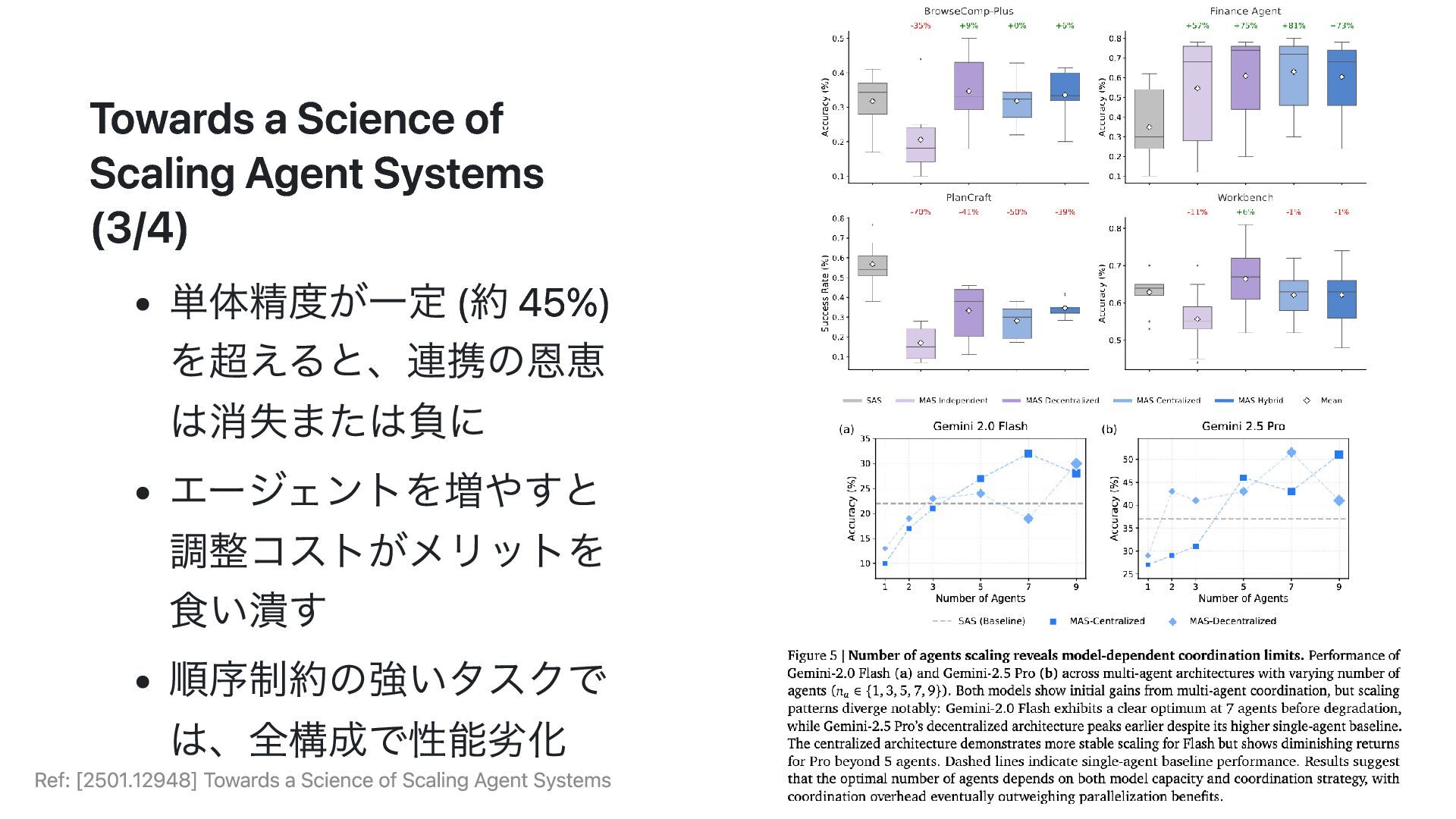
Web ナビゲーション、金融分析、複雑な計画、ワーク フロー 前提条件 (Agentic Evaluation) : i. 継続的な環境との対話 ii. 部分観測下での反復的な情報収集 iii. フィードバックに基づく適応的な戦略修正 Ref: [2501.12948] Towards a Science of Scaling Agent Systems
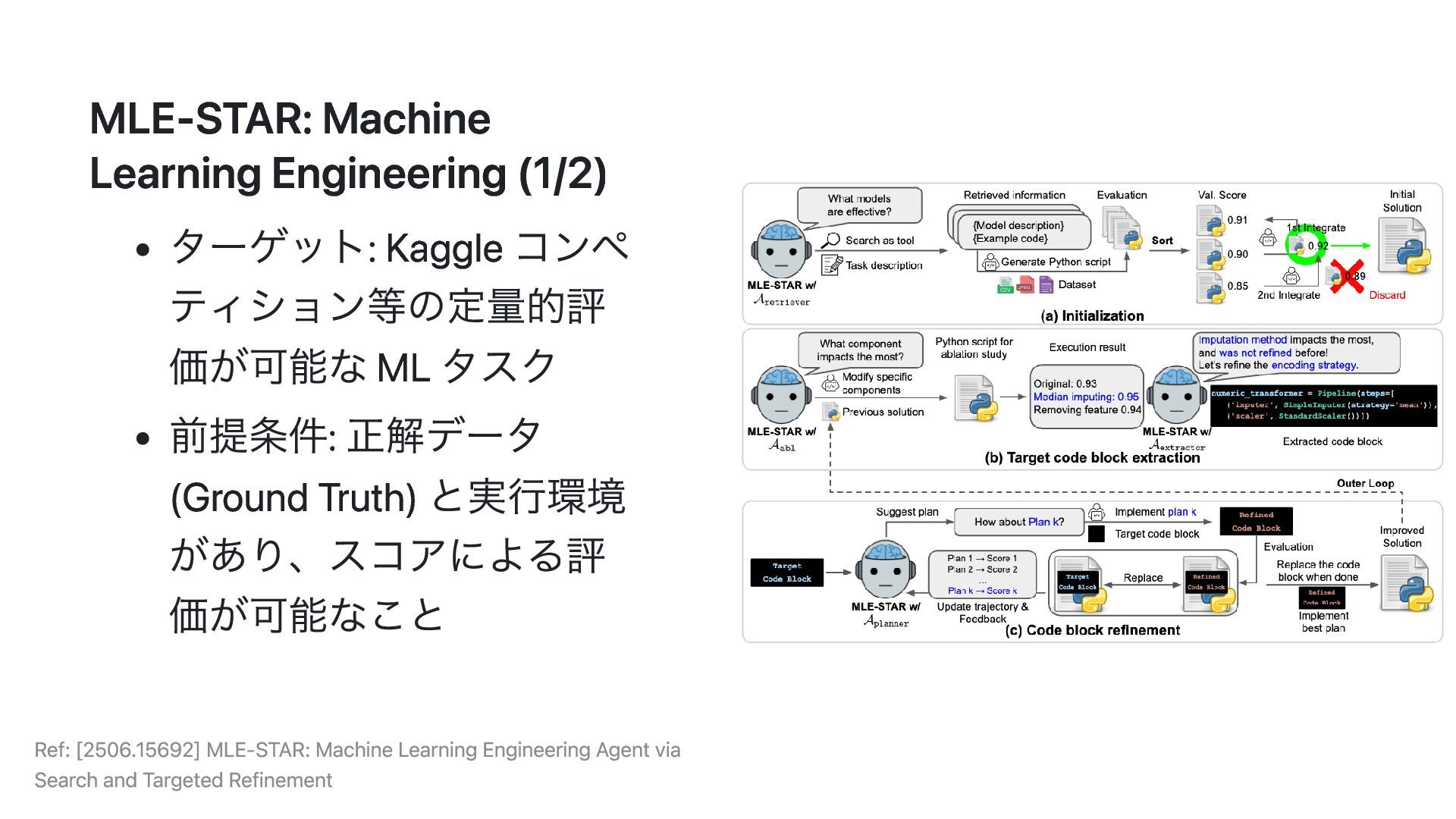
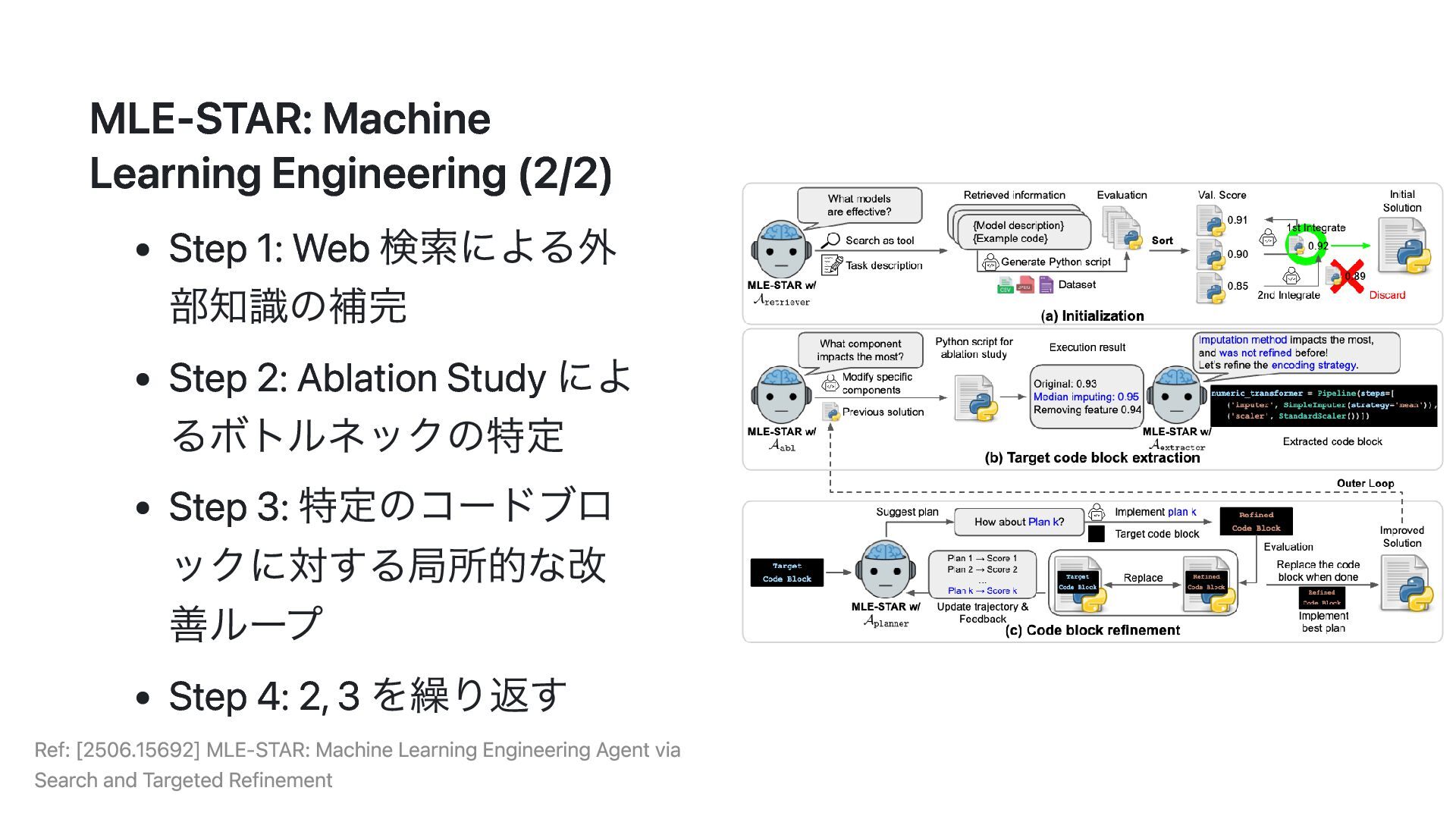
Context of Context Engineering MLE-STAR: [2506.15692] MLE-STAR: Machine Learning Engineering Agent via Search and Targeted Refinement DS-STAR: [2509.21825] DS-STAR: Data Science Agent via Iterative Planning and Verification PlanGen: [2411.02275] PlanGen: A Multi-Agent Framework for Generating Planning and Reasoning Trajectories MASS: [2502.02533] Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies
and Weights Scaling Agent Systems: [2501.12948] Towards a Science of Scaling Agent Systems MCP: Model Context Protocol Specification (Anthropic / community- led) Skills: Agent Skills Standard (https://agentskills.io/) A2A: Agent-to-Agent Protocol (https://a2a-protocol.org/)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 (References) Context Engineering 2.0: [2510.26493] Context Engineering 2.0: The](https://files.speakerdeck.com/presentations/011f31770cc643b6926abafc8a66479c/slide_53.jpg){kind=link}
![参考文献 (References) H-Swarm: [2502.13840] Heterogeneous Swarms: Jointly Optimizing Model Roles](https://files.speakerdeck.com/presentations/011f31770cc643b6926abafc8a66479c/slide_54.jpg){kind=link}