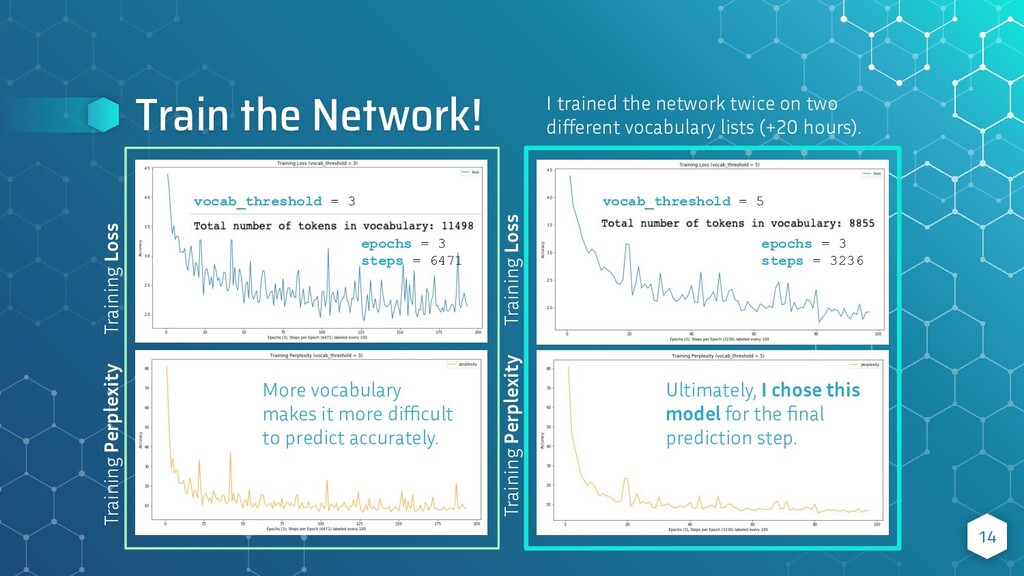
As a part of Udacity's Computer Vision Nanodegree, I defined a Recurrent Neural Network in PyTorch, using LSTM cells, and trained the last layer of a pre-trained CNN model to be able to accurately label images with a string of up to 10 words, based on images and captions the network had previously trained on.
This PPT was submitted as a part of my PhD coursework to detail my project process and reflection.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
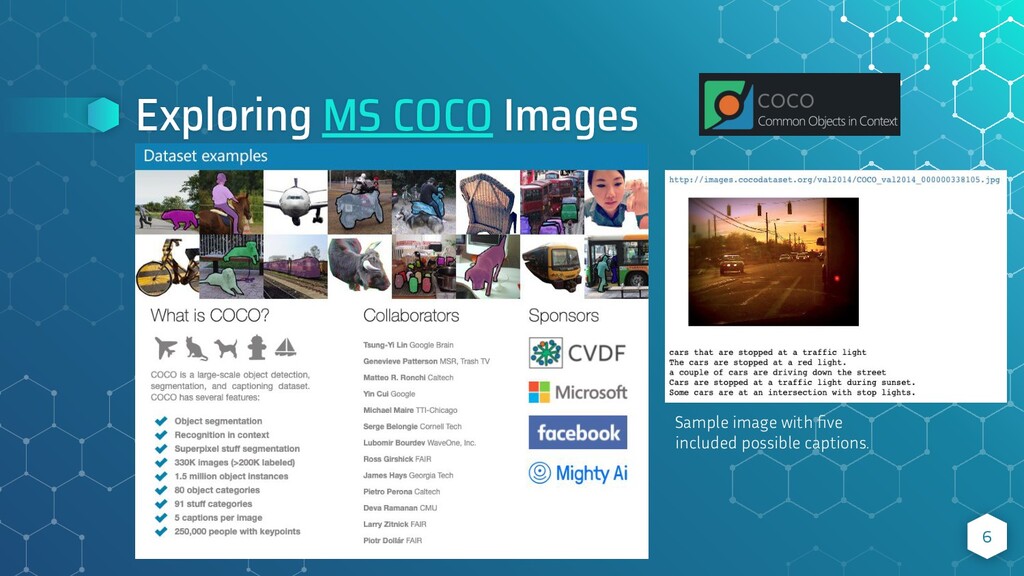{kind=link}
{kind=link}
{kind=link}
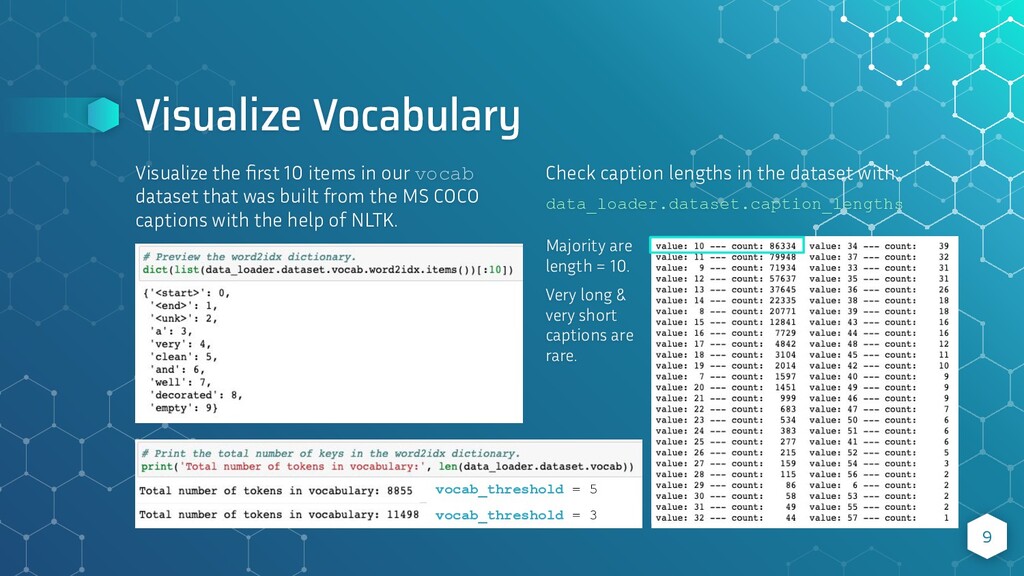{kind=link}
{kind=link}
{kind=link}
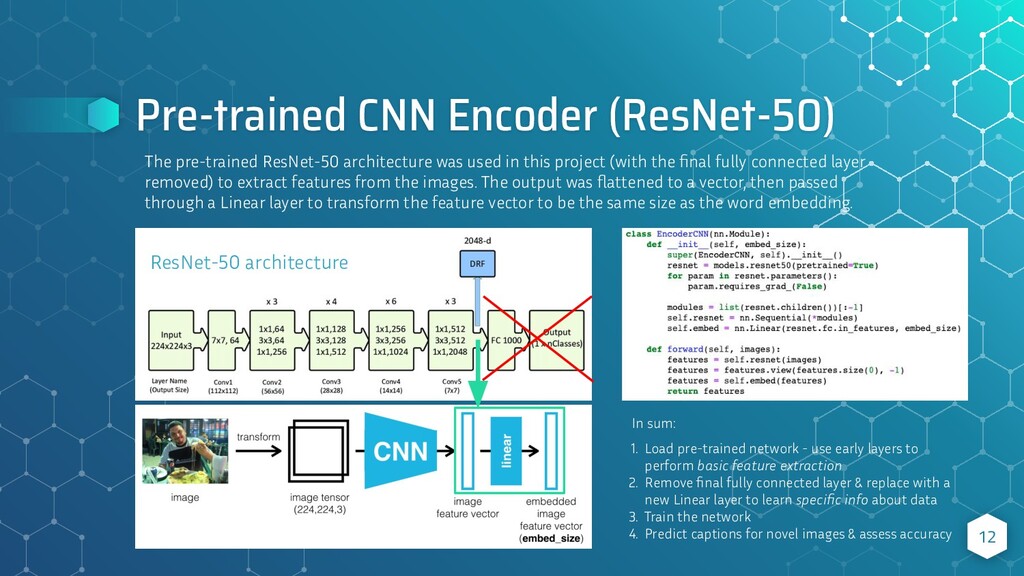{kind=link}
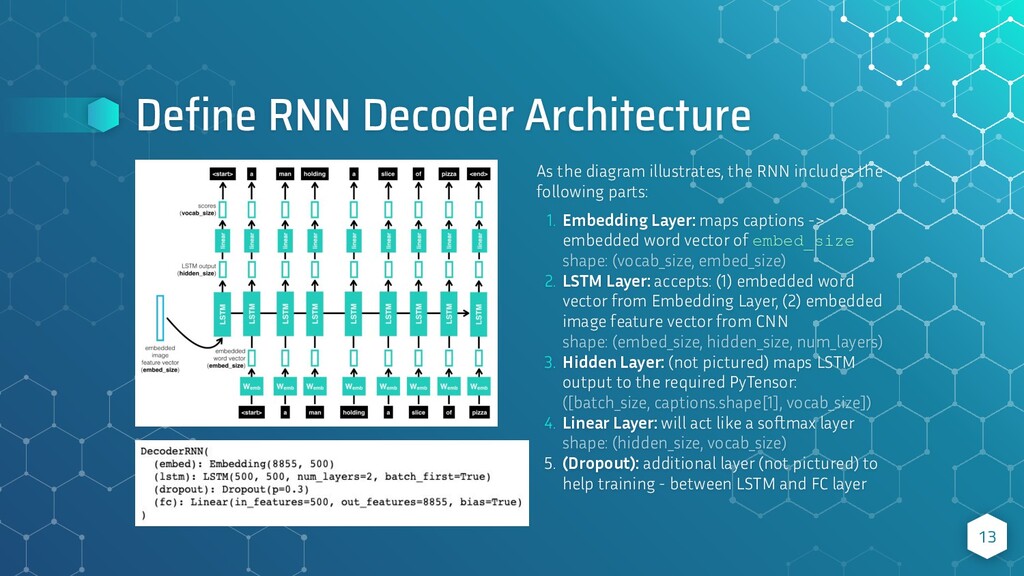{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}