Stu ff just got into production, everything runs fi ne • Some bugs here and there might be found, you fi x it quick • Not many people uses it yet, things seem to work well • Everyone is happy!
• Tra ff i c is high, things start to break • You tried to upgrade your servers, things are still breaking • e.g. update DB? DOWN FOR 6 HOURS • Bugs, bugs, bugs • Questions raised: • How do people get 99.99%+ uptime? That’s ~52m downtime per year! • How can I know something is going wrong before my users does?
to walk, learn to run • Planned, maintained systems running well and with minimum disruption • People with titles like “SRE (Site Reliability Engineer)”, “Devops Engineer”, “System Engineer”, “Software Engineer” starts to come in • You start seeing less and less downtime or error pages • Question: How to get there?
responsible for managing the service throughout the entire lifecycle • From requirement gathering to handling production issue • There might be infra team to help on platform, but ultimately the team is responsible for the system • No “we don’t understand Kubernetes / Networking / Linux” excuse • This is why DevOps is Development and Operations
the team are also responsible for the product as a whole • This means that the team has its own product, business, qa, etc person • The team would also de fi nes their own successes • i.e. Success for wallet team is if 10% of payment uses wallet • The team operates locally, within their own domain
The team should only need to do local changes for their change • Want to change 1 feature? Update only 1 repo / directory (if you use monorepo) • Changes should impact others as little as possible • If to deploy you often need to coordinate with multiple teams, its not local • If you often need to work with too many teams to deliver a feature, it’s not local • How do you achieve locality?
much can we decouple applications / services? • What architectural / code pattern to use? • i.e. (design patterns) Mediator, Bridge, Factory • How do we know we’re simple? • i.e. (software metrics) Connascene, Coupling • Your process has to be simple as well • i.e. do you need to talk to engineers to ask something? Or do your manager have to talk to their manager to do something at all?
As a developer, you have to be able to focus on your work • Coding should be a joy: with minium dependencies, delays, and impediments • If it’s not like that, you should make it so • This is part of “ownership”
better • Start from architecture: good architecture is one of the most important part of reducing coupling • Sadly huge topic. Next slide will show some references. • Pay down your technical debt constantly • Each iteration (sprint, release, etc) should have tech debt tickets • The team should roughly know what their painpoints are, and when it will be addressed
It should be safe to talk about problems • It should be safe to make mistakes • There should never be castigation, ridicule, blame even for big mistakes • Personally, I’ve seen mistake amounts to ~15m+ USD in a day and leadership’s focus is “what can we learn from it?”. That is good leadership. • It’s very important to have blameless culture because people learn when they make mistake
and iterate on what the customer wants from your product • Every change in your system should answer the question: “what problem does this change solve for my customer?” • Understand core and context: • Core: how much the customer is willing to pay • Context: what the customer don’t care about
your systems - you are responsible for its entire lifecycle • Make things local and simple - simple == maintainable • Improve on things daily - one step at a time • Failure should be safe - humans are fl awed, we learn from mistakes • Focus on customer - a great product without customers is a dead product
should know what “success” means • How do you know if you have achieve success? Track it via metrics! • De fi ne your success criteria upfront, and track it • Your sucecss criteria must be measurable, hence trackable metrics • Have a simple way for everyone in your team to see if the system is meeting its success criteria • Usually this would be a (soft) real-time dashboard
1. Business Metrics • Tracks what makes a business successful • Example: • e-commerce: no. of new customers, no. of transactions, Gross Merchandise Value • e-wallet: total transaction amount, no. of daily transactions • Usually discussed with business people • Sometimes is simply your KPI / OKR etc
2. Service Metrics • Tracks if your service is healthy • Example: • API server: response time, error rates, request per second • Server: CPU utilization, free storage, RAM usage • Usually de fi ned by tech team, to make sure the system could handle users’ request
Latency • Time it takes to service a request. Successful and failure should be tracked separately • i.e. error latency might be related to timeouts, success taking too long is indication of slow system somewhere • Tra ffi c • How much demand is being placed in your system? • i.e. request / second, network I/O, concurrent sessions
Errors • Rate of request failure • i.e. HTTP 5xx, cache miss • Saturation • How much of your system is “utilized” • i.e. memory utilization, 99th percentile response time
Usually your metrics & monitoring tool will provide SDK • Use the SDK to send data to your monitoring system, then build a dashboard out of the data you sent • If you are afraid of vendor locking, there’s projects like Open Telemetry (https://opentelemetry.io) that you can use • You should build your system such as any feature build should answer the question “how will I track the success of this feature?”
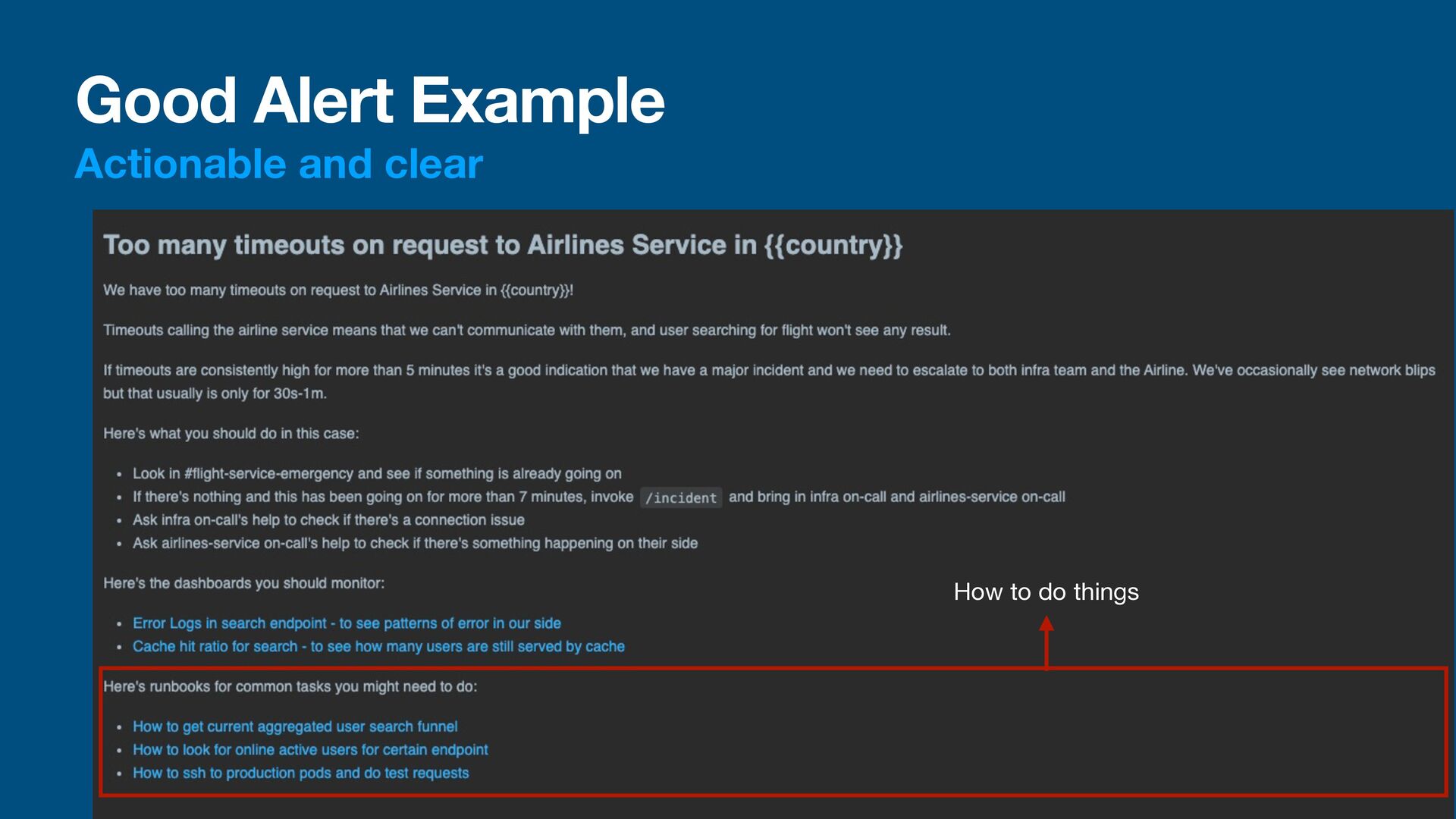
it? • Metrics should be tracked. A metrics that no one looks at is a waste of resources. • A monitoring system could give you visualization of your metrics • This could help with things like analyzing long term trends • A monitoring system could also keep an eye of your metrics and alerts you when things don’t go as expected • i.e. too many errors? Alert the team!
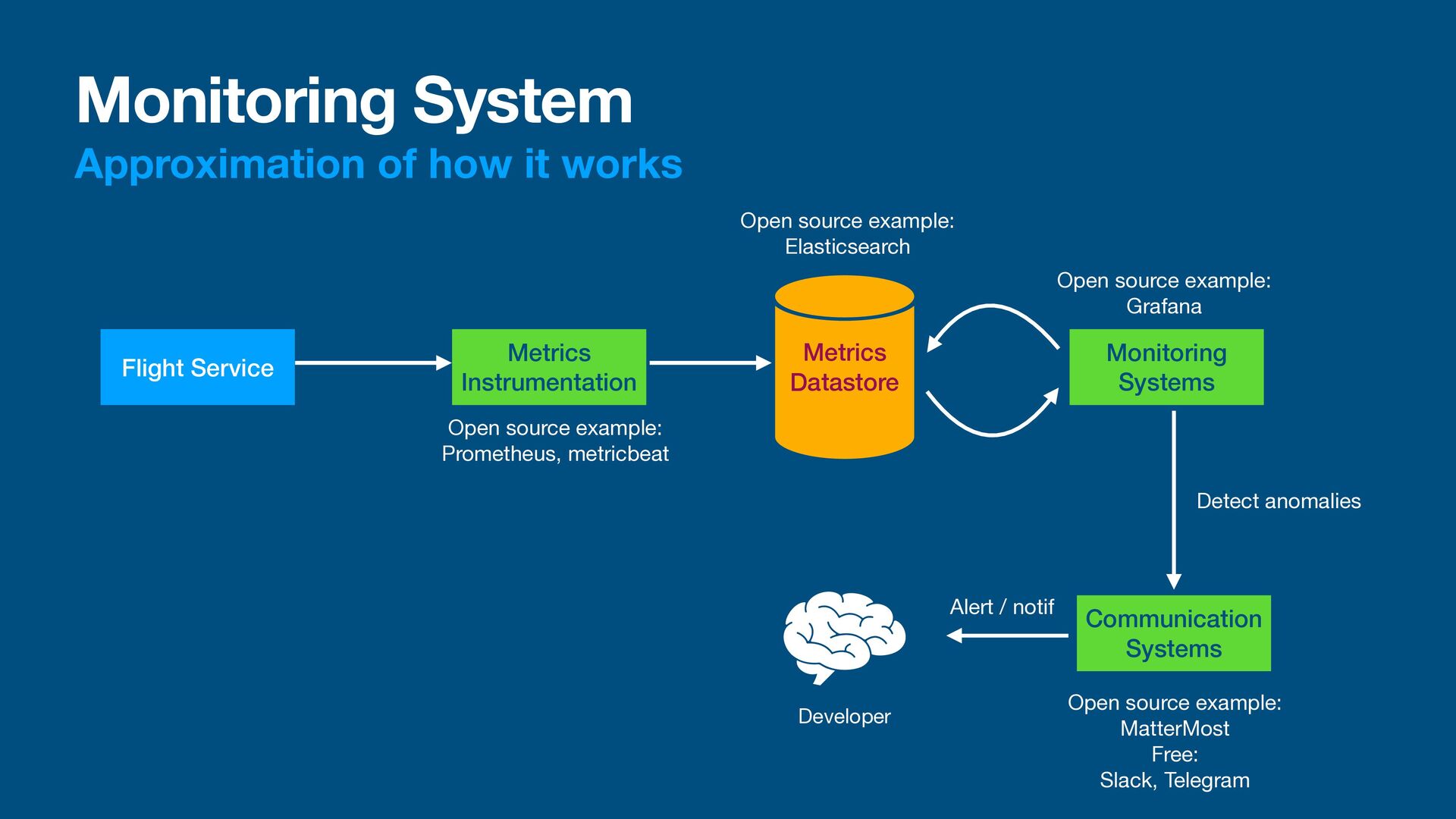
Instrumentation Metrics Datastore Monitoring Systems Communication Systems Developer Open source example: Prometheus, metricbeat Open source example: Elasticsearch Open source example: Grafana Open source example: MatterMost Free: Slack, Telegram Alert / notif Detect anomalies
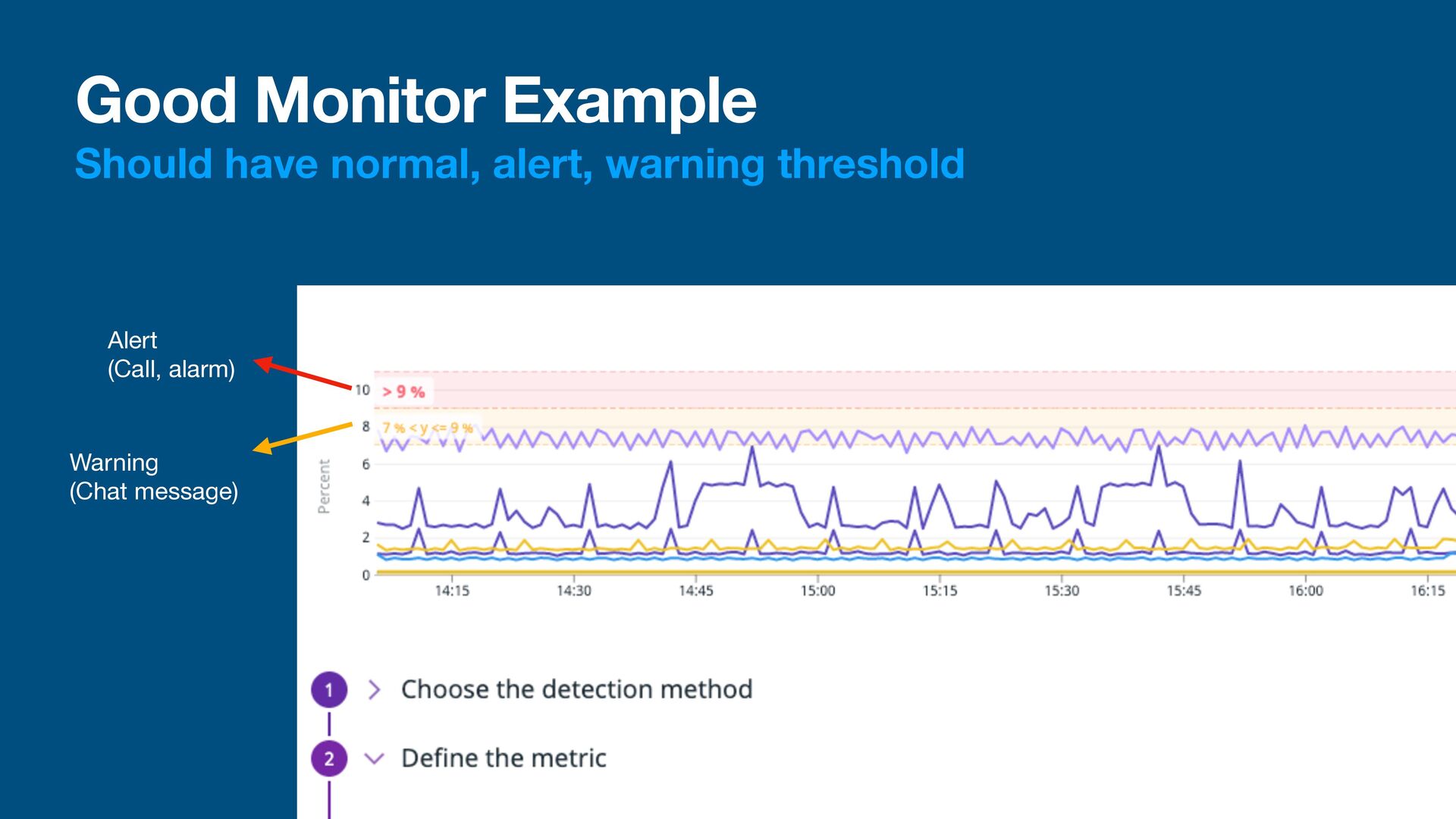
Too many monitors and alerts leads to apathy • “Oh the alarm is ringing all the time, just ingore it” <- we don’t want this • Rule of thumb of what to monitor: Can your customer still use your product if this metrics is out of ordinary? • Example: a payment system that can only process 10% of transaction is useless. Alert when success rate is < 90% • This means that we at least need 3 metrics: transaction start, success, and failure
alert • A monitor should have a clear threshold before alerting developers • A good monitor sholud show the data being monitored • Usually we’ll start with warning, then alert • This is because sometimes spikes / glitch happen, and we don’t want to be alerted every time • Example: • timeout due to network glitch for 1s might not need an alert, just noti fi cation • If the timeout persist for 30s, we should be worried and check
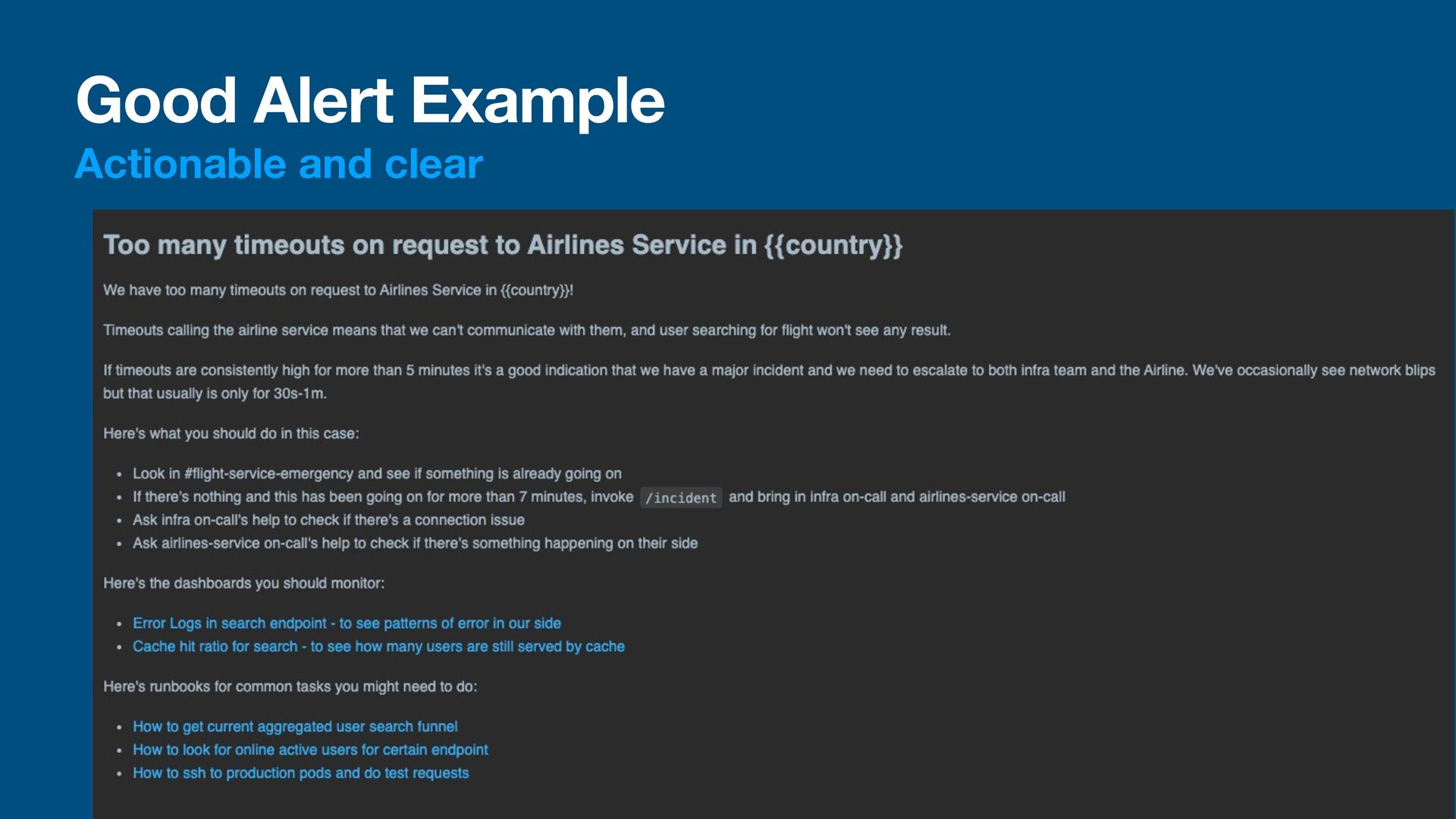
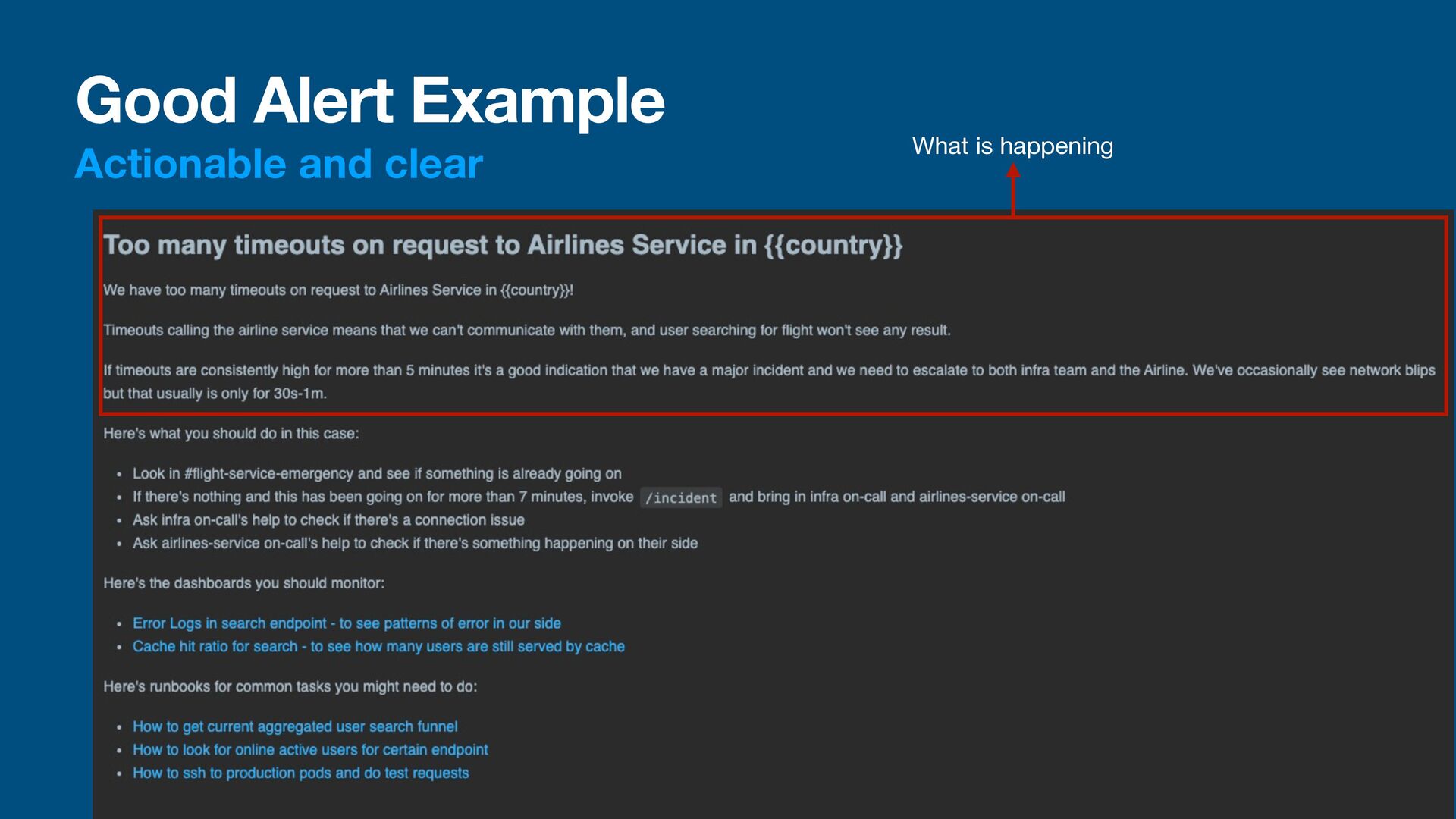
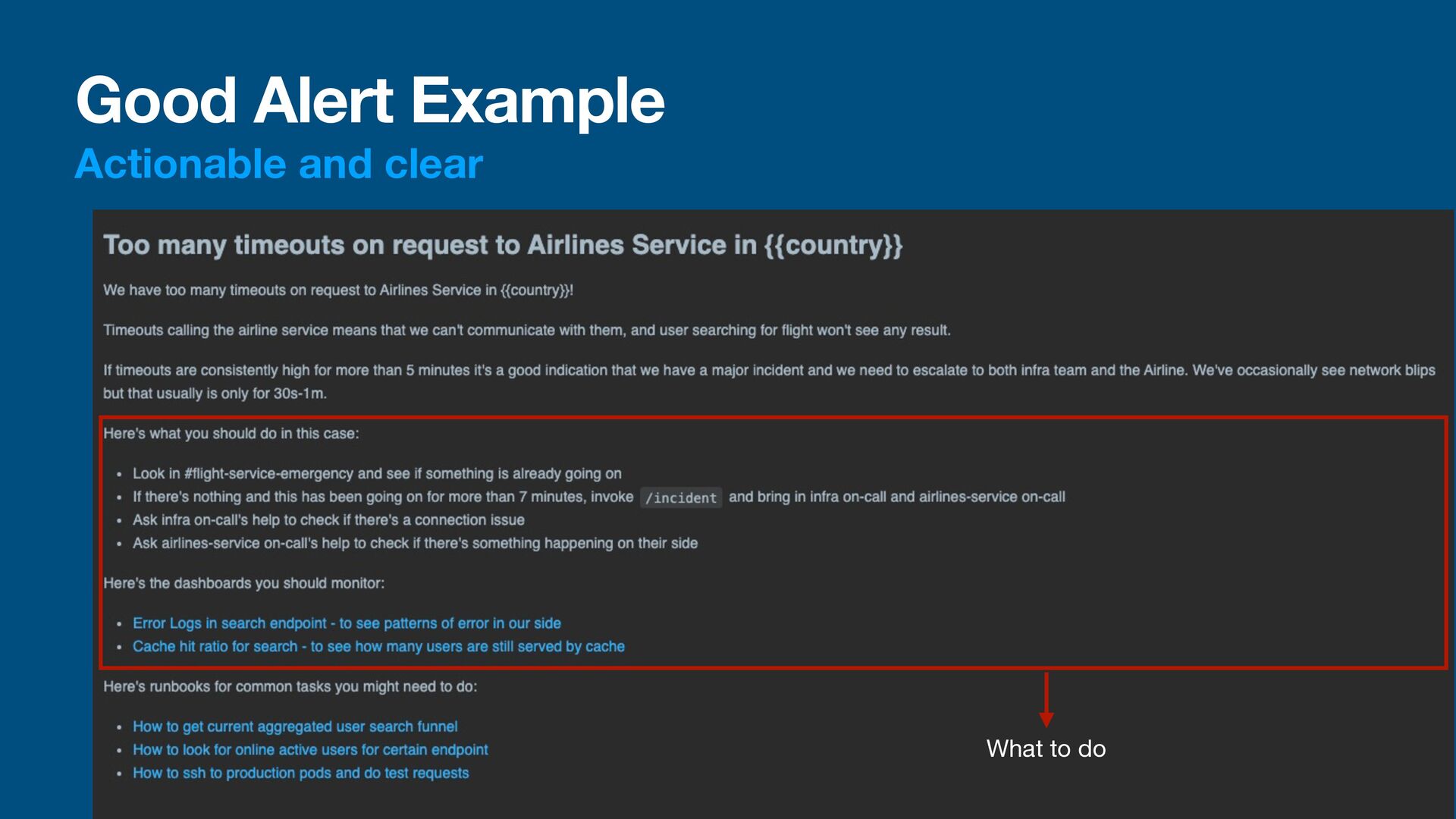
talking • A monitor must be actionable • The receiver of an alert should know what happened and why it happened • The receiver of an alert must be able to act on it • A good alert would have a message to tell the receiver what happen and what to do about it • We could also write a runbook: a guide on how to handle a situation
metric to de fi ne your success • System metrics to make sure you can be successful • Metrics must be measurable above all • Collect your metric, and acts on it. Monitor it. • Notify, warn, then alert. Too many alerts leads to apathy. • Make sure your alert is actionable, otherwise the responder would be helpless.
we measure and monitor our goals, what comes next? • The best of the best softwares have 1 key: continuous improvement • Getting it right the fi rst time is a rare event • It’s better to have something, then improve it as you go • You can try to understand a user, but it’s di ffi cult to understand millions of user
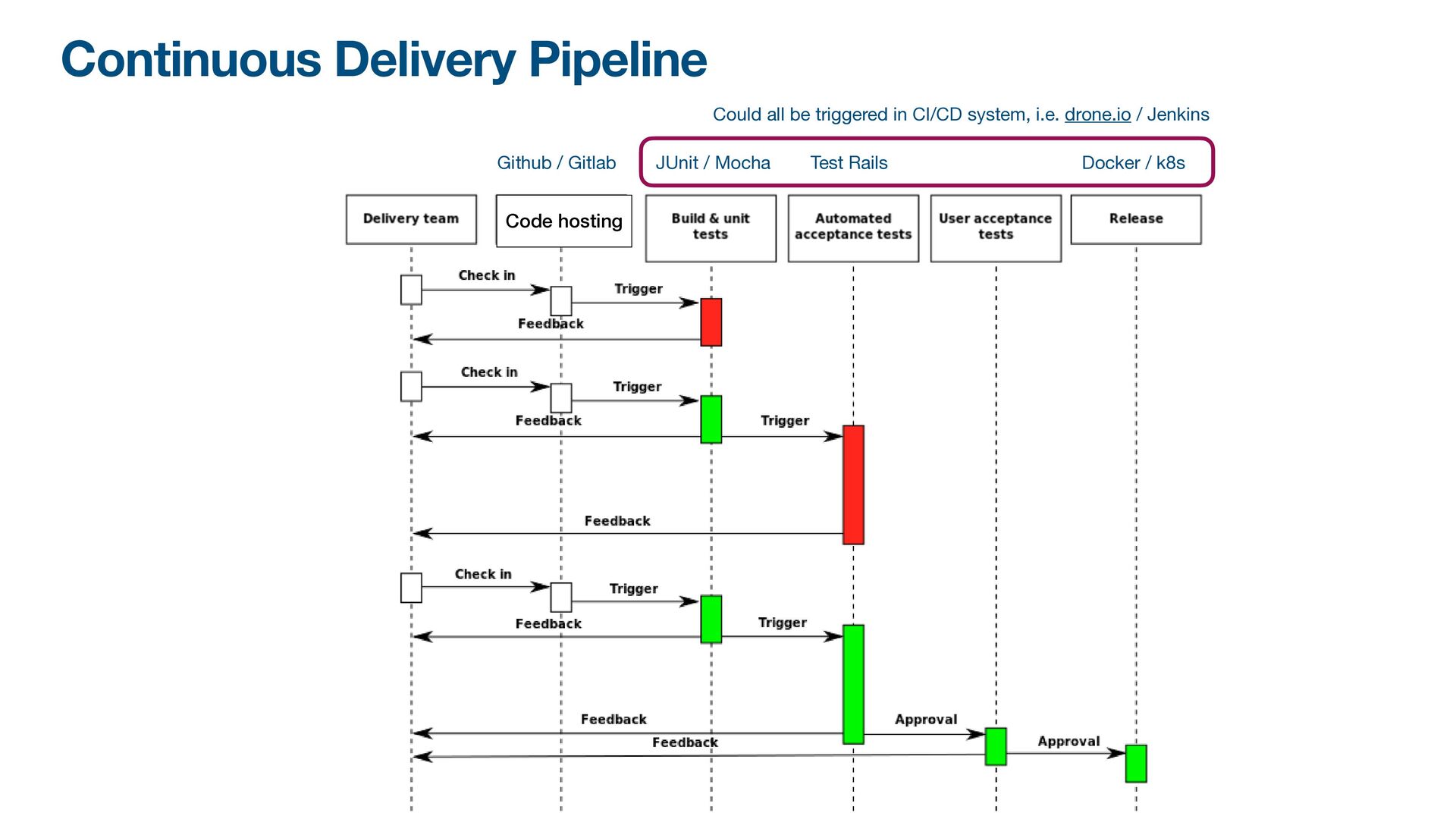
world, the ability to change your system easily, reliably, and fast is very rare • The one that can do that usually achieve it by doing it continuously • The core of continious delivery is that you deliver your changes: • In short cycle (fast and small) • In any time (safe and reliable) • Automatically (minimum human intervention)
do fast deployment, anytime • Small bug fi x would take minutes-hours instead of days • Easy deployment incentivize daily improvement - it’s motivating if your mini- changes go to production fast and directly improve a user’s life • Having a continuous release means that changes are usually small - when something goes wrong, it’s easier to rollback a small change vs huge change • Small changes also means it’s cheap to throw away - easy to pivot before you are investing in a feature too much
Debugging • Managing Dependencies - both in tech (library, framework, tool) and people (teams) • Scaling Operations - what works for 100 person team might not work for 1000 person team • Toil - How to fi nd and eliminate them
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}