Talk given at EuroPython 2022
BBC News Labs is an innovation team within BBC R&D, working with journalists and production teams to build prototypes to demonstrate and trial new ideas for ways to help journalists or bring new experiences to audiences.
Working in short project cycles, it's important for us to be able to quickly build processing pipelines connected to BBC services, test and iterate on ideas and demonstrate working prototypes. We make use of modern cloud technologies to accelerate delivery and reduce friction.
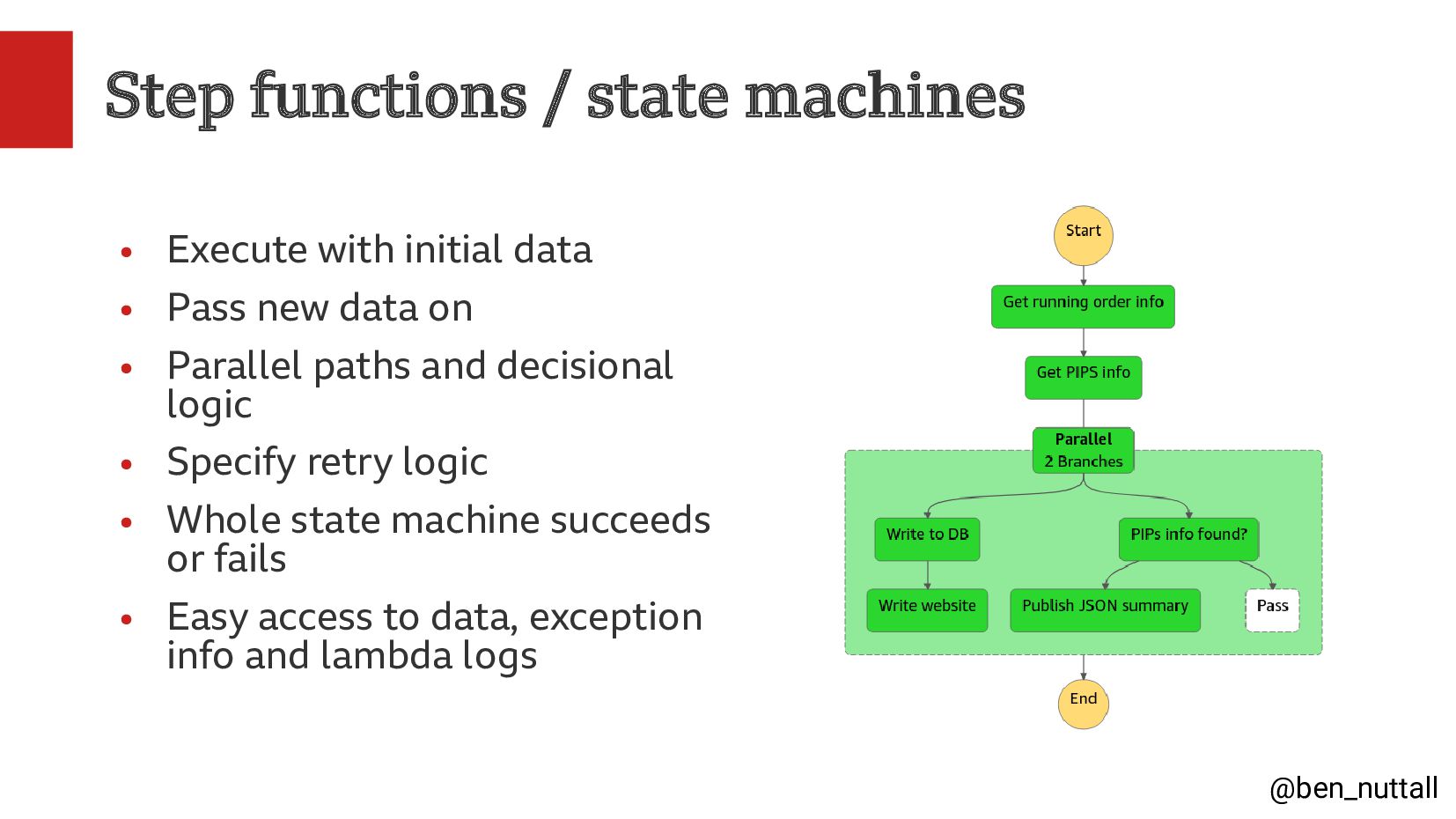
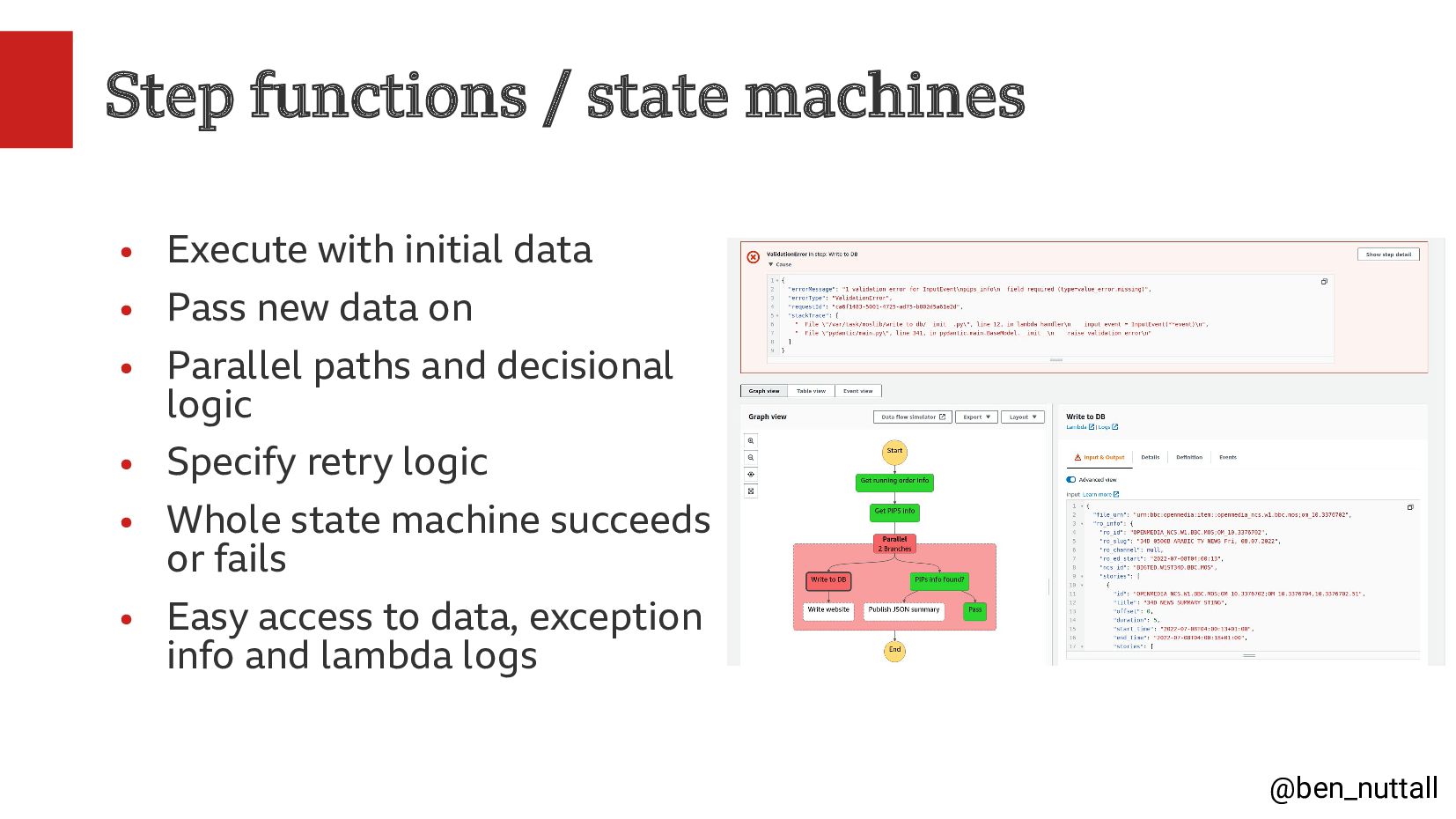
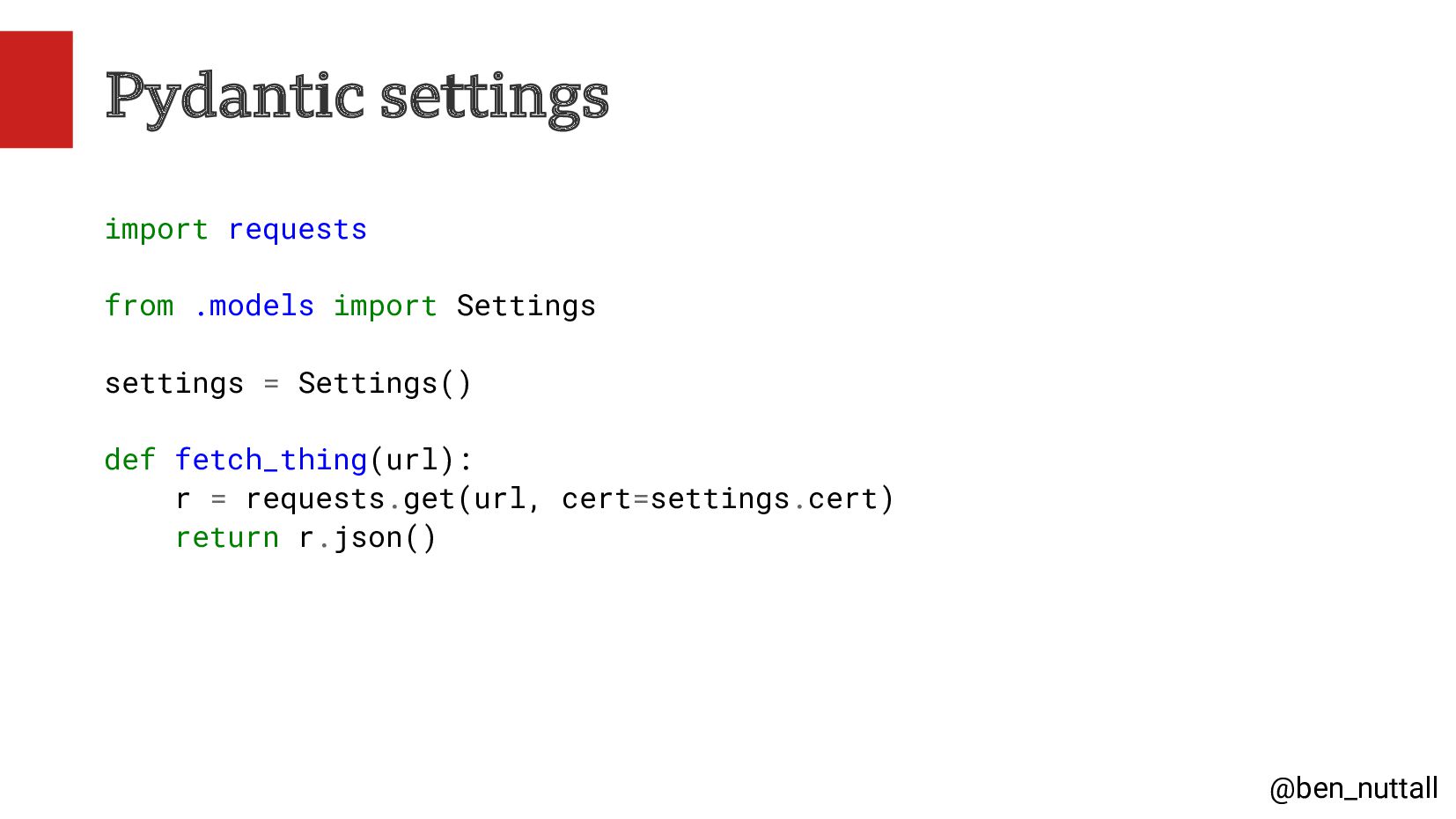
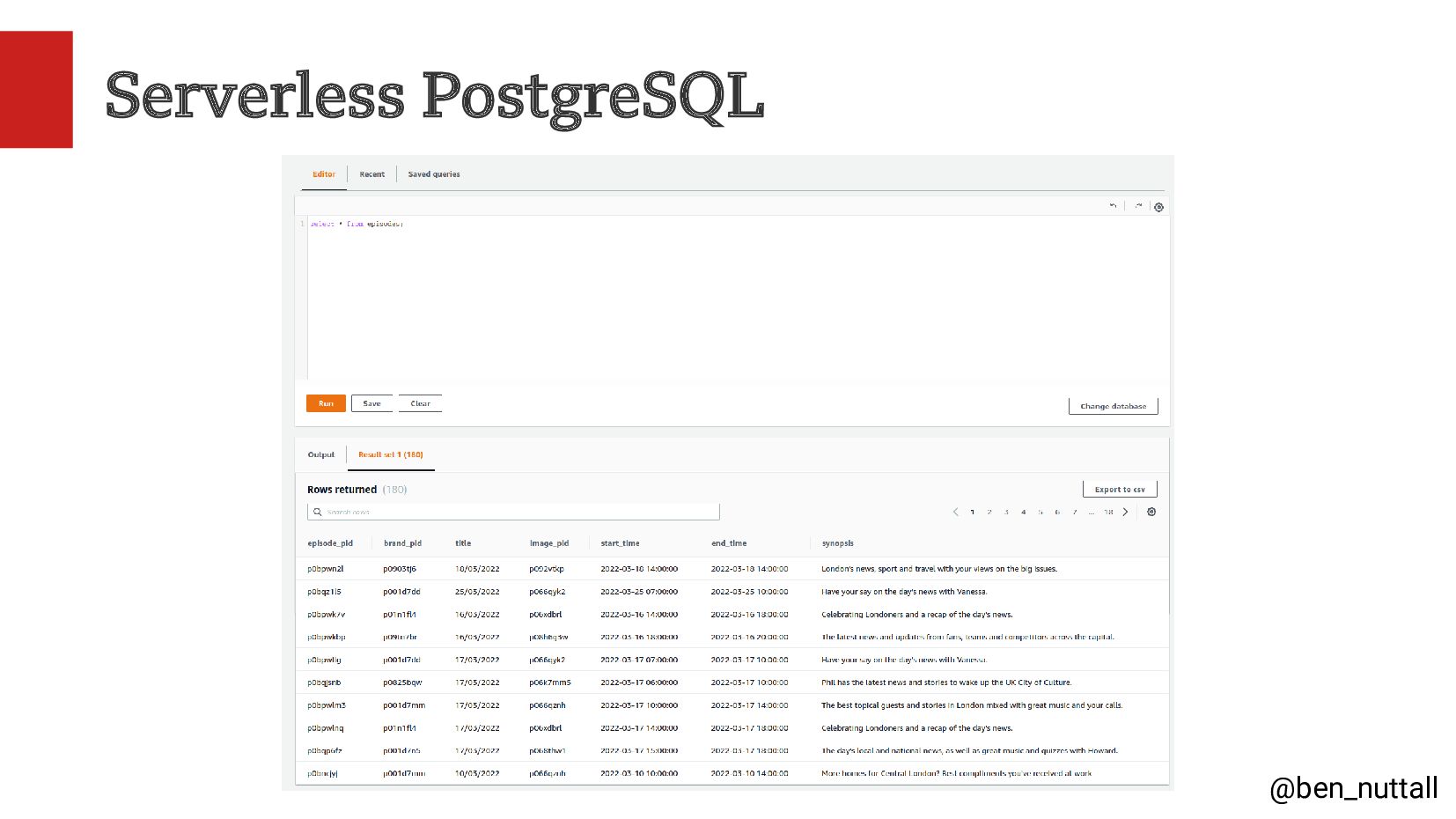
In this talk I will share our ways of working, our ideation and research methods, and the tools we use to be able to build, deploy and iterate quickly, the BBC's cloud deployment platform, and our use of serverless AWS services such as Lambda, Step Functions and Serverless Postgres.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
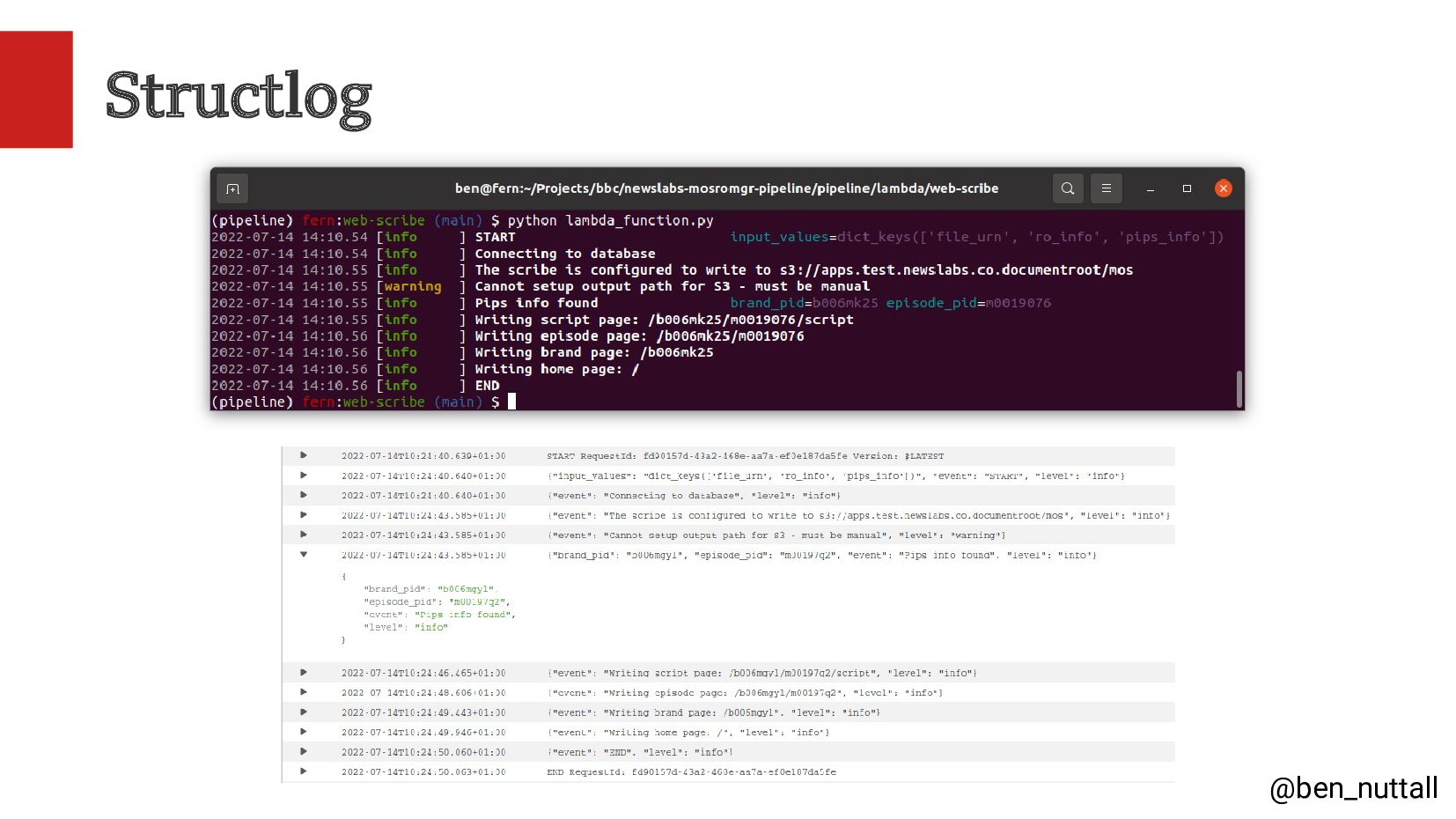{kind=link}
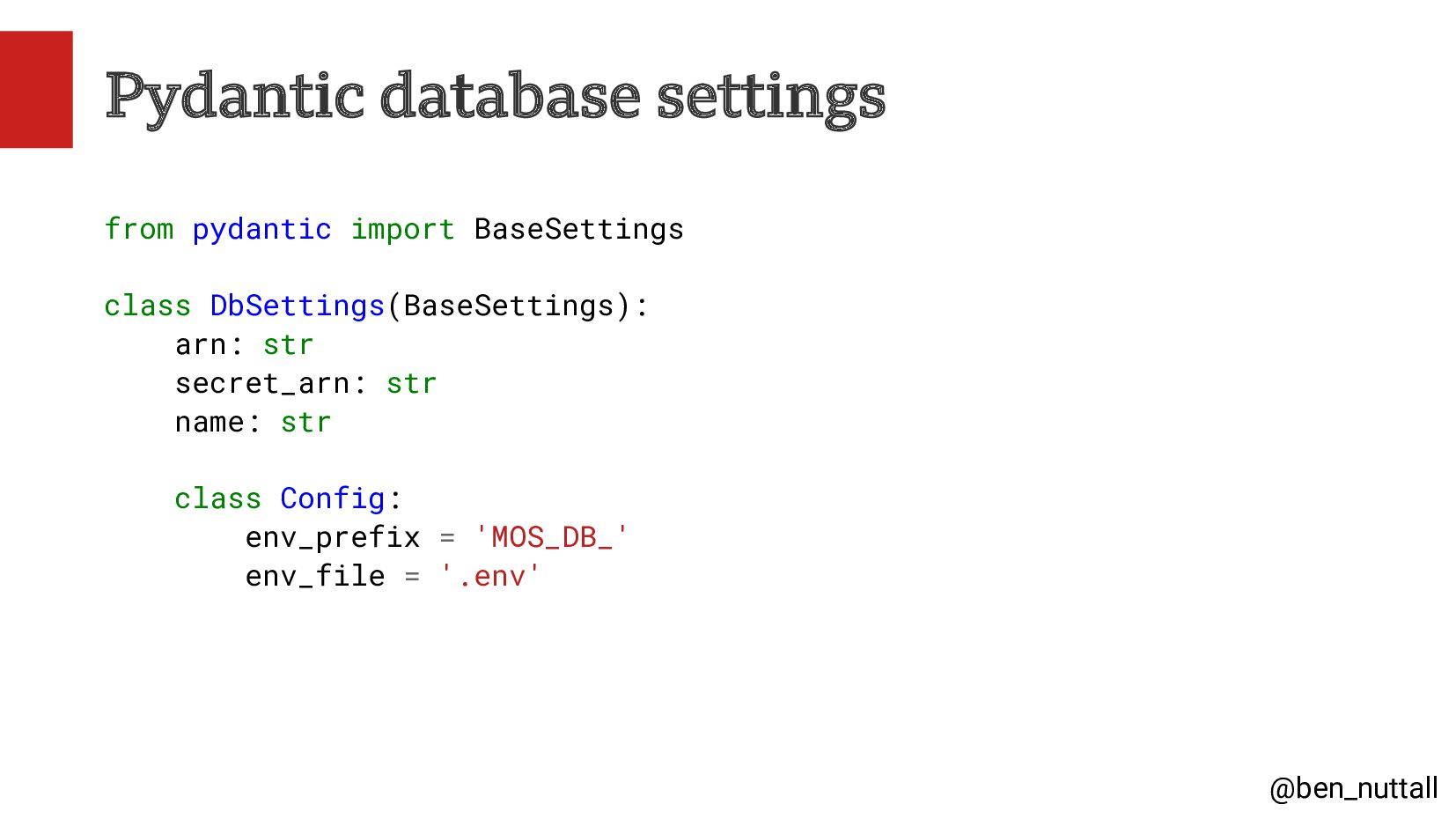{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}