It was presented at the Data Council conference in Singapore on 17th July, 2019.
About the talk:
Setting up your data architecture can be tricky and confusing without knowing what the future holds for your company’s growth. Some might have attempted to sell you out of the shelf solutions or you could have been overwhelmed by hearing about unlimited different technologies, concepts, big data engines that are scalable without a limit... Right? Or just go with Google Analytics since your marketing team is already keen on that? Do you have a hunch of what you should use?
I have worked and built multiple data architectures for companies with different sizes from only few thousands to billions of active users; and used all modern technologies such as Azure SQL Data Warehouse, Redshift, Presto, Hive, Spark, Airflow, Kinesis Data Firehose. From my experiences at Facebook and Microsoft, I know how these tools can be used efficiently and what are the best practices of the industry.
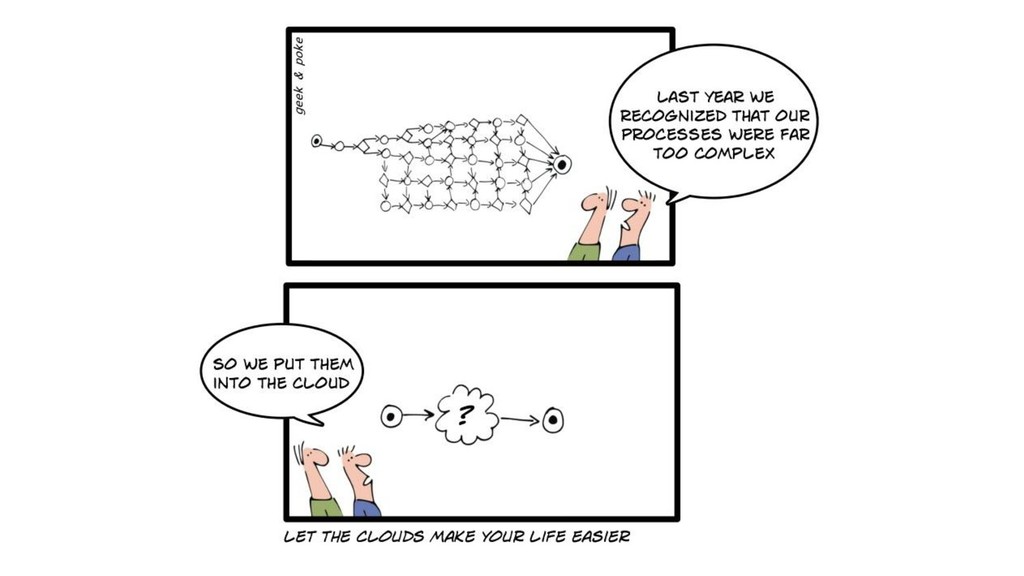
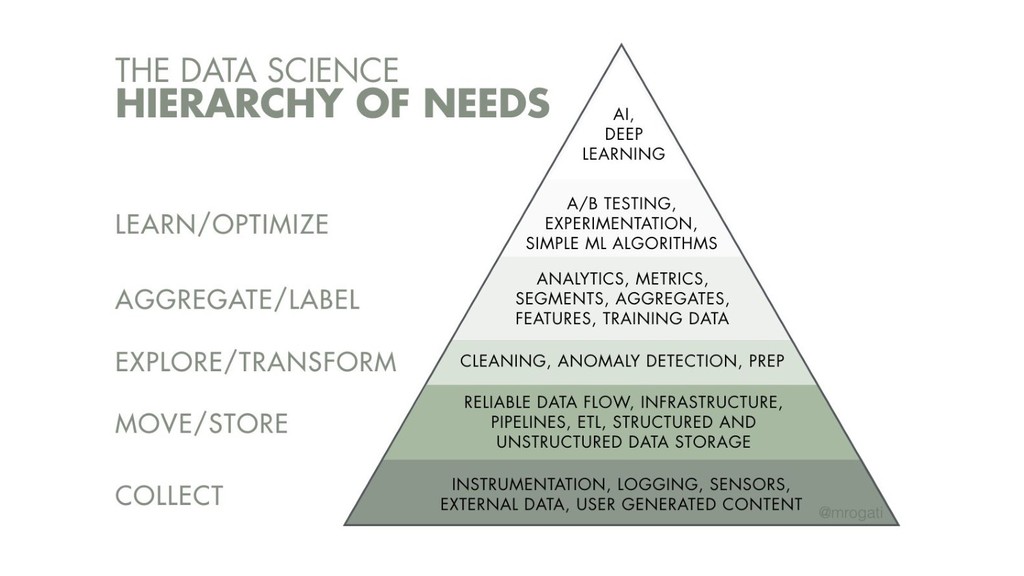
In this talk I will guide you what solutions are available for all company sizes, when is the right time to add or replace architecture elements for better scaling and/or better engineering. What are the caveats and deep technical tricks to get the most out of these tools. Moreover, I will answer how to avoid building or setting up overcomplicated systems, and when should you hire data scientists or data engineers.
![Data Architecture 101 for Your Business Bence Faludi - [email protected]](https://files.speakerdeck.com/presentations/97e82cc26c924bddb395113176cfb1c6/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Bence Faludi Independent contractor [email protected] My background - Contractor for](https://files.speakerdeck.com/presentations/97e82cc26c924bddb395113176cfb1c6/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
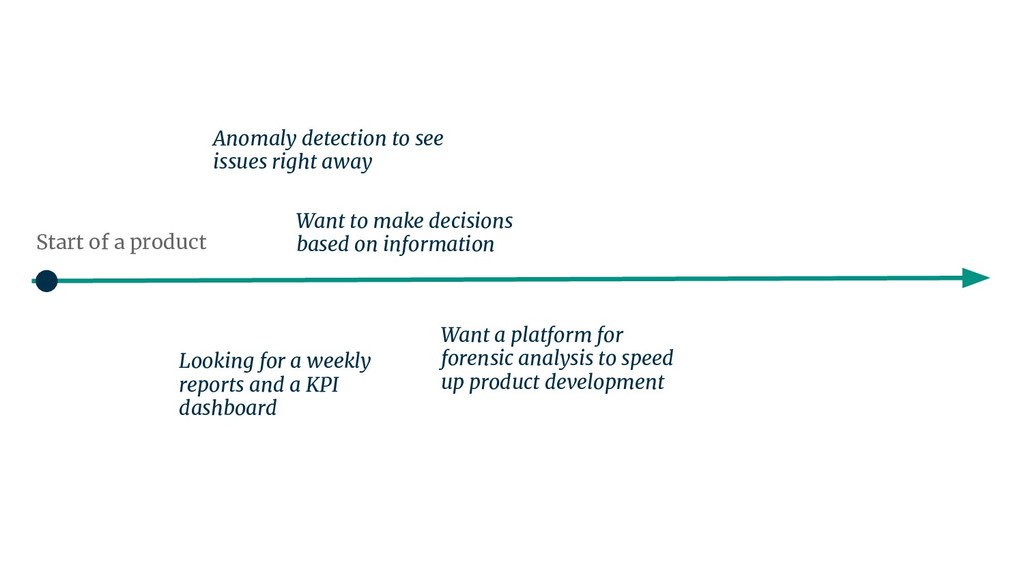{kind=link}
{kind=link}
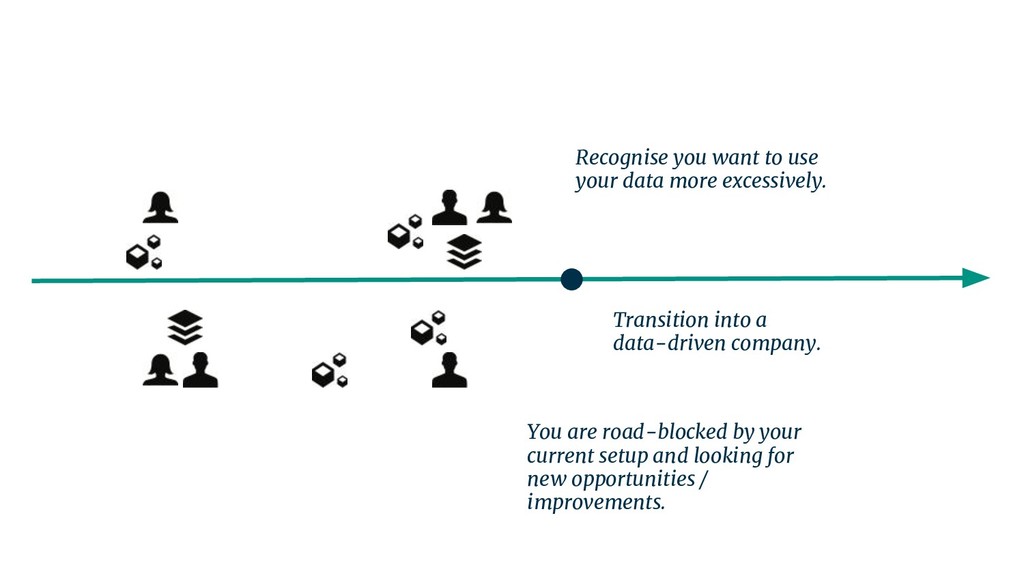{kind=link}
{kind=link}
{kind=link}
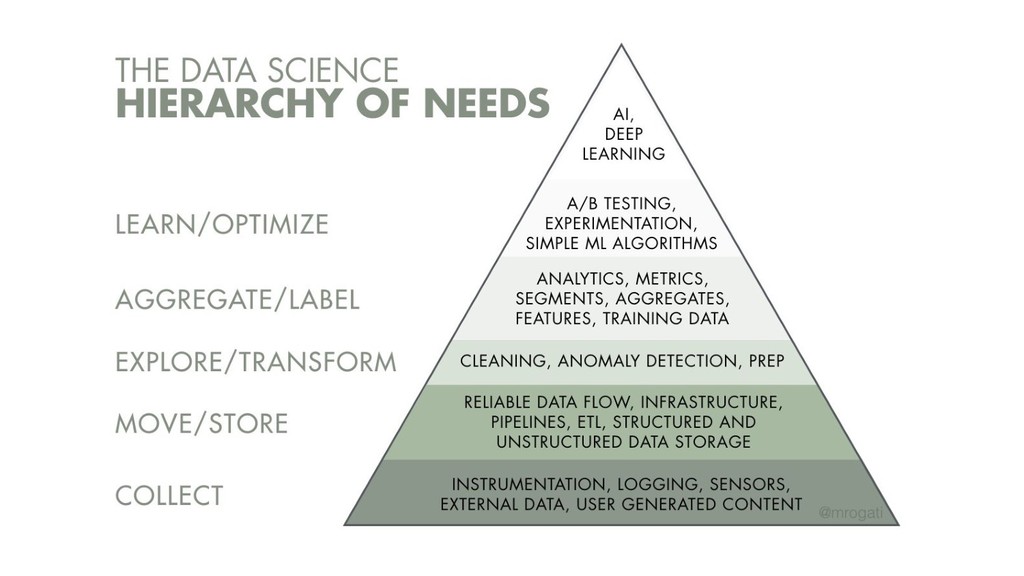{kind=link}
{kind=link}
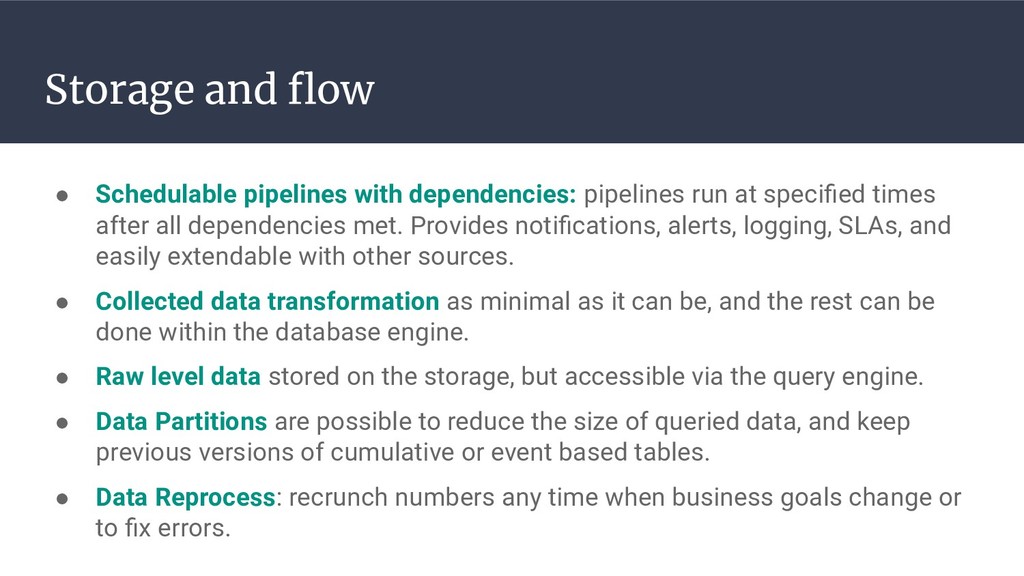{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}