This presentation aims to demystify and explain the whys and hows of Big Data in the Industry. I made it when I was a Consultant at Devoteam Technology.
• Use Cases of Big Data • Related Technologies • “The Big Data Métier” • The Big Data Information System. • How hard do the clients need Big Data Systems today?
• Understand the usefulness of Big Data. • Know some of the Big Data Use Cases. • Clarify the difference between Big Data vs Traditional Systems. • Understand What Big Data really means. • Be introduced to some of the architectures of Big Data. • Have an idea about the technologies used in the industry. • Know the different skills needed to form a “Big Data Team”. • Comprehend the whole lifecycle of a Big Data Information System. • Have an idea about the needs of companies today, and how to make clients trust us. 4
been growing fast… Really fast. • Every two days, we create as much information as we did up to 2003. • In a lot of contexts, traditionals systems are no longer suitable. • We do not guess anymore, let’s take some decisions based on data! • Data generated today is unstructured. • Data is so large that it cannot be processed using traditionals systems. • ... Because it’s cheaper. 6
Tweets: ~500 million/Day. • IDC (International Data Corporation) estimates that the value Big Data market will be $102 billion by 2019. • “Using 10.000 attributes collected from 90 metrics in six different locations of the heart, analytics has been able to find patterns and pinpoint disease states more quickly and accurately than even the most highly-trained physicians.” healthitanalytics • Because Big Data gave birth to Watson, and Watson won against the Jeopardy World Champion, Ken Jennings. 7
live in a highly competitive world. • The challenge is not where the data is, nor how much do we have. • The challenge IS how fast and accurate our insights from it are. • Data is nothing but an unstructured garbage • … And we need to make sense out of it. 8
really a revolution? • Big Data is nothing but a buzz-term. www.linkedin.com/pulse/truth-behind-big-data-buzz-term-ayoub-fakir • It’s rather “Data of Unusual Size”. • The principles behind exist since the beginning of the last century. • But, it is still needed: We were able to democratize all those concept together. 9
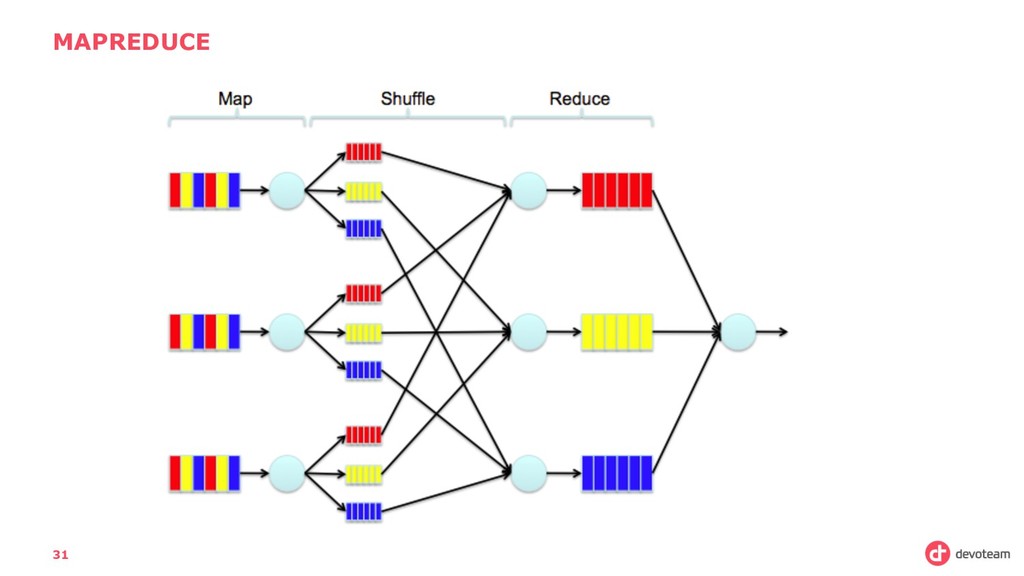
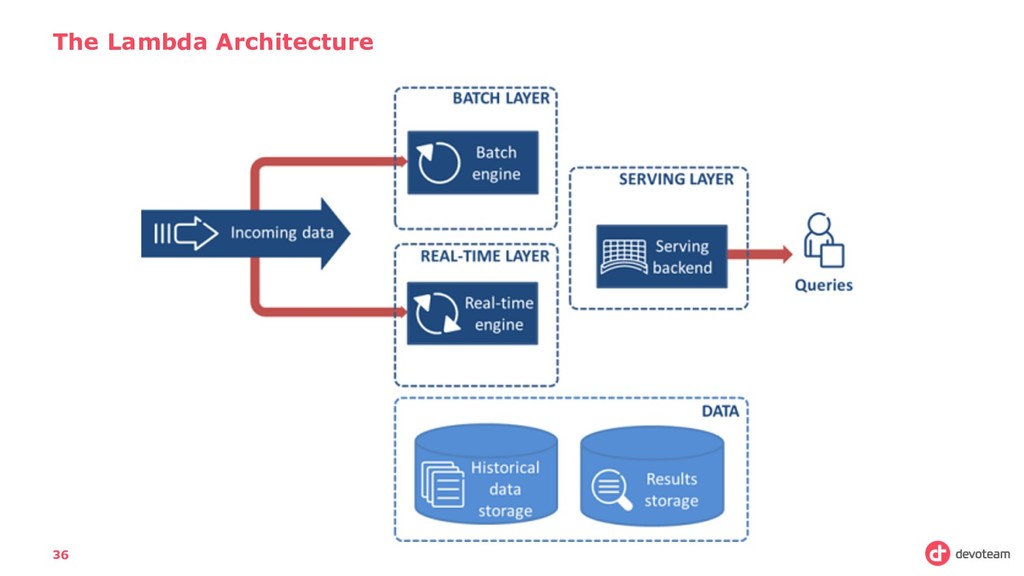
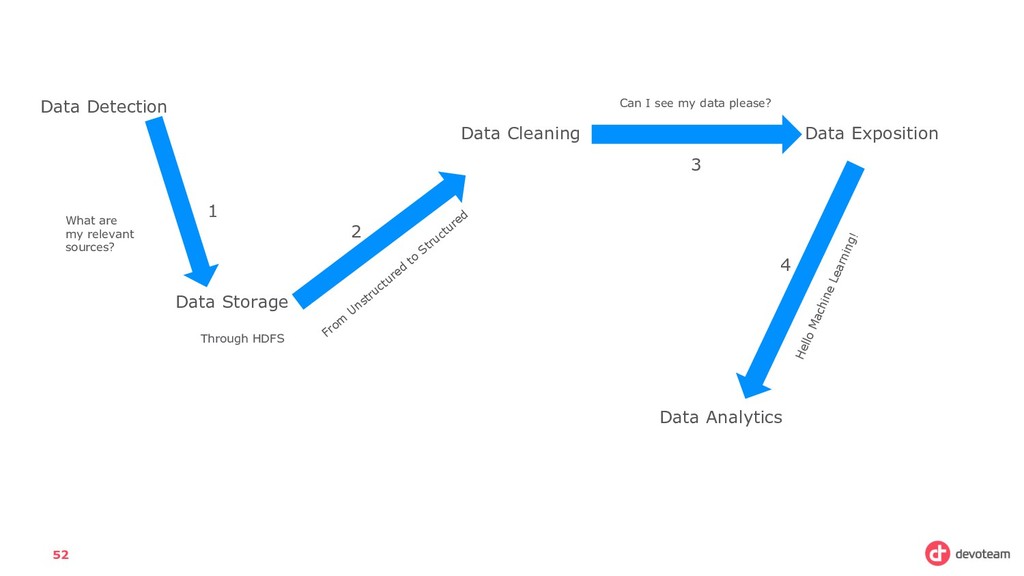
really, is a set of steps to follow: • Collect Data (coming from different unstructured sources) • Store this data, to process is later (also known technically as batch processing) • Analyze this data: Either in real time (stream processing) or afterwards.
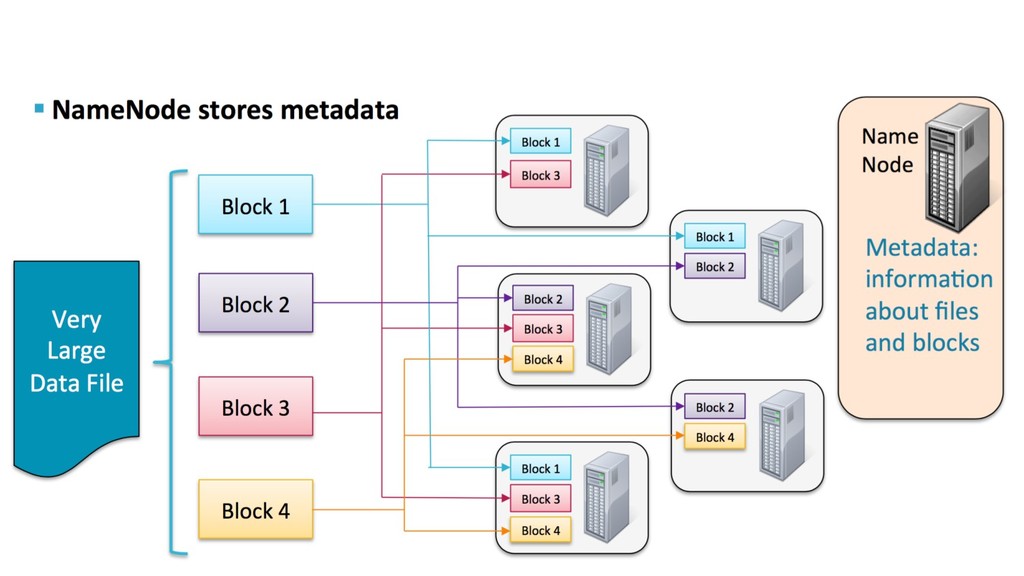
A datalake is a ”containers” where lots of data, from various sources, cohabit. • We store them first, and have no idea of how they are structured. • We analyze and process them afterwards, depending on the needs. • In a traditional Data Warehouse, we still need to structure data before storing, and it takes lots, lots of time and energy. • We forget about the business problems when trying to store structured data… Without knowing which type of insights we’re looking for. 16
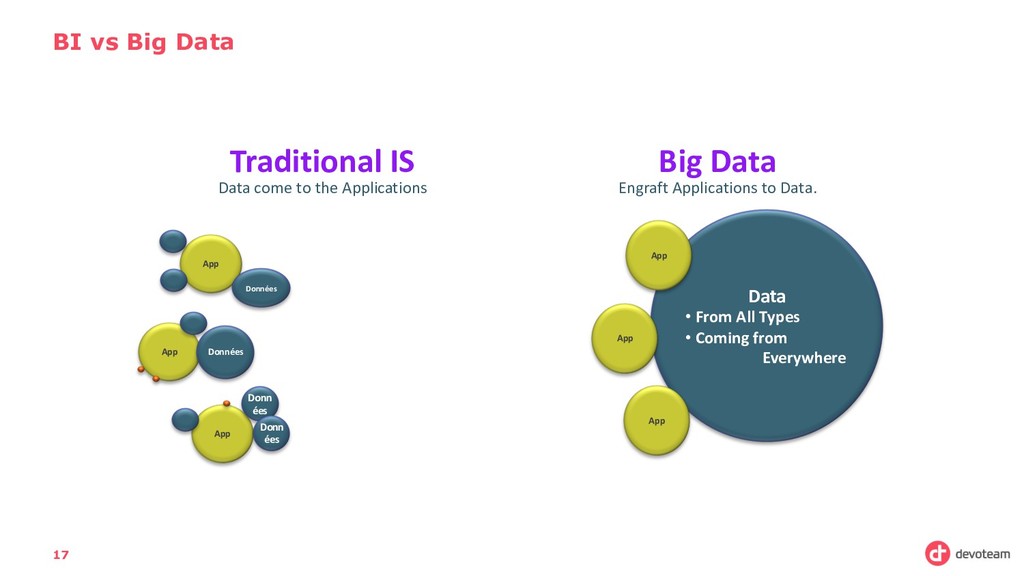
the Applications Big Data Engraft Applications to Data. Data • From All Types • Coming from Everywhere App App App App App App Données Données Donn ées Donn ées
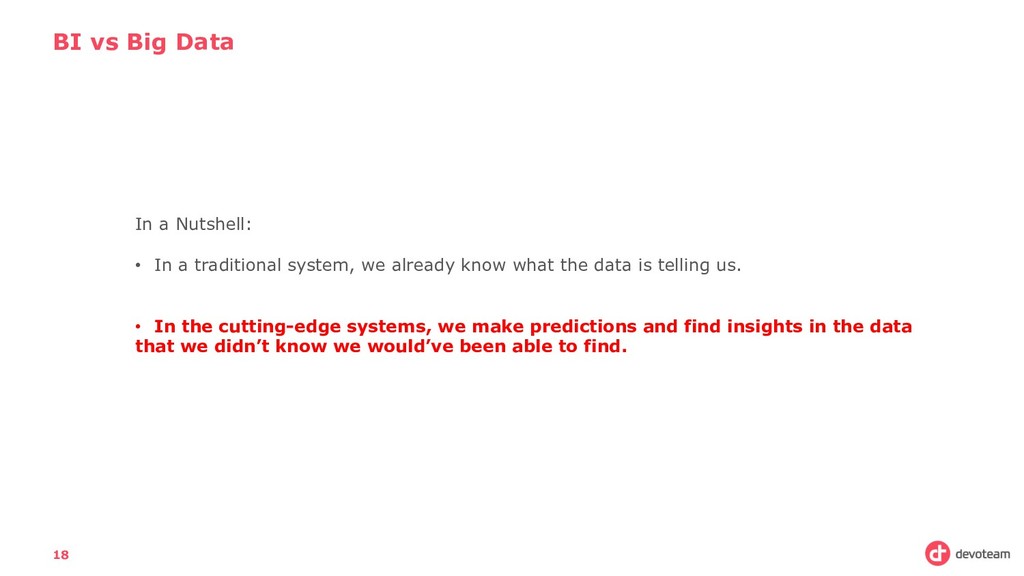
a traditional system, we already know what the data is telling us. • In the cutting-edge systems, we make predictions and find insights in the data that we didn’t know we would’ve been able to find.
• Some Big Data Examples. • Why Big Data is mandatory today. • “The Big Data Buzz-Term”. • Companies that use Big Data “the right way”. • The Data Vendors and the Infrastructure & Platform Services providers. • And finally, an example of a limitation of one of the “traditional systems”. 19
• The vast majority of them are, somehow, web related. • People tend to think about Big Data as the “solution”, since it is really the problem. • We tend to be “technology centric”, however, the technologies are chosen after the needs are specified. 21
and their friends say about a particular product. • Uses the data collected to send targeted messages about a particular product. • Shares discounts offers. • Targets customers siblings. 23
has been said about former president Obama in a variety of social media (Twitter, Facebook, Quora, …) • Classifies the followers: For Obama / Hesitating / Totally Against. • Acts accordingly. 24
a Big Data solution called “Match Insight”. • Gathers data about Germany’s opponents: Videos, tweets, moods of the players, etc… • Gave the coach dashboards to help him make decisions: Which player should play in which game? Is the defender quick enough to handle this football stricker? • The coach no longer needed to replay videos himself, he focused on game strategies. • ... They won J 25
on Google’s GFS. • Sits on top of a native filesystem(ext3, ext4, …). • Provides redundant storage for massive amounts of data. • Using readily available, industry-standard servers. • Is optimized for large, streaming reads of files. 29
Hadoop processing layer, and plays the roles of: • Resource Manager & Negotiator • Job Scheduler • It allows multiple processing engines to run on a single Hadoop Cluster • Batch Programs • Interactive SQL (Impala / Hive) • Streaming (Spark Streaming / Flume) • … And so forth. 32
high-level APIs in Java, Scala & Python. • Written in Scala (so would better to start learning Scala NOW!). • Provides a various of built-in libraries: • Spark SQL • Spark Streaming • Spark ML • … • Prove itself to be 100x faster than Hadoop for in-memory processing. • ... And 10x faster for disk processing. • Near real-time processing. • In-memory data storage and caching. 34
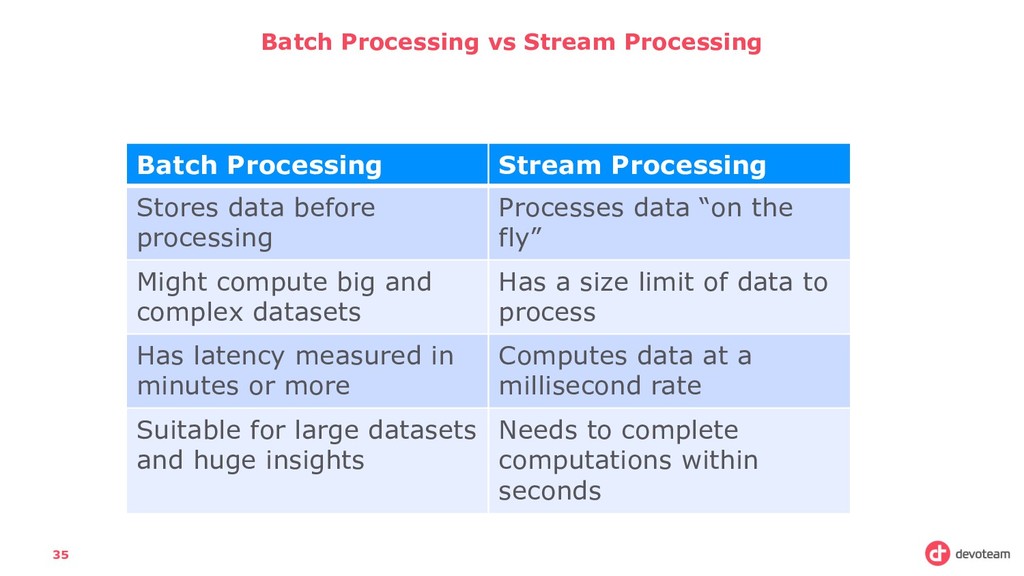
Stores data before processing Processes data “on the fly” Might compute big and complex datasets Has a size limit of data to process Has latency measured in minutes or more Computes data at a millisecond rate Suitable for large datasets and huge insights Needs to complete computations within seconds
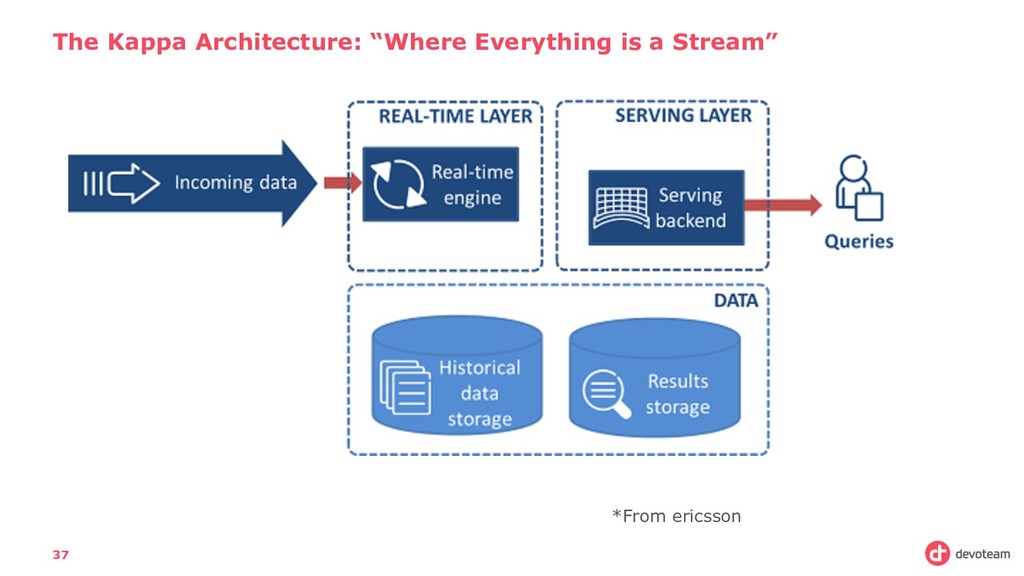
Unbounded Datasets • Provides results that are accurate, even in the case of out-of-order or late-arriving data • Apache Flink’s dataflow programming model provides event-at-a-time processing on both finite and infinite datasets. 38
the industry today: Hadoop Ecosystem & Spark. • What YARN is and how it performs in a Distributed System. • The difference between Batch & Stream Processing paradigms. • Some of the Big Data well known architectures. • Flink, a new framework for Stream Processing. 39
prepare the Big Data infrastructure, to be used by Data Scientists. • Software Engineering profiles. • Focus more on the design and architecture of the solutions. • They’re not supposed to have any machine learning skills. • Key Skills & Tools: • Programming • NoSQL • Data Streaming • Big Data platforms mastering • Hadoop Ecosystem (Hive, Pig, …) • Spark 41
“alchemist” of the 21st century (according to bigdatauniversity). • Turns data into useful insights. • Usually have mathematics background. • Are able to interpret and deliver the results of their findings by visualization techniques or user stories. • Find patterns in data: Recommendation engines, stock market predictions, etc… • Key Skills & Tools: • Statistics • Mathematics • Python • R • Datamining • Algorithms 42
be able to define the problem: Know the business needs. • Help define the challenges that can be gone through, using data. • Help build the design of a Big Data Information System. • Know which tool should be used for which problematic. • Skills & Tools: • SAS • SAS Miner • SQL • SSAS • Microsoft Excel • Design Architecture 43
the solutions made by Data Engineers happen. • Ensure that the distributed applications keep up and running. • Monitor the Big Data Systems. • Is one of your nodes down? Your productions engineers will help you get through that! • Skills & Tools: • Hadoop Ecosystem Administration • Spark monitoring & Metrics. • Strong technical skills on JVM. • Strong Linux administration skills. 44
The “Devops” engineer doesn’t exist. • It’s more of a paradigm: Data Engineers, Data Analysts, Production Engineers, Testers and Data Scientists work all together, to create a “Devops Synergy” • Ensure the continuous delivery. • Work in an agile context. • Skills & Tools: • It’s a team ;) 45
the Big Data industry. • The role of a Data Engineer. • The role of a Data Scientist. • The role of a Data Analyst. • The role of a Production Engineer. • The Devops Paradigm. 46
faced in many Big Data Projects? • Lack of appropriately scoped objectives • Lack of required skills • The size of Big Data • Privacy • Anonymization • Data Management / Integration • Rights Management • Data Discovery (how to find high-quality data from the web?) • Data Verification • Technical challenges when data is in motion • Data Velocity: “It’s not just how fast data is produced or changes, but the speed at which it must be understood, acted upon, turned into something useful.” 48
analyzing Big Data? • Before beginning a Big Data Project in every company, a quantitative ROI must be identified. • The investment on a Big Data Project should be lower than the ROI. • With Big Data, we can learn more about our clients’ behavior, and extend our knowledge capabilities. 49
• Which technology can best scale to petabytes? • “One of the benefits of Hadoop is that you don’t need to understand the questions you are going to ask ahead of time, you can combine many different data types and determine required analysis you need after the data is in place.” MapR • The fundamental principle of hybrid architectures is that each constituent Big Data platform is fit-for- purpose to the role for which it’s best suited. 50
need the utility-like nature of a Hadoop cluster, without the capital investment. Time to analytics is the benefit. • After all, if you’re a start-up analytics firm seeking venture capital funding, do you really walk into to your investor and ask for millions to set up a cluster; you’ll get kicked out the door. No, you go to Rackspace or Amazon, swipe a card, and get going. IBM or any other vendor are there with their Hadoop clusters (private and public) and you’re looking at clusters that cost as low as $0.60 US an hour. 51
to convince our clients, let’s be convinced ourselves. • The good news is that a vast majority of them are already aware (either consciously or unconsciously). • Without data, every company will be, one day or another, outperformed. • The giants understood the value of Big Data, so should our clients. • Data-Driven decisions are precise decisions. • We have data: it’s either we use it, or throw it away: the choice is yours. • But before… Let’s go through understunding the real business challenges. • Let’s narrate stories... The Watson example is a great one ;) • Seek first to understand, then to be understood. 54
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}