Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
項目反応理論の基礎と実践@岩手大学2022
Search
Daiki Nakamura
March 04, 2022
Education
2.6k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
項目反応理論の基礎と実践@岩手大学2022
学部生を対象としたIRTの講習会
Rの使用して、2PLモデルを実行する。
岩手大学にて(2022.02.22-23)
Daiki Nakamura
March 04, 2022
More Decks by Daiki Nakamura
See All by Daiki Nakamura
諸外国の理科カリキュラムにおけるビッグアイデアの構造比較
arumakan
0
890
国際調査ROSESの標本調査設計および調査実施の工夫
arumakan
0
84
適切な回帰推定量の使用が学力調査の推定精度を向上させる効果の検討
arumakan
0
120
Developing a Diverse Interests Scale for STEM Learners: Based on the ROSES Survey in Japan
arumakan
0
120
条件制御能力を測定するコンピュータ適応型テストの開発
arumakan
0
310
科学教育の読書会を中心とした新しい研究活動の展開
arumakan
0
300
The Value of Science Education in an Age of Misinformation
arumakan
1
400
教育研究における研究倫理問題の論点整理
arumakan
0
720
TIMSS 2019 環境認識尺度に関する日本人学習者の特徴
arumakan
0
510
Other Decks in Education
See All in Education
生成AI時代の情報発信
molmolken
0
140
アラムコSTEAMチャレンジ 実践報告書
codeforeveryone
0
180
Center for Entrepreneurship Education | Science Tokyo (Institute of Science Tokyo)
sciencetokyo
PRO
0
130
モブ社員がモブエンジニアを名乗って得られたこと_20260413
masakiokuda
4
560
Portable & Reproducible Research Environments in the Age of AI Agents
denkiwakame
0
510
良書紹介08_ 頭のいい子がやっているすごいグラフの読み方
bunnchinn3
0
120
We部コミュニティスライド2026-04-24
junhat6
0
200
Lectura 2 (PIT : Python Basico)
robintux
0
380
Beyond the Prompt: Programming as a Pathway to Statistical Thinking
minecr
0
250
Lectura 1 (PIT : Python Basico)
robintux
0
390
Πλουτοκρατία: Η Τυραννία του Μαμμωνά και η Μεταανθρώπινη Δουλεία
amethyst1
0
280
View Manipulation and Reduction - Lecture 9 - Information Visualisation (4019538FNR)
signer
PRO
1
2.8k
Featured
See All Featured
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
Paper Plane (Part 1)
katiecoart
PRO
1
9.7k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Utilizing Notion as your number one productivity tool
mfonobong
4
440
WENDY [Excerpt]
tessaabrams
11
38k
Design in an AI World
tapps
1
260
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
190
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Transcript
項目反応理論の基礎と実践 中村 大輝(広島大学大学院) 2022年2月22-23日 @岩手大学 全90枚+補 資料ダウンロード https://drive.google.com/drive/folders/1QIDheXt5YBnvdYiezp4ll BGGpZBsYCpo?usp=sharing Item
Response Theory
自己紹介 2 中村 大輝(Daiki Nakamura) ◼ 所属 広島大学大学院 教育学研究科 博士課程後期
D3 ◼ 専門 科学教育、理科教育、教育心理学 ◼ 研究テーマ 科学的思考力、教育測定、メタ分析、研究方法論 ◼ 論文 • 中村大輝・田村智哉・小林誠…・松浦拓也(2020)「理科における授業実践の効果に関するメタ 分析-教育センターの実践報告を対象として-」『科学教育研究』44(4), 215-233. 10.14935/jssej.44.215 • 中村大輝・雲財寛・松浦拓也(2021)「理科における認知欲求尺度の再構成および項目反応理論 に基づく検討」『科学教育研究』45(2), 215-233. 10.14935/jssej.45.215 • 中村大輝・原田勇希・久坂哲也・雲財寛・松浦拓也(2021)「理科教育学における再現性の危機 とその原因」『理科教育学研究』62(1), 3-22. 10.11639/sjst.sp20016 #Twitter @d_nakamuran #E-mail
[email protected]
#HP https://www.nakamu ra-edu.com/
勉強会の概要 Outline of the workshop 3
本勉強会の目標とスケジュール 4 ⚫ 2日間を通しての目標 ✓ 古典的テスト理論の限界について理解する ✓ 項目反応理論の基礎を理解する ✓ Rを用いた分析を実行できるようになる
※対象として、最低限の統計の基礎知識を持っている初学者を想定しています。 ⚫ スケジュール • 2月22日(火)午前 • テストとは何か • Rと統計の基礎 • 古典的テスト理論 • 項目反応理論の基礎 • 2月22日(火)午後 • 項目反応理論の基礎 • 項目反応モデルのパラメタ推定 • 2月23日(水)午前 • 項目反応モデルのパラメタ推定 • データと項目反応モデルの適合度 • 2月23日(水)午後 • テストの開発と運用 • コンピューターを活用したテスト
いま、なぜ項目反応理論(IRT)なのか? 5 ⚫ 背景 • 項目反応理論の発展とコンピューター性能の向上 – 1950年代に提案、60年代に体系化、80年代に実務での採用が広がる • エビデンスに基づく政策決定(EBPM)の広がり
• 大規模な学力試験の作成・運用においてグローバルスタンダードになっている(e.g., TOEIC, TOEFL, PISA, TIMSS) ⚫ IRTのメリット(豊田,2012を基に作成) • 問題項目や受験者集団の能力分布に左右されない公平な評価が可能 ➢ 項目に依存しない評価(項目依存性の克服) ➢ 集団に依存しない評価(集団依存性の克服) • 項目特性の詳細な分析が可能(どのような能力集団に対して、弁別性を持つのかなど) • 測定精度を細かく確認できる • 平均点を事前に制御できる • コンピューター適応型テスト(CAT)によって、受験者ごとに最適な問題を出題できるよ うになる
アイスブレイク 6 ⚫ 自己紹介(全体) • 名前、所属 • 研究関心 • 最近、頑張ったこと
⚫ 良いテストってなんだろう?(グループ)
テストとは何か What is a test? 7
テストの歴史(池田,1992, pp.1-4を基に作成) 8 ⚫ 紀元前 旧約聖書:ギレアデ人が「シボレテ」という言葉を上手く発音できるかどうかに よってテストを実施した B.C.413年、捕虜となったアテナイ軍のうち、ユリピデスの詩を暗唱することので きた者は釈放された。 ⚫
6世紀 科挙:官僚を筆記試験方式で選抜。20世紀まで続いた。 ⚫ 13世紀 ボローニャ大学:博士号をとるのに1週間の口述試験があった。 ⚫ 19世紀 米国:口述試験の問題点が指摘され、卒業試験に筆記試験の導入が進む。 ※紙と鉛筆が廉価になって一般庶民にも普及してきたという背景がある。 ⚫ 20世紀 大規模な学力調査の広がり(e.g., 1979年~共通一次、1990年~センター試験) ⚫ 21世紀 コンピューターを利用したテストの普及
テストの定義 9 ⚫ テストの定義(日本テスト学会,2007) テストとは、能力、学力、性格、行動などの個人や集団の特性を測定するための用具であり、 実施方法、採点手続き、結果の利用法などが明確に定められているべきものである。 ⚫ テストの種類と目的(日本テスト学会,2010, p.41を基に作成) 種類
クラス内のテスト 選抜テスト 学力調査 対象 個人 個人 集団 目的 クラス内の学習状況の把握 受験者の合否を判定する 調査対象集団の学力の 全体像を把握する 設計方針の例 ・指導内容や到達目標を特定 ・クラスの実態に合った作問 公平であり、受験者の実力 が発揮できる 学力の全体的な様相を 多角的かつ正確に把握 する 評価の種類 絶対評価 相対評価 ― 信頼性 ←相対的に低い 相対的に高い→ • テストの種類によって、目的や方針が異なる。
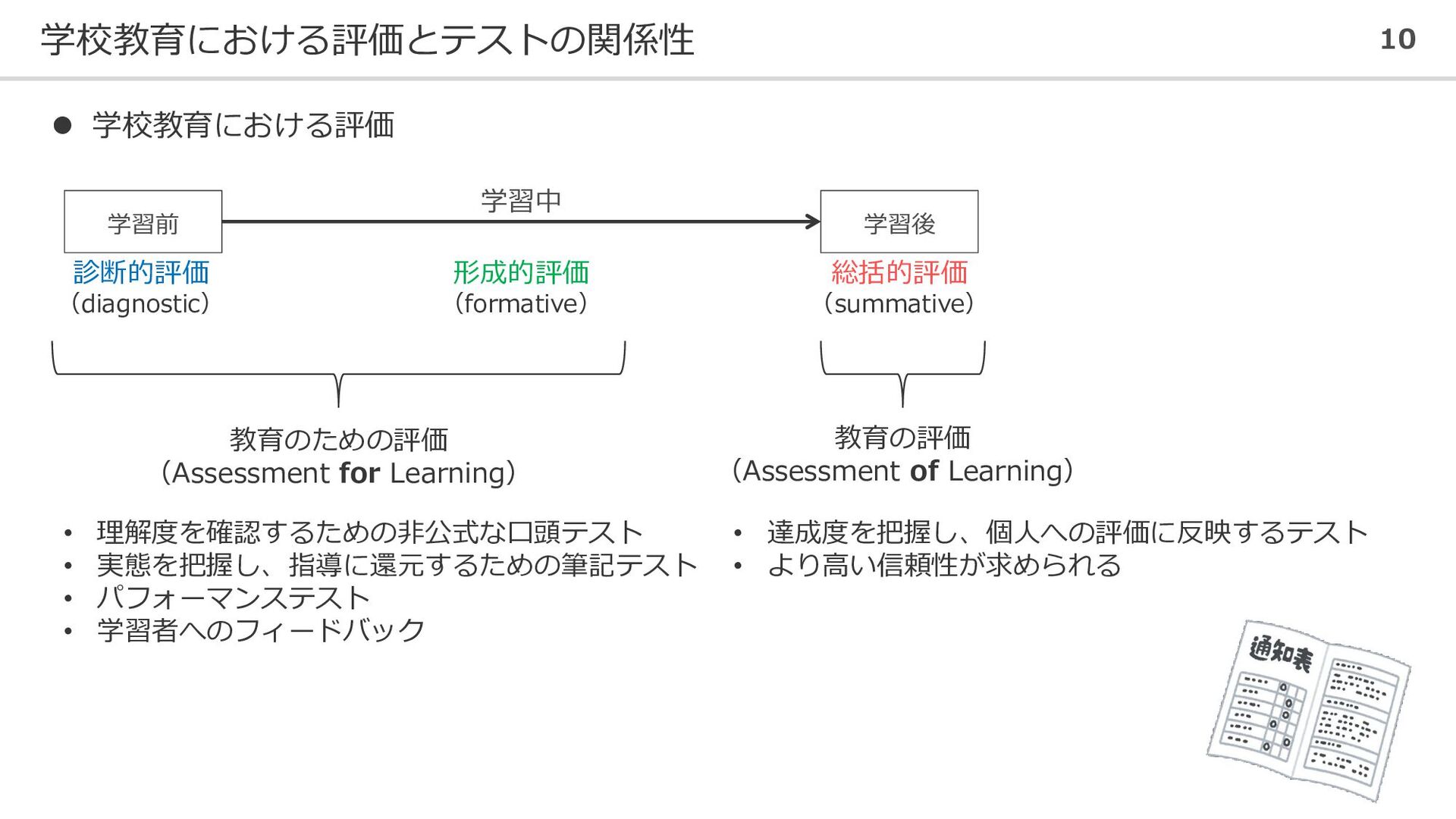
学校教育における評価とテストの関係性 10 ⚫ 学校教育における評価 学習前 学習後 診断的評価 (diagnostic) 形成的評価 (formative)
学習中 総括的評価 (summative) 教育のための評価 (Assessment for Learning) 教育の評価 (Assessment of Learning) • 理解度を確認するための非公式な口頭テスト • 実態を把握し、指導に還元するための筆記テスト • パフォーマンステスト • 学習者へのフィードバック • 達成度を把握し、個人への評価に反映するテスト • より高い信頼性が求められる
テストの公平性 11 ⚫ 何がテストの公平性を損ねるか? • 特定の個人が有利/不利になる • 問題流出 • カンニング
• 採点ミス • 評価者間のずれ • テストに無関係な要素の影響(e.g., リスニング機器の不備) • 特定の集団が有利/不利になる • 合計点に対する各テストの重みの偏り(e.g., センター試験の得点調整) • テストセットの違い(e.g., センター試験の本試験と追試験) • 色の使い方 • 試験会場の環境 • ジェンダーバイアス • 民族観、宗教観
良いテストとは何か 12 ⚫ 良いテストの条件(日本テスト学会,2010, p.5を基に作成) • テストの目的が明確で、目的を達成できるようにテストが作成・実施・採点・ 運用されている。 • テストによって測りたい特性に関連した内容が、広く偏りなく含まれている。
また、測りたい特性の範囲をカバーするのに適切な問題量である。 • 受験者のレベルにあった問題が用意されている。難易度や時間設定が適切であ る。 • 過去のテスト結果や他の集団のテスト結果と比較可能である。 • テストの公平性が担保されている。 ➢ 項目反応理論は、このようなテストの実現に寄与する
Rと統計の基礎 R and Statistics Basics 13
SPSS vs R • 有料ソフトである • ボタンをポチポチして操作(GUI) • 日本語対応 •
無料ソフトである • コードを入力して操作(CUI) • パッケージ(拡張機能)も8000を超える • Rでしかできない最新手法が多くある • 幅広いコミュニティが形成されている • 基本英語 <
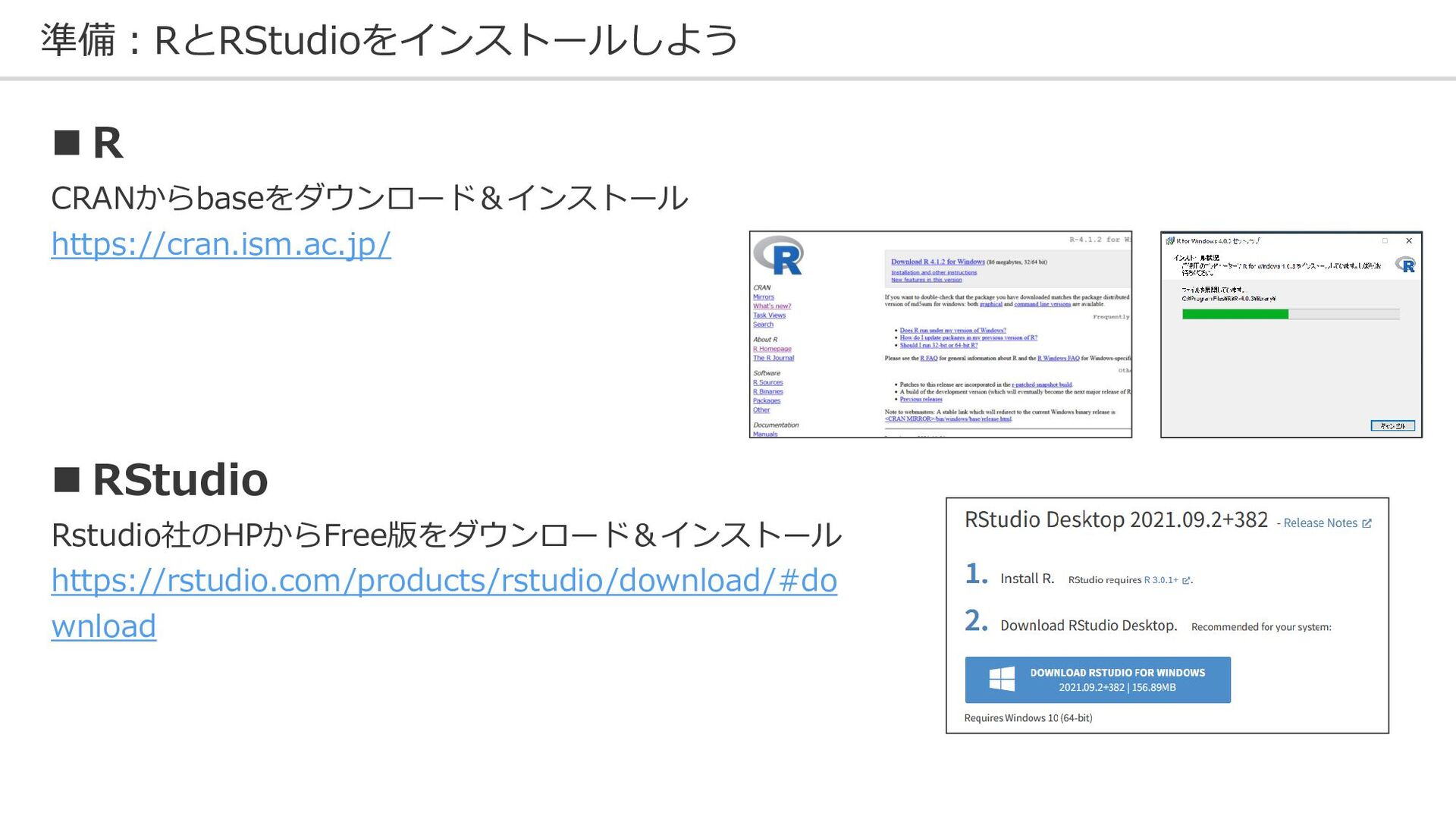
準備:RとRStudioをインストールしよう ◼ R CRANからbaseをダウンロード&インストール https://cran.ism.ac.jp/ ◼ RStudio Rstudio社のHPからFree版をダウンロード&インストール https://rstudio.com/products/rstudio/download/#do wnload
RStudioについて ⚫ RStudioは、Rをより使いやすくするためのソフト(基本無料) ⚫ この勉強会では、すべてRStudioを利用して分析する ⚫ 必ずインストール <便利なところ> • コードの予測変換や引数リストを表示してくれる
• 変数の管理が容易
RStudioの画面 エディタ (コードを書くところ) コンソール (結果・出力が出るところ) パッケージの管理 図表の出力など ワークスペース (変数の管理)
R Script を作成して保存 ⚫ R Script の作成と保存 新しくフォルダを作成し、R Script を保存する。
ファイル名には英語を使った方がよい 例)script1, 220222, code_0223 新規の R Script を作成 コードを書いておくメモ帳のようなもの
四則演算 # Rの練習 #### # 四則演算 3+5 10-3 2*3 100/20
(12+34-56)*78/90 4^2 #二乗だよ • エディタに書いて実行 or コンソールに直接入力 ⚫ 実行の方法 • Alt(⌥)+Enterでその行を実行 • Ctr(⌘)+Enterでその行を実行+改行 • 範囲をドラッグで指定してRunをクリック ⚫ コメントアウト(メモ) • #から始めるとそれ以降は読み込まれない • メモやコメントを残せる • コメントの後ろに#を連ねると見出しとして 認識される
変数と代入 • 代入演算子「<-」「=」を使って、変数にオブジェクトを代入することができる • Ctr(⌥) + - で、<- が入力できる #
変数と代入 x <- 3+5 y <- 9 z <- x+y z オブジェクト 変数の箱 ※イメージ オブジェクト:データそのもの 変数:オブジェクトを保管する箱 代入:オブジェクトを箱に保管すること スペースは無視して読み込まれる スペースを入れた方が可読性が高い
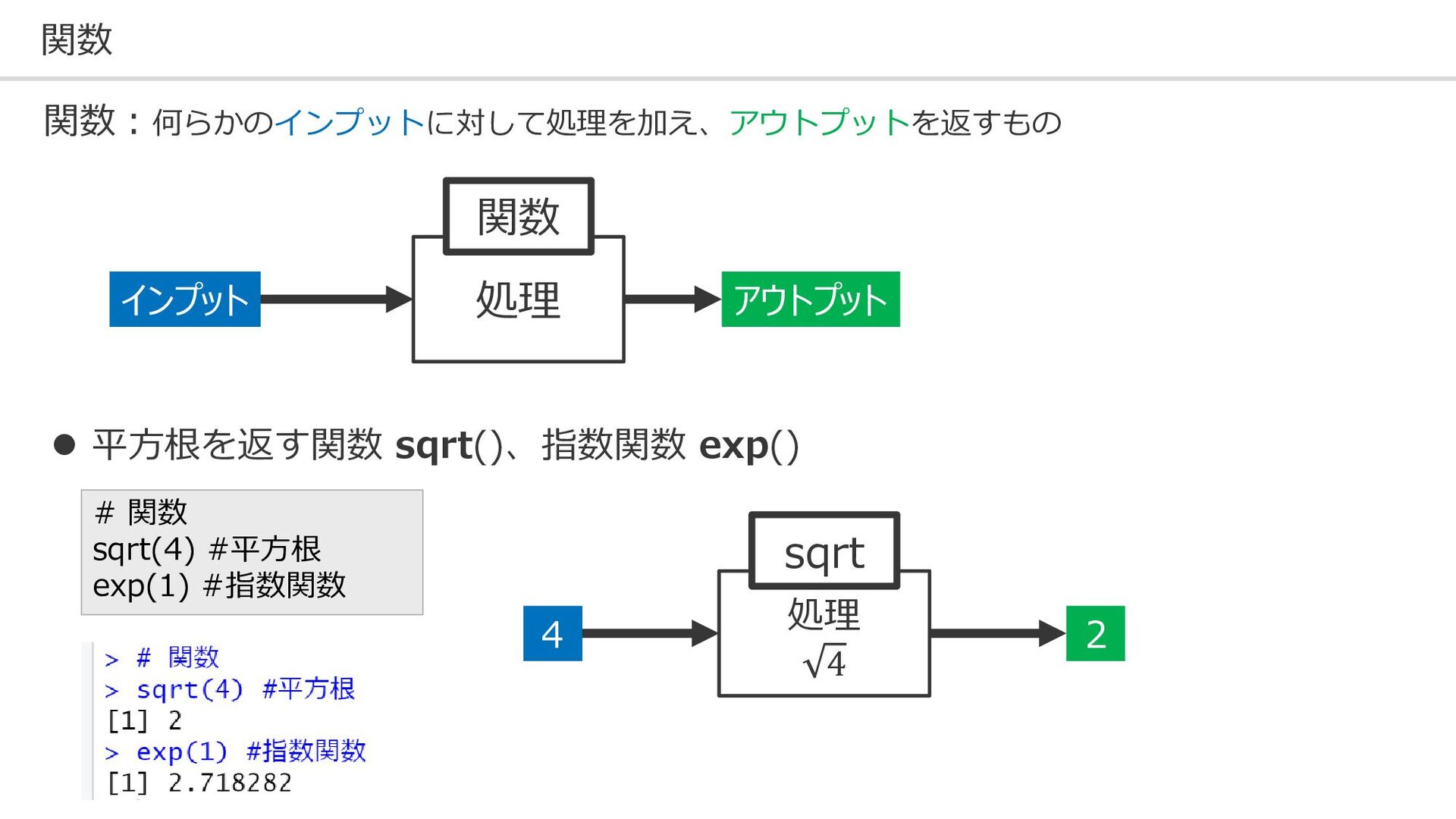
関数 アウトプット インプット 処理 関数 2 4 処理 4 sqrt
# 関数 sqrt(4) #平方根 exp(1) #指数関数 ⚫ 平方根を返す関数 sqrt()、指数関数 exp() 関数:何らかのインプットに対して処理を加え、アウトプットを返すもの
Rによる分析の流れ データの 読み込み コードの 入力 分析の実行 コード(スクリプト)を書いて、 Rにやってほしいことを命令 分析に使うデータを読み込む 分析を実行し、出力を読み取る
今回使用するデータ 23 ◼ data1.xlsx:教育測定に関する架空データ • ID :通し番号(1~250) • school :学校名(sakura/kita)
• grade :学年(5,6) • class :クラス • number :出席番号 • sex :性別(M男、F女) • kokugo1~3:国語のテスト結果 • sansu1~3 :算数のテスト結果 • rika1~3 :理科のテストの結果 • CT1~7 :批判的思考質問紙 ※ Rは変数名を英語にした方がエラーが出にくい ← まずはデータを眺めて構造を理解しよう。
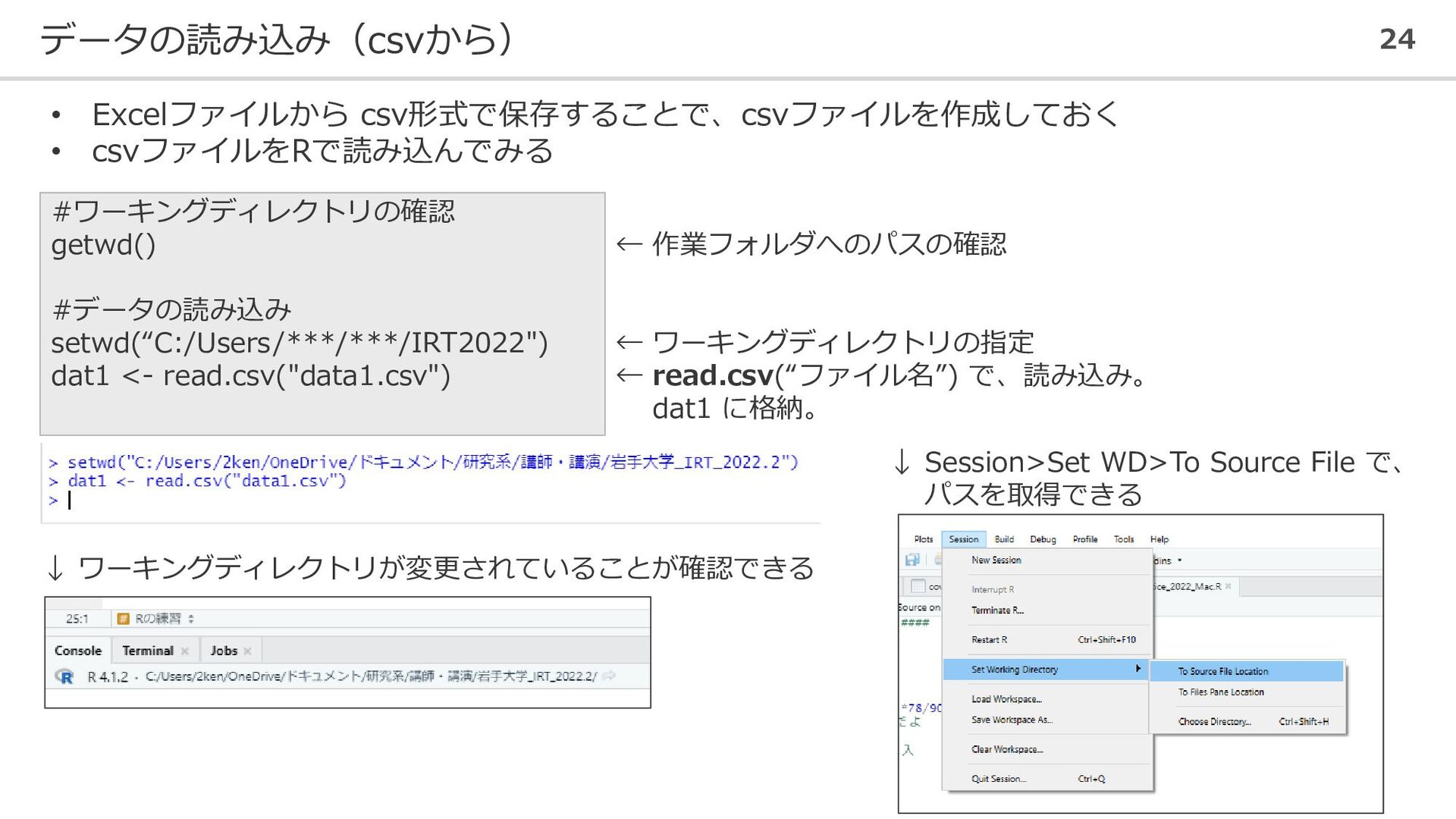
データの読み込み(csvから) 24 #ワーキングディレクトリの確認 getwd() #データの読み込み setwd(“C:/Users/***/***/IRT2022") dat1 <- read.csv("data1.csv") ←
作業フォルダへのパスの確認 ← ワーキングディレクトリの指定 ← read.csv(“ファイル名”) で、読み込み。 dat1 に格納。 ↓ Session>Set WD>To Source File で、 パスを取得できる • Excelファイルから csv形式で保存することで、csvファイルを作成しておく • csvファイルをRで読み込んでみる ↓ ワーキングディレクトリが変更されていることが確認できる
データの確認 25 ⚫ データが正しく読み込まれているか確認しよう # 行列数 dim(dat1) # 先頭6行の表示 head(dat1)
head(dat1$rika1) ← dim(データ)で、行数・列数の表示 ← head(データ)で、先頭6行を表示 ← データ$変数名で、1つの変数を指定 250行/22列(250人/22変数) データセット 変数
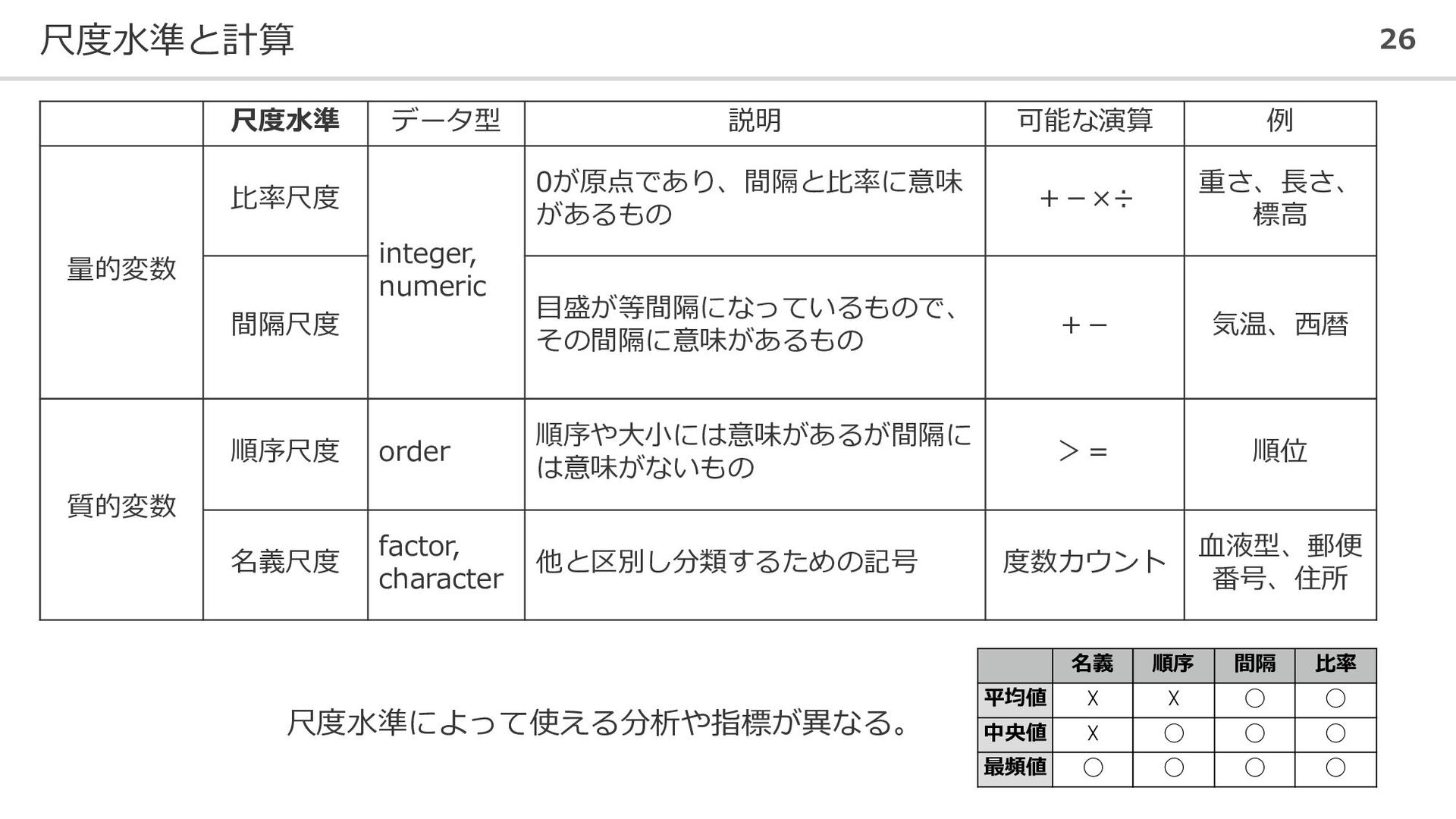
尺度水準と計算 26 尺度水準 データ型 説明 可能な演算 例 量的変数 比率尺度 integer,
numeric 0が原点であり、間隔と比率に意味 があるもの +-×÷ 重さ、長さ、 標高 間隔尺度 目盛が等間隔になっているもので、 その間隔に意味があるもの +- 気温、西暦 質的変数 順序尺度 order 順序や大小には意味があるが間隔に は意味がないもの >= 順位 名義尺度 factor, character 他と区別し分類するための記号 度数カウント 血液型、郵便 番号、住所 名義 順序 間隔 比率 平均値 ☓ ☓ ◯ ◯ 中央値 ☓ ◯ ◯ ◯ 最頻値 ◯ ◯ ◯ ◯ 尺度水準によって使える分析や指標が異なる。
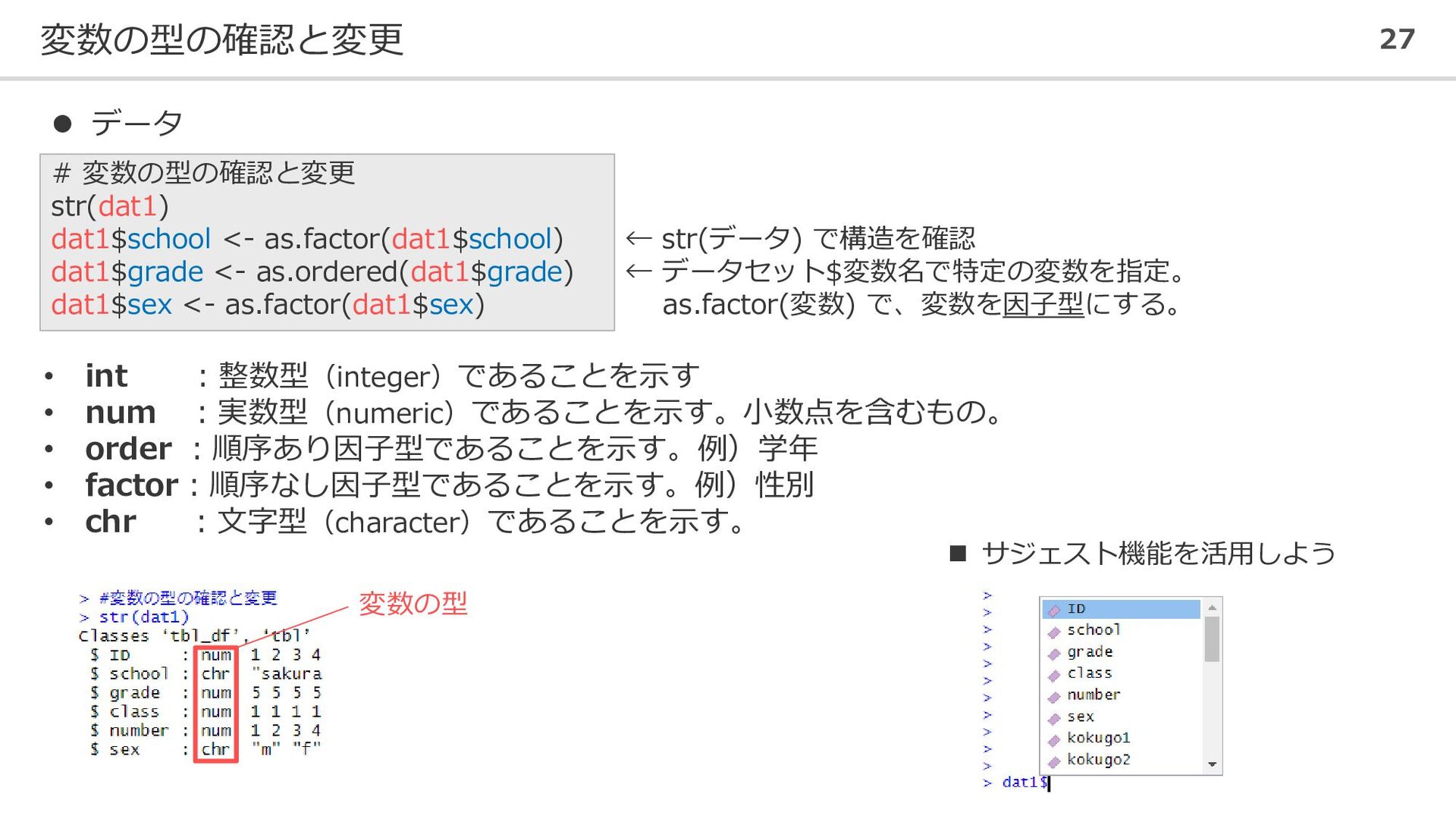
変数の型の確認と変更 27 # 変数の型の確認と変更 str(dat1) dat1$school <- as.factor(dat1$school) dat1$grade <-
as.ordered(dat1$grade) dat1$sex <- as.factor(dat1$sex) ⚫ データ ← str(データ) で構造を確認 ← データセット$変数名で特定の変数を指定。 as.factor(変数) で、変数を因子型にする。 • int :整数型(integer)であることを示す • num :実数型(numeric)であることを示す。小数点を含むもの。 • order :順序あり因子型であることを示す。例)学年 • factor:順序なし因子型であることを示す。例)性別 • chr :文字型(character)であることを示す。 変数の型 ◼ サジェスト機能を活用しよう
代表値と散布度の種類 28 ⚫ 代表値:データの分布の中心的な位置を表す指標値 ◼ 平均値(mean) ҧ 𝑥 = 1
𝑛 σ𝑖=1 𝑛 𝑥𝑖 ◼ 中央値(median) データを小さい順に並べた時に中央に位置する値。 データが偶数個の場合は中央の2つの平均。 ⚫ 散布度:データのばらつきの度合を表す指標値 ◼ 偏差(diviation) 𝑑𝑖 = 𝑥𝑖 − ҧ 𝑥 ◼ 不偏分散(variance) 𝑠2 = 1 𝑛−1 σ𝑖=1 𝑛 𝑥𝑖 − ҧ 𝑥 2 ◼ 標準偏差(standard deviation) 𝑠 = 𝑠2 = 1 𝑛 σ 𝑖=1 𝑛 𝑥𝑖 − ҧ 𝑥 2 ◼ 標本平均の標準誤差(standard error) 𝑆 ҧ 𝑥 = 𝑠 𝑛
代表値と散布度の算出 29 # 代表値と散布度 mean(dat1$rika1) #相加平均 median(dat1$rika1 ) #中央値 table(dat1$CT1)
#最頻値 var(dat1$rika1) #不偏分散 sd(dat1$rika1) #標準偏差 # 要約統計量 summary(dat1) #代表値 install.packages("psych") #初回のみ library(psych) describe(dat1) #基礎集計 追加のパッケージをインストール&読み込むことで、 様々な分析が可能になる。 [最小値、第一四分位、中央値、平均、 第三四分位、最大値] [変数番号、サンプルサイズ、平均、標準偏差、中央値、トリム平均、 中央絶対偏差、最小、最大、レンジ、歪度、尖度、標準誤差]
新しい変数やデータセットの作成 30 ⚫ 各教科の3回のテストの平均を個人ごとに算出する # 新しい変数の作成 dat1$kokugo_all <- apply(dat1[,7:9], 1,
mean) dat1$sansu_all <- apply(dat1[,10:12], 1, mean) dat1$rika_all <- apply(dat1[,13:15], 1, mean) # 新しいデータセットの作成 dat_seiseki <- dat1[,c(“kokugo_all”, “sansu_all”, “rika_all”)] ← 国語平均の作成 ← 算数平均の作成 ← 理科平均の作成 ※ 0なら列, 1なら行に対して処理 ← 国算理の平均が入ったデータセット 新しい変数が増えている データ名[行, 列]
標準化とz得点 31 ⚫ 標準化 データを平均0、標準偏差(分散)1に変換する作業を標準化と呼ぶ。 𝑧 = 𝑥𝑖 − 𝜇𝑥
𝜎𝑥 変換した後の得点をz得点(標準得点)と呼ぶこともある。 ⚫ 偏差値 偏差値 = 50 + 10 × 𝑧得点 • 平均50、標準偏差10になるように変換 • 受験者全体の分布の中でどれだけ高いかを反映している ⚫ 知能指数(IQ) 𝐼𝑄 = 100 + 15 × 𝑧得点 • 平均100、標準偏差15になるように変換 ※ ただし、いくつかのバージョンがあるのと、フリン効果で分布が変化しつつある
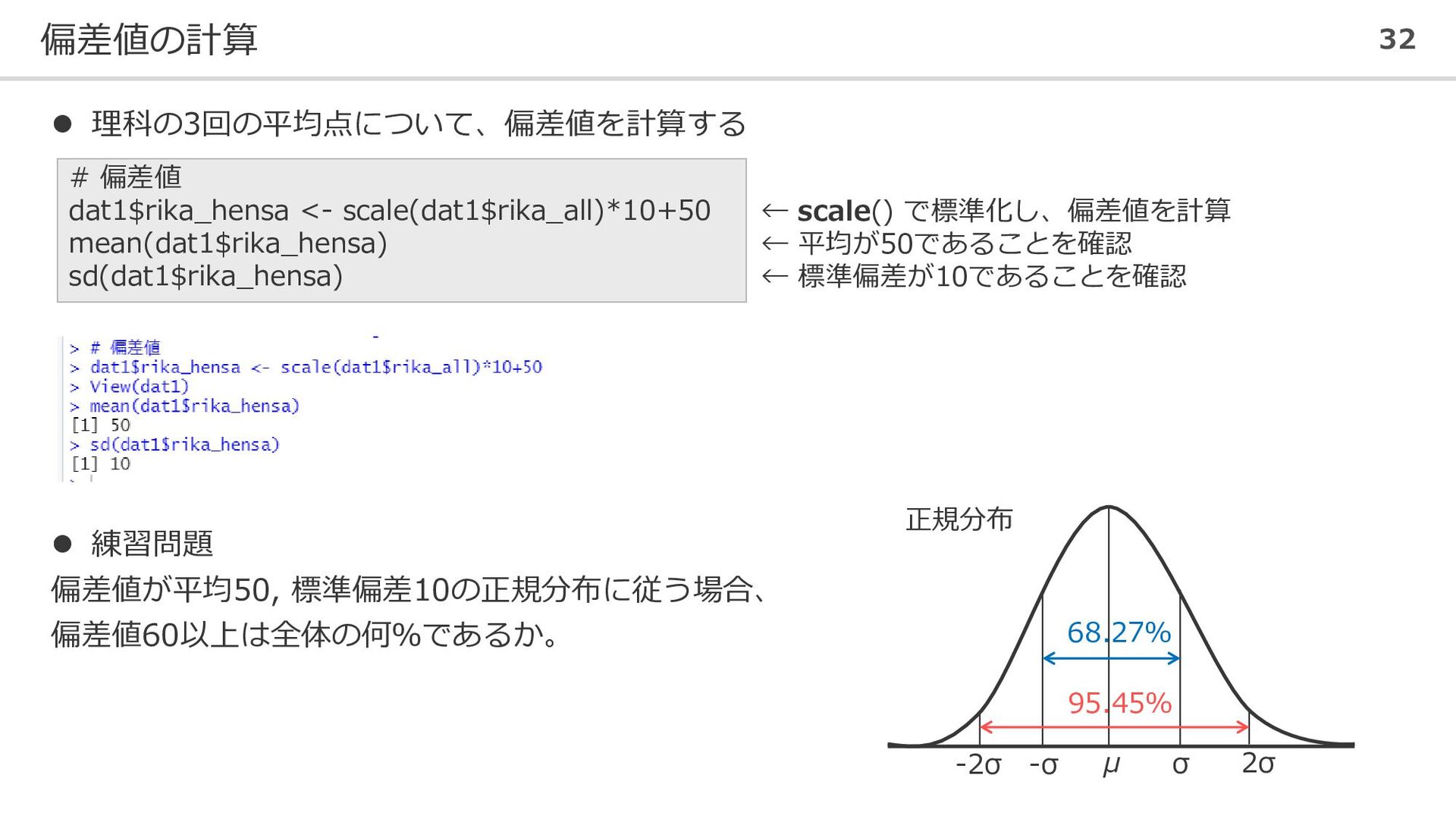
偏差値の計算 32 ⚫ 理科の3回の平均点について、偏差値を計算する # 偏差値 dat1$rika_hensa <- scale(dat1$rika_all)*10+50 mean(dat1$rika_hensa)
sd(dat1$rika_hensa) 68.27% 95.45% μ σ 2σ -σ -2σ 正規分布 ⚫ 練習問題 偏差値が平均50, 標準偏差10の正規分布に従う場合、 偏差値60以上は全体の何%であるか。 ← scale() で標準化し、偏差値を計算 ← 平均が50であることを確認 ← 標準偏差が10であることを確認
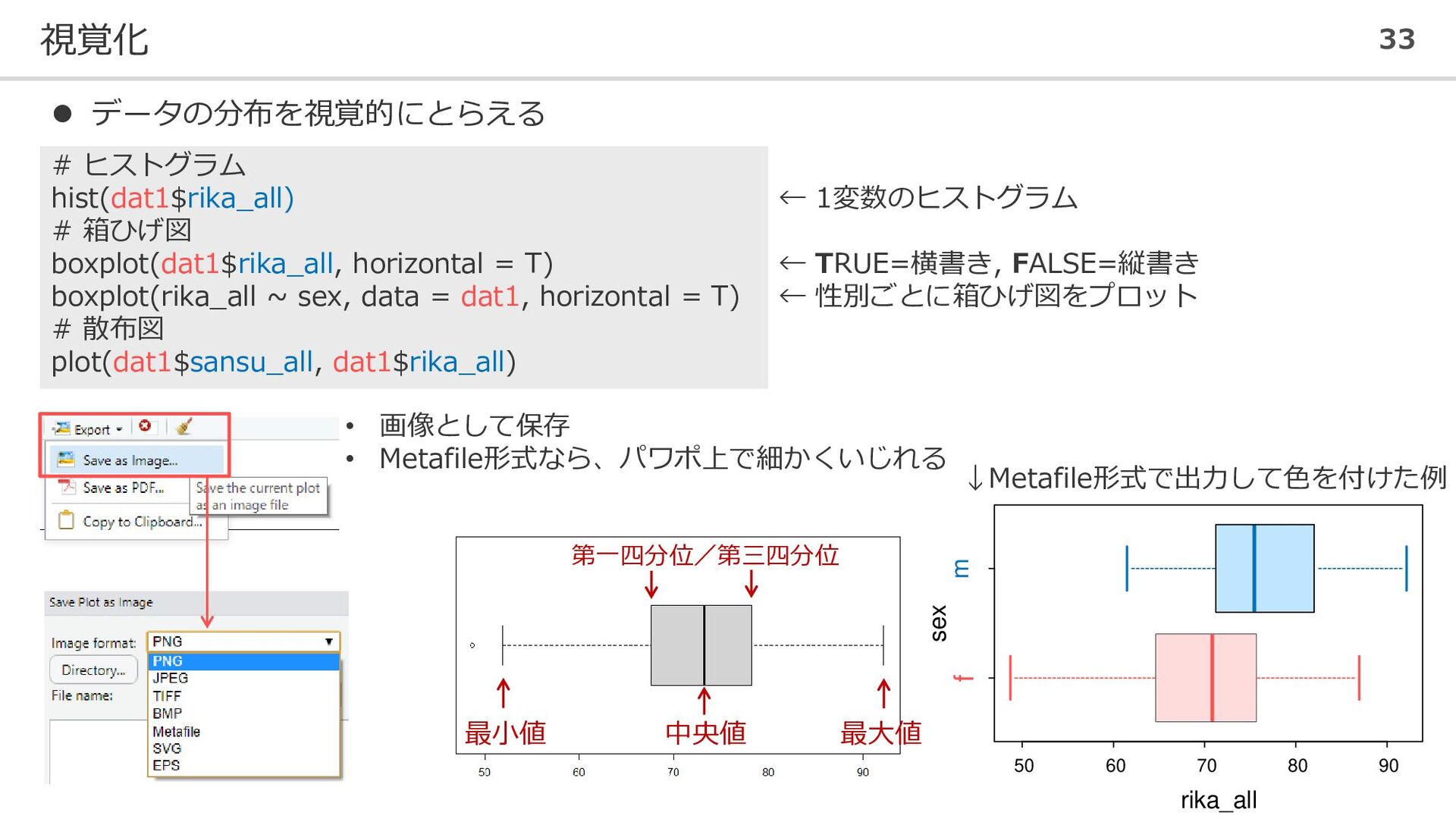
視覚化 33 ⚫ データの分布を視覚的にとらえる # ヒストグラム hist(dat1$rika_all) # 箱ひげ図 boxplot(dat1$rika_all,
horizontal = T) boxplot(rika_all ~ sex, data = dat1, horizontal = T) # 散布図 plot(dat1$sansu_all, dat1$rika_all) ← 1変数のヒストグラム ← TRUE=横書き, FALSE=縦書き ← 性別ごとに箱ひげ図をプロット • 画像として保存 • Metafile形式なら、パワポ上で細かくいじれる f m 50 60 70 80 90 rika_all sex ↓Metafile形式で出力して色を付けた例 最小値 中央値 第一四分位/第三四分位 最大値
対応のないt検定(2群の平均値差) # 性別間比較 tapply(dat1$rika_all, dat1$sex, mean) #性別ごとの平均値 m.rika <- dat1$rika_all[dat1$sex=="m"]
#第1群の指定 f.rika <- dat1$rika_all[dat1$sex=="f"] #第2群の指定 t.test(m.rika, f.rika, var.equal = F) #F=Welchのt検定 # 効果量 library(effsize) cohen.d(m.rika, f.rika, hedges.correction = T) #効果量:T=Heages’ g, F=Cohen’s d * Cohenの基準(dとgに適応できる) d=0.2 小さな効果 d=0.5 中程度の効果 d=0.8 大きな効果 中程度の大きさの差 有意 ⚫ 理科の点数に男女間で差はあるだろうか? ◆ どんなに差が小さくても、サンプルサ イズが大きければ有意になってしまう。 効果量も重要。 95%CI 男子(N = 118)と女子(N = 132)の理科の点数に差があるのかを明らかにするために、Welchのt検定を行った。その結果、男子(M = 76.17, SD = 6.88)と女子(M = 70.36, SD = 7.60)の点数には有意な差が見られた(t(247.96) = 6.35, p < .001, g = 0.80, 95%CI [0.54, 1.06])。
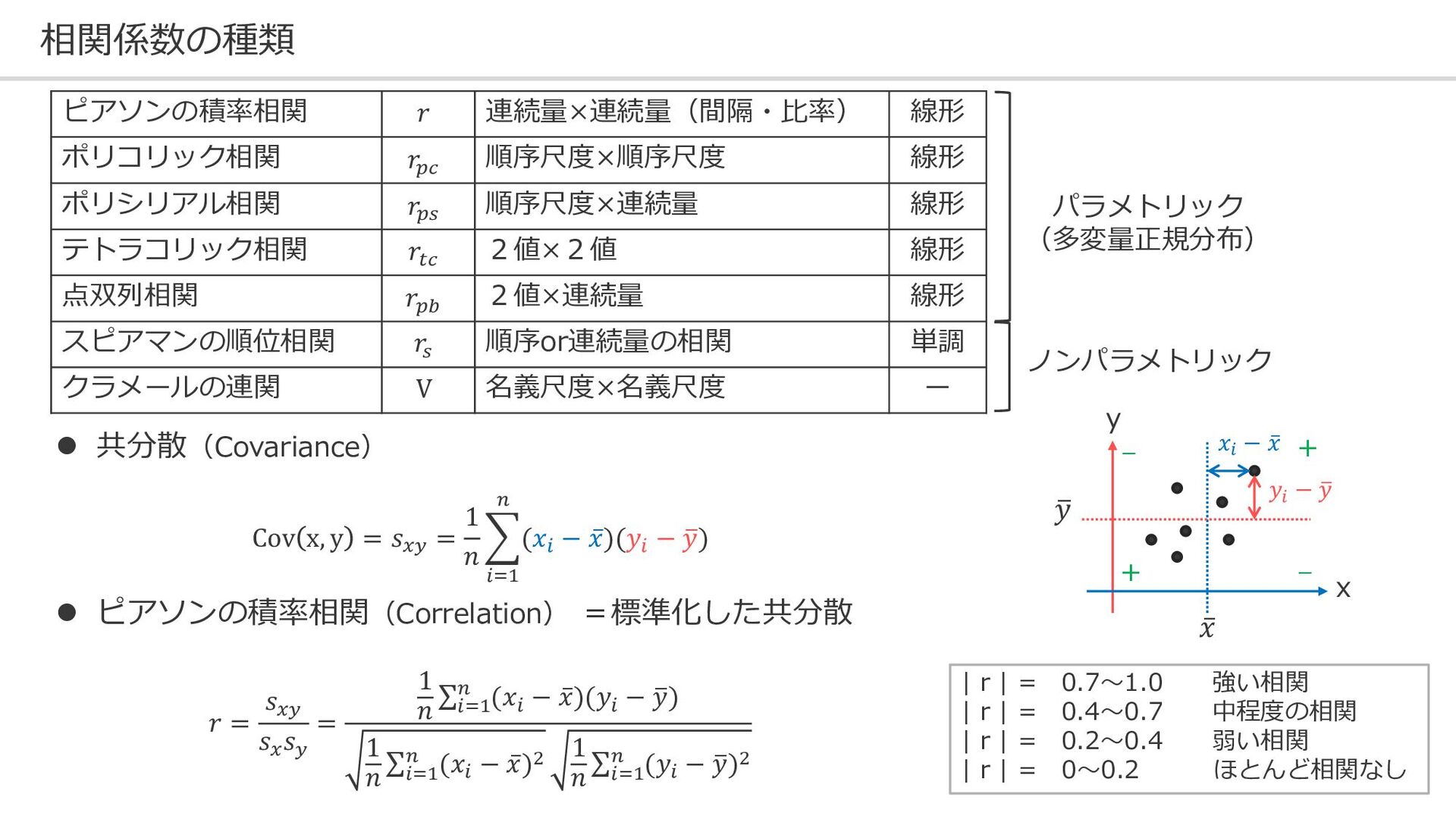
相関係数の種類 ピアソンの積率相関 𝑟 連続量×連続量(間隔・比率) 線形 ポリコリック相関 𝑟𝑝𝑐 順序尺度×順序尺度 線形 ポリシリアル相関
𝑟𝑝𝑠 順序尺度×連続量 線形 テトラコリック相関 𝑟𝑡𝑐 2値×2値 線形 点双列相関 𝑟𝑝𝑏 2値×連続量 線形 スピアマンの順位相関 𝑟𝑠 順序or連続量の相関 単調 クラメールの連関 V 名義尺度×名義尺度 ー パラメトリック (多変量正規分布) | r | = 0.7~1.0 強い相関 | r | = 0.4~0.7 中程度の相関 | r | = 0.2~0.4 弱い相関 | r | = 0~0.2 ほとんど相関なし ⚫ 共分散(Covariance) Cov x, y = 𝑠𝑥𝑦 = 1 𝑛 𝑖=1 𝑛 (𝑥𝑖 − ҧ 𝑥)(𝑦𝑖 − ത 𝑦) ⚫ ピアソンの積率相関(Correlation) =標準化した共分散 𝑟 = 𝑠𝑥𝑦 𝑠𝑥 𝑠𝑦 = 1 𝑛 σ 𝑖=1 𝑛 (𝑥𝑖 − ҧ 𝑥)(𝑦𝑖 − ത 𝑦) 1 𝑛 σ 𝑖=1 𝑛 (𝑥𝑖 − ҧ 𝑥)2 1 𝑛 σ 𝑖=1 𝑛 (𝑦𝑖 − ത 𝑦)2 x y ҧ 𝑥 ത 𝑦 𝑥𝑖 − ҧ 𝑥 𝑦𝑖 − ത 𝑦 + + - - ノンパラメトリック
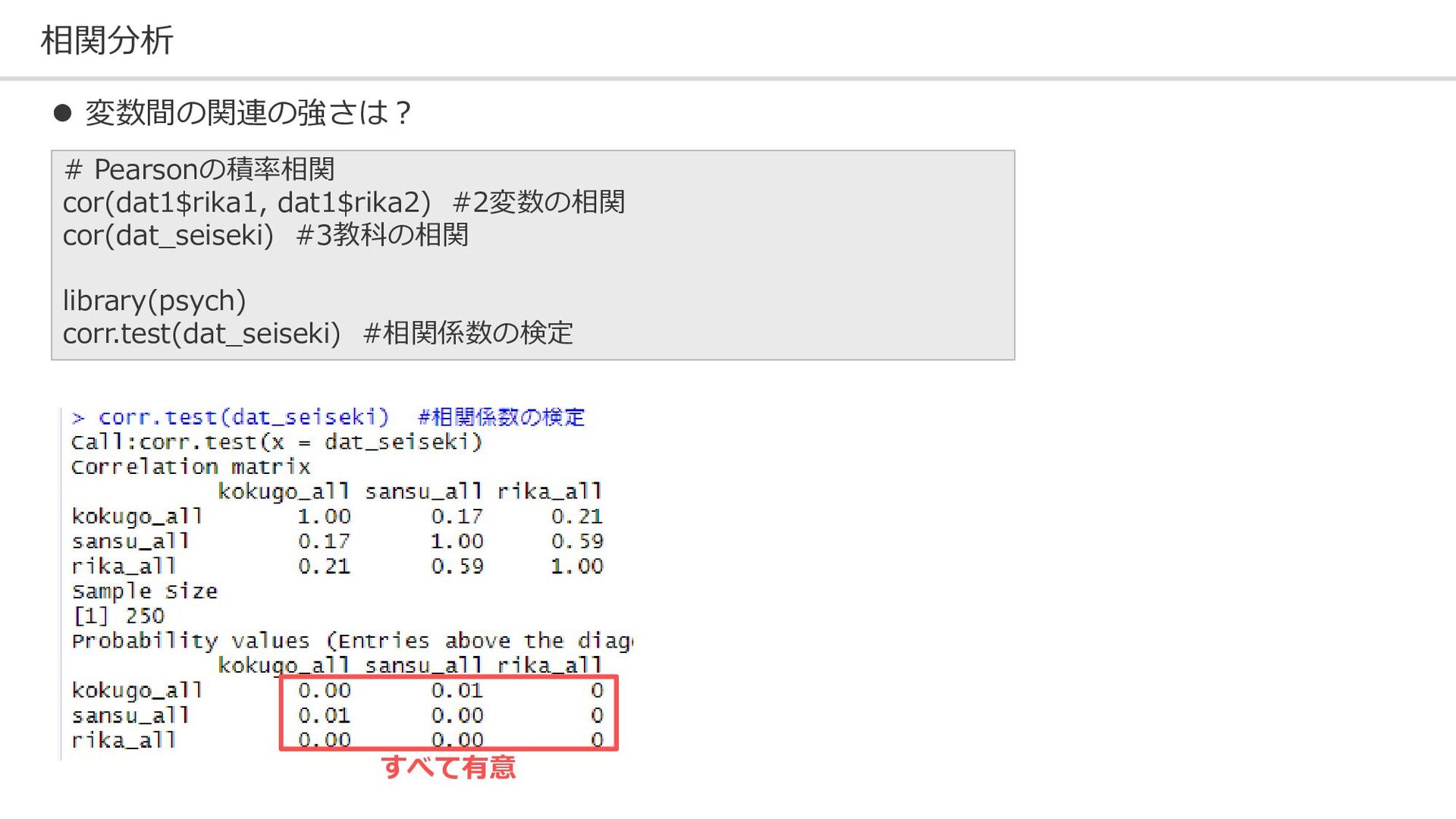
相関分析 # Pearsonの積率相関 cor(dat1$rika1, dat1$rika2) #2変数の相関 cor(dat_seiseki) #3教科の相関 library(psych) corr.test(dat_seiseki)
#相関係数の検定 ⚫ 変数間の関連の強さは? すべて有意
古典的テスト理論 Classical Test Theory 37
古典的テスト理論とは何か 38 ⚫ 古典的テスト理論(Classical Test Theory, CTT) 古典的テスト理論とは、複数の項目に対する結果を総合したテスト得点に関する統計的理論 と分析を指す。 ⚫
古典的の意味 後から開発された現代的テスト理論と比べて古くに開発されたという意味。 古くてまったく使われなくなったという意味ではない。現在でも有用な考え方。 ⚫ 古典的テスト理論のトピック 1. 項目困難度、項目識別力 2. 測定の標準誤差 ☆観測得点=真の得点+測定誤差 3. 信頼性係数 • 測定誤差の平均は0、真の得点と測定誤差は無相関 • 信頼性係数=真の得点の分散/観測得点の分散 ➢ クロンバックのα係数 4. (項目分析)
いくつかの記号の定義 39 テストを構成する個々の問題のことを項目(item)と呼ぶ。 𝑖番目の受験者の項目𝑗への回答を 𝑢𝑖𝑗 と表記する。項目への反応に応じて、 𝑢𝑖𝑗 ൝ 1 正答の時
0 誤答の時 のように、項目反応を二値データで表現できる。 𝑖番目の受験者の𝐽個すべての項目への反応を、𝐮𝑖 = 𝑢𝑖1 , 𝑢𝑖2 , … , 𝑢𝑖𝐽 のように行ベクトルで表す。 この𝐮𝑖 を項目反応パタンと呼ぶ。 この項目反応パタンの行ベクトル𝐮𝑖 を縦に𝐼人分並べると、𝐼行×𝐽列のサイズの行列で表現できる。 これを𝐔と表記し、項目反応パタン行列と呼ぶ。このうち、𝐔の第𝑗列だけ取り出すと、これは項目𝑗 に対する 𝐼人の項目反応をまとめた列ベクトル𝐮𝑗 ∗となる。 𝐔 = 𝐮1 𝐮2 ⋮ 𝐮𝑖 ⋮ 𝐮𝐼 = 𝑢11 𝑢12 ⋯ 𝑢1𝑗 ⋯ 𝑢1𝐽 𝑢21 𝑢22 ⋯ 𝑢2𝑗 ⋯ 𝑢2𝐽 ⋮ ⋮ ⋮ ⋮ 𝑢𝑖1 𝑢𝑖2 ⋯ 𝑢𝑖𝑗 ⋯ 𝑢𝑖𝐽 ⋮ ⋮ ⋮ ⋮ 𝑢𝐼1 𝑢𝐼2 ⋯ 𝑢𝐼𝑗 ⋯ 𝑢𝐼𝐽 , 𝐮𝑗 ∗ = 𝑢1𝑗 𝑢2𝑗 ⋮ 𝑢𝑖𝑗 ⋮ 𝑢𝐼𝑗
平均と分散 40 項目反応は0か1の二値データなので、ある項目𝑗の項目反応𝐮𝑗 ∗をすべて足し合わせると、正答者数𝑛𝑗 を 求めることができる。 𝑛𝑗 = 𝑖=1
𝐼 𝑢𝑖𝑗 また、𝑖番目の受験者のテスト得点を𝑦𝑖 とすると、これは行ベクトル𝐮𝑖 の要素をすべて足し合わせればよ いので、 𝑦𝑖 = 𝑖=1 𝐽 𝑢𝑖𝑗 となる。受験者𝑖のテスト得点を𝑦𝑖 とすると、テストの平均𝑦は、 𝑦 = σ𝑖=1 𝐼 𝑦𝑖 𝐼 である。このテスト得点𝑦𝑖 の不偏分散は、以下のように表される。 ො 𝜎𝑦 2 = σ𝑖=1 𝐼 𝑦𝑖 − 𝑦 2 𝐼 − 1
項目を評価する指標 41 テストを構成する個々の項目の性能を評価する指標として、項目困難度と項目識別力を考える。 これらの指標は、古典的テスト理論と項目反応理論で登場するが、理論間で定義が異なることに注意 が必要である。 CTTにおける項目困難度(item difficulty)とは、項目の正答率𝑝𝑖 として以下のように定義される。 𝑝𝑖 =
𝑛𝑗 𝐼 = σ𝑖=1 𝐼 𝑢𝑖𝑗 𝐼 これは、その項目に対する正答率であるため、値が小さいほど難しいことを意味する。 通過率と呼ぶこともある。 CTTにおける項目識別力(item discrimination)とは、個々の項目と合計点の点双列相関係数𝑟𝑝𝑏 として 以下のように定義される。 𝑟𝑝𝑏 𝑦, 𝑢𝑗 = 1 𝐼 σ𝑖=1 𝐼 (𝑦𝑖 − 𝑦)(𝑢𝑖𝑗 − 𝑢𝑗 ) 𝑠𝑦 𝑠𝑗 項目識別力が高いほど、テスト全体で測定している能力をより良く反映していることになり、当該能 力を区別する性能が高いことを意味する。0.2を下回る項目は除外対象となる(熊谷・荘島,2015)。
テストの信頼性 42 ある受験者𝑖のテスト得点𝑦𝑖 は、受験者𝑖の真の得点𝑡𝑖 と測定誤差𝑒𝑖 の和として以下のように表現される。 𝑦𝑖 = 𝑡𝑖 +
𝑒𝑖 ここで、真の得点𝑡𝑖 とは、受験者𝑖に対して測定を無限回繰り返した場合の𝑦𝑗 の期待値である。 𝑡𝑖 = 𝐸 𝑦𝑖 個々の受験者𝑖に対して𝑡𝑖 は定数として存在するが、観測することはできない。実際に観測できるのは、 真の得点𝑡𝑖 に誤差𝑒𝑖 が加わった𝑦𝑖 である。誤差𝑒𝑖 が小さく、テスト得点𝑦𝑖 に含まれる真の得点𝑡𝑖 の割合が 大きいほど、結果が一貫していて信頼性の高い測定が実現していると考えられる。しかし、個々の受験 者に対して無限回の測定を繰り返すことはできないため、ここでは受験者の母集団を考えてみる。 𝑦 = 𝑡 + 𝑒 ここで、誤差𝑒の平均は0であり、真の得点𝑡と誤差𝑒に相関は無いと仮定する。すると、受験者母集団に おけるテスト得点の分散𝜎𝑦 2は、真の得点の分散𝜎𝑡 2と測定誤差の分散𝜎𝑒 2に分解できる。 𝜎𝑦 2 = 𝜎𝑡 2 + 𝜎𝑒 2 このとき、テスト得点の分散𝜎𝑦 2に対する真の得点の分散𝜎𝑡 2の割合をテスト得点𝑦の信頼性係数と呼ぶ。 𝜌 = 𝜎𝑡 2 𝜎𝑦 2 = 𝜎𝑡 2 𝜎𝑡 2 + 𝜎𝑒 2 = 1 − 𝜎𝑒 2 𝜎𝑦 2 信頼性係数𝜌は、0 ≤ 𝜌 ≤ 1であり、1に近いほど測定の信頼性が高いと言える。
クロンバックの𝛼係数 43 信頼性係数の定義式を見ると分かる通り、ギリシャ文字で表現されている部分は母集団における値(母数) であり、実際には観測できない。そこで、再検査法、平行テスト、折半法といった様々な方法で信頼性係数 を推定することになる。 ここでは、信頼性係数の推定値として、クロンバックの𝛼係数を使用する。 𝛼 = 𝐽 𝐽
− 1 (1 − σ 𝑗=1 𝐽 𝑠𝑗 2 𝑠𝑦 2 ) ここで、 𝑠𝑦 2はテスト得点の分散、 𝑠𝑗 2は各項目の得点の分散を表す。 信頼性係数の推定値として𝛼係数を用いることで、測定の標準誤差(standard error of measurement, SEM)を以下のように計算できる。 𝑆𝐸𝑀 = 𝜎𝑒 = 𝑠𝑦 1 − ො 𝜌 = 𝑠𝑦 1 − 𝛼 これは、そのテスト得点がどれだけの精度を持っているかを意味している。 CTTを用いたテスト構成の目標は、信頼性の高い(SEMの小さい)テストを作ることとなる。 ただし、信頼性係数や測定の標準誤差は、テストを実施する集団が異なれば値も変わることに注意が必要で ある。
Rによる項目特性、信頼性係数の計算 44 ⚫ データの読み込み # 古典的テスト理論 #### # データの読み込み dat2
<- read.csv("data2.csv") dim(dat2) #項目反応パタン行列 ← csvファイルの読み込み ← 行と列の数の表示 1000*10 ⚫ 基礎集計 # 基礎集計 apply(dat2[1:1000,], 2, sum) #正答者数n_j dat2$score <- apply(dat2[,1:10], 1, sum) #テスト得点y_i var(dat2$score) #不偏分散 ← 2=列ごとの処理 総和 ← 1=行ごとの処理 総和 ← 不偏分散 variance # 項目特性値と信頼性係数 library(ltm) descript(dat2[,1:10]) sd(dat2$score)*sqrt(1-0.7404) ⚫ 項目特性値と信頼性係数 困難度 識別力 𝛼係数
CTTの問題は何か 45 ⚫ クイズ(加藤・山田・川端,2014) A1. 「2人の実力が等しいとは言えない」 テストXとテストYの難易度が等しいとは限らない。2つのテスト問題が異なるので、テストXの80点とテストY の80点とが同等の能力水準を表しているという保証がない。→項目依存性 A2. 「2人の実力が等しいとは言えない」
偏差値は、所属する集団の中での相対的な位置を表すものである。A中学とB中学の学力レベルが等しいという 前提が満たされていなければ、異なる集団から計算された偏差値を比較することには意味がない。→標本依存性 A3. 「2つのテストの難易度が等しいとは言えない」 A中学とB中学の学力レベルが等しいという保証がない。例えば、A中学がテストYを受けたら、平均点が70点に なるかもしれない(A中学の学力レベルが、B中学の学力に比べて高い場合)。→標本依存性
標本依存性と項目依存性 46 ⚫ 標本(集団)依存性 CTTでは、項目困難度を項目の正答率として定義するが、正答率は受験者集団に よって異なる。そのため、項目困難度はテストを受ける受験者集団に依存する。 同様に、項目識別力もテストを受ける受験者集団に依存する。問題のレベルよりも 能力が高い/低い集団では、ほぼ全員が正答/誤答になり、能力を識別することが できないことになる(識別力が低くなる)。 このように、項目の特性を表す2つの指標が、受験者集団によって変わってしまう。
偏差値なども集団に依存する。 ⚫ 項目依存性 CTTでは、テスト得点という受験者の能力に関する情報が、テストに含まれる項目 によって変わってしまう。 → 項目反応理論では、これらの問題に対処することができる。
項目反応理論の基礎 Basics of Item Reaction Theory 47
いま、なぜ項目反応理論(IRT)なのか?(再掲) 48 ⚫ 背景 • 項目反応理論の発展とコンピューター性能の向上 – 1950年代に提案、60年代に体系化、80年代に実務での採用が広がる • エビデンスに基づく政策決定(EBPM)の広がり
• 大規模な学力試験の作成・運用においてグローバルスタンダードになっている(e.g., TOEIC, TOEFL, PISA, TIMSS) ⚫ IRTのメリット(豊田,2012を基に作成) • 問題項目や受験者集団の能力分布に左右されない公平な評価が可能 ➢ 項目に依存しない評価(項目依存性の克服) ➢ 集団に依存しない評価(集団依存性の克服) • 項目特性の詳細な分析が可能(どのような能力集団に対して、弁別性を持つのかなど) • 測定精度を細かく確認できる • 平均点を事前に制御できる • コンピューター適応型テスト(CAT)によって、受験者ごとに最適な問題を出題できるよ うになる
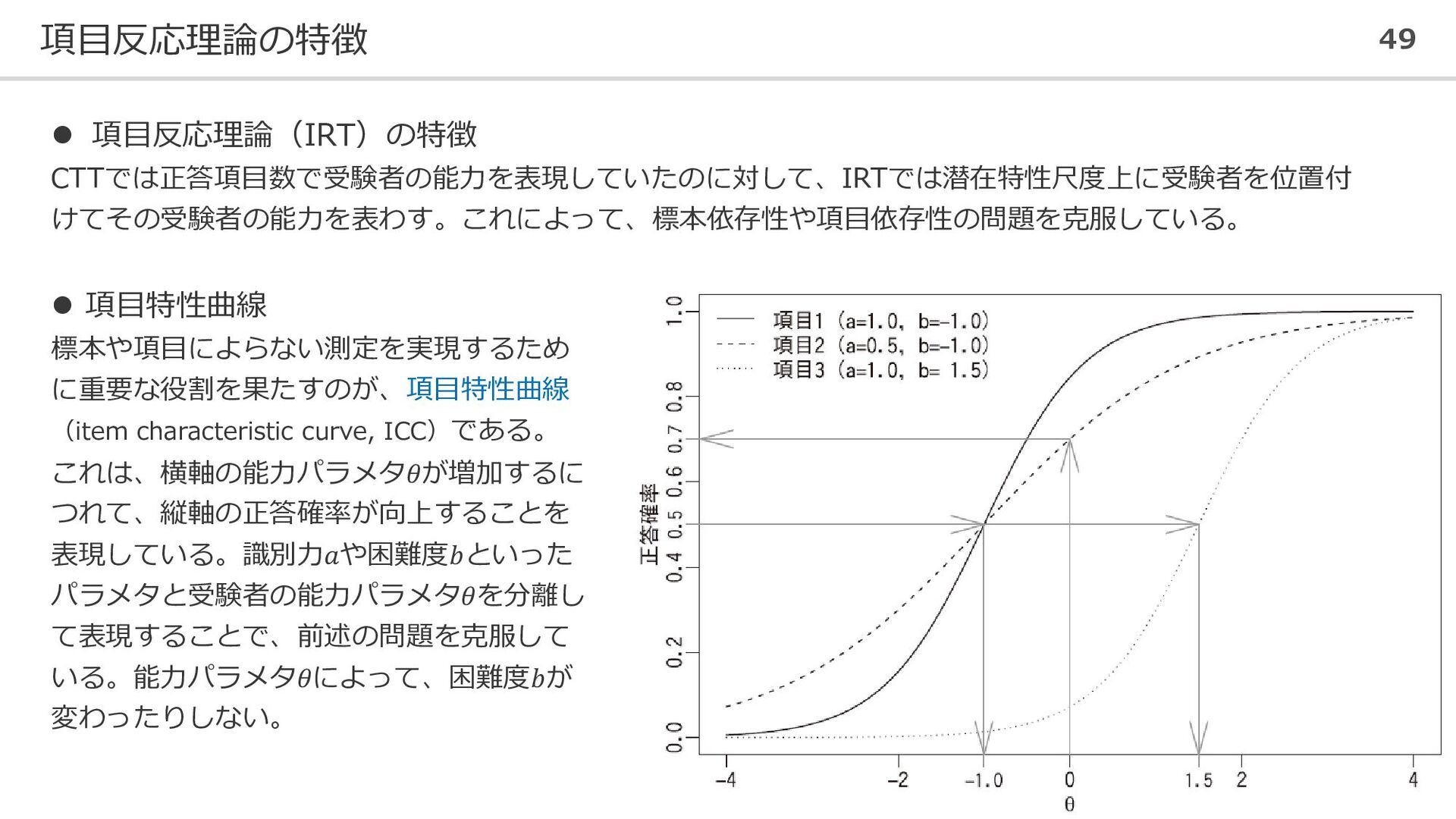
項目反応理論の特徴 49 ⚫ 項目反応理論(IRT)の特徴 CTTでは正答項目数で受験者の能力を表現していたのに対して、IRTでは潜在特性尺度上に受験者を位置付 けてその受験者の能力を表わす。これによって、標本依存性や項目依存性の問題を克服している。 ⚫ 項目特性曲線 標本や項目によらない測定を実現するため に重要な役割を果たすのが、項目特性曲線
(item characteristic curve, ICC)である。 これは、横軸の能力パラメタ𝜃が増加するに つれて、縦軸の正答確率が向上することを 表現している。識別力𝑎や困難度𝑏といった パラメタと受験者の能力パラメタ𝜃を分離し て表現することで、前述の問題を克服して いる。能力パラメタ𝜃によって、困難度𝑏が 変わったりしない。
項目反応モデルの種類 50 ある能力値𝜃の受験者が項目𝑗に正答する確率𝑃𝑗 (𝜃)を以下のように表現する。 ここで、𝑏𝑗 は項目𝑗の困難度、𝑎𝑗 は識別力、𝑐𝑗 は当て推量を表すパラメタである。 Dは尺度因子と呼ばれ、定数として1.0(ロジスティック計量)か1.7(正規計量)を用いる。 ⚫
1パラメタ・ロジスティックモデル(1PLM) ※別名:ラッシュモデル 𝑃𝑗 𝜃 = 1 1 + exp(−𝐷 𝜃 − 𝑏𝑗 ) , −∞ < 𝜃 < ∞ ⚫ 2パラメタ・ロジスティックモデル(2PLM) 𝑃𝑗 𝜃 = 1 1 + exp(−𝐷𝑎𝑗 𝜃 − 𝑏𝑗 ) , −∞ < 𝜃 < ∞ ⚫ 3パラメタ・ロジスティックモデル(3PLM) 𝑃𝑗 𝜃 = 𝑐𝑗 + (1 − 𝑐𝑗 ) 1 1 + exp(−𝐷𝑎𝑗 𝜃 − 𝑏𝑗 ) , −∞ < 𝜃 < ∞ このような関数によって、能力が高いほど正答する確率が高まる関係を表現している。
項目反応モデルの比較 51 ⚫ 3つのモデルの推薦順位(大友,1996 を基に作成) 観点 1PLM 2PLM 3PLM 推定の正確度
2 1 3 最小標本数 1 (N=100~) 2 (N=300~) 3 (N=1000~) 与えてくれる情報 3 2 1 解釈の容易性 1 2 3 採用実績 2 1 3 → 本勉強会では、2PLMに基づく解説を行う。
項目特性曲線(ICC)とその解釈 52 ⚫ 2PLMのICCの関数 𝑃𝑗 𝜃 = 1 1 +
exp(−𝐷𝑎𝑗 𝜃 − 𝑏𝑗 ) ※ここでは、D=1.7とする ⚫ ICCの2通りの解釈(南風原,1991) A) 能力値が𝜃である受験者の正答確率 B) 能力値が𝜃である受験者母集団における正答者の割合 # 項目反応理論の基礎 #### # 能力-1.0の人が正答する確率 x <- -1.0 1/(1+exp(-1.7*1.0*(x-(-1)))) # item1 1/(1+exp(-1.7*0.5*(x-(-1)))) # item2 1/(1+exp(-1.7*1.0*(x-1.5))) # item3 # 2PLMのICC curve(1/(1+exp(-1.7*1.0*(x-(-1)))), -4,4, lty=1, xlab = "能力θ", ylab = "正答確率") # item1 curve(1/(1+exp(-1.7*0.5*(x-(-1)))), lty=2, add=TRUE) # item2 curve(1/(1+exp(-1.7*1.0*(x-1.5))), lty=3, add=TRUE) # item3
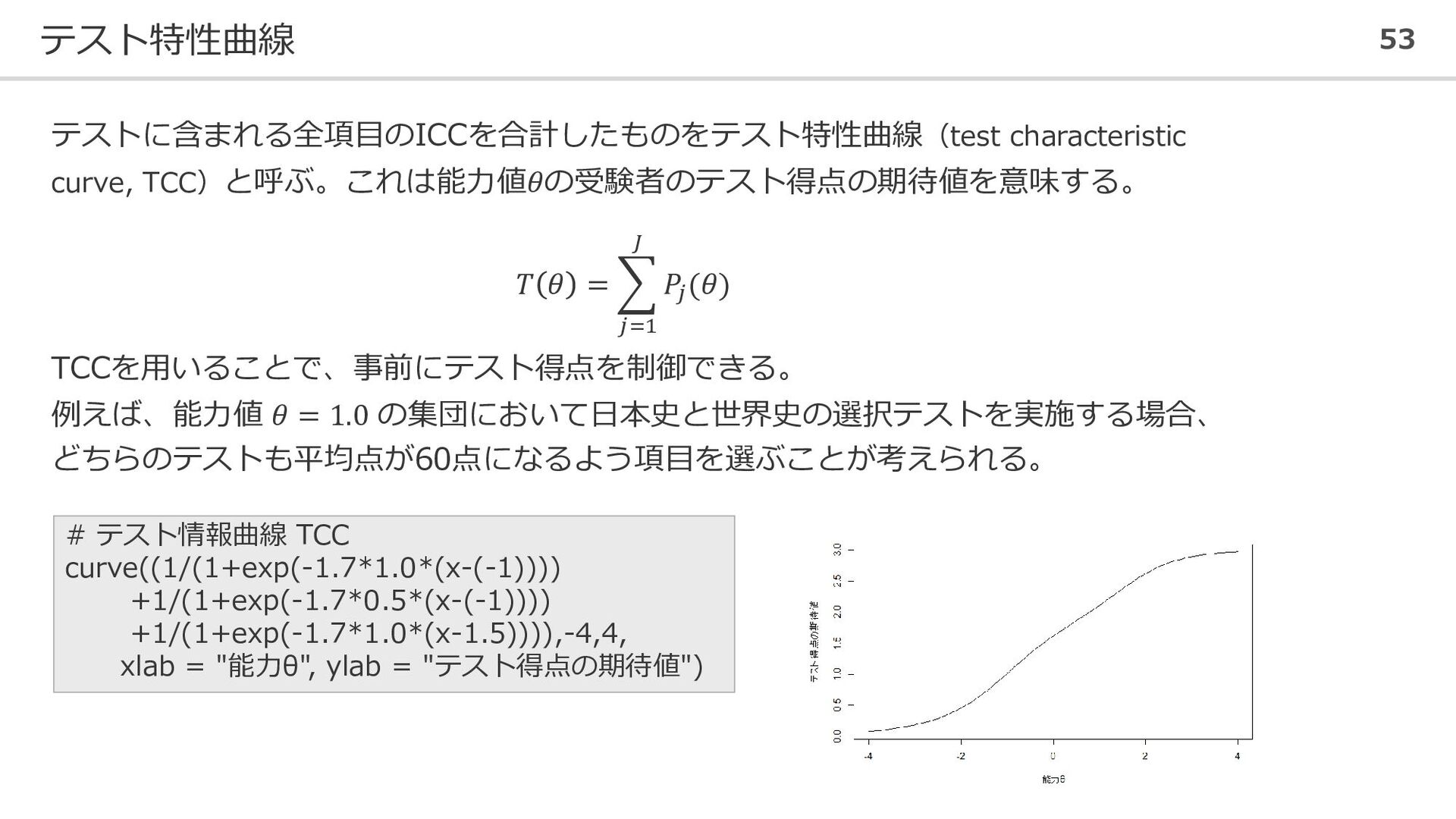
テスト特性曲線 53 テストに含まれる全項目のICCを合計したものをテスト特性曲線(test characteristic curve, TCC)と呼ぶ。これは能力値𝜃の受験者のテスト得点の期待値を意味する。 𝑇 𝜃 =
𝑗=1 𝐽 𝑃𝑗 (𝜃) TCCを用いることで、事前にテスト得点を制御できる。 例えば、能力値 𝜃 = 1.0 の集団において日本史と世界史の選択テストを実施する場合、 どちらのテストも平均点が60点になるよう項目を選ぶことが考えられる。 # テスト情報曲線 TCC curve((1/(1+exp(-1.7*1.0*(x-(-1)))) +1/(1+exp(-1.7*0.5*(x-(-1)))) +1/(1+exp(-1.7*1.0*(x-1.5)))),-4,4, xlab = "能力θ", ylab = "テスト得点の期待値")
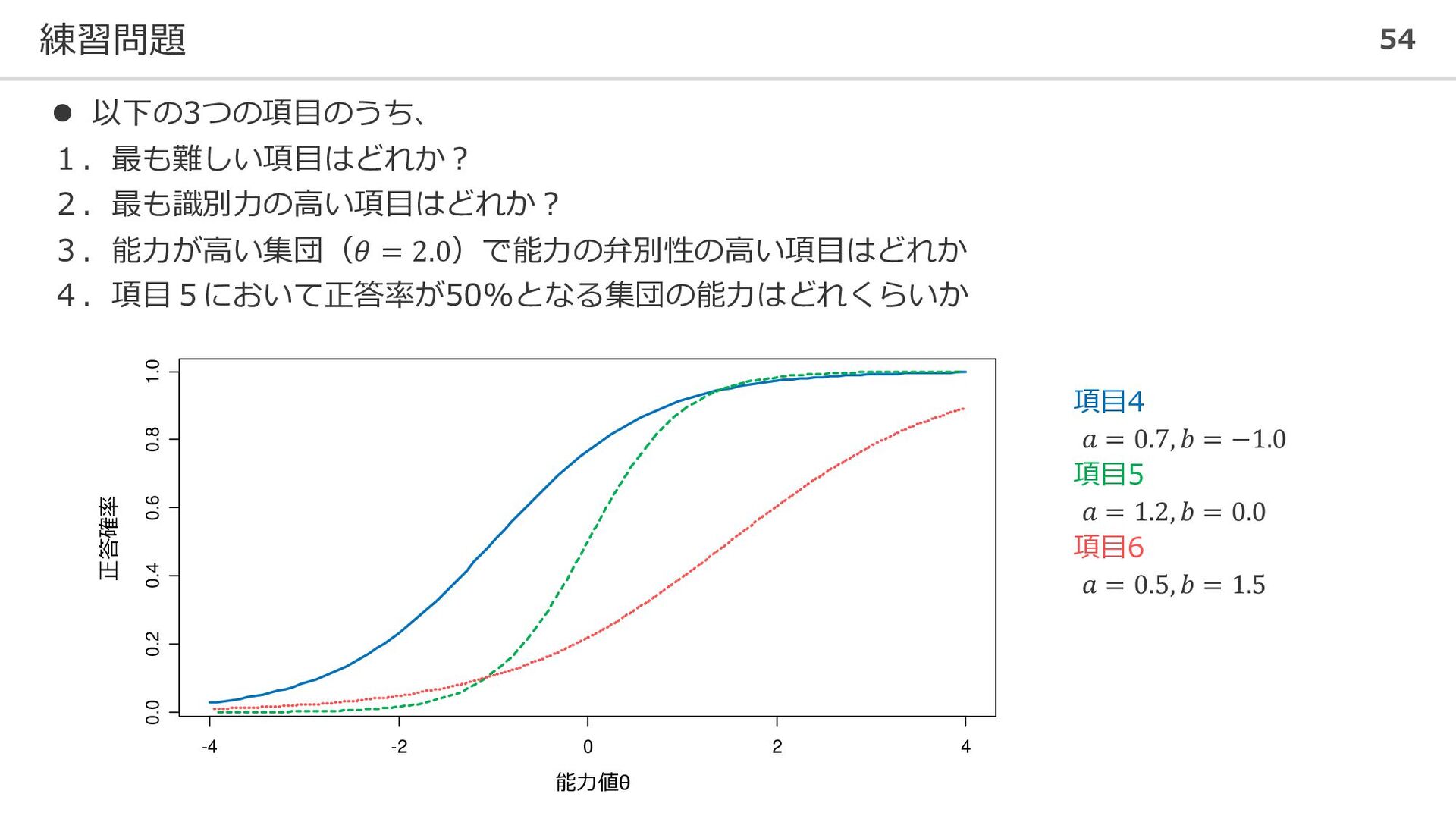
練習問題 54 ⚫ 以下の3つの項目のうち、 1.最も難しい項目はどれか? 2.最も識別力の高い項目はどれか? 3.能力が高い集団(𝜃 = 2.0)で能力の弁別性の高い項目はどれか 4.項目5において正答率が50%となる集団の能力はどれくらいか
-4 -2 0 2 4 0.0 0.2 0.4 0.6 0.8 1.0 能力値θ 正答確率 項目4 𝑎 = 0.7, 𝑏 = −1.0 項目5 𝑎 = 1.2, 𝑏 = 0.0 項目6 𝑎 = 0.5, 𝑏 = 1.5
2PLMにおけるパラメタ推定法 Parameter Estimation in 2PLM 55
パラメタ推定の種類 56 ⚫ 既知の項目パラメタを用いて、能力パラメタの推定を行う – 最尤推定法(ML) – ベイズ推定法 • EAP推定
• MAP推定 ⚫ (既知の)能力パラメタを用いて、項目パラメタの推定を行う – 周辺最尤推定法(MML) – 周辺ベイズ推定(MBE) – マルコフ連鎖モンテカルロ法(MCMC) ※ 数学的に少し高度なので、数理面の紹介は最低限にとどめる。
能力パラメタの推定:最尤推定法 57 2PLMのICCは以下の通りであった。また、誤答確率𝑄𝑗 (𝜃)は、1-正答確率で表せる。 𝑃𝑗 𝜃 = 1 1 +
exp(−𝐷𝑎𝑗 𝜃 − 𝑏𝑗 ) , 𝑄𝑗 𝜃 = 1 − 𝑃𝑗 𝜃 このICCを計算する自作関数を定義してみよう。 能力値𝜃の受験者がテストに含まれる項目群に正答する確率の総乗の関数 L(尤度関数) を考えてみる。ここで能力値𝜃は未知であり、尤度関数Lは𝜃の関数である。 𝐿 𝜃𝑖 𝐮𝑖 = ෑ 𝑗=1 𝐽 𝑃𝑗 𝜃𝑖 𝑢𝑖𝑗𝑄𝑗 𝜃𝑖 1−𝑢𝑖𝑗 # パラメタ推定法 #### # 能力パラメタの最尤推定 # 2PLMのICCの関数を定義 icc2PL <- function(a, b, theta){ prob <- 1/(1+exp(-1.7*a*(theta-b))) prob }
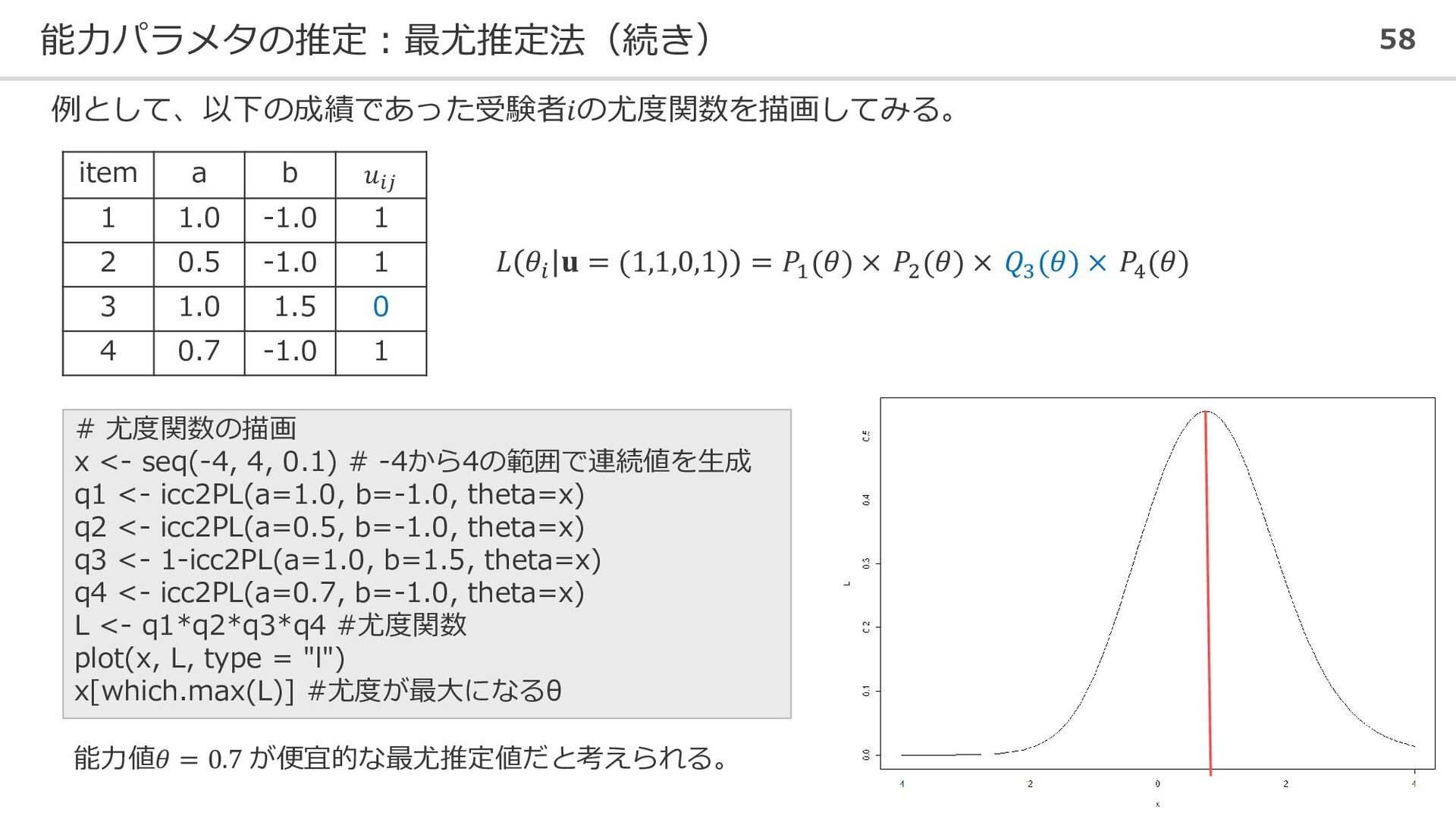
能力パラメタの推定:最尤推定法(続き) 58 例として、以下の成績であった受験者𝑖の尤度関数を描画してみる。 item a b 𝑢𝑖𝑗 1 1.0 -1.0
1 2 0.5 -1.0 1 3 1.0 1.5 0 4 0.7 -1.0 1 𝐿 𝜃𝑖 𝐮 = (1,1,0,1) = 𝑃1 (𝜃) × 𝑃2 (𝜃) × 𝑄3 (𝜃) × 𝑃4 (𝜃) # 尤度関数の描画 x <- seq(-4, 4, 0.1) # -4から4の範囲で連続値を生成 q1 <- icc2PL(a=1.0, b=-1.0, theta=x) q2 <- icc2PL(a=0.5, b=-1.0, theta=x) q3 <- 1-icc2PL(a=1.0, b=1.5, theta=x) q4 <- icc2PL(a=0.7, b=-1.0, theta=x) L <- q1*q2*q3*q4 #尤度関数 plot(x, L, type = "l") x[which.max(L)] #尤度が最大になるθ 能力値𝜃 = 0.7 が便宜的な最尤推定値だと考えられる。
能力パラメタの推定:最尤推定法(続き) 59 尤度関数は、項目が増えるほど尤度の値が極端に小さくなり、扱いにくい。 そこで、尤度関数の対数をとった対数尤度関数というものを考える。 ln𝐿 = 𝑗=1 𝐽 [𝑢𝑗
ln𝑃𝑗 𝜃 + 1 − 𝑢𝑗 ln 1 − 𝑃𝑗 𝜃 ] Rで対数尤度関数を描画すると右図のようになる。この対数尤度が最大になる点を求め るのが最尤推定である。対数尤度関数を微分して頂点を求めれば良さそうだ。 しかし、この点は解析的に求めることはできないため、 実際にはNewton-Raphson法といった逐次近似法を用いる。 # 対数尤度関数の描画 LL <- log(L) plot(x, LL, type = "l")
最尤推定法の問題点とEAP推定法 60 先ほどの例において、4問すべてに正解だったとして、尤度関数を求めてみよう。 すると、全問正解の場合、尤度関数が発散してしまい、能力値𝜃の推定に問題が発 生することが分かる。 このような問題に対して、ベイズ推定法では適切な事前分布を用いることで、 この問題に対処できる。数理的な説明は省略するが、後の演習ではベイズ推定 法の1種であるEAP推定法を使用する。 # 全問正解の場合の尤度関数
x <- seq(-4, 4, 0.1) # -4から4の範囲で連続値を生成 q1 <- icc2PL(a=1.0, b=-1.0, theta=x) q2 <- icc2PL(a=0.5, b=-1.0, theta=x) q3 <- icc2PL(a=1.0, b=1.5, theta=x) q4 <- icc2PL(a=0.7, b=-1.0, theta=x) L <- q1*q2*q3*q4 #尤度関数 plot(x, L, type = "l") x[which.max(L)] #尤度が最大になるθ
項目パラメタの推定 61 ⚫ 周辺最尤推定法(MML) 項目パラメタの推定には、周辺最尤推定法がよく用いられる。 能力値θの分布が標準正規分布に従うと仮定し(周辺化)、項目パラメタの尤 度関数から能力パラメタを積分消去する。こうして求められる周辺尤度関数 とEMアルゴリズムという計算法を用いて、項目パラメタを推定する。 ⚫ マルコフ連鎖モンテカルロ法(MCMC)
近年では、PC性能の向上に伴い、マルコフ連鎖モンテカルロ法を用いて事後 分布を近似した乱数を発生させて、EAP推定値やMAP推定値を求める方法も 採用が進んでいる。しかし、計算負荷が高いためこの勉強会では扱わない。
演習 62 ⚫ data2.csv を用いて、周辺最尤推定法による項目パラメタの推定を行う。 続いて、推定した項目パラメタを用いて能力パラメタを2種類の方法で推定する。 # IRT演習 #### #
データの読み込み dat3 <- read.csv("data2.csv") head(dat3) # 項目パラメタの推定 library(irtoys) ip <- est(resp = dat3, model = "2PL", engine = "ltm") ip$est # 項目特性曲線ICCの描画 val.icc <- irf(ip$est) #各項目の項目特性関数 plot(val.icc, label = T, co = NA) # テスト特性曲線TCCの描画 val.tcc <- trf(ip$est) plot(val.tcc) # 能力パラメタの推定 res.ml <- mlebme(resp = dat3, ip = ip$est, method = "ML") #最尤推定法 head(res.ml) res.eap <- eap(resp = dat3, ip = ip$est, qu=normal.qu()) #EAP推定法 head(res.eap) ※これらのパッケージでは、D=1.0となっている点に注意。 識別力𝑎を1.7で割れば、D=1.7の時と一致する。
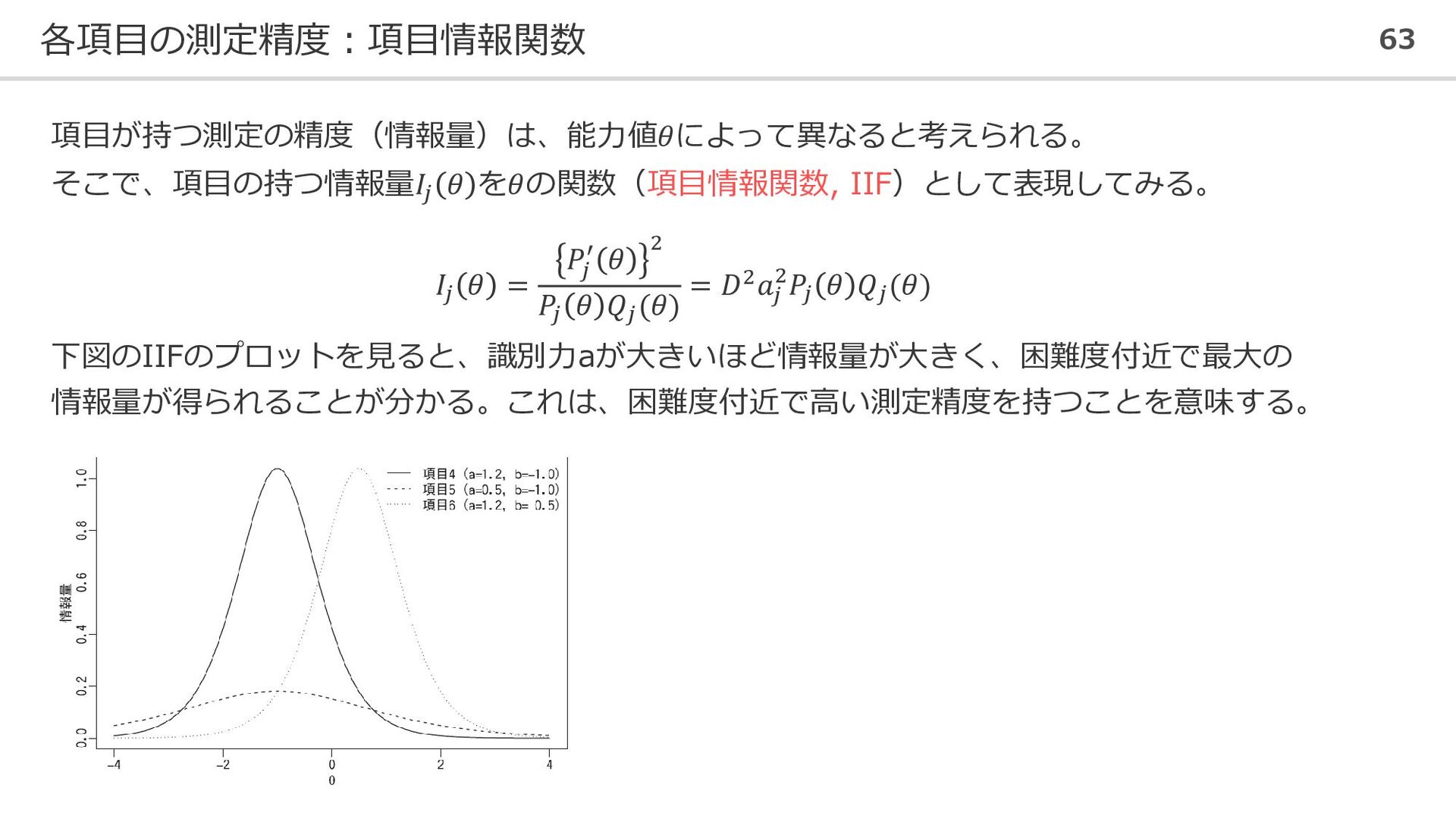
各項目の測定精度:項目情報関数 63 項目が持つ測定の精度(情報量)は、能力値𝜃によって異なると考えられる。 そこで、項目の持つ情報量𝐼𝑗 𝜃 を𝜃の関数(項目情報関数, IIF)として表現してみる。 𝐼𝑗 𝜃 =
𝑃𝑗 ′ 𝜃 2 𝑃𝑗 𝜃 𝑄𝑗 (𝜃) = 𝐷2𝑎𝑗 2𝑃𝑗 𝜃 𝑄𝑗 (𝜃) 下図のIIFのプロットを見ると、識別力aが大きいほど情報量が大きく、困難度付近で最大の 情報量が得られることが分かる。これは、困難度付近で高い測定精度を持つことを意味する。
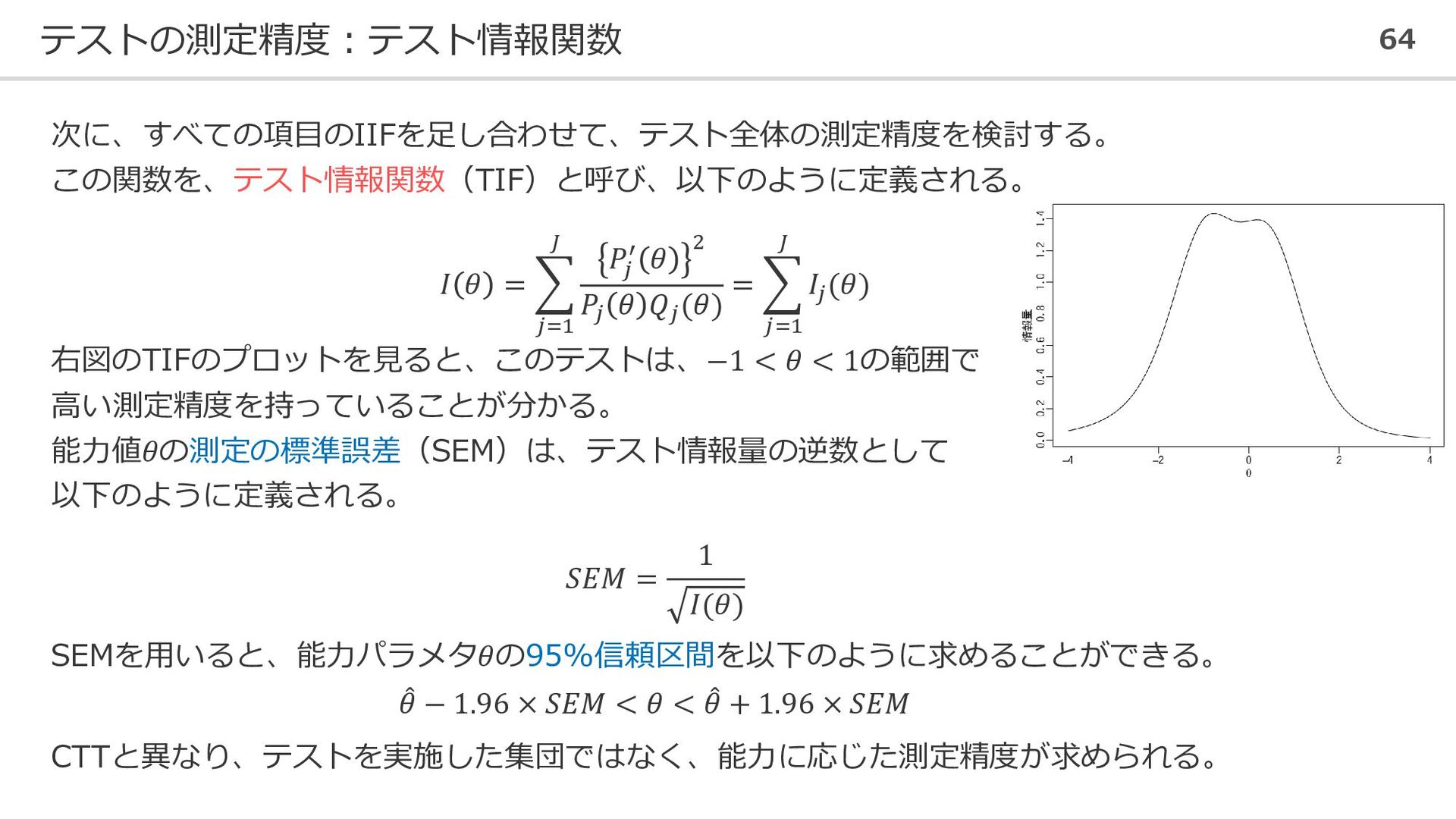
テストの測定精度:テスト情報関数 64 次に、すべての項目のIIFを足し合わせて、テスト全体の測定精度を検討する。 この関数を、テスト情報関数(TIF)と呼び、以下のように定義される。 𝐼 𝜃 = 𝑗=1 𝐽
𝑃𝑗 ′ 𝜃 2 𝑃𝑗 𝜃 𝑄𝑗 (𝜃) = 𝑗=1 𝐽 𝐼𝑗 (𝜃) 右図のTIFのプロットを見ると、このテストは、−1 < 𝜃 < 1の範囲で 高い測定精度を持っていることが分かる。 能力値𝜃の測定の標準誤差(SEM)は、テスト情報量の逆数として 以下のように定義される。 𝑆𝐸𝑀 = 1 𝐼(𝜃) SEMを用いると、能力パラメタ𝜃の95%信頼区間を以下のように求めることができる。 መ 𝜃 − 1.96 × 𝑆𝐸𝑀 < 𝜃 < መ 𝜃 + 1.96 × 𝑆𝐸𝑀 CTTと異なり、テストを実施した集団ではなく、能力に応じた測定精度が求められる。
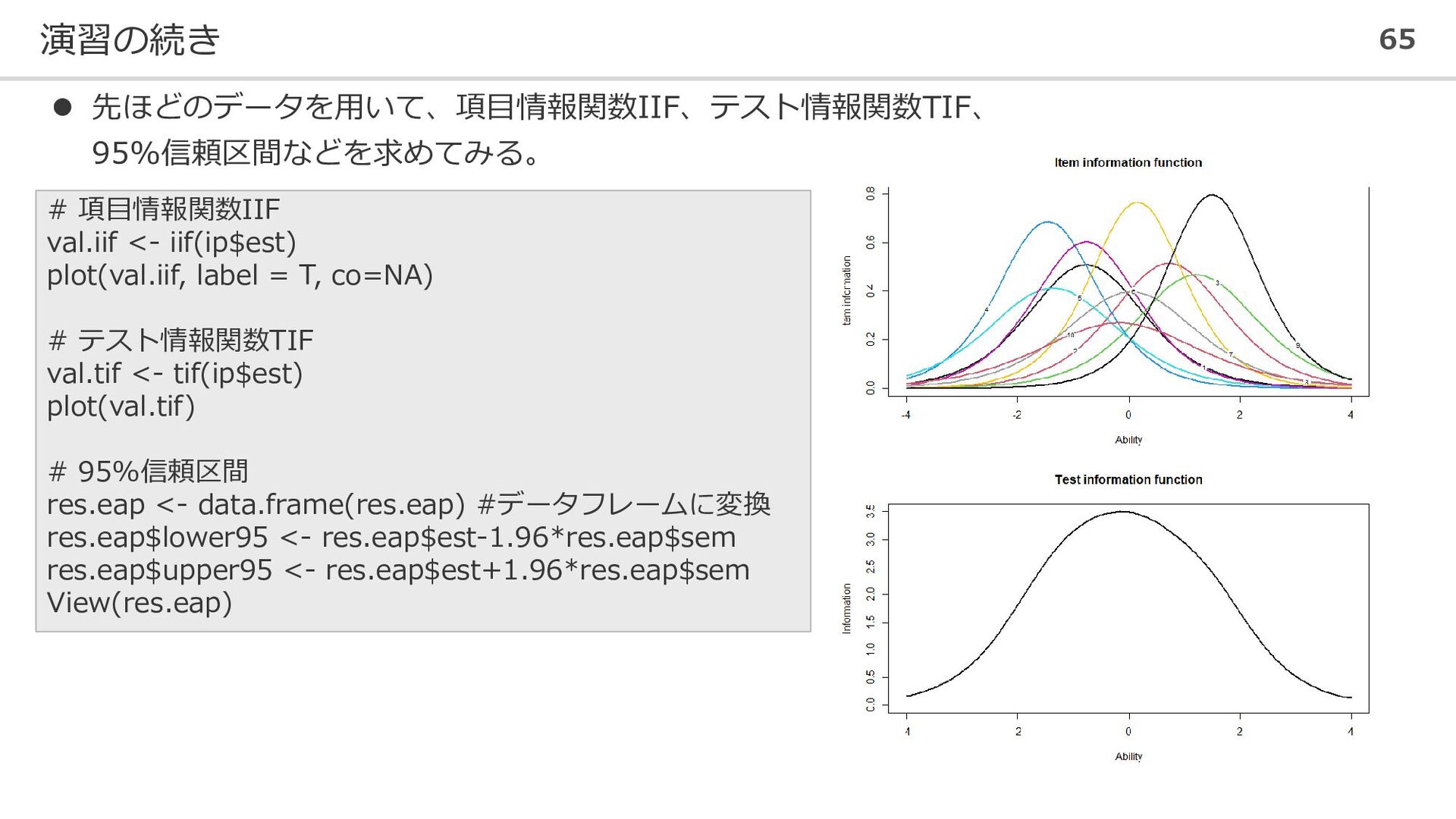
演習の続き 65 ⚫ 先ほどのデータを用いて、項目情報関数IIF、テスト情報関数TIF、 95%信頼区間などを求めてみる。 # 項目情報関数IIF val.iif <- iif(ip$est)
plot(val.iif, label = T, co=NA) # テスト情報関数TIF val.tif <- tif(ip$est) plot(val.tif) # 95%信頼区間 res.eap <- data.frame(res.eap) #データフレームに変換 res.eap$lower95 <- res.eap$est-1.96*res.eap$sem res.eap$upper95 <- res.eap$est+1.96*res.eap$sem View(res.eap)
データと項目反応モデルの適合度 Goodness of fit between data and item response model
66
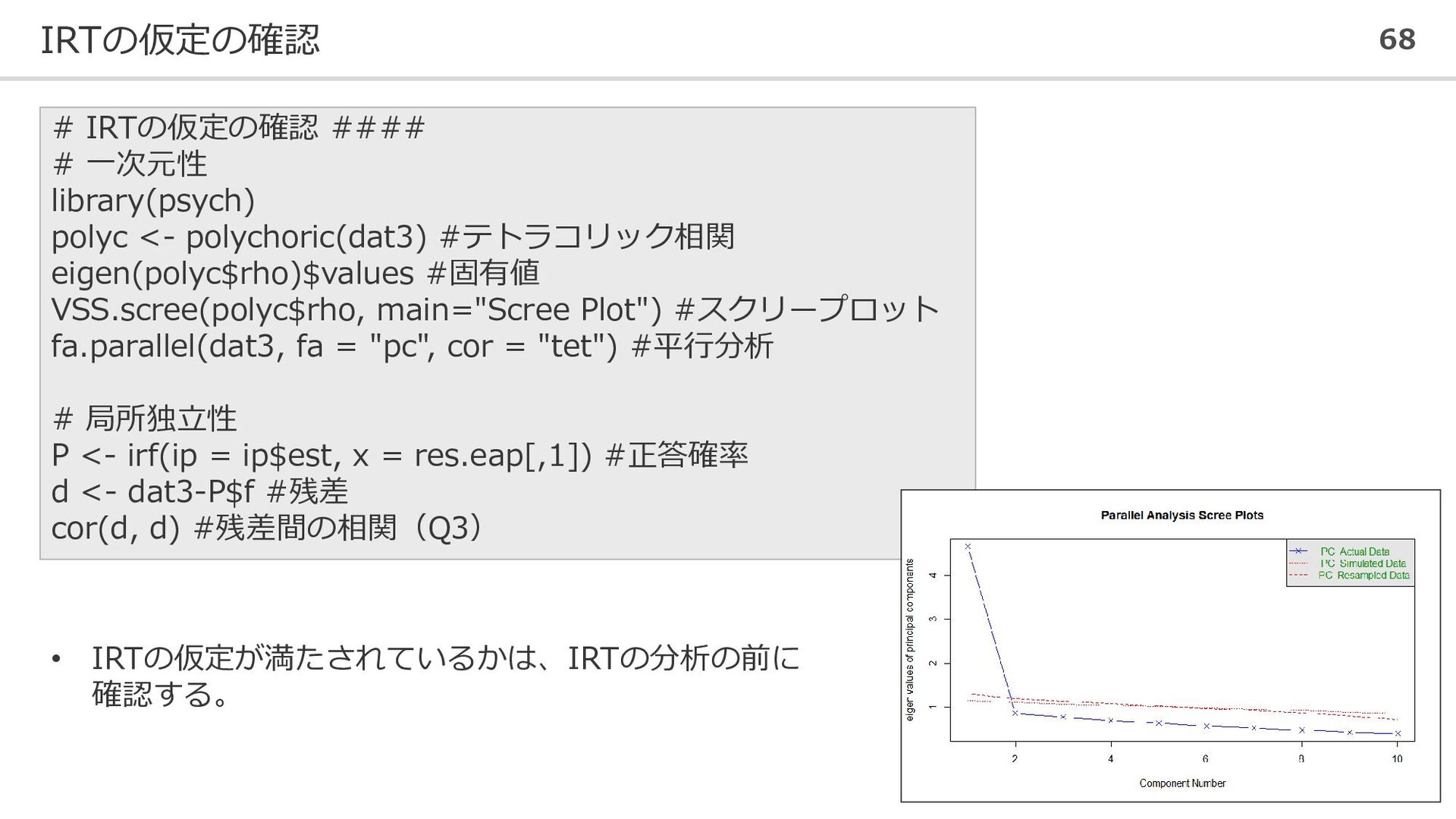
IRTの仮定 67 IRTの項目反応モデルを適用するには、データが2つの仮定を満たす必要がある。 ①一次元性(unidimensionality) 対象となる項目群が1種類(1因子)の能力を測定している → 因子分析の枠組みで、1因子への適合を確認する。因子数の確認方法には、以下の方法がある。 ガットマン基準:固有値が1以上の因子を採用する スクリー基準:固有値の大きさをプロットし、推移がなだらかになる前までを抽出する 平行分析:ランダムに生成したデータの固有値よりも大きな固有値を持つ因子を選択
②局所独立性(local independence) 能力値𝜃を固定したときに、各テスト項目への反応が互いに独立である。 言い換えれば、ある項目に正答するかどうかが他の項目の正答に影響しない。 → Yenの𝑄3 統計量を用いて検証する。 𝑄3 統計量が0.2を下回ることが望ましい。 ◼ 局所独立が侵害される例 項目連鎖:問題1の計算結果を使って問題2に回答する必要がある。 文脈依存:同じ文章題に紐づけられた小問である。
IRTの仮定の確認 68 # IRTの仮定の確認 #### # 一次元性 library(psych) polyc <-
polychoric(dat3) #テトラコリック相関 eigen(polyc$rho)$values #固有値 VSS.scree(polyc$rho, main="Scree Plot") #スクリープロット fa.parallel(dat3, fa = "pc", cor = "tet") #平行分析 # 局所独立性 P <- irf(ip = ip$est, x = res.eap[,1]) #正答確率 d <- dat3-P$f #残差 cor(d, d) #残差間の相関(Q3) • IRTの仮定が満たされているかは、IRTの分析の前に 確認する。
適合度 69 データの項目反応モデルに対する当てはまりの良さを評価する指標として適合度がある。 適合度は、モデルから予測される予測値と実際のデータのズレの大きさで評価される。 適合度指標には、以下の3種類がある。 *個人適合度:受験者の反応パタンが受験者の能力から予測されるパタンと一致しているか 例)𝑧3 統計量など *項目適合度:項目特性曲線ICCから予測される正答率と実際の正答率が一致しているか 例)Χ2統計量,𝐺2統計量など
*全体適合度:モデル全体から予測される反応パタンの期待度数と観測度数が一致しているか 例) 𝐺2統計量など ➢ 詳しい解説は、加藤・山田・川端(2014)を参照。 # 適合度の確認 #### pfit <- api(dat3, ip$est) #個人適合度 which(abs(pfit)>1.96) #z3が絶対値1.96を超える受験者 itf(dat3, ip$est, item=1) #項目1の項目適合度G^2 ← ただし、5%程度は常に超えることに注意 ← 有意でないことが望ましいが、有意になったか らといって直ちに排除するべきではない。出力さ れる図からズレの程度を確認。
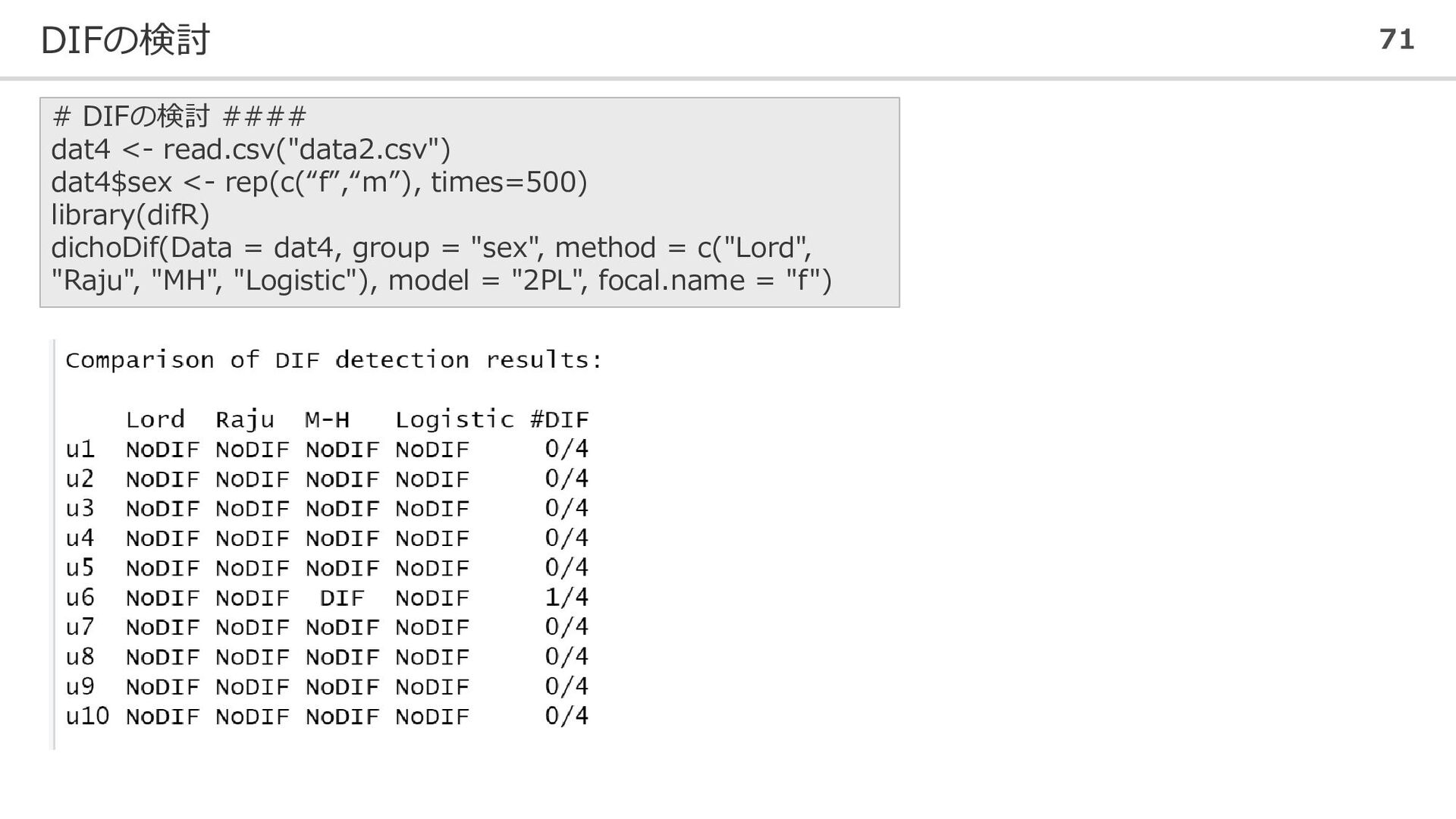
特異性項目機能 70 測定しようとしている能力が等しいのに、受験者が所属する下位集団(e.g., 性別、民族) によって正答確率が異なる場合、その項目には特異性項目機能(differential item functioning, DIF)が存在するとして問題視される。 DIFには、常に片方の集団の正答確率が高い均一DIFと、能力によって集団の有利・不利 が入れ替わる不均一DIFが存在する。
DIFを検出するには、以下のような方法がある(豊田,2013)。 ⚫ IRTに基づく方法 – Lordの方法 – Rajuの方法 – LR検定 ⚫ IRTに基づかない方法 – Mantel-Haentszel法 – ロジスティック法 図は、熊谷・荘島(2015)より
DIFの検討 71 # DIFの検討 #### dat4 <- read.csv("data2.csv") dat4$sex <-
rep(c(“f”,“m”), times=500) library(difR) dichoDif(Data = dat4, group = "sex", method = c("Lord", "Raju", "MH", "Logistic"), model = "2PL", focal.name = "f")
補足:様々な項目反応モデル 72 データの種類に応じて、様々な項目反応モデルが提案されている。 ⚫ 2値データ – 1PLM, 2PLM, 3PLM –
ラッシュモデル ⚫ 多値データ – 段階反応モデル(GRM) – 部分得点モデル(PCM) – 一般化部分得点モデル(GPCM) ⚫ 多因子データ – 多次元項目反応モデル(MIRT) 各モデルの詳細については、加藤・山田・川端(2014)や豊田(2013) を参照。 # 段階反応モデルの例 #### dat5 <- dat1[,16:22]-1 #批判的思考力の質問紙 7件法 head(dat5) library(ltm) res.grm <- ltm::grm(dat5) res.grm #項目パラメタ plot(res.grm, type="IIC", items=0) #TIF dat5$theta <- factor.scores.grm(res.grm, resp.patterns = dat5, method = "EAP")$score.dat$Exp ◼ 段階反応モデル(GRM)の実行例
演習 73 ⚫ data4.csv を用いて項目反応理論に基づく分析を実行せよ 基礎集計 点双列相関係数に基づくスクリーニング
一次元性の確認 局所独立性の確認 項目パラメタの推定 ICCの描画 TCCの描画 適合度の確認 能力パラメタの推定 TIFの描画 測定精度の検討
テストの開発と運用 74
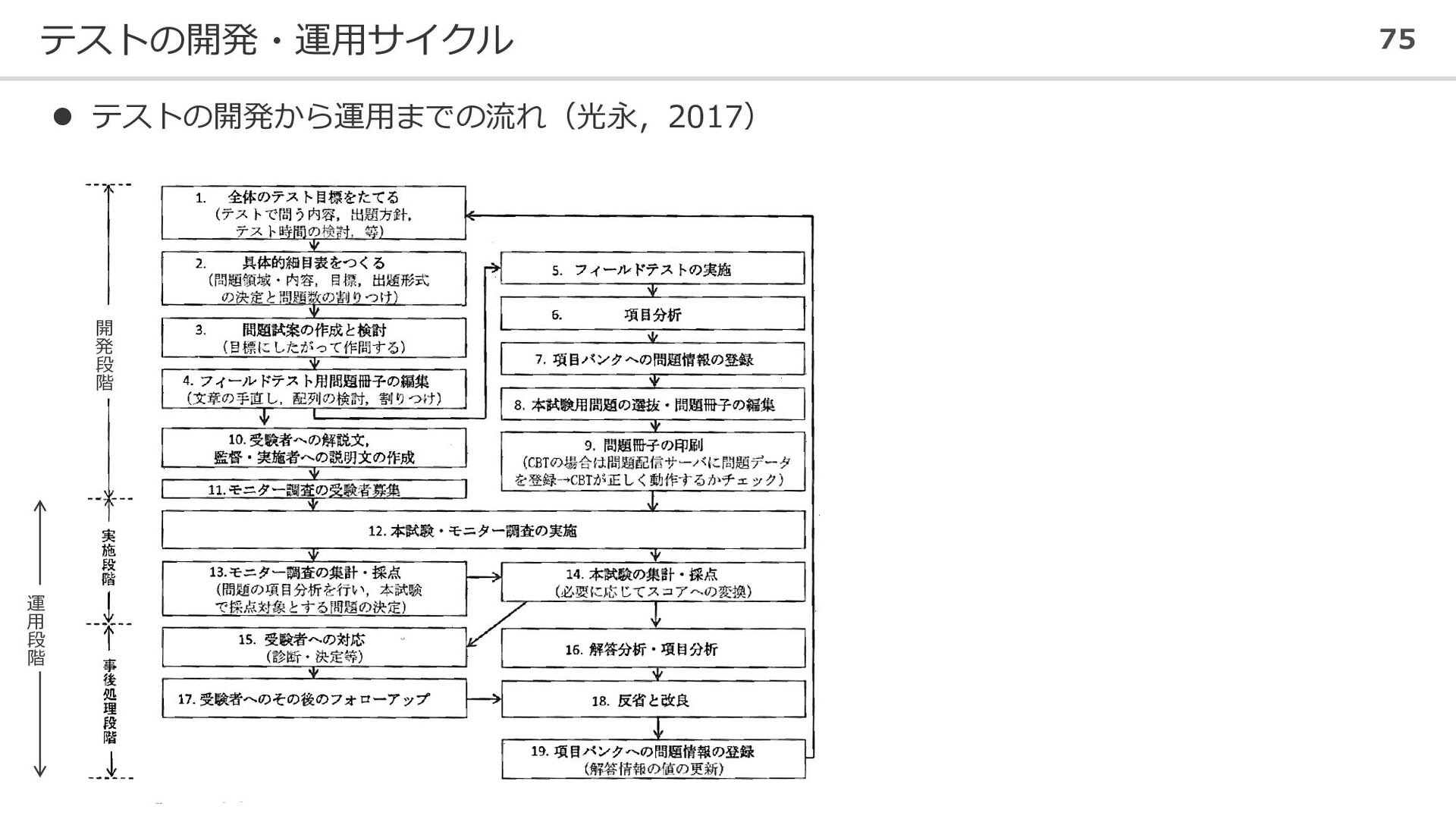
テストの開発・運用サイクル 75 ⚫ テストの開発から運用までの流れ(光永,2017) 開 発 段 階 運 用
段 階
テストの開発サイクル:妥当性 76 ⚫ 妥当性と妥当化 • 妥当性(validity):測りたいものが測れているかどうか(Borsboom et al., 2004) •
妥当化(validation):得点の解釈に必要な証拠を集める(Messick, 1995) 構成概念 妥当性 内容的な側面の証拠 本質的な側面の証拠 構造的な側面の証拠 一般化可能性の側面の証拠 外的な側面の証拠 ⚫ 妥当性の証拠(Messick, 1995; 村山,2012) 項目の内容が目的とした領域を十分に代表しているかの証拠 項目への反応プロセスに関する理論的・実証的証拠 項目間の関係が理論的な構造に一致しているかの証拠 他の指標との間に予測通りの相関関係が示されるかの証拠 測定がどの程度新しい状況に一般化できるかの証拠 結果的な側面の証拠 その測定を利用した結果として、悪影響が生じないかの証拠
内容的な側面の証拠|領域の代表性 77 ◼ 構成概念の定義の明確化 • どのような学力を測定しようとしているのかを分析し、定義を明確化する • カリキュラム分析・授業観察 ➢ 〇〇力とは?下位能力は?
➢ 〇〇力が高い学習者の姿は? ➢ 既存の理論との関係性は? ◆ 内容的な側面の証拠 項目の内容が目的とした領域を十分に代表しているかの証拠 Q1 Q5 Q6 Q3 Q2 Q4 Q1 Q5 Q6 Q3 Q2 Q4 良い例 悪い例 Q1 悪い例 ◼ 領域を代表した項目の作成 • 目的とした領域を十分に代表できるような項目群を作成する 例)理科における〇〇能力の問題の題材 Q1: 力と運動 Q5: 動物 Q2: 電磁気 Q6: 植物 Q3: 無機化学 Q7: 地質 Q4: 有機化学 Q8: 天体
内容的な側面の証拠|定義の明確化 78 ◼ 文章表現の難易度 • 発達段階に応じた文章表現 • 使用する漢字 ◼ 項目作成時の留意点
➢ 系統誤差を減らすことが重要 ⚫ 質問紙の場合 • 局所的な項目の類似性 • ダブルバーレル質問 • 曖昧な表現 • 社会的望ましさバイアス ⚫ テストの場合 • 局所的な項目の依存性 • 測りたい学力以外の要因の影響 • 回答形式 ◼ 複数の立場の専門家(研究者/教師)で項目を吟味 ◆ 問題のある質問項目の例 ➢ 理科好き尺度(仮) Q1: 物理の実験が好き Q2: 化学の実験が好き Q3: 生物の授業の観察や考察が好き Q4: 1日1時間以上理科の勉強をしている ◆ 問題のあるテスト項目の例 Q1. ヒトの肺胞での酸素濃度は相対値100、二酸化炭素 濃度は相対値40である。図に示す酸素解離曲線をもとに、 肺胞の血液における Oxyhämoglobin の割合を求めよ。 Q2. Q1の結果をもとに、次の選択肢の中から正しいもの をすべて選べ。 ◆ 文章の難易度を評価するアプリケーション • 帯3(佐藤,2008) • jreadability(李,2016)
本質的な側面の証拠 79 ◆ 本質的な側面の証拠 ⚫ 項目への反応プロセスに関する理論的・実証的証拠 ⚫ → 学習者から見て妥当かどうか ◼
反応プロセスの検討(予備調査) • 発話思考法(think-aloud)を用いた検討 考えていることを話しながら項目に回答してもらう → 研究者の想定(理論)通りのプロセスを経て回答しているか • 反応時間の分析 → 難易度が高い問題ほど時間がかかりやすい ◼ 本当にあった怖い話(Lederman & O'Malley, 1990) 科学の本質(NOS)の理解度を測る質問紙 「科学の見解は暫定的なものである」 はい/いいえ 暫定的ってどういう意味ですか?
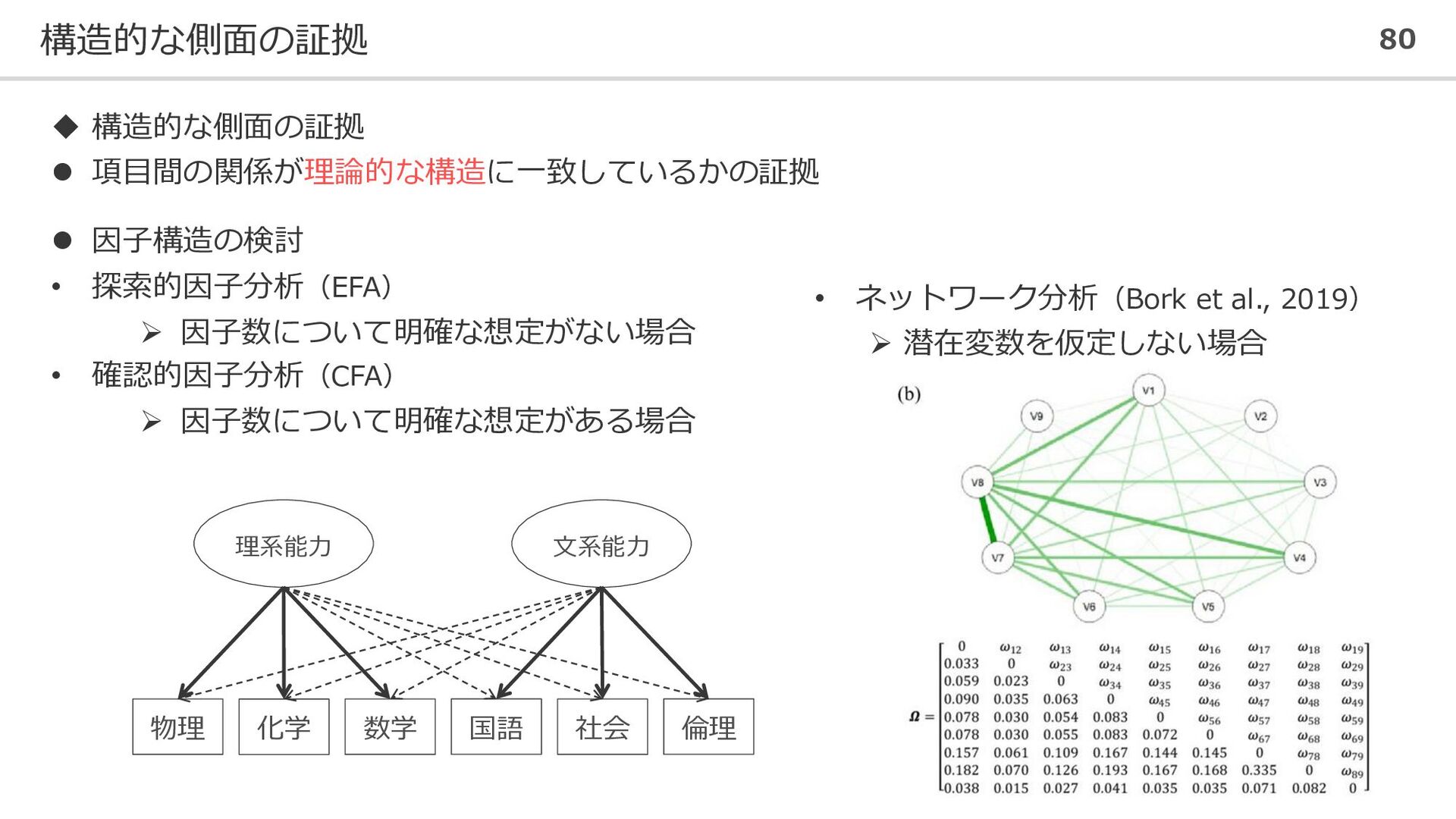
構造的な側面の証拠 80 ◆ 構造的な側面の証拠 ⚫ 項目間の関係が理論的な構造に一致しているかの証拠 ⚫ 因子構造の検討 • 探索的因子分析(EFA)
➢ 因子数について明確な想定がない場合 • 確認的因子分析(CFA) ➢ 因子数について明確な想定がある場合 物理 化学 数学 国語 社会 倫理 理系能力 文系能力 • ネットワーク分析(Bork et al., 2019) ➢ 潜在変数を仮定しない場合
一般化可能性の側面の証拠 81 ◆ 一般化可能性の側面の証拠 ⚫ 測定がどの程度新しい状況(異なる場面、集団など)に一般化できるかの証拠 ⚫ 信頼性の検討 ➢ 信頼性とは?
測定値 = 真値 + 測定誤差 信頼性 = 真値の分散/測定値の分散 • 再テスト法:同じ人に2度の測定を行った際の相関 • Cronbachのα係数 • McDonaldのω係数 • IRTにおける情報量(測定の精度) 信頼性 高 真値の分散 測定誤差 の分散 信頼性 低 真値の分散 測定誤差の分散 測定値の分散
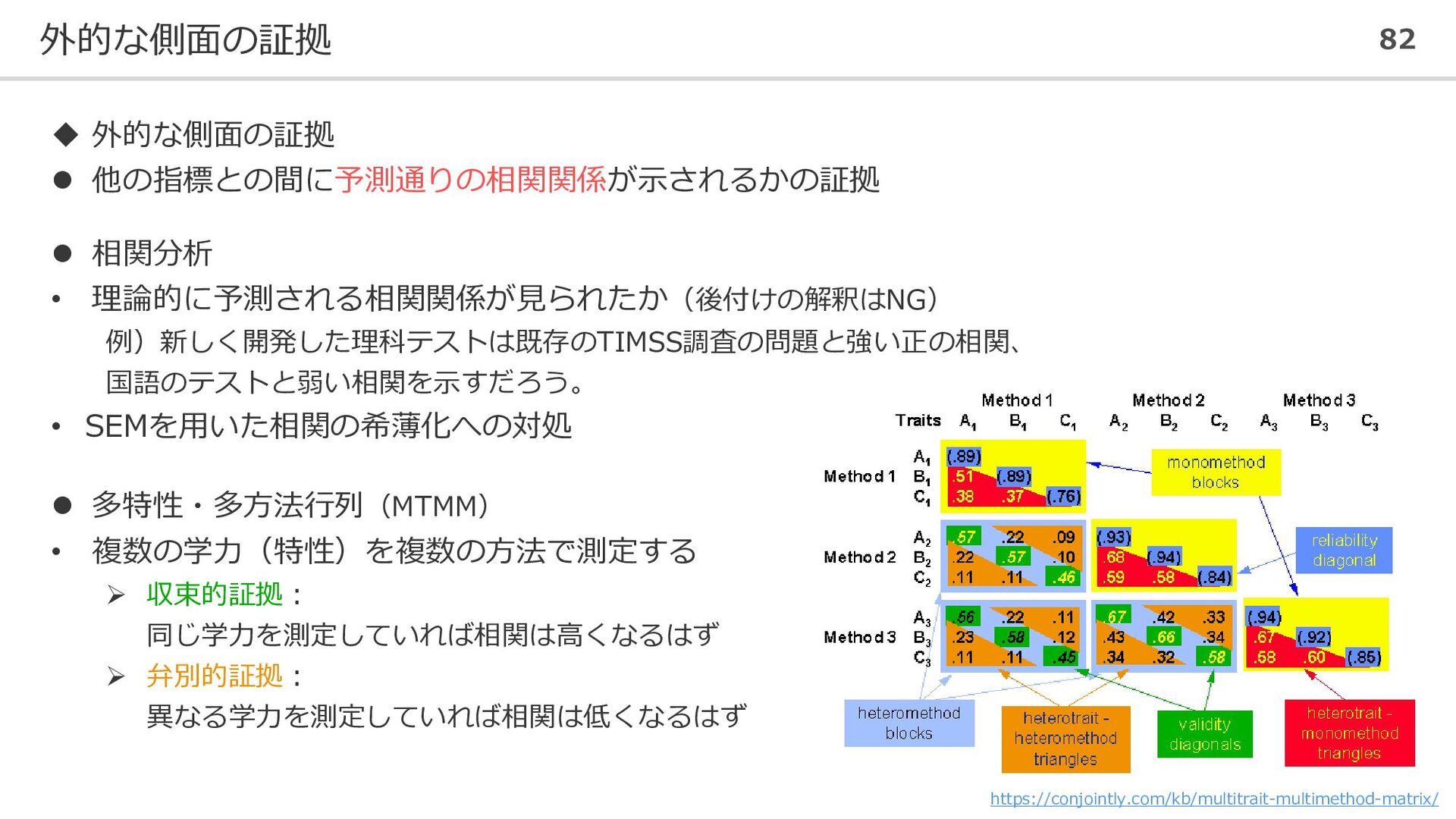
外的な側面の証拠 82 ◆ 外的な側面の証拠 ⚫ 他の指標との間に予測通りの相関関係が示されるかの証拠 ⚫ 相関分析 • 理論的に予測される相関関係が見られたか(後付けの解釈はNG)
例)新しく開発した理科テストは既存のTIMSS調査の問題と強い正の相関、 国語のテストと弱い相関を示すだろう。 • SEMを用いた相関の希薄化への対処 ⚫ 多特性・多方法行列(MTMM) • 複数の学力(特性)を複数の方法で測定する ➢ 収束的証拠: 同じ学力を測定していれば相関は高くなるはず ➢ 弁別的証拠: 異なる学力を測定していれば相関は低くなるはず https://conjointly.com/kb/multitrait-multimethod-matrix/
フィールドテスト・モニター調査 83 ⚫ 古典的テスト理論に基づく項目のスクリーニング フィールドテストの結果に対して、いきなりIRTに基づく分析を行うので はなく、まずはCTTに基づく分析を通して項目のスクリーニングを行う。 基準としては、点双列相関係数が0.2以上であること。 正答率が過度に高い/低い状態にないこと。 ⚫ モニター調査の実施
予備調査を通して精選した項目を使用して、モニター調査を実施する。 この集団が基準集団となるため、本番の試験を受ける受験者と似通った集 団に対して実施することが望ましい。得られた結果をIRTに基づき分析し、 項目パラメタを推定する。以降の本試験では、この項目パラメタを使用し て能力パラメタを推定する。
テストの運用サイクル:等化 84 項目 モニター調査 (基準集団) 本試験1 本試験2 共通項目 新作項目 本試験で追加した新作項目の項目パラメタも、基準集団
と同一尺度上で表現したい。以下の手順で等化を行うこ とで、新作項目の項目パラメタを基準集団に合わせる。 ①モニター調査と本試験のそれぞれで項目パラメタを推 定する。 item モニター調査 本試験1 𝑎𝑗 ∗ 𝑏𝑗 ∗ 𝑎𝑗 𝑏𝑗 1 0.8 -1.2 0.8 -2.2 2 1.2 -0.8 1.2 -1.8 3 0.8 0.4 0.8 -0.6 4 1.0 1.2 1.0 0.2 5 ― ― 1.0 0.8 ②左式の等化係数KとLを推定し、新作項目の項目パラメ タを等化する。 上の例だと等化係数は、K=1, L=1.0 だと推定できる。 等化係数を用いると、新作項目の等化後の項目パラメタ は、 𝑎𝑗 ∗ = 1.0, 𝑏𝑗 ∗ = 1.8 となる。 𝑎𝑗 ∗ = 𝑎𝑗 𝐾 𝑏𝑗 ∗ = 𝐾 × 𝑏𝑗 + 𝐿 ◼ 2PLMにおける等化係数 …
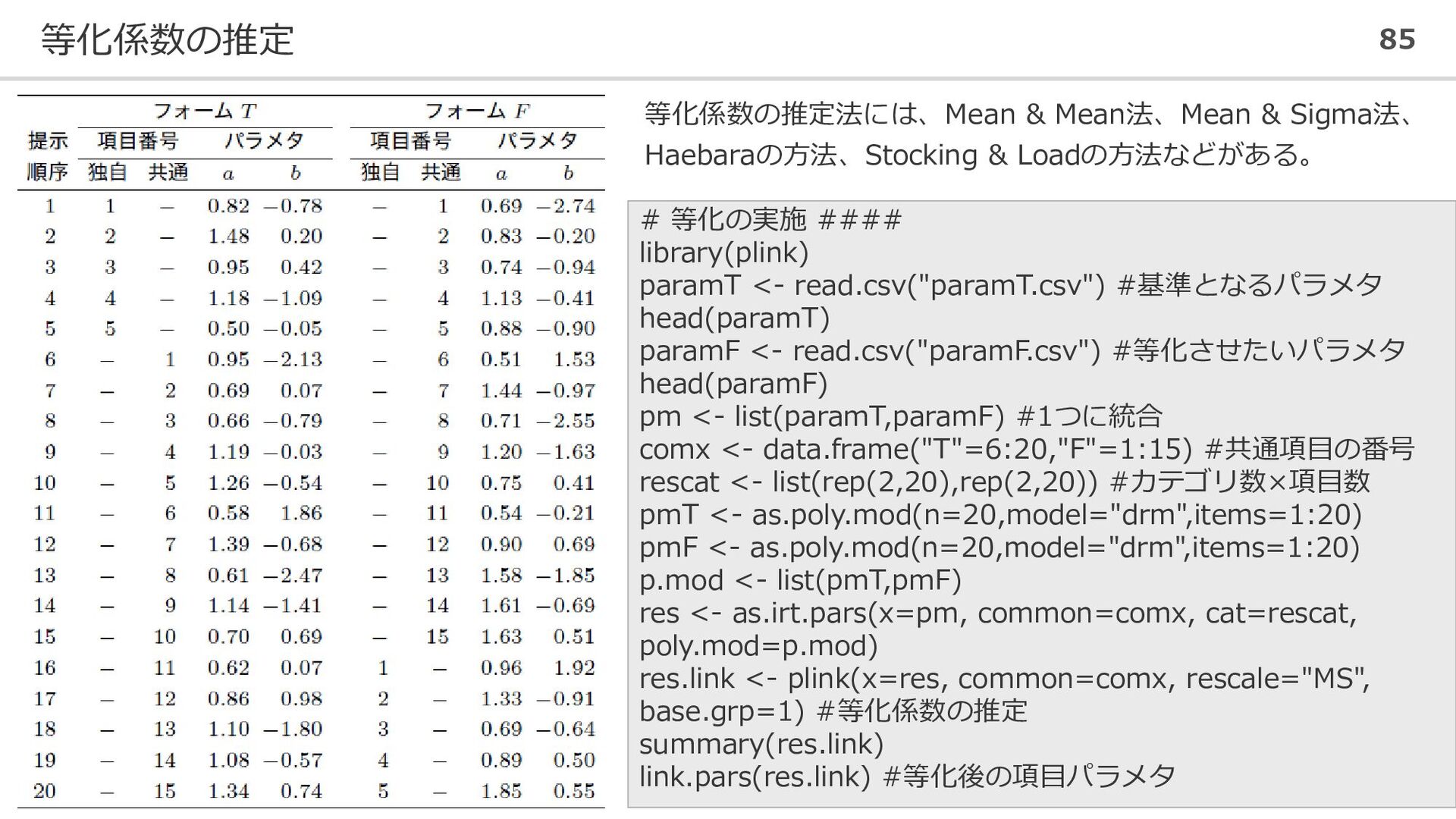
等化係数の推定 85 等化係数の推定法には、Mean & Mean法、Mean & Sigma法、 Haebaraの方法、Stocking & Loadの方法などがある。
# 等化の実施 #### library(plink) paramT <- read.csv("paramT.csv") #基準となるパラメタ head(paramT) paramF <- read.csv("paramF.csv") #等化させたいパラメタ head(paramF) pm <- list(paramT,paramF) #1つに統合 comx <- data.frame("T"=6:20,"F"=1:15) #共通項目の番号 rescat <- list(rep(2,20),rep(2,20)) #カテゴリ数×項目数 pmT <- as.poly.mod(n=20,model="drm",items=1:20) pmF <- as.poly.mod(n=20,model="drm",items=1:20) p.mod <- list(pmT,pmF) res <- as.irt.pars(x=pm, common=comx, cat=rescat, poly.mod=p.mod) res.link <- plink(x=res, common=comx, rescale="MS", base.grp=1) #等化係数の推定 summary(res.link) link.pars(res.link) #等化後の項目パラメタ
コンピューターを活用したテスト Computer Based Test 86
コンピューター使用型テスト(CBT)のメリット 87 ⚫ コンピューター使用型テストのメリット(日本テスト学会,2007) • 即時採点が可能になる。 • テストセットを自動で構成できる。 • マルチメディアを活用して、これまでの筆記テストでは測定することので
きなかった特性を測定できるようになる • 障害のある受験者に対して高度に対応する機能をもつ(アクセシビリティ) • 回答に至るまでの認知プロセスに関連するデータが得られる(e.g., 所要時 間、注視箇所) • 受験者の能力に応じた最適な項目を出題する コンピューター適応型テスト(CAT)が実現できる
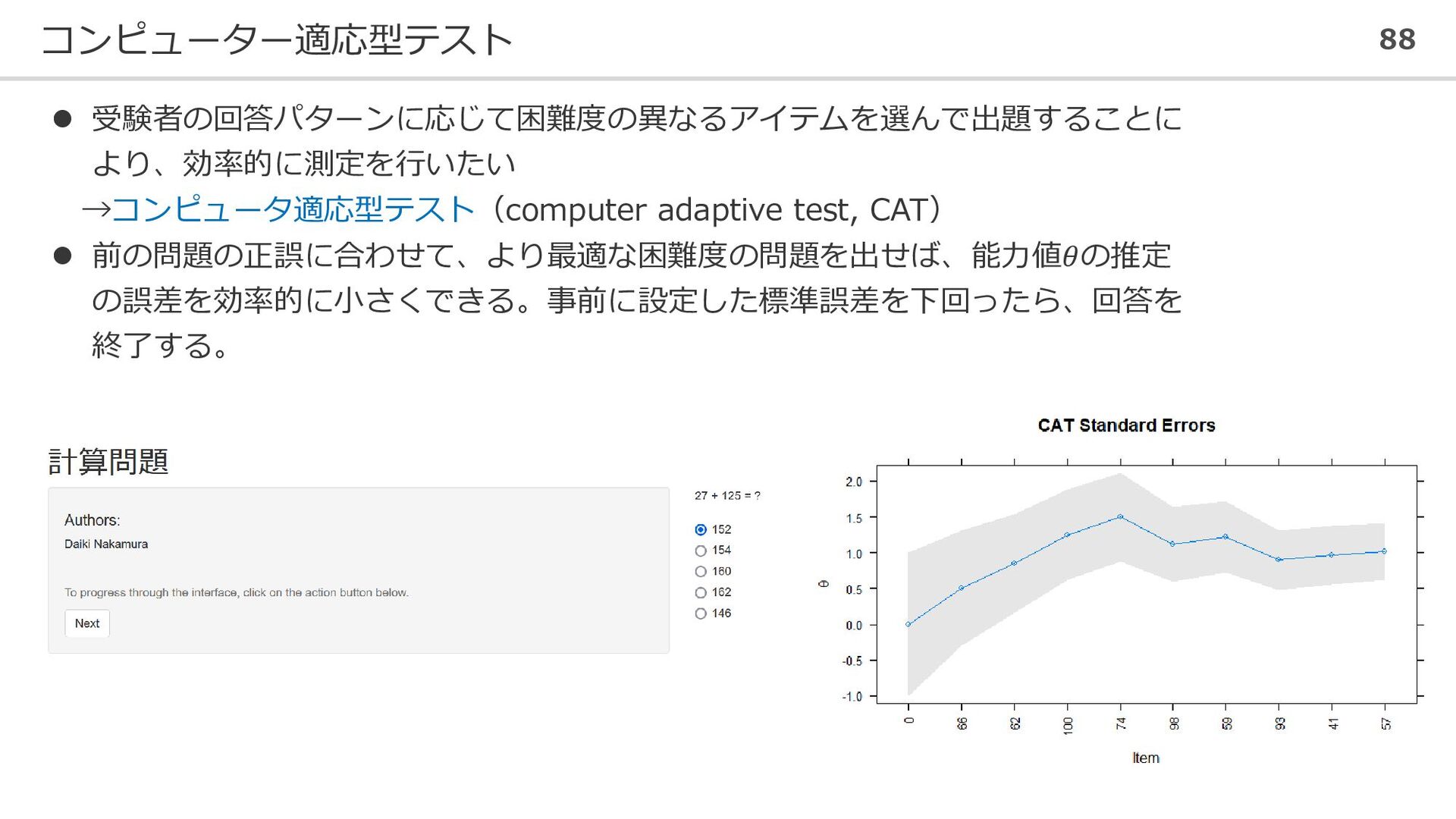
コンピューター適応型テスト 88 ⚫ 受験者の回答パターンに応じて困難度の異なるアイテムを選んで出題することに より、効率的に測定を行いたい →コンピュータ適応型テスト(computer adaptive test, CAT) ⚫
前の問題の正誤に合わせて、より最適な困難度の問題を出せば、能力値𝜃の推定 の誤差を効率的に小さくできる。事前に設定した標準誤差を下回ったら、回答を 終了する。
全体のまとめ 89 ⚫ CTTには、標本依存性や項目依存性といった問題がある。 ⚫ IRTでは、テストを受けた集団や問題に依存しない評価が可能になる。 ⚫ IRTに基づきモデル化することで、問題の難易度などの統計的性質を受験者に 依存しない数値情報として表現することができる。 ⚫
テストの測定精度を受験者の能力水準別に評価できる。 ⚫ 等化を実施することで、新しく作成した問題も同一尺度上で評価できる。 ⚫ コンピューターを活用することで、筆記テストではできなかった新たな測定を 実現できる可能性がある。 質問などがあればいつでもご連絡ください。 📧
[email protected]
参考・引用文献 90 • 池田央(1992)テストの科学,日本文化科学社. • 加藤健太郎・山田剛史・川端一光(2014)Rによる項目反応理論,オーム社. • 熊谷龍一・荘島宏二郎(2015)教育心理学のための統計学,誠信書房. • 光永悠彦(2017)テストは何を測るのか,ナカニシヤ出版.
• 日本テスト学会(2007)テスト・スタンダード,金子書房. • 日本テスト学会(2010)見直そう,テストを支える基本の技術と教育,金子書房. • 豊田秀樹(2012)項目反応理論[入門編]第2版,朝倉書店. • 豊田秀樹(2013)項目反応理論[中級編],朝倉書店.
補足 Supplemental 91
確率変数と確率分布 ⚫ 確率変数 取る値の範囲と取る確率だけがわかっている変数 ➢ 連続確率変数: 例)身長 ➢ 離散確率変数: 例)コインの表裏
⚫ 確率分布 確率変数がとる値とその値をとる確率の対応の様子 コインの出る目の確率分布 コインの表裏 表(=1) 裏(=0) 確率 0.5 0.5
確率分布の種類 確率分布 離散型 一様分布 二項分布 ポアソン分布 正規分布 z 分布(標準正規分布) t
分布 χ2分布 F 分布 連続型 χ2分布 (標準)正規分布 t分布 F分布 二項分布 ポアソン分布 一様分布
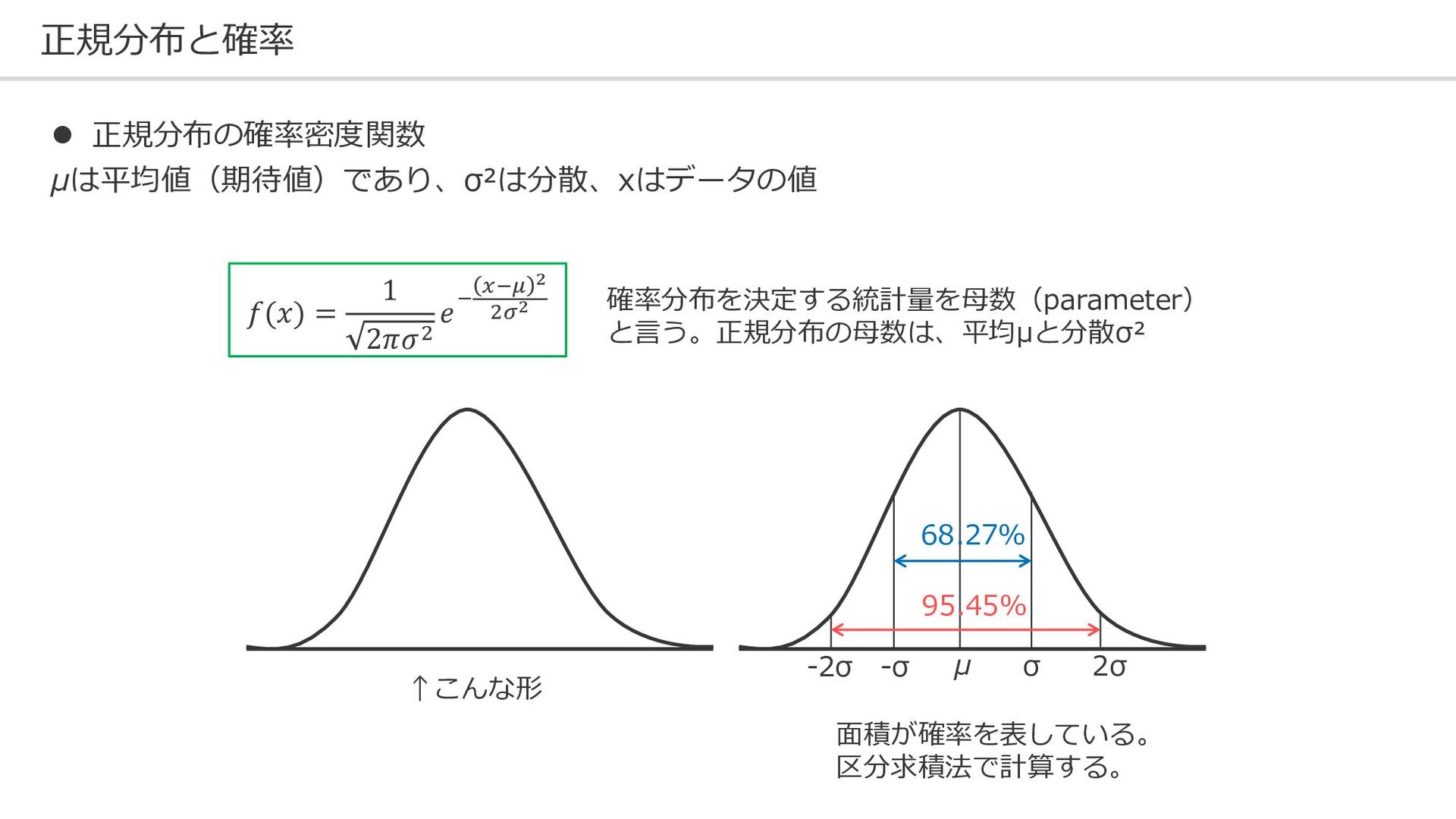
正規分布と確率 ⚫ 正規分布の確率密度関数 μは平均値(期待値)であり、σ²は分散、xはデータの値 𝑓(𝑥) = 1 2𝜋𝜎2 𝑒− 𝑥−𝜇
2 2𝜎2 面積が確率を表している。 区分求積法で計算する。 68.27% 95.45% μ σ 2σ -σ -2σ ↑こんな形 確率分布を決定する統計量を母数(parameter) と言う。正規分布の母数は、平均μと分散σ²
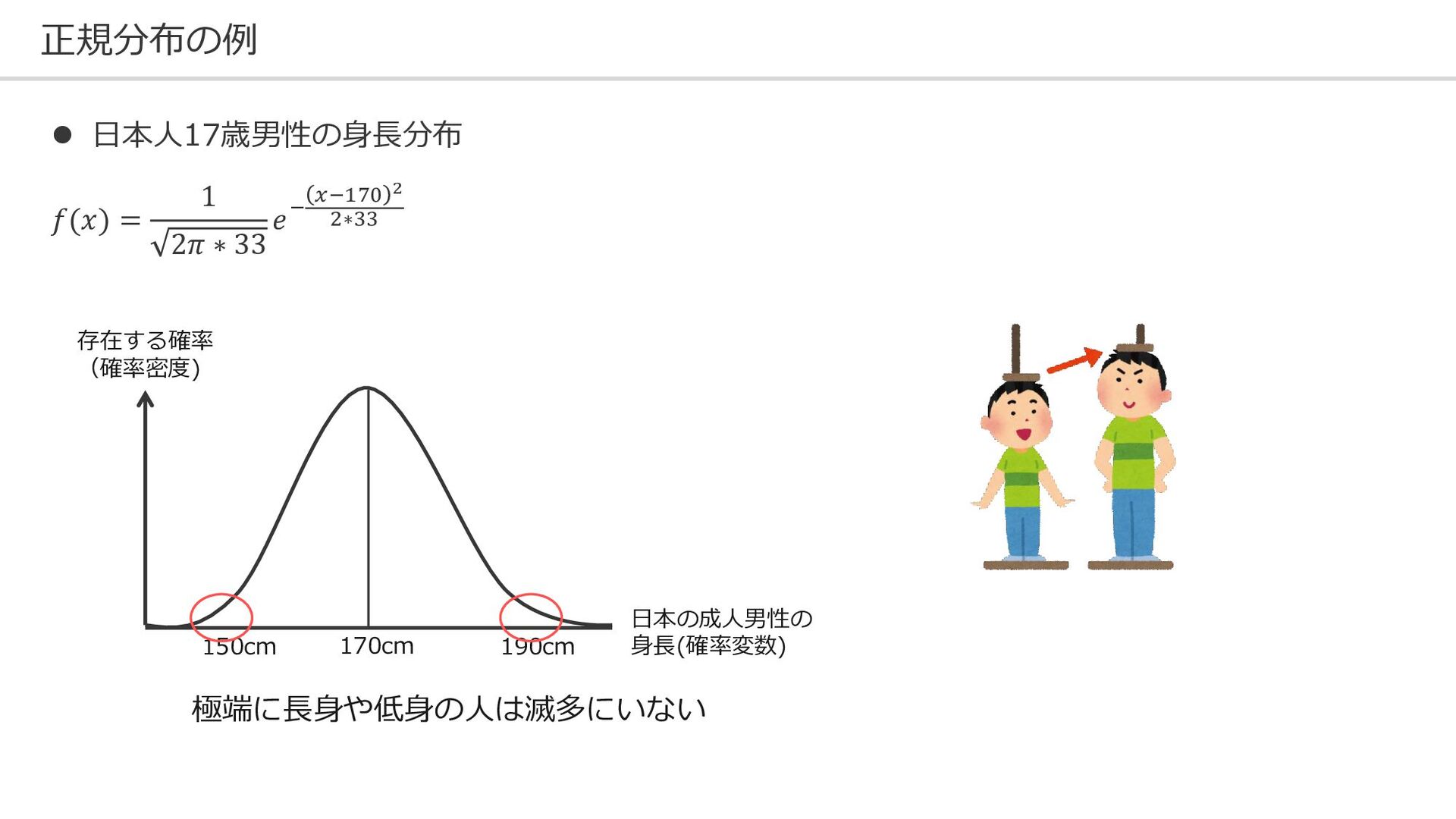
正規分布の例 ⚫ 日本人17歳男性の身長分布 𝑓(𝑥) = 1 2𝜋 ∗ 33 𝑒−
𝑥−170 2 2∗33 日本の成人男性の 身長(確率変数) 170cm 190cm 150cm 存在する確率 (確率密度) 極端に長身や低身の人は滅多にいない
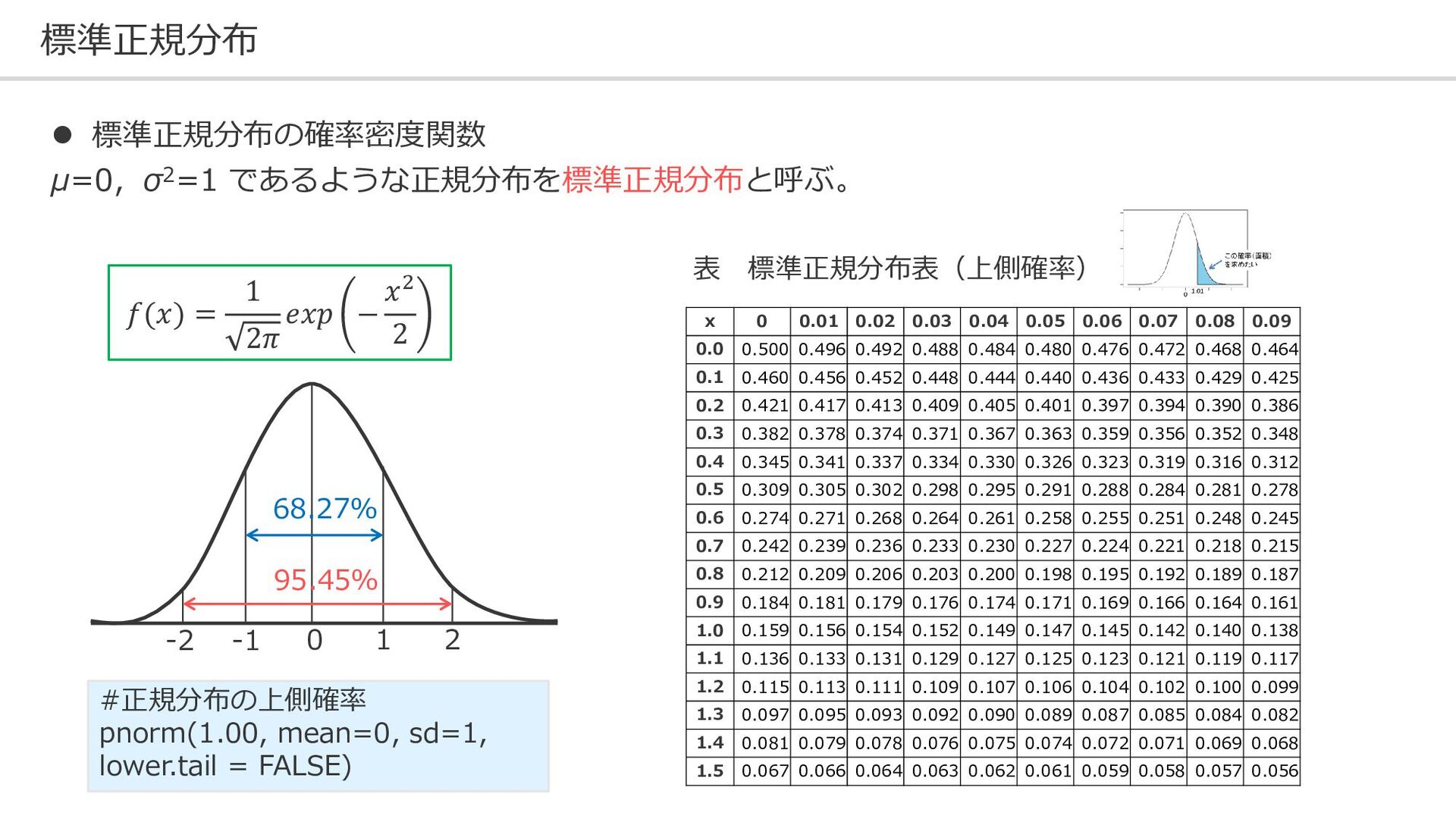
標準正規分布 ⚫ 標準正規分布の確率密度関数 μ=0,σ2=1 であるような正規分布を標準正規分布と呼ぶ。 𝑓(𝑥) = 1 2𝜋 𝑒𝑥𝑝
− 𝑥2 2 68.27% 95.45% 0 1 2 -1 -2 x 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.0 0.500 0.496 0.492 0.488 0.484 0.480 0.476 0.472 0.468 0.464 0.1 0.460 0.456 0.452 0.448 0.444 0.440 0.436 0.433 0.429 0.425 0.2 0.421 0.417 0.413 0.409 0.405 0.401 0.397 0.394 0.390 0.386 0.3 0.382 0.378 0.374 0.371 0.367 0.363 0.359 0.356 0.352 0.348 0.4 0.345 0.341 0.337 0.334 0.330 0.326 0.323 0.319 0.316 0.312 0.5 0.309 0.305 0.302 0.298 0.295 0.291 0.288 0.284 0.281 0.278 0.6 0.274 0.271 0.268 0.264 0.261 0.258 0.255 0.251 0.248 0.245 0.7 0.242 0.239 0.236 0.233 0.230 0.227 0.224 0.221 0.218 0.215 0.8 0.212 0.209 0.206 0.203 0.200 0.198 0.195 0.192 0.189 0.187 0.9 0.184 0.181 0.179 0.176 0.174 0.171 0.169 0.166 0.164 0.161 1.0 0.159 0.156 0.154 0.152 0.149 0.147 0.145 0.142 0.140 0.138 1.1 0.136 0.133 0.131 0.129 0.127 0.125 0.123 0.121 0.119 0.117 1.2 0.115 0.113 0.111 0.109 0.107 0.106 0.104 0.102 0.100 0.099 1.3 0.097 0.095 0.093 0.092 0.090 0.089 0.087 0.085 0.084 0.082 1.4 0.081 0.079 0.078 0.076 0.075 0.074 0.072 0.071 0.069 0.068 1.5 0.067 0.066 0.064 0.063 0.062 0.061 0.059 0.058 0.057 0.056 表 標準正規分布表(上側確率) #正規分布の上側確率 pnorm(1.00, mean=0, sd=1, lower.tail = FALSE)
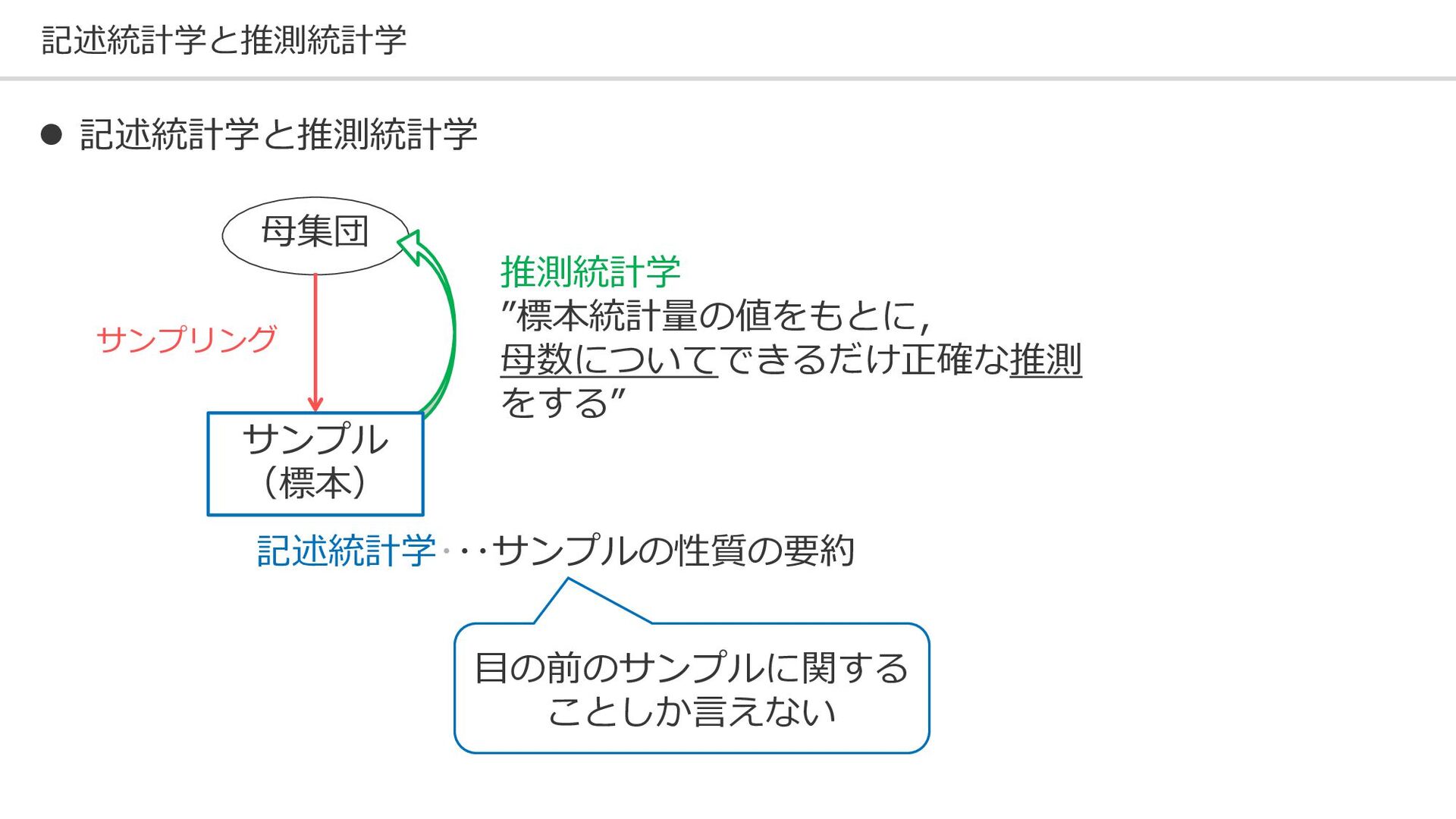
記述統計学と推測統計学 母集団 記述統計学・・・サンプルの性質の要約 推測統計学 ”標本統計量の値をもとに, 母数についてできるだけ正確な推測 をする” サンプル (標本) サンプリング
⚫ 記述統計学と推測統計学 目の前のサンプルに関する ことしか言えない
標本統計量と標本誤差 母集団 サンプル (標本) μ m 標本統計量(sample statistic) 母数(parameter) 標本平均
母平均 サンプリング 母 数 ( 未 知 の 真 の 値 ) 推 定 値 標本誤差 平均や分散 標本データから母数を推定する場合は必ず 誤差(標本誤差)が生じる
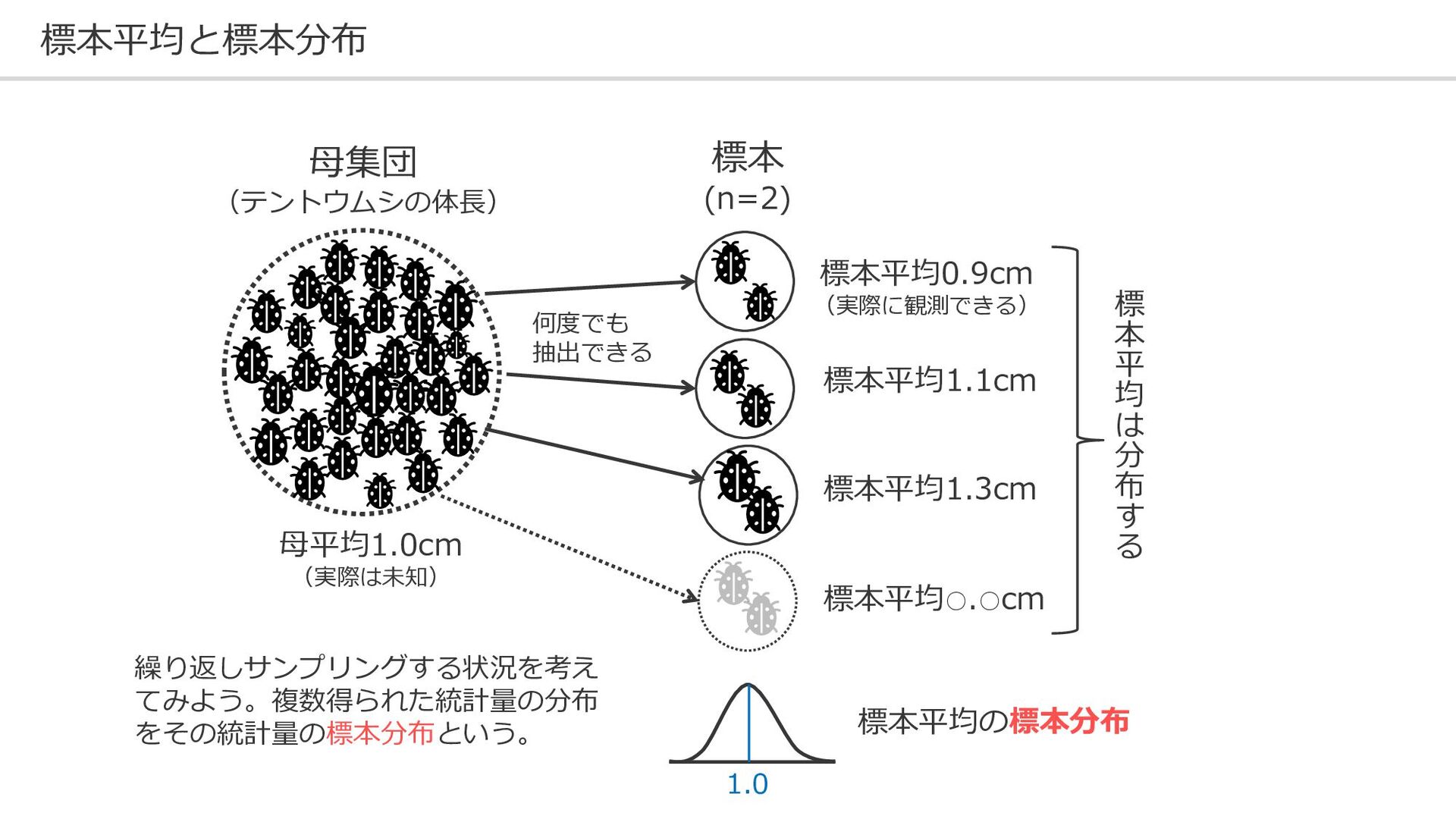
標本平均と標本分布 母集団 (テントウムシの体長) 標本 (n=2) 母平均1.0cm (実際は未知) 標本平均0.9cm (実際に観測できる) 標本平均1.1cm
標本平均1.3cm 標本平均◦.◦cm 標 本 平 均 は 分 布 す る 何度でも 抽出できる 標本平均の標本分布 1.0 繰り返しサンプリングする状況を考え てみよう。複数得られた統計量の分布 をその統計量の標本分布という。
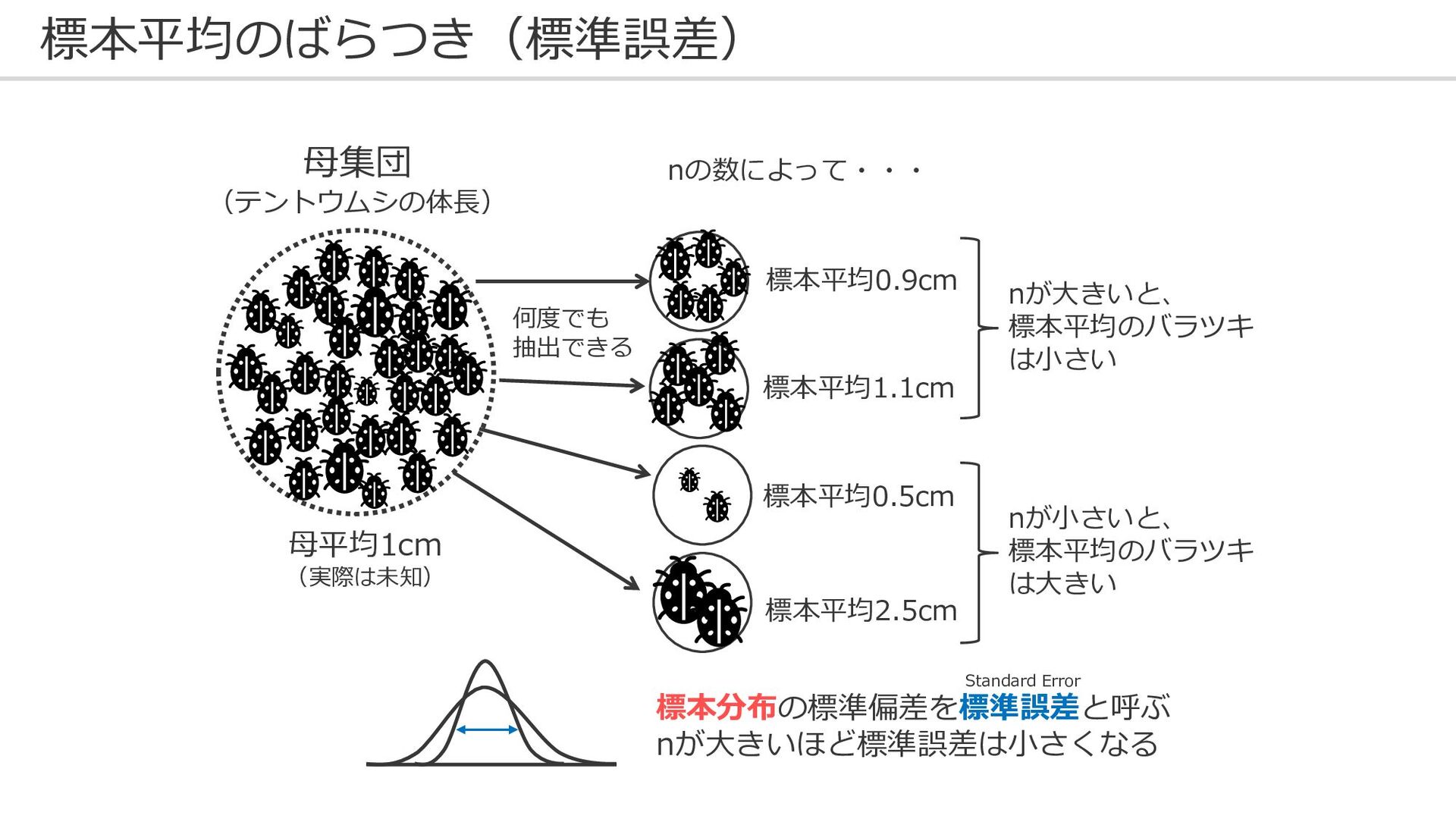
標本平均のばらつき(標準誤差) 母集団 (テントウムシの体長) 母平均1cm (実際は未知) 標本平均0.9cm 標本平均1.1cm 標本平均0.5cm 何度でも 抽出できる
nの数によって・・・ 標本平均2.5cm nが大きいと、 標本平均のバラツキ は小さい nが小さいと、 標本平均のバラツキ は大きい 標本分布の標準偏差を標準誤差と呼ぶ nが大きいほど標準誤差は小さくなる Standard Error
サンプルサイズと標準誤差 μ 母集団の最小値 (最小個体) 母集団の最大値 (最大個体) 母集団の個体の分布 標本平均の分布(n=5) 標本平均の分布(n=10) 標本平均の分布
(n=全数N,母平均) 母標準偏差σ 母標準誤差σ/√5 母標準誤差σ/√10 x ➢ 母標準誤差(SE) 𝜎 ҧ 𝑥 = 𝜎𝑥 𝑛 ➢ 標本標準誤差(se) 𝑆 ҧ 𝑥 = 𝑆𝑥 𝑛 nが大きいほど標準誤差は小さくなる →精度良く母集団の平均値の推定がで きる
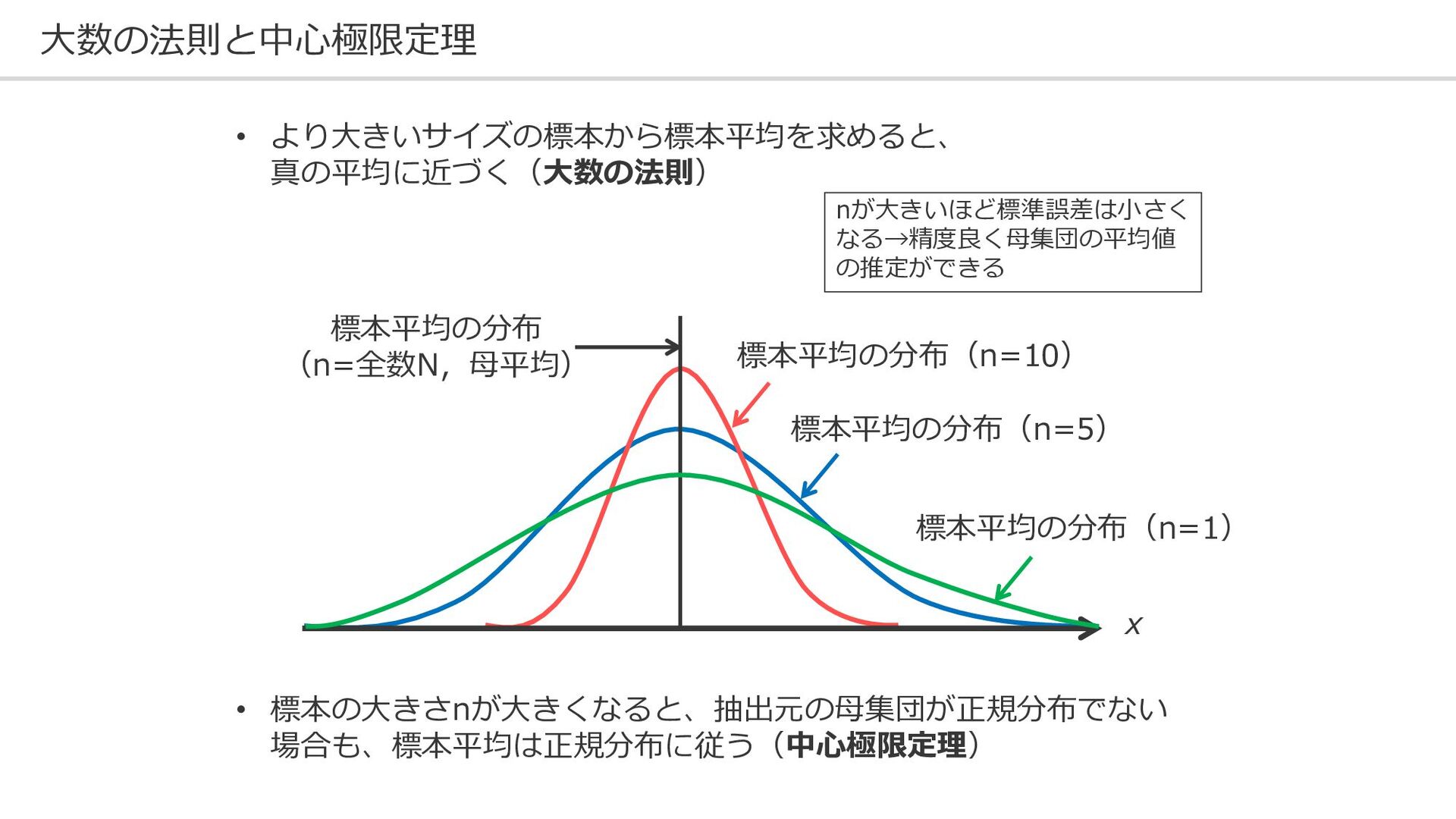
大数の法則と中心極限定理 標本平均の分布(n=1) 標本平均の分布(n=5) 標本平均の分布(n=10) 標本平均の分布 (n=全数N,母平均) x • より大きいサイズの標本から標本平均を求めると、 真の平均に近づく(大数の法則)
nが大きいほど標準誤差は小さく なる→精度良く母集団の平均値 の推定ができる • 標本の大きさnが大きくなると、抽出元の母集団が正規分布でない 場合も、標本平均は正規分布に従う(中心極限定理)
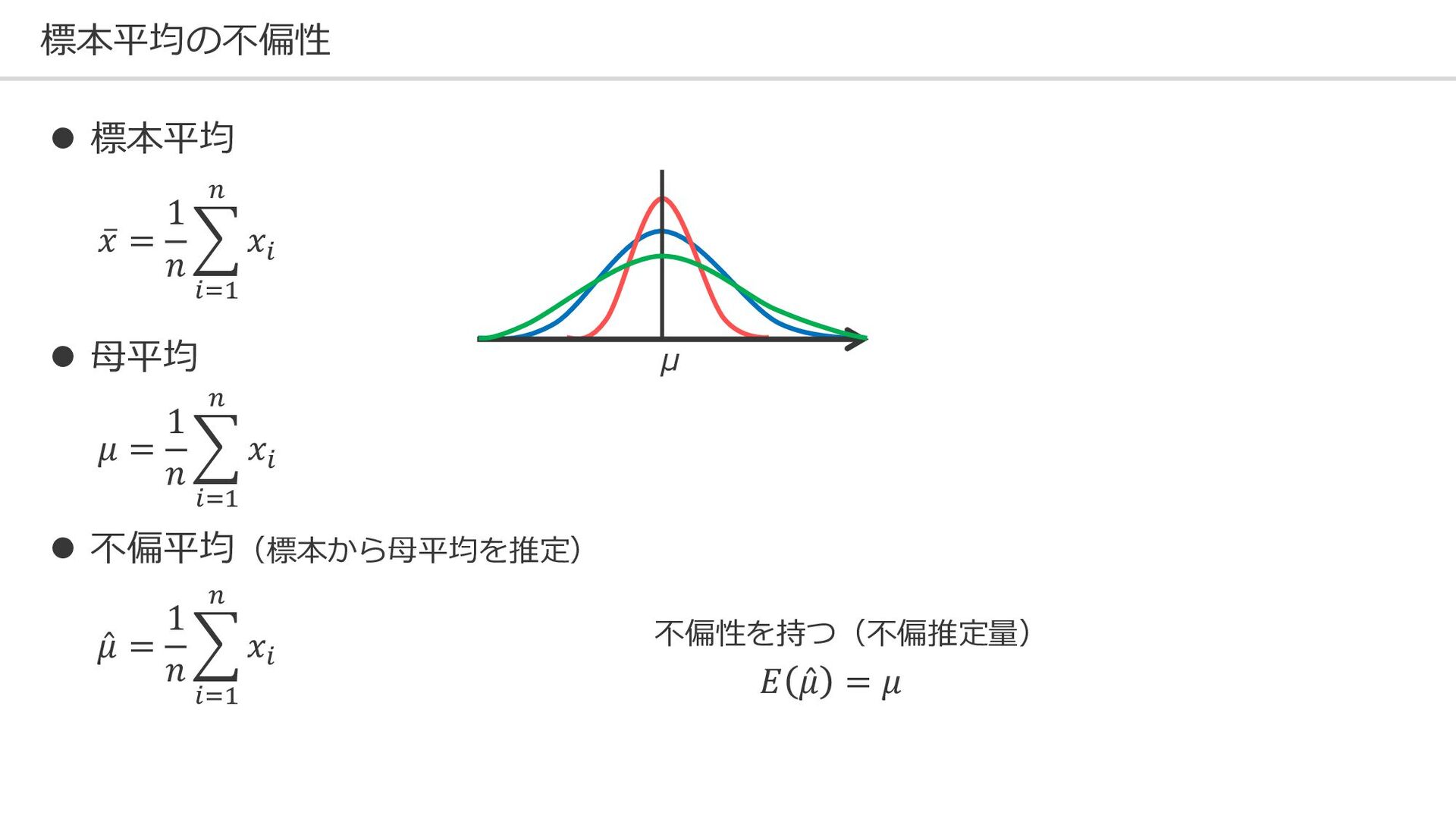
標本平均の不偏性 μ ⚫ 標本平均 ⚫ 母平均 ⚫ 不偏平均(標本から母平均を推定) 不偏性を持つ(不偏推定量) ҧ
𝑥 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 𝜇 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 Ƹ 𝜇 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 𝐸 Ƹ 𝜇 = 𝜇
不偏分散 ⚫ 標本分散 𝑠2 = 1 𝑛 𝑖=1 𝑛
𝑥𝑖 − ҧ 𝑥 2 ⚫ 母分散 𝜎2 = 1 𝑛 𝑖=1 𝑛 𝑥𝑖 − 𝜇 2 ⚫ 不偏分散(標本から母分散を推定) 𝜎2 = 1 𝑛 − 1 𝑖=1 𝑛 𝑥𝑖 − ҧ 𝑥 2
練習問題 1. 標本分布とは何か説明せよ 2. 標準偏差(sd)と標準誤差(se)の違いについて述べよ 3. n=100で20代男性のBMIを調べた結果、 平均22.7、標準偏差4.0であった。この場合の標本平均の標準誤差を算出せよ。 4. 標準誤差を半分にするには、サンプルサイズを何倍にすればよいだろうか。
(ヒント:標準誤差の計算式の分母に注目)
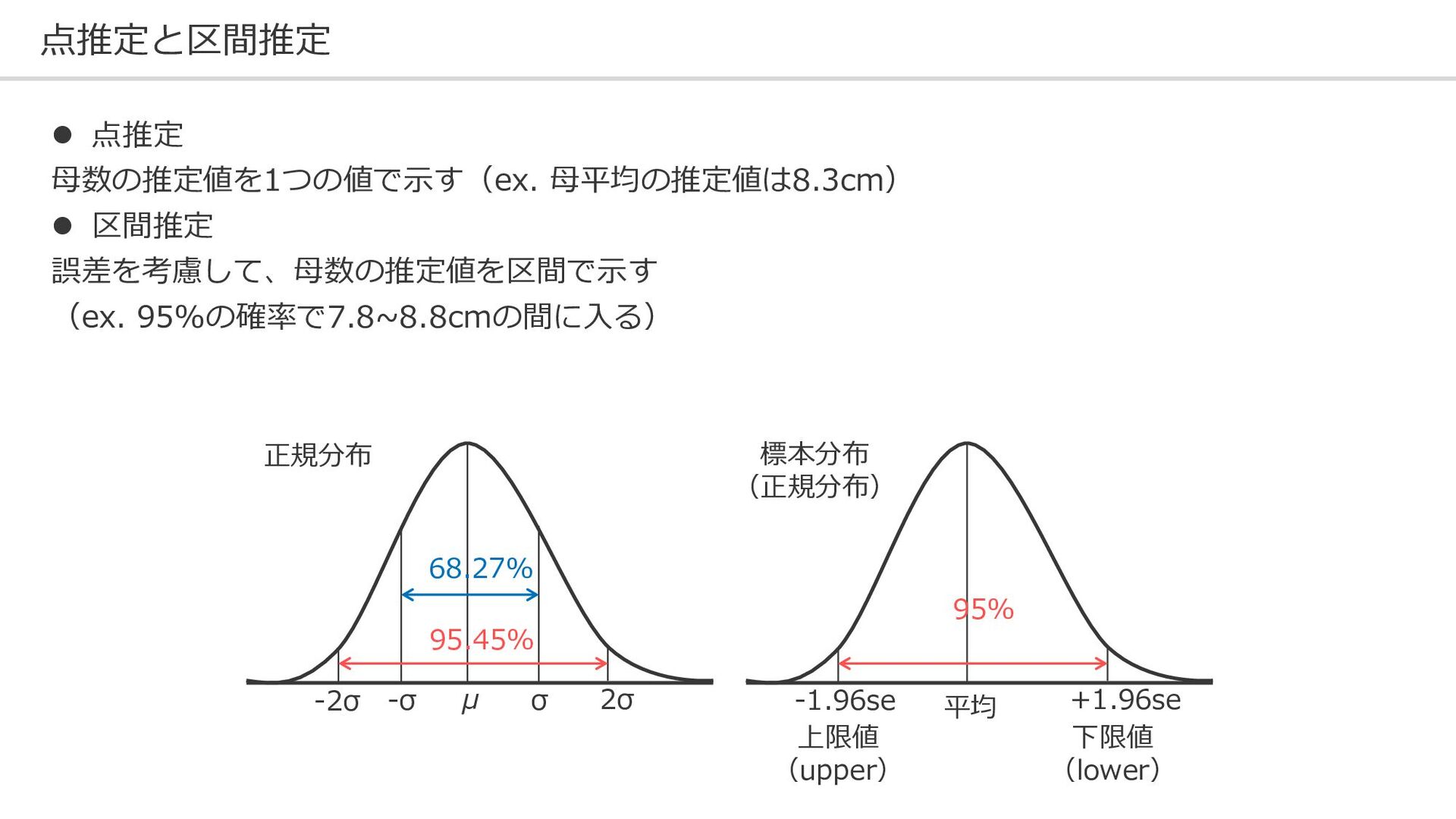
点推定と区間推定 ⚫ 点推定 母数の推定値を1つの値で示す(ex. 母平均の推定値は8.3cm) ⚫ 区間推定 誤差を考慮して、母数の推定値を区間で示す (ex. 95%の確率で7.8~8.8cmの間に入る)
68.27% 95.45% μ σ 2σ -σ -2σ 95% 平均 +1.96se -1.96se 正規分布 標本分布 (正規分布) 上限値 (upper) 下限値 (lower)
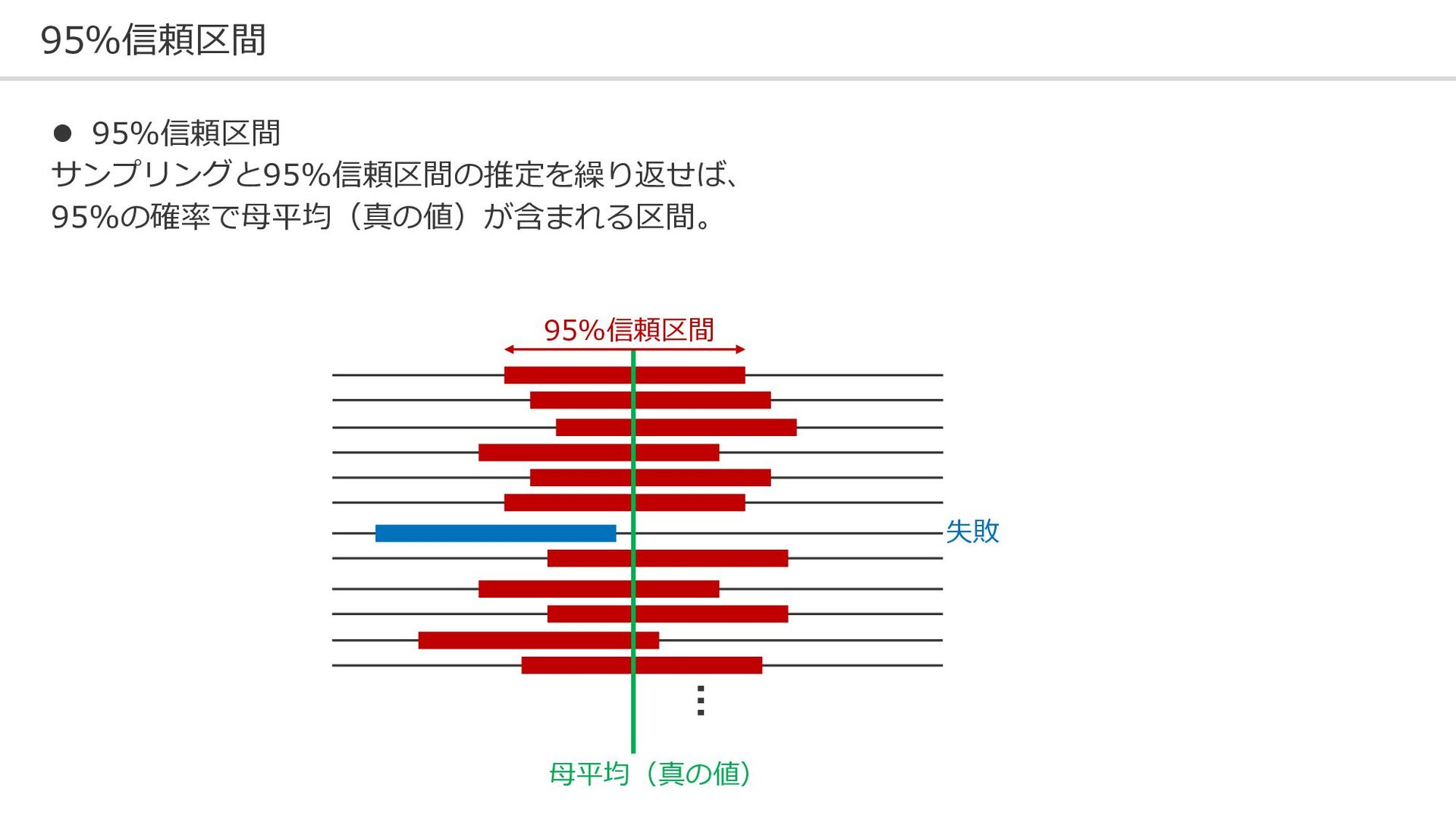
95%信頼区間 ⚫ 95%信頼区間 サンプリングと95%信頼区間の推定を繰り返せば、 95%の確率で母平均(真の値)が含まれる区間。 母平均(真の値) … 95%信頼区間 失敗
欠損値の除去 #欠損値除去 dat1 <- na.omit(dat1) ← リストワイズ除去(欠損値がある行を1行丸々除去する) 1. 完全にランダムに欠損 →
Missing Completely At Random(MCAR) 2. 観測データに依存する欠損 → Missing At Random(MAR) 3. 欠損データに依存する欠損 → Missing Not At Random(MNAR) ⚫ 欠損値の種類と対応 • MCARの場合、ペアワイズ削除(その分析に使う場合のみ除去)でもリストワイ ズ削除でもOK • MARの場合、完全情報最尤法による推定や、多重代入法による欠損値代入を行う • MNARの場合、お手上げ状態 ※ペアワイズ削除は、多くの関数でデフォルト設定になっている。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![新しい変数やデータセットの作成 30 ⚫ 各教科の3回のテストの平均を個人ごとに算出する # 新しい変数の作成 dat1$kokugo_all <- apply(dat1[,7:9], 1,](https://files.speakerdeck.com/presentations/ac5d96d7408f4e8682b7c7167fa0a6f5/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![対応のないt検定(2群の平均値差) # 性別間比較 tapply(dat1$rika_all, dat1$sex, mean) #性別ごとの平均値 m.rika <- dat1$rika_all[dat1$sex=="m"]](https://files.speakerdeck.com/presentations/ac5d96d7408f4e8682b7c7167fa0a6f5/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}