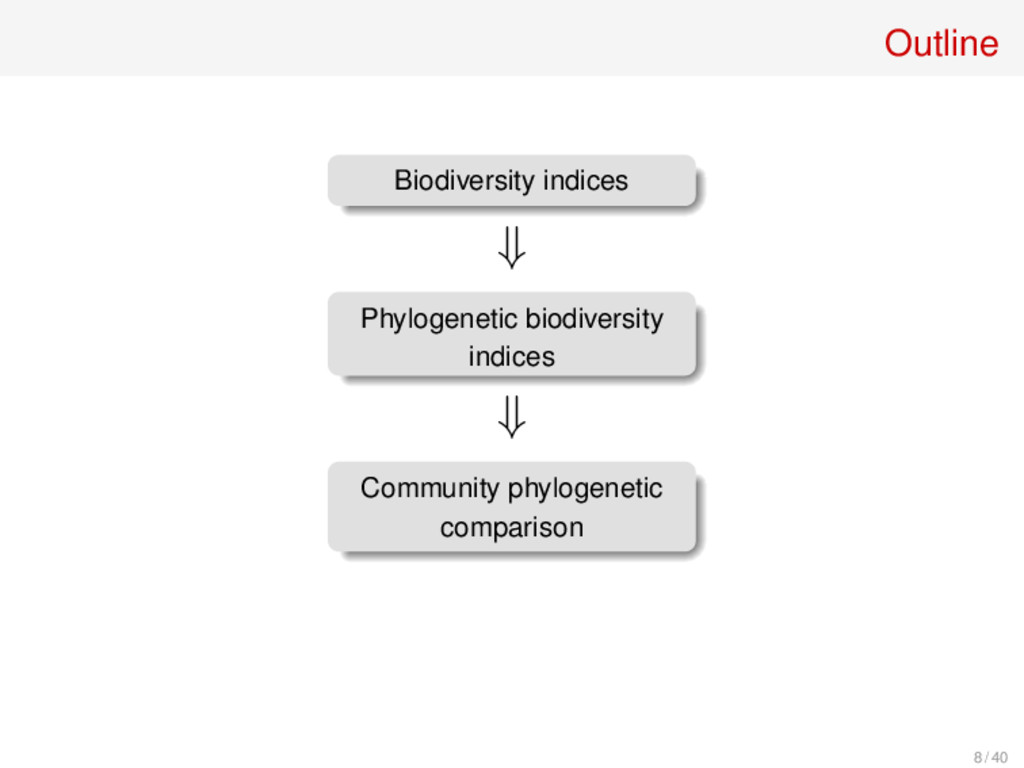
and compares patterns between communities Methods: • Supervised and unsupervised classification techniques (BIG data analysis) • Biodiversity measures (indices and distances) 7 / 40
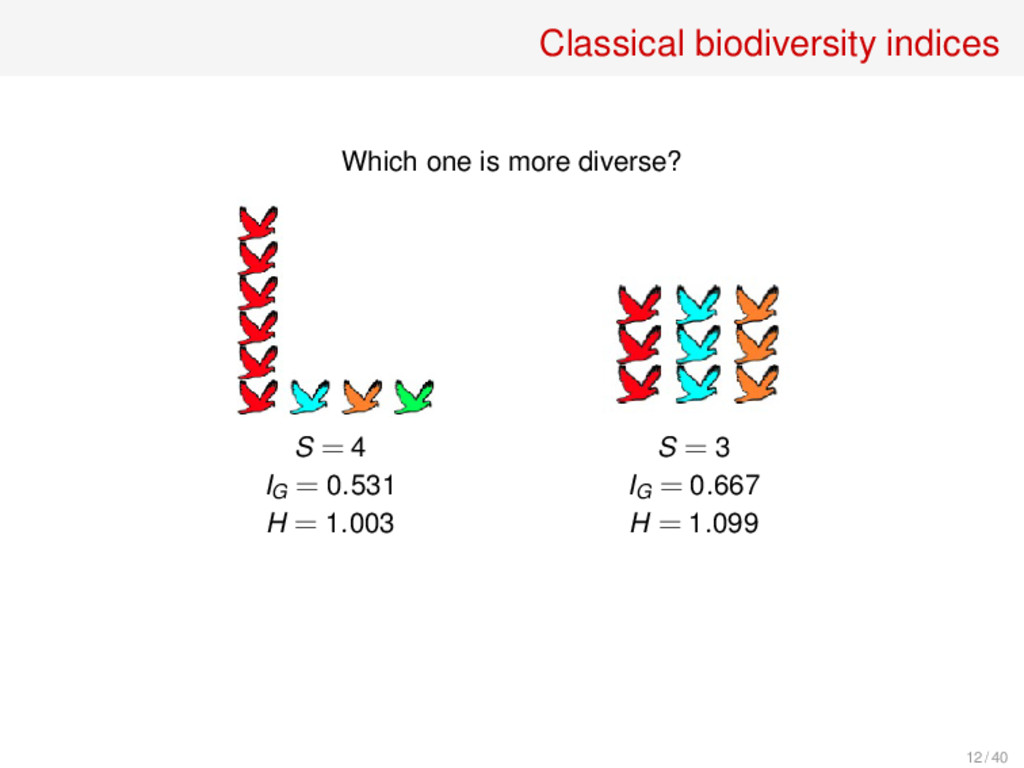
of s species Species richness S(p) = s Gini index (1912) The probability that two randomly chosen individuals belong to different species: IG (p) = ∑ i pi (1 −pi ) = 1 −∑ i p2 i Simpson index (1949) The probability that two randomly chosen individuals belong to the same species: IS (p) = ∑ i p2 i Shannon entropy (1948) Uncertainty in the species identity of a randomly sampled individual: H(p) = −∑ i pi ln(pi ) 11 / 40
each with diversity X, and we take the union, the resulting community should have diversity 2X Gini-Simpson indices and Shannon entropy do not satisfy it, but. . . • S satisfies it • 1/IS satisfies it • eH satisfies it 13 / 40
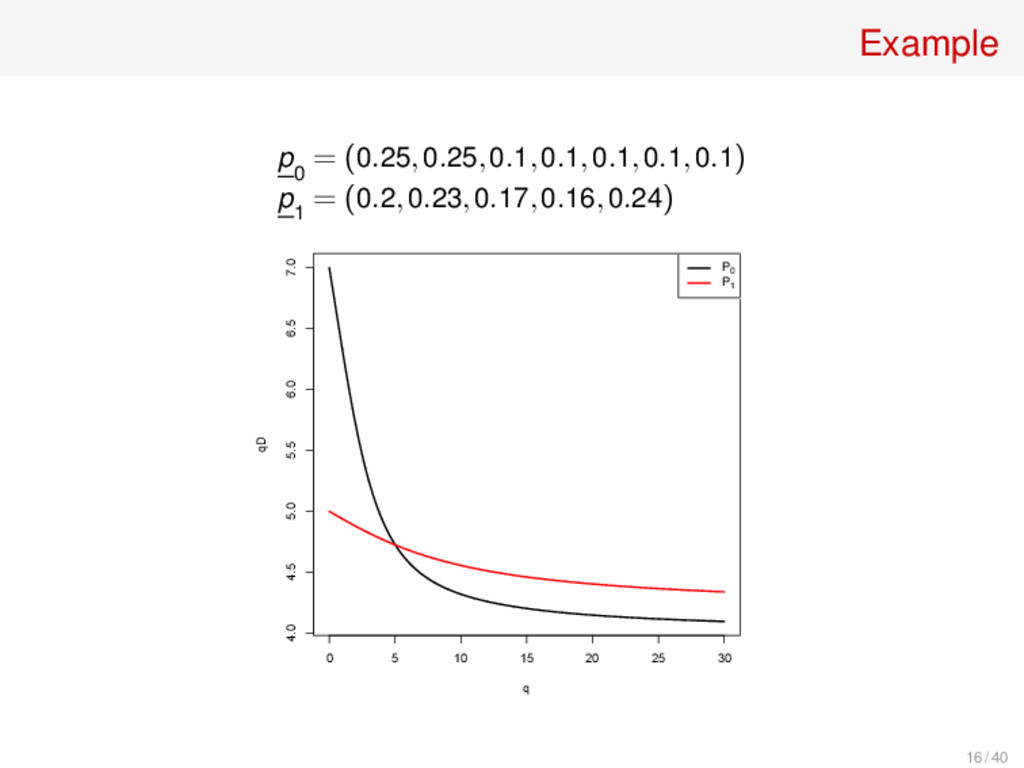
ps, then qD(p) = s for every q • qD(p) = number of equally common species needed to give the same “q-diversity” s ∑ i=1 pq i = D ∑ i=1 1 D q = D1−q ⇒ D = ∑ i pq i 1 1−q E.g. Shannon entropy H = 1.003 means e1.003 ≈ 2.7 “species” 15 / 40
ps, then qD(p) = s for every q • qD(p) = number of equally common species needed to give the same “q-diversity” s ∑ i=1 pq i = D ∑ i=1 1 D q = D1−q ⇒ D = ∑ i pq i 1 1−q E.g. Shannon entropy H = 1.003 means e1.003 ≈ 2.7 “species” • The parameter q controls the relative emphasis placed on common species 15 / 40
Given x = (x1 ,...,xs ) and y = (y1 ,...,ys ) mr (x,yt ) = ∑ i xi ·yr i 1/r if r = 0 ∏ i y−xi i if r = 0 (limit) min xi >0 1 yi if r = ∞ (limit) For instance, qD(p) = ∑ i pq i 1 1−q = m1−q p, 1 pt 18 / 40
an s ×s similarity matrix, qDZ (p) = m1−q (p,(Z ·pt )t ) = ∑ i pi (Z ·p)q−1 1 1−q if q = 1 ∏ i (Z ·pt )−pi i if q = 1 min pi >0 1 (Z ·pt )i if q = ∞ Notice that qDId = qD T. Leinster, Ch. Cobbold, Ecology 93 (2012), 477–489 19 / 40
, qD(p)1−q = ∑ i pi ·pq−1 i qDZ (p)1−q = ∑ i pi · ∑ j zi,j pj q−1 For instance, when q = 2 2DZ (p) = ∑ i,j zi,j pi pj −1 related to Rao’s quadratic entropy (more on it later) ∑ i,j ti,j pi pj where ti,j is a distance 20 / 40
, qD(p)1−q = ∑ i pi ·pq−1 i qDZ (p)1−q = ∑ i pi · ∑ j zi,j pj q−1 For instance, when q = 2 2DZ (p) = ∑ i,j zi,j pi pj −1 related to Rao’s quadratic entropy (more on it later) ∑ i,j ti,j pi pj where ti,j is a distance (Quite) Open problem Study the statistical properties of qDZ (p) 20 / 40
Number of species in a community Homogeneity: Evenness of species in a community Regularity: Evenness of spread of species across a phylogenetic tree (∼ balance of their phylogenetic tree) Divergence: Mean phylogenetic difference in a community 21 / 40
the framework of Hill–Leinster–Cobbold approach • Indices associated to the structure of the phylogenetic tree of a community • Phylogenetic dissimilarities between communities 22 / 40
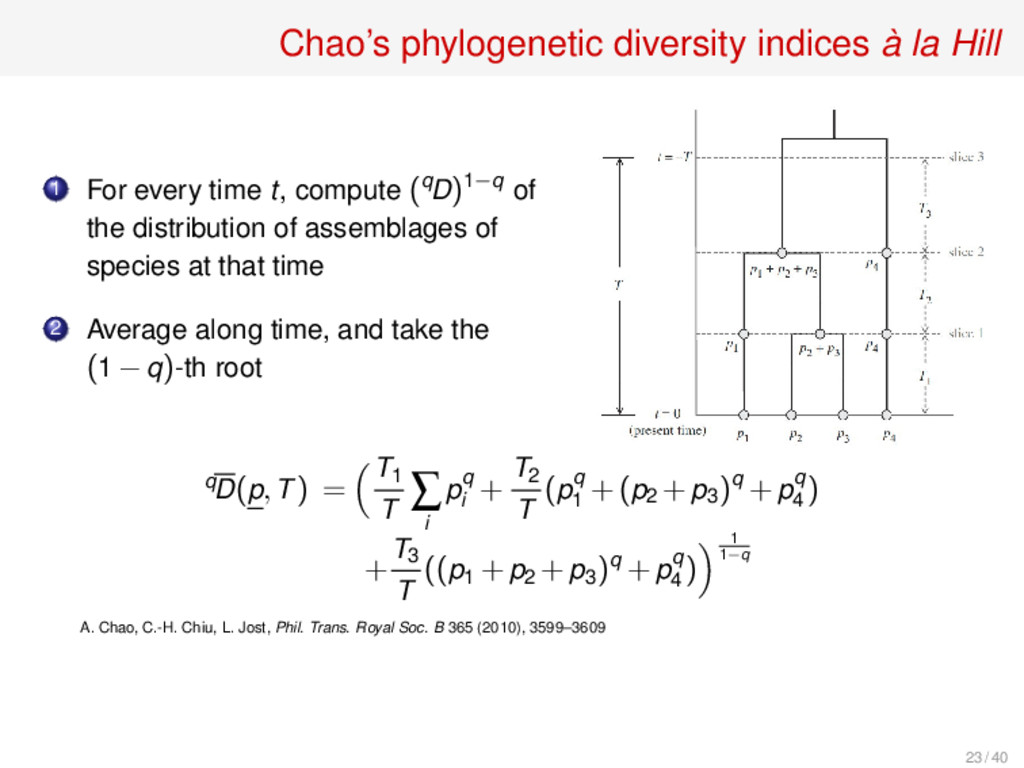
time t, compute (qD)1−q of the distribution of assemblages of species at that time 2 Average along time, and take the (1 −q)-th root qD(p,T) = T1 T ∑ i pq i + T2 T (pq 1 +(p2 +p3 )q +pq 4 ) + T3 T ((p1 +p2 +p3 )q +pq 4 ) 1 1−q A. Chao, C.-H. Chiu, L. Jost, Phil. Trans. Royal Soc. B 365 (2010), 3599–3609 23 / 40
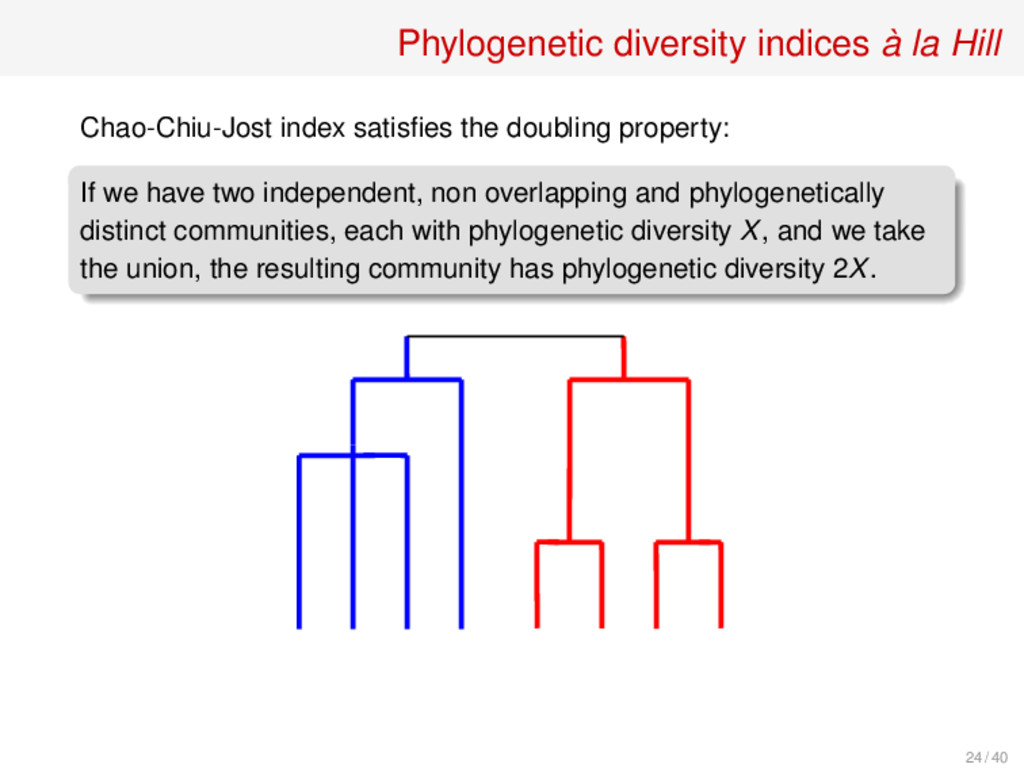
doubling property: If we have two independent, non overlapping and phylogenetically distinct communities, each with phylogenetic diversity X, and we take the union, the resulting community has phylogenetic diversity 2X. 24 / 40
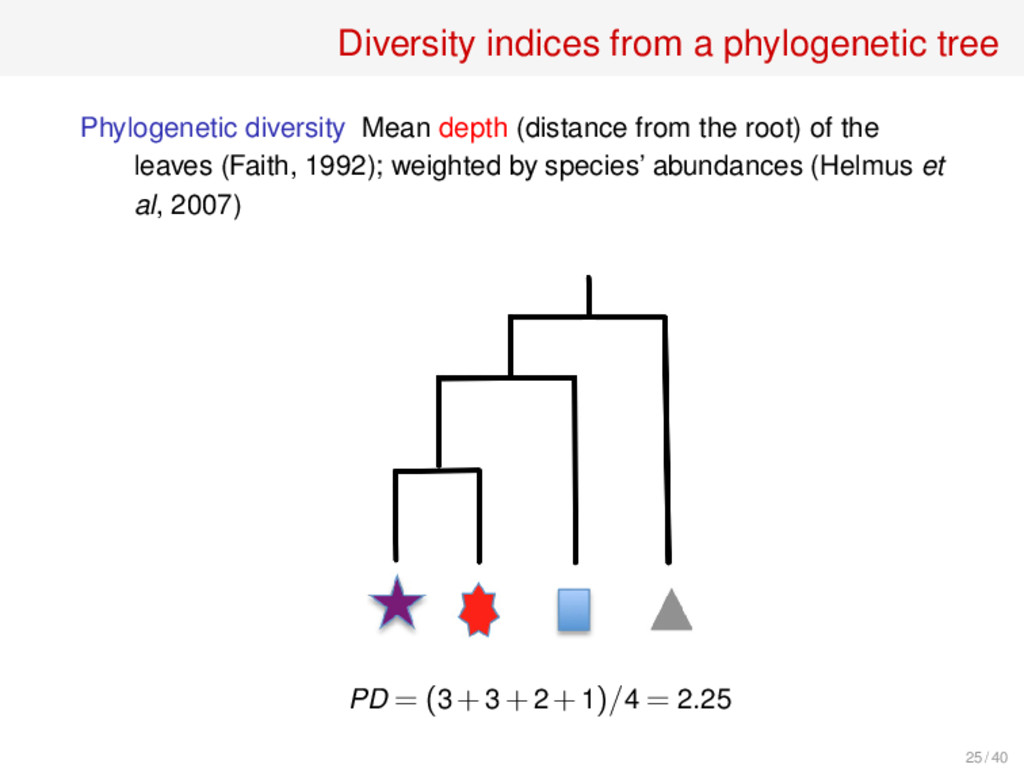
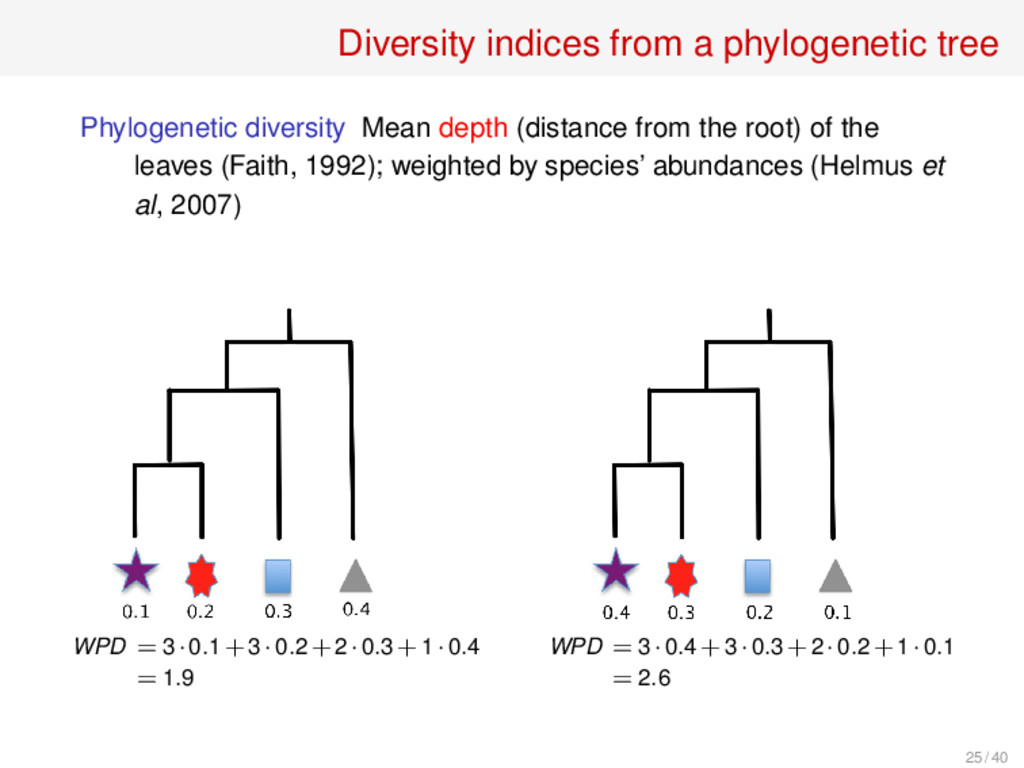
the leaves (Faith, 1992); weighted by species’ abundances (Helmus et al, 2007) Mean phylogenetic distance Mean of the distances between pairs of leaves (Webb, 2000); weighted by species’ abundances (Bell, 2001) Mean nearest neighbour distance Mean of the distances of each leaf to its closest leaf (Webb, 2000); no weighted version Variabilities Variances, instead of means, of the previous values Cophenetic index Mean depth of the least common ancestor of a pair of leaves (UIB, 2013); weighted version in progress 26 such indices compared in S. Pavoine, M. Bonsall, Biol. Rev. 86 (2011), 792–812 26 / 40
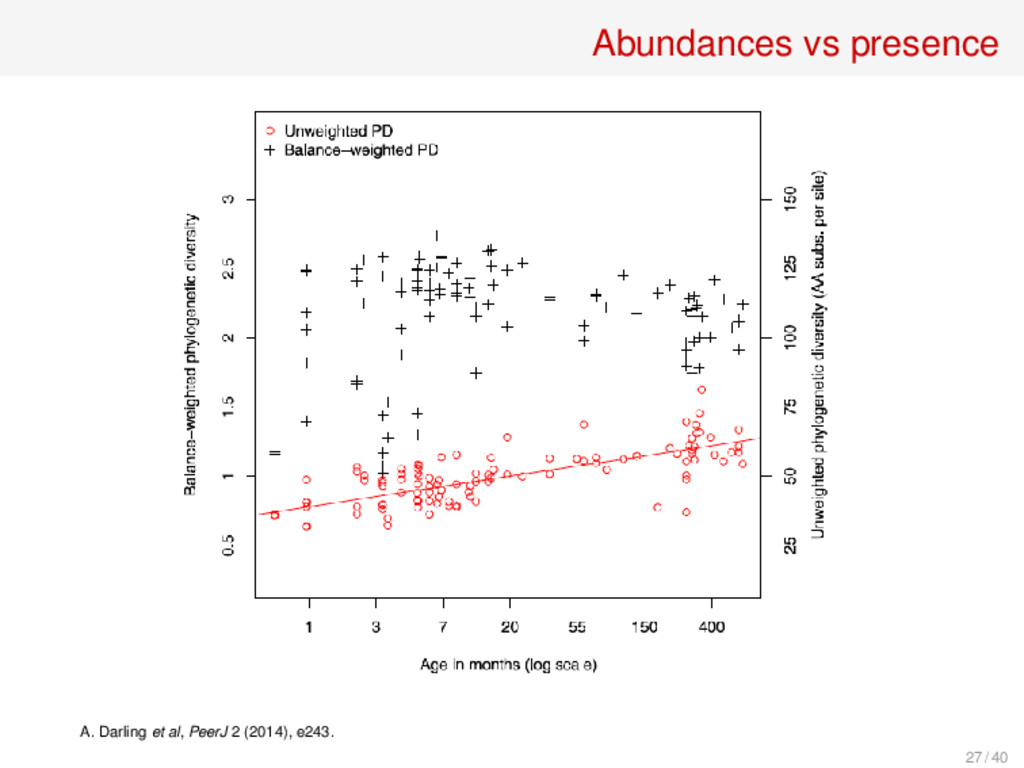
reads, sequences) • For every edge e of a phylogenetic tree T, De (σ) is the fraction of reads in σ at the descendant leaves of e BWPDθ (σ) = ∑ e edges e ·De (σ)θ θ = 0 yields PD, θ = 1 yields ∼ WPD BWPD0.25 and BWPD0.5 always in top 5 indices as classifiers of different types of human microbiomes C. O. McCoy, F. Matsen IV, PeerJ 1 (2013), e157. 28 / 40
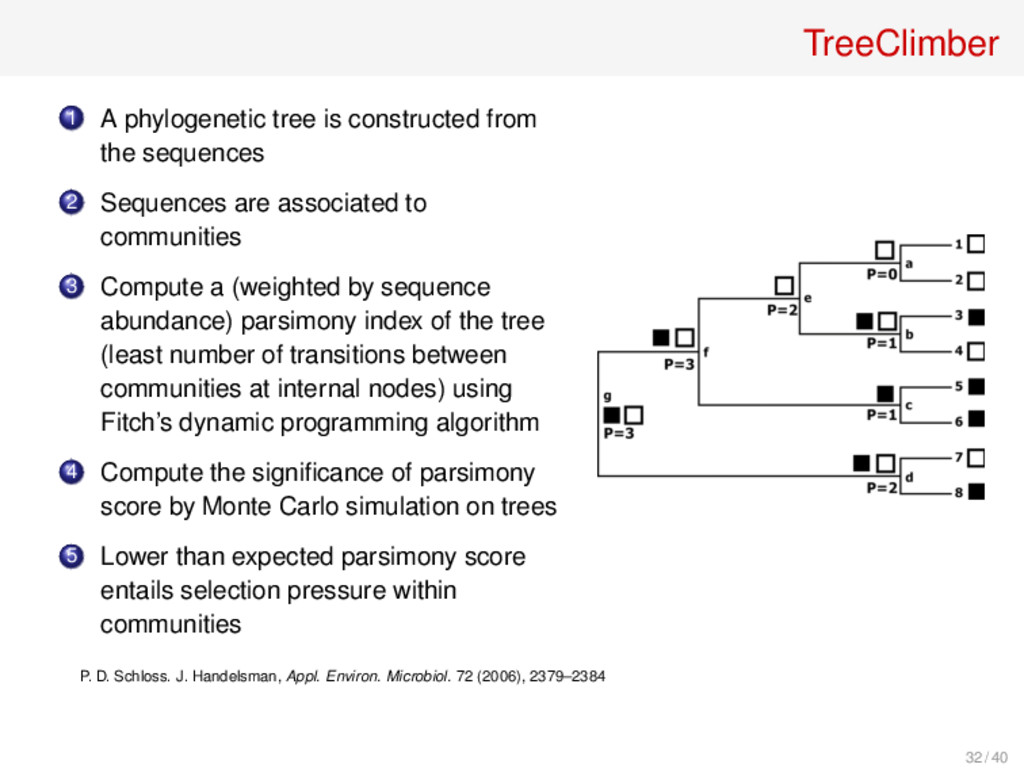
and the phylogenetic differences observed between them are due to an accumulation of random variation. Departure from randomly joining trees occur when communities experience some effect that causes species to be either gained or lost. Selection pressure entails that populations of similar members are more likely to appear in a single community. P. D. Schloss, J. Handelsman, Appl. Environ. Microbiol. 72 (2006), 2379–2384 31 / 40
2 Sequences are associated to communities 3 Compute a (weighted by sequence abundance) parsimony index of the tree (least number of transitions between communities at internal nodes) using Fitch’s dynamic programming algorithm 4 Compute the significance of parsimony score by Monte Carlo simulation on trees 5 Lower than expected parsimony score entails selection pressure within communities P. D. Schloss. J. Handelsman, Appl. Environ. Microbiol. 72 (2006), 2379–2384 32 / 40
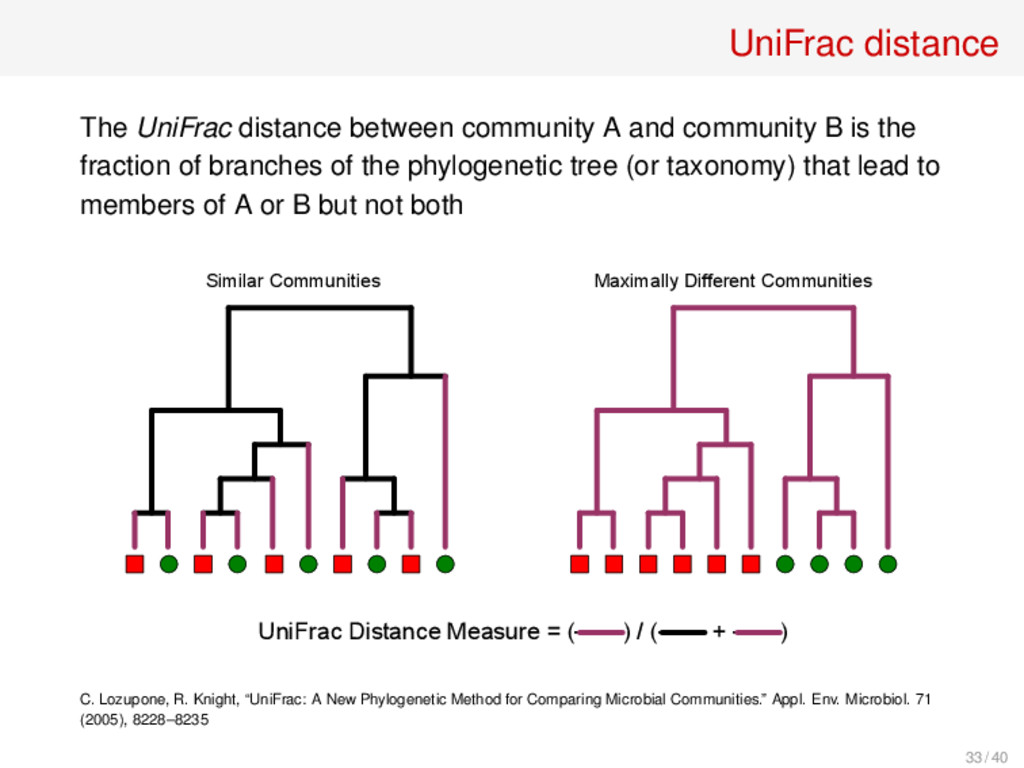
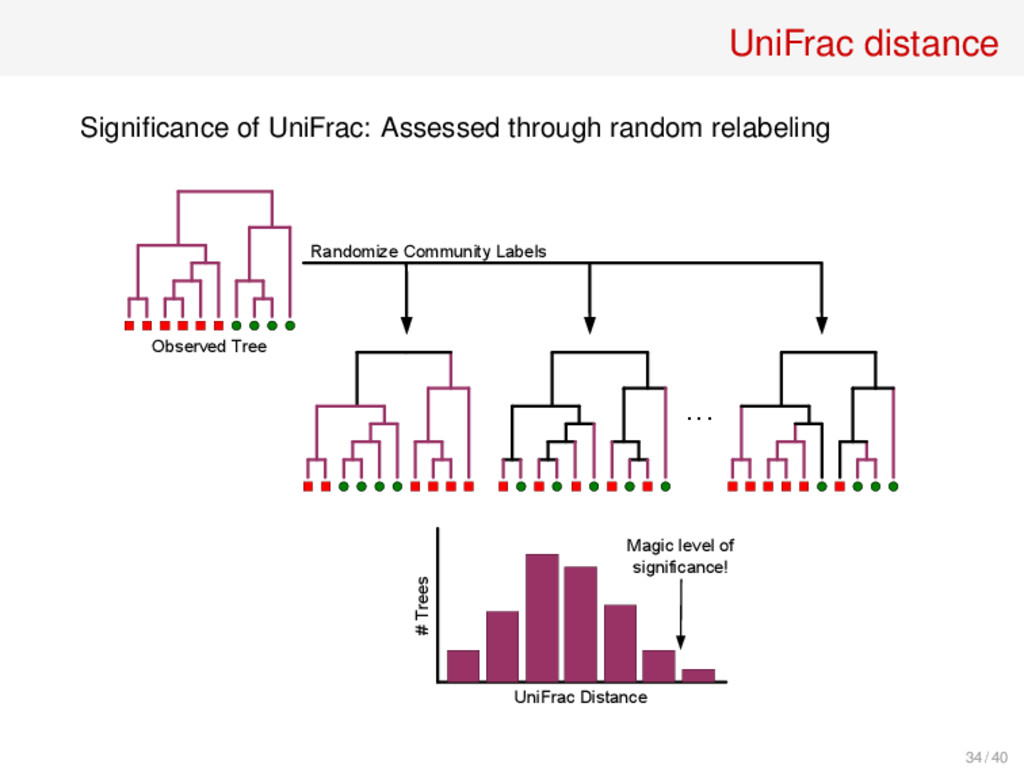
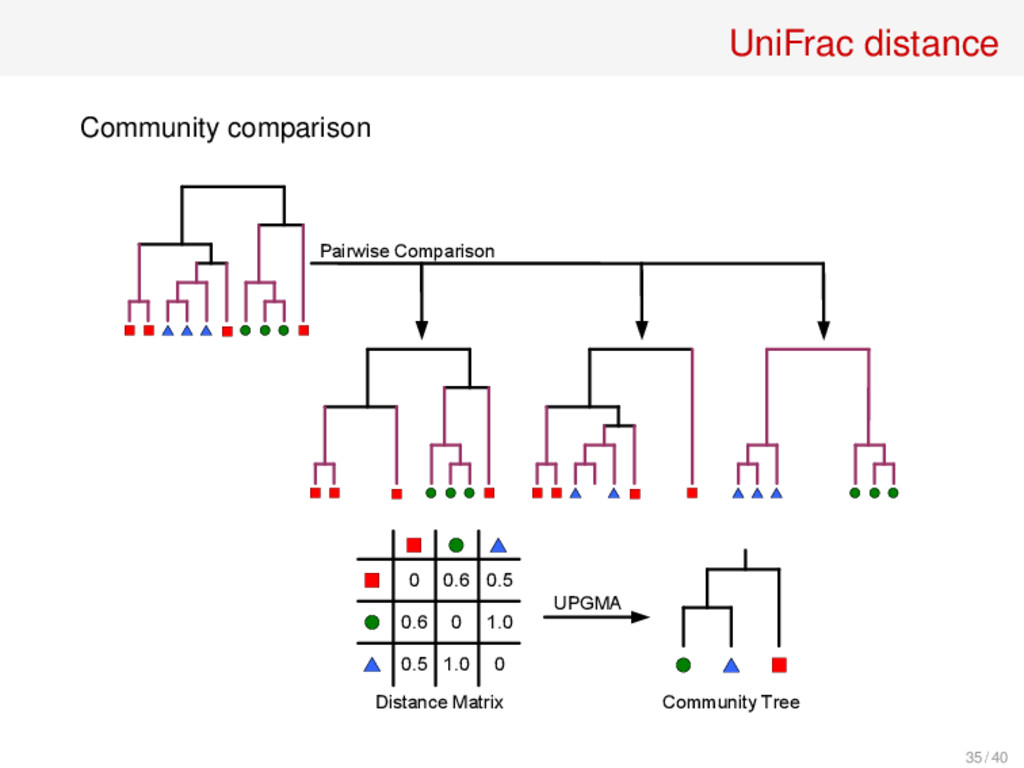
B is the fraction of branches of the phylogenetic tree (or taxonomy) that lead to members of A or B but not both Similar Communities Maximally Different Communities UniFrac Distance Measure = (------) / (------ + ------) C. Lozupone, R. Knight, “UniFrac: A New Phylogenetic Method for Comparing Microbial Communities.” Appl. Env. Microbiol. 71 (2005), 8228–8235 33 / 40
(A,B) = ∑ i i |pA i −pB i | ∑ i i (pA i +pB i ) d(α)(A,B) = ∑ i i (pA i +pB i )α |pA i −pB i | pA i +pB i ∑ i i (pA i +pB i )α where • i the length of branch i • pA i and pB i are the taxa proportions descending from the branch i for community A and B dW (A,B): C. Lozupone et al, Appl. Environ. Microbiol. 73 (2007), 1576–1585. d(α): J. Chen et al, Bioinformatics 28 (2012), 2106–2113 36 / 40
PCA, PCoA etc. • Hierarchical clustering • Split networks • Metagenomes are not expected to evolve along a tree • Allows the visualization of incompatible clusters 37 / 40
• Many indices measuring phylogenetic richness and homogeneity • Many indices measuring community composition differences • Several indices measuring community phylogenetic composition differences • I have skipped the spatial component of diversity • No one-size-fits-it-all index in any category • Metagenomics poses its own problems, due to the nature and amount of the data 40 / 40
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}