https://aaron.kr/content/portfolio/word-cloud-big-data-analysis-of-manchu-script-in-weiwenqiju/
Poster presentation at The 50th Fall Comprehensive Conference of the Korea Information and Communication Society (KIICE) (제50회 한국정보통신학회 추계종합학술대회).
The Qing dynasty's Yumentingzheng (御門聽政) is an important document comparable to the Annals of Joseon in Korea. This is a record of conversations between the Qing dynasty emperor and his ministers.
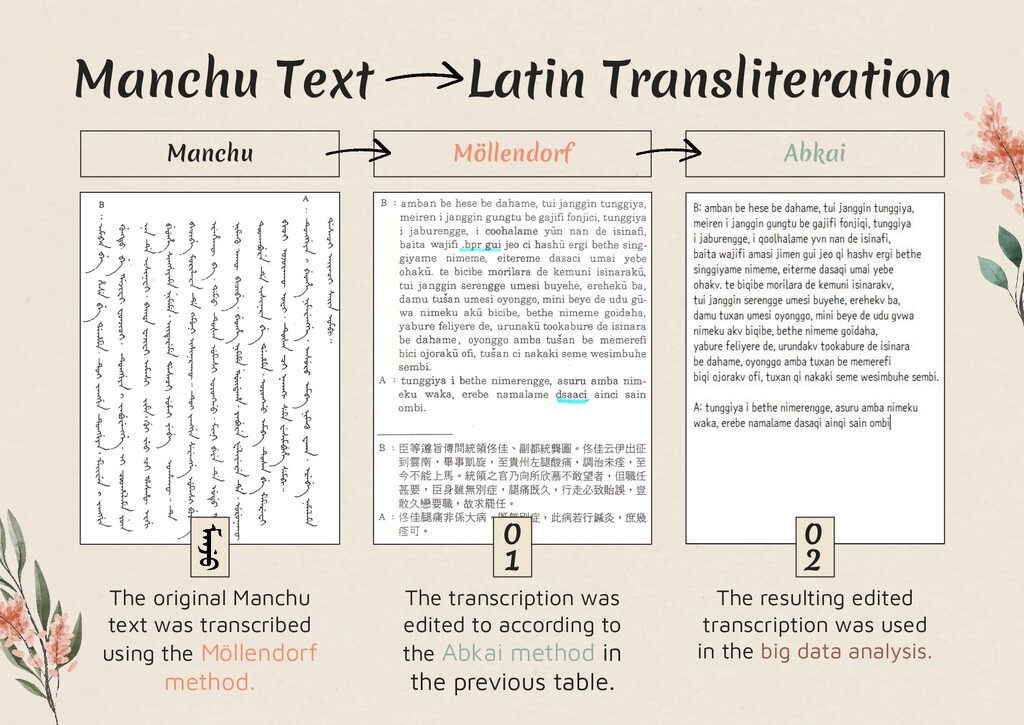
Manchu script is one of the few scripts left in the world that does NOT have an easy way to perform OCR (optical character recognition) on it to scan and read documents into a digital format. There is also no readily available and complete Manchu dictionary available for word lookup. Therefore, pages containing the Manchu script must first be transliterated in a way that computers can perform analysis.
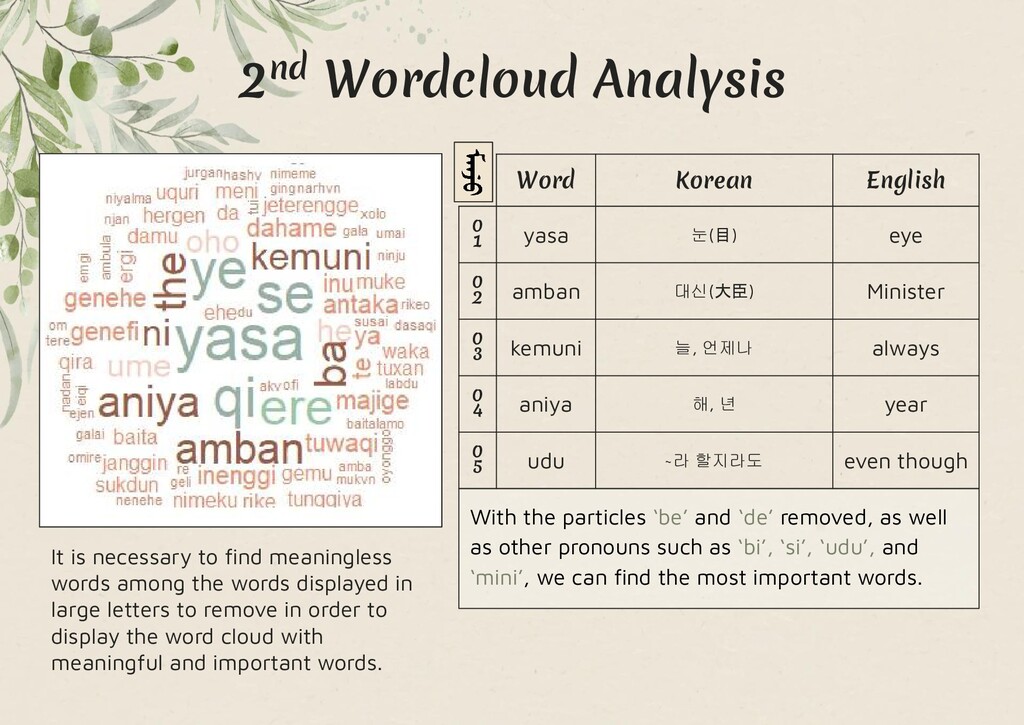
In this study, text that was already transcribed using the Möllendorf method was simplified to the Abkai method (transliterations of Manchu) in order to perform a big data analysis on the text and pull out the most important keywords from this portion of the text, the Weiwenqiji (慰問起居).
{kind=link}
{kind=link}
![Text[1] that was already transcribed by the Möllendorf method was](https://files.speakerdeck.com/presentations/4c41ecaaff5a4970896d8aa60bdea3ef/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1] Zhuang Jifa, Yumentingzheng, Wenshizhe Press, 2000. [2] Manchu alphabet.](https://files.speakerdeck.com/presentations/4c41ecaaff5a4970896d8aa60bdea3ef/slide_8.jpg){kind=link}