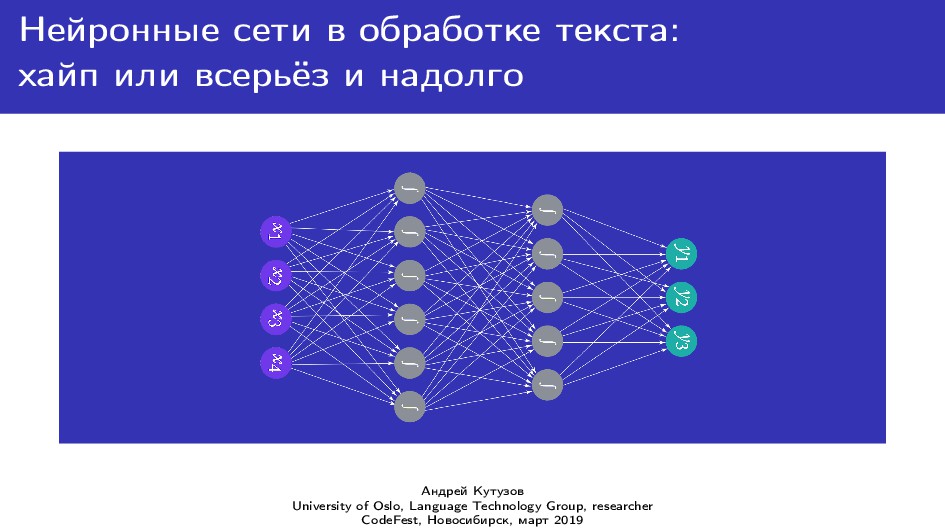
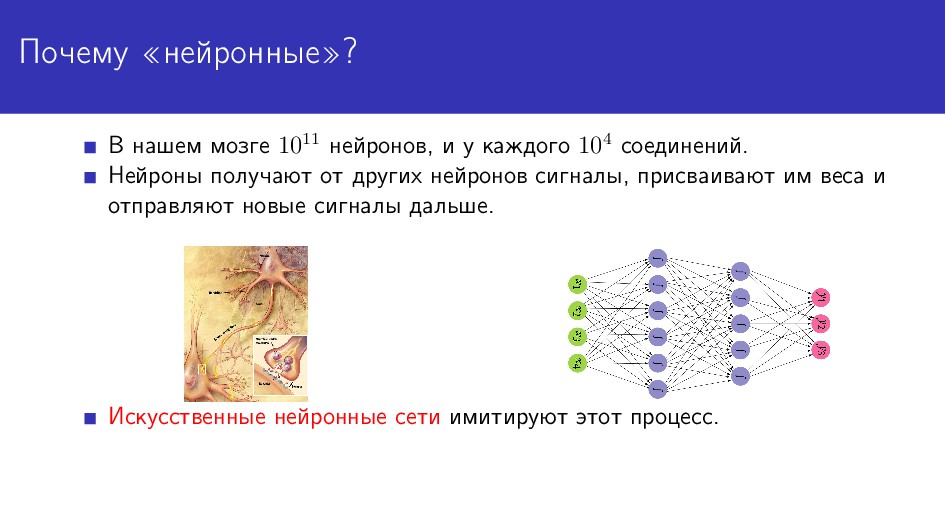
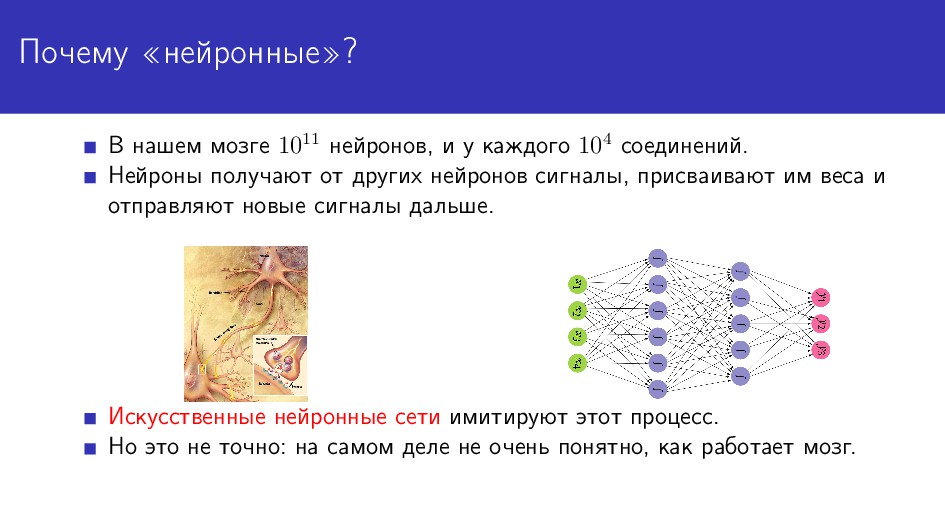
Автоматическая обработка текстовых данных (natural language processing, NLP) сейчас всё больше и больше становится привязана к использованию разнообразных искусственных нейронных сетей. Это следующий шаг в NLP после правиловых методов и классического машинного обучения. Я расскажу о том, почему нейронные сети подняли такой шум в NLP (и других областях data science), и как с ними связаны дистрибутивные модели значения в языке, вроде word2vec, fastText, ElMO и т.д. Я кратко обрисую основные особенности и различия популярных популярных в NLP фреймворков для работы с нейронными сетями: PyTorch, TensorFlow, Keras и т.п. Кроме того, расскажу, в чём особенности обработки языковых данных и какие методы их предобработки часто оказываются полезными.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
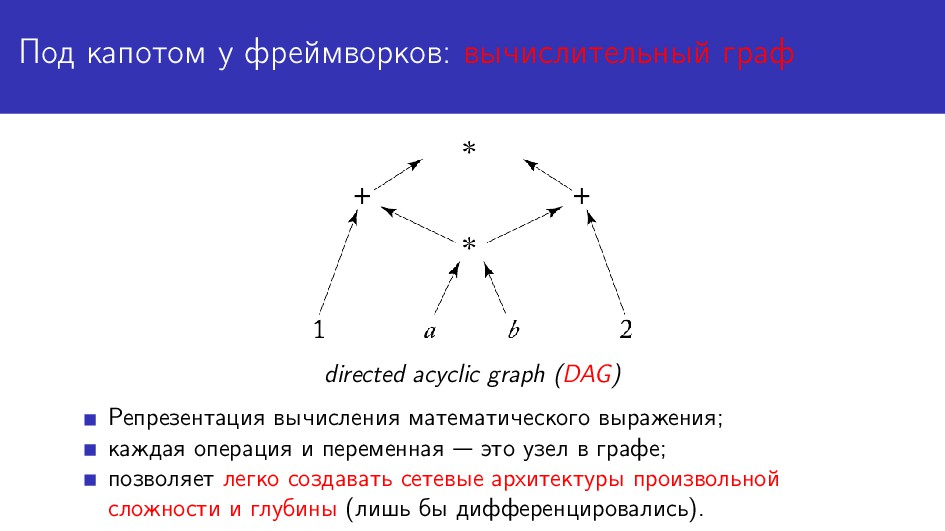{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}