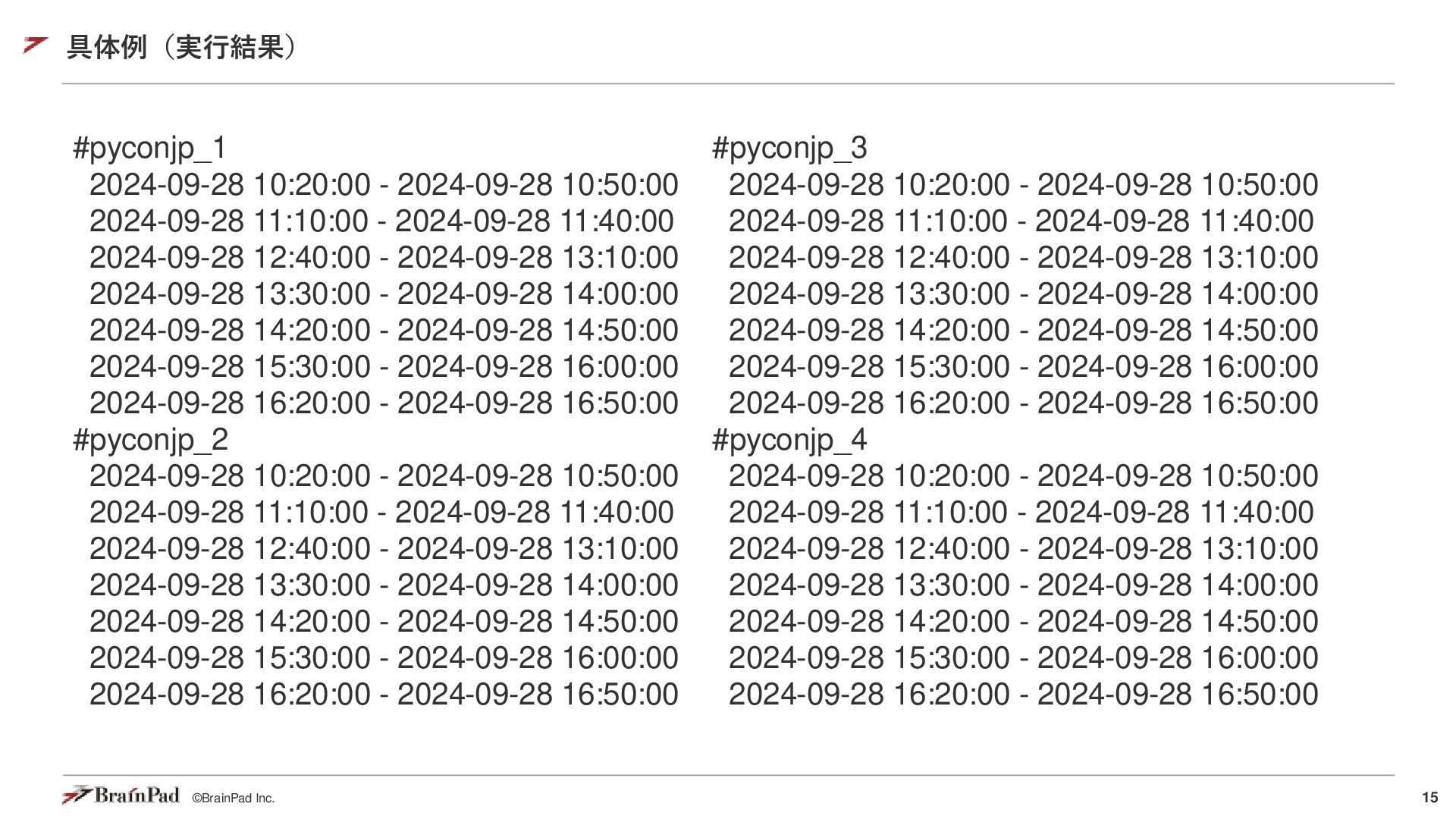
9, 28, 10, 20) end_time = datetime(2024, 9, 28, 17, 00) break_times = [(datetime(2024, 9, 28, 11, 40), datetime(2024, 9, 28, 12, 40)), (datetime(2024, 9, 28, 14, 50), datetime(2024, 9, 28, 15, 30))] slot_length = timedelta(minutes=30) transition_length = timedelta(minutes=20) lines = [Track(f"#pyconjp_{i}", []) for i in range(1, 5)] current_time = start_time while current_time + slot_length <= end_time: if any(start <= current_time < end for start, end in break_times): current_time = max(end for start, end in break_times if start <= current_time < end) else: for line in lines: line.presentations.append(Schedule(current_time, current_time + slot_length)) current_time += slot_length + transition_length return lines 具体例: PyConJP タイムテーブル生成 生成されたコード(Gemini 1.5 Proを利用) 中間コード
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
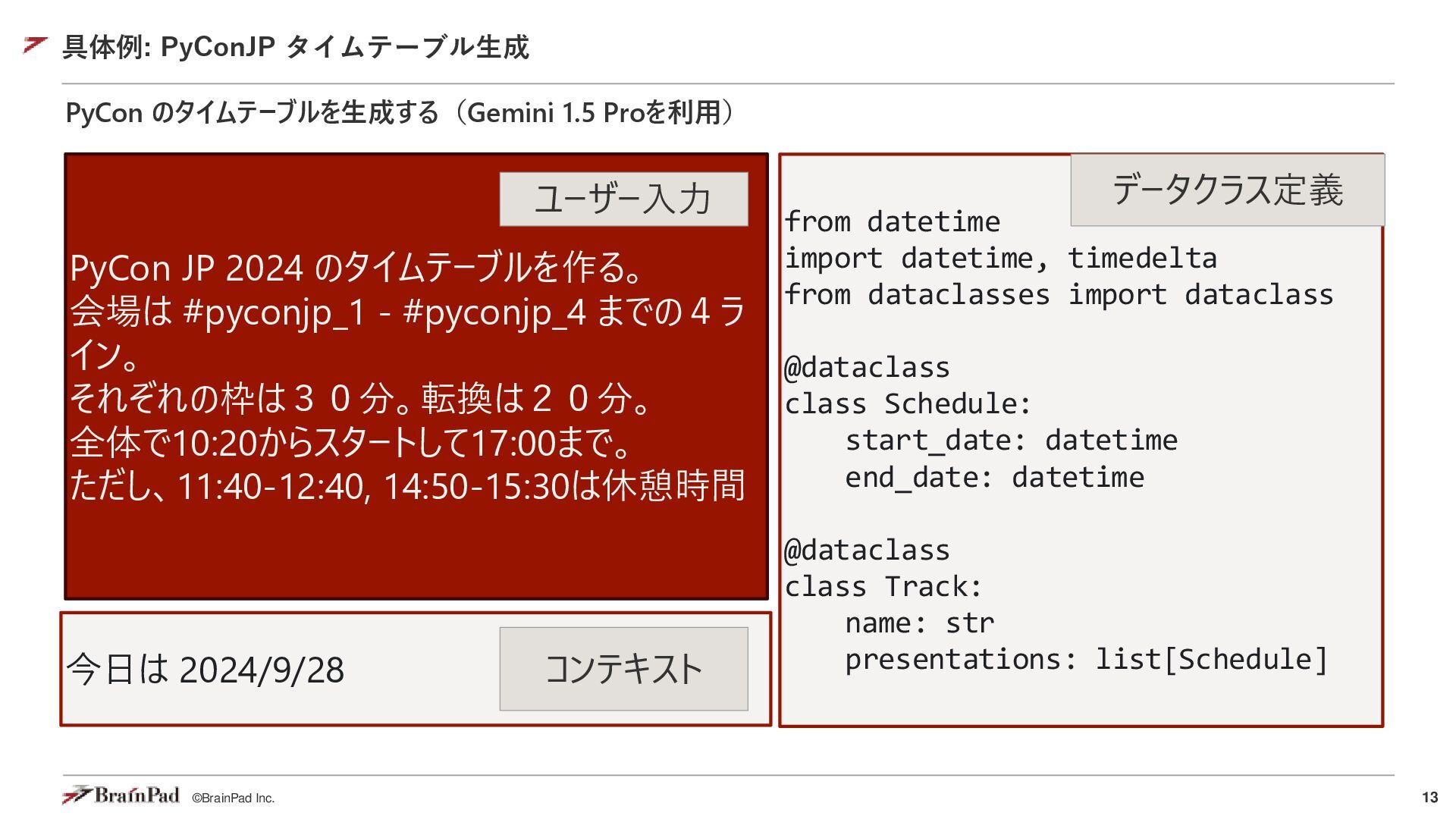{kind=link}
![14 ©BrainPad Inc. def generate_timetable() -> list[Track]: start_time = datetime(2024,](https://files.speakerdeck.com/presentations/5611881887e94ab19953b9eaf60daf7d/slide_13_1742211224.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
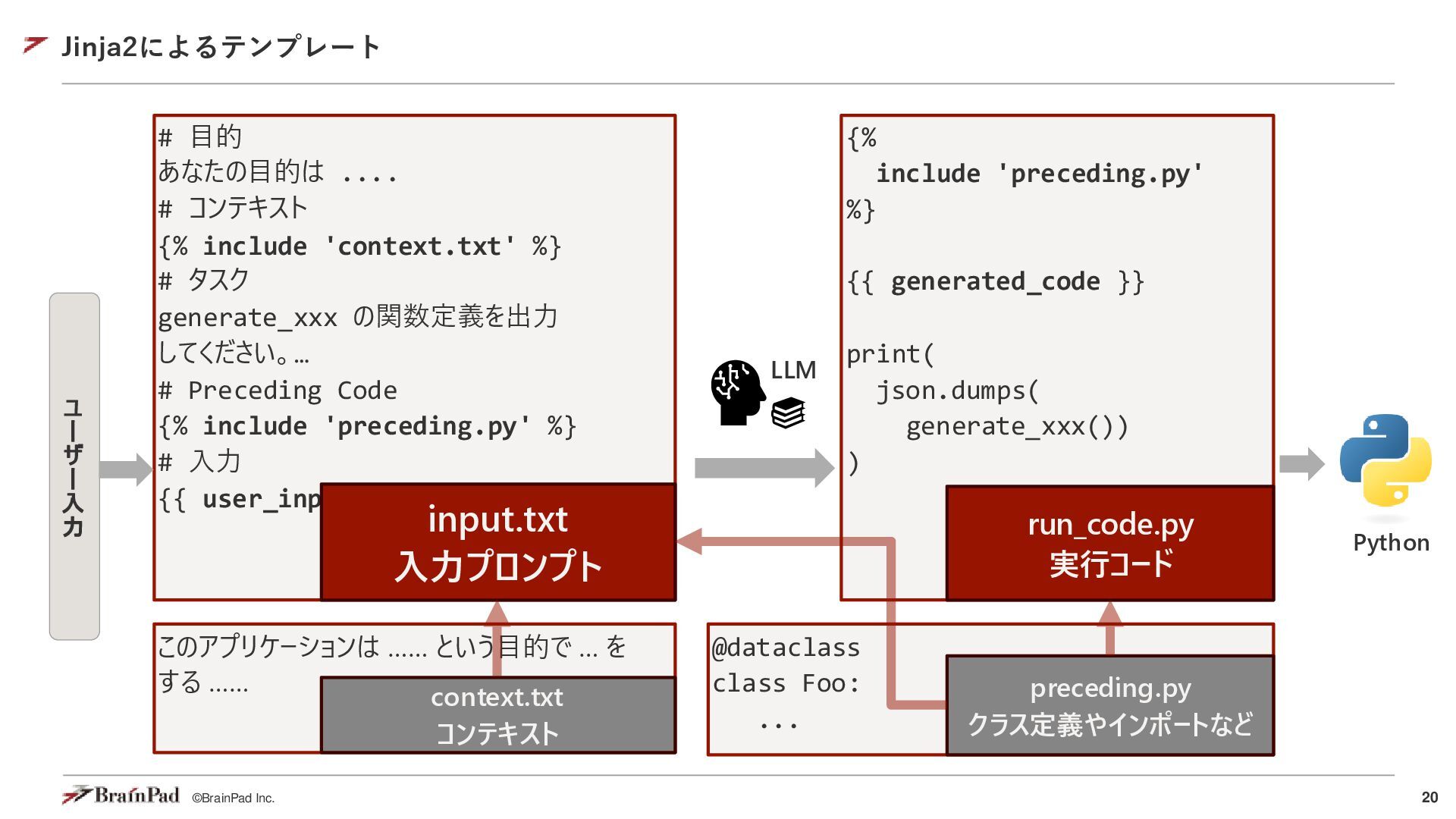{kind=link}
{kind=link}
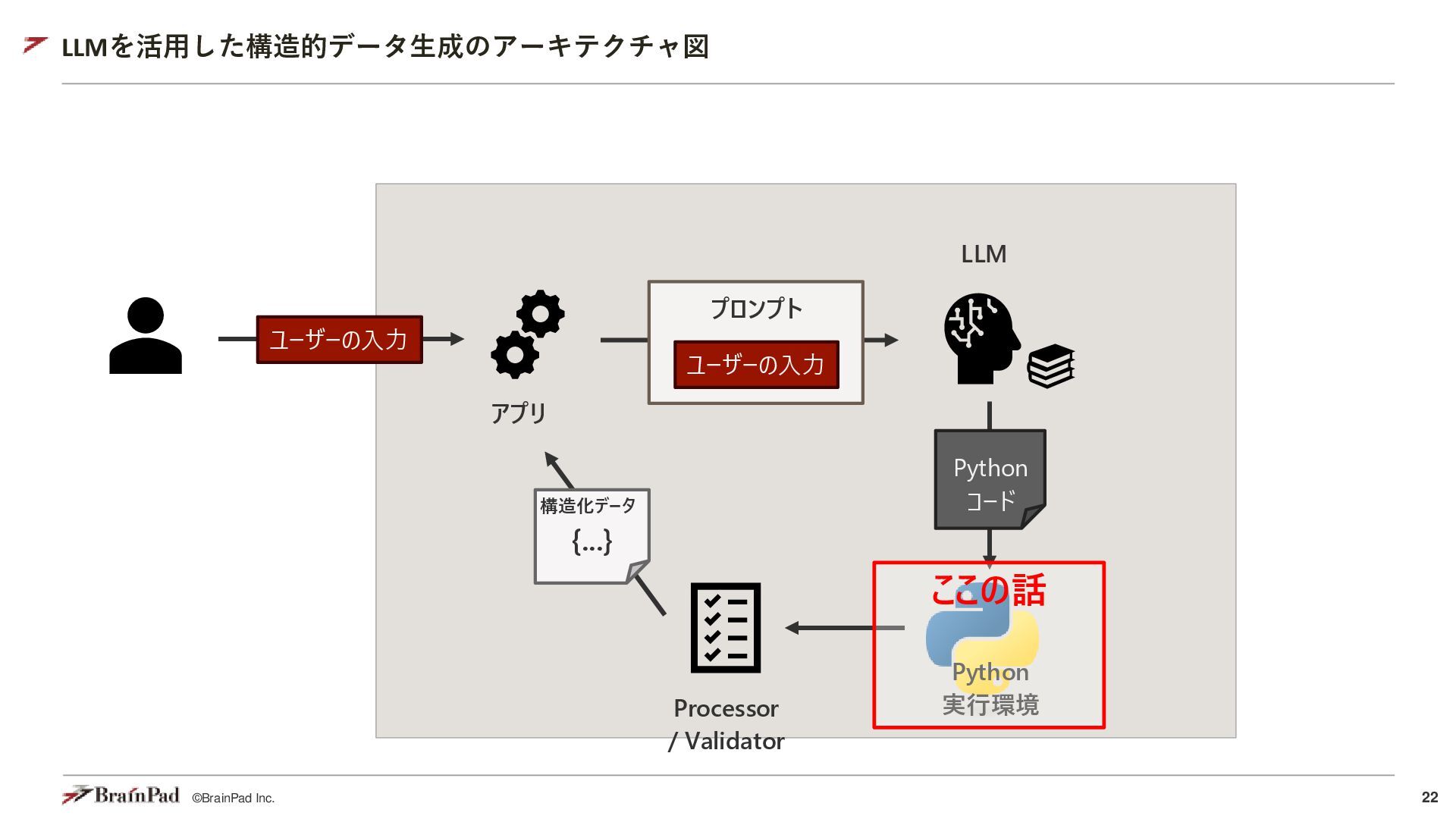{kind=link}
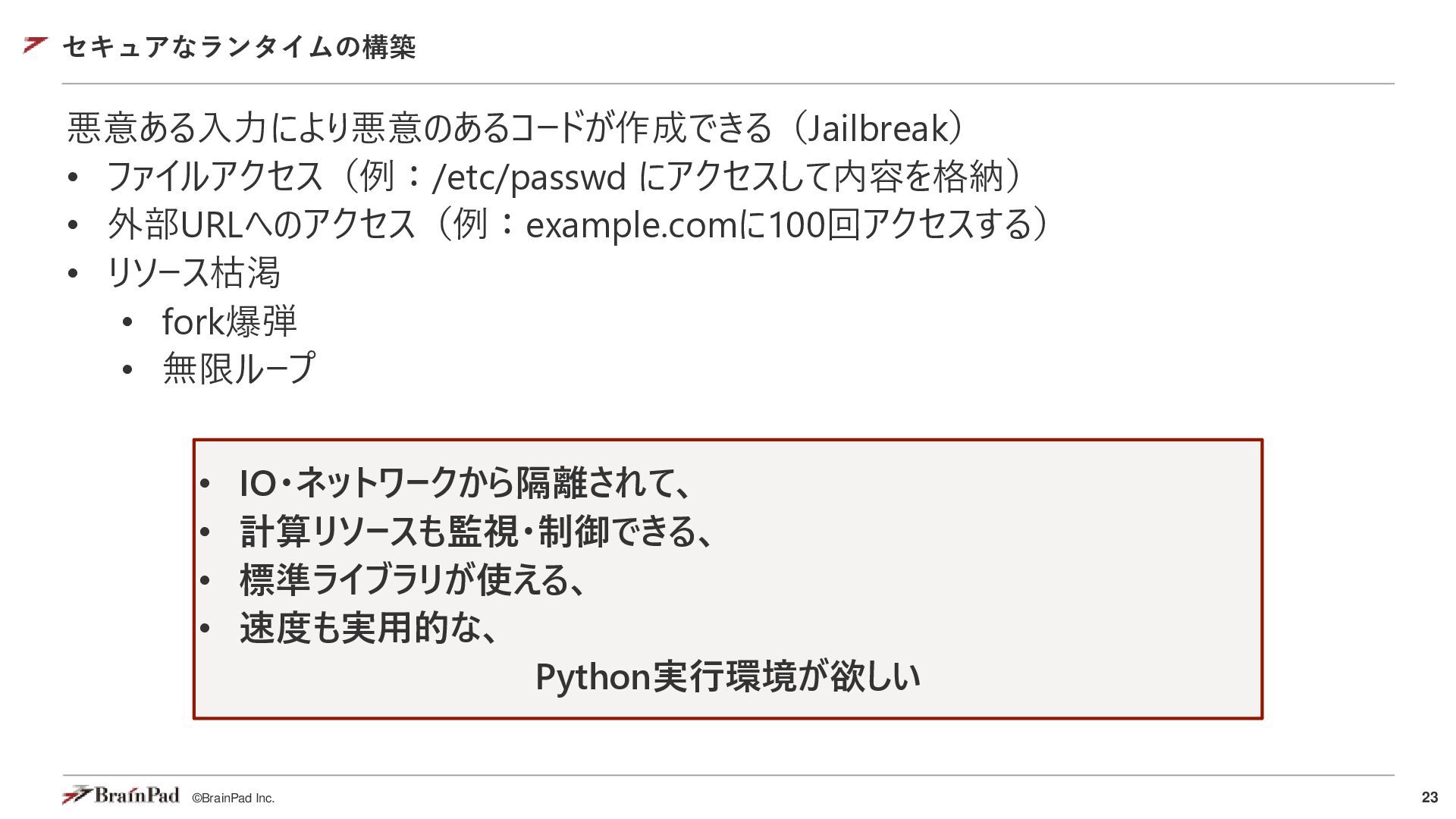{kind=link}
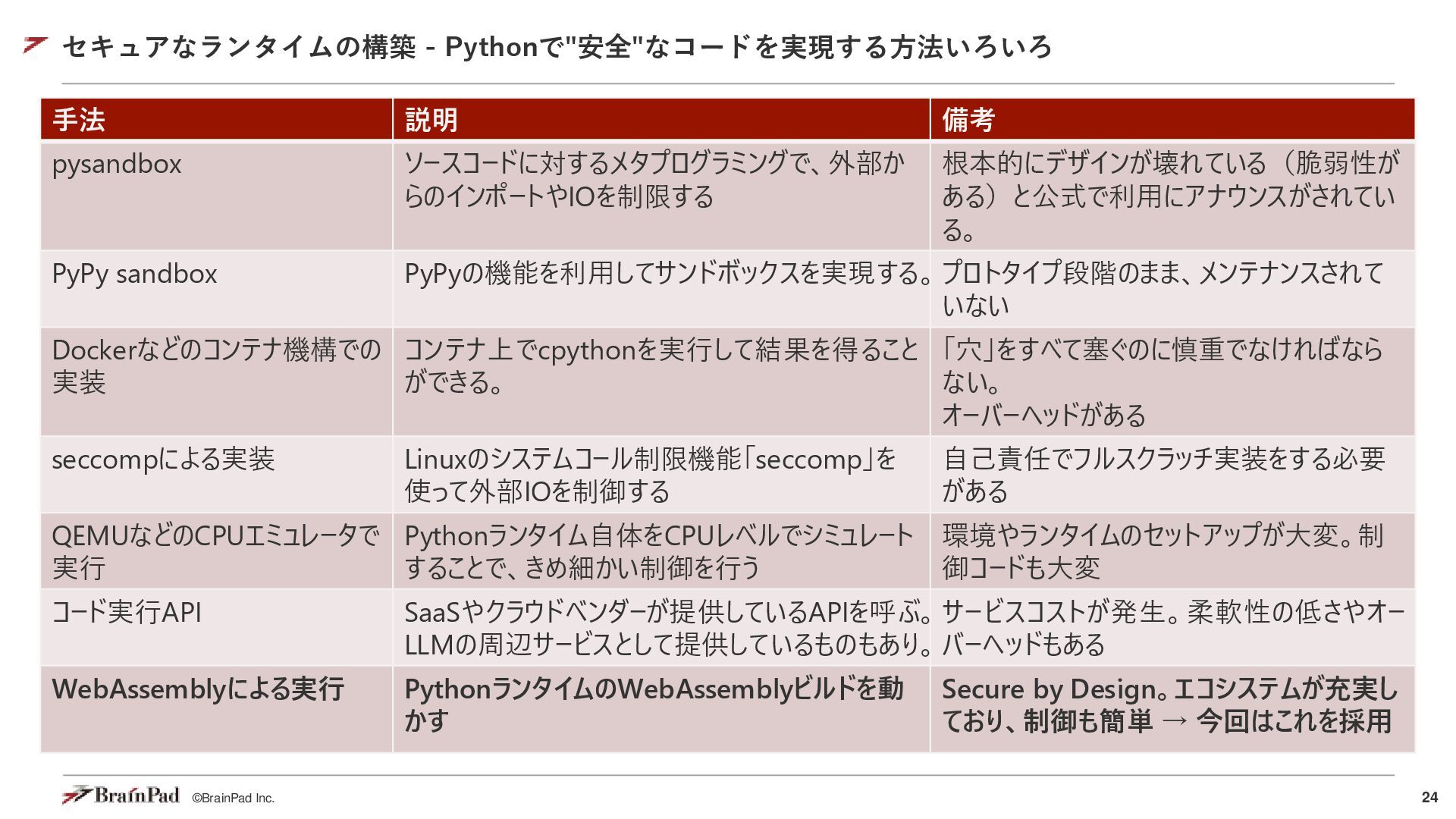{kind=link}
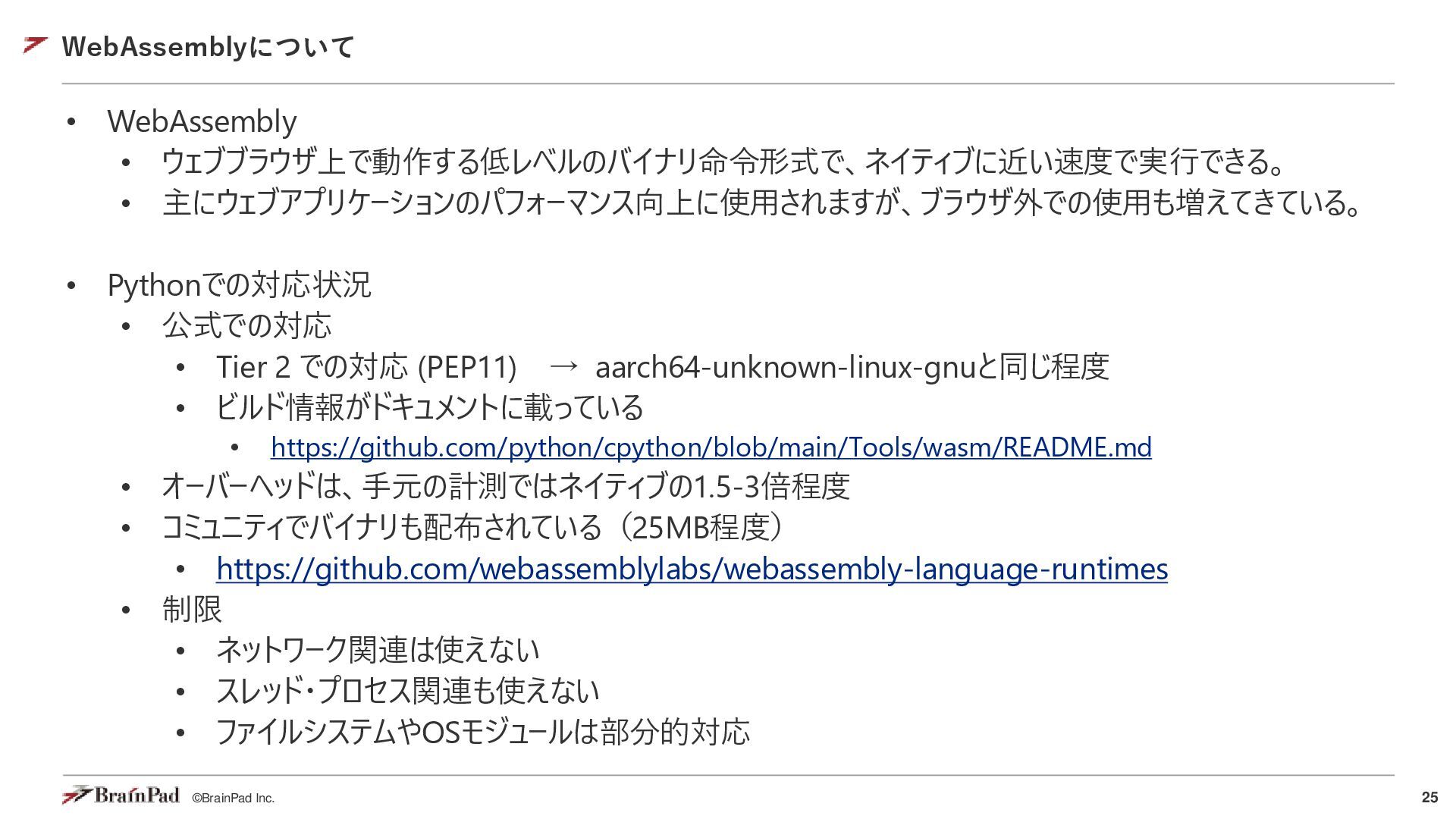{kind=link}
{kind=link}
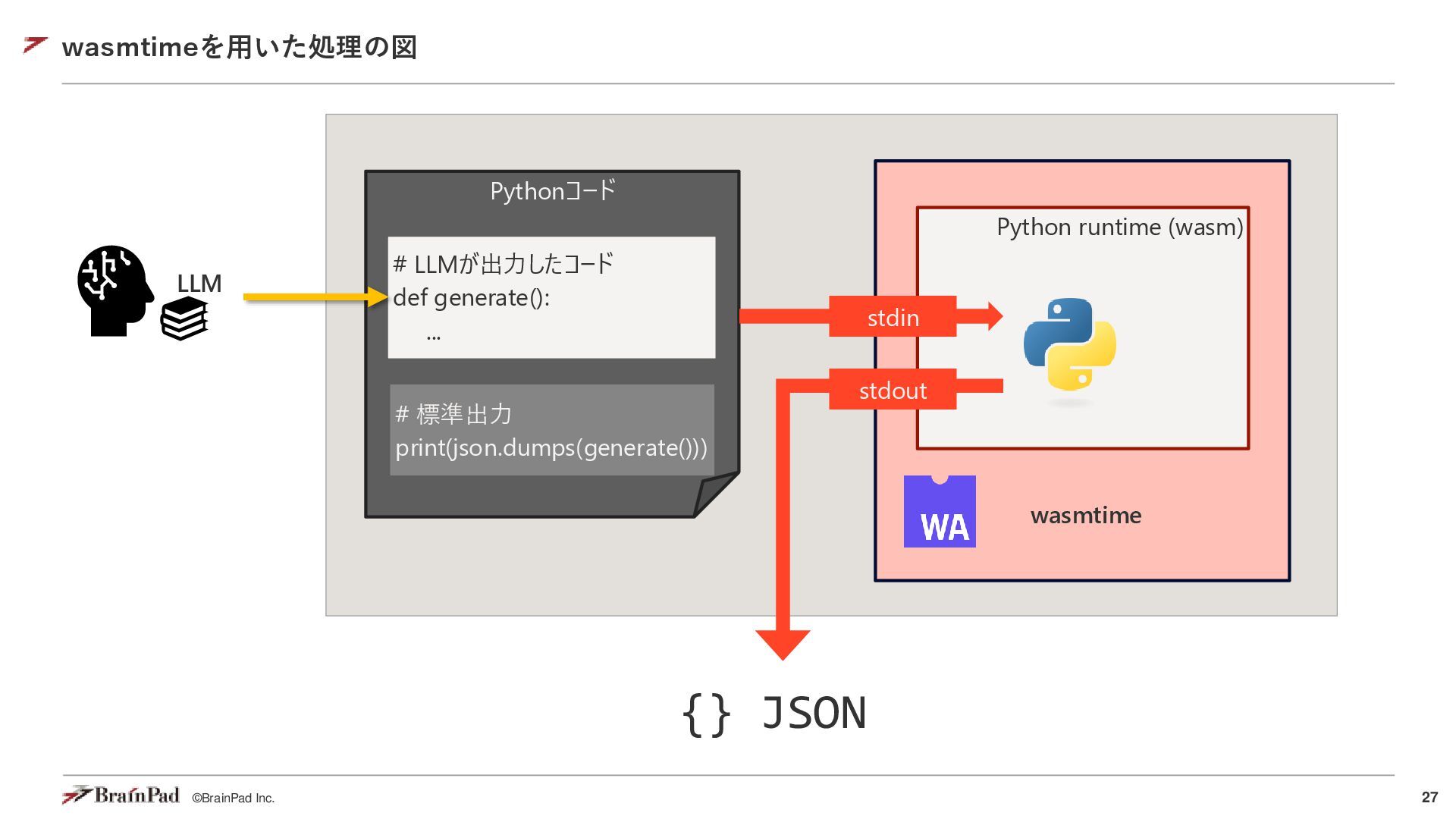{kind=link}
{kind=link}
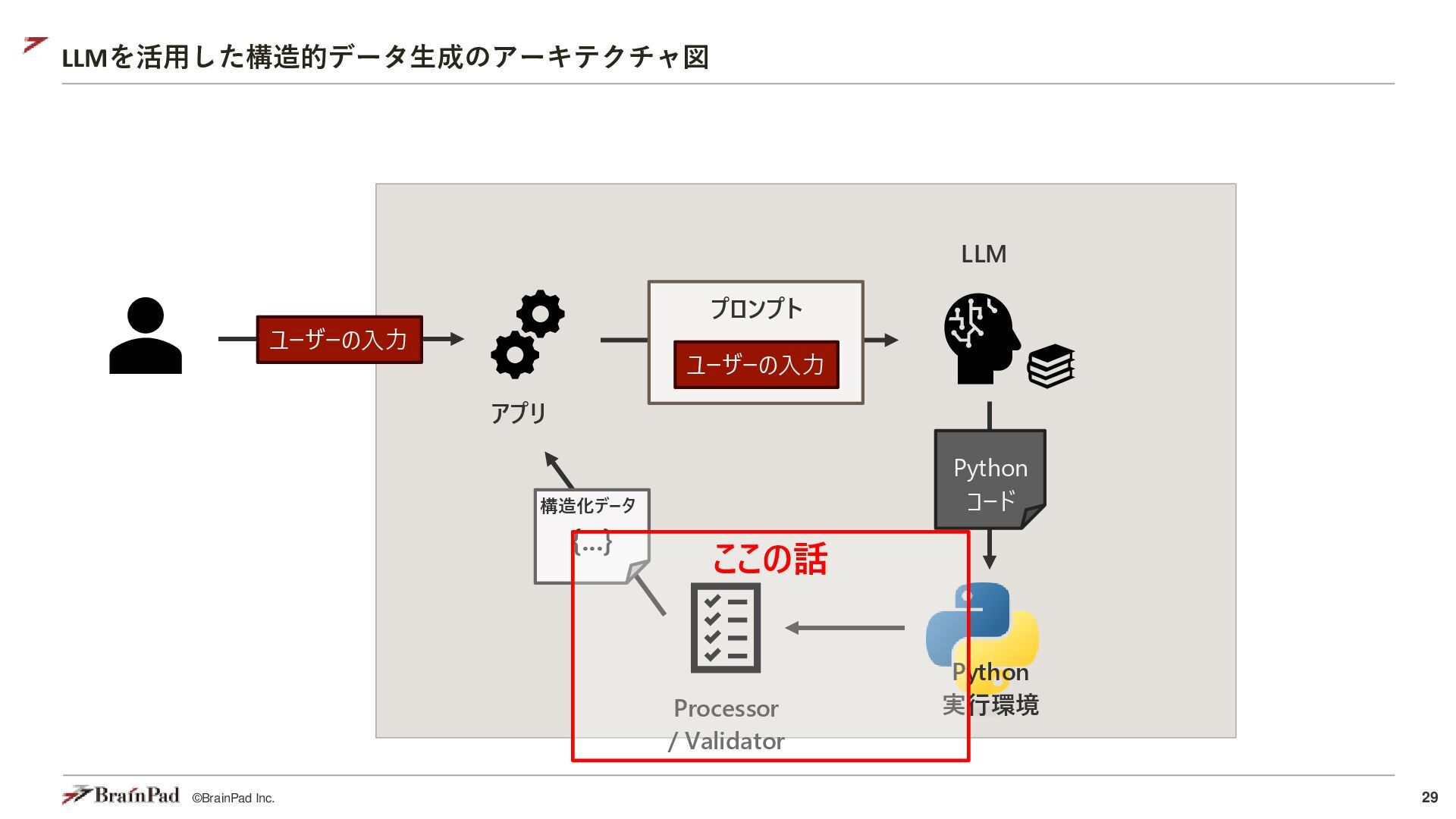{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
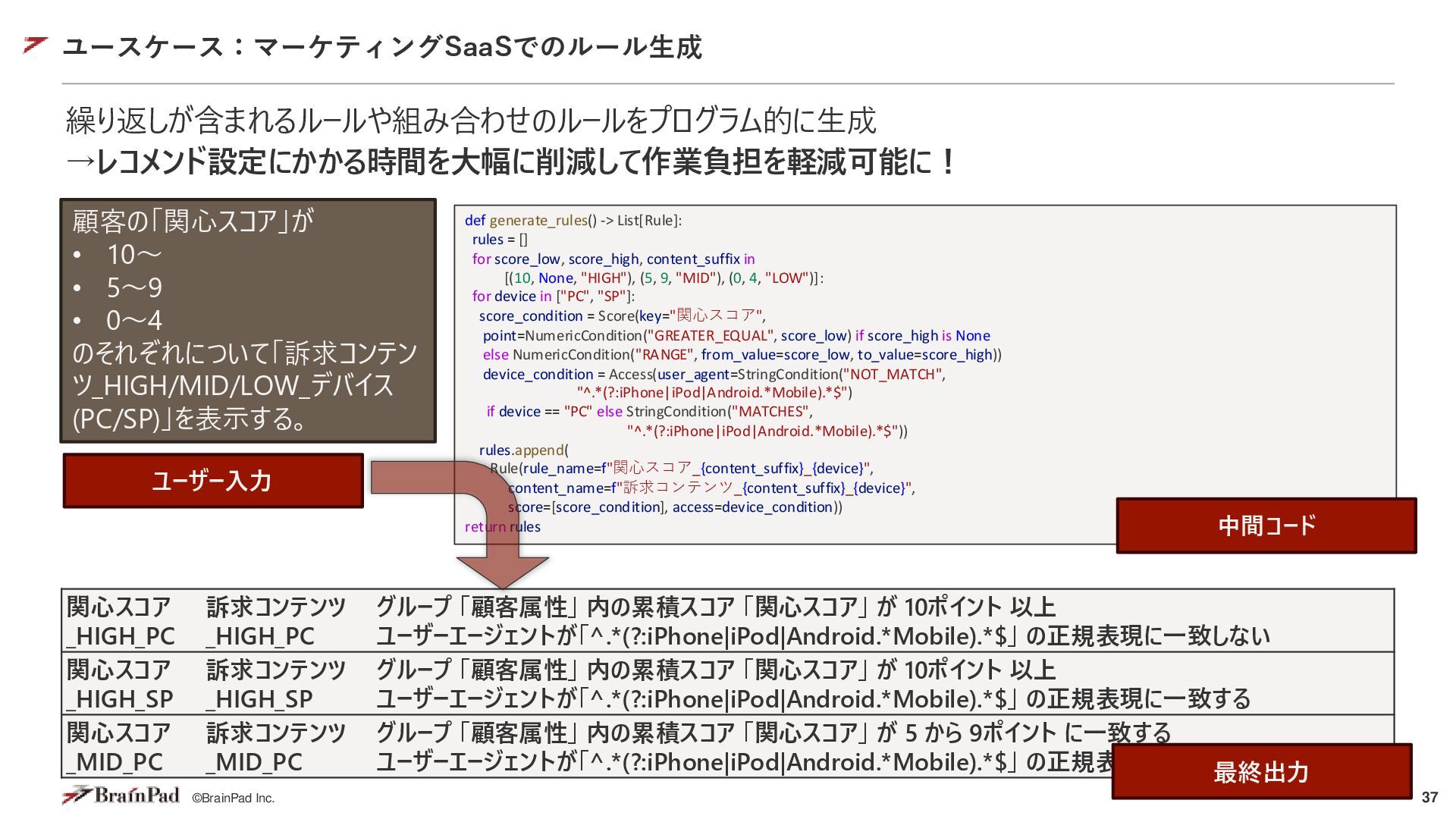{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}