the process of adopting Scala in your organization You want to hear about other people's experience adopting Scala You want to learn about companies using Scala to build cool software solutions
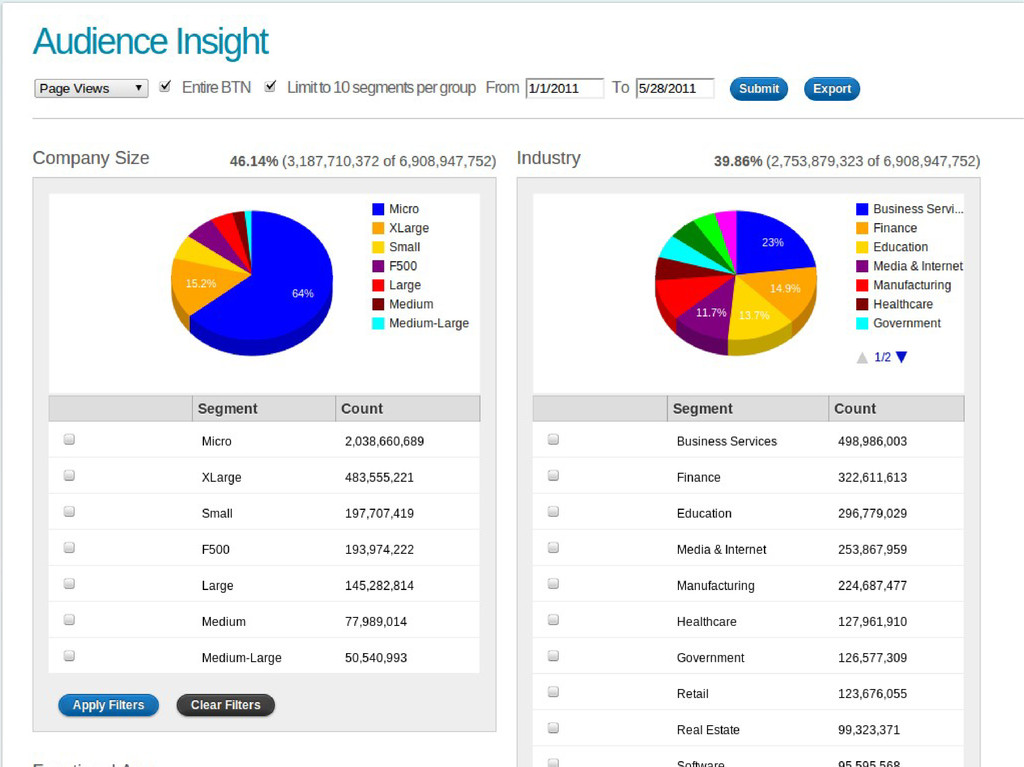
80 million business professionals online • Help better understand composition of web audience • Site personalization, action tracking, custom audiences, funnel analysis, … • And more! Offer many services through web APIs. Classify web visitors into “business demographics” • 150+ industries (agriculture, construction, health care, government, ...) • 100+ functional areas (finance, engineering, legal, sales, ...) • Company size (small, medium, large, F500, …) • Seniority (non-management, mid-management, executive, …) • … location, education, gender, and more.
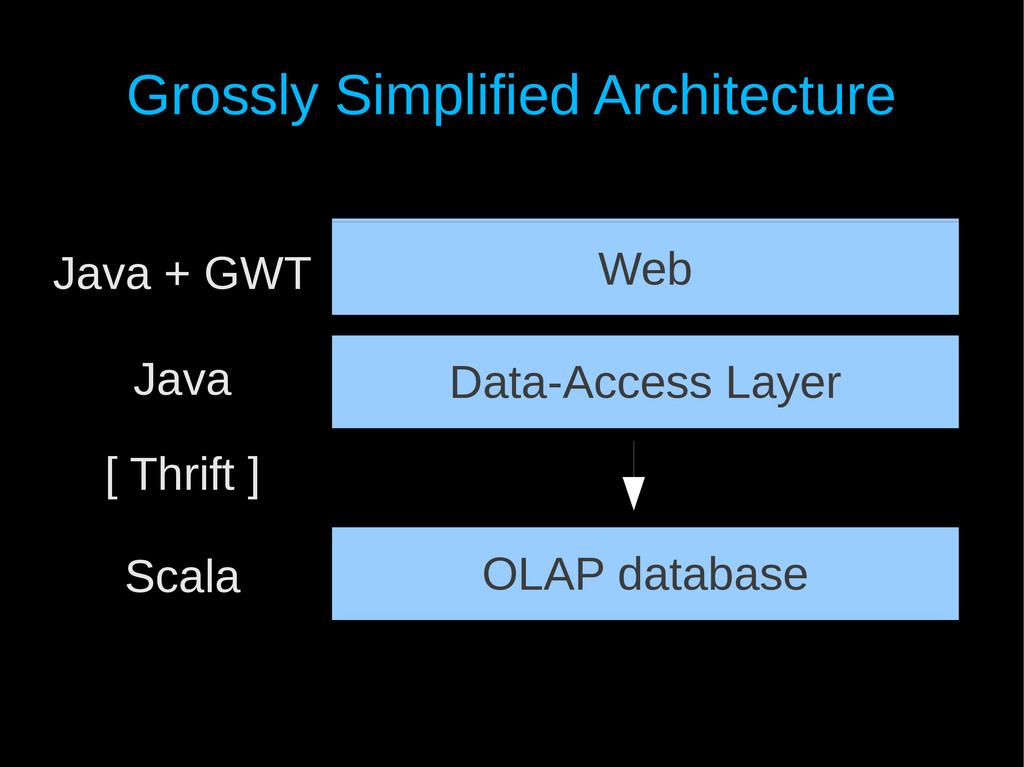
Scala, Ruby, Java, Javascript, … All infrastructure running on Amazon Web Services such as EC2, Elastic Map-Reduce (Hadoop), etc. Started using Scala late in 2009. Scala now used almost everywhere (analytics backend, web APIs, scripts, etc.) except, • Large legacy Java components (will take some time) • Web codebase using Google Web Toolkit (GWT) • Smallish / prototyping-size web apps (Ruby + Rails)
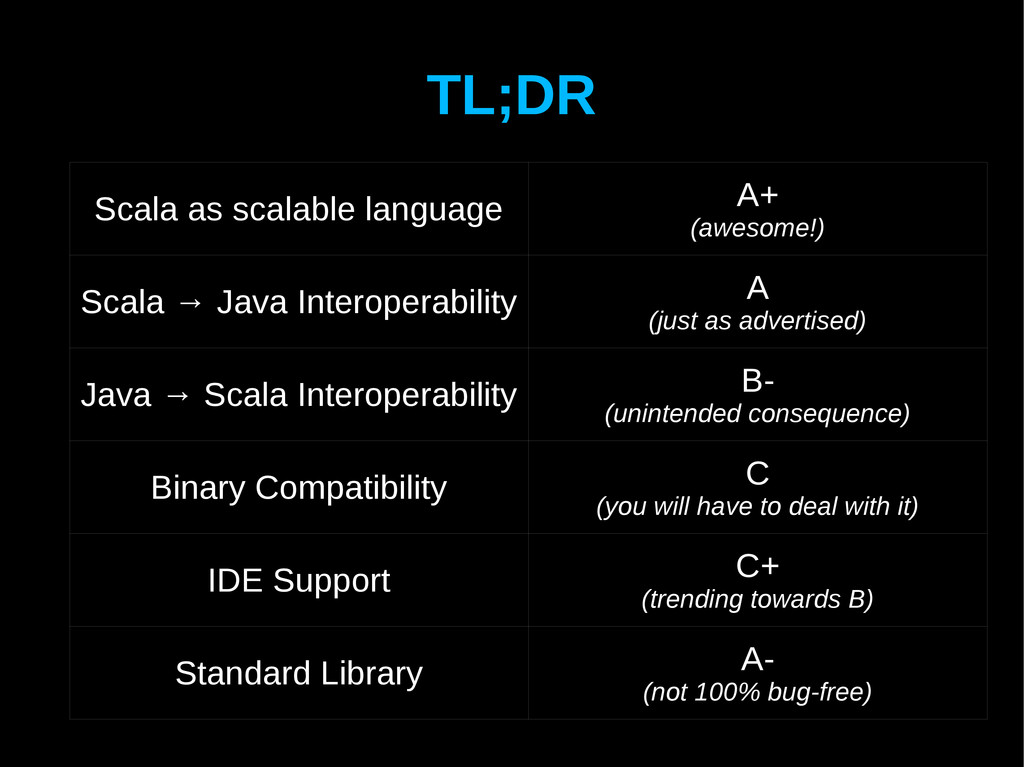
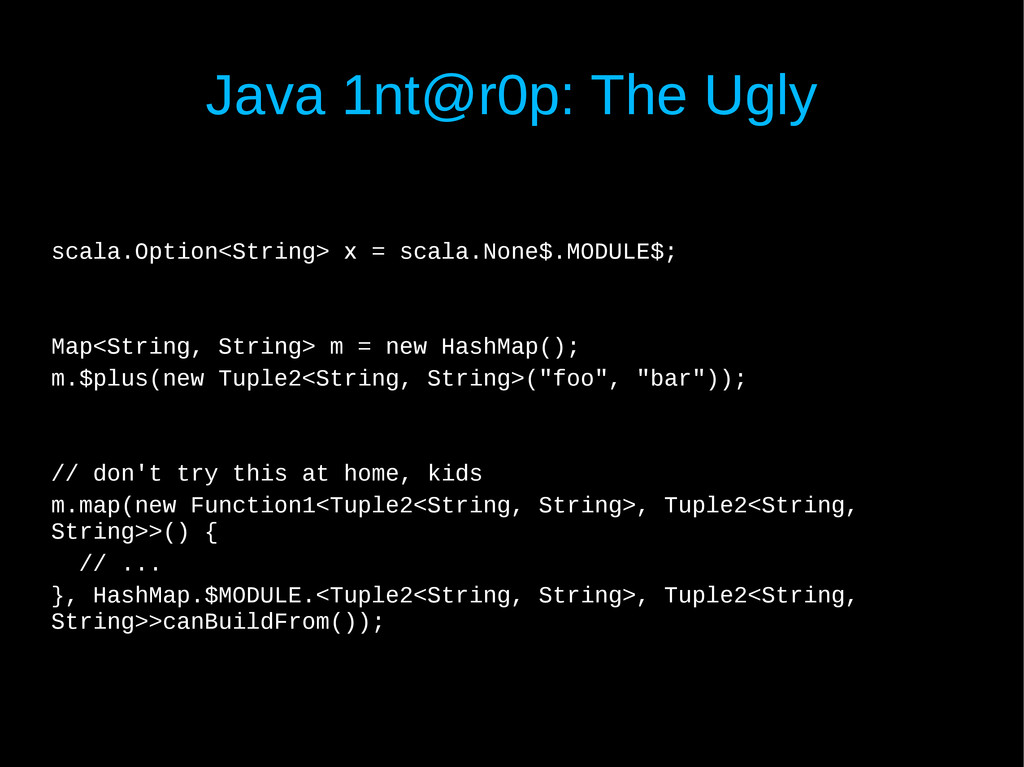
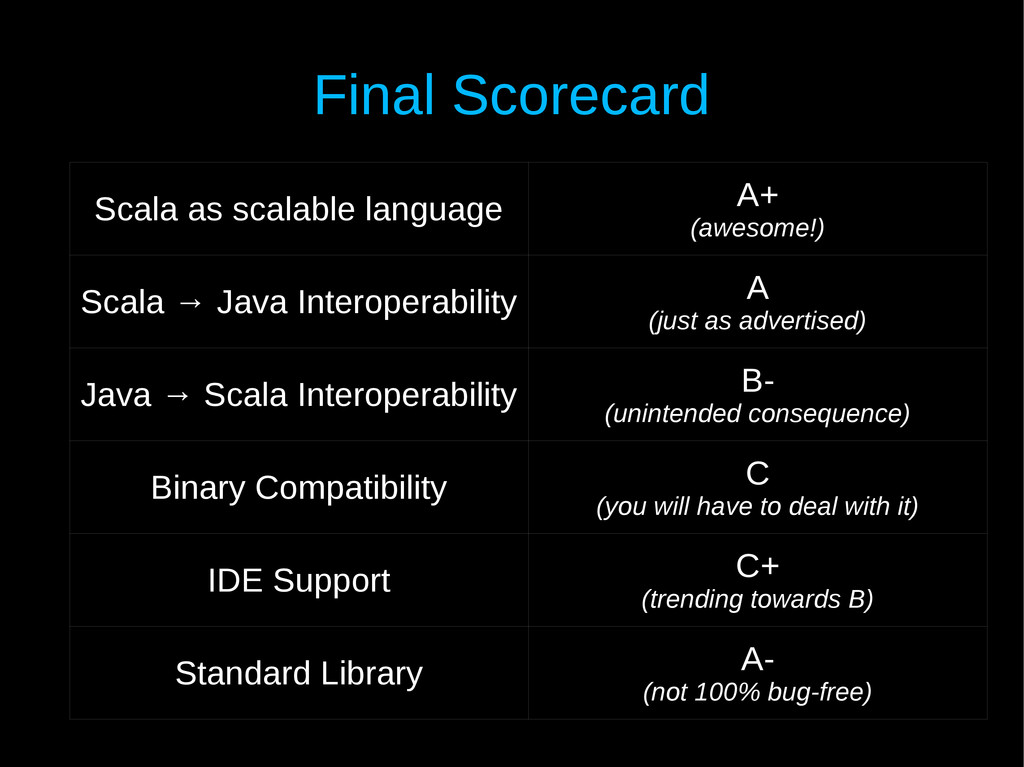
Interoperability A (just as advertised) Java → Scala Interoperability B- (unintended consequence) Binary Compatibility C (you will have to deal with it) IDE Support C+ (trending towards B) Standard Library A- (not 100% bug-free)
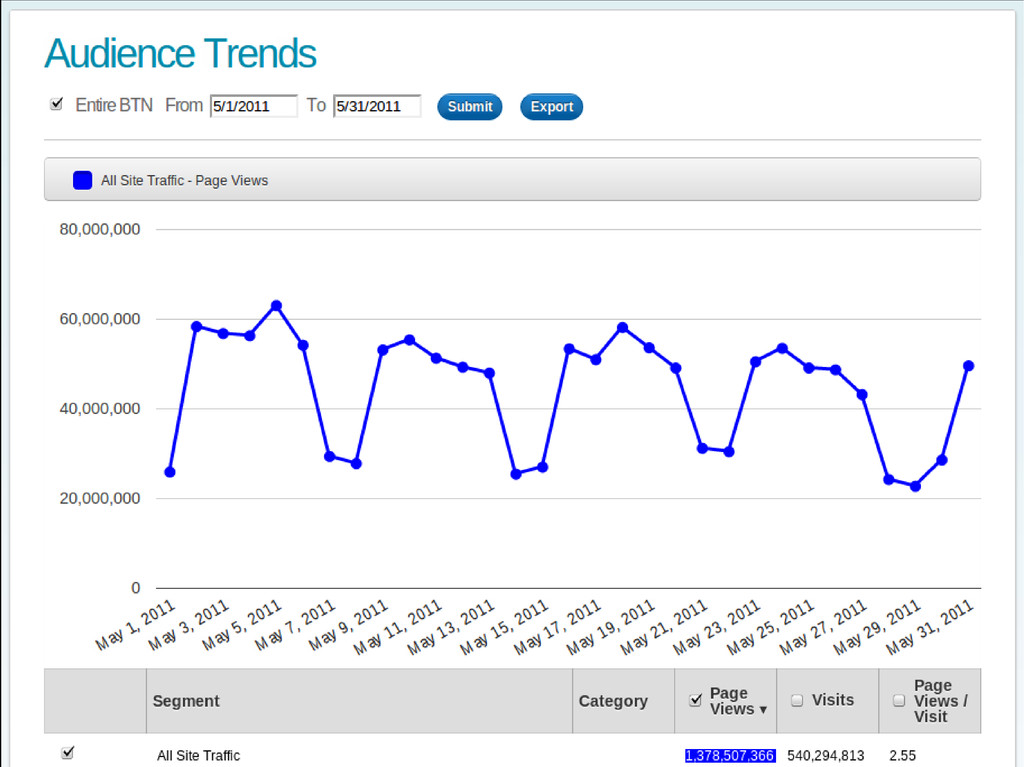
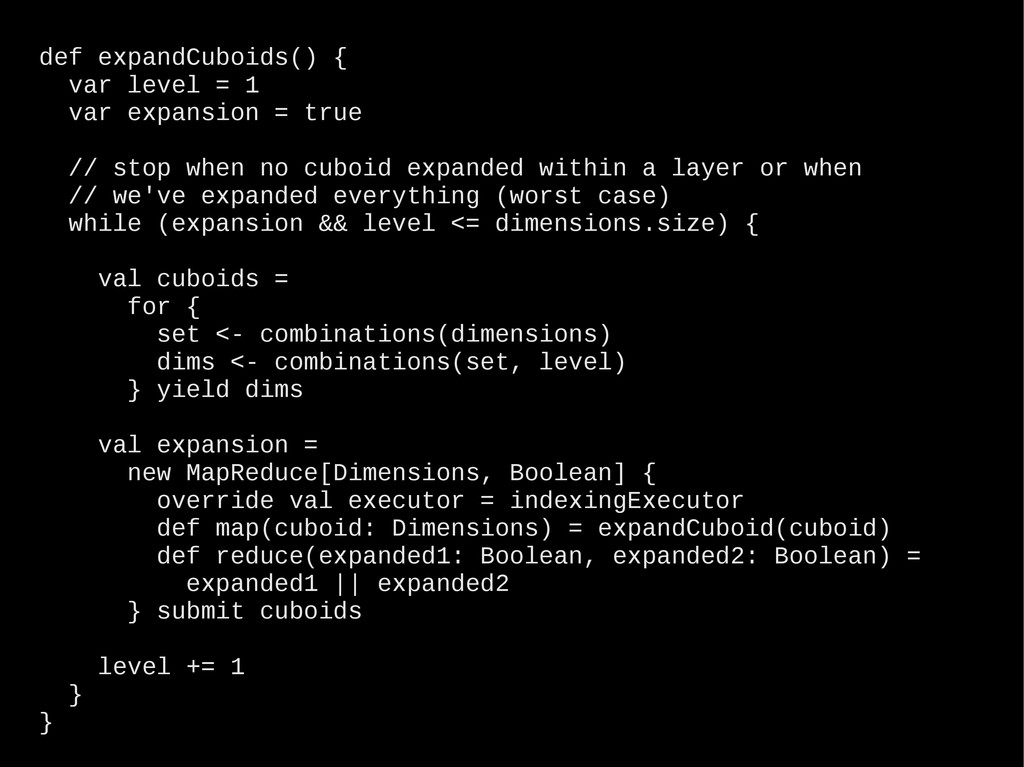
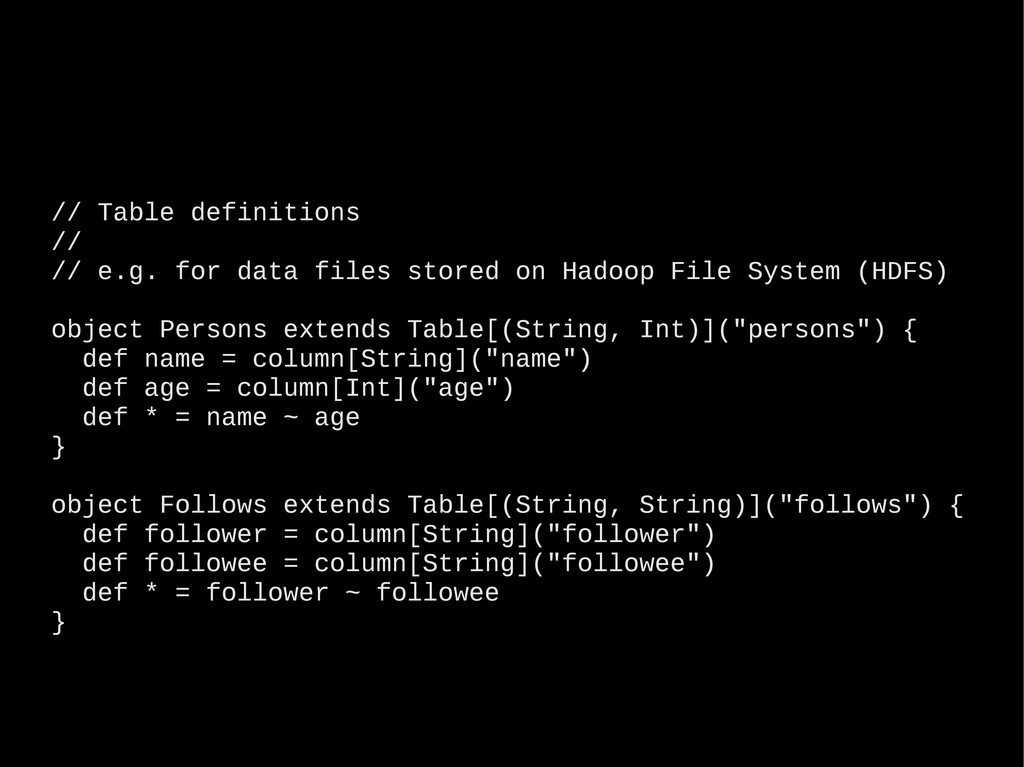
billion web requests per month Data growing at 400% pace year-over-year Use Hadoop + Hive to aggregate web traffic Built “Sugarcube” – a NoSQL analytics database (OLAP) • 100% Scala code + some Java libraries – 20K LoC • Distributed, cloud-friendly (AWS), scale-out architecture • Multi-dimensional indexing of billions of rows with 12+ dimensions • Response time: < 100 ms (for typical queries) • 6 man-months from paper to production (2 prototype iterations) • Server cluster: 4 x m1.large EC2 instances • Indexing cluster: 2 x m2.2xlarge EC2 instances (2-3 hours/day)
is “just another jar” • No special handling compared to 100% Java apps Mix in many Java libraries • Jersey (RESTful web services / JAX-RS) • Apache Common-*, HTTPClient, Log4J/SLF4J, etc. • Thrift, Spring, … and lots more. Still using Ant + Ivy to build most projects!
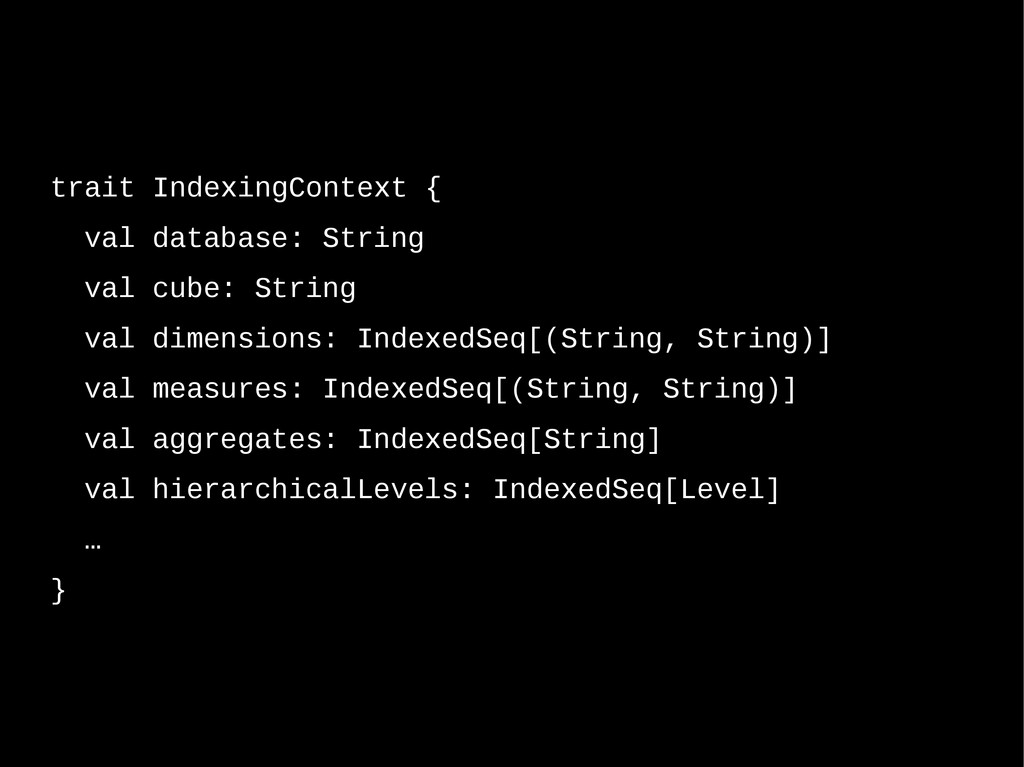
dimensions: IndexedSeq[(String, String)] val measures: IndexedSeq[(String, String)] val aggregates: IndexedSeq[String] val hierarchicalLevels: IndexedSeq[Level] … }
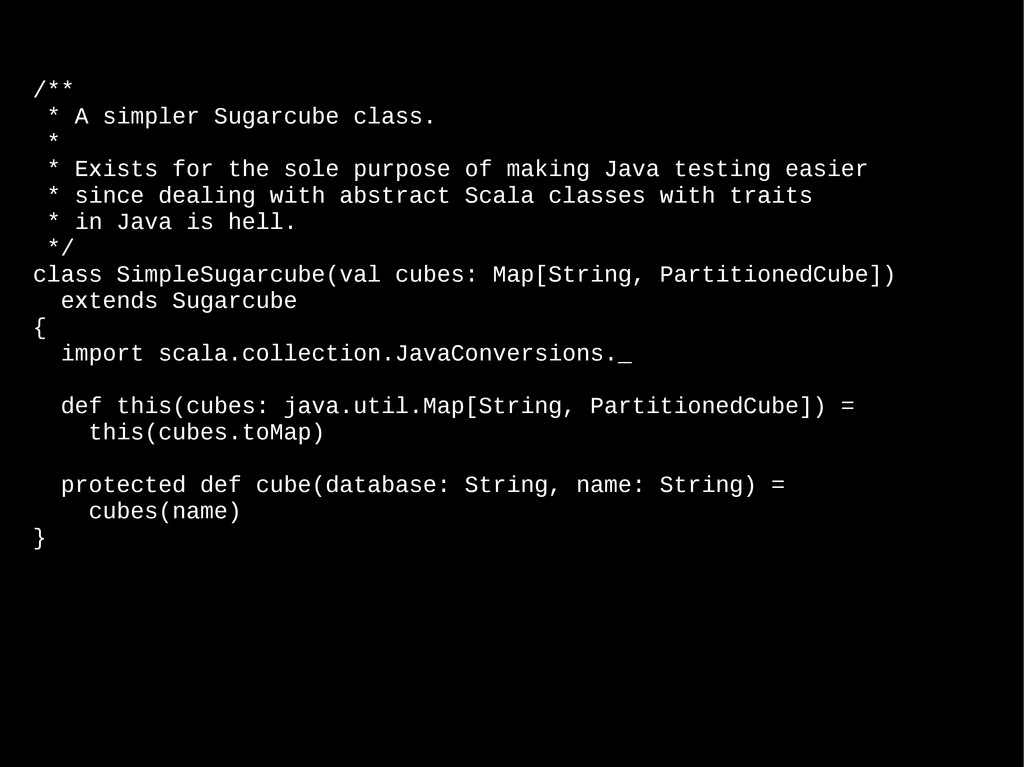
the sole purpose of making Java testing easier * since dealing with abstract Scala classes with traits * in Java is hell. */ class SimpleSugarcube(val cubes: Map[String, PartitionedCube]) extends Sugarcube { import scala.collection.JavaConversions._ def this(cubes: java.util.Map[String, PartitionedCube]) = this(cubes.toMap) protected def cube(database: String, name: String) = cubes(name) }
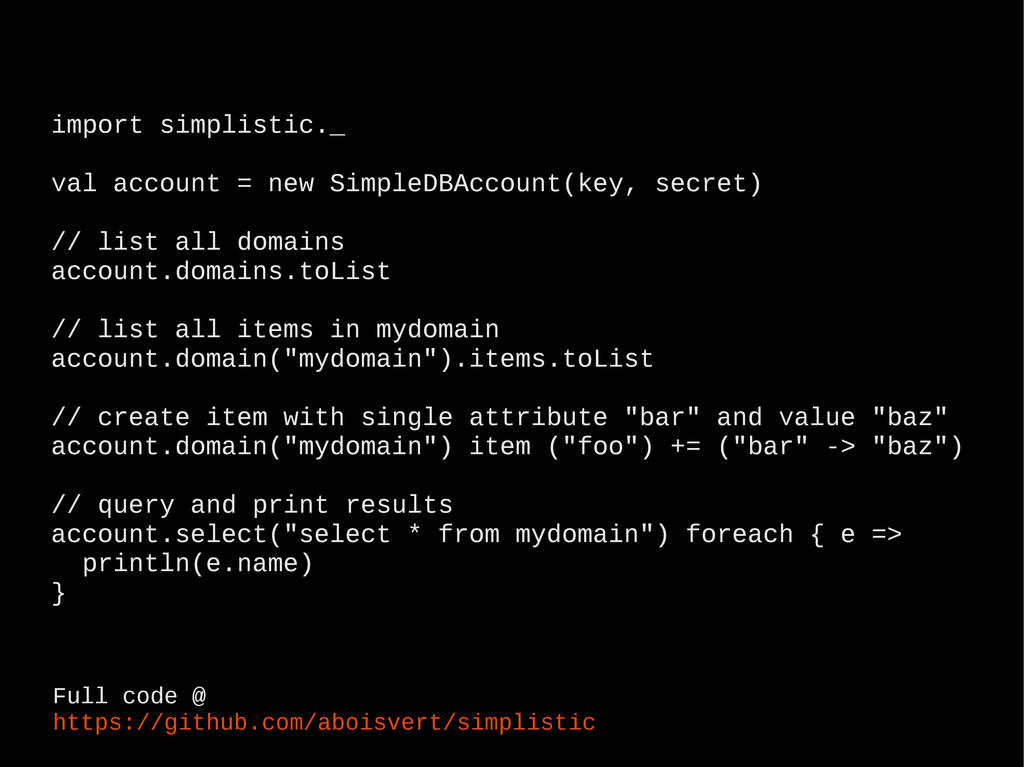
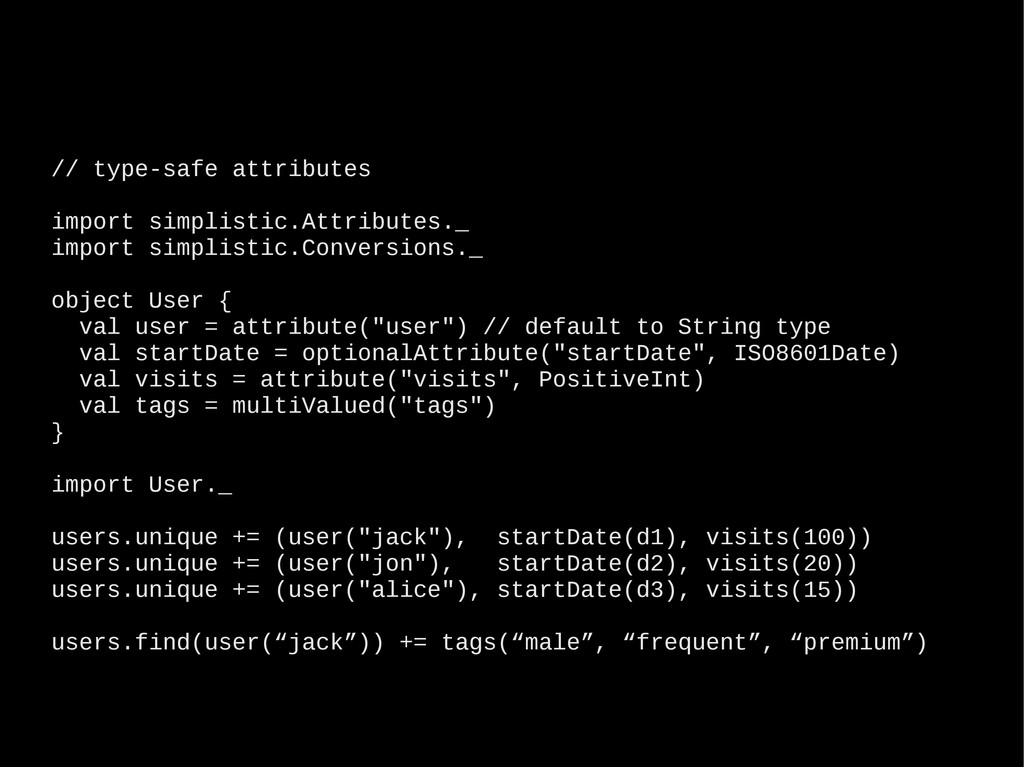
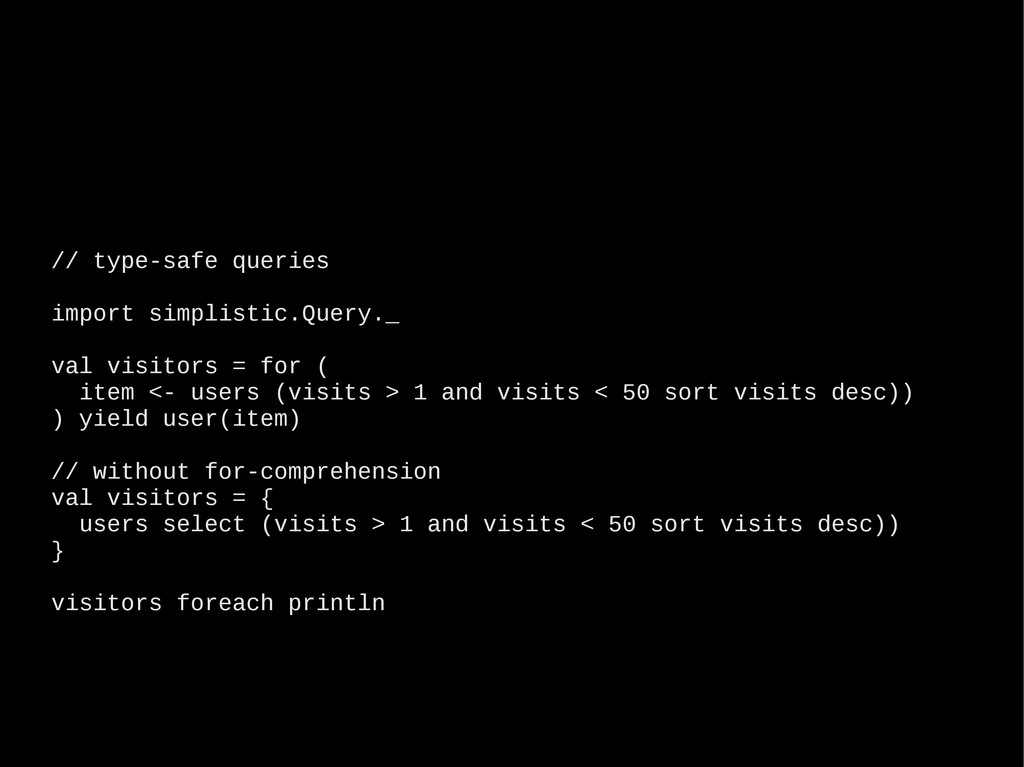
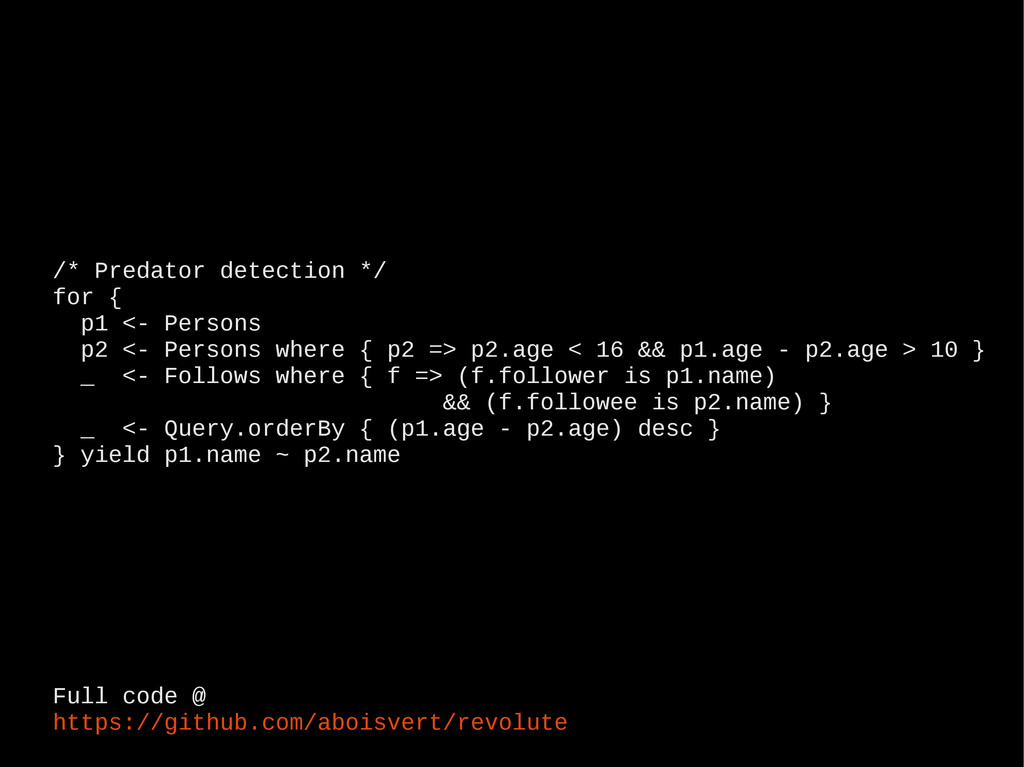
all domains account.domains.toList // list all items in mydomain account.domain("mydomain").items.toList // create item with single attribute "bar" and value "baz" account.domain("mydomain") item ("foo") += ("bar" -> "baz") // query and print results account.select("select * from mydomain") foreach { e => println(e.name) } Full code @ https://github.com/aboisvert/simplistic
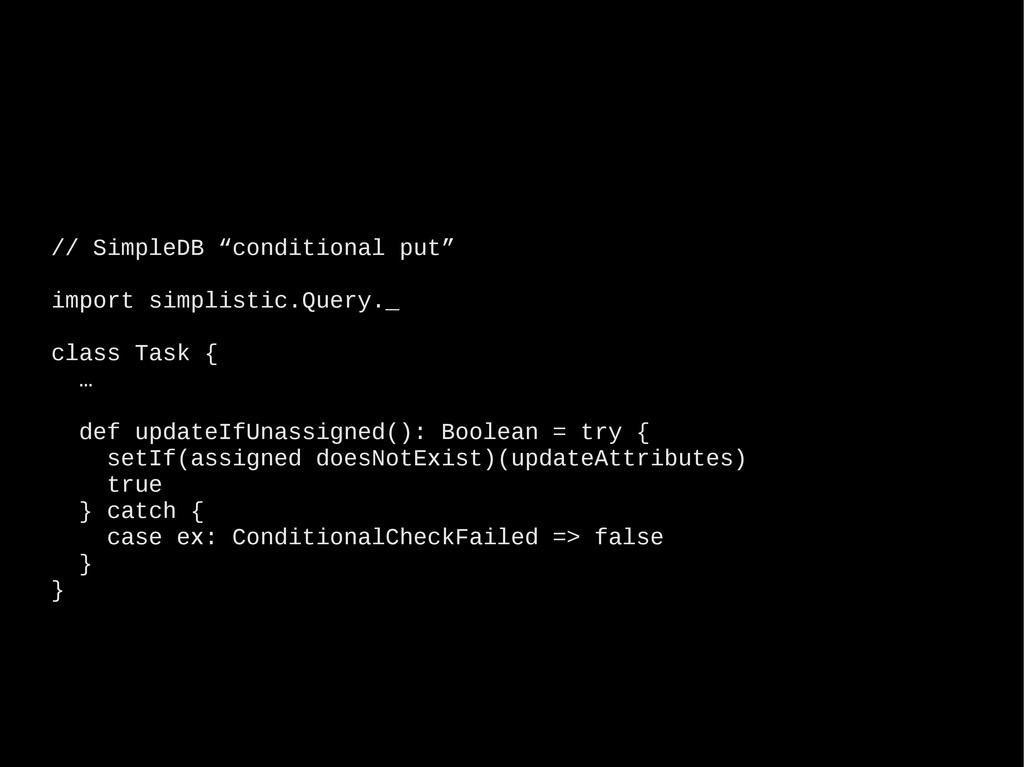
bugs :-( • 2.8.1: NoSuchElementException in HashSet (issue with hash-code collisions) • 2.9.0: View.groupBy() broken (StackOverflowException) Scala releases are few and far between … How will you deal with situation? • Avoid the feature • Build your own • Fix it yourself • Buy support from Typesafe We decided to maintain patched version of standard library.
Java Interoperability A (just as advertised) Java → Scala Interoperability B- (unintended consequence) Binary Compatibility C (you will have to deal with it) IDE Support C+ (trending towards B) Standard Library A- (not 100% bug-free)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![trait MapReduce[Input, Output] { val executor: ExecutorService = { /*](https://files.speakerdeck.com/presentations/4fd73bd6824fa0002101dcc6/slide_23.jpg){kind=link}
{kind=link}
![trait PartitionedCube { … def query( aggregates: Set[Aggregate], conditions: Map[Dimension,](https://files.speakerdeck.com/presentations/4fd73bd6824fa0002101dcc6/slide_25.jpg){kind=link}
(f: T](https://files.speakerdeck.com/presentations/4fd73bd6824fa0002101dcc6/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Twitter: @boia01 Email: [email protected] / [email protected] Pssst! We're hiring!](https://files.speakerdeck.com/presentations/4fd73bd6824fa0002101dcc6/slide_39.jpg){kind=link}