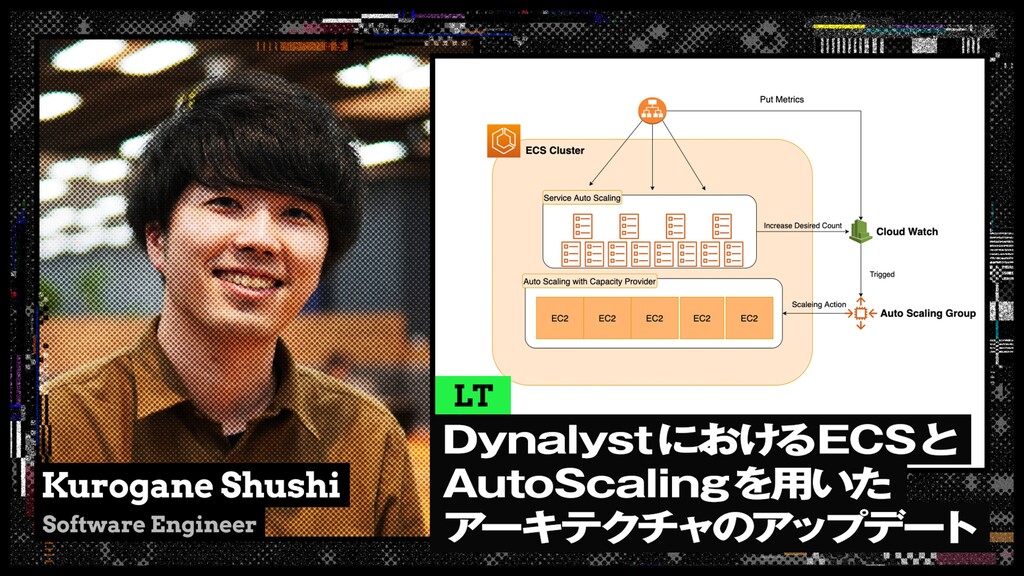
□ 登壇者
黒金 宗史
□ 発表について
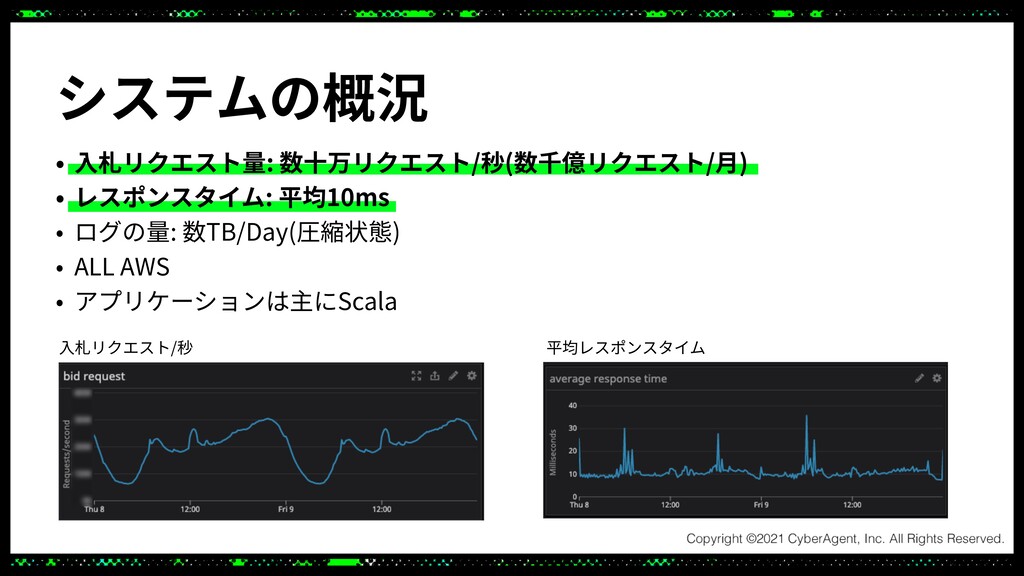
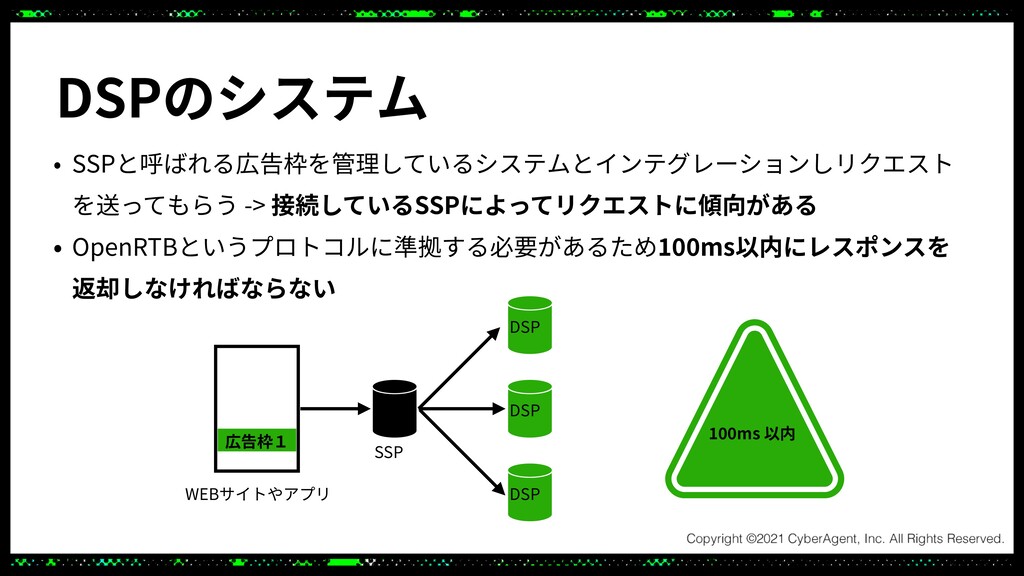
Dynalystはゲームに特化したリターゲティング広告のシステムを開発、運用しています。リクエストは秒間数十万にも上り広告システムの制約上、100ms以内にレスポンスを返さなくてはなりません。
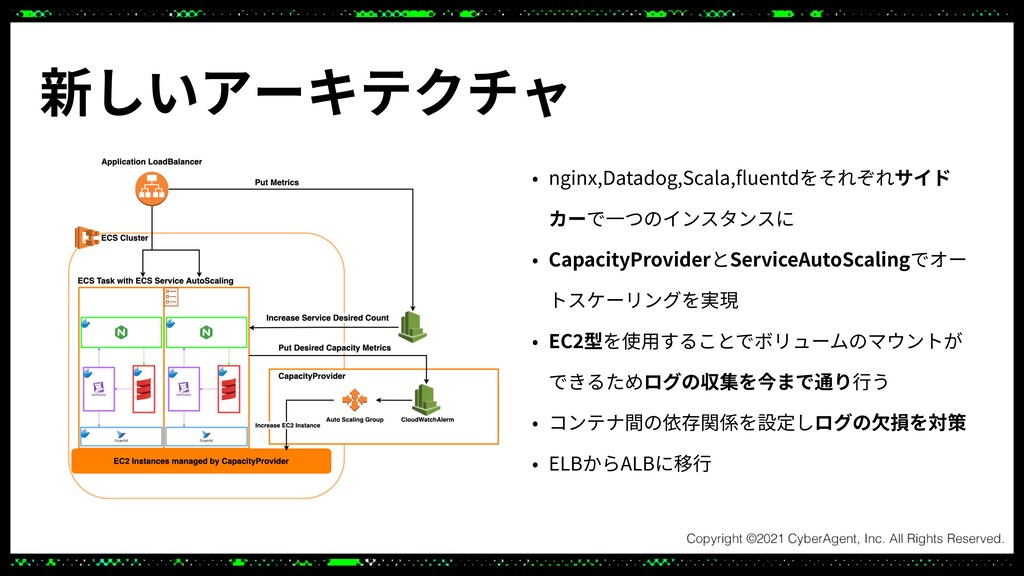
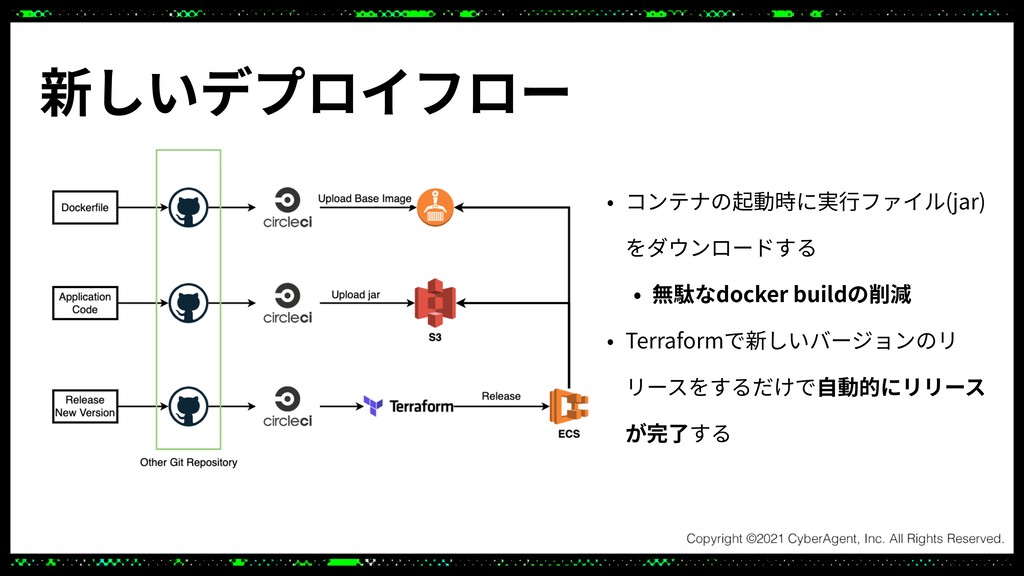
プロダクトに数々のMLモデルを組み込んだりさらにプロダクトをスケールさせるためにはシステムのアップデートが不可欠になりました。
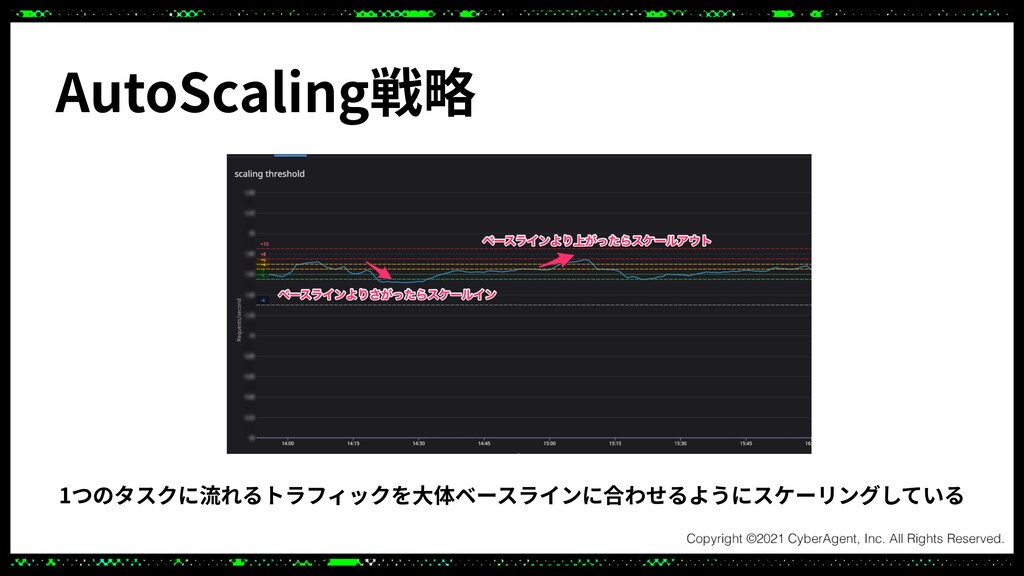
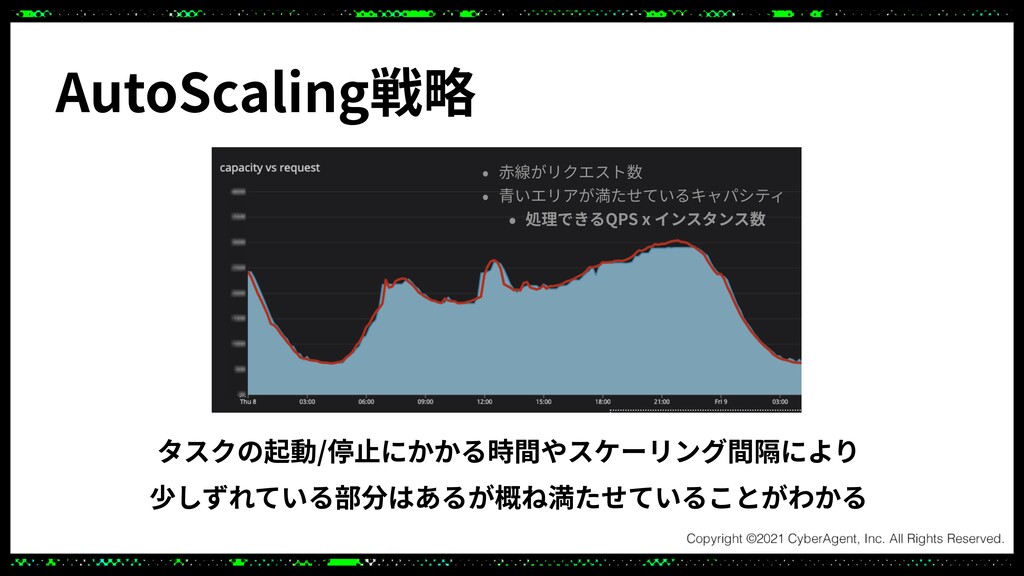
このセッションでは高トラフィックかつ低レイテンシなシステムをより低コストで運用しやすいシステムにするためにECSとAutoScalingを用いてアップデートしたことについてご紹介させていただきます。
□ CA BASE NEXT (CyberAgent Developer Conference by Next Generations) とは
20代のエンジニア・クリエイターが中心となって創り上げるサイバーエージェントの技術カンファレンスです。
当日はセッション・LT・パネルディスカッション・インタビューセッションを含む約50のコンテンツをYouTube Liveを通じて配信します。
イベントページ
□ 採用情報
サイバーエージェントに少しでも興味を持っていただきましたら、お気軽にマイページ登録やエントリーをおねがいします!
◆新卒エンジニア採用
エントリー・マイページ登録はこちら
採用関連情報のまとめはこちら
◆新卒クリエイター採用
エントリー・マイページ登録はこちら
◆中途採用
採用情報はこちら
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}