Lecture slides for Lecture 07 of the Saint Louis University Course Quantitative Analysis: Applied Inferential Statistics. These slides cover the topics related to difference of mean testing by hand.
the solution to the various issues in the lab. If you have any problems - including RStudio missing or packages not installing, let me know asap. SOC 5050 annotated bibliographies were due today! Lab 06 and Lecture Prep 08 are due before the next lecture. Feedback backlog being unjammed this week - keep eyes out for feedback on PS-01 and PS-02 - please make sure to apply feedback moving forward with PS-04 etc.
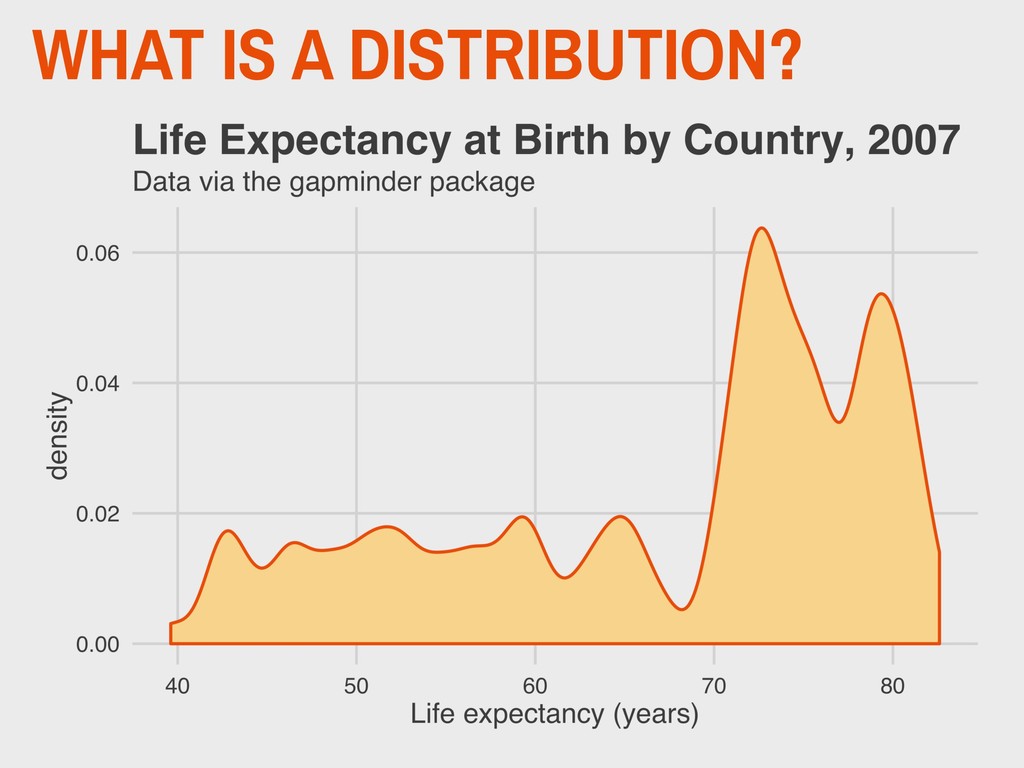
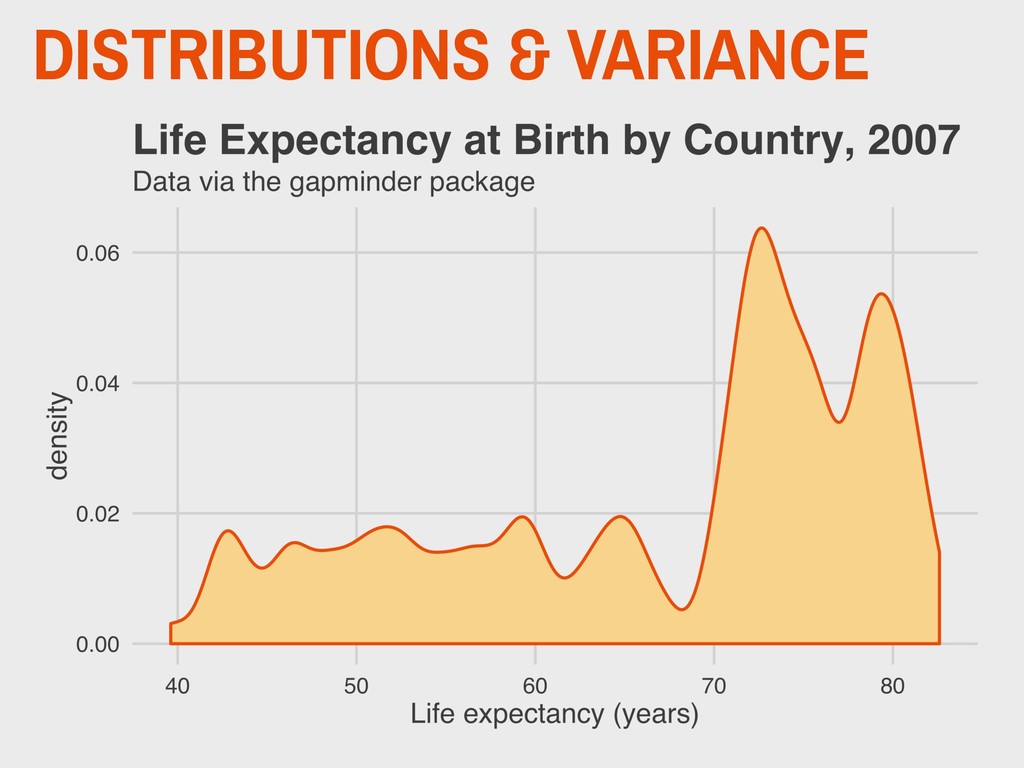
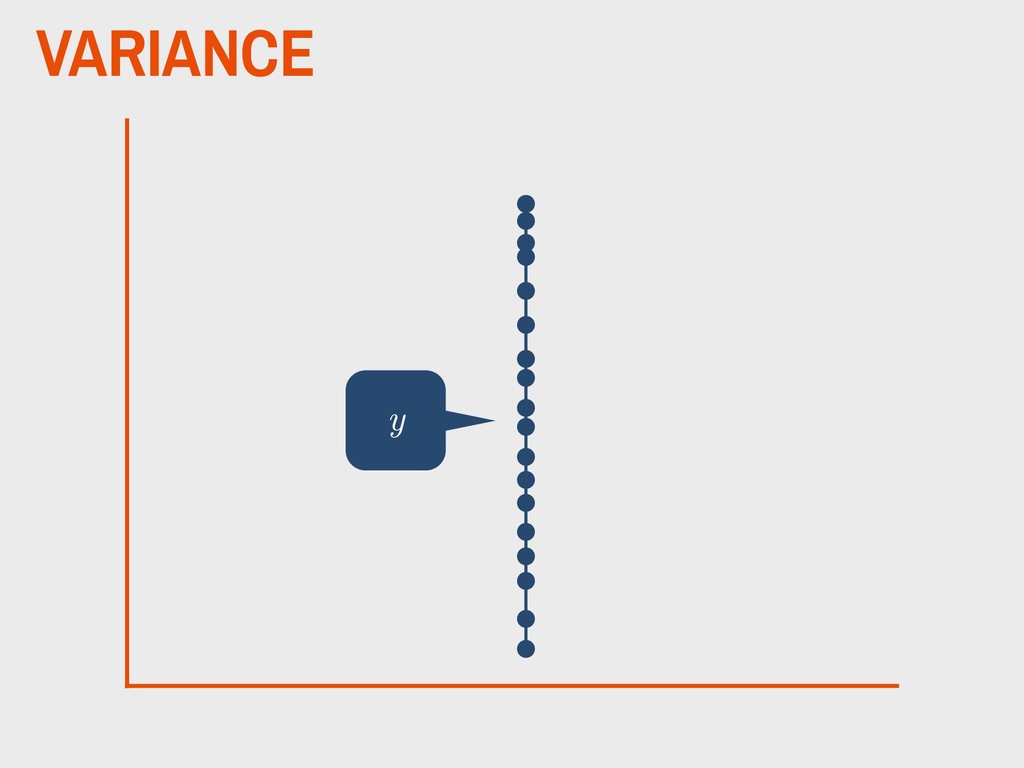
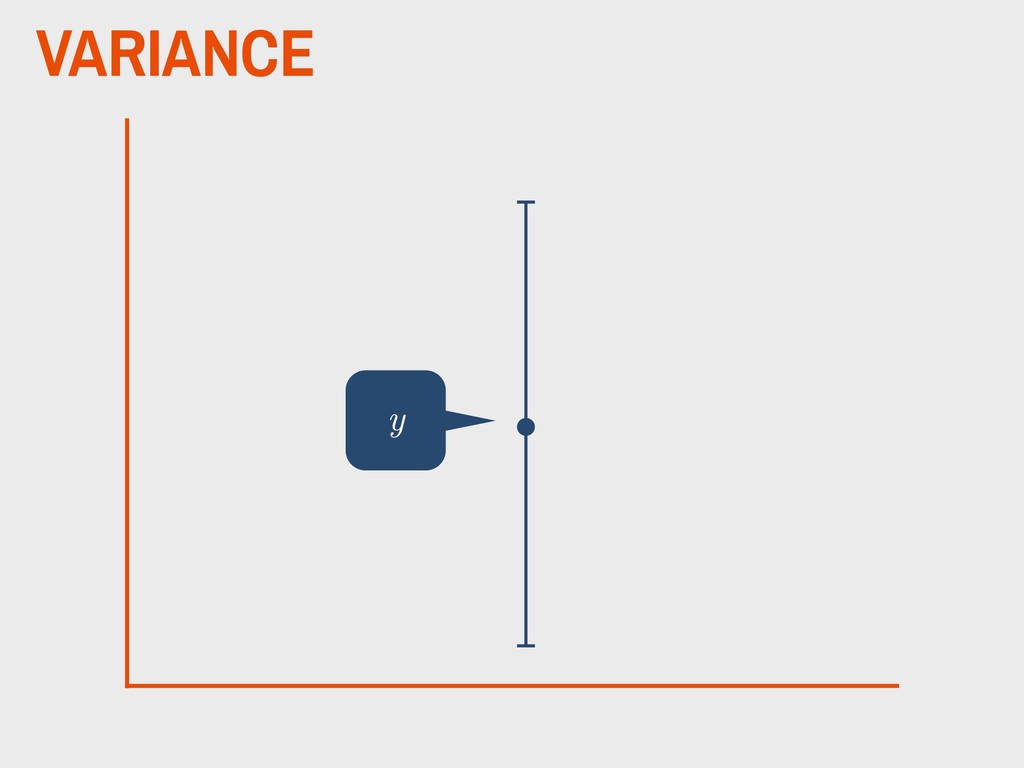
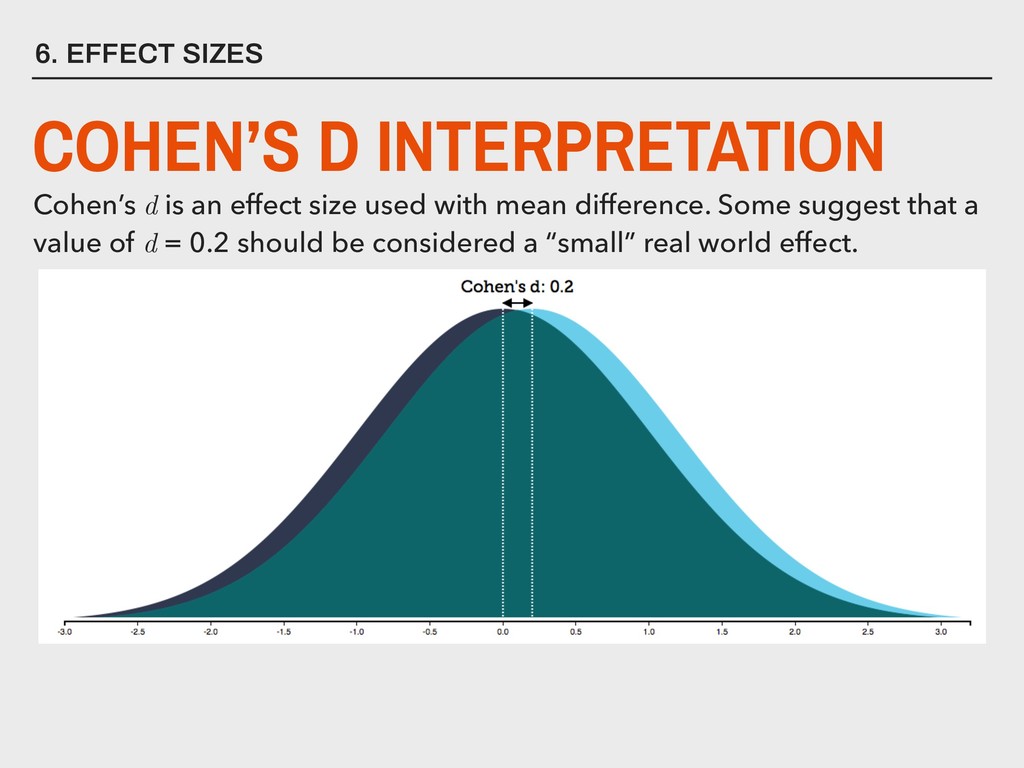
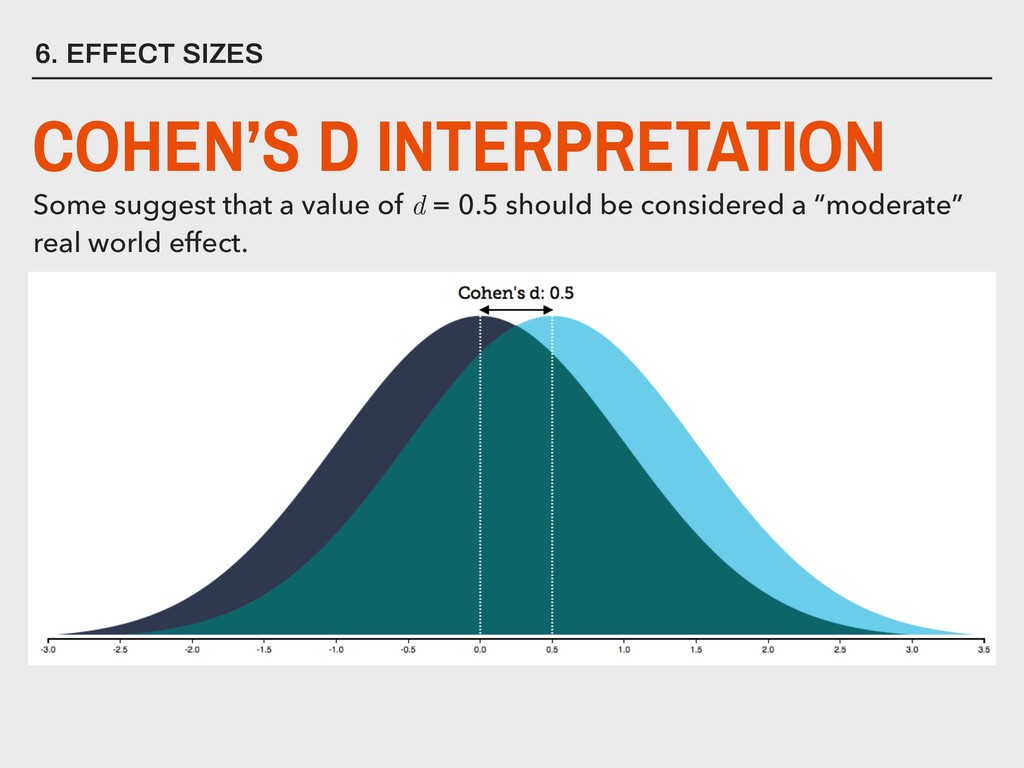
varies from the mean. ▸ This can be easily calculated in R using the stats::var() function. ▸ Greek letter 2 (“sigma”) used for referring to the population variance ▸ The variance is the second moment of a distribution 4. DESCRIBING DISTRIBUTIONS
= a given value in the vector ▸ n = sample size “The variance is the sum of square error divided by n minus 1 degrees of freedom.” 4. DESCRIBING DISTRIBUTIONS Let: SAMPLE VARIANCE s2 = ∑n i=1 (x − ¯ x)2 n − 1 ¯ x
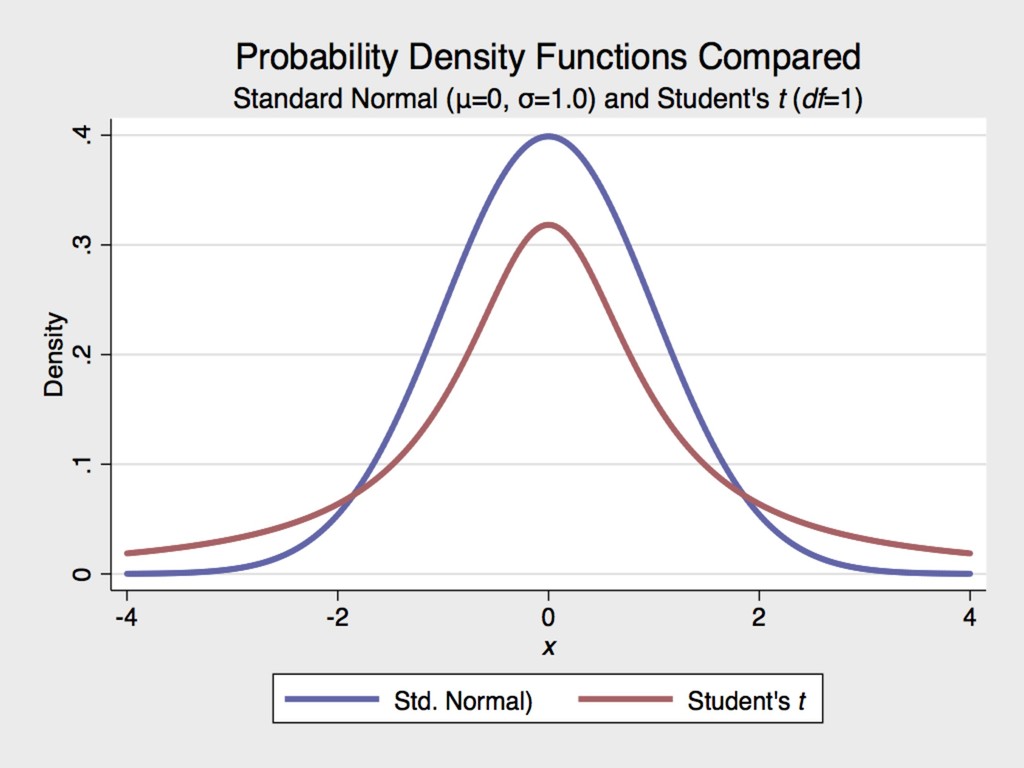
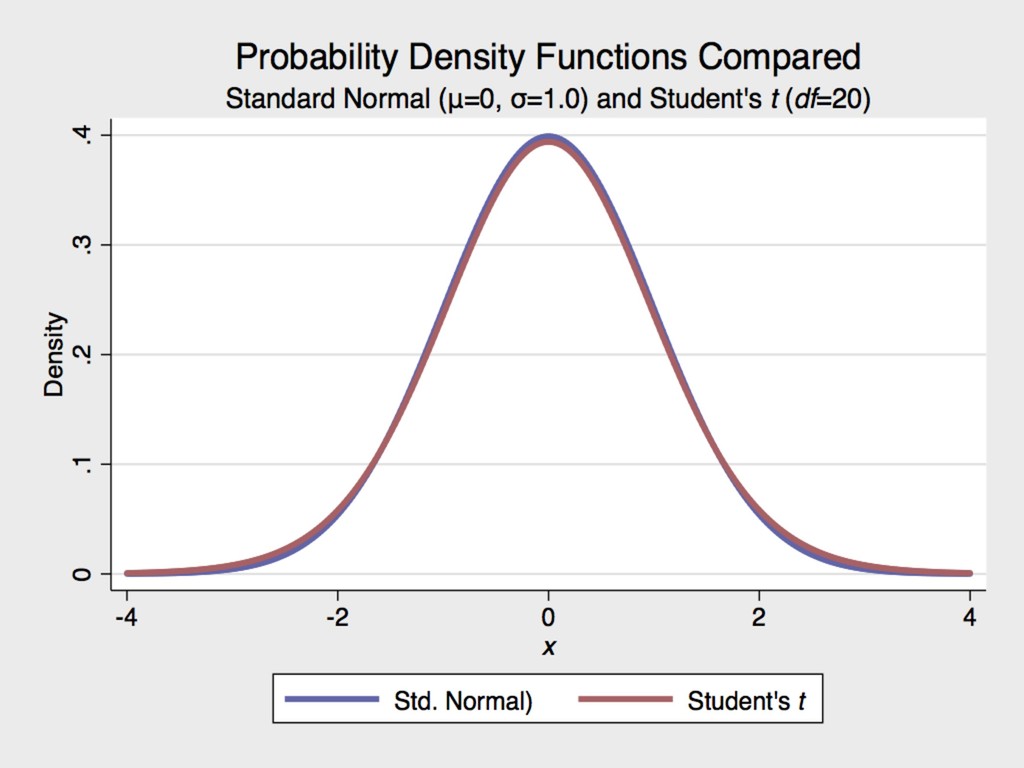
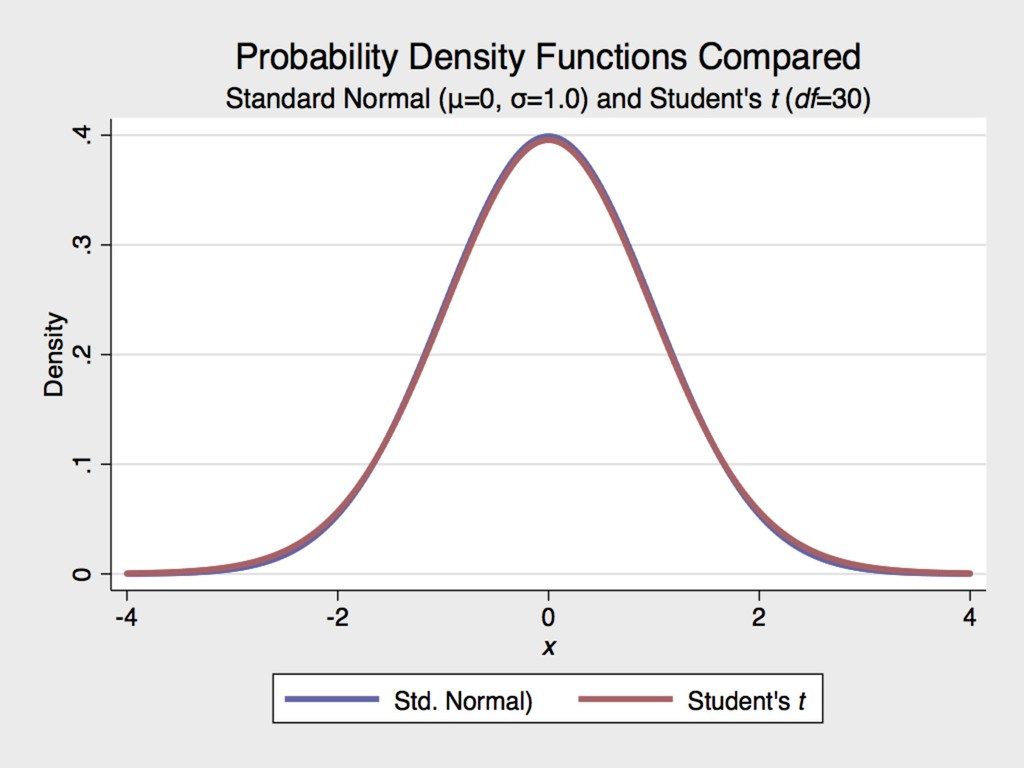
for the Guinness Brewery in Dublin, Ireland at the turn of the 20th century ▸ The Student’s t distribution approximates normal once the degrees of freedom (n-1) is ≥ 30. 6. MORE ON HYPOTHESIS TESTING GOSSET 1876-1937
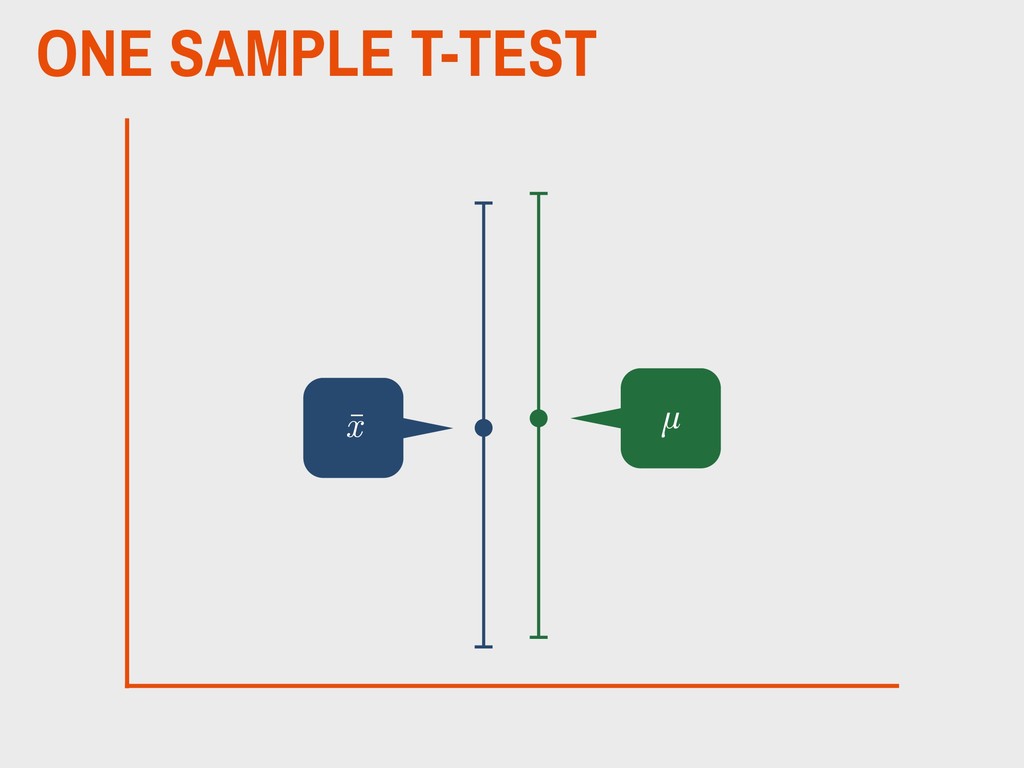
sample distribution (x) is not substantively different from the mean of the population (µ). H0 The mean of the sample distribution (x) is substantively different from the mean of the population (µ). HA _ _
#' #' @description This function calculates the probability of observing a t score #' at least as extreme as the given t value. #' #' @param t A given t score #' @param n The sample size associated with t #' #' @return A probability value #’ 3. ONE SAMPLE
```{r load-packages} # tidyverse packages library(dplyr) # data cleaning # other packages library(here) # file path management ``` This notebook also uses a custom function `probt`: ```{r load-functions} source(here(“source”, “probt.R”)) ``` 3. ONE SAMPLE
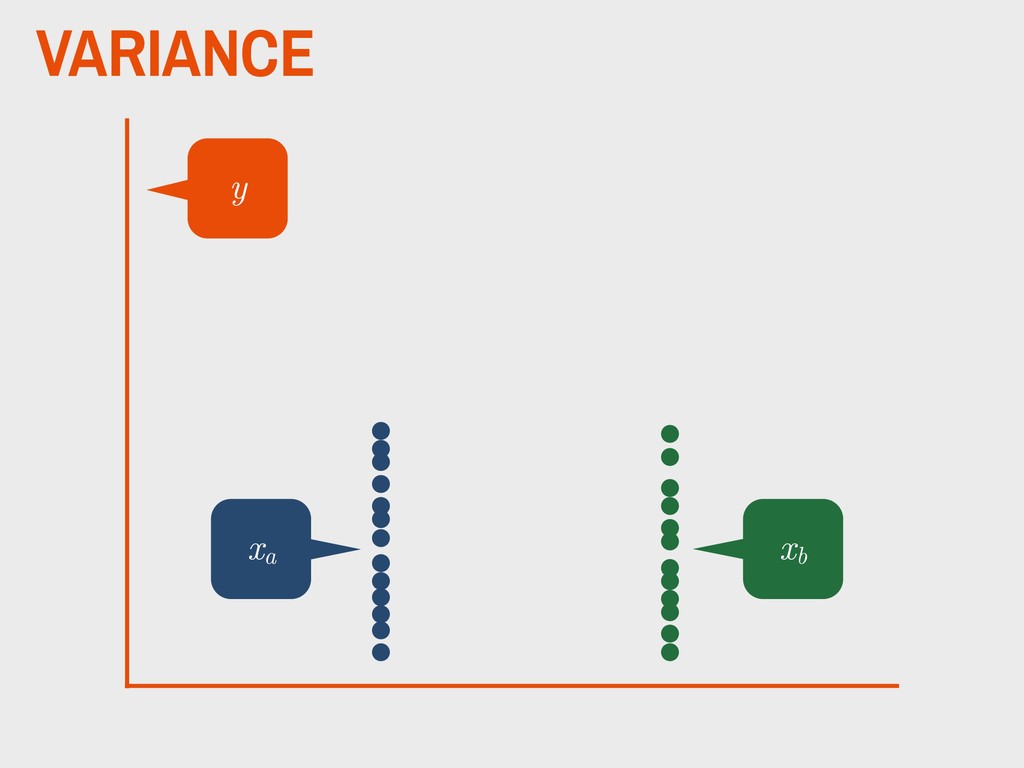
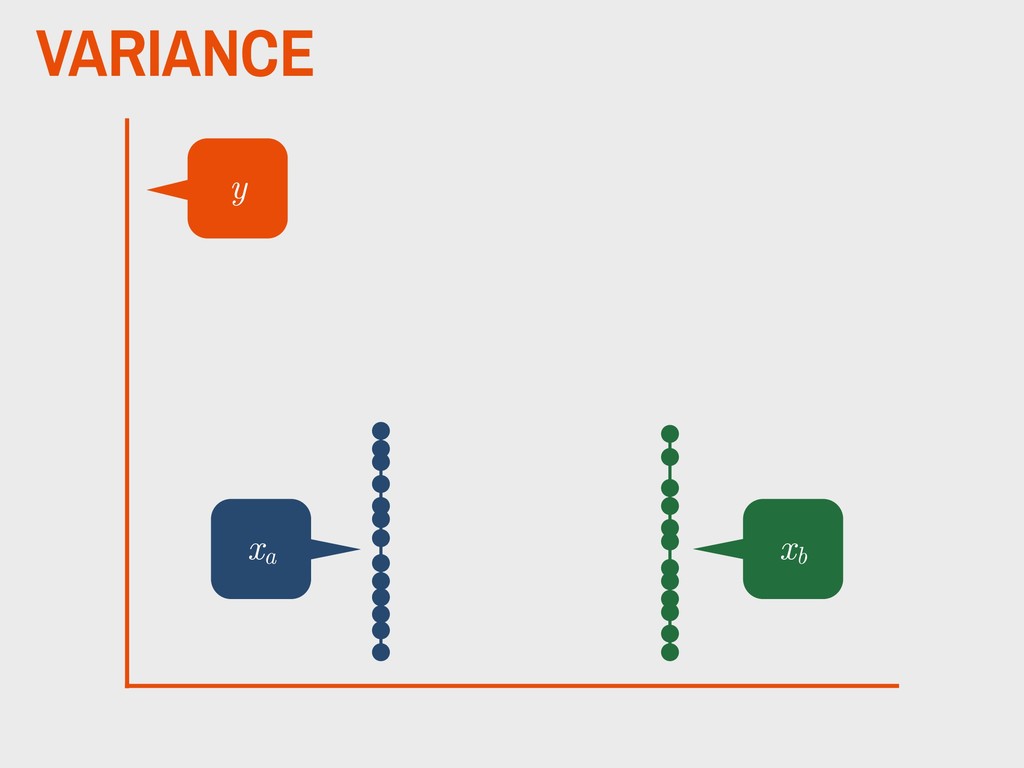
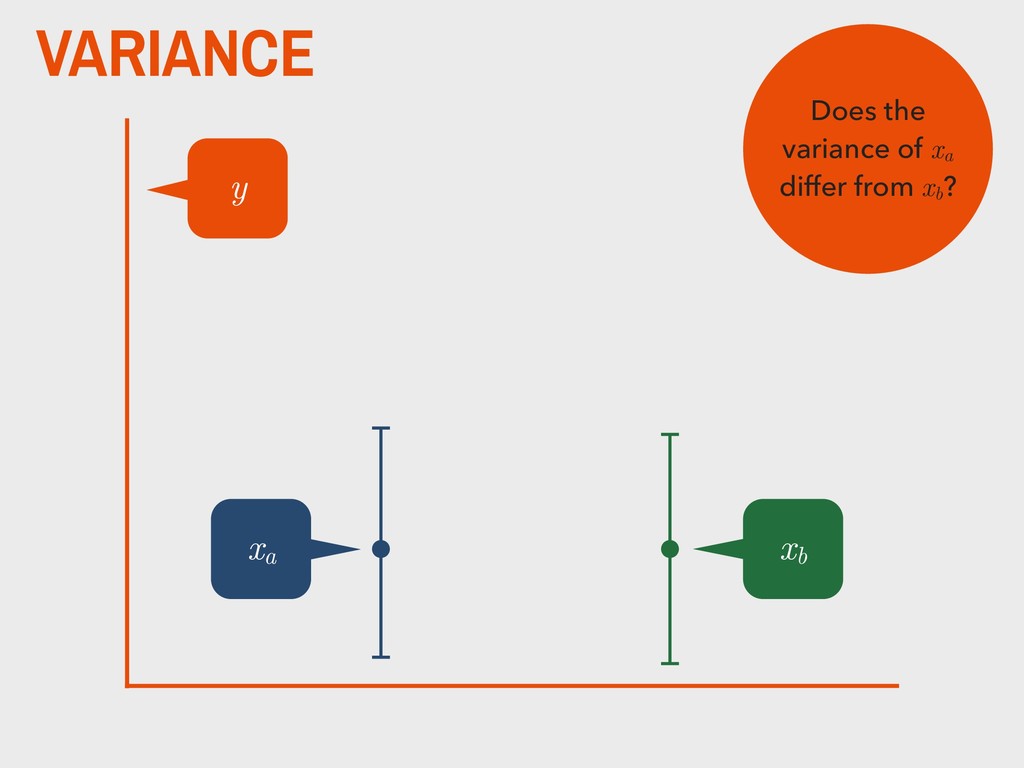
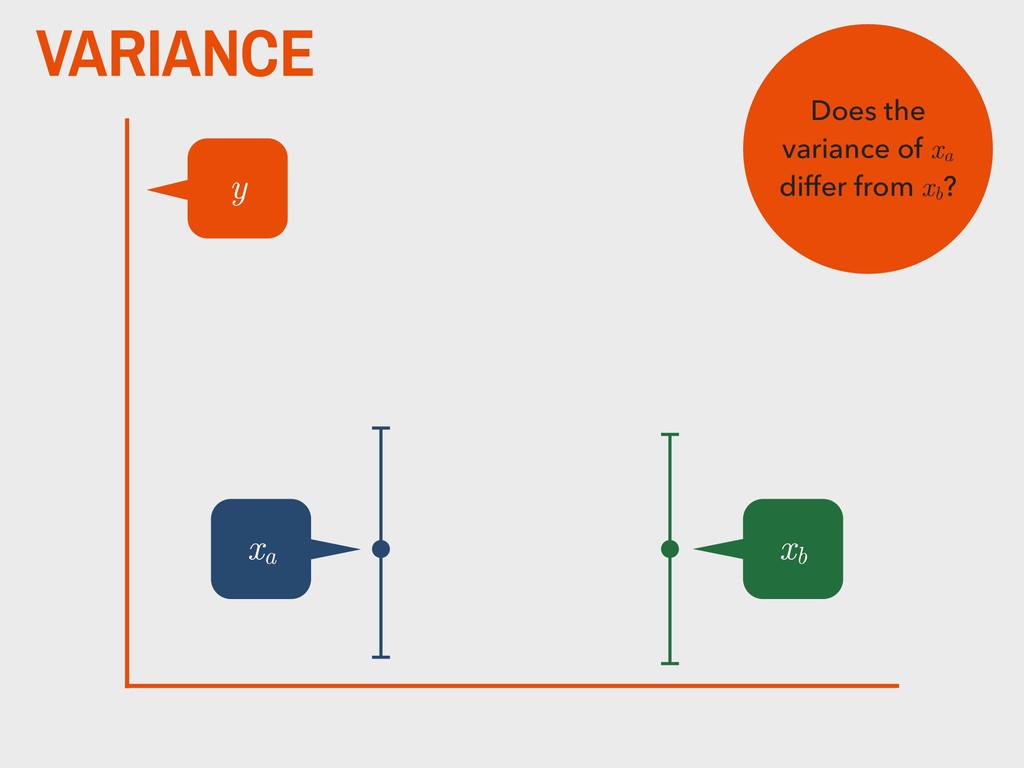
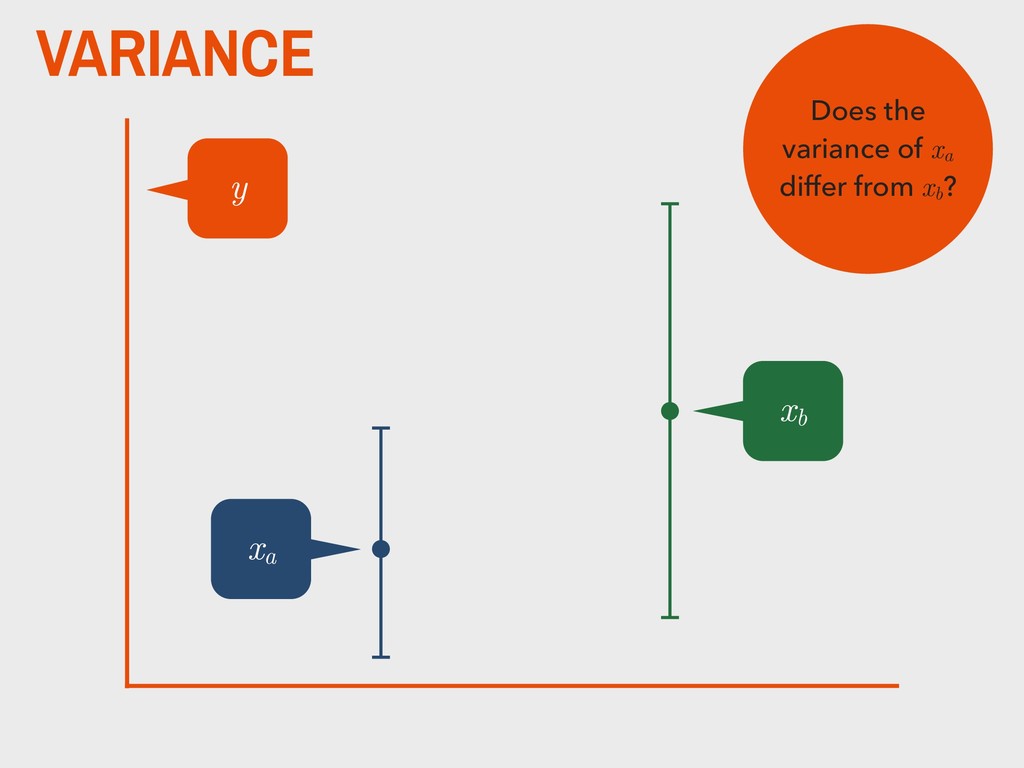
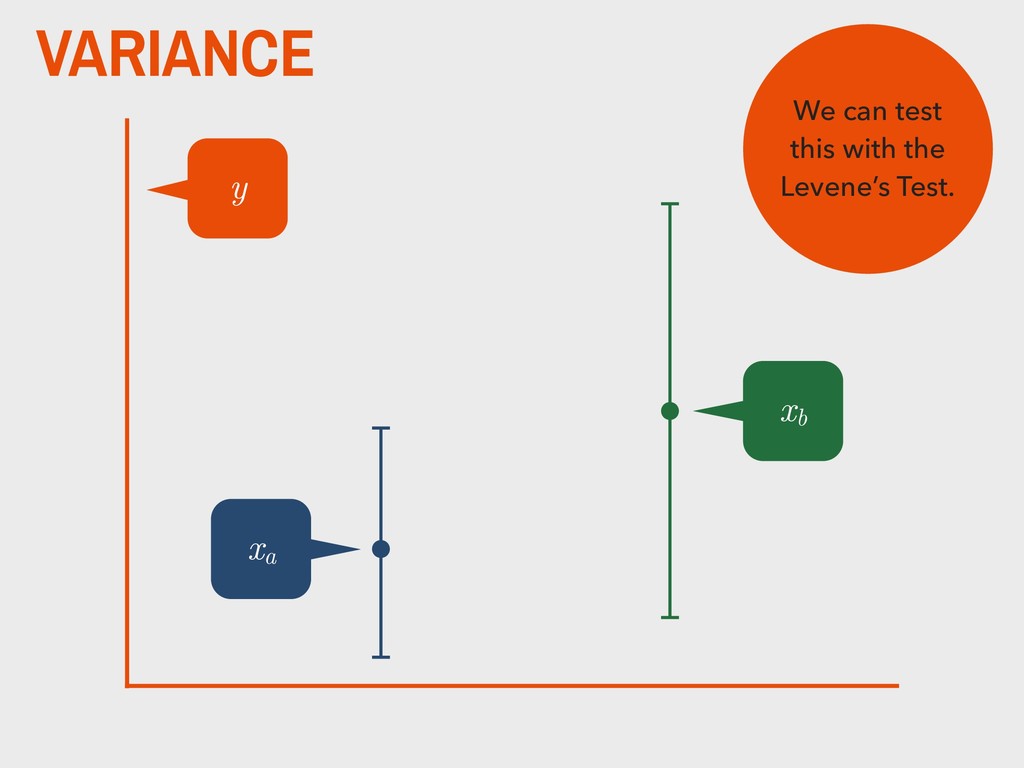
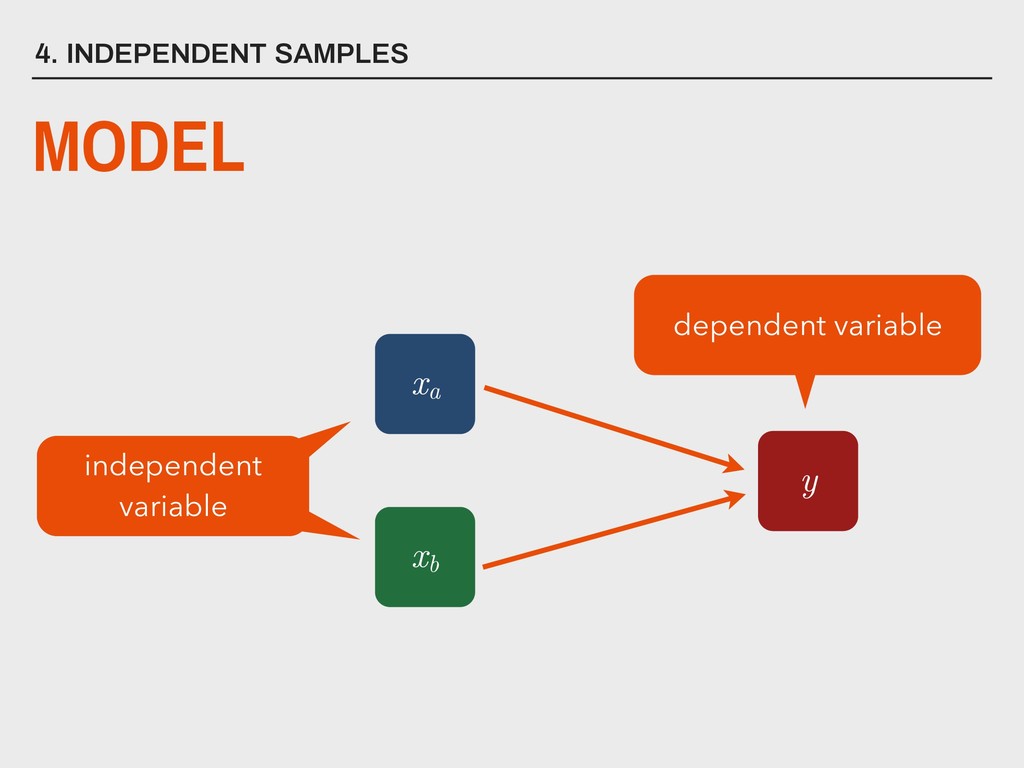
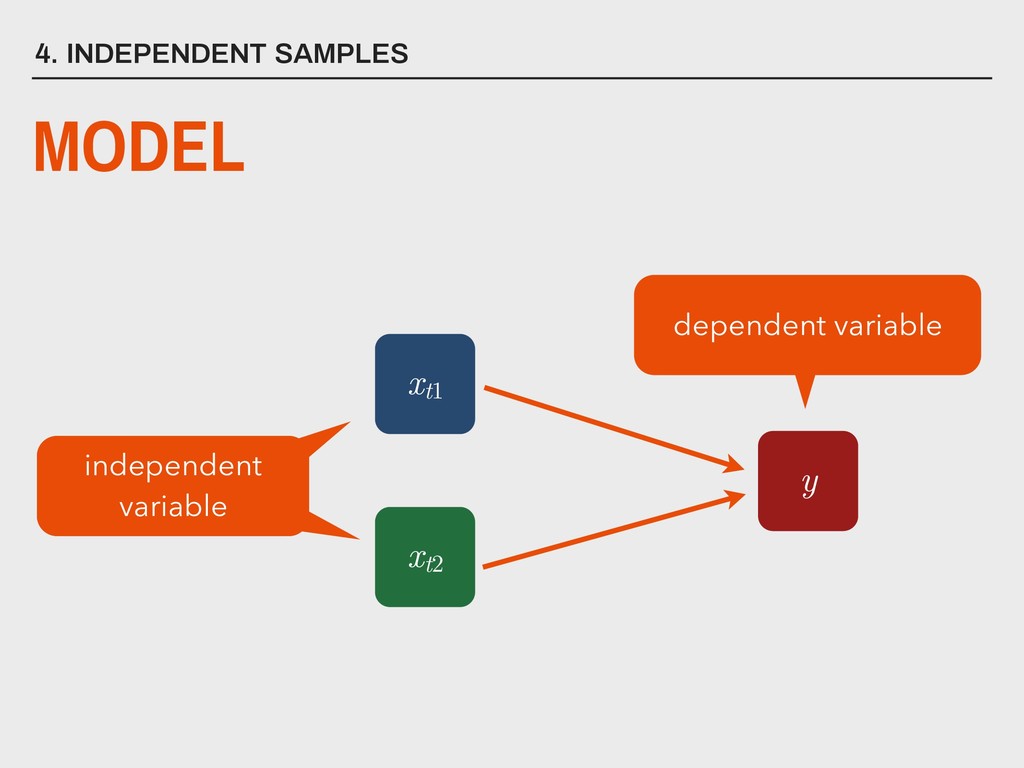
dependent variable y contains continuous data 2. the distribution of y is approximately normal 3. independent variable is binary (xa and xb ) 4. homogeneity of variance between xa and xb 5. observations are independent 6. degrees of freedom (v) are defined as na +nb -2
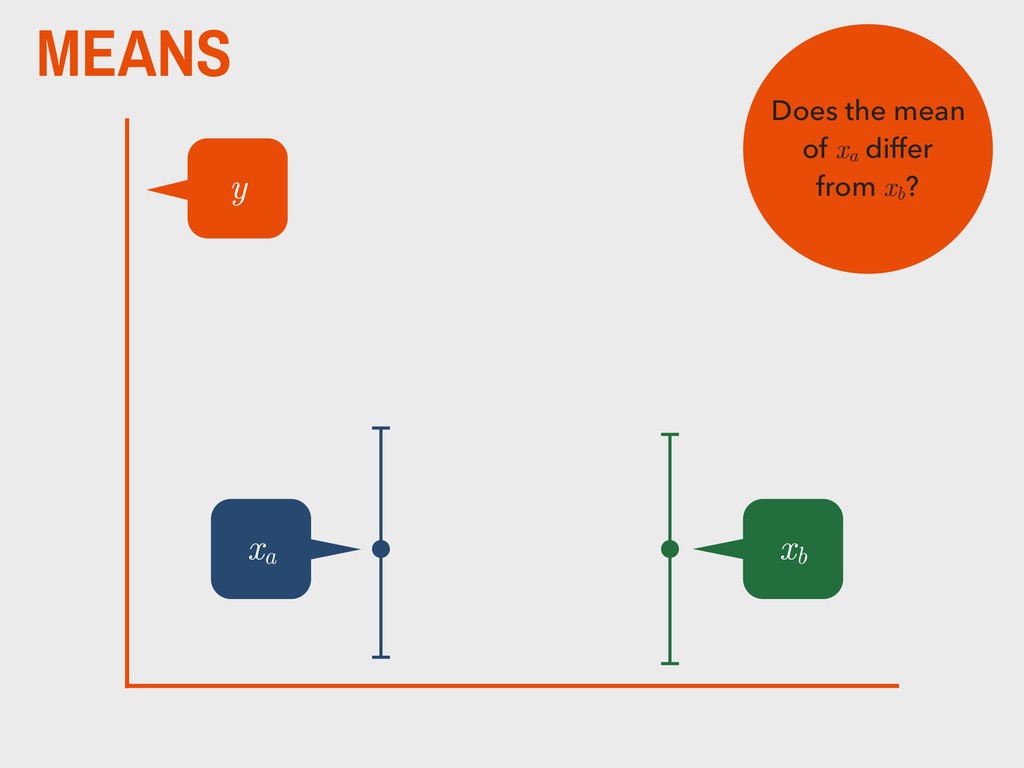
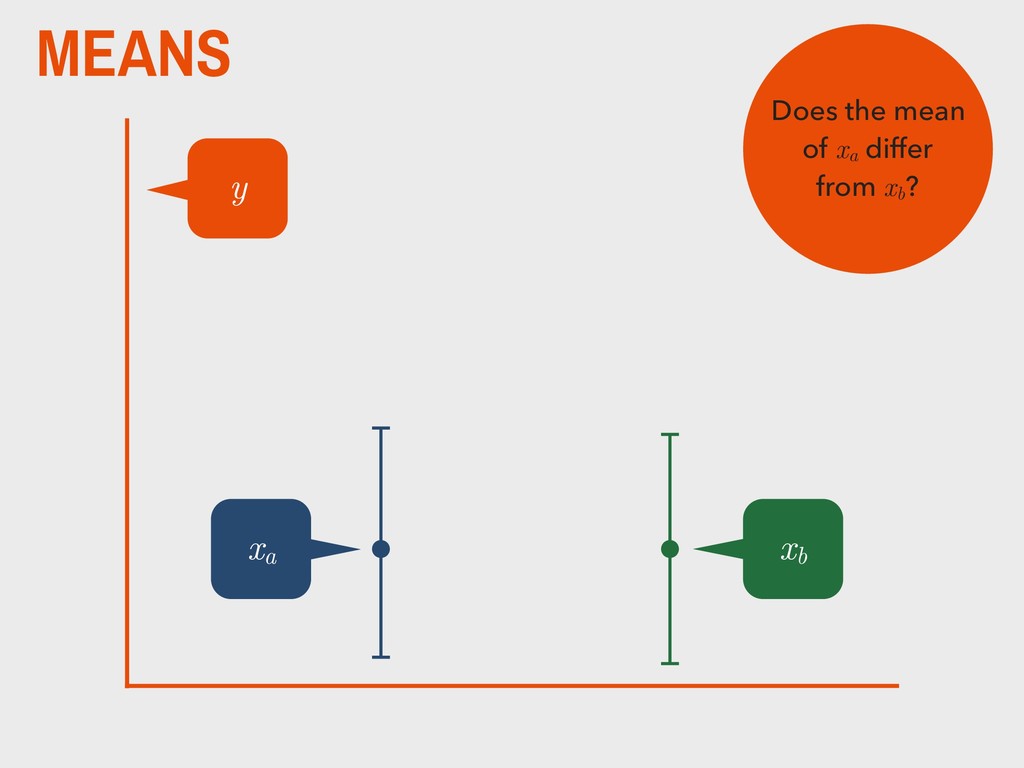
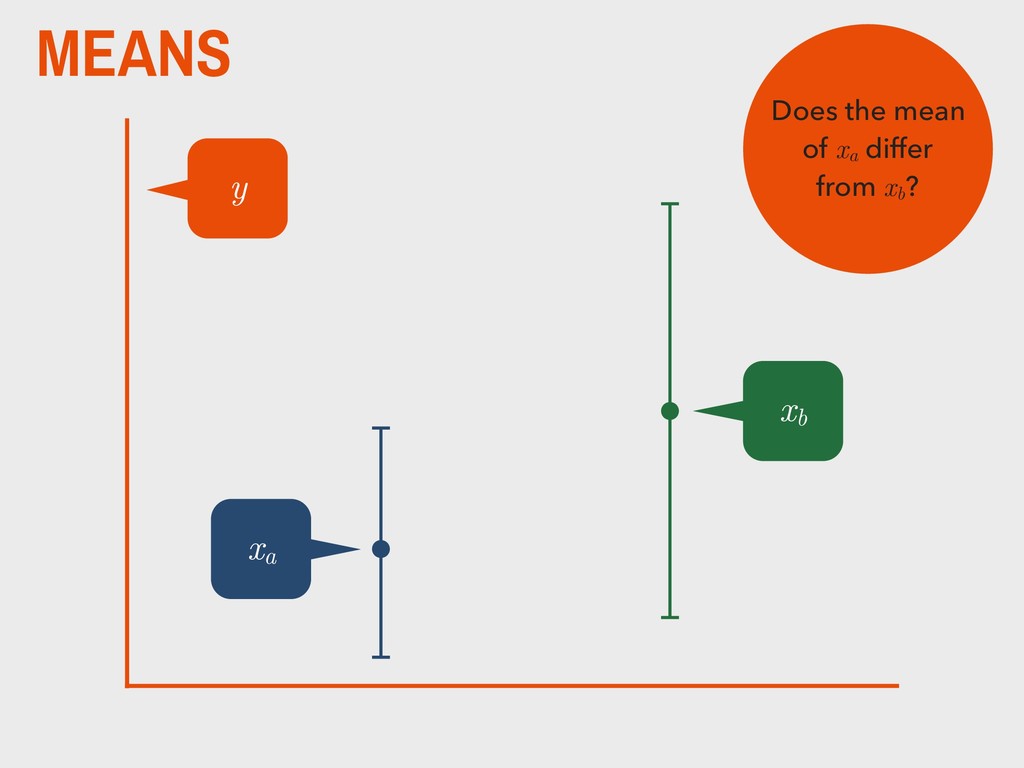
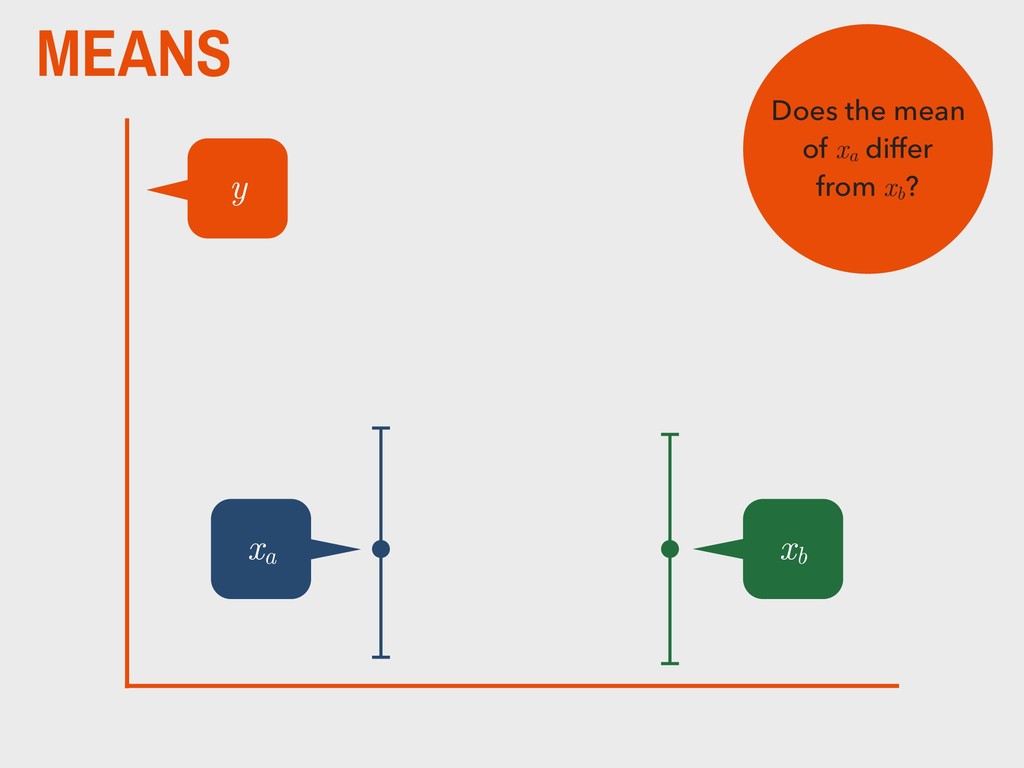
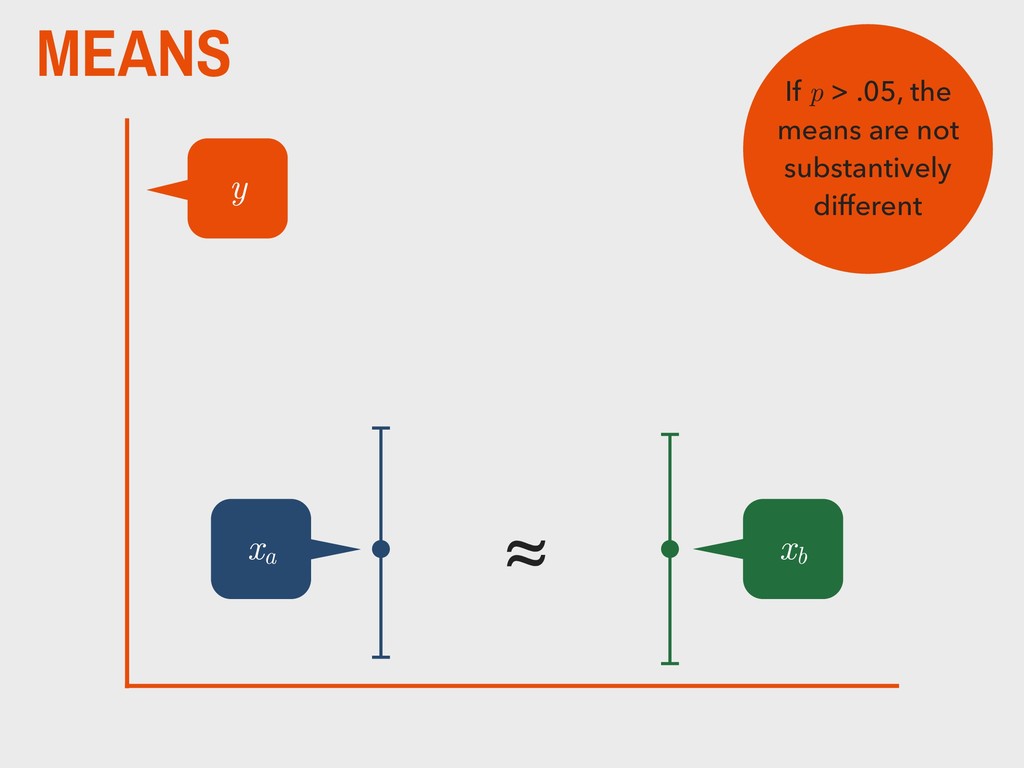
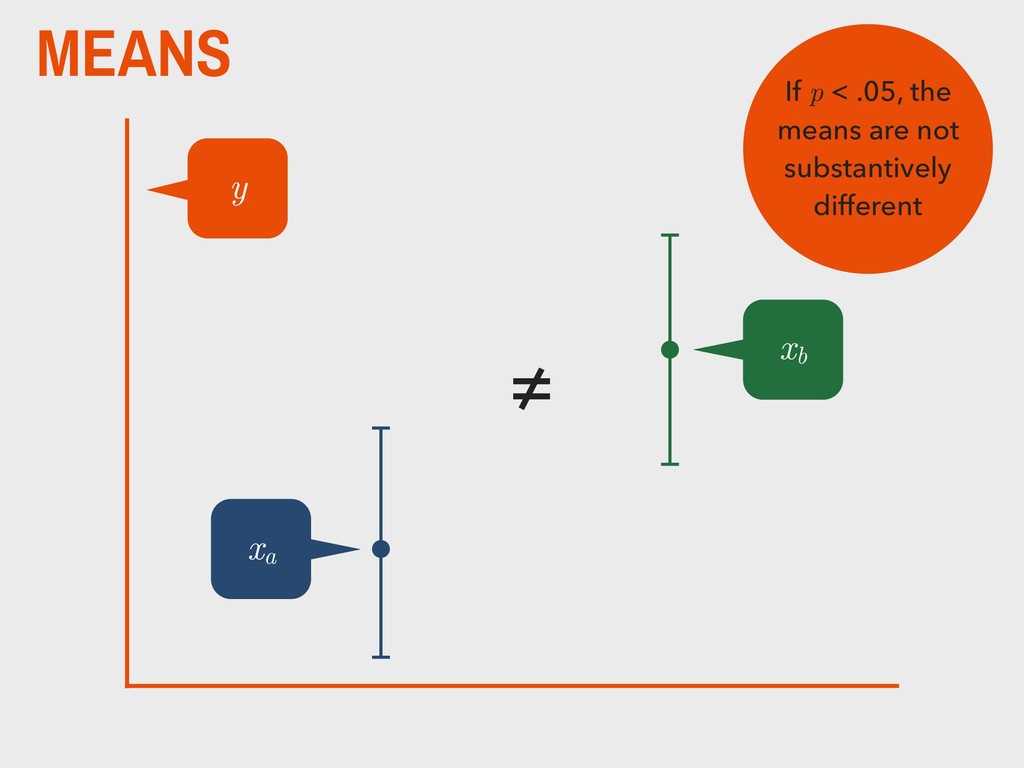
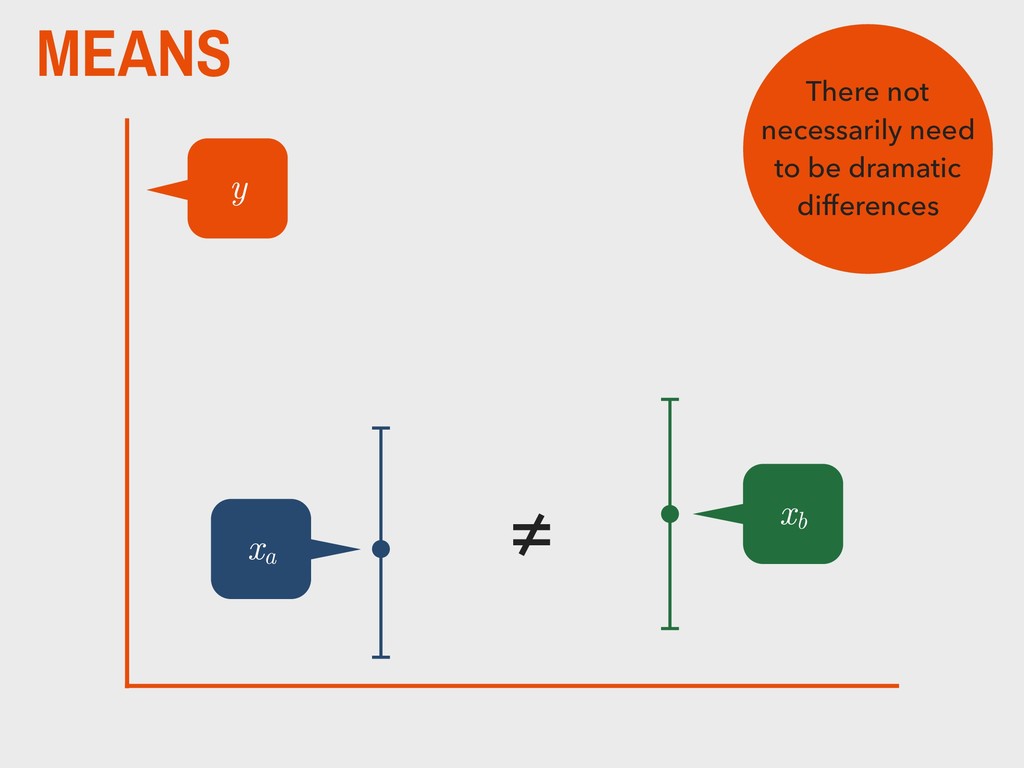
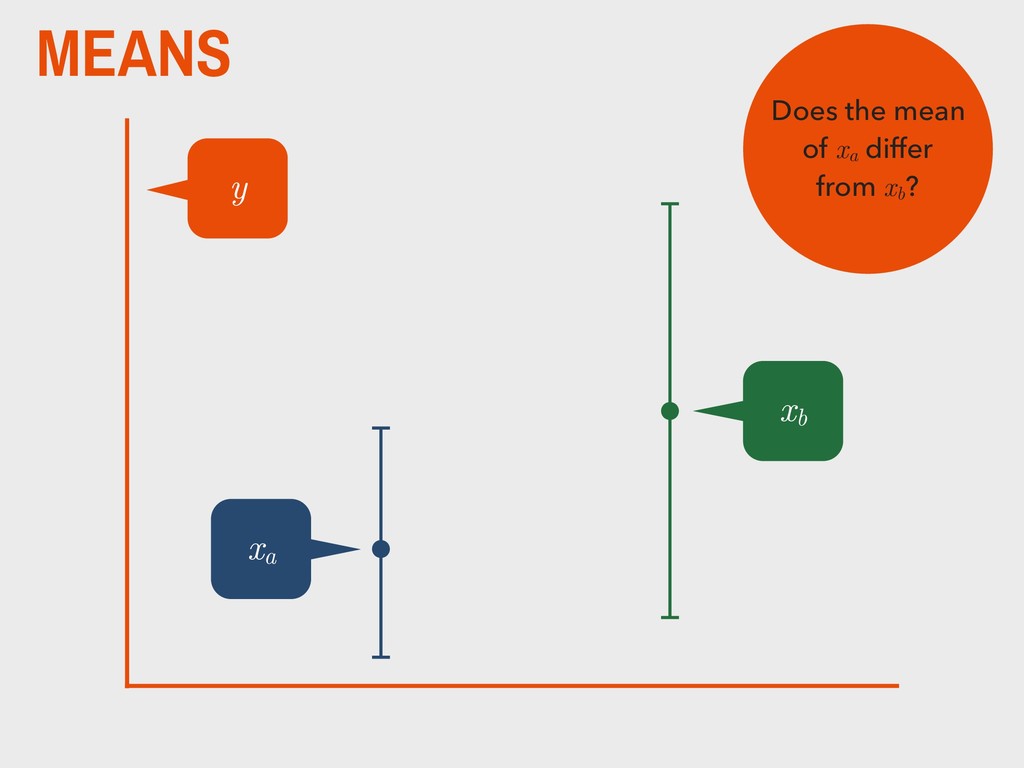
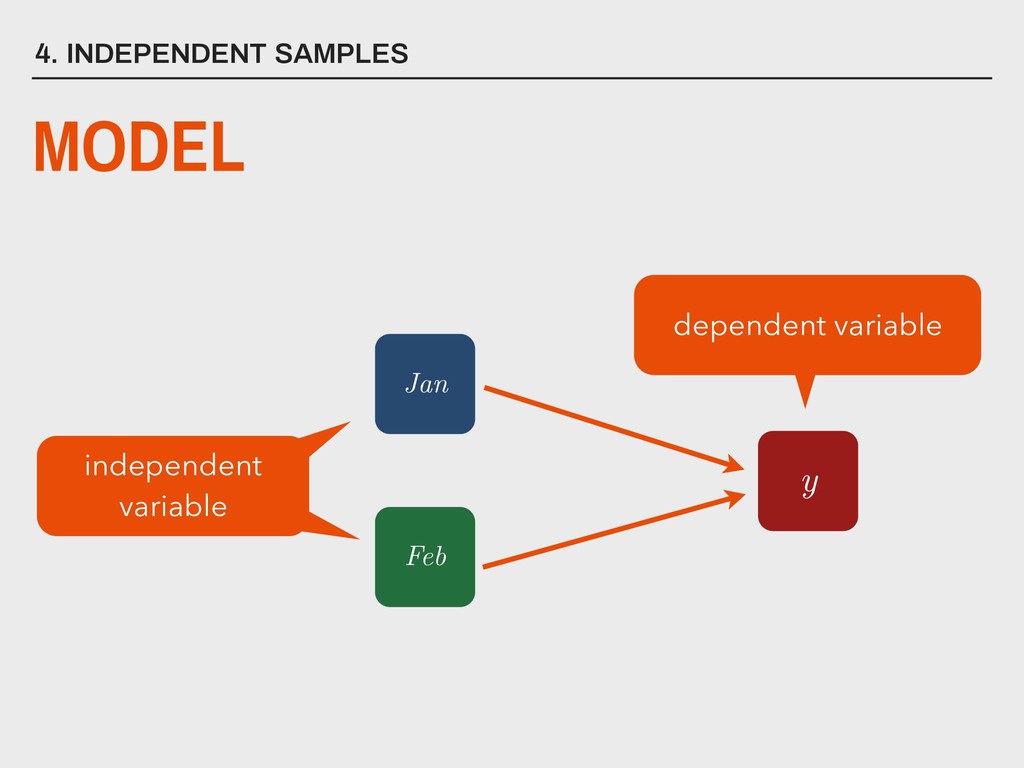
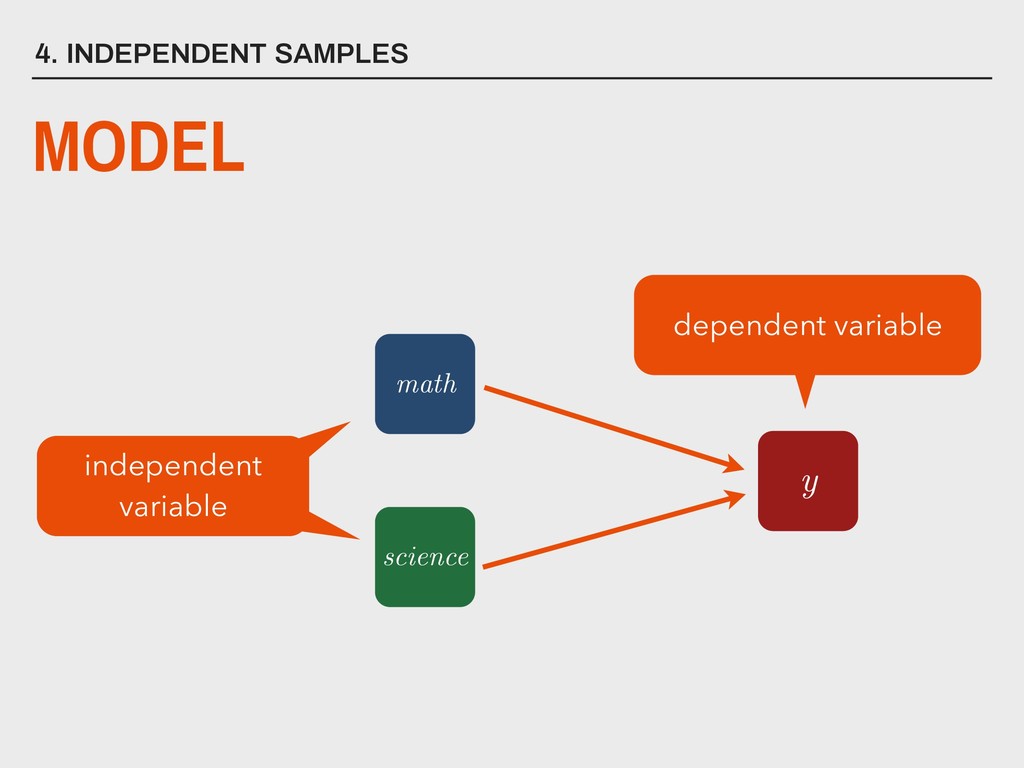
group (xa ) is not substantively different from the mean of the second group (xb ). H0 The mean of one group (xa ) is substantively different from the mean of the second group (xb ). HA _ _ _ _
and b respectively ▸ na and nb - sample size for groups a and b respectively ▸ sp - pooled variance 4. INDEPENDENT SAMPLES Let: EQUAL VARIANCE ASSUMED _ _ 2
variance for groups a and b respectively ▸ na and nb - sample size for groups a and b respectively 4. INDEPENDENT SAMPLES Let: EQUAL VARIANCE ASSUMED 2 2 2
dependent variable y contains continuous data 2. the distribution of y is approximately normal 3. independent variable is binary (xa and xb ) 4. homogeneity of variance between xa and xb 5. observations are independent 6. degrees of freedom (v) are defined as na +nb -2
and b respectively ▸ sa and sb - variance for groups a and b respectively ▸ na and nb - sample size for groups a and b respectively 4. INDEPENDENT SAMPLES Let: EQUAL VARIANCE NOT ASSUMED _ _ 2 2
- variance for groups a and b respectively ▸ sa and sb - standard deviation for groups a and b respectively ▸ na and nb - sample size for groups a and b respectively 4. INDEPENDENT SAMPLES Let: WELCH’S CORRECTED V 2 2
type of formula you used, including whether pooled variance or Welch’s correction was used 2. The value of t, the value of v, and the associated p value 3. The mean for each group (xa and xb ) 4. A plain English interpretation of any difference observed between xa and xb .
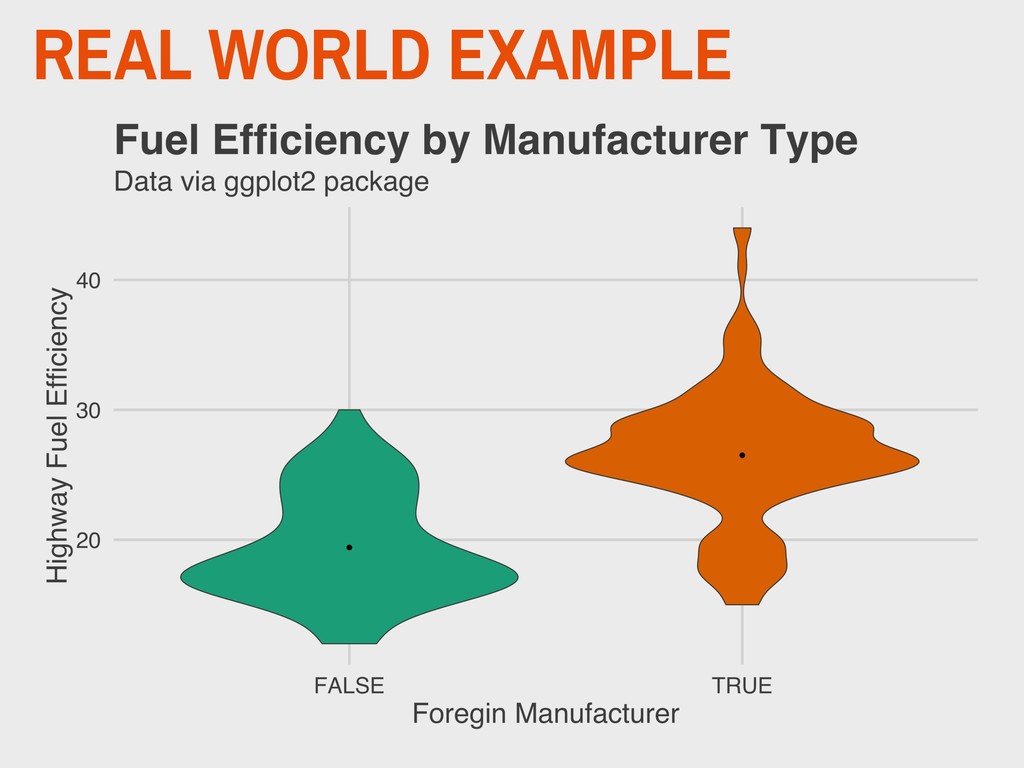
independent t-test calculated with pooled variance (t = 4.052, v = 42, p < .001) suggests that there is a significant difference in scores been men (mean of 20) and women (mean of 25). Results for women were found to be higher, on average, than results for men.
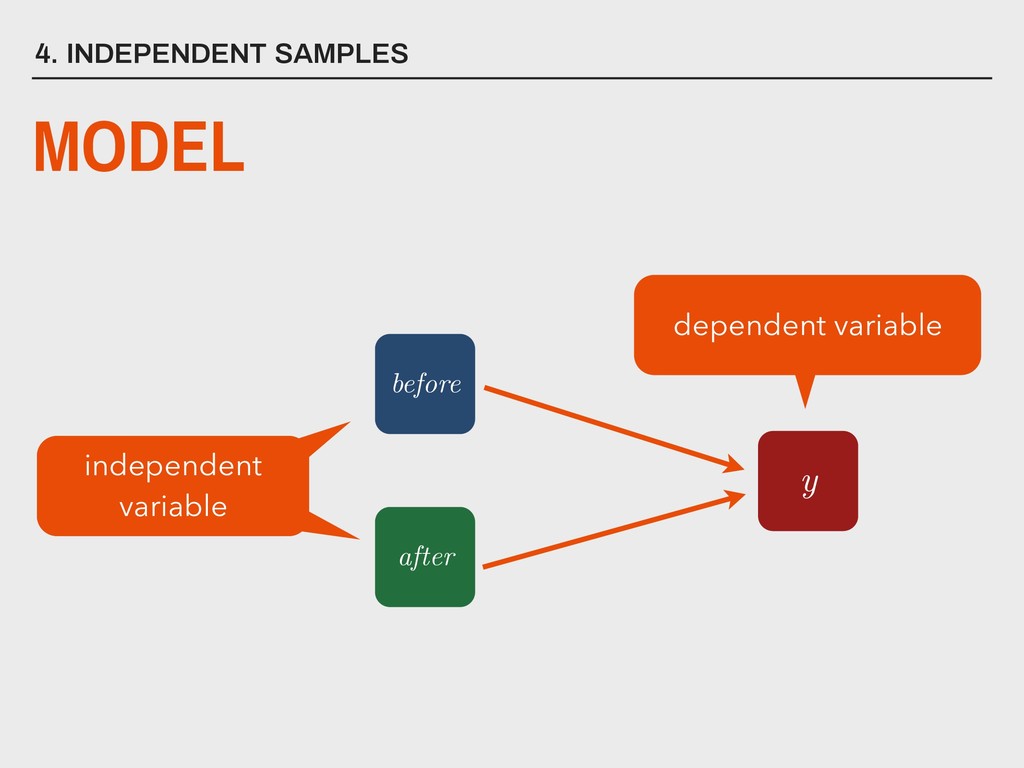
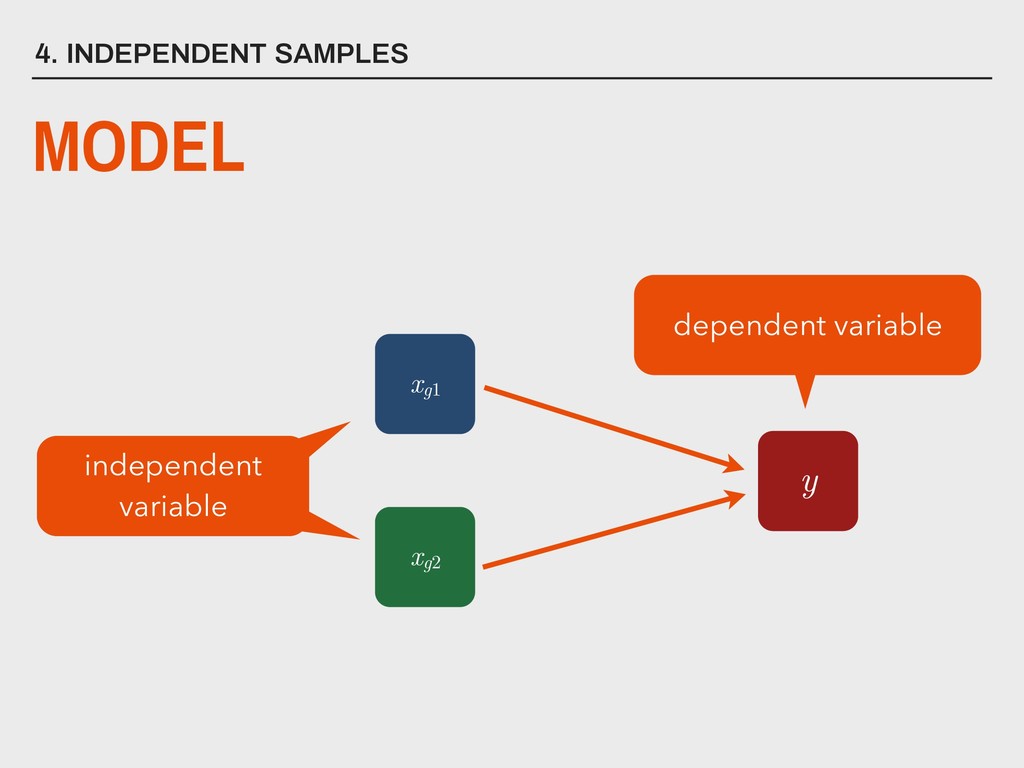
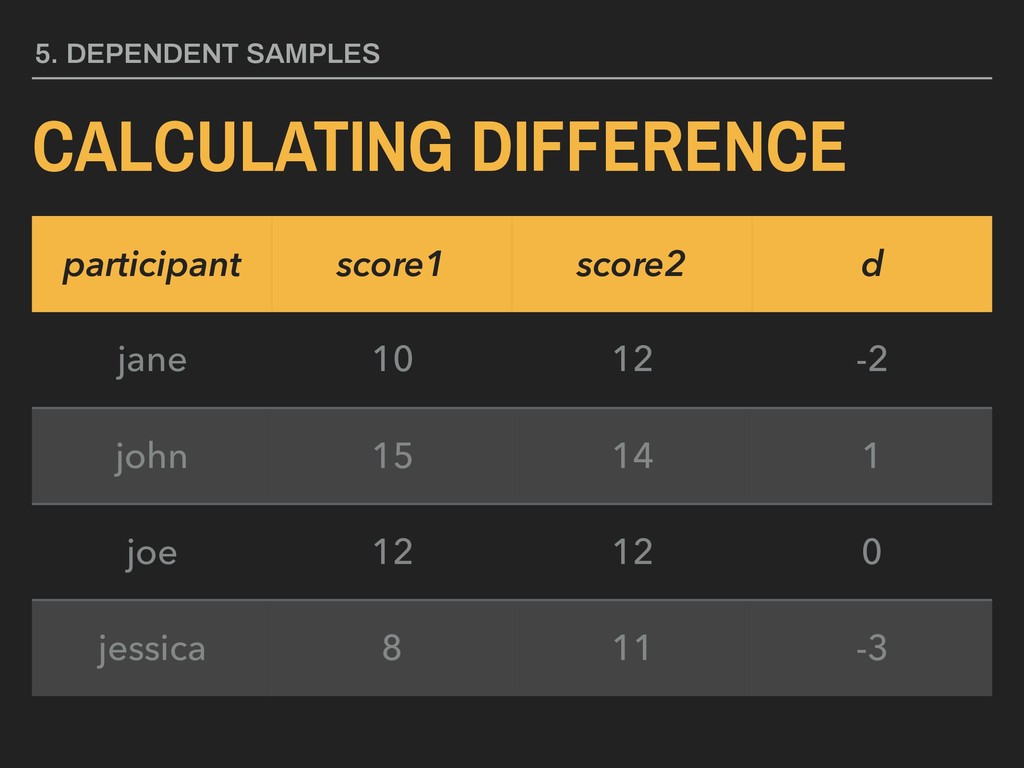
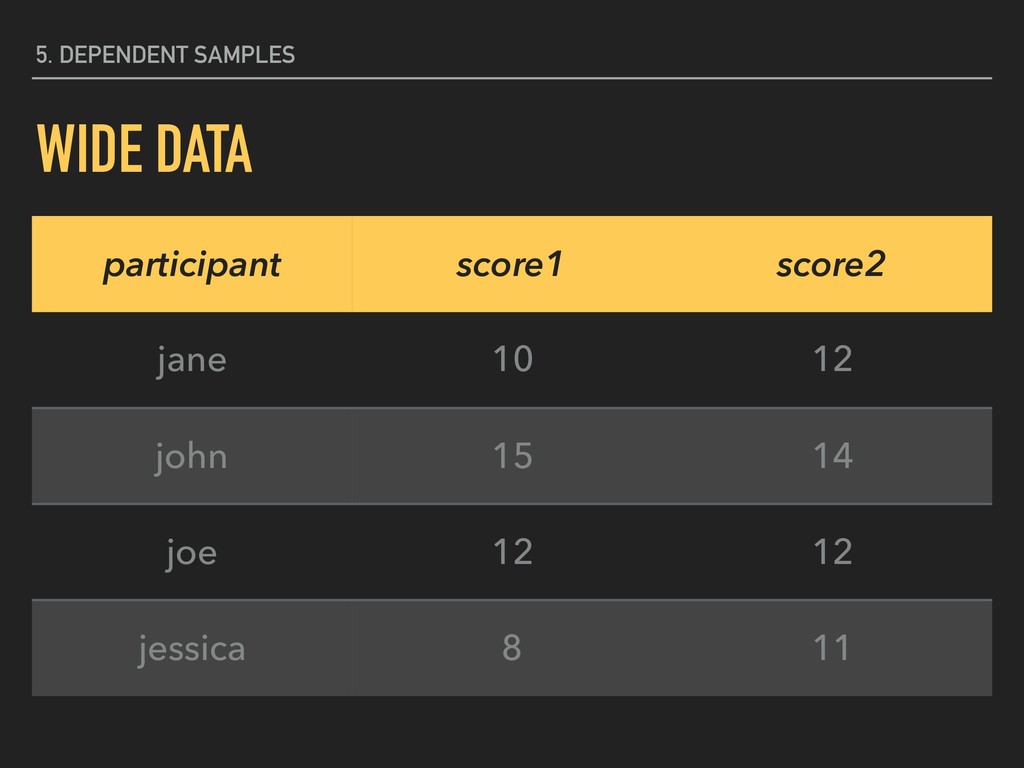
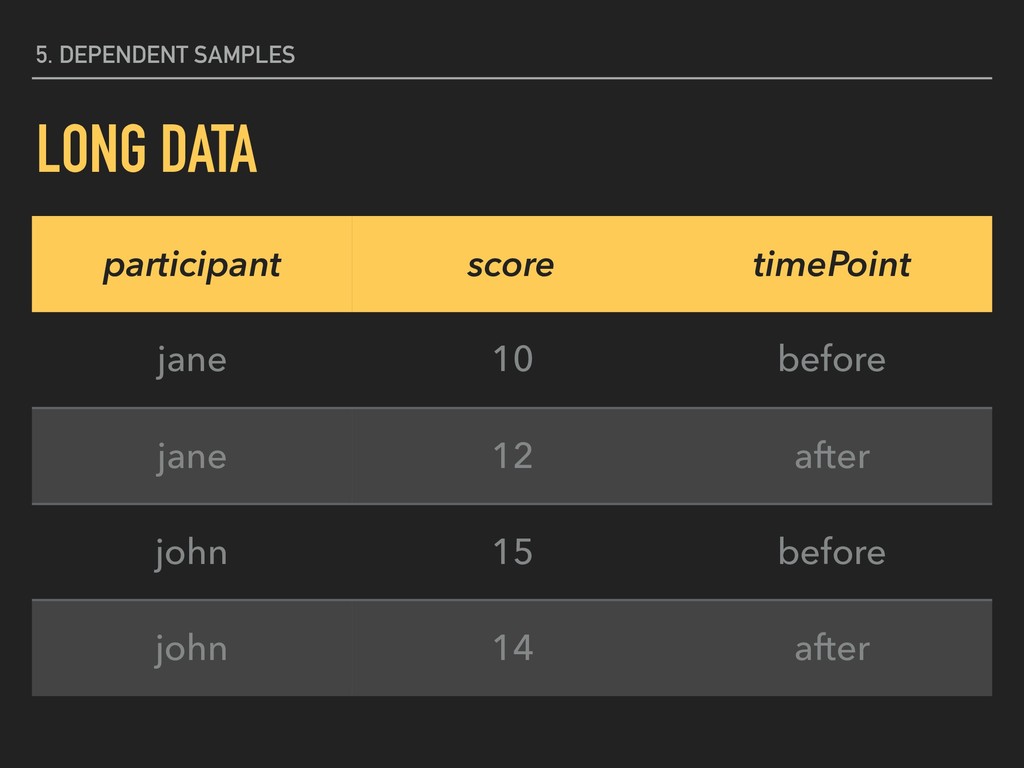
dependent variable y contains continuous data 2. independent variable is binary (xg1 and xg2 ) 3. homogeneity of variance between xg1 and xg2 4. the distribution of the differences between xg1 and xg2 is approximately normally distributed 5. scores are dependent
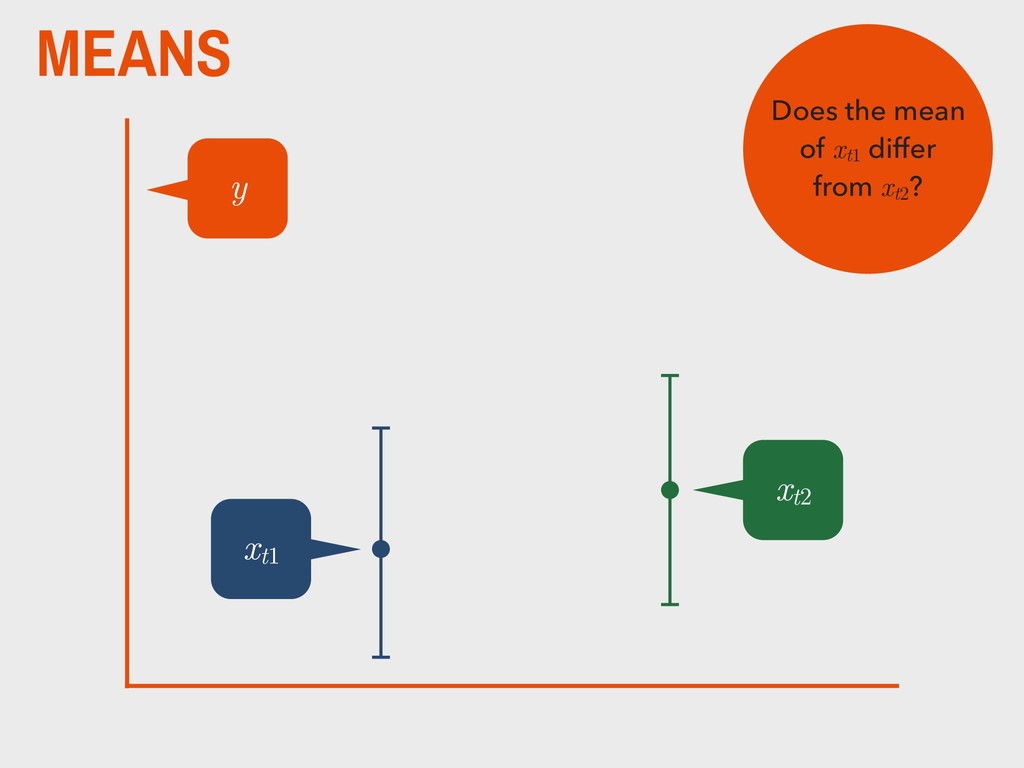
group (xg1 ) is not substantively different from the mean of the second group (xg2 ). H0 The mean of one group (xg1 ) is substantively different from the mean of the second group (xg2 ). HA _ _ _ _
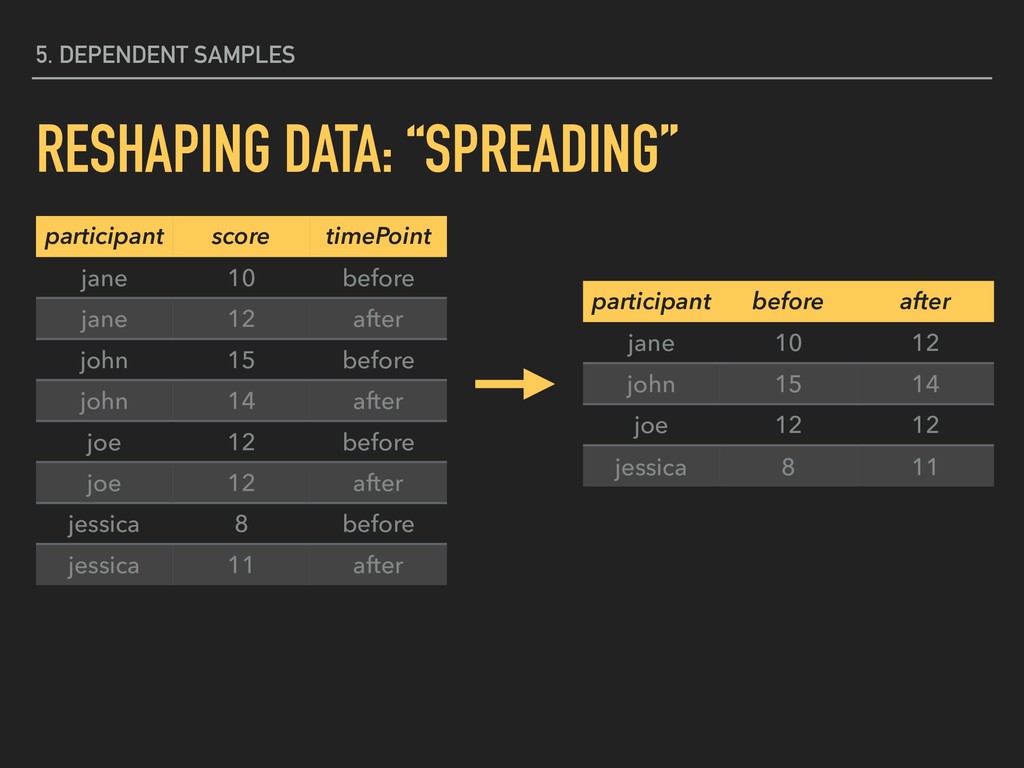
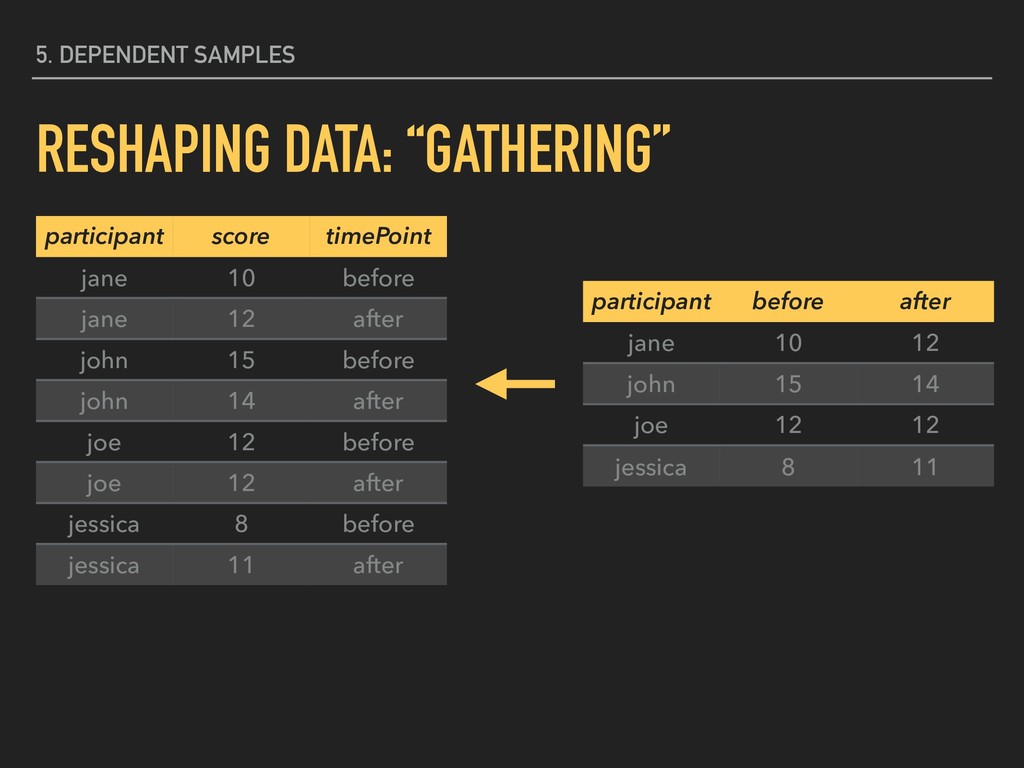
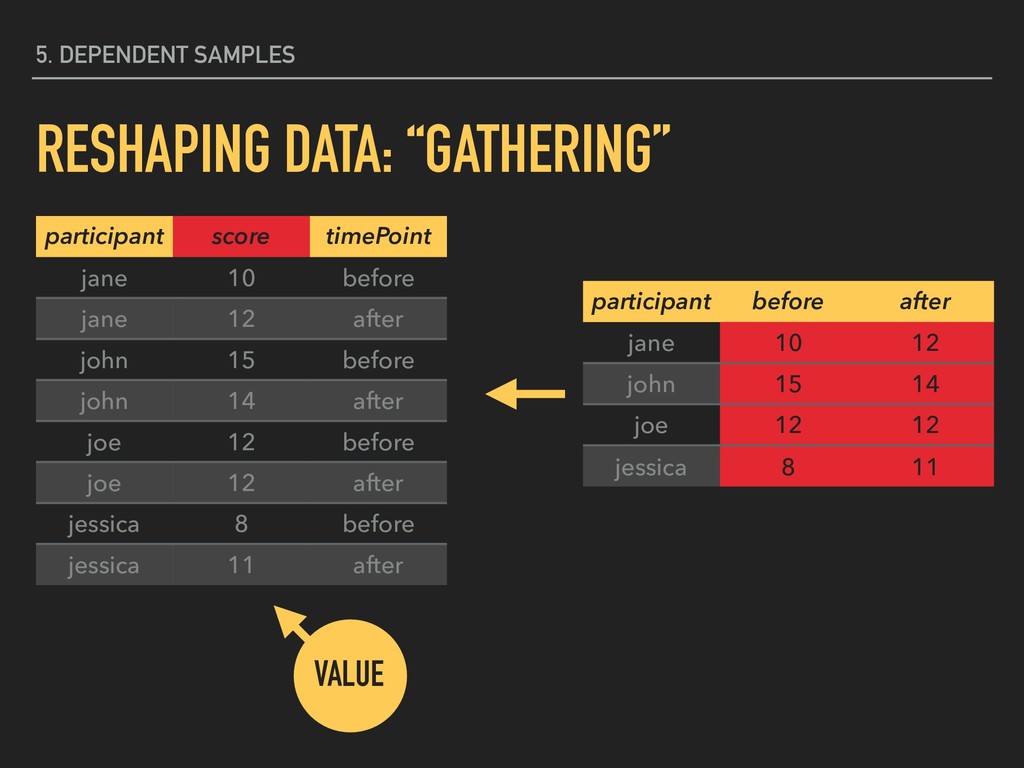
before jane 12 after john 15 before john 14 after joe 12 before joe 12 after jessica 8 before jessica 11 after participant before after jane 10 12 john 15 14 joe 12 12 jessica 8 11
10 before jane 12 after john 15 before john 14 after joe 12 before joe 12 after jessica 8 before jessica 11 after participant before after jane 10 12 john 15 14 joe 12 12 jessica 8 11
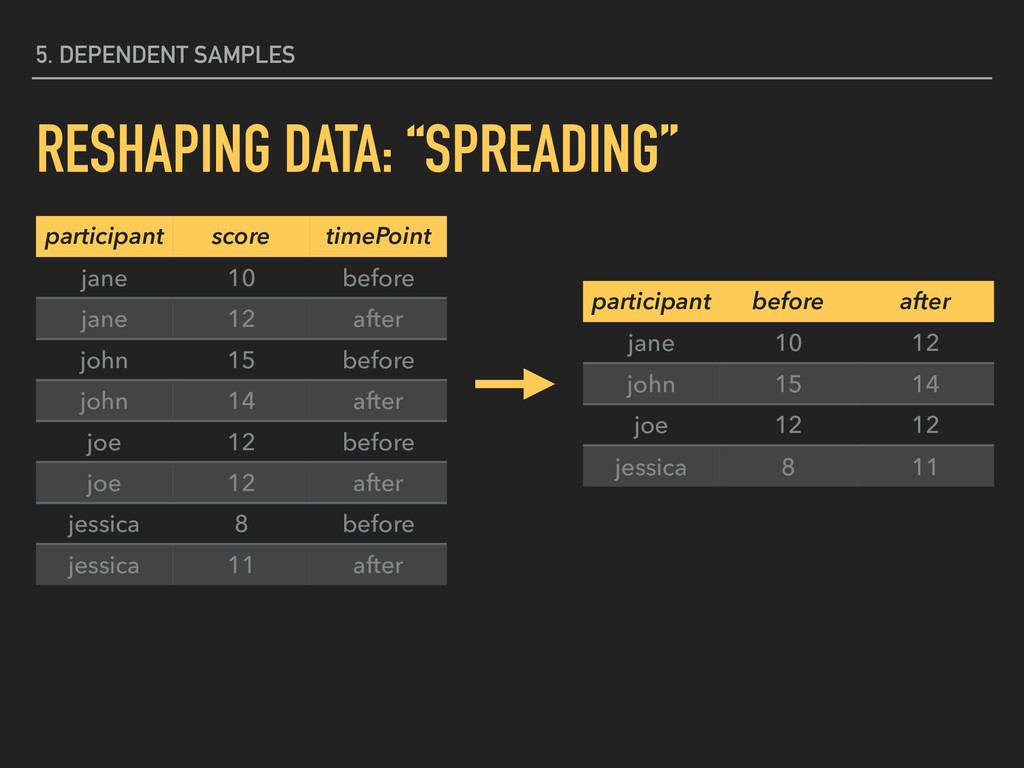
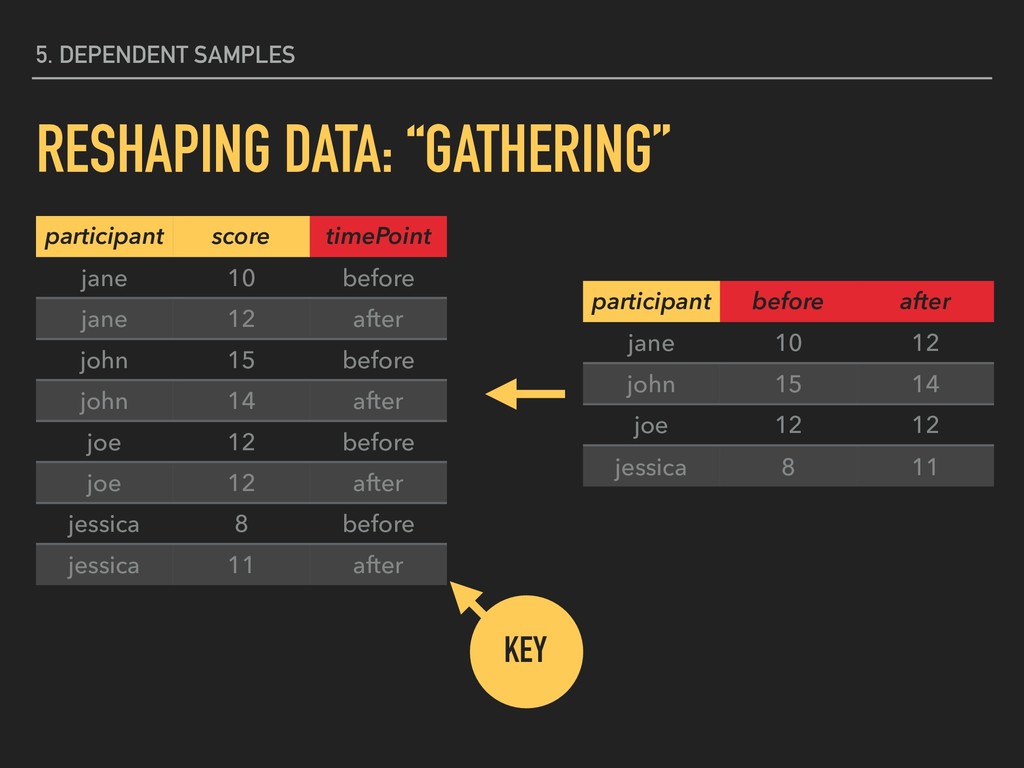
10 before jane 12 after john 15 before john 14 after joe 12 before joe 12 after jessica 8 before jessica 11 after THE “KEY” IS THE VARIABLE WHOSE VALUES WILL BECOME COLUMN HEADINGS
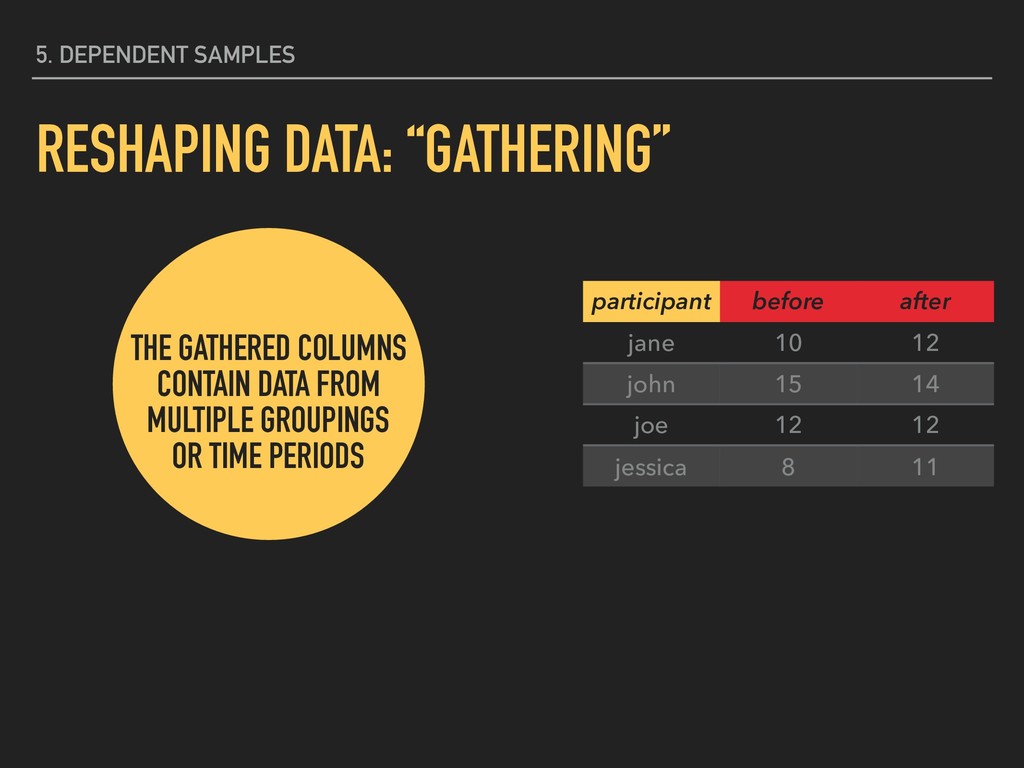
10 before jane 12 after john 15 before john 14 after joe 12 before joe 12 after jessica 8 before jessica 11 after THE “VALUE” IS THE VARIABLE WHOSE VALUES WILL POPULATE THE NEW “KEY” COLUMNS
10 before jane 12 after john 15 before john 14 after joe 12 before joe 12 after jessica 8 before jessica 11 after participant before after jane 10 12 john 15 14 joe 12 12 jessica 8 11
10 before jane 12 after john 15 before john 14 after joe 12 before joe 12 after jessica 8 before jessica 11 after participant before after jane 10 12 john 15 14 joe 12 12 jessica 8 11
10 before jane 12 after john 15 before john 14 after joe 12 before joe 12 after jessica 8 before jessica 11 after participant before after jane 10 12 john 15 14 joe 12 12 jessica 8 11 KEY
10 before jane 12 after john 15 before john 14 after joe 12 before joe 12 after jessica 8 before jessica 11 after participant before after jane 10 12 john 15 14 joe 12 12 jessica 8 11 VALUE
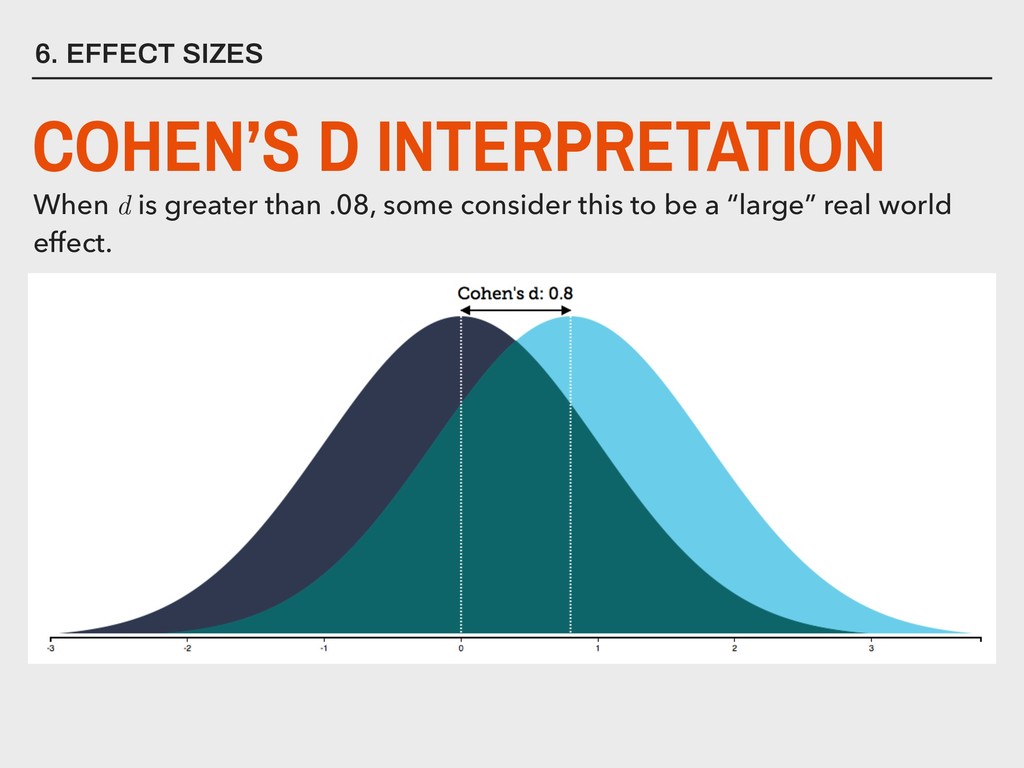
and b respectively ▸ sa and sb - variance for groups a and b respectively ▸ na and nb - sample size for groups a and b respectively ▸ d - effect size 4. INDEPENDENT SAMPLES Let: EQUAL VARIANCE NOT ASSUMED _ _ 2 2 pooled variance
the solution to the various issues in the lab. If you have any problems - including RStudio missing or packages not installing, let me know asap. SOC 5050 annotated bibliographies were due today! Lab 06 and Lecture Prep 08 are due before the next lecture. Feedback backlog being unjammed this week - keep eyes out for feedback on PS-01 and PS-02 - please make sure to apply feedback moving forward with PS-04 etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}