at Raspberry Pi • PyPI critical project maintainer • Based in Cambridgeshire • bennuttall.com • twitter.com/ben_nuttall • github.com/bennuttall Ben Nuttall
• Prototypes of new audience experiences • Solutions to help journalists • Research and trying out ideas • bbcnewslabs.co.uk • twitter.com/bbc_news_labs BBC News Labs
radio for social media mosromgr Processing TV/radio running orders to extract structured metadata BBC Images Image metadata enrichment pipeline Projects
do their job using existing tools • Work out what their workflows are • Look for pain points, inefficiencies, slowness, manual work that could be automated Shadowing
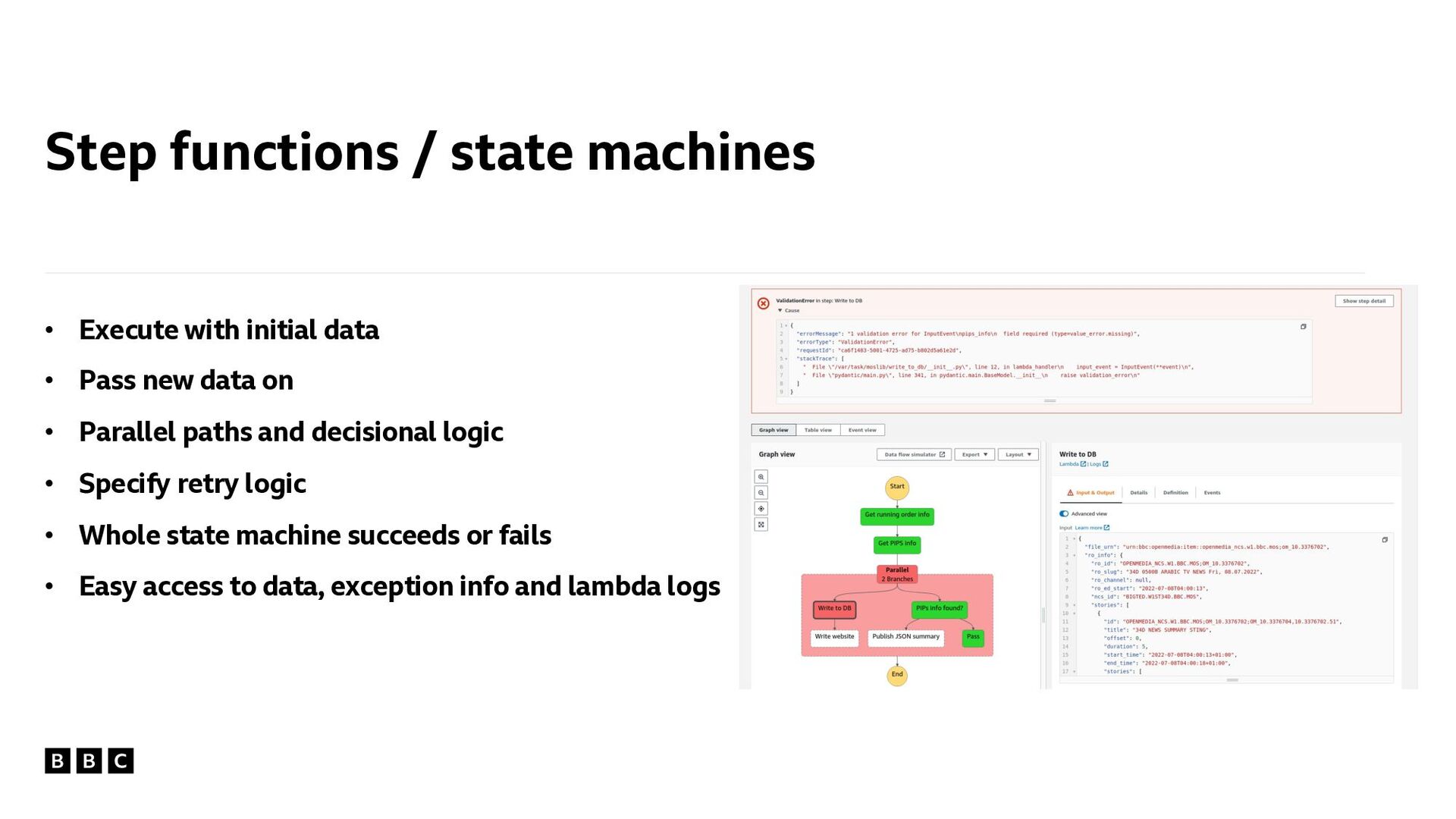
• Parallel paths and decisional logic • Specify retry logic • Whole state machine succeeds or fails • Easy access to data, exception info and lambda logs Step functions / state machines
• Parallel paths and decisional logic • Specify retry logic • Whole state machine succeeds or fails • Easy access to data, exception info and lambda logs Step functions / state machines
• Create Chameleon templates for each page type • Create logic layer for retrieving data required for each page write • Create lambda for writing/rewriting relevant pages • e.g. new episode processed: • write new episode page /<brand>/<episode>/index.htm • update brand index page /<brand>/index.htm • update homepage /index.htm • Create CLI for manual rewrites Static HTML websites with Chameleon
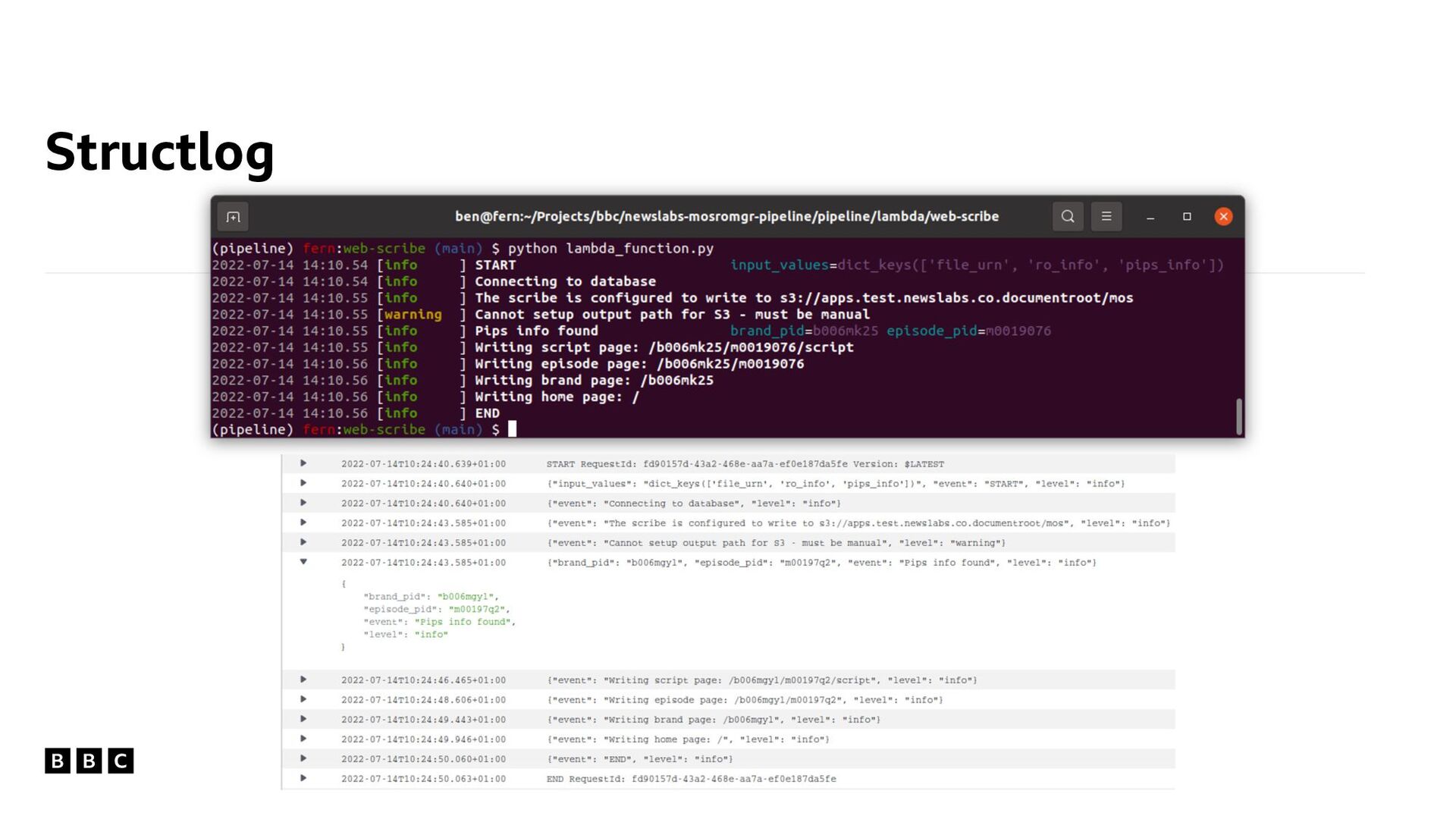
easy to see relevant information • JSON logging support ideal for running in AWS • can access and search structured logs in CloudWatch • Encourages good logging practice! Structlog import structlog if os.environ.get('MOS_LOGGING') == 'JSON': processors = [ structlog.stdlib.add_log_level, structlog.processors.StackInfoRenderer(), structlog.processors.format_exc_info, structlog.processors.JSONRenderer(), ] structlog.configure(processors=processors)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def lambda_handler(event: dict, context=None) -> dict: ... event['thing'] = do_thing(data)](https://files.speakerdeck.com/presentations/f7d804d8efeb4250804aaf93bfc42bd0/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}