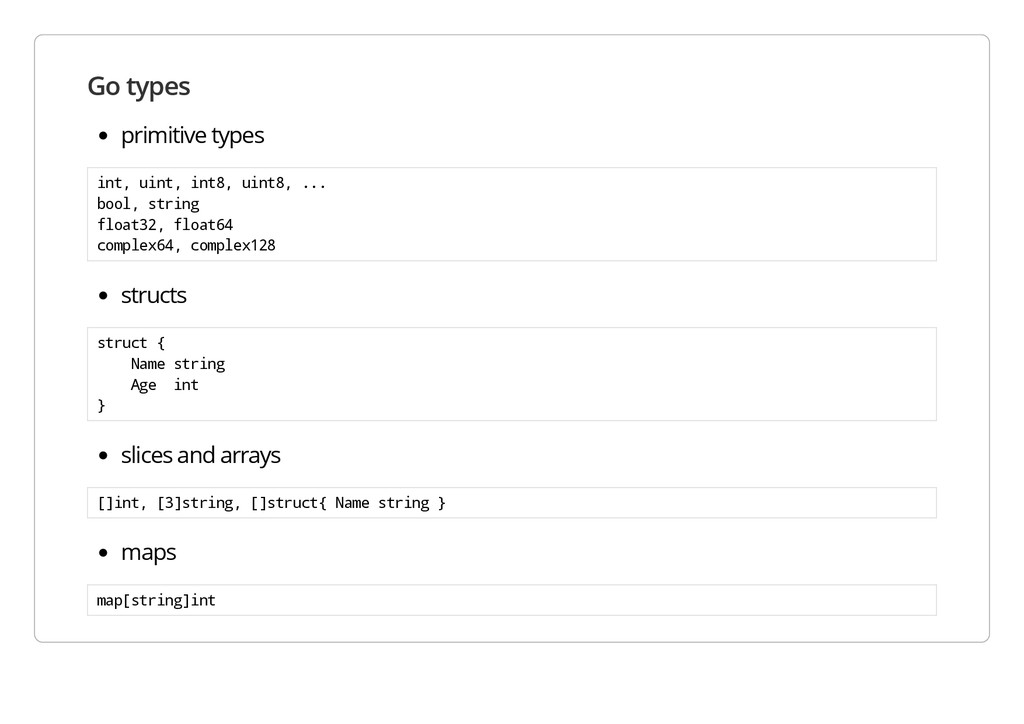
n t , i n t 8 , u i n t 8 , . . . b o o l , s t r i n g f l o a t 3 2 , f l o a t 6 4 c o m p l e x 6 4 , c o m p l e x 1 2 8 structs s t r u c t { N a m e s t r i n g A g e i n t } slices and arrays [ ] i n t , [ 3 ] s t r i n g , [ ] s t r u c t { N a m e s t r i n g } maps m a p [ s t r i n g ] i n t
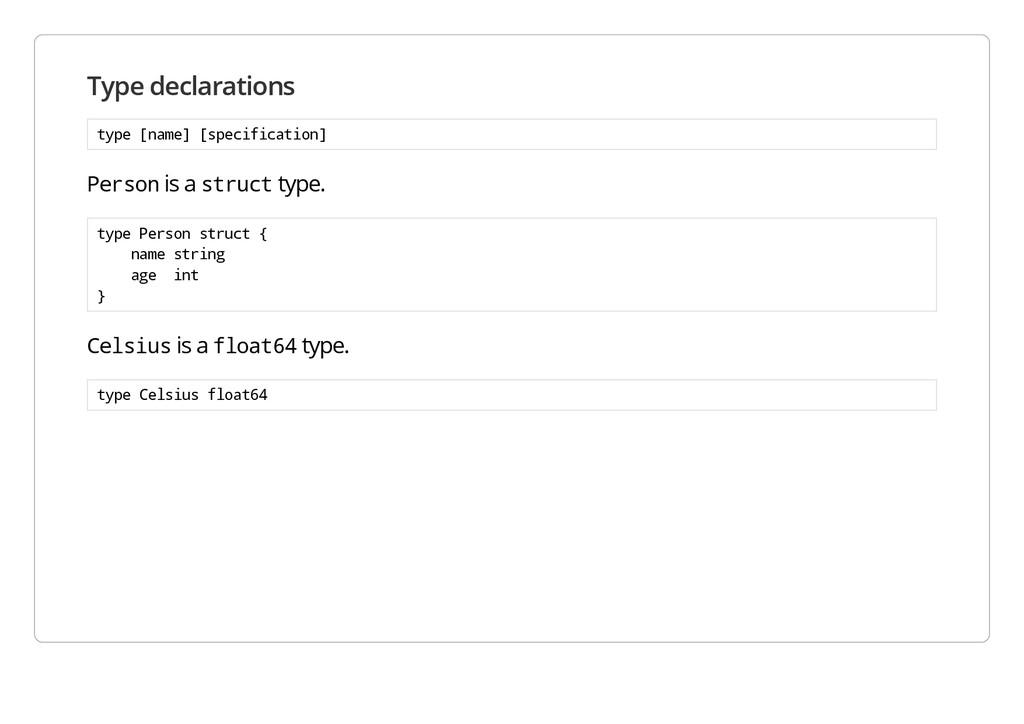
e ] [ s p e c i f i c a t i o n ] P e r s o n is a s t r u c t type. t y p e P e r s o n s t r u c t { n a m e s t r i n g a g e i n t } C e l s i u s is a f l o a t 6 4 type. t y p e C e l s i u s f l o a t 6 4
e ] ( [ p a r a m s ] ) [ r e t u r n v a l u e ] f u n c [ n a m e ] ( [ p a r a m s ] ) ( [ r e t u r n v a l u e s ] ) A sum function: f u n c s u m ( a i n t , b i n t ) i n t { r e t u r n a + b } A function with multiple returned values: f u n c d i v ( a , b i n t ) ( i n t , i n t ) r e t u r n a / b , a % b } Made clearer by naming the return values: f u n c d i v ( d e n , d i v i n t ) ( q , r e m i n t ) r e t u r n a / b , a % b }
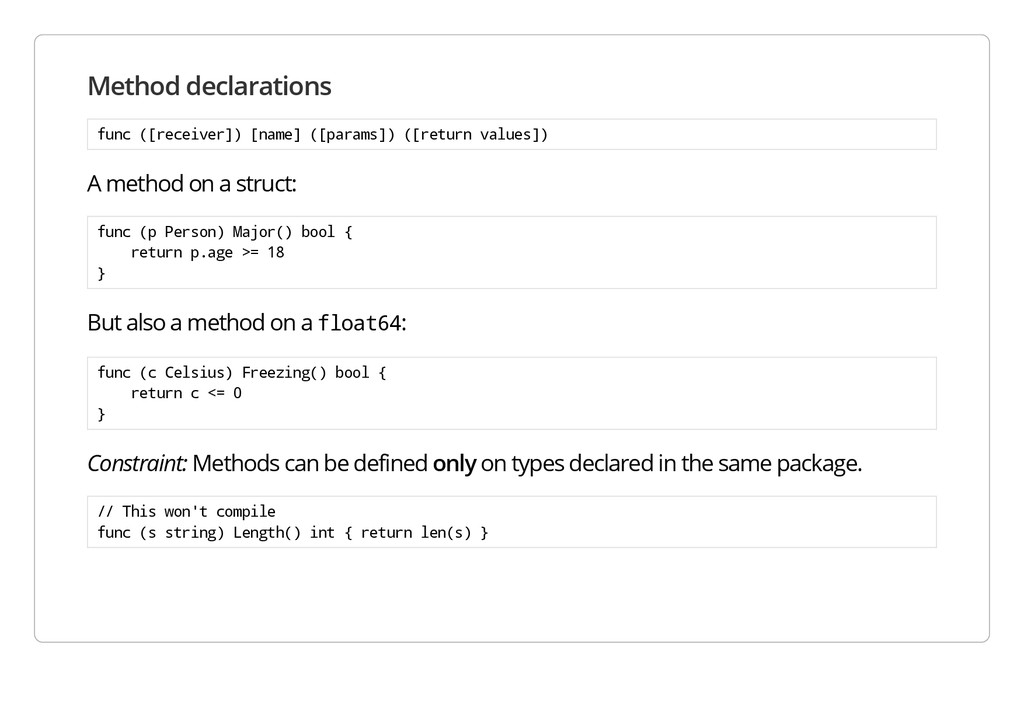
c e i v e r ] ) [ n a m e ] ( [ p a r a m s ] ) ( [ r e t u r n v a l u e s ] ) A method on a struct: f u n c ( p P e r s o n ) M a j o r ( ) b o o l { r e t u r n p . a g e > = 1 8 } But also a method on a f l o a t 6 4 : f u n c ( c C e l s i u s ) F r e e z i n g ( ) b o o l { r e t u r n c < = 0 } Constraint: Methods can be defined only on types declared in the same package. / / T h i s w o n ' t c o m p i l e f u n c ( s s t r i n g ) L e n g t h ( ) i n t { r e t u r n l e n ( s ) }
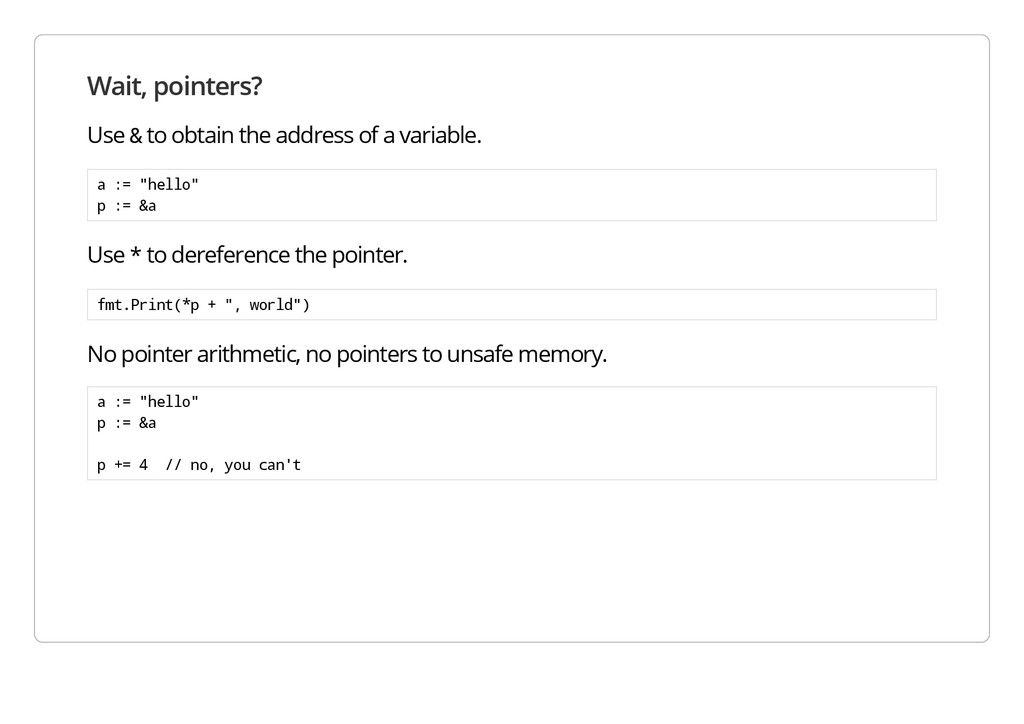
variable. a : = " h e l l o " p : = & a Use * to dereference the pointer. f m t . P r i n t ( * p + " , w o r l d " ) No pointer arithmetic, no pointers to unsafe memory. a : = " h e l l o " p : = & a p + = 4 / / n o , y o u c a n ' t
no side-effects: f u n c d o u b l e ( x i n t ) { x * = 2 } passing pointers: side-effects possible: f u n c d o u b l e ( x * i n t ) { * x * = 2 } Control your memory layout. compare []Person and []*Person
Pointers allow modifying the pointed receiver: f u n c ( p * P e r s o n ) I n c A g e ( ) { p . a g e + + } The method receiver is a copy of a pointer (pointing to the same address). Method calls on nil receivers are perfectly valid (and useful!). f u n c ( p * P e r s o n ) N a m e ( ) s t r i n g { i f p = = n i l { r e t u r n " a n o n y m o u s " } r e t u r n p . n a m e }
i n t e r f a c e S w i t c h { v o i d o p e n ( ) ; v o i d c l o s e ( ) ; } In Go: t y p e O p e n C l o s e r i n t e r f a c e { O p e n ( ) C l o s e ( ) }
interfaces are satisfied implicitly. Picture by Gorupdebesanez CC-BY-SA-3.0 (http://creativecommons.org/licenses/by-sa/3.0) , via Wikimedia Commons (http://commons.wikimedia.org/wiki/File%3ARolling_Stones_09.jpg)
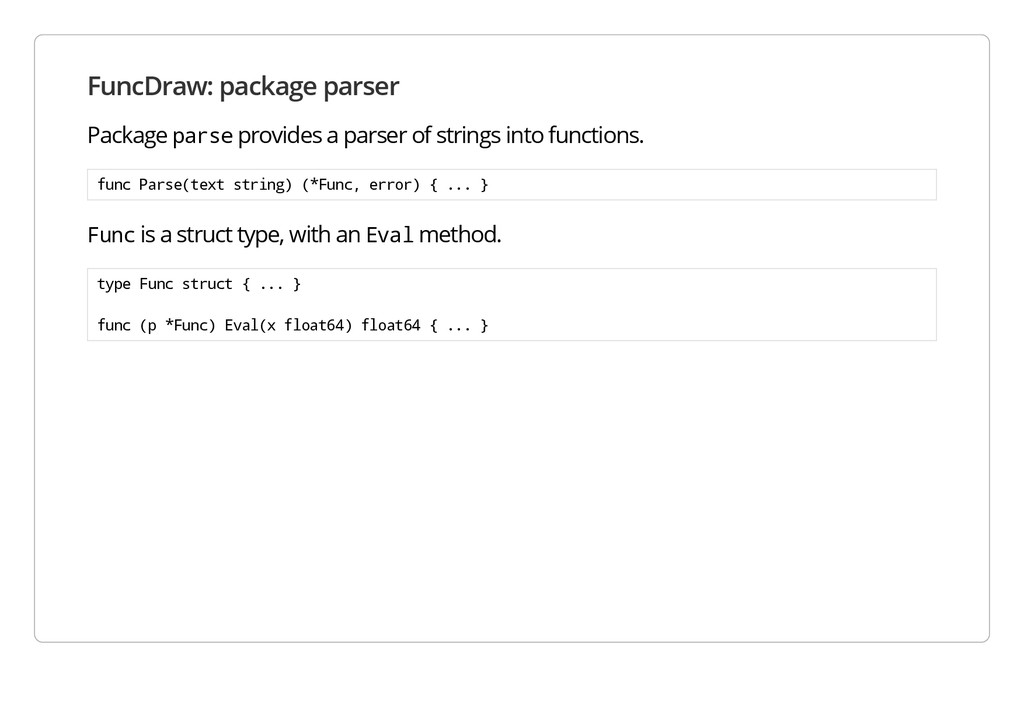
a parser of strings into functions. f u n c P a r s e ( t e x t s t r i n g ) ( * F u n c , e r r o r ) { . . . } F u n c is a struct type, with an E v a l method. t y p e F u n c s t r u c t { . . . } f u n c ( p * F u n c ) E v a l ( x f l o a t 6 4 ) f l o a t 6 4 { . . . }
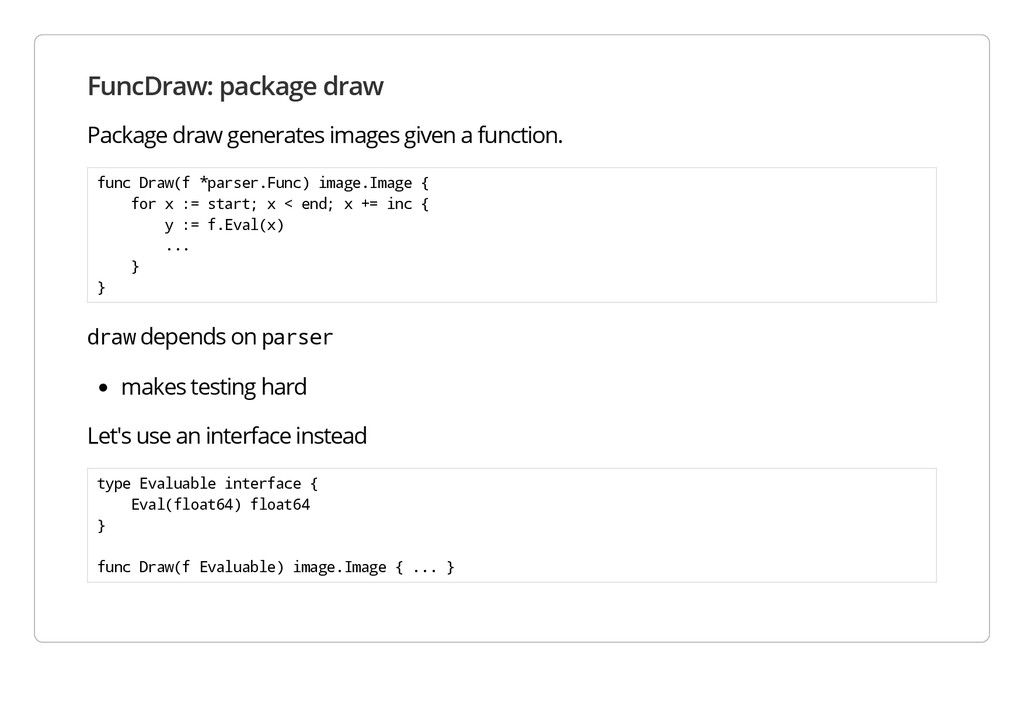
f u n c D r a w ( f * p a r s e r . F u n c ) i m a g e . I m a g e { f o r x : = s t a r t ; x < e n d ; x + = i n c { y : = f . E v a l ( x ) . . . } } d r a w depends on p a r s e r makes testing hard Let's use an interface instead t y p e E v a l u a b l e i n t e r f a c e { E v a l ( f l o a t 6 4 ) f l o a t 6 4 } f u n c D r a w ( f E v a l u a b l e ) i m a g e . I m a g e { . . . }
e r { p r i v a t e S t r i n g n a m e ; p u b l i c R u n n e r ( S t r i n g n a m e ) { t h i s . n a m e = n a m e ; } p u b l i c S t r i n g g e t N a m e ( ) { r e t u r n t h i s . n a m e ; } p u b l i c v o i d r u n ( T a s k t a s k ) { t a s k . r u n ( ) ; } p u b l i c v o i d r u n A l l ( T a s k [ ] t a s k s ) { f o r ( T a s k t a s k : t a s k s ) { r u n ( t a s k ) ; } } }
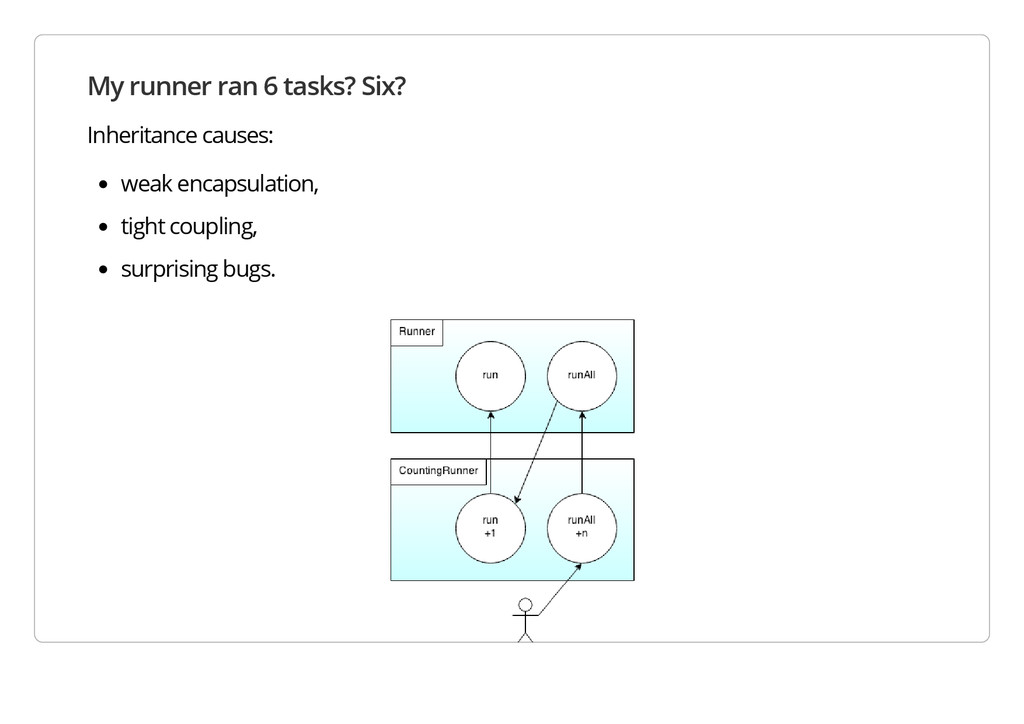
R u n C o u n t e r e x t e n d s R u n n e r { p r i v a t e i n t c o u n t ; p u b l i c R u n C o u n t e r ( S t r i n g m e s s a g e ) { s u p e r ( m e s s a g e ) ; t h i s . c o u n t = 0 ; } @ O v e r r i d e p u b l i c v o i d r u n ( T a s k t a s k ) { c o u n t + + ; s u p e r . r u n ( t a s k ) ; } @ O v e r r i d e p u b l i c v o i d r u n A l l ( T a s k [ ] t a s k s ) { c o u n t + = t a s k s . l e n g t h ; s u p e r . r u n A l l ( t a s k s ) ; } p u b l i c i n t g e t C o u n t ( ) { r e t u r n c o u n t ; } }
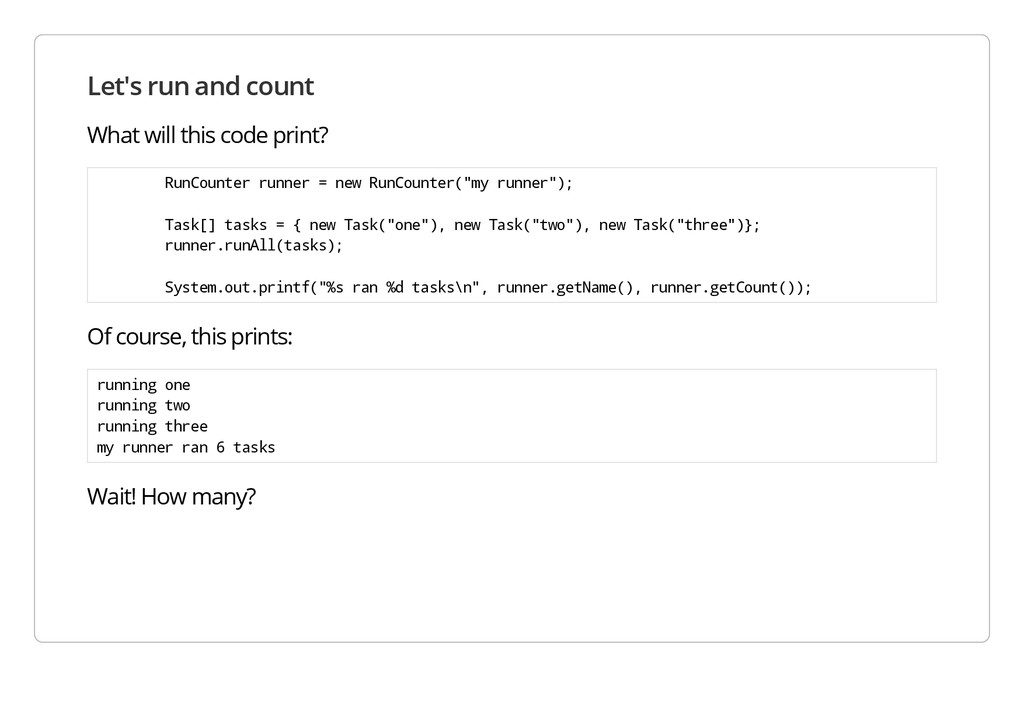
u n C o u n t e r r u n n e r = n e w R u n C o u n t e r ( " m y r u n n e r " ) ; T a s k [ ] t a s k s = { n e w T a s k ( " o n e " ) , n e w T a s k ( " t w o " ) , n e w T a s k ( " t h r e e " ) } ; r u n n e r . r u n A l l ( t a s k s ) ; S y s t e m . o u t . p r i n t f ( " % s r a n % d t a s k s \ n " , r u n n e r . g e t N a m e ( ) , r u n n e r . g e t C o u n t ( ) ) ; Of course, this prints: r u n n i n g o n e r u n n i n g t w o r u n n i n g t h r e e m y r u n n e r r a n 6 t a s k s Wait! How many?
n C o u n t e r { p r i v a t e R u n n e r r u n n e r ; p r i v a t e i n t c o u n t ; p u b l i c R u n C o u n t e r ( S t r i n g m e s s a g e ) { t h i s . r u n n e r = n e w R u n n e r ( m e s s a g e ) ; t h i s . c o u n t = 0 ; } p u b l i c v o i d r u n ( T a s k t a s k ) { c o u n t + + ; r u n n e r . r u n ( t a s k ) ; } p u b l i c v o i d r u n A l l ( T a s k [ ] t a s k s ) { c o u n t + = t a s k s . l e n g t h ; r u n n e r . r u n A l l ( t a s k s ) ; } / / c o n t i n u e d o n n e x t s l i d e . . .
u n n e r is completely independent of R u n C o u n t e r . The creation of the R u n n e r can be delayed until (and if) needed. Cons We need to explicitly define the R u n n e r methods on R u n C o u n t e r : p u b l i c S t r i n g g e t N a m e ( ) { r e t u r n r u n n e r . g e t N a m e ( ) ; } This can cause lots of repetition, and eventually bugs.
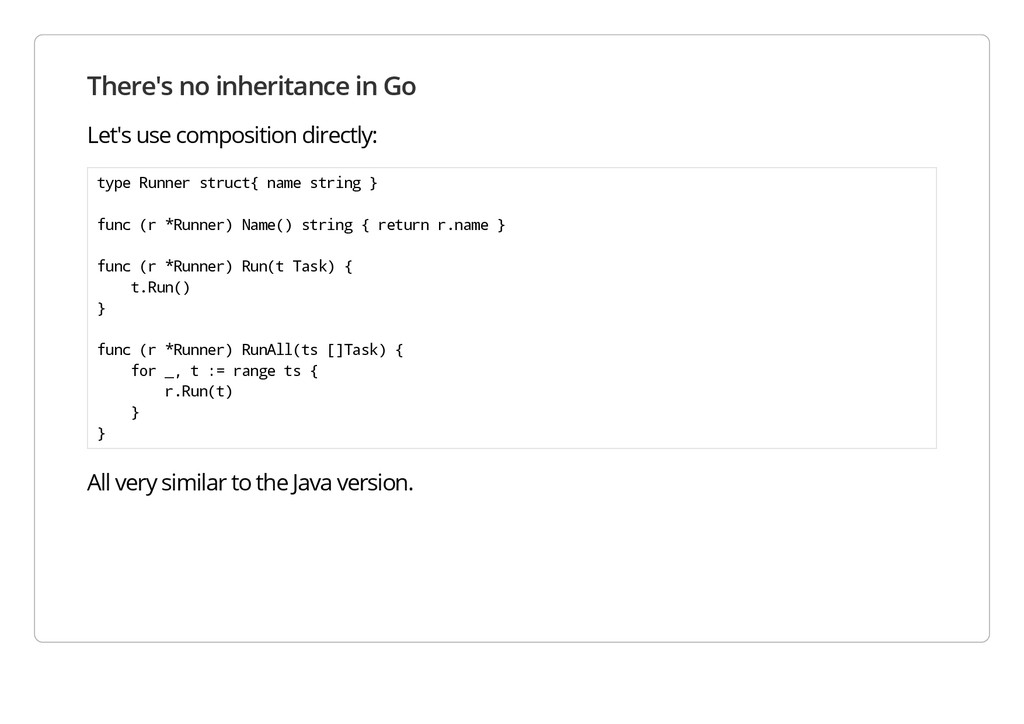
y p e R u n n e r s t r u c t { n a m e s t r i n g } f u n c ( r * R u n n e r ) N a m e ( ) s t r i n g { r e t u r n r . n a m e } f u n c ( r * R u n n e r ) R u n ( t T a s k ) { t . R u n ( ) } f u n c ( r * R u n n e r ) R u n A l l ( t s [ ] T a s k ) { f o r _ , t : = r a n g e t s { r . R u n ( t ) } } All very similar to the Java version.
r has a R u n n e r field. t y p e R u n C o u n t e r s t r u c t { r u n n e r R u n n e r c o u n t i n t } f u n c N e w R u n C o u n t e r ( n a m e s t r i n g ) * R u n C o u n t e r { r e t u r n & R u n C o u n t e r { r u n n e r : R u n n e r { n a m e } } } f u n c ( r * R u n C o u n t e r ) R u n ( t T a s k ) { r . c o u n t + + r . r u n n e r . R u n ( t ) } f u n c ( r * R u n C o u n t e r ) R u n A l l ( t s [ ] T a s k ) { r . c o u n t + = l e n ( t s ) r . r u n n e r . R u n A l l ( t s ) } f u n c ( r * R u n C o u n t e r ) C o u n t ( ) i n t { r e t u r n r . c o u n t } f u n c ( r * R u n C o u n t e r ) N a m e ( ) s t r i n g { r e t u r n r . r u n n e r . N a m e ( ) }
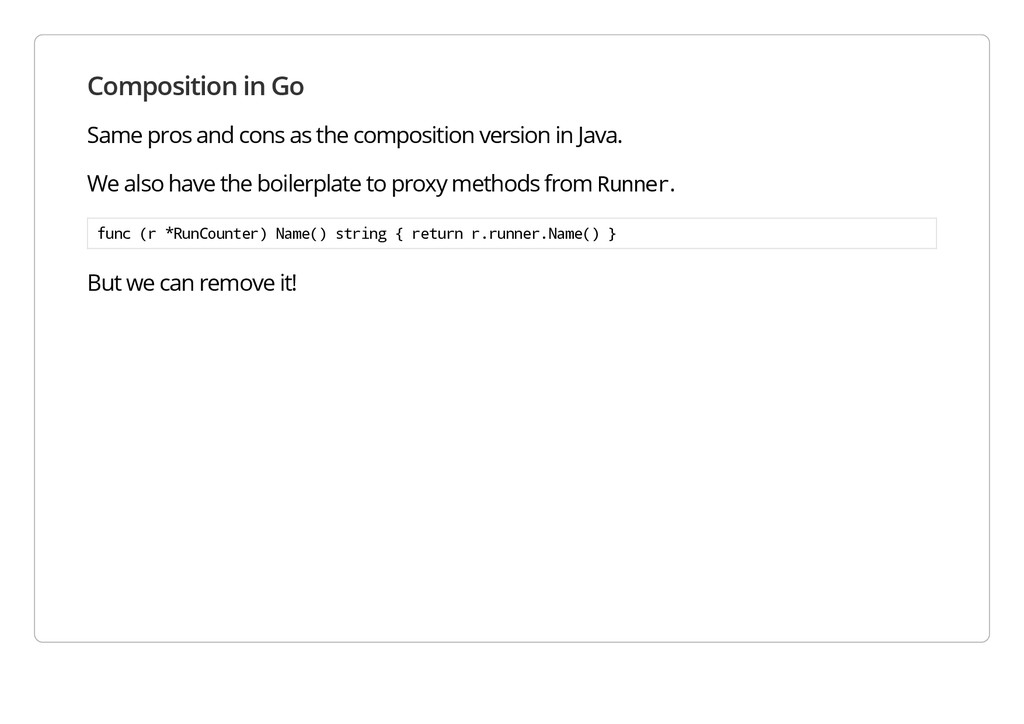
version in Java. We also have the boilerplate to proxy methods from R u n n e r . f u n c ( r * R u n C o u n t e r ) N a m e ( ) s t r i n g { r e t u r n r . r u n n e r . N a m e ( ) } But we can remove it!
struct. It is still composition. The fields and methods of the embedded type are defined on the embedding type. Similar to inheritance, but the embedded type doesn't know it's embedded.
s o n : t y p e P e r s o n s t r u c t { N a m e s t r i n g } f u n c ( p P e r s o n ) I n t r o d u c e ( ) { f m t . P r i n t l n ( " H i , I ' m " , p . N a m e ) } We can define a type E m p l o y e e embedding P e r s o n : t y p e E m p l o y e e s t r u c t { P e r s o n E m p l o y e e I D i n t } All fields and methods from P e r s o n are available on E m p l o y e e : v a r e E m p l o y e e e . N a m e = " P e t e r " e . E m p l o y e e I D = 1 2 3 4 e . I n t r o d u c e ( )
o u n t e r 2 s t r u c t { R u n n e r c o u n t i n t } f u n c N e w R u n C o u n t e r 2 ( n a m e s t r i n g ) * R u n C o u n t e r 2 { r e t u r n & R u n C o u n t e r 2 { R u n n e r { n a m e } , 0 } } f u n c ( r * R u n C o u n t e r 2 ) R u n ( t T a s k ) { r . c o u n t + + r . R u n n e r . R u n ( t ) } f u n c ( r * R u n C o u n t e r 2 ) R u n A l l ( t s [ ] T a s k ) { r . c o u n t + = l e n ( t s ) r . R u n n e r . R u n A l l ( t s ) } f u n c ( r * R u n C o u n t e r 2 ) C o u n t ( ) i n t { r e t u r n r . c o u n t }
is composition. You can't reach into another type and change the way it works. Method dispatching is explicit. It is more general. Struct embedding of interfaces.
/ W r i t e C o u n t e r t r a c k s t h e t o t a l n u m b e r o f b y t e s w r i t t e n . t y p e W r i t e C o u n t e r s t r u c t { i o . R e a d W r i t e r c o u n t i n t } f u n c ( w * W r i t e C o u n t e r ) W r i t e ( b [ ] b y t e ) ( i n t , e r r o r ) { w . c o u n t + = l e n ( b ) r e t u r n w . R e a d W r i t e r . W r i t e ( b ) } WriteCounter can be used with any i o . R e a d W r i t e r . f u n c m a i n ( ) { b u f : = & b y t e s . B u f f e r { } w : = & W r i t e C o u n t e r { R e a d W r i t e r : b u f } f m t . F p r i n t f ( w , " H e l l o , g o p h e r s ! \ n " ) f m t . P r i n t f ( " P r i n t e d % v b y t e s " , w . c o u n t ) } Run
of a n e t . C o n n ? t y p e C o n n i n t e r f a c e { R e a d ( b [ ] b y t e ) ( n i n t , e r r e r r o r ) W r i t e ( b [ ] b y t e ) ( n i n t , e r r e r r o r ) C l o s e ( ) e r r o r L o c a l A d d r ( ) A d d r R e m o t e A d d r ( ) A d d r S e t D e a d l i n e ( t t i m e . T i m e ) e r r o r S e t R e a d D e a d l i n e ( t t i m e . T i m e ) e r r o r S e t W r i t e D e a d l i n e ( t t i m e . T i m e ) e r r o r } I want to test h a n d l e C o n : f u n c h a n d l e C o n n ( c o n n n e t . C o n n ) { We could create a f a k e C o n n and define all the methods of C o n n on it. But that's a lot of boring code.
n d l e C o n with the l o o p B a c k type. t y p e l o o p B a c k s t r u c t { n e t . C o n n b u f b y t e s . B u f f e r } Any calls to the methods of n e t . C o n n will fail, since the field is nil. We redefine the operations we support: f u n c ( c * l o o p B a c k ) R e a d ( b [ ] b y t e ) ( i n t , e r r o r ) { r e t u r n c . b u f . R e a d ( b ) } f u n c ( c * l o o p B a c k ) W r i t e ( b [ ] b y t e ) ( i n t , e r r o r ) { r e t u r n c . b u f . W r i t e ( b ) }
Based on two concepts: goroutines: lightweight threads channels: typed pipes used to communicate and synchronize between goroutines So cheap you can use them whenever you want.
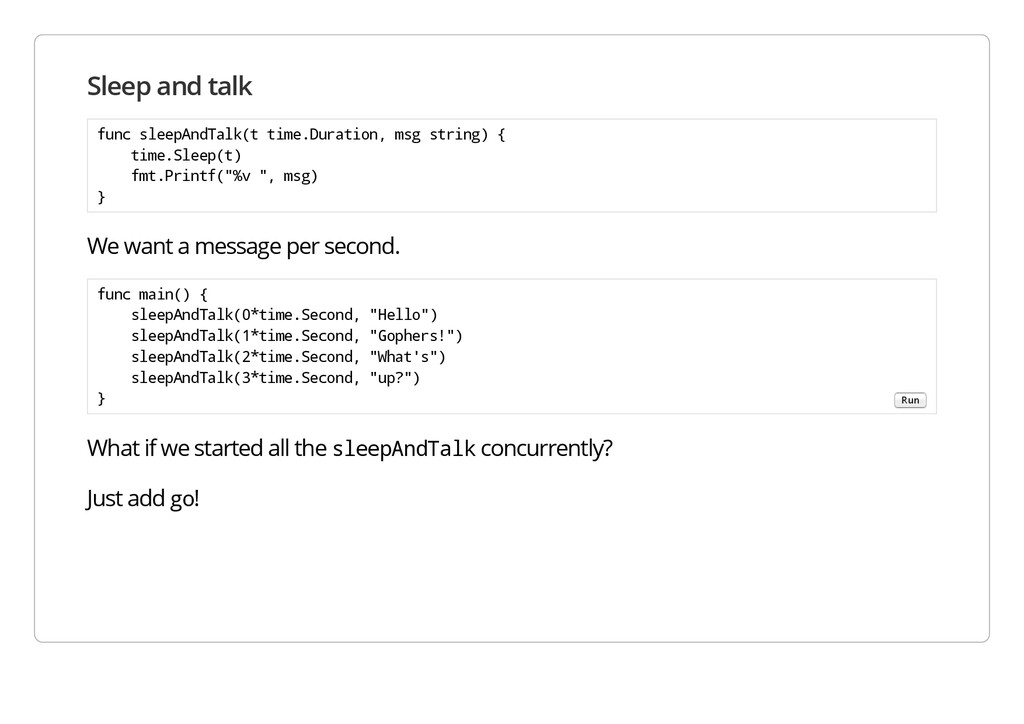
e p A n d T a l k ( t t i m e . D u r a t i o n , m s g s t r i n g ) { t i m e . S l e e p ( t ) f m t . P r i n t f ( " % v " , m s g ) } We want a message per second. What if we started all the s l e e p A n d T a l k concurrently? Just add g o ! f u n c m a i n ( ) { s l e e p A n d T a l k ( 0 * t i m e . S e c o n d , " H e l l o " ) s l e e p A n d T a l k ( 1 * t i m e . S e c o n d , " G o p h e r s ! " ) s l e e p A n d T a l k ( 2 * t i m e . S e c o n d , " W h a t ' s " ) s l e e p A n d T a l k ( 3 * t i m e . S e c o n d , " u p ? " ) } Run
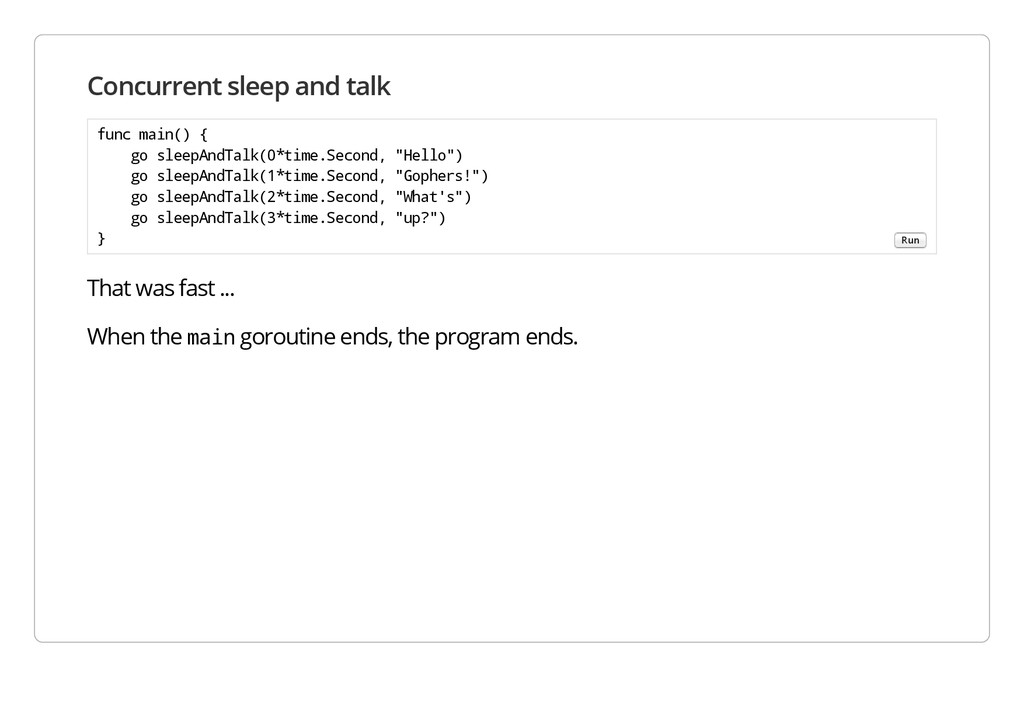
m a i n goroutine ends, the program ends. f u n c m a i n ( ) { g o s l e e p A n d T a l k ( 0 * t i m e . S e c o n d , " H e l l o " ) g o s l e e p A n d T a l k ( 1 * t i m e . S e c o n d , " G o p h e r s ! " ) g o s l e e p A n d T a l k ( 2 * t i m e . S e c o n d , " W h a t ' s " ) g o s l e e p A n d T a l k ( 3 * t i m e . S e c o n d , " u p ? " ) } Run
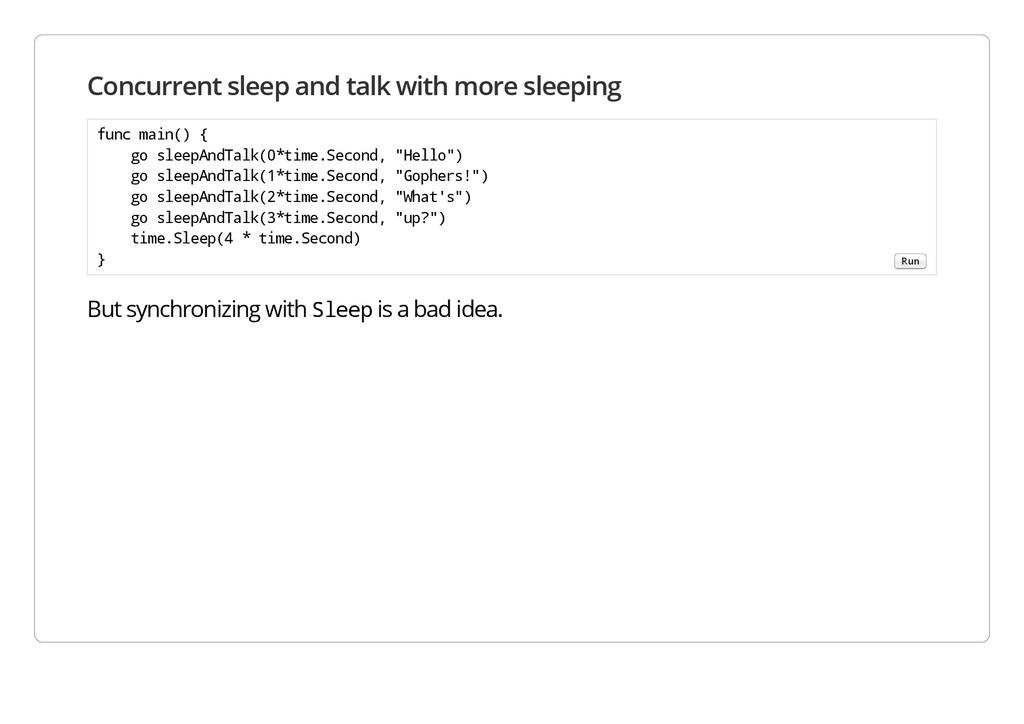
S l e e p is a bad idea. f u n c m a i n ( ) { g o s l e e p A n d T a l k ( 0 * t i m e . S e c o n d , " H e l l o " ) g o s l e e p A n d T a l k ( 1 * t i m e . S e c o n d , " G o p h e r s ! " ) g o s l e e p A n d T a l k ( 2 * t i m e . S e c o n d , " W h a t ' s " ) g o s l e e p A n d T a l k ( 3 * t i m e . S e c o n d , " u p ? " ) t i m e . S l e e p ( 4 * t i m e . S e c o n d ) } Run
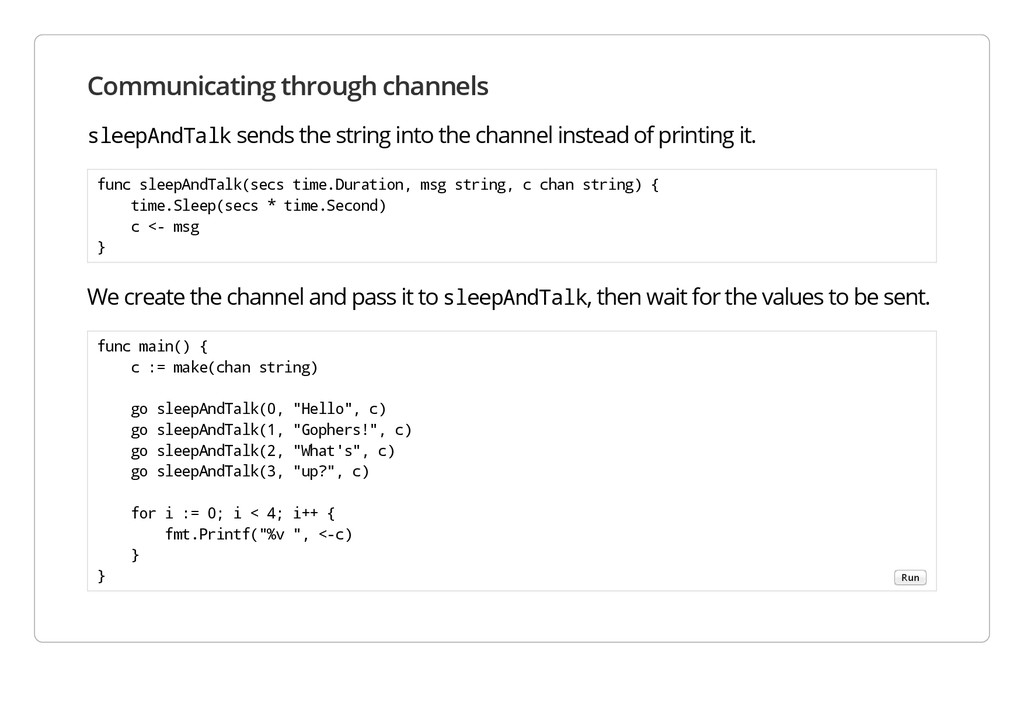
d T a l k sends the string into the channel instead of printing it. f u n c s l e e p A n d T a l k ( s e c s t i m e . D u r a t i o n , m s g s t r i n g , c c h a n s t r i n g ) { t i m e . S l e e p ( s e c s * t i m e . S e c o n d ) c < - m s g } We create the channel and pass it to s l e e p A n d T a l k , then wait for the values to be sent. f u n c m a i n ( ) { c : = m a k e ( c h a n s t r i n g ) g o s l e e p A n d T a l k ( 0 , " H e l l o " , c ) g o s l e e p A n d T a l k ( 1 , " G o p h e r s ! " , c ) g o s l e e p A n d T a l k ( 2 , " W h a t ' s " , c ) g o s l e e p A n d T a l k ( 3 , " u p ? " , c ) f o r i : = 0 ; i < 4 ; i + + { f m t . P r i n t f ( " % v " , < - c ) } } Run
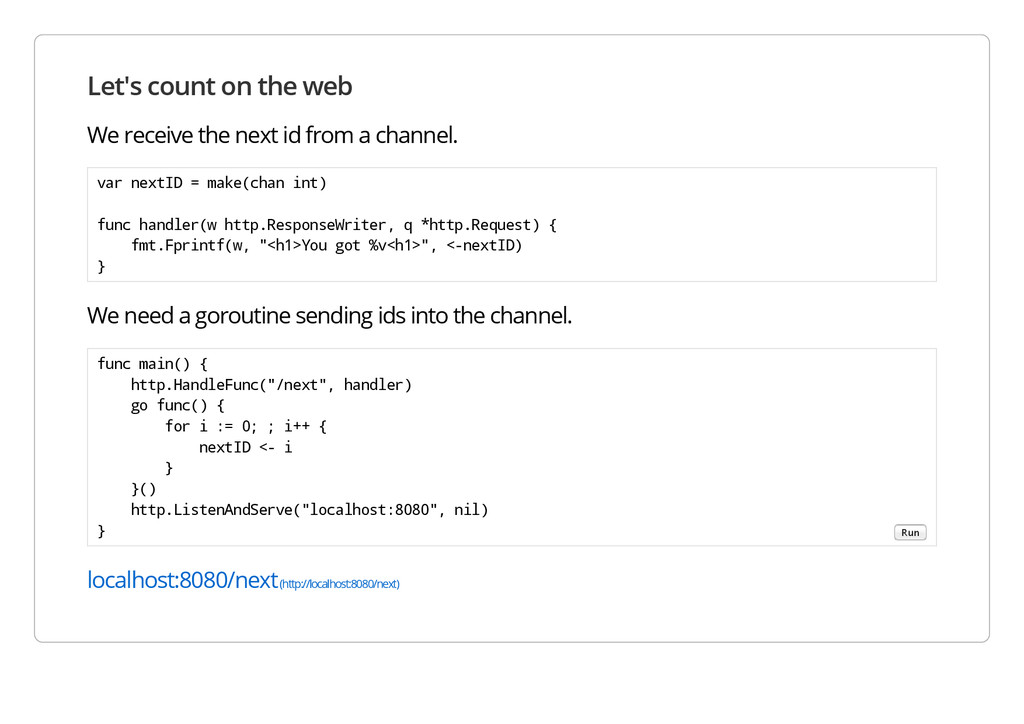
from a channel. v a r n e x t I D = m a k e ( c h a n i n t ) f u n c h a n d l e r ( w h t t p . R e s p o n s e W r i t e r , q * h t t p . R e q u e s t ) { f m t . F p r i n t f ( w , " < h 1 > Y o u g o t % v < h 1 > " , < - n e x t I D ) } We need a goroutine sending ids into the channel. localhost:8080/next (http://localhost:8080/next) f u n c m a i n ( ) { h t t p . H a n d l e F u n c ( " / n e x t " , h a n d l e r ) g o f u n c ( ) { f o r i : = 0 ; ; i + + { n e x t I D < - i } } ( ) h t t p . L i s t e n A n d S e r v e ( " l o c a l h o s t : 8 0 8 0 " , n i l ) } Run
to chose among multiple channel operations. Go - localhost:8080/fight?usr=go (http://localhost:8080/fight?usr=go) Java - localhost:8080/fight?usr=java (http://localhost:8080/fight?usr=java) v a r b a t t l e = m a k e ( c h a n s t r i n g ) f u n c h a n d l e r ( w h t t p . R e s p o n s e W r i t e r , q * h t t p . R e q u e s t ) { s e l e c t { c a s e b a t t l e < - q . F o r m V a l u e ( " u s r " ) : f m t . F p r i n t f ( w , " Y o u w o n ! " ) c a s e w o n : = < - b a t t l e : f m t . F p r i n t f ( w , " Y o u l o s t , % v i s b e t t e r t h a n y o u " , w o n ) } } Run
e f t , r i g h t c h a n i n t ) { l e f t < - 1 + < - r i g h t } f u n c m a i n ( ) { s t a r t : = t i m e . N o w ( ) c o n s t n = 1 0 0 0 l e f t m o s t : = m a k e ( c h a n i n t ) r i g h t : = l e f t m o s t l e f t : = l e f t m o s t f o r i : = 0 ; i < n ; i + + { r i g h t = m a k e ( c h a n i n t ) g o f ( l e f t , r i g h t ) l e f t = r i g h t } g o f u n c ( c c h a n i n t ) { c < - 0 } ( r i g h t ) f m t . P r i n t l n ( < - l e f t m o s t , t i m e . S i n c e ( s t a r t ) ) } Run
Concurrency Patterns (http://talks.golang.org/2012/concurrency.slide#1) , by Rob Pike Advanced Concurrency Patterns (http://talks.golang.org/2013/advconc.slide#1) , by Sameer Ajmani Concurrency is not Parellelism (http://talks.golang.org/2012/waza.slide#1) , by Rob Pike
types are equal methods on any type Implicit interfaces Structural typing Less dependencies Code testable and reusable Use composition instead of inheritance Struct embedding to remove boilerplate. Struct embedding of interfaces to satisfy them fast. Concurrency is awesome, and you should check it out.
tour.golang.org (http://tour.golang.org) Find more about Go on golang.org (http://golang.org) Join the community at golang-nuts (https://groups.google.com/forum/#!forum/Golang-nuts) Link to the slides talks.golang.org/2014/go4java.slide (http://talks.golang.org/2014/go4java.slide)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}