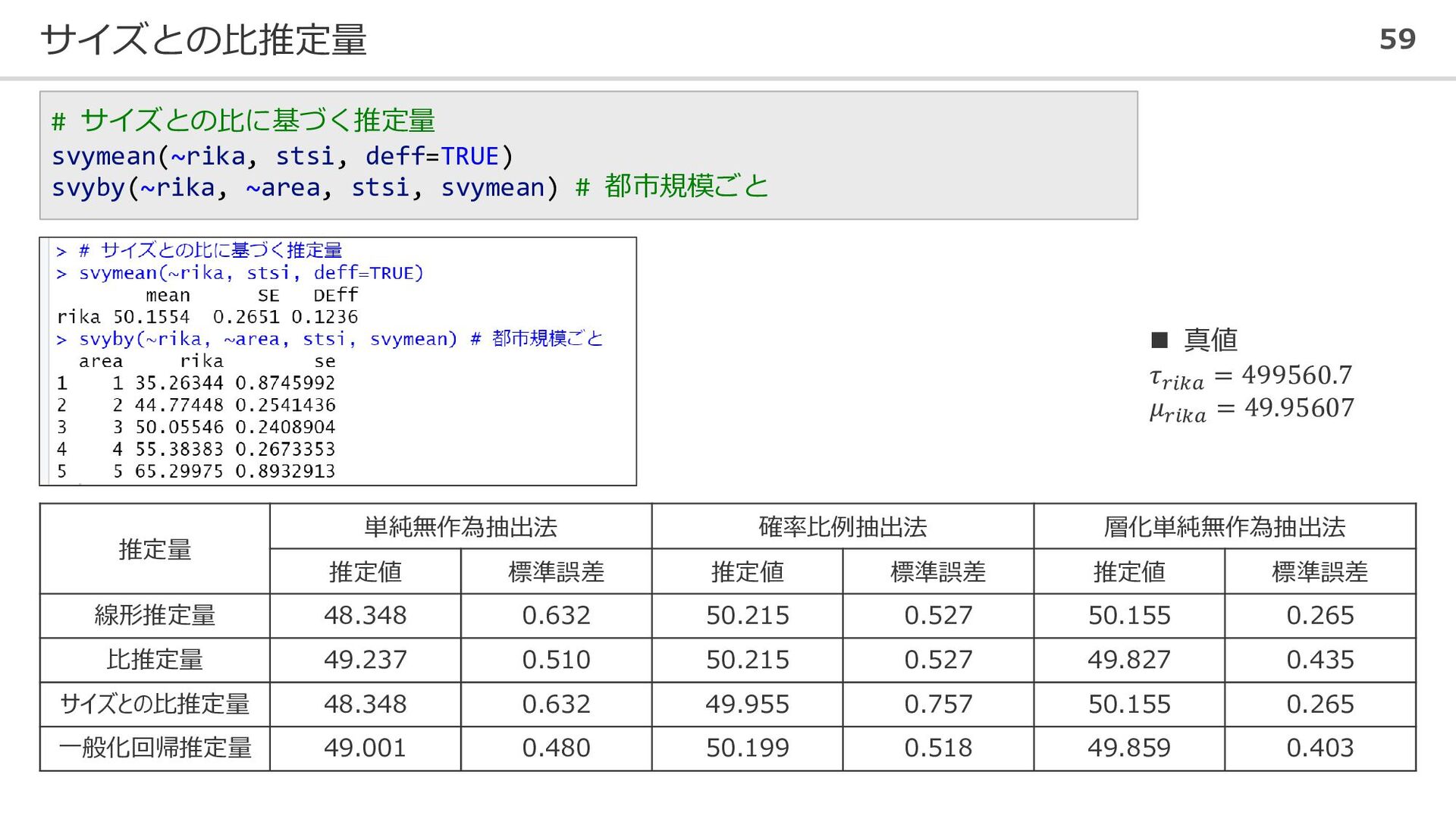
サイズとの比推定量 59 # サイズとの比に基づく推定量 svymean(~rika, stsi, deff=TRUE) svyby(~rika, ~area, stsi,
svymean) # 都市規模ごと 推定量 単純無作為抽出法 確率比例抽出法 層化単純無作為抽出法 推定値 標準誤差 推定値 標準誤差 推定値 標準誤差 線形推定量 48.348 0.632 50.215 0.527 50.155 0.265 比推定量 49.237 0.510 50.215 0.527 49.827 0.435 サイズとの比推定量 48.348 0.632 49.955 0.757 50.155 0.265 一般化回帰推定量 49.001 0.480 50.199 0.518 49.859 0.403 ◼ 真値 𝜏𝑟𝑖𝑘𝑎 = 499560.7 𝜇𝑟𝑖𝑘𝑎 = 49.95607
集落抽出法(クラスター抽出法) cluster sampling 60
クラスター抽出法の概要 p.135- 61 • クラスター抽出法では、要素のまとまりであるクラスターを抽出単位とする。 – 例)学校を単位とした抽出 • 一般に、要素を単位とするよりも推定精度は下がるが、調査実施の難易度も下がる •
クラスター抽出法ではクラスターのリストさえ用意すればよく、母集団の全要素の リストは必要ない • 同一クラスター内の要素は似たような性質を持ちやすいため、標本に含まれる情報 が重複しムダの多い抽出法になってしまう ⇒精度の低下
クラスター抽出の方法 p.137- 62 ①母集団𝑈を𝑀個のクラスター𝑈1 , … , 𝑈𝑀 に分割する 𝑈
= 𝑈1 ∪ 𝑈2 ∪ ⋯ ∪ 𝑈𝑀 = ራ 𝑎∈𝑈I 𝑈𝑎 第𝑎クラスターに含まれる要素の数(クラスターサイズ)を𝑁𝑎 とする。 𝑁 = 𝑎∈𝑈I 𝑁𝑎 母集団総計𝜏𝑦 はクラスター総計𝜏𝑦,1 , … , 𝜏𝑦,𝑀 の合計である。 𝜏𝑦 = 𝜏𝑦,1 + ⋯ + 𝜏𝑦,𝑀 = 𝑎∈𝑈I 𝜏𝑦,𝑎 ②𝑚個のクラスターを任意の抽出法で抽出する。 抽出法は何でも良いが、一般的に単純無作為抽出よりもクラスターサイズ を補助変数とした確率比例抽出や層化抽出をする方が精度が高い。 なお、標本サイズ𝑛はクラスターサイズの合計である。 𝑛 = 𝑎∈𝑠I 𝑛𝑎
クラスター抽出法における線形推定量 p.139- 63 • これまで要素と単位としていた計算をクラスターに置き換えて考えればよい • 母集団総計𝜏𝑦 の線形推定量 Ƹ 𝜏𝑦
は以下の通りである Ƹ 𝜏𝑦 = 𝑎∈𝑠I 𝑤𝑎 𝜏𝑦,𝑎 = 𝑎∈𝑠I 𝑤𝑎 𝑖∈𝑈𝑎 𝑦𝑖 = 𝑎∈𝑠I 𝑖∈𝑈𝑎 𝑤𝑎 𝑦𝑖 ここで、抽出ウェイト𝑤𝑎 は、クラスターの抽出デザインによって決まる。 単純無作為抽出であれば 𝑤𝑎 = 𝑀 𝑚 確率比例抽出であれば 𝑤𝑎 = 𝜏𝑥 (𝑚𝜏𝑥,𝑎)
抽出の実施(非復元単純無作為クラスター抽出) 64 # 単純無作為クラスター抽出法----------------------------------- # 学校を単位としてクラスター抽出 M <- 100 #
クラスター数 m <- 10 # 抽出数 set.seed(123) clusters <- sample(unique(population$school_id), size=m, replace=F) # クラスター抽出 dat_sic <- subset(population, school_id %in% clusters) # 選ばれた学校IDの取り出し
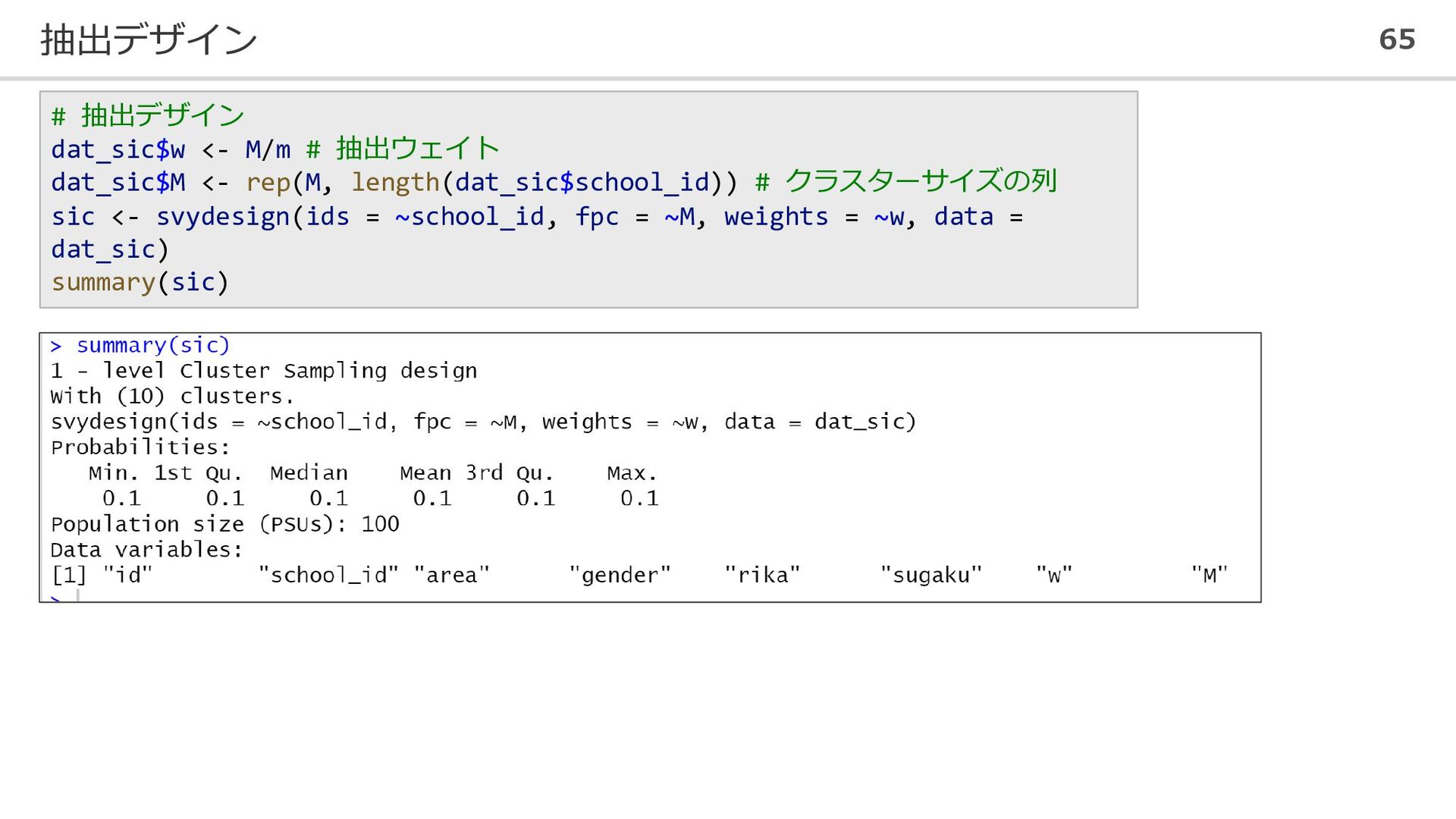
抽出デザイン 65 # 抽出デザイン dat_sic$w <- M/m # 抽出ウェイト dat_sic$M
<- rep(M, length(dat_sic$school_id)) # クラスターサイズの列 sic <- svydesign(ids = ~school_id, fpc = ~M, weights = ~w, data = dat_sic) summary(sic)
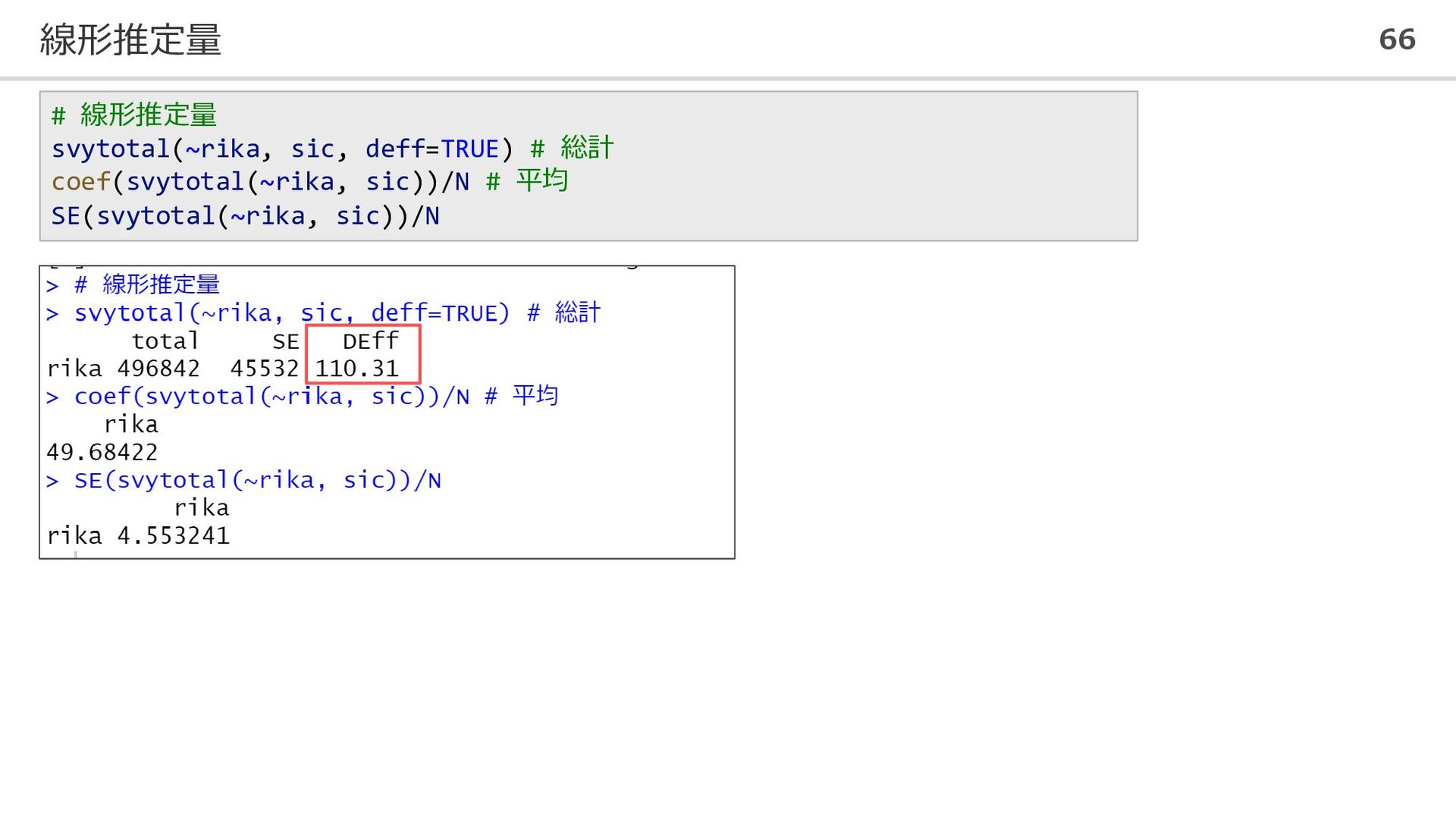
線形推定量 66 # 線形推定量 svytotal(~rika, sic, deff=TRUE) # 総計 coef(svytotal(~rika,
sic))/N # 平均 SE(svytotal(~rika, sic))/N
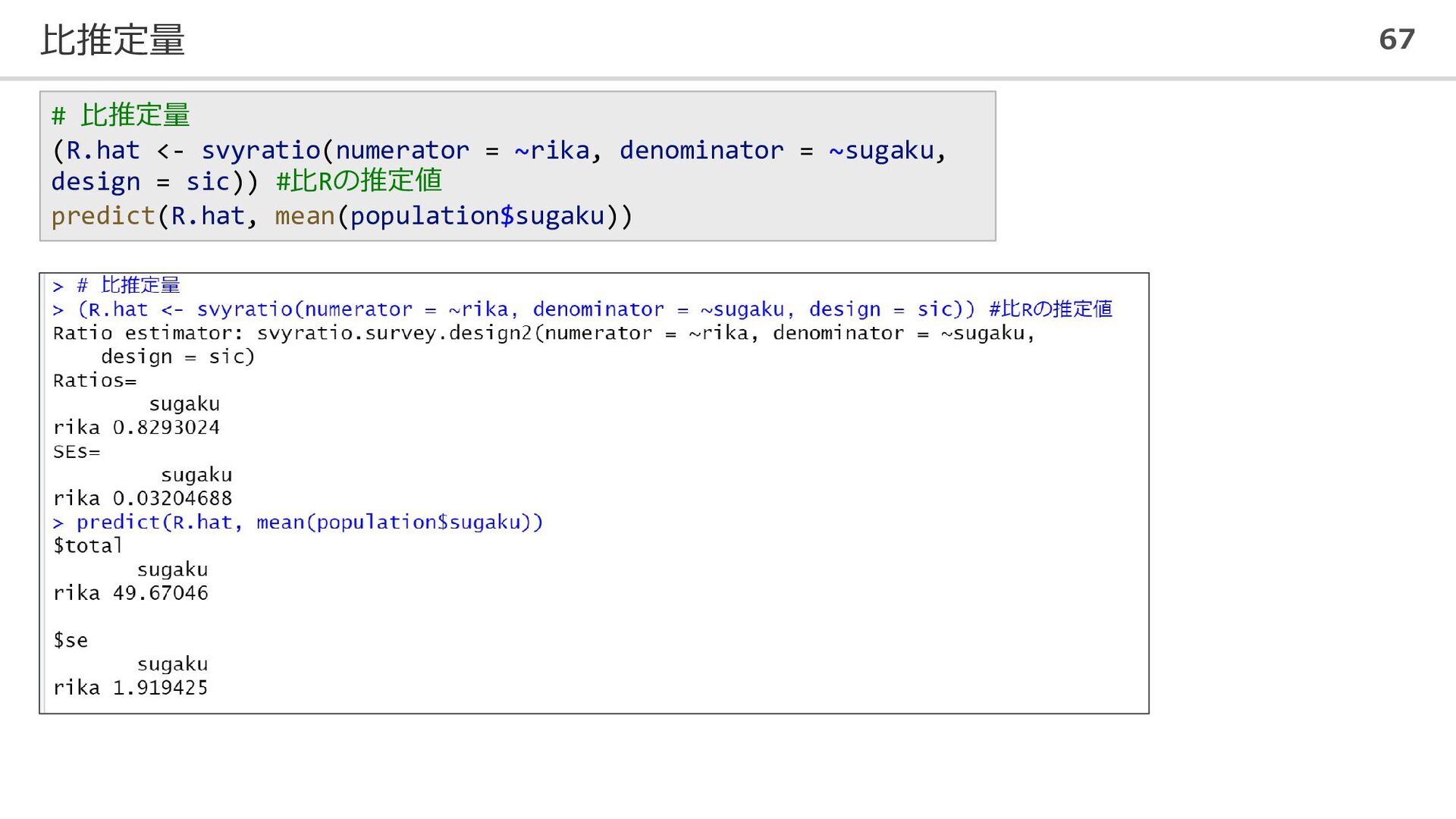
比推定量 67 # 比推定量 (R.hat <- svyratio(numerator = ~rika, denominator
= ~sugaku, design = sic)) #比Rの推定値 predict(R.hat, mean(population$sugaku))
サイズとの比推定量 68 # サイズとの比に基づく推定量 svymean(~rika, sic, deff=TRUE) 推定量 単純無作為抽出法(n=1000) 単純無作為クラスター抽出法
推定値 標準誤差 推定値 標準誤差 線形推定量 49.967 0.295 49.684 4.553 比推定量 49.869 0.224 49.670 1.919 サイズとの比推定量 49.967 0.295 49.684 4.553 一般化回帰推定量 49.890 0.218 49.668 1.468 ◼ 真値 𝜏𝑟𝑖𝑘𝑎 = 499560.7 𝜇𝑟𝑖𝑘𝑎 = 49.95607
抽出の実施(確率比例クラスター抽出) 69 # 確率比例クラスター抽出 ----------------------------------------- school <- data.frame(id=1:M, ssize=rep(100, 100))
# 学校一覧の作成 library(pps) set.seed(123) randomize <- school[sample(nrow(school)),] # 無作為並べ替え set.seed(123) units <- ppss(randomize$ssize, m) # 系統抽出 clusters <- randomize[units,]$id # 学校IDの抽出 dat_ppsc <- subset(population, school_id %in% clusters) # 該当校に所属する生徒の抽出
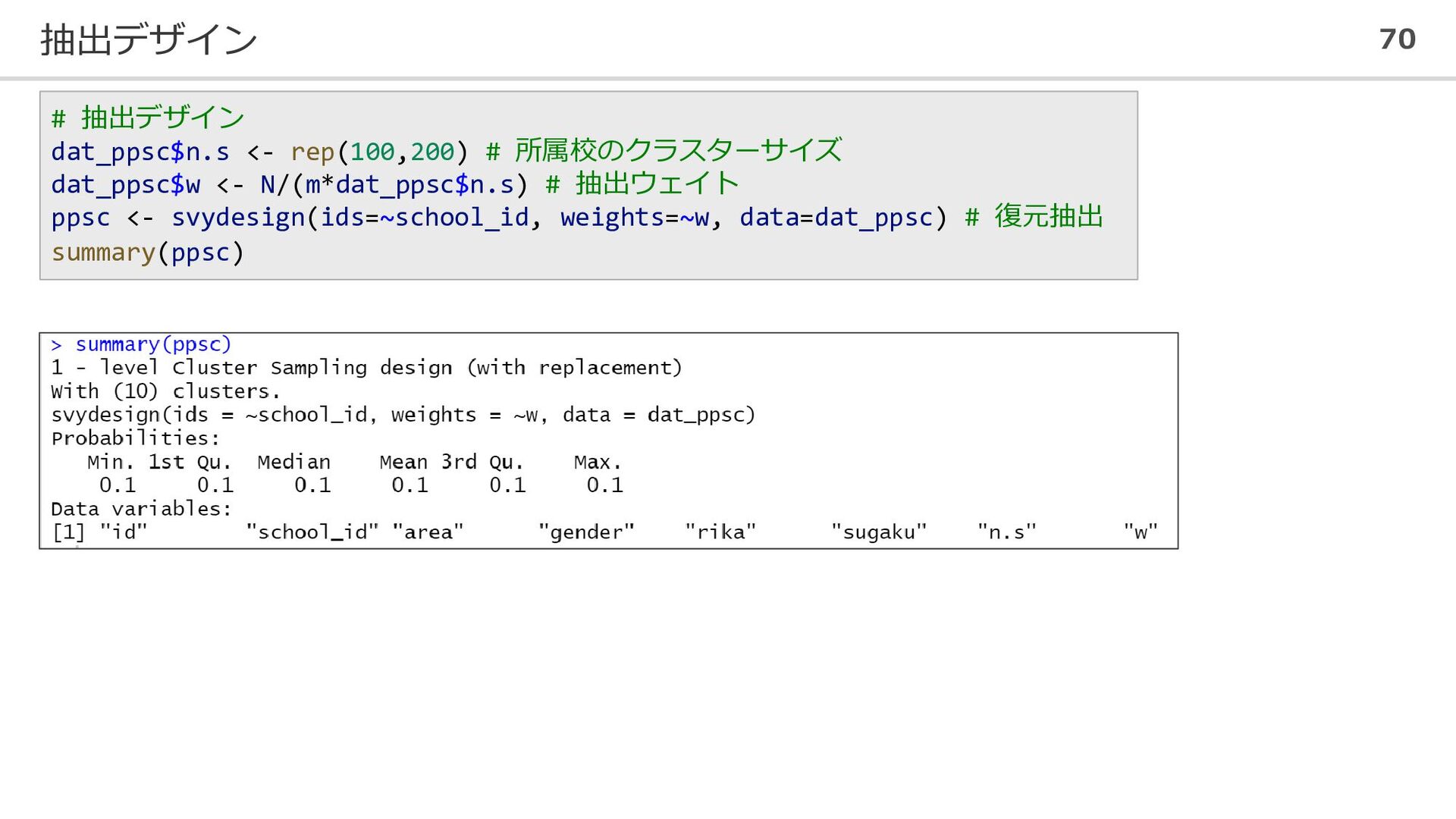
抽出デザイン 70 # 抽出デザイン dat_ppsc$n.s <- rep(100,200) # 所属校のクラスターサイズ dat_ppsc$w
<- N/(m*dat_ppsc$n.s) # 抽出ウェイト ppsc <- svydesign(ids=~school_id, weights=~w, data=dat_ppsc) # 復元抽出 summary(ppsc)
線形推定量 71 # 線形推定量 svytotal(~rika, ppsc, deff=TRUE) coef(svytotal(~rika, ppsc)) /
N SE(svytotal(~rika, ppsc)) / N
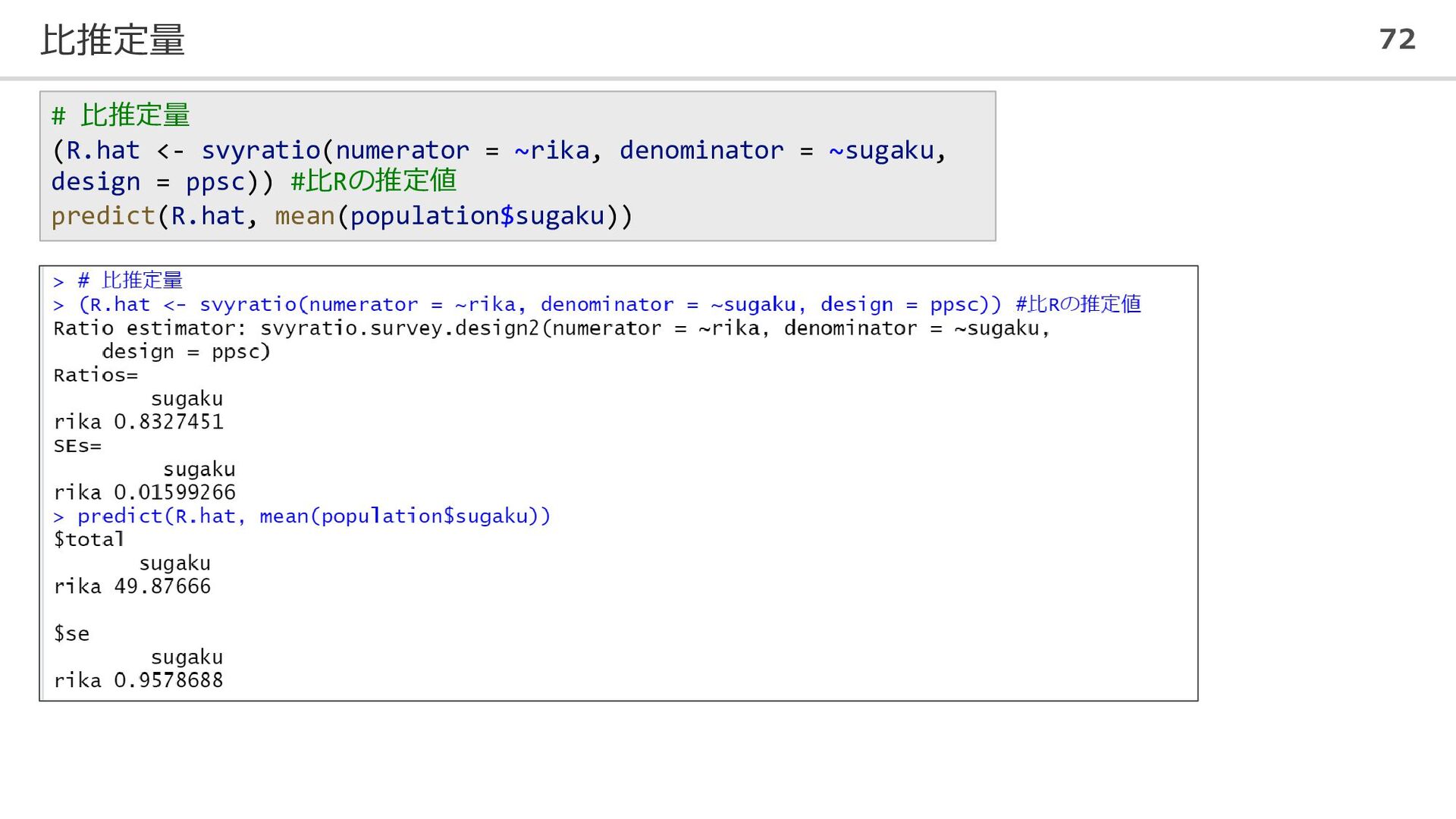
比推定量 72 # 比推定量 (R.hat <- svyratio(numerator = ~rika, denominator
= ~sugaku, design = ppsc)) #比Rの推定値 predict(R.hat, mean(population$sugaku))
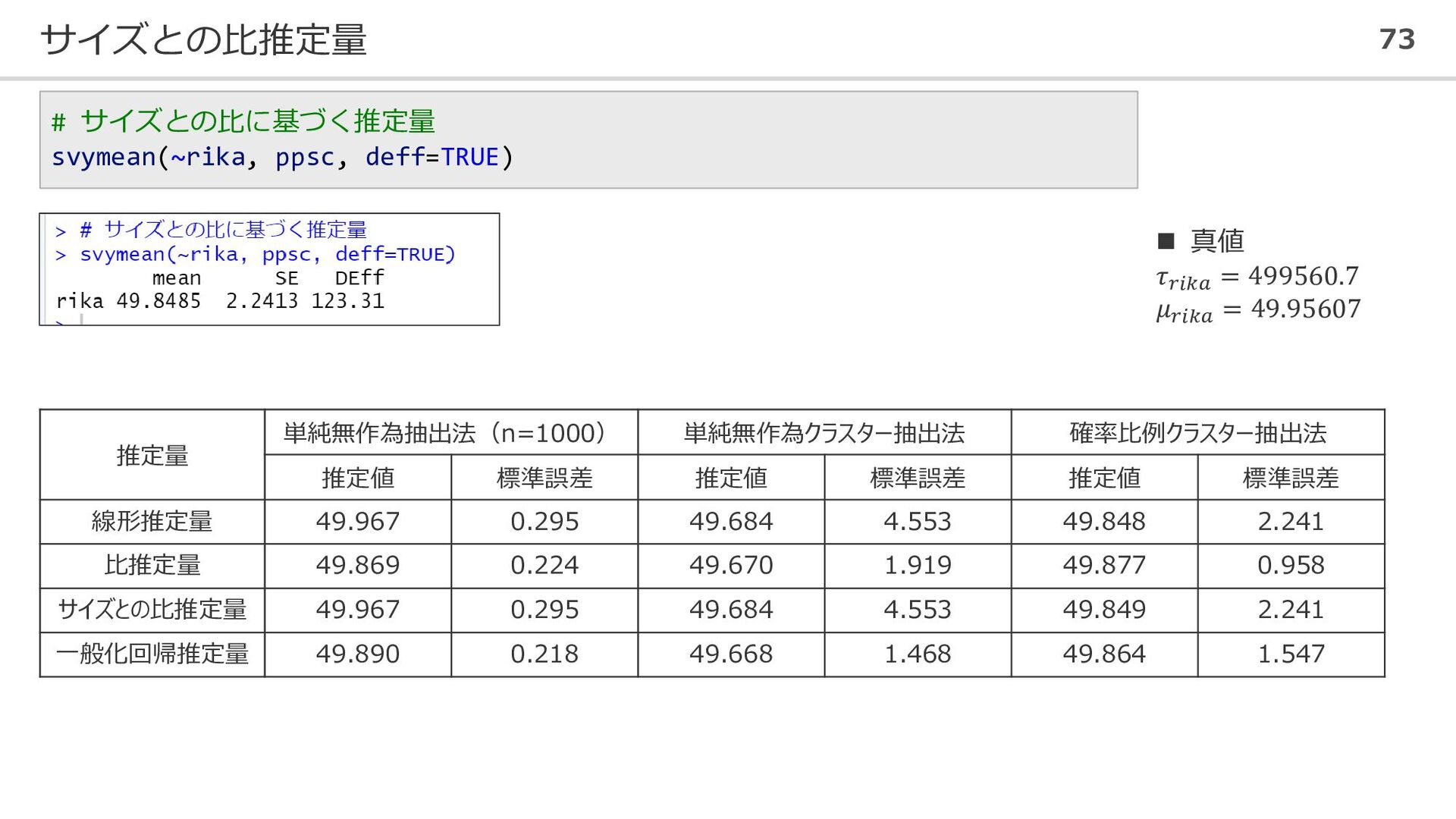
サイズとの比推定量 73 # サイズとの比に基づく推定量 svymean(~rika, ppsc, deff=TRUE) 推定量 単純無作為抽出法(n=1000) 単純無作為クラスター抽出法
確率比例クラスター抽出法 推定値 標準誤差 推定値 標準誤差 推定値 標準誤差 線形推定量 49.967 0.295 49.684 4.553 49.848 2.241 比推定量 49.869 0.224 49.670 1.919 49.877 0.958 サイズとの比推定量 49.967 0.295 49.684 4.553 49.849 2.241 一般化回帰推定量 49.890 0.218 49.668 1.468 49.864 1.547 ◼ 真値 𝜏𝑟𝑖𝑘𝑎 = 499560.7 𝜇𝑟𝑖𝑘𝑎 = 49.95607
層化確率比例クラスター抽出 stratified probability proportional cluster sampling 74
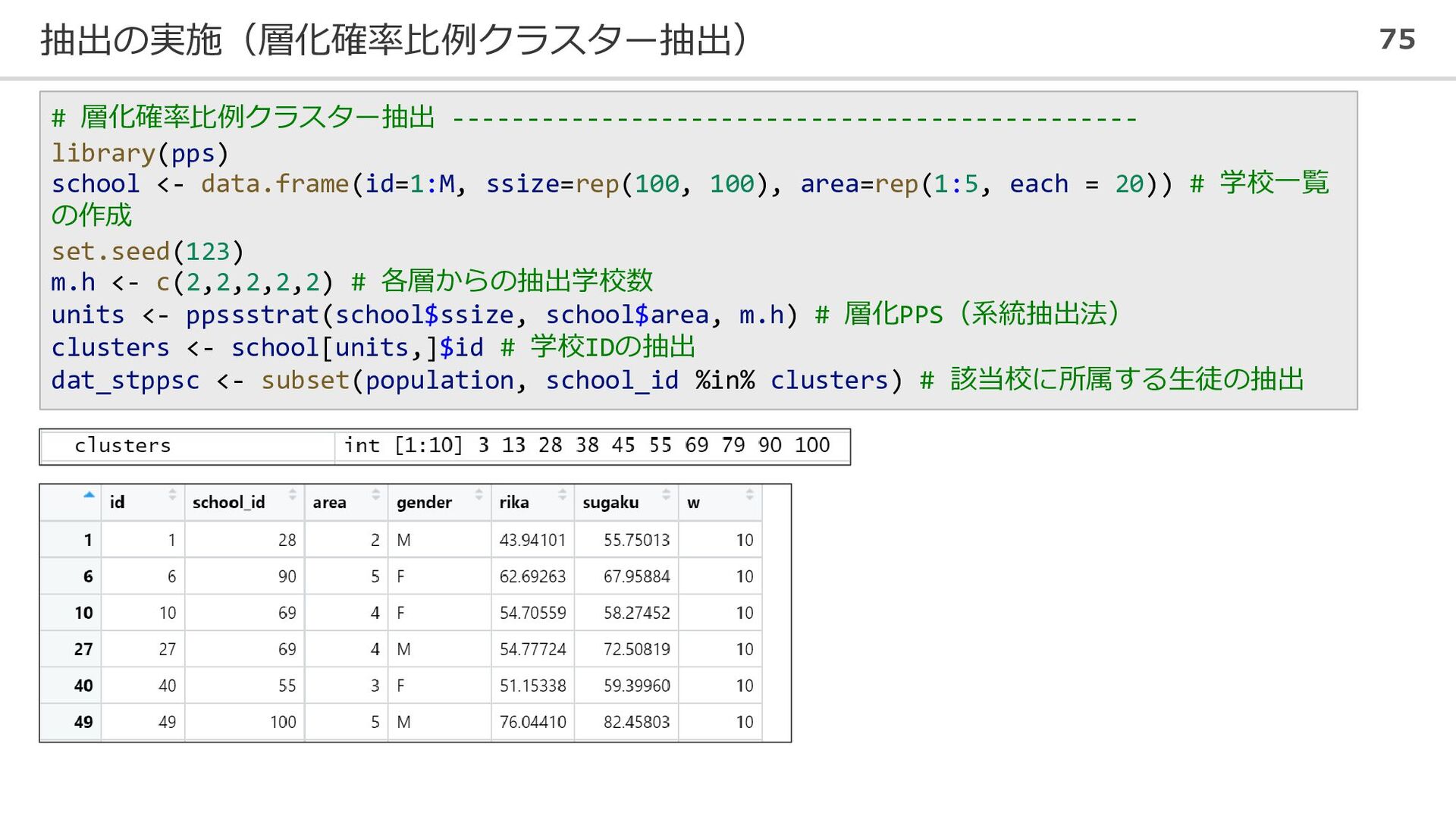
抽出の実施(層化確率比例クラスター抽出) 75 # 層化確率比例クラスター抽出 ---------------------------------------------- library(pps) school <- data.frame(id=1:M, ssize=rep(100,
100), area=rep(1:5, each = 20)) # 学校一覧 の作成 set.seed(123) m.h <- c(2,2,2,2,2) # 各層からの抽出学校数 units <- ppssstrat(school$ssize, school$area, m.h) # 層化PPS(系統抽出法) clusters <- school[units,]$id # 学校IDの抽出 dat_stppsc <- subset(population, school_id %in% clusters) # 該当校に所属する生徒の抽出
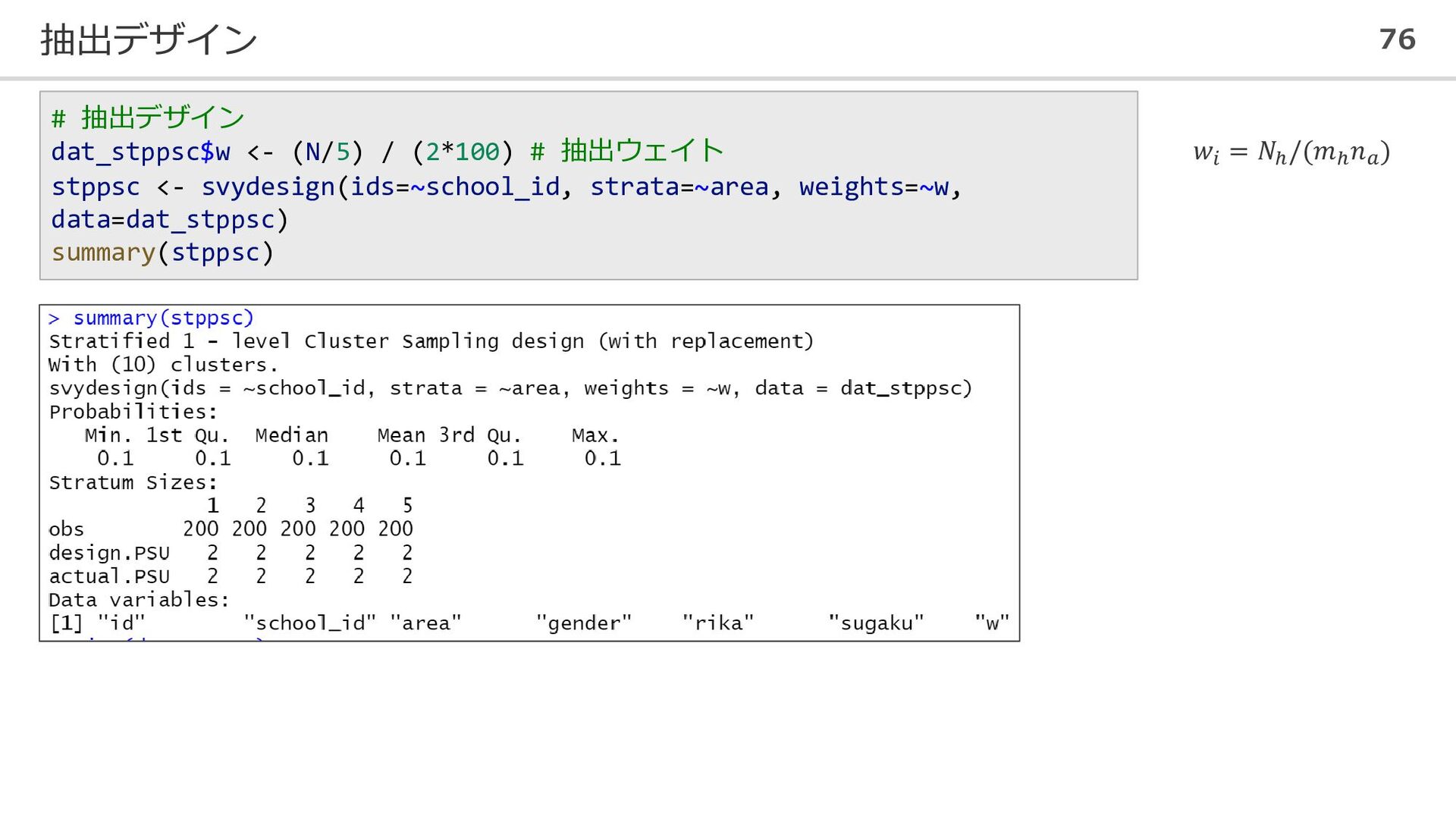
抽出デザイン 76 # 抽出デザイン dat_stppsc$w <- (N/5) / (2*100) #
抽出ウェイト stppsc <- svydesign(ids=~school_id, strata=~area, weights=~w, data=dat_stppsc) summary(stppsc) 𝑤𝑖 = 𝑁ℎ /(𝑚ℎ 𝑛𝑎 )
線形推定量 77 # 線形推定量 svytotal(~rika, stppsc, deff=TRUE) coef(svytotal(~rika, stppsc)) /
N SE(svytotal(~rika, stppsc)) / N
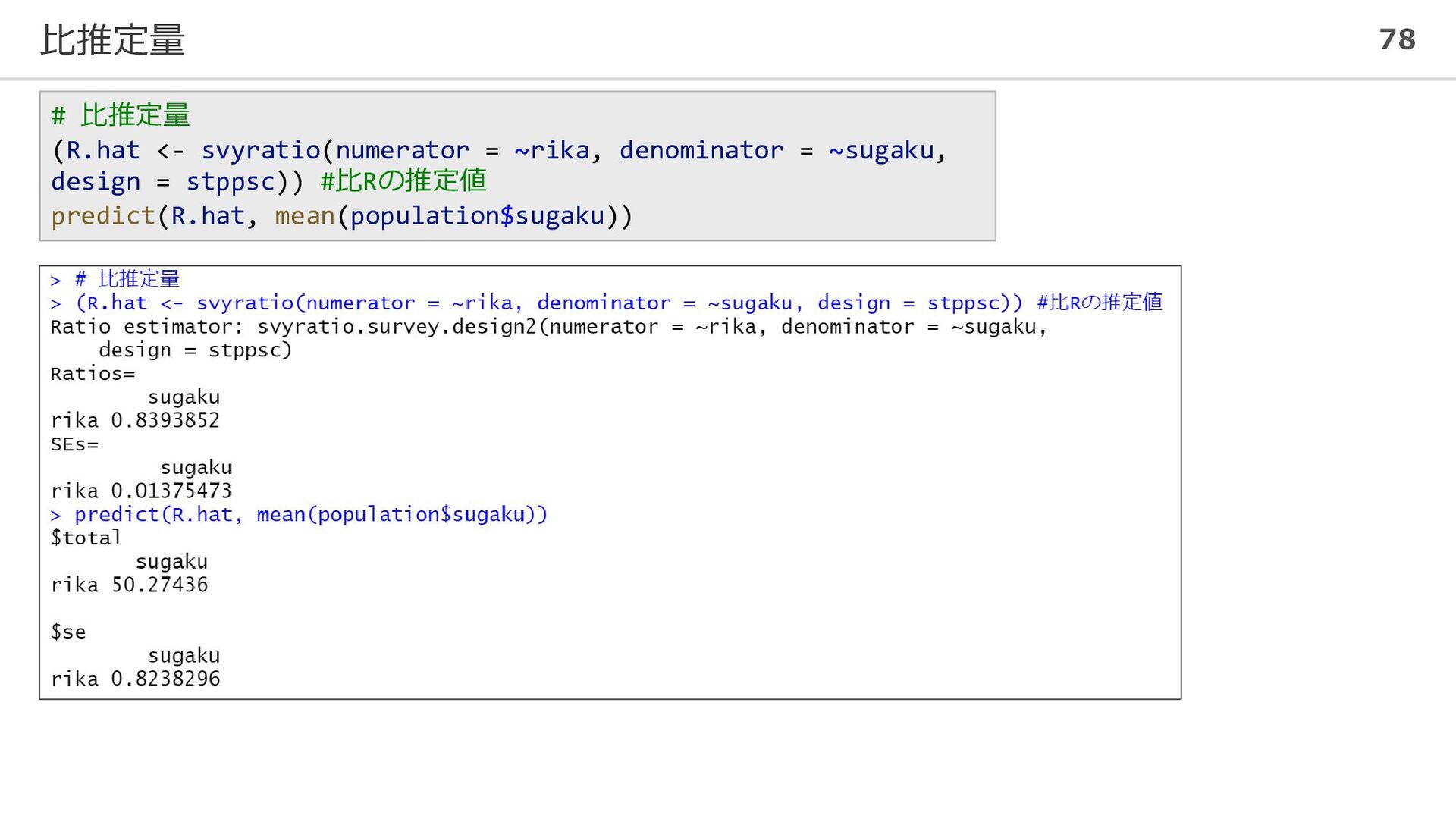
比推定量 78 # 比推定量 (R.hat <- svyratio(numerator = ~rika, denominator
= ~sugaku, design = stppsc)) #比Rの推定値 predict(R.hat, mean(population$sugaku))
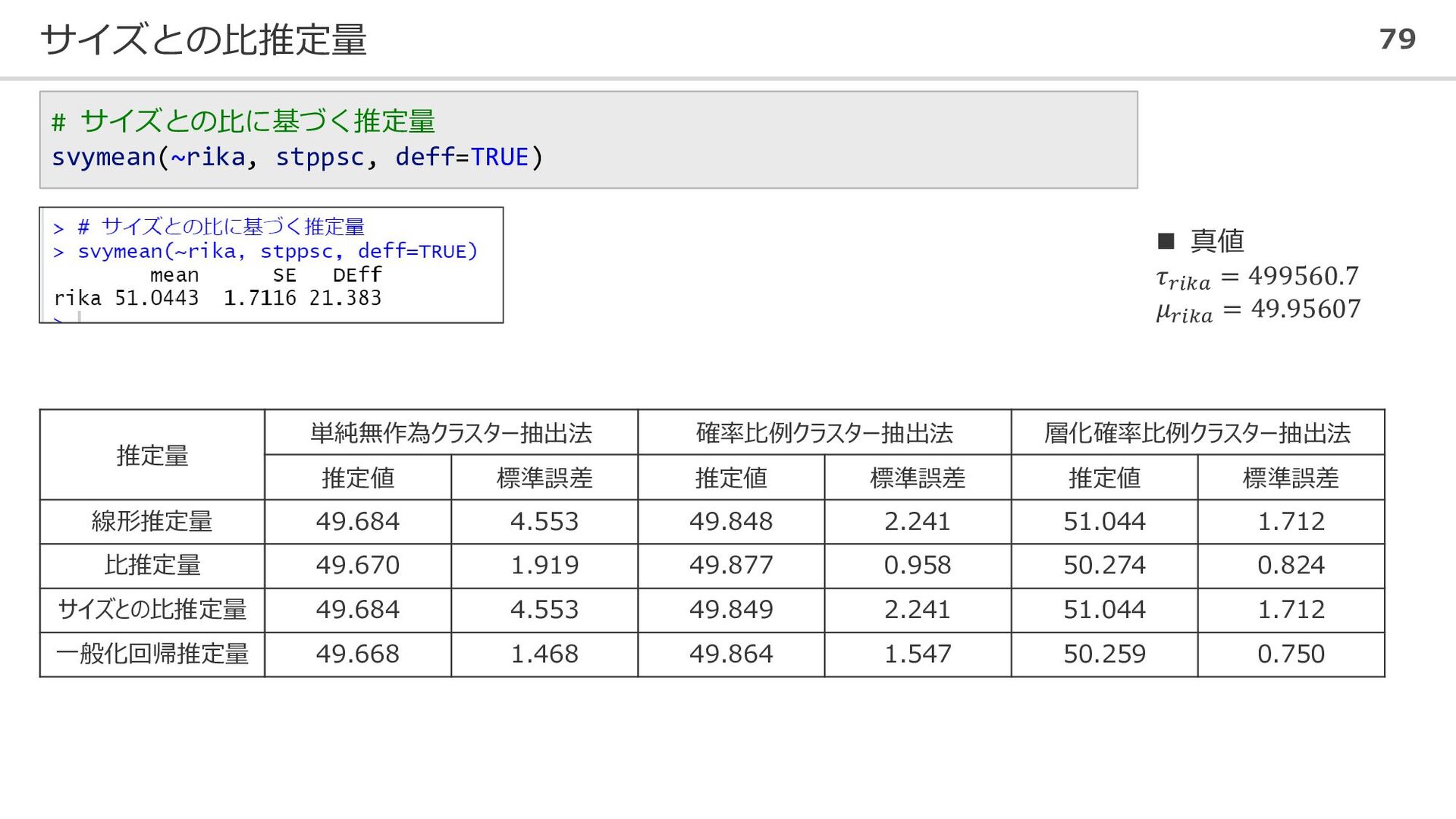
サイズとの比推定量 79 # サイズとの比に基づく推定量 svymean(~rika, stppsc, deff=TRUE) 推定量 単純無作為クラスター抽出法 確率比例クラスター抽出法
層化確率比例クラスター抽出法 推定値 標準誤差 推定値 標準誤差 推定値 標準誤差 線形推定量 49.684 4.553 49.848 2.241 51.044 1.712 比推定量 49.670 1.919 49.877 0.958 50.274 0.824 サイズとの比推定量 49.684 4.553 49.849 2.241 51.044 1.712 一般化回帰推定量 49.668 1.468 49.864 1.547 50.259 0.750 ◼ 真値 𝜏𝑟𝑖𝑘𝑎 = 499560.7 𝜇𝑟𝑖𝑘𝑎 = 49.95607
まとめ summary 80
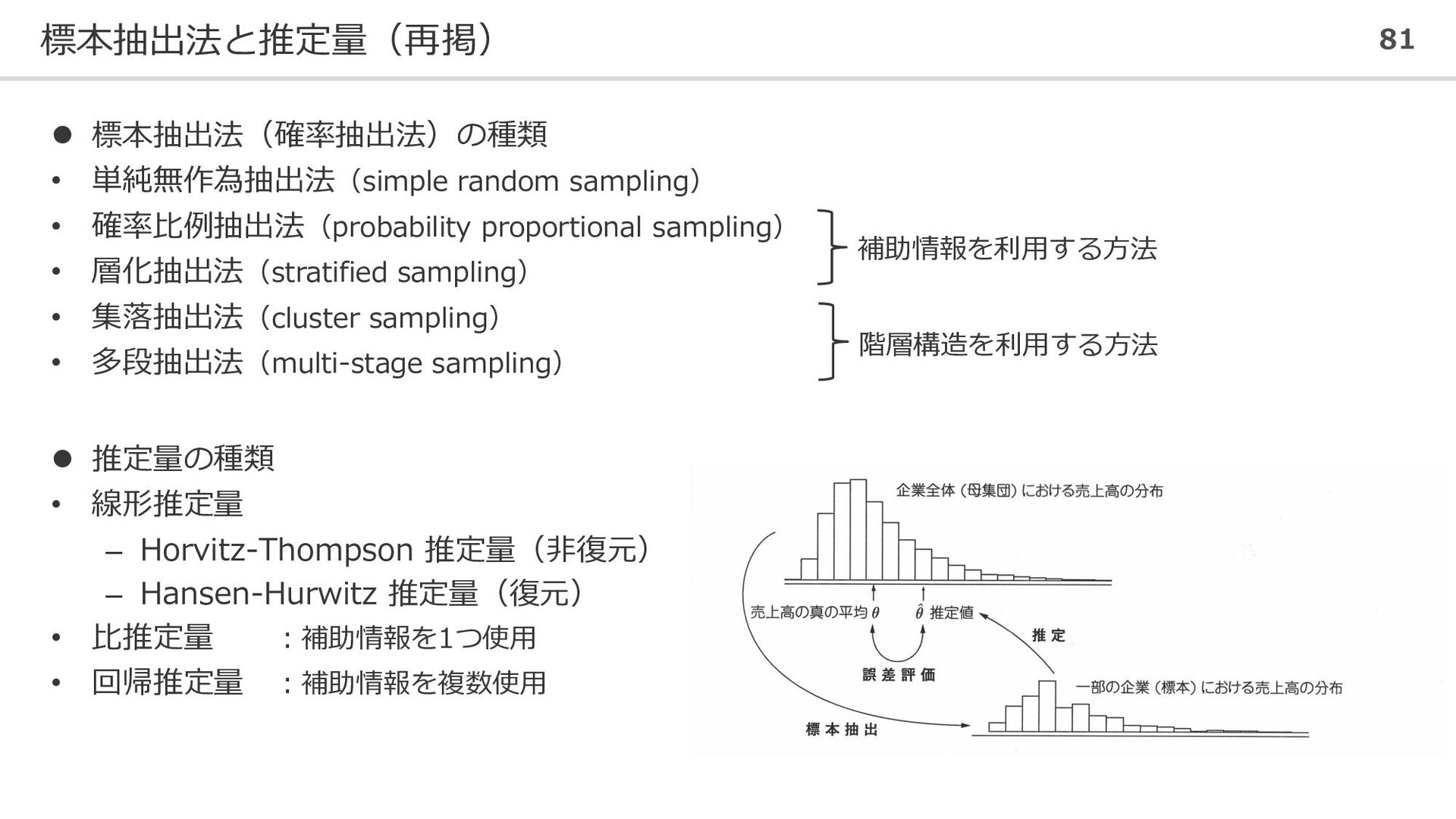
標本抽出法と推定量(再掲) 81 ⚫ 標本抽出法(確率抽出法)の種類 • 単純無作為抽出法(simple random sampling) • 確率比例抽出法(probability
proportional sampling) • 層化抽出法(stratified sampling) • 集落抽出法(cluster sampling) • 多段抽出法(multi-stage sampling) 階層構造を利用する方法 補助情報を利用する方法 ⚫ 推定量の種類 • 線形推定量 – Horvitz-Thompson 推定量(非復元) – Hansen-Hurwitz 推定量(復元) • 比推定量 :補助情報を1つ使用 • 回帰推定量 :補助情報を複数使用
まとめ 82 ⚫ 目的変数と相関の高い補助変数を活用することで推定の精度を高めることができる – 母数+全要素の値が分かっている場合は抽出段階で活用 ➢連続量:確率比例抽出法、カテゴリカル:層化抽出 – 母数のみ分かっている場合は推定段階で活用 ➢単一:比推定量、複数:一般化回帰推定量
⚫ クラスターを単位とした抽出の場合、クラスター内の類似度が高いほど抽出の効率は悪く なる ⚫ 今日の講習会をきっかけに標本抽出法に興味を持ってくださる方が 増えると嬉しいです。 ⚫ 質問などありましたらいつでもメールで受け付けます。 ⚫ この講習会は完全ボランティアで実施しています。 それでも、コーヒー代を奢ってくださる方がいると嬉しいです(笑)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}