𝑣𝑗 σ 𝑗′=1 𝑛 exp 1 𝑑 𝑞𝑖 𝑘 𝑗′ T 𝑧𝑖 = σ𝑗=1 𝑛 𝜙 𝑞𝑖 𝜙 𝑘𝑗 T 𝑣𝑗 σ 𝑗′=1 𝑛 𝜙 𝑞𝑖 𝜙 𝑘 𝑗′ T = 𝜙 𝑞𝑖 σ𝑗=1 𝑛 𝜙 𝑘𝑗 T 𝑣𝑗 𝜙 𝑞𝑖 σ 𝑗′=1 𝑛 𝜙 𝑘 𝑗′ T 通常のセルフアテンションはこう。 この「単語 𝑖 から単語 𝑗 への注意の強さ」exp 1 𝑑 𝑞𝑖 ⋅ 𝑘𝑗 を何らかの特徴 softmax 𝑖 単語目にセルフアテンションを適用した 𝑧𝑖 を得る のに、𝑗 = 1, ⋯ , 𝑛 に対し 𝑞𝑖 𝑘𝑗 T を計算する必要。 ⇒ 𝑖 = 1, ⋯ , 𝑛 単語目すべてのセルフアテンション を得るには2重ループになり計算量が 𝑂(𝑛2) になる。 和と内積が交換するため、 点線で囲んだ箇所を 𝑖 = 1, ⋯ , 𝑛 で使い回せるので、 計算量が 𝑂(𝑛) になる。 Kernelized Attention のモチベーション(1 / 2) 単語 𝑖 から単語 𝑗 への注意の強さ (仮称) 空間における内積で近似したい (= Kernelized Attention )。 特徴写像 注意の強さ (仮称) カーネル法 ―― 線形モデルを適用するべくデータの方を特徴空間に埋め込もうとする方法論。 特徴写像は不要で特徴の内積があればよい。今回は線形モデルなら計算量が落ちる点にモチ ベーションがある。なお exp(・,・/√d ) は内積の要請を満たさないので近似することになる。 なので上式の特徴写像 𝜙 をどうすべきか知りたい。 7
{kind=link}
{kind=link}
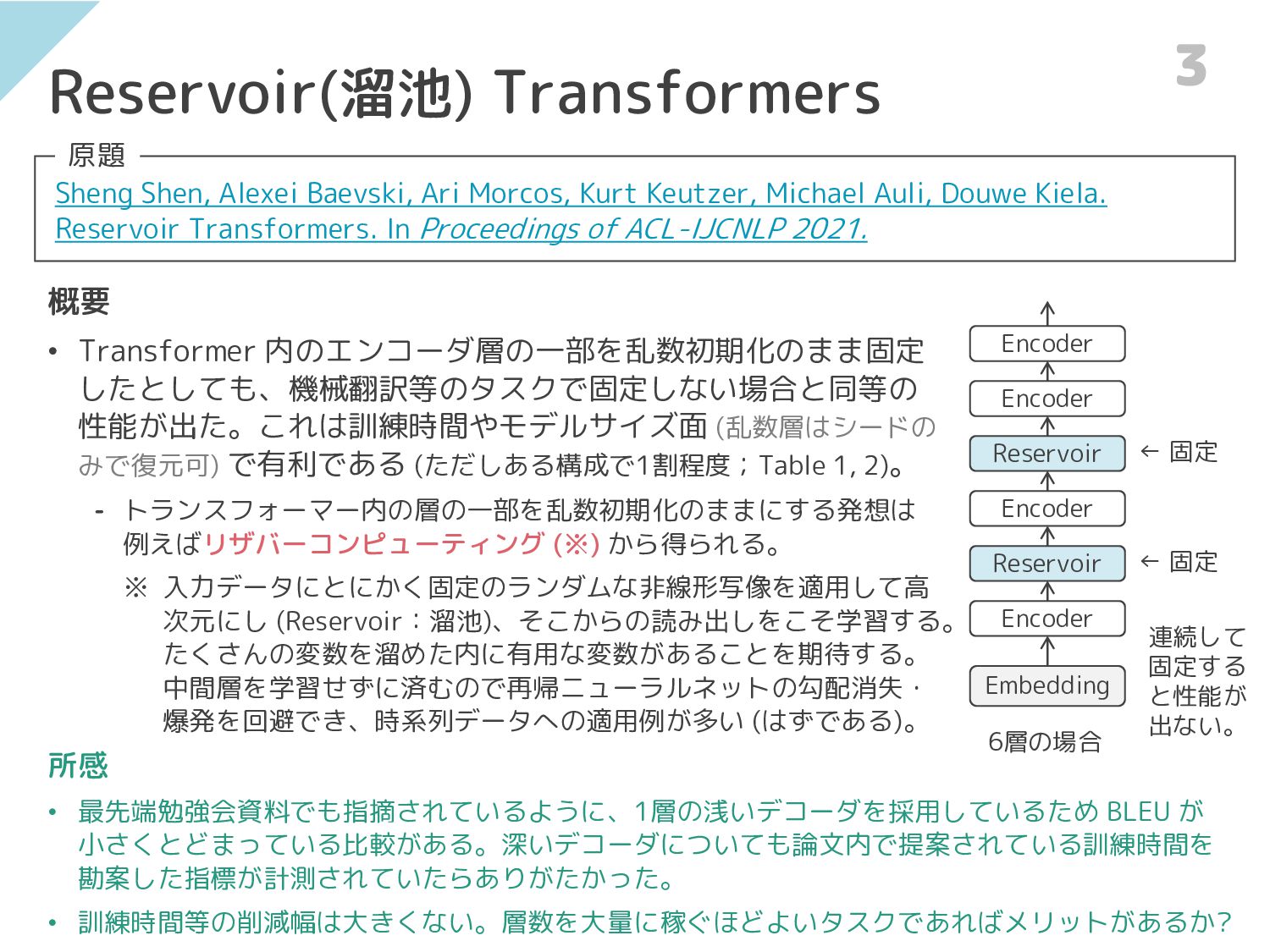{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
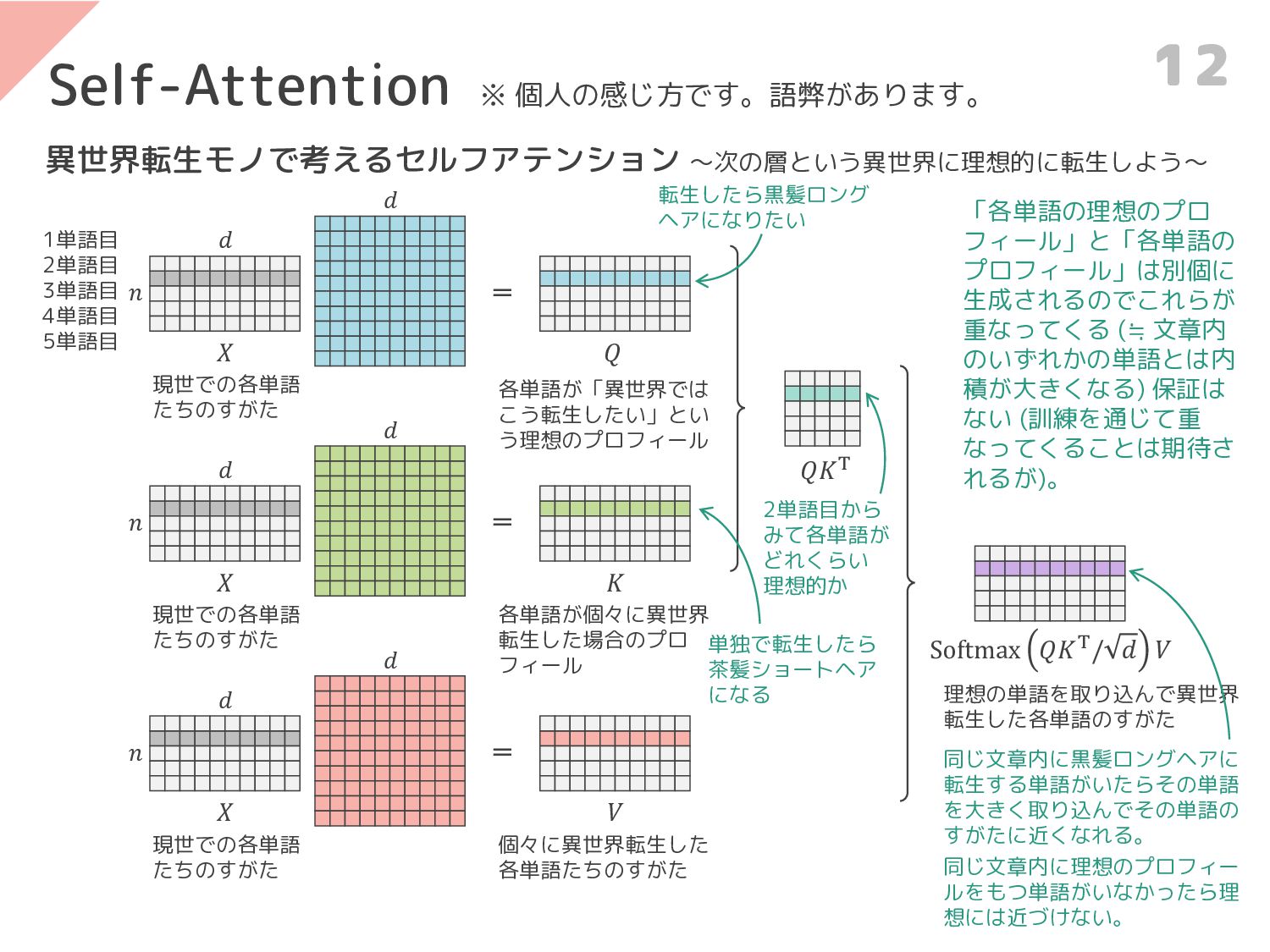{kind=link}
{kind=link}