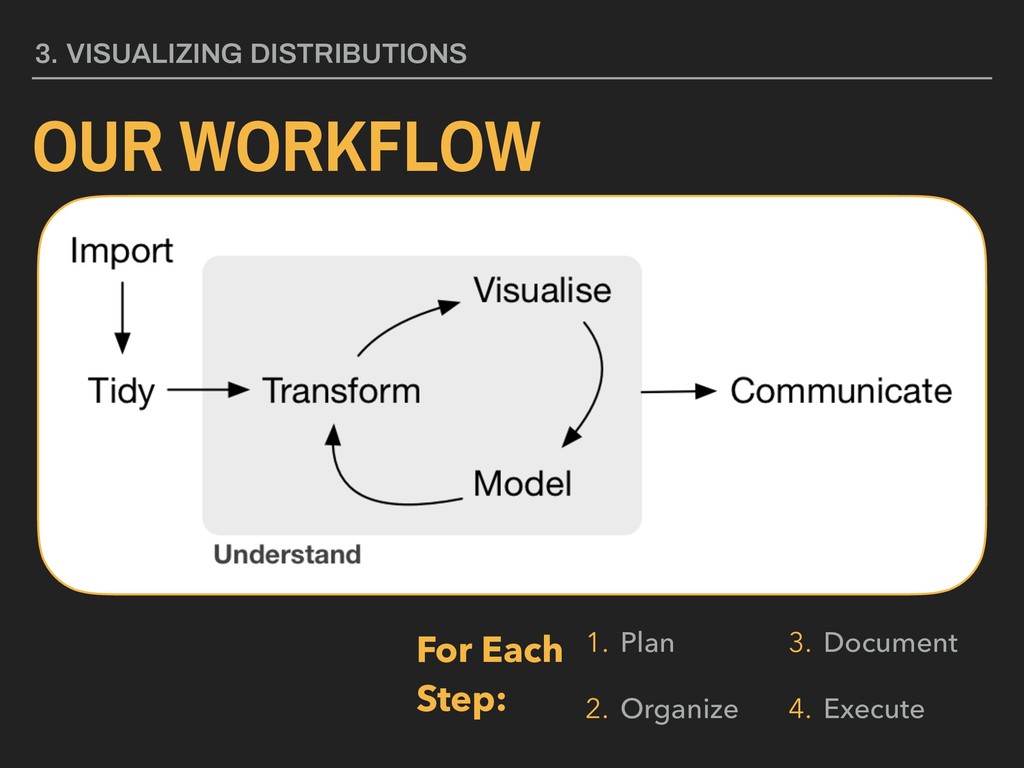
Slides for Lecture 03 of the Saint Louis University Course Quantitative Analysis: Applied Inferential Statistics. These slides cover descriptive statistics and the importance of data visualization.
Please make sure you have installed in on your laptop or desktop (it cannot be pre-installed on SLU computers). Open it up and log in if you are prompted. Go to Preferences if not prompted (in menu on macOS or File menu on Windows). WELCOME! GETTING STARTED There is an anonymous entry ticket to complete (link posted in Slack’s #_news channel)
all due today Lab-02, PS-01, and LP-04 are due before Lecture-04 Final project data for the 2016 General Social Survey is now available on GitHub (linked to via “Final Project” page on course website) 1. FRONT MATTER ANNOUNCEMENTS Final project progress report due at Lecture-05; focus on Vignettes 2 & 4
resources on GitHub • Link to topic index entries that allow you to see all weeks in which specific topics were covered; package index links to documentation • Link to syllabus (and vice versa) ▸ Make sure you’re checking in with the #_news channel on Slack ▸ Post questions in #helpdesk… channels on Slack and celebrate victories in #weekly-wins • Important threads are being catalogued on the lecture webpages 1. FRONT MATTER
you keep different versions of files as your assignment or project progresses? ▸ If you needed your files in 5 years, could you find them? ▸ If you needed your files in 5 years, could you open them? ▸ Do you backup files ever? ▸ If your house was robbed or burned down, would your backup also be destroyed? 2. GETTING ORGANIZED
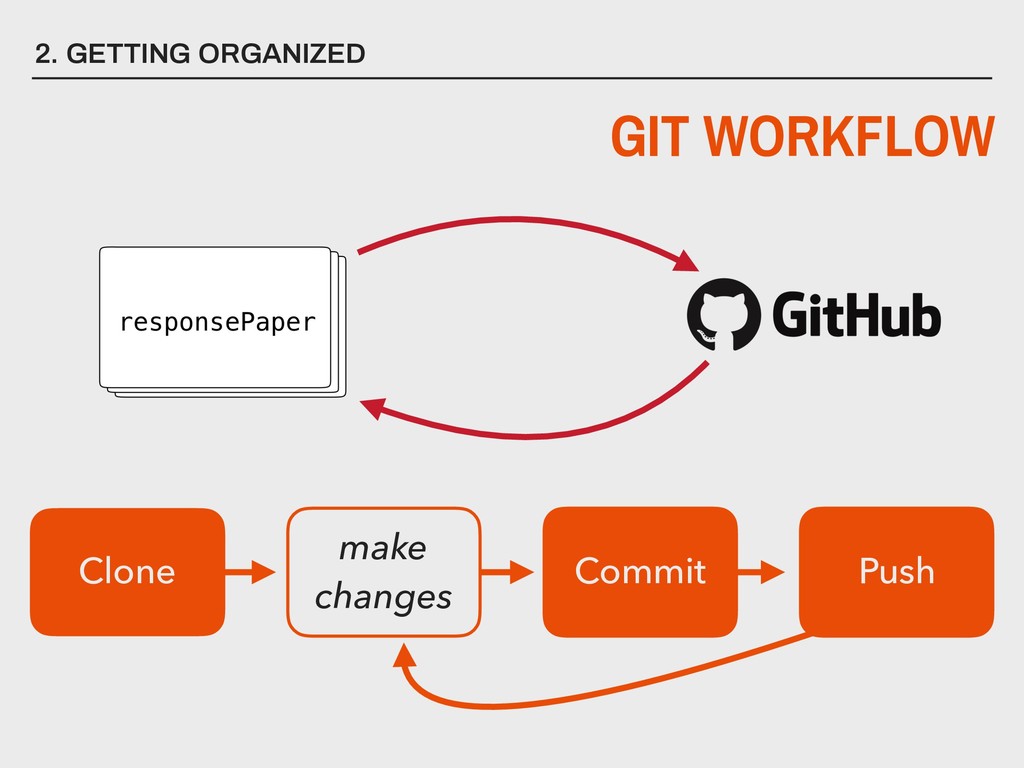
you keep different versions of files as your assignment or project progresses? ▸ If you needed your files in 5 years, could you find them? ▸ If you needed your files in 5 years, could you open them? ▸ Do you backup files ever? ▸ If your house was robbed or burned down, would your backup also be destroyed? 2. GETTING ORGANIZED Git & GitHub can help you address all of these key questions/issues!
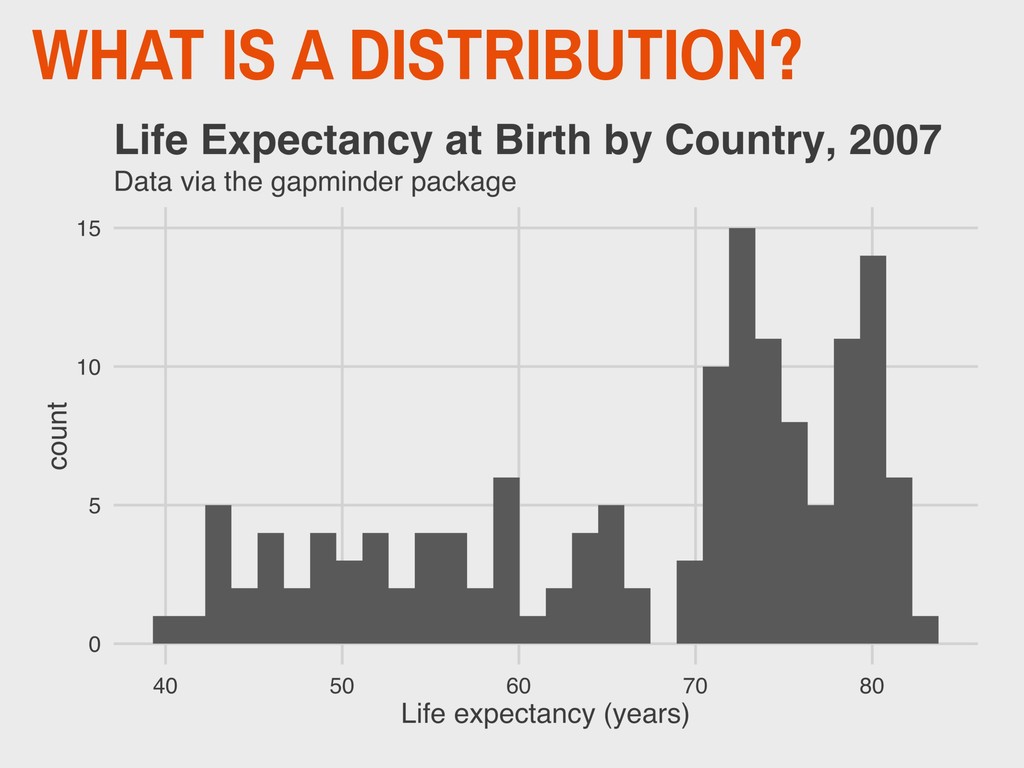
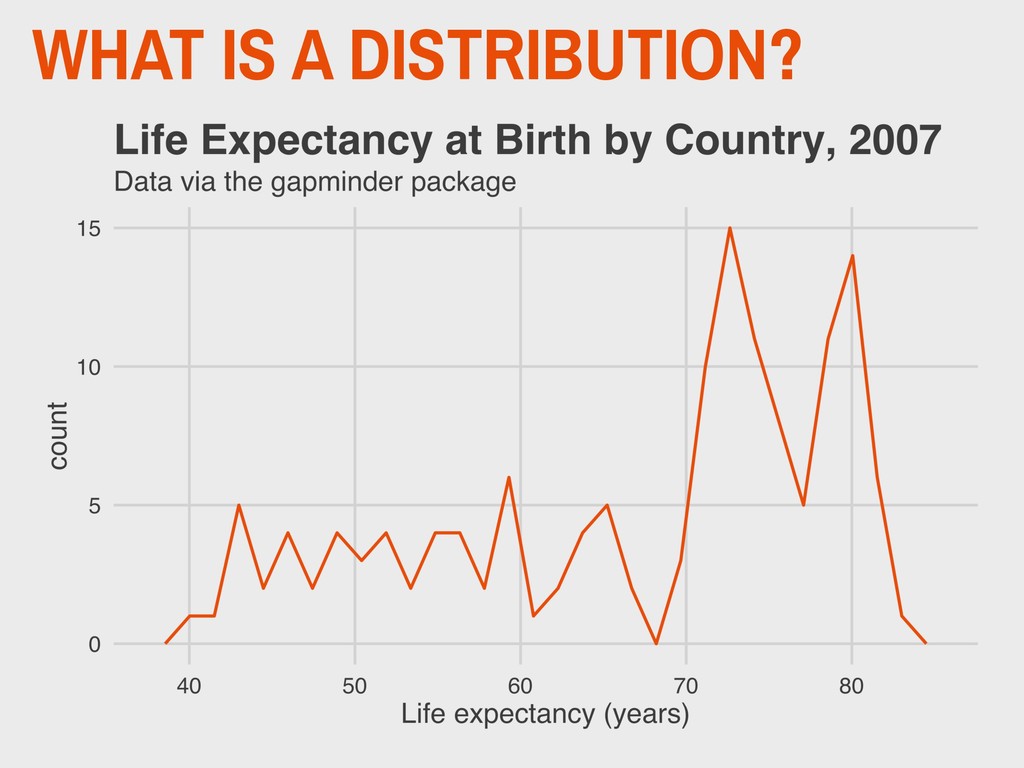
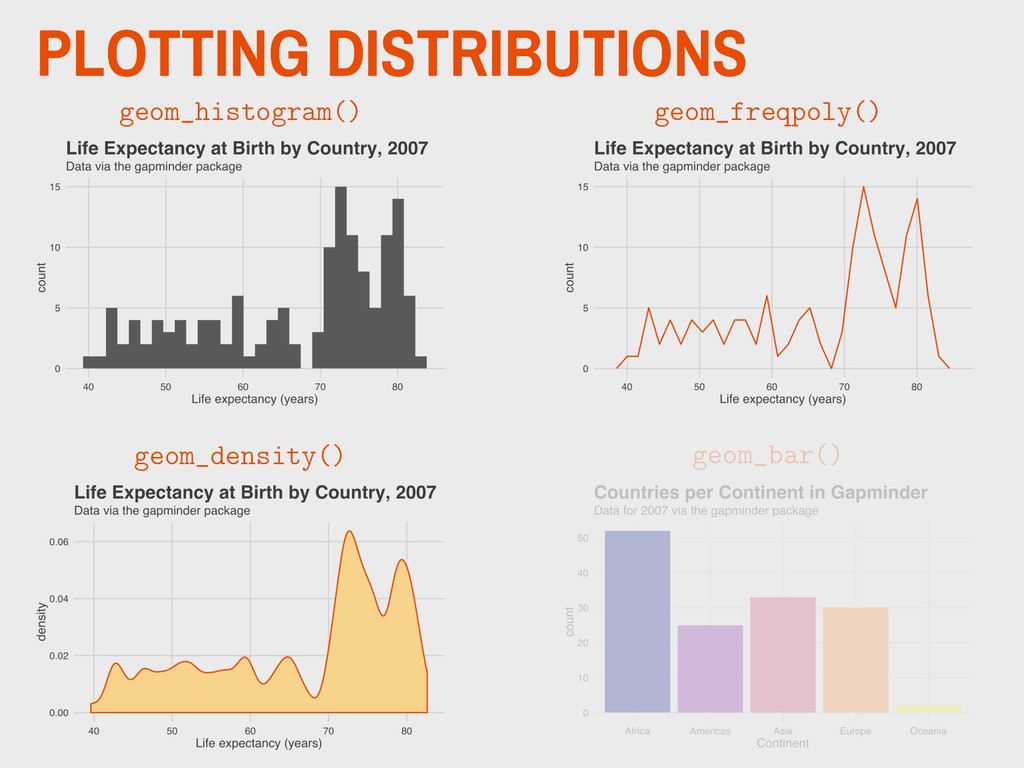
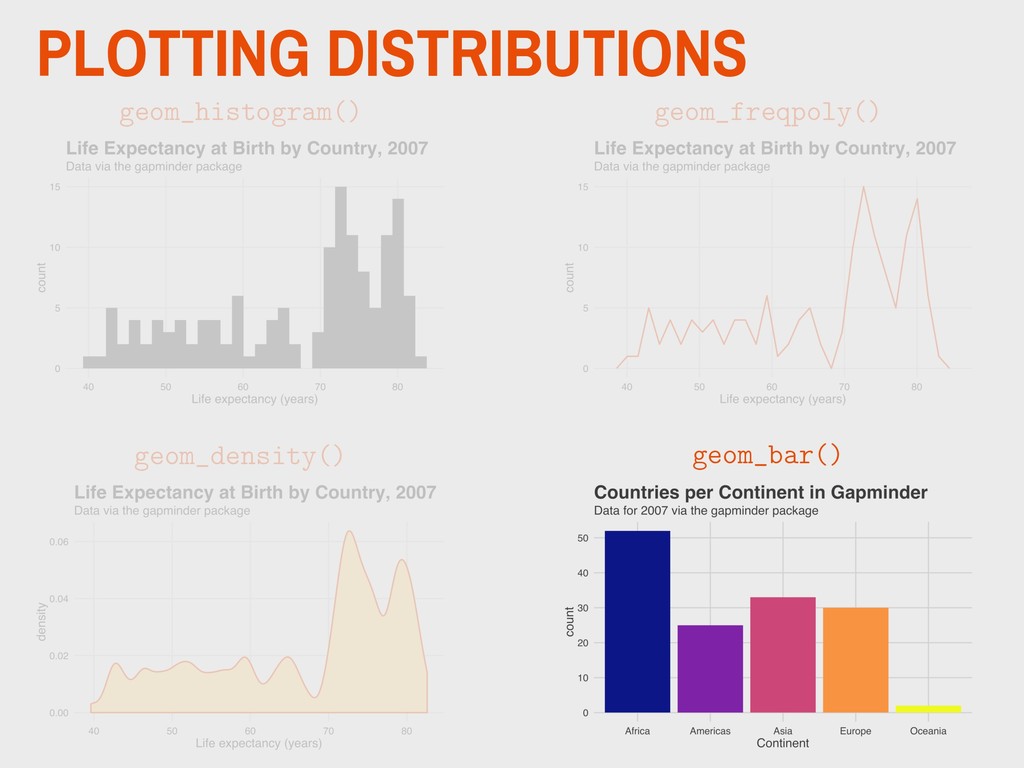
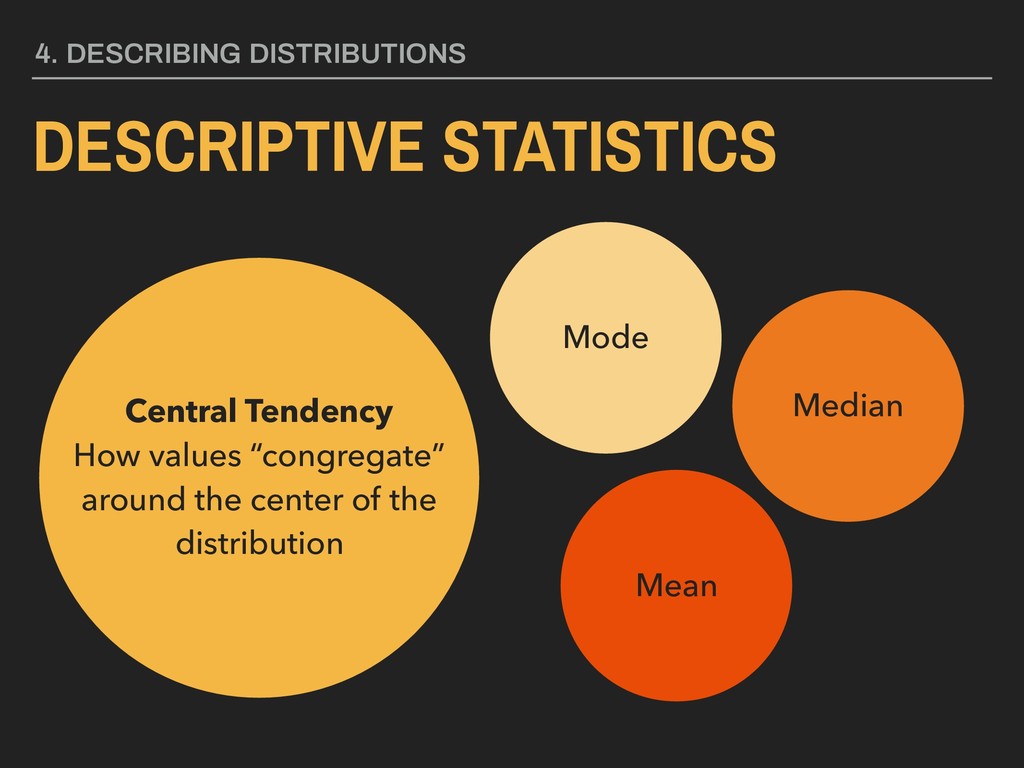
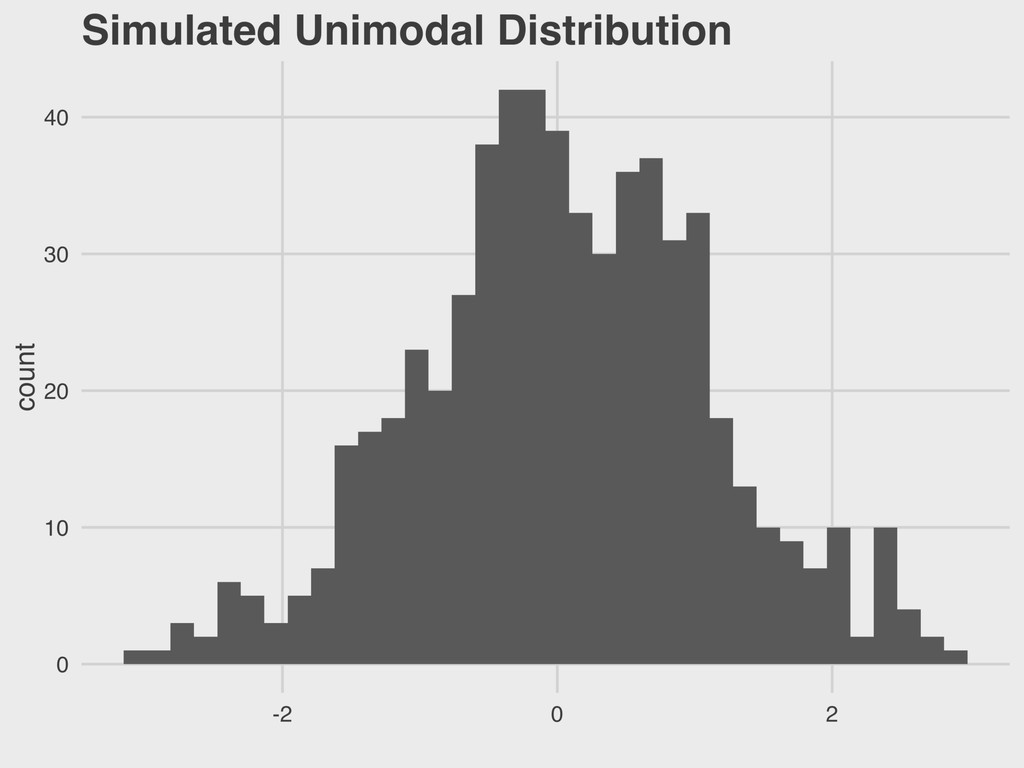
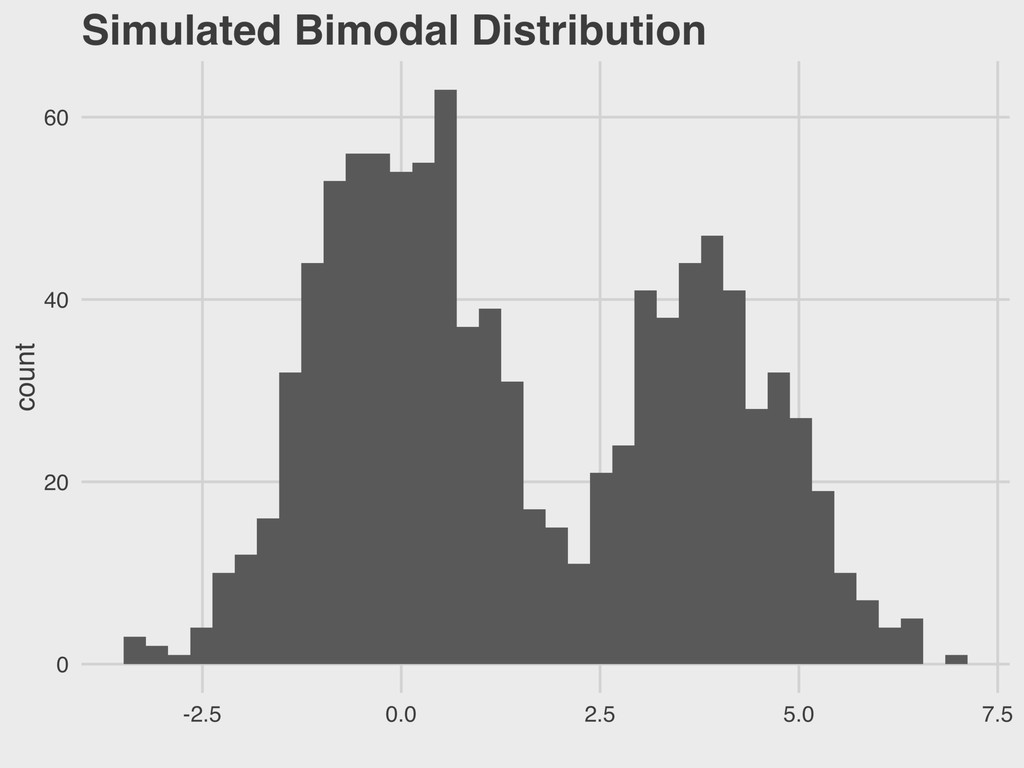
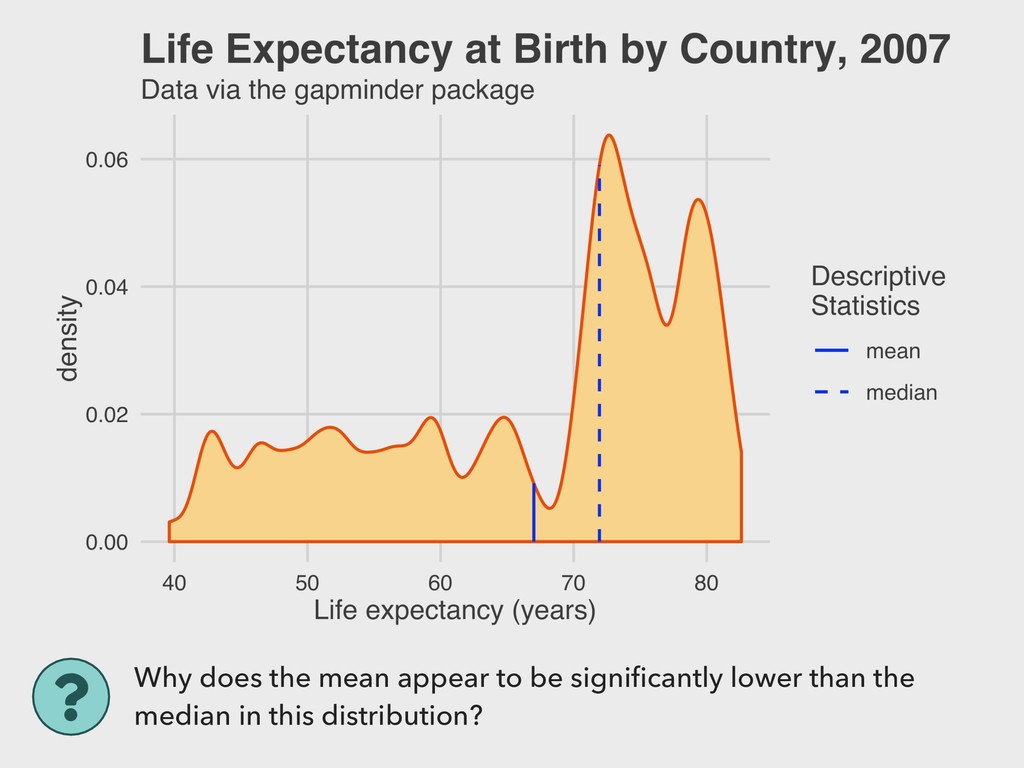
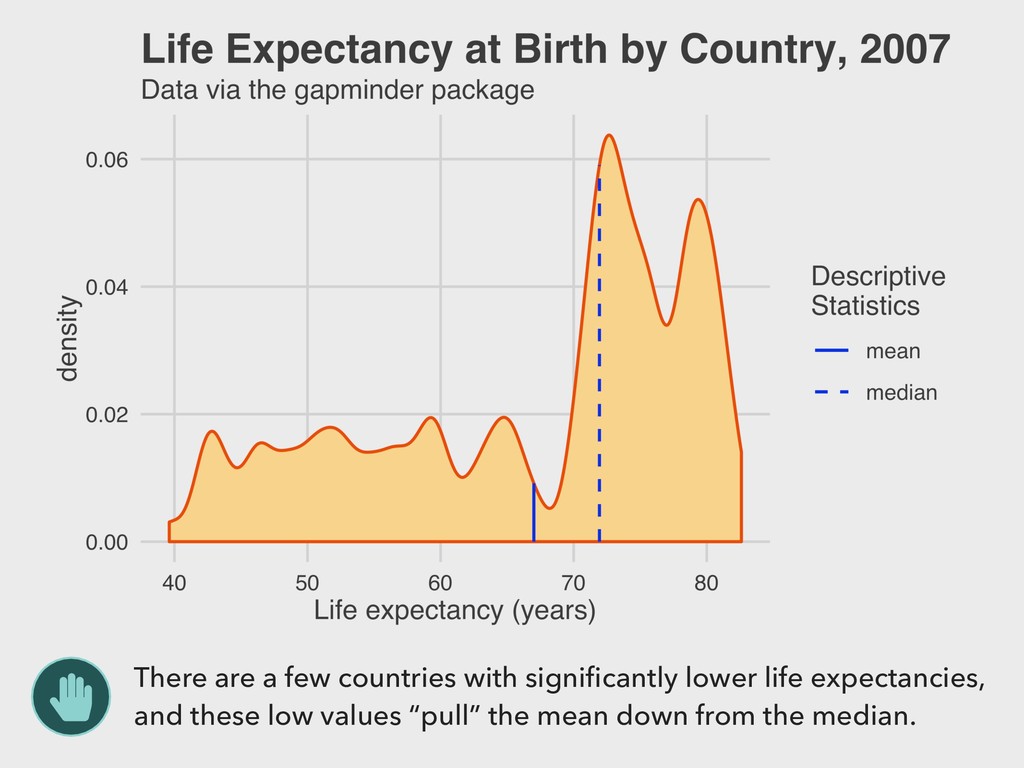
1965 ▸ His 1977 book Exploratory Data Analysis advocated the use of visual methods to: - Gain insight into data, particularly the underlying “structure” (i.e. distribution) - Identify relevant variables - Detect anomalies - Check assumptions 3. VISUALIZING DISTRIBUTIONS EDA JOHN TUKEY
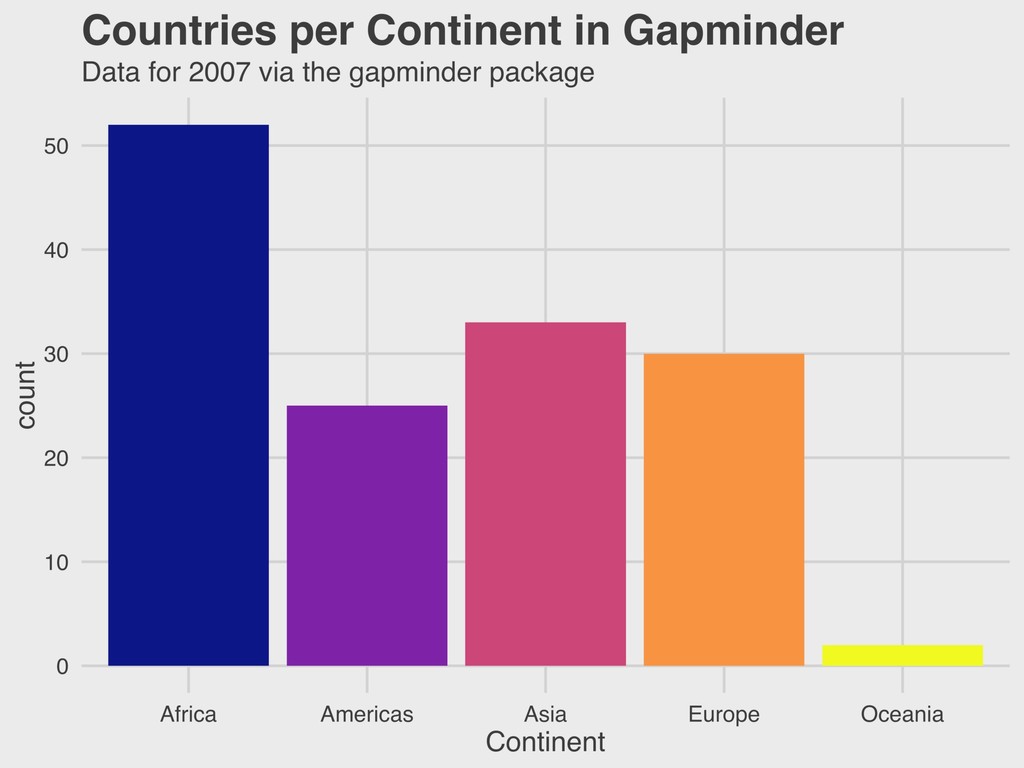
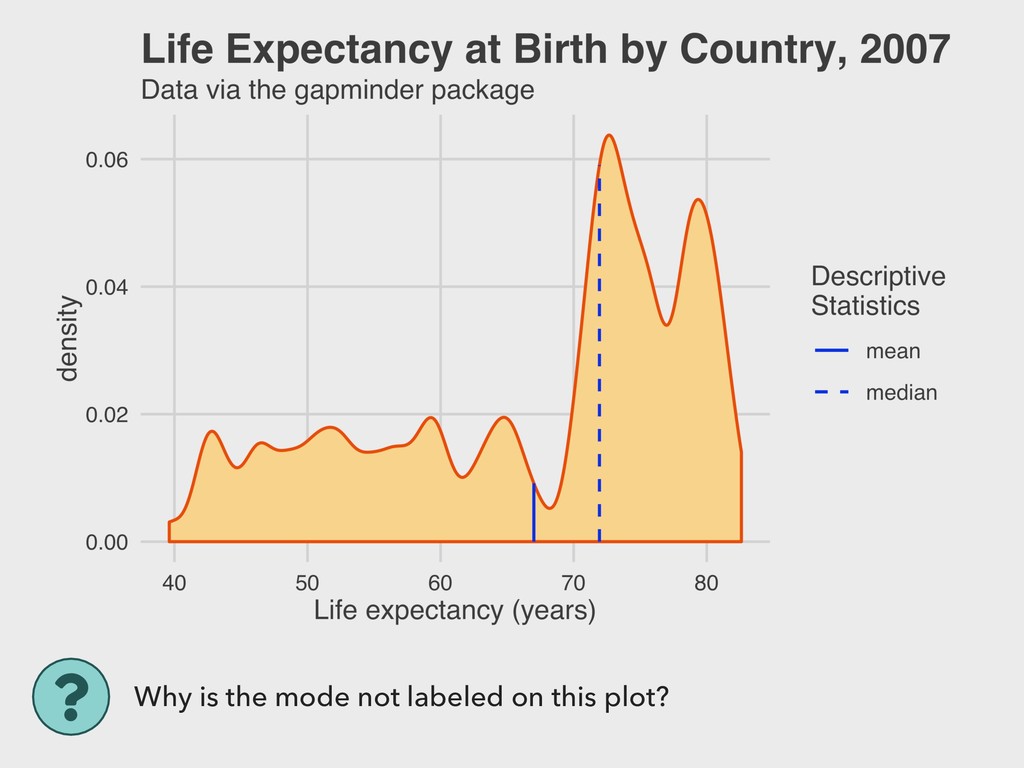
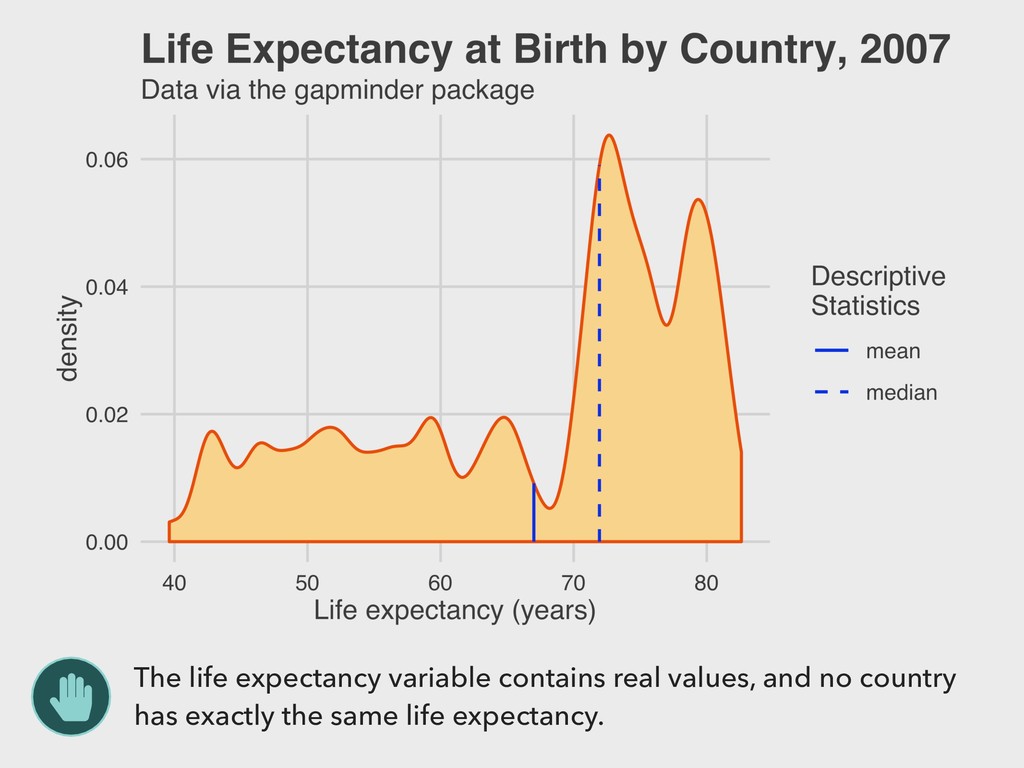
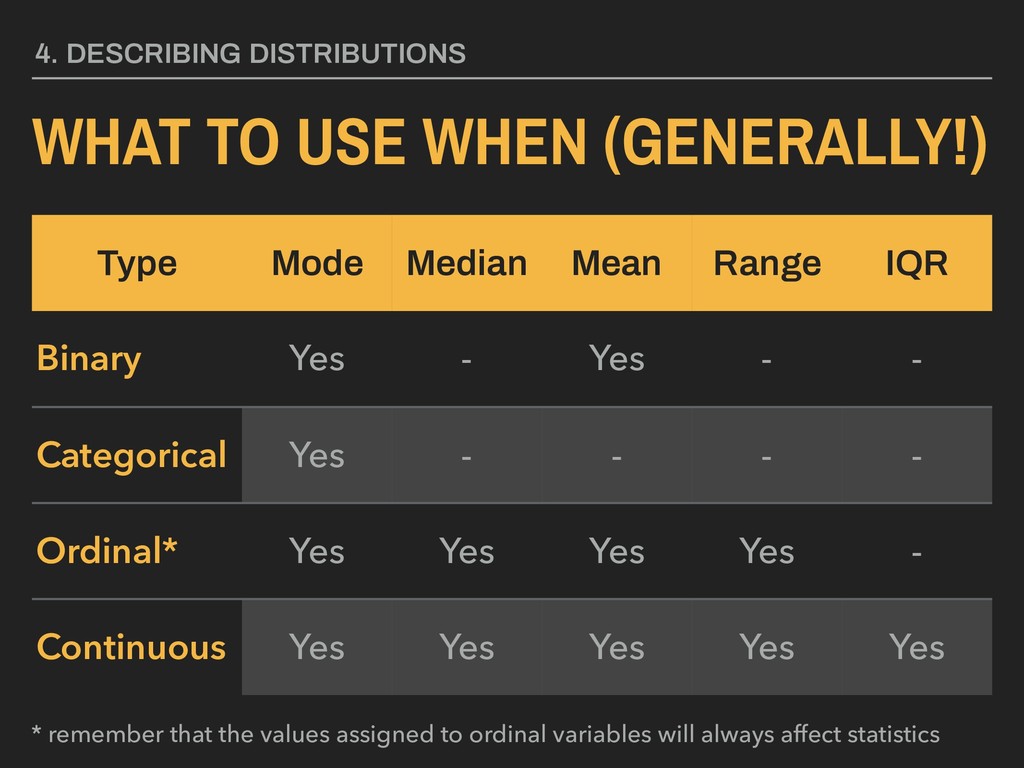
vector. ▸ This is easiest to visualize for nominal data in either table or bar plot form… ▸ …but can also be used to describe other types of variables. ▸ There is no direct R function for calculating this. The easiest way is to look at a frequency table. 4. DESCRIBING DISTRIBUTIONS MODE > mortality %>% + tabyl(continent) continent n percent Africa 52 0.36619718 Americas 25 0.17605634 Asia 33 0.23239437 Europe 30 0.21126761 Oceania 2 0.01408451
the vector. ▸ This can be easily calculated in R using the stats::median() function. ▸ Calculating median by hand varies based on whether or not there are an even number of values in the vector or not. 4. DESCRIBING DISTRIBUTIONS
xa = the next lower value below position ma ▸ xb = the next higher value above position ma 4. DESCRIBING DISTRIBUTIONS Let: MEDIAN (EVEN, STEP 2) mb = ( xa + xb 2 )
vector. ▸ This can be easily calculated in R using the stats::mean() function. ▸ Calculating mean by hand involves the use of sigma or summation notation ▸ Greek letter (“mu”) used for referring to the population mean, which is often theoretical, meaning we cannot directly measure it ▸ The mean is the first moment of a distribution 4. DESCRIBING DISTRIBUTIONS
lower bound ▸ n = upper bound; n is typically used because we want to iterate over the entire vector until its last item ▸ xi = operation 4. DESCRIBING DISTRIBUTIONS Let: SIGMA NOTATION n ∑ i=m xi
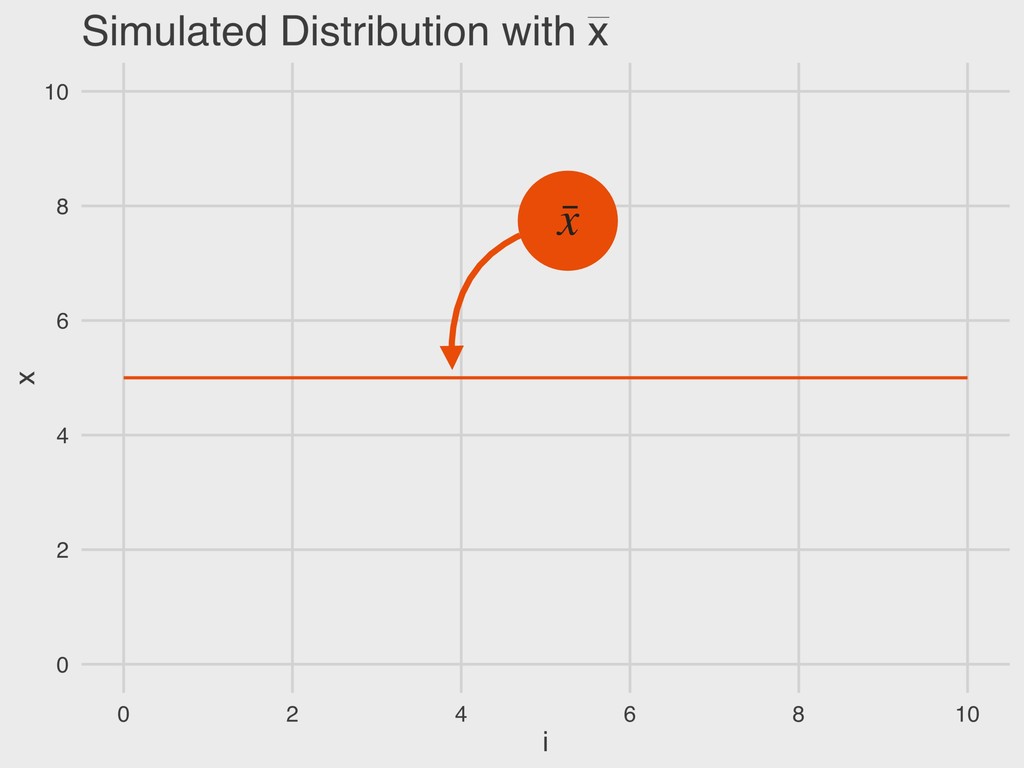
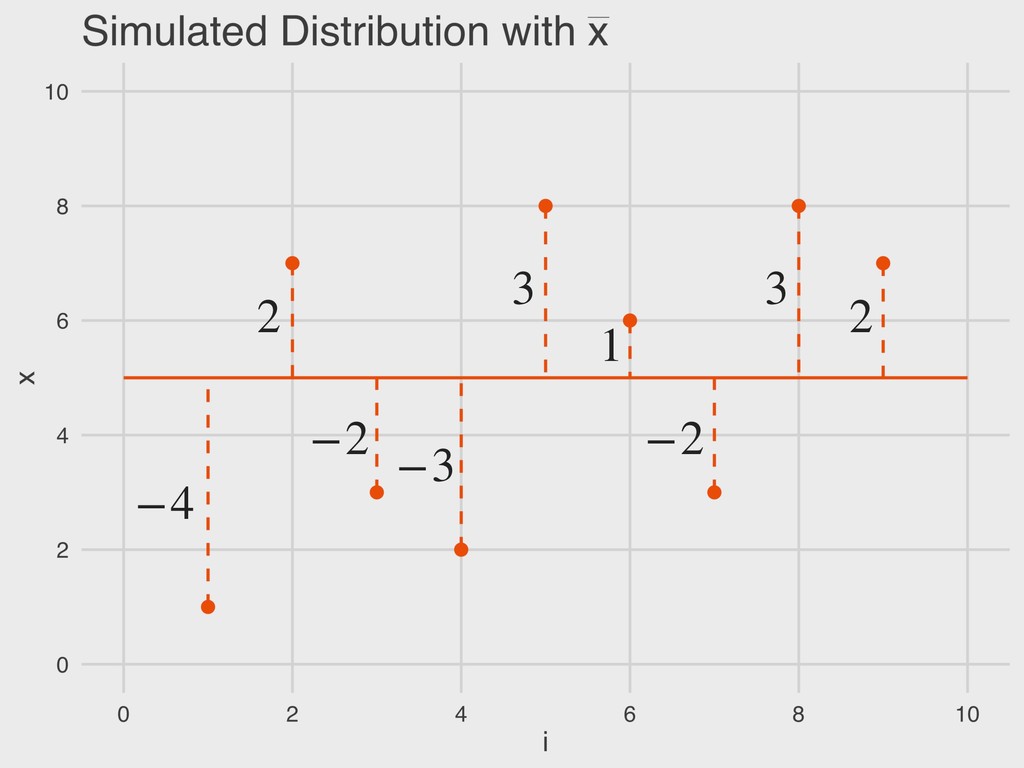
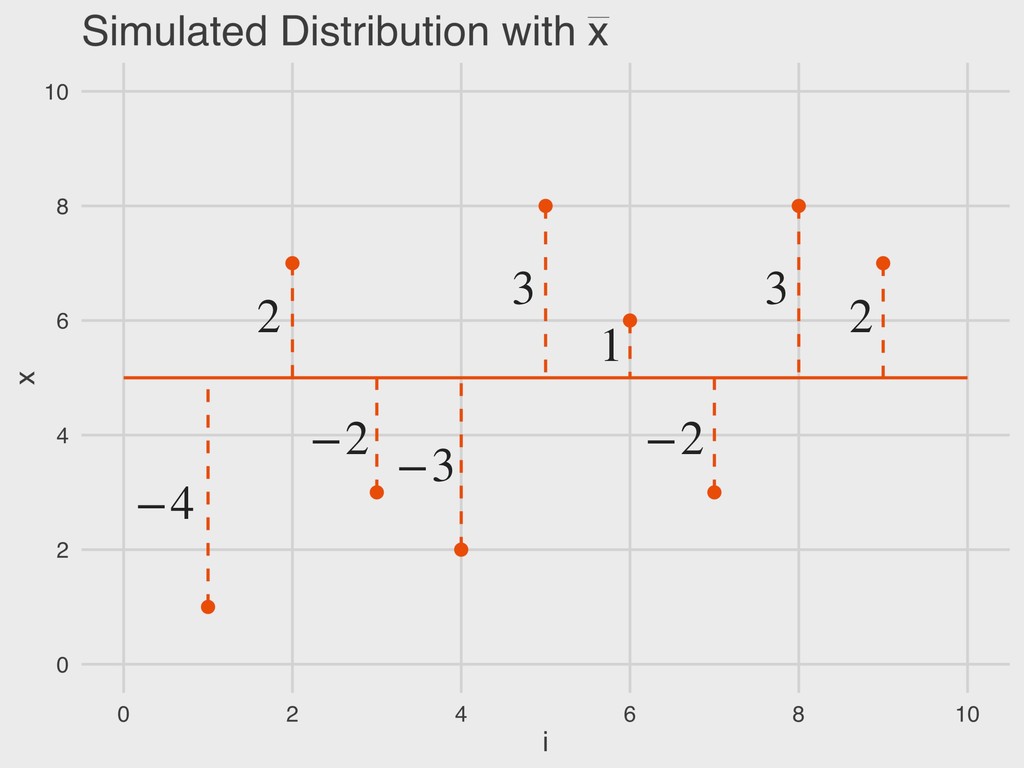
n = sample size ▸ xi = a given value in the vector “The sample mean is equal to the sum of all values of x in the vector divided by the total number of observations (n).” 4. DESCRIBING DISTRIBUTIONS Let: SAMPLE MEAN ¯ x = ∑n i=1 xi n ¯ x
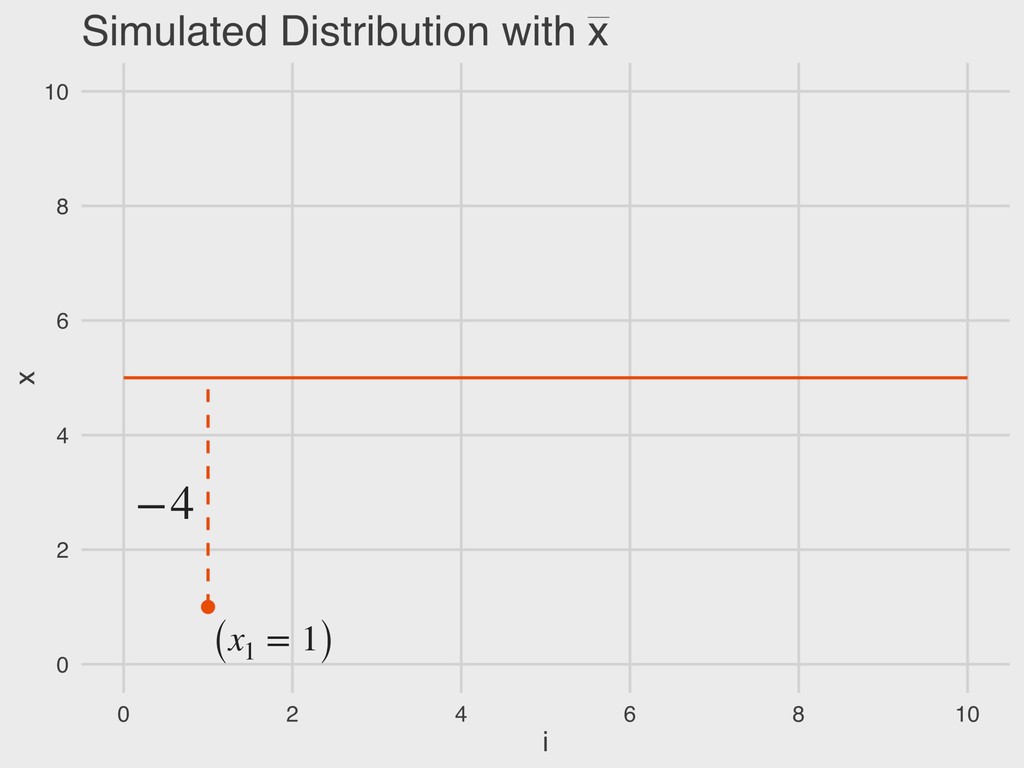
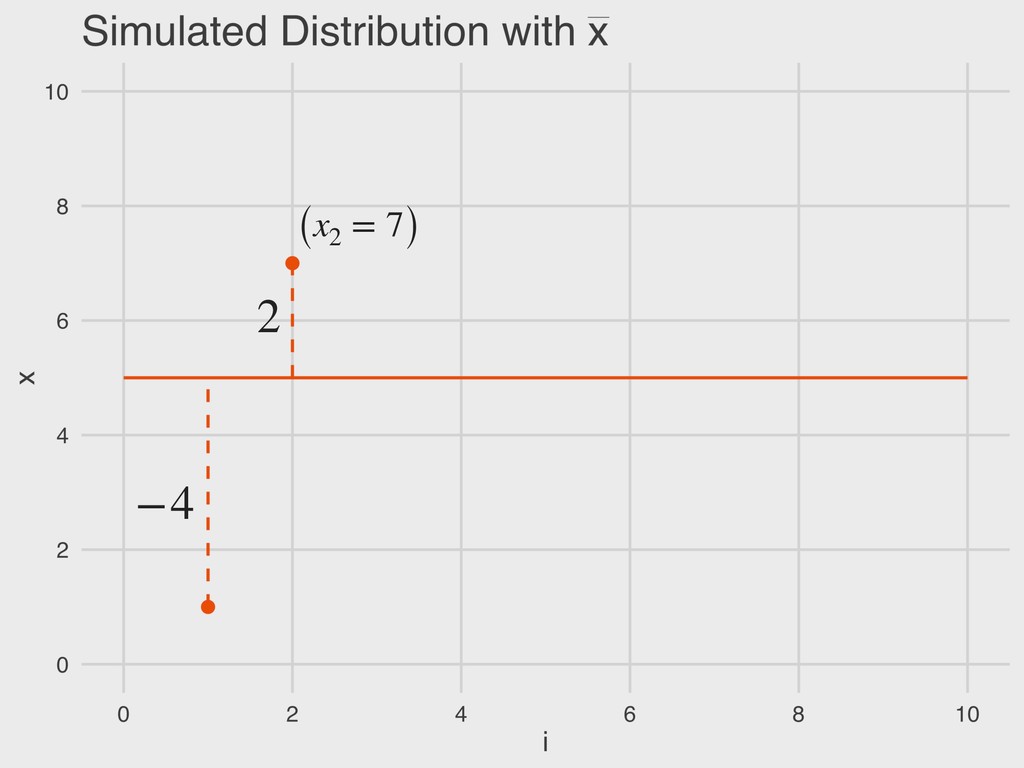
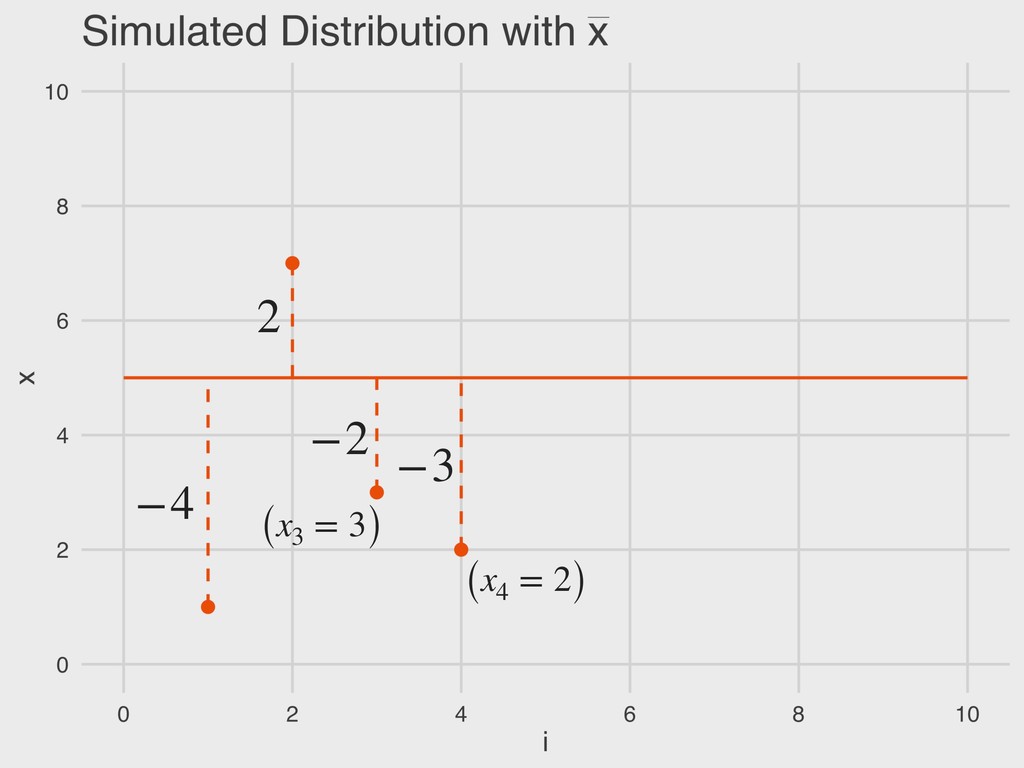
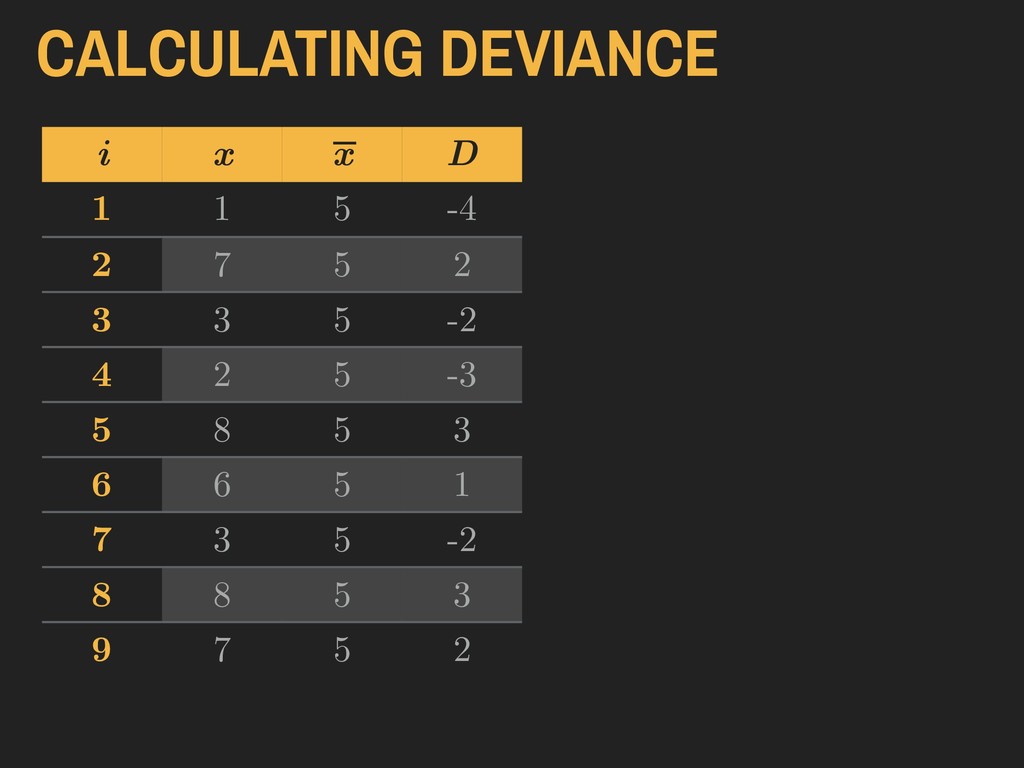
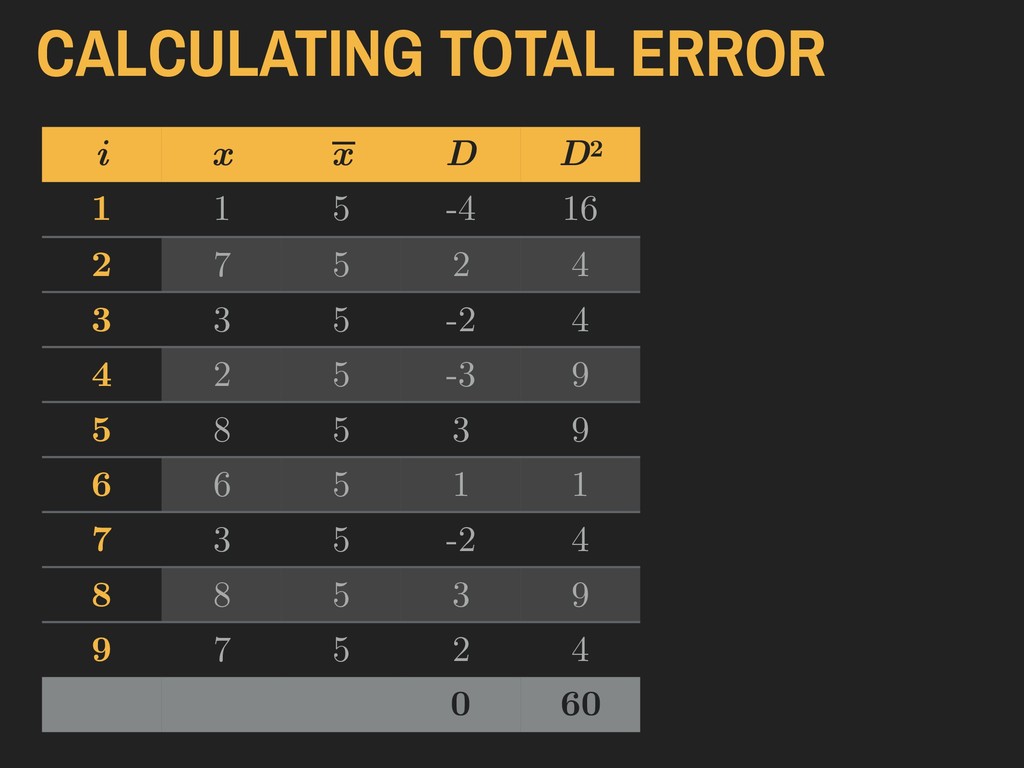
= a given value in the vector “The deviance (D) is the difference between a given value of x and the sample mean ( ).” 4. DESCRIBING DISTRIBUTIONS Let: DEVIANCE D = (x − ¯ x) ¯ x ¯ x
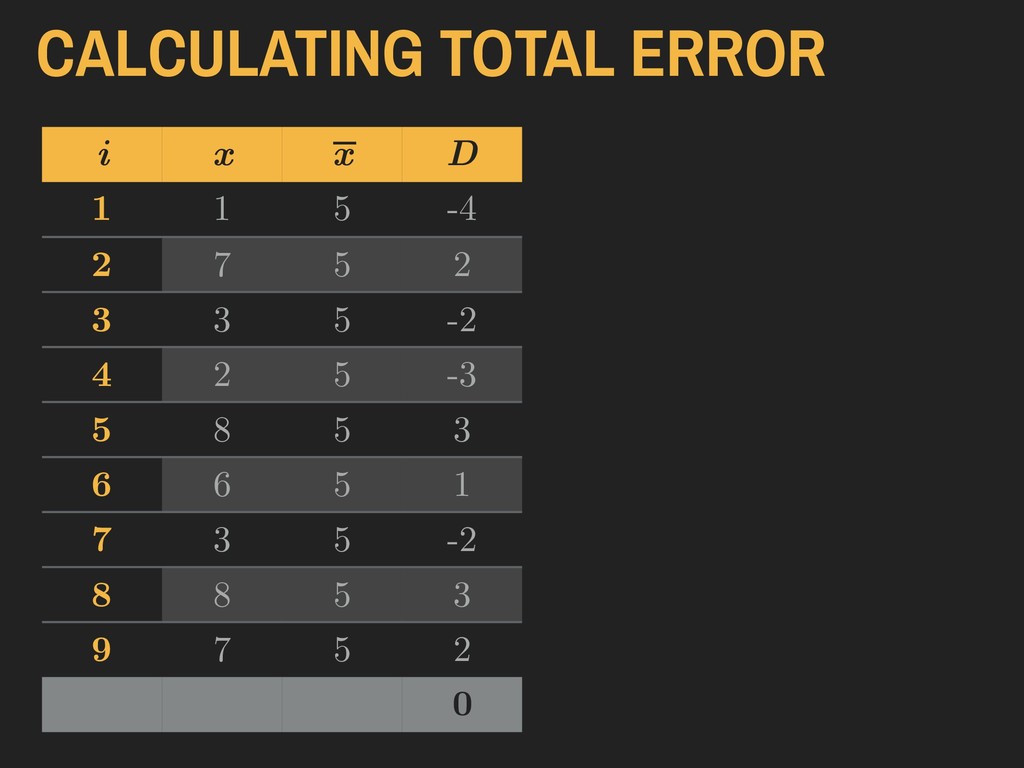
x = a given value in the vector ▸ n = sample size “The total error is the sum of all deviance values. Total error should always be zero.” 4. DESCRIBING DISTRIBUTIONS Let: TOTAL ERROR TE = n ∑ i=1 (x − ¯ x) ¯ x
x = a given value in the vector ▸ n = sample size “The sum of squared error is the sum of all squared deviance values.” 4. DESCRIBING DISTRIBUTIONS Let: SUM OF SQUARED ERROR SS = n ∑ i=1 (x − ¯ x)2 ¯ x
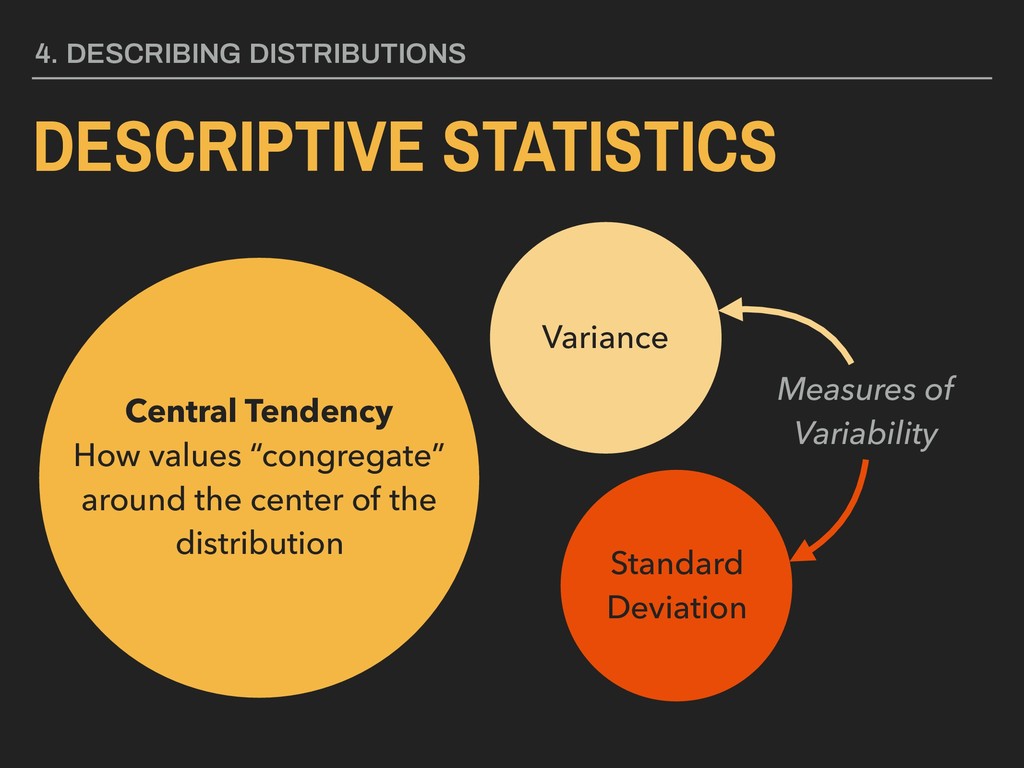
varies from the mean. ▸ This can be easily calculated in R using the stats::var() function. ▸ Greek letter 2 (“sigma”) used for referring to the population variance ▸ The variance is the second moment of a distribution 4. DESCRIBING DISTRIBUTIONS
= a given value in the vector ▸ n = sample size “The variance is the sum of square error divided by n minus 1 degrees of freedom.” 4. DESCRIBING DISTRIBUTIONS Let: SAMPLE VARIANCE s2 = ∑n i=1 (x − ¯ x)2 n − 1 ¯ x
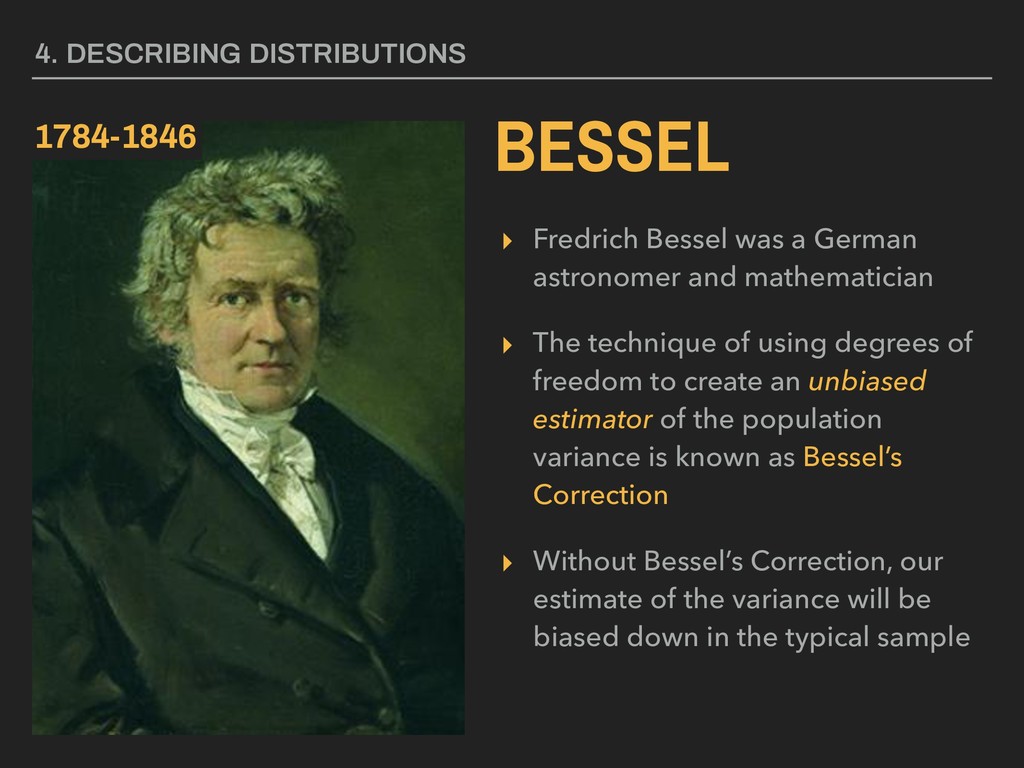
for the Guinness Brewery in Dublin, Ireland at the turn of the 20th century ▸ His 1908 article “The Probable Error of a Mean” established the modern use of degrees of freedom ▸ Gosset published under the pen name “Student” to avoid betraying Guinness trade secrets 4. DESCRIBING DISTRIBUTIONS GOSSET 1876-1937
was faculty at University College London and Cambridge ▸ He established the term degrees of freedom ▸ He also established a number of other techniques we’ll use this semester ▸ Fisher, like many of his contemporaries, was a eugenicist 4. DESCRIBING DISTRIBUTIONS FISHER 1890-1962
four day vacation, and have one shirt for each of the four days. By the time you reach the fourth and final day of your trip, you have no choices left - you must wear the orange shirt. You had n-1 (4-1=3) days in which you had freedom to over what you wore.
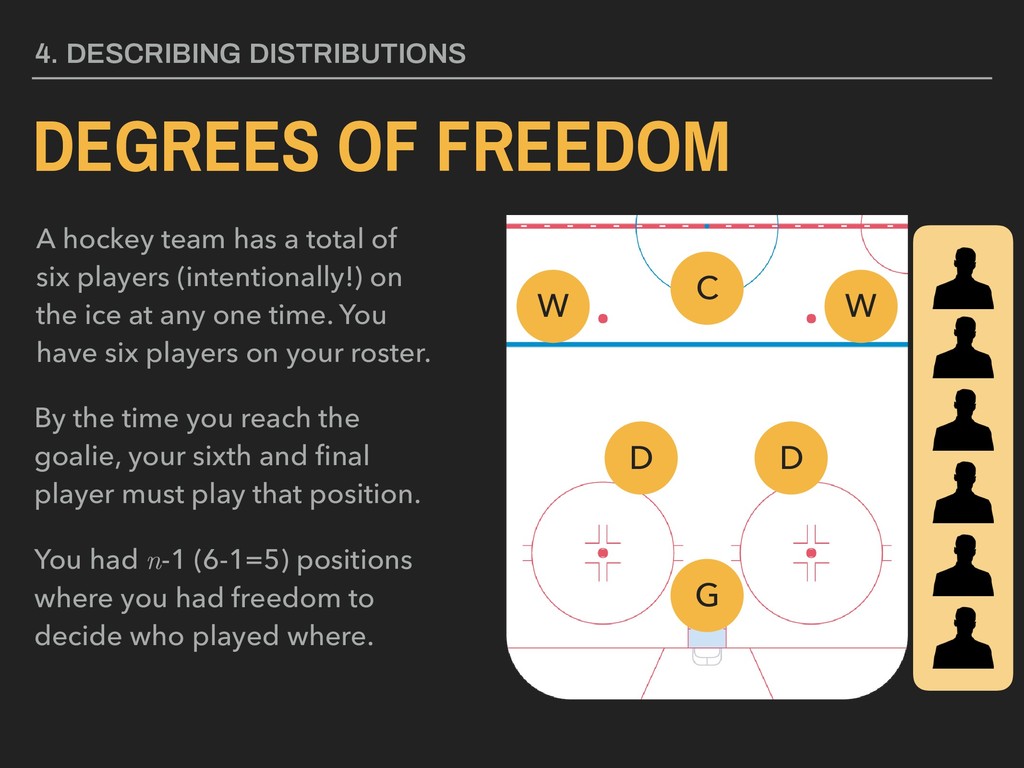
a total of six players (intentionally!) on the ice at any one time. You have six players on your roster. By the time you reach the goalie, your sixth and final player must play that position. You had n-1 (6-1=5) positions where you had freedom to decide who played where. C W W D D G
on the right, you can select whatever values you want for x and y so long as they total to 7. However, if I tell you that x is equal to 4, your choice becomes limited. x + y = 7 4 + y = 7
on the right, you can select whatever values you want for x, y, and z so long as they equal 0. However, if I tell you that x is equal to 4, your choice becomes constrained. If I tell you that y is equal to -2, your choice becomes further constrained. x + y + z = 0 4 + y + z = 0 4 + −2 + z = 0
(x − ¯ x)2 n − 1 σ2 = ∑n i=1 (x − ¯ x)2 n Degrees of freedom (v) is always calculated by subtracting the number of constraints (relationships) from the total number of observations (n). When you calculate deviance, you impose a limiting relationship. Thus n-1 is included in calculations. SAMPLE VARIANCE POPULATION VARIANCE
The technique of using degrees of freedom to create an unbiased estimator of the population variance is known as Bessel’s Correction ▸ Without Bessel’s Correction, our estimate of the variance will be biased down in the typical sample 4. DESCRIBING DISTRIBUTIONS BESSEL 1784-1846
values that do not make intuitive sense for interpretation. ▸ Standard deviation measures the degree to which a distribution varies from the mean in a measure that is consistent with the units of the distribution. ▸ This can be easily calculated in R using the stats::sd() function. ▸ Greek letter (“sigma”) used for referring to the population standard deviation 4. DESCRIBING DISTRIBUTIONS
x = a given value in the vector ▸ n = sample size “The standard deviation is the square root of the variance.” 4. DESCRIBING DISTRIBUTIONS Let: STANDARD DEVIATION s = ∑n i=1 (x − ¯ x)2 n − 1 ¯ x
smallest values of a vector. Since range relies on these two values, it is affected by outliers. ▸ These two values can be displayed in R using the stats::range() function. ▸ The range of x can be calculated using: 4. DESCRIBING DISTRIBUTIONS stats::max(x) - stats::min(x)
the 25th and 75th percentiles (or the first and third quartile). Since outliers are trimmed from the data, this provides a better assessment of the dispersion for the bulk of the data. ▸ This range can be displayed in R using the stats::IQR() function. 4. DESCRIBING DISTRIBUTIONS
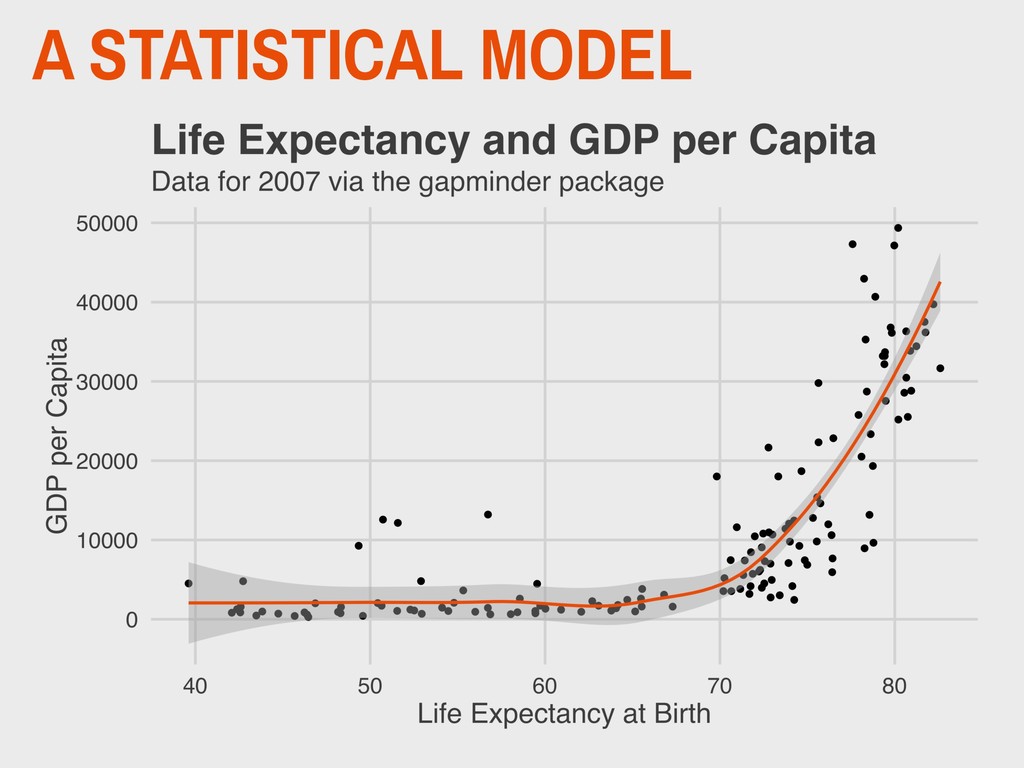
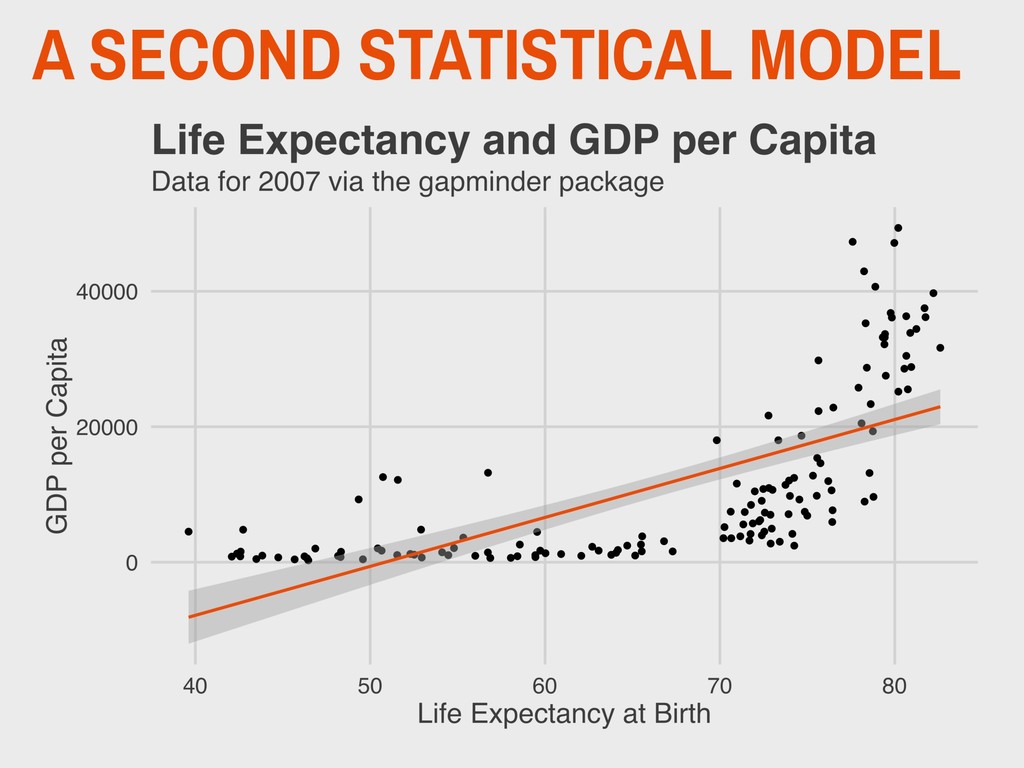
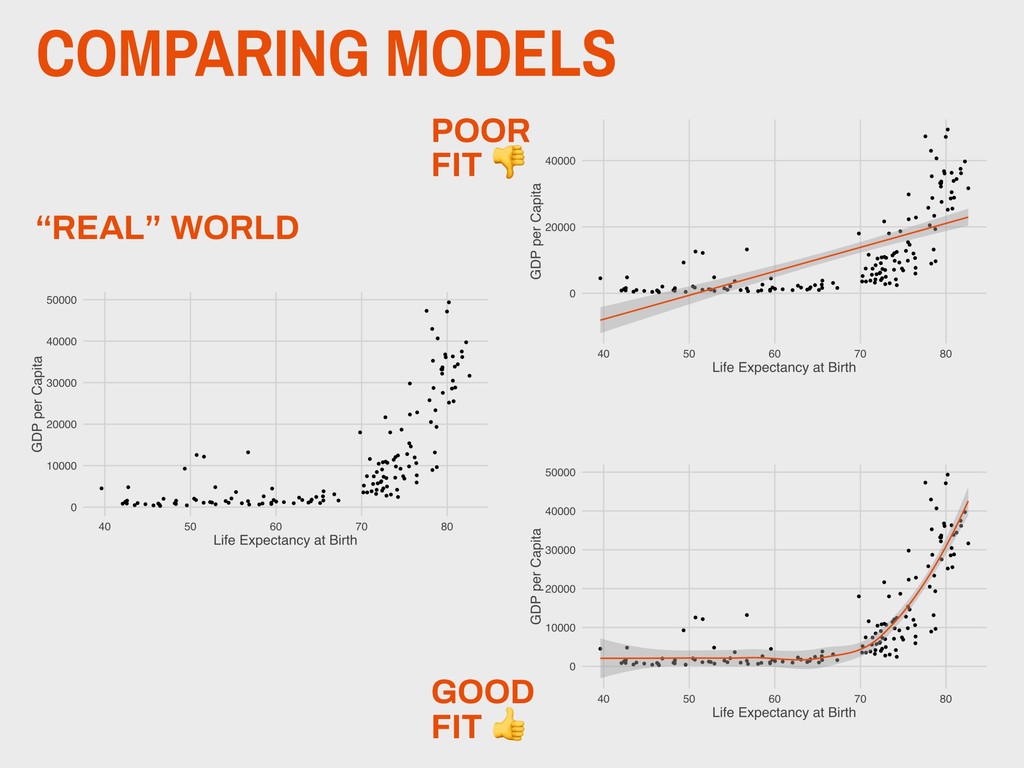
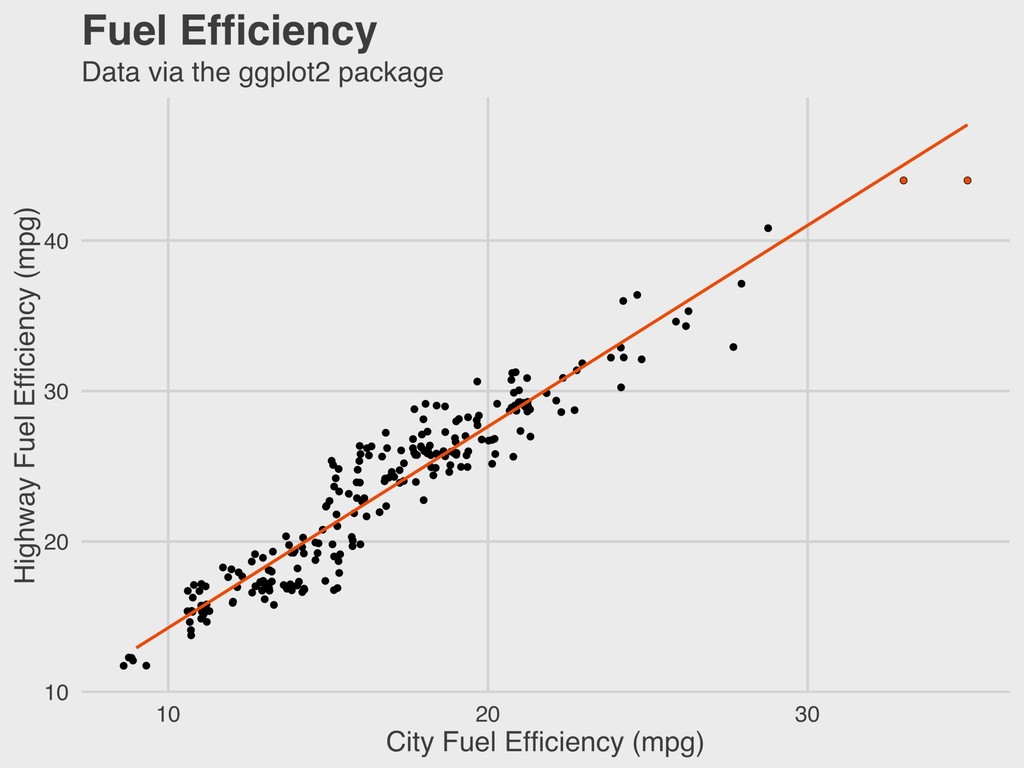
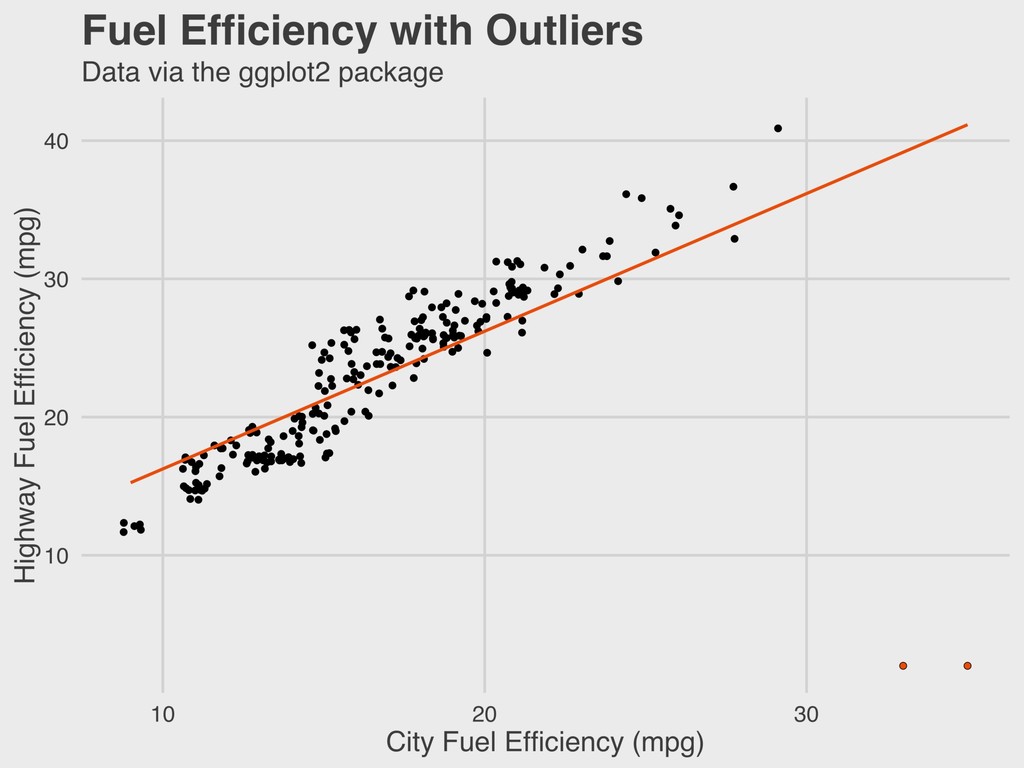
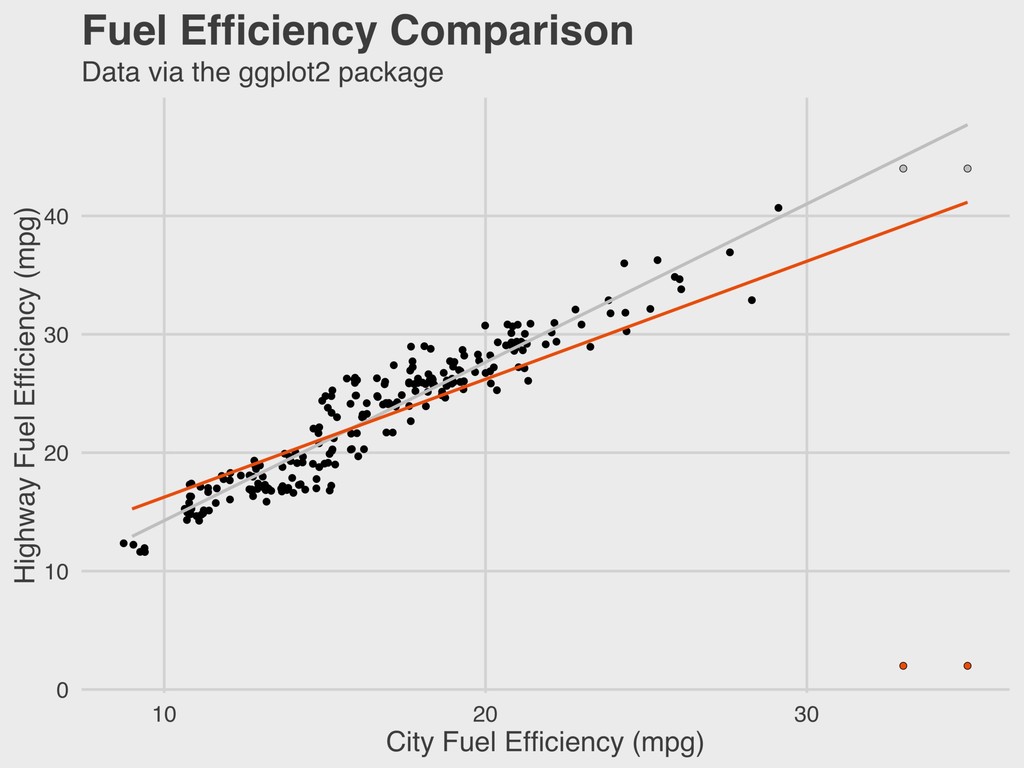
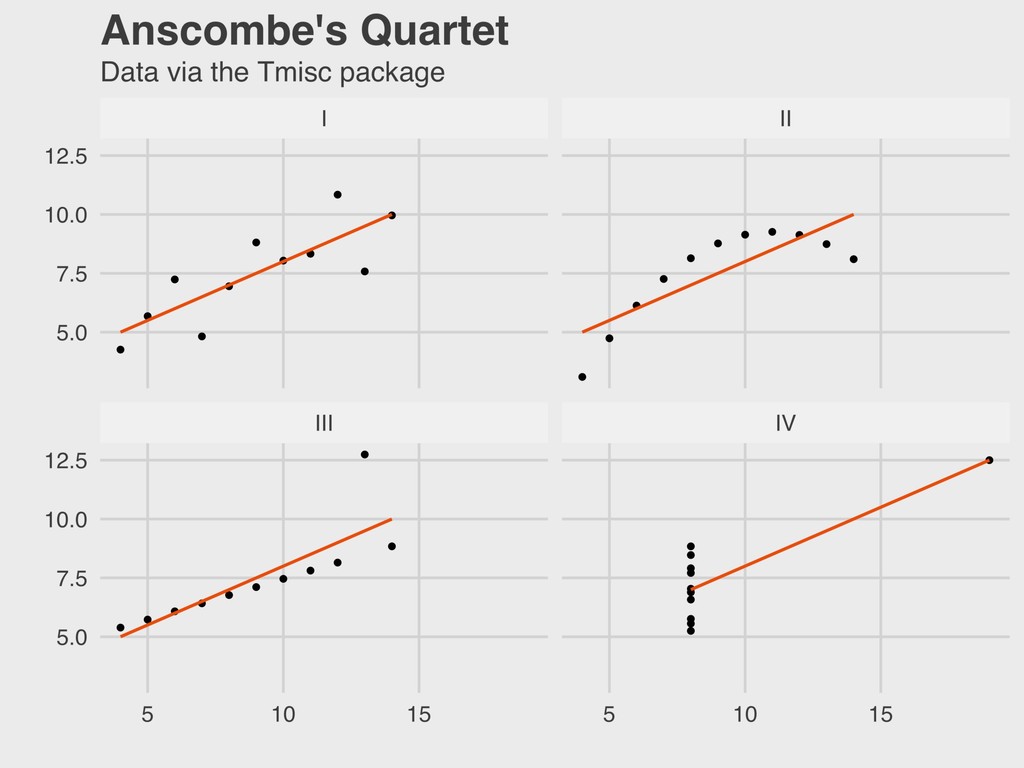
Yale ▸ Founded Yale’s Department of Statistics in 1963 ▸ Early proponent of statistical computing and the important of graphing distributions ▸ Ancombe’s quartet is a famous statistical problem 5. ANSCOMBE’S QUARTET ANSCOMBE 1918-2001
base distribution of R, used for calculating statistics ▸ skimr is an rOpenSci package for calculating descriptive statistics ▸ reprex is a tidyverse package for creating reproducible examples 5. DESCRIPTIVE STATS AND GETTING HELP IN R PACKAGES
or tibble ▸ var is the variable you want output for Available in janitor Download via CRAN 5. DESCRIPTIVE STATS AND GETTING HELP IN R FREQUENCY TABLES Parameters: tabyl(dataFrame, var) f(x)
tabyl(dataFrame, var) Using the cyl variable from ggplot2’s mpg data: > tabyl(mpg, cyl) [ output on next slide ] Can also be used with a pipe - mpg %>% tabyl(cyl) f(x)
data frame vector combination (df$x) ▸ na.rm will return an error if there is missing data when FALSE; when TRUE, it will return the median or mean without including missing data Available in base and stats Download via CRAN 5. DESCRIPTIVE STATS AND GETTING HELP IN R DESCRIPTIVE STATISTICS Parameters: median(x, na.rm = FALSE), mean(x, na.rm = FALSE), var(x, na.rm = FALSE), sd(x, na.rm = FALSE), range(x), min(x), max(x), IQR(x) f(x)
data frame vector combination (df$x) ▸ na.rm will return an error if there is missing data when FALSE; when TRUE, it will return the median or mean without including missing data 5. DESCRIPTIVE STATS AND GETTING HELP IN R DESCRIPTIVE STATISTICS Parameters: median(x, na.rm = FALSE), mean(x, na.rm = FALSE), var(x, na.rm = FALSE), sd(x, na.rm = FALSE), range(x), min(x), max(x), IQR(x) f(x)
data frame vector combination (df$x) Available in stats Download via CRAN 5. DESCRIPTIVE STATS AND GETTING HELP IN R DESCRIPTIVE STATISTICS Parameters: summary(x) f(x)
summary(x) Using the hwy variable from ggplot2’s mpg data: > summary(mpg$hwy) Min. 1st Qu. Median Mean 3rd Qu. Max. 12.00 18.00 24.00 23.44 27.00 44.00 Remember to use the base R “dollar sign” syntax: df$x; using it on a large data frame yields a lot of output f(x)
research using shared data and reusable software” (rOpenSci 2018) ▸ rOpenSci: • Reviews and helps support packages to accessing scientific data • Hosts “unconferences” 5. DESCRIPTIVE STATS AND GETTING HELP IN R ROPENSCI
or tibble ▸ varlist is an optional input that allows you to limit the output to a single variable or a set of variables • Referred to as … in skimr documentation • Variable names should be separated by commas and unquoted Available in skimr Download via CRAN 5. DESCRIPTIVE STATS AND GETTING HELP IN R DESCRIPTIVE STATISTICS Parameters: skim(dataFrame, varlist) f(x)
or tibble ▸ varlist is an optional input that allows you to limit the output to a single variable or a set of variables • Referred to as … in skimr documentation • Variable names should be separated by commas and unquoted 5. DESCRIPTIVE STATS AND GETTING HELP IN R DESCRIPTIVE STATISTICS Parameters: skim(dataFrame, varlist) f(x)
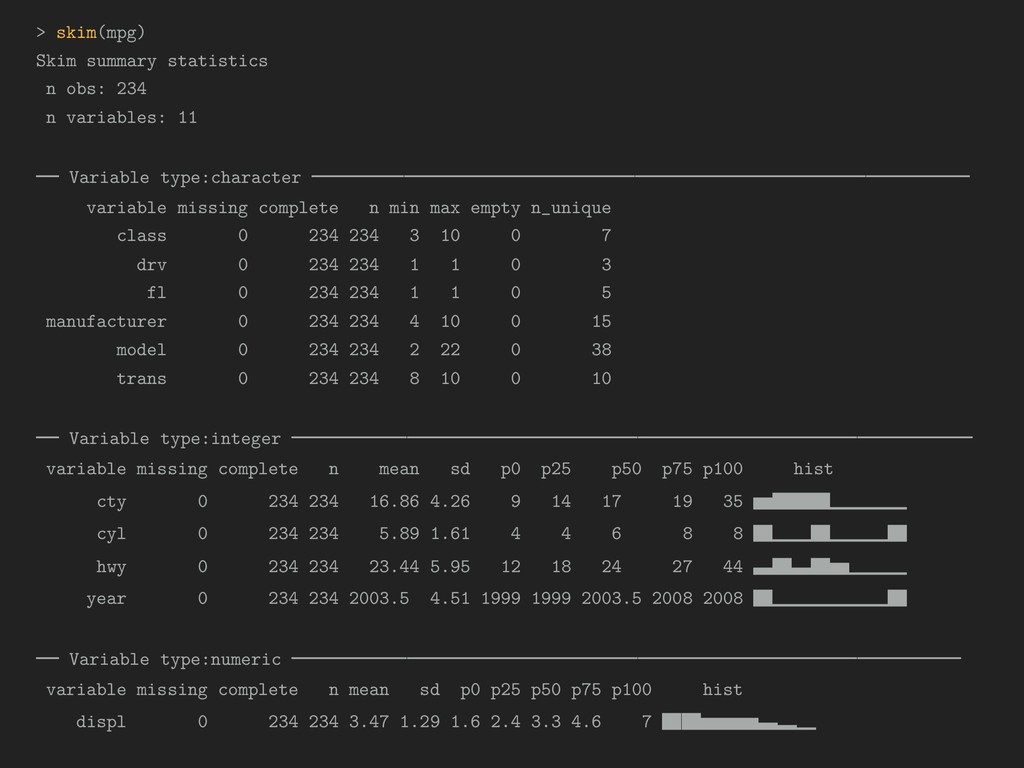
skim(dataFrame, varlist) Using ggplot2’s mpg data: > skim(mpg) [ output on next slide ] Output in notebooks will sometimes not fit on one row and will wrap when those notebooks are knit. f(x)
2 & 4 REMINDERS 6. BACK MATTER Lab-02, PS-01, and LP-04 are due before Lecture-04 Final project data for the 2016 General Social Survey is now available on GitHub (linked to via “Final Project” page on course website; for SOC 4015 only)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}