Про онлайн-эксперименты и А/Б-тесты не рассказывал только ленивый. Тем не менее, снова поговорим про то, как правильно организовать А/Б-тестирование, чтобы получать статистически значимые результаты.
Коротко вспомним, что представляет собой процедура тестирования статистических гипотез. Вооружившись этими знаниями, мы разберем 7 основных ошибок при проведении А/Б-тестов. Посмотрим практические примеры того, к каким парадоксальным результатам может приводить плохо организованный процесс сбора данных и неверная интерпретация результатов.
{kind=link}
{kind=link}
{kind=link}
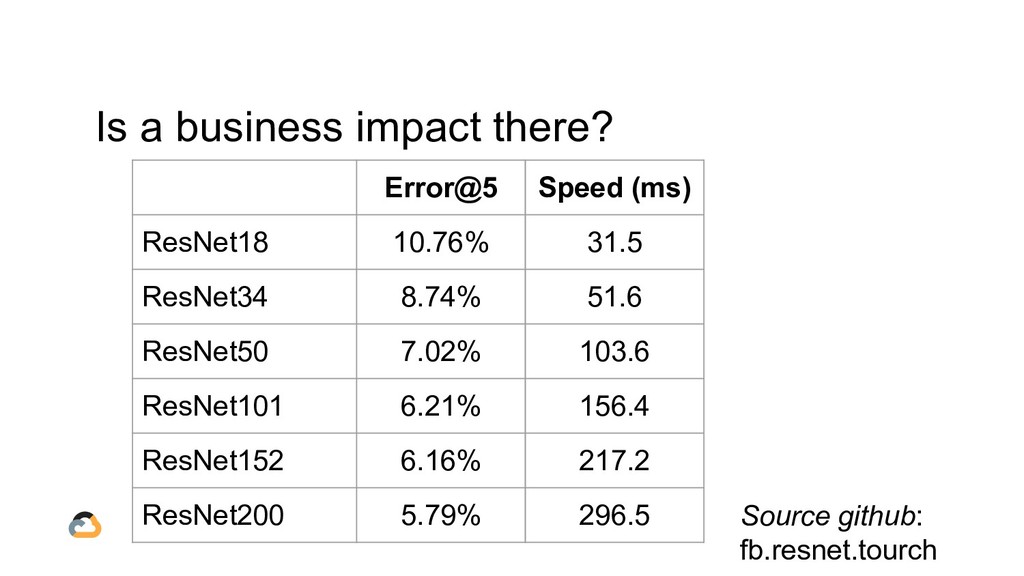
![[Almost] any problem can be solved. The issue is whether](https://files.speakerdeck.com/presentations/fd5ffeaf38434ceab37c0a48e052196d/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![... in order to get those [better] results, we need](https://files.speakerdeck.com/presentations/fd5ffeaf38434ceab37c0a48e052196d/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
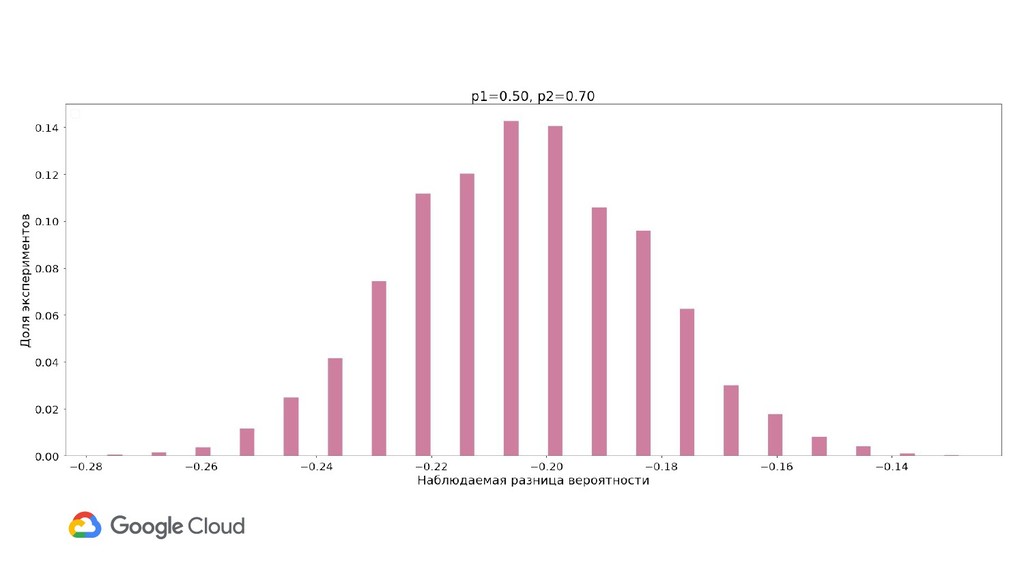{kind=link}
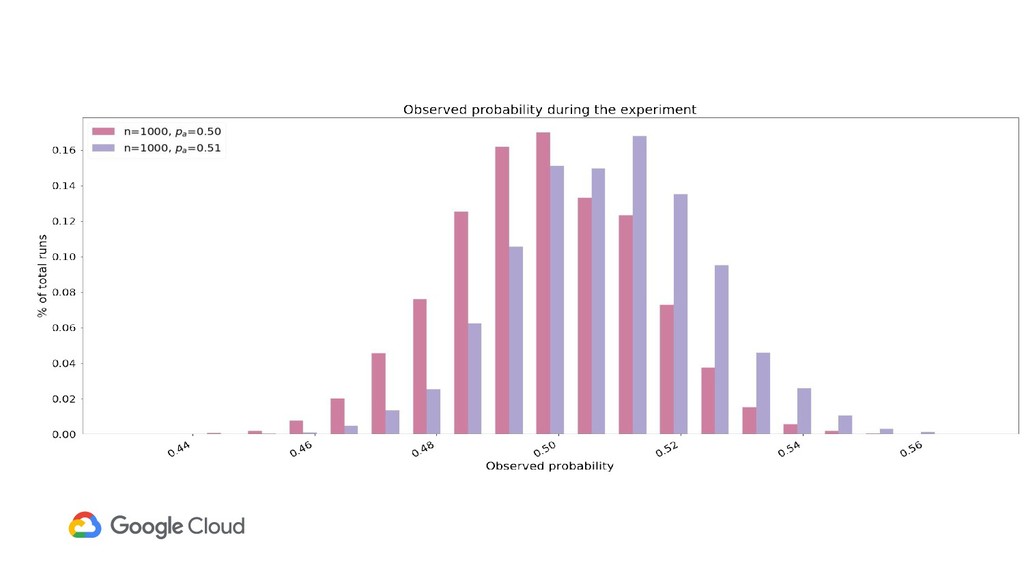{kind=link}
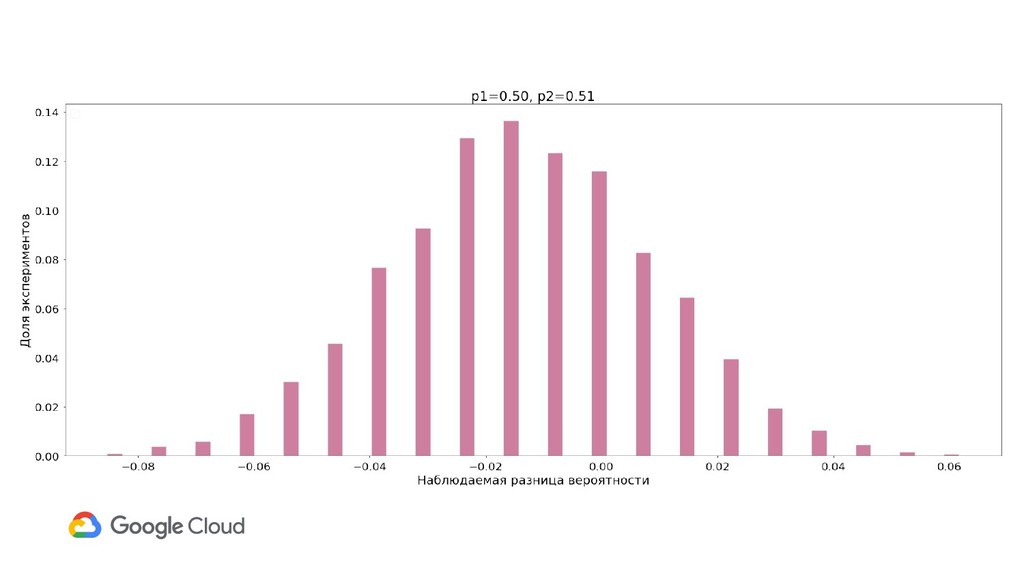{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}