the process of giving explanations to humans. n There is no clear definition, but it is l To explain not only output of models (what) but also the reason (why). l To interpret the model by using some method or criteria.
the model? n We can make Fair and Ethical decision. l (i.e.) Medical diagnosis, Terrorism detection n We can trust the model prediction. n We can generate hypotheses. l (i.e.) a simple regression model might reveal a strong association between thalidomide use and birth defects or smoking and lung cancer (Wang et al., 1999) Wang et al. Smoking and the occurence of alzheimer’s disease: Cross-sectional and longitudinal data in a population-based study. American journal of epidemiology, 1999.
model. l Rule-base method, decision tree, linear regression model… Sometimes, we can’t get enough accuracy by doing so. 2. Use some method to interpret.
interpretability l Interpreting the whole tendency of model or data. l Sometimes not accurate locally. n Local interpretability l Interpreting the limited area of model or data. l We can get more accurate explanations.
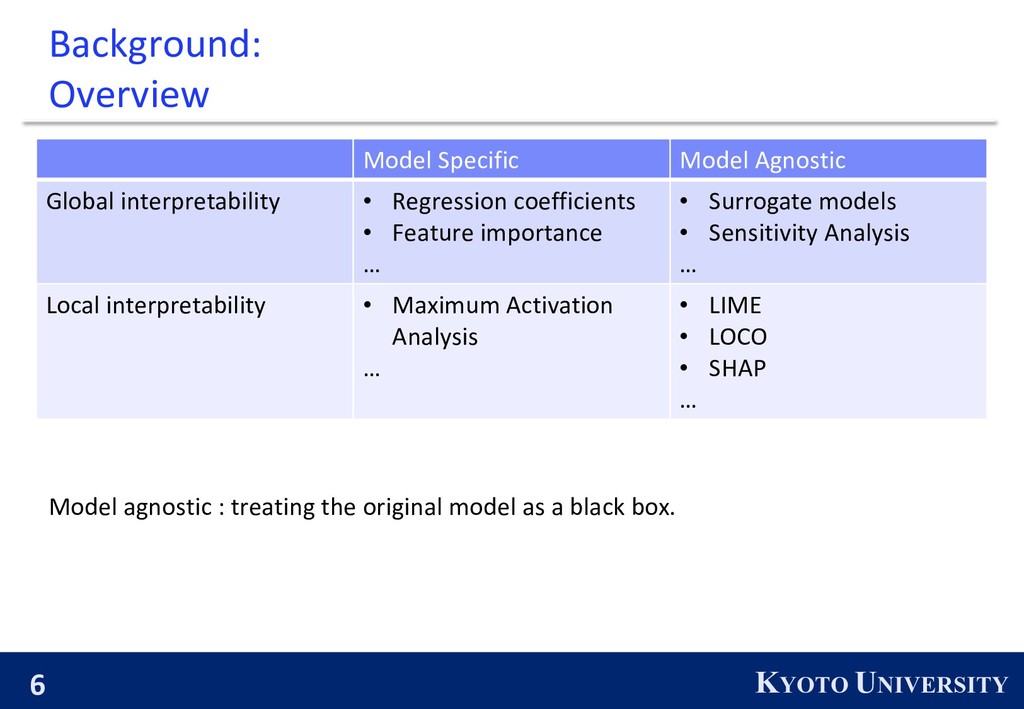
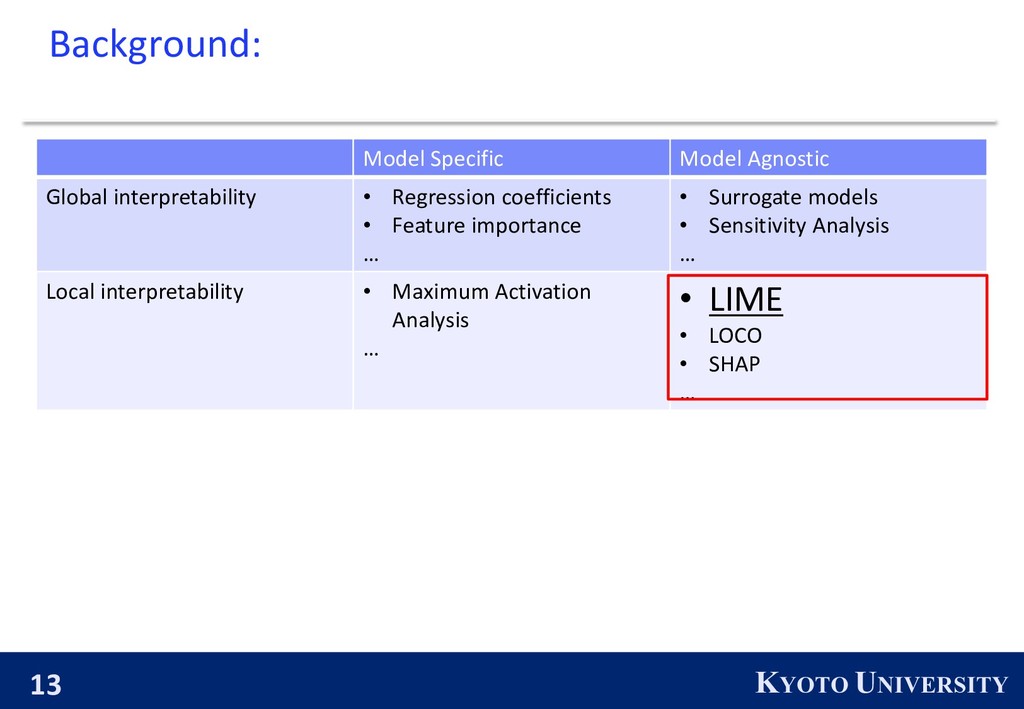
interpretability • Regression coefficients • Feature importance … • Surrogate models • Sensitivity Analysis … Local interpretability • Maximum Activation Analysis … • LIME • LOCO • SHAP … Model agnostic : treating the original model as a black box.
Sparse Linear Regression ! = #$ % & By doing Lasso regression, we know which features are important. n Feature importance l Random Forest (trees.feature_impotances_) l In model agnostic way, l Do ROC analysis for each explanatory variable.
Surrogate models l Finding a simple model which can substitute the complex model. l Surrogate models are usually created by training a linear regression or decision tree on the original inputs and predictions of a complex model. n Sensitivity Analysis l Investigating whether model behavior and outputs remain stable when data is perturbed. S x = $f $x Simple model Original inputs Teaching Complex model
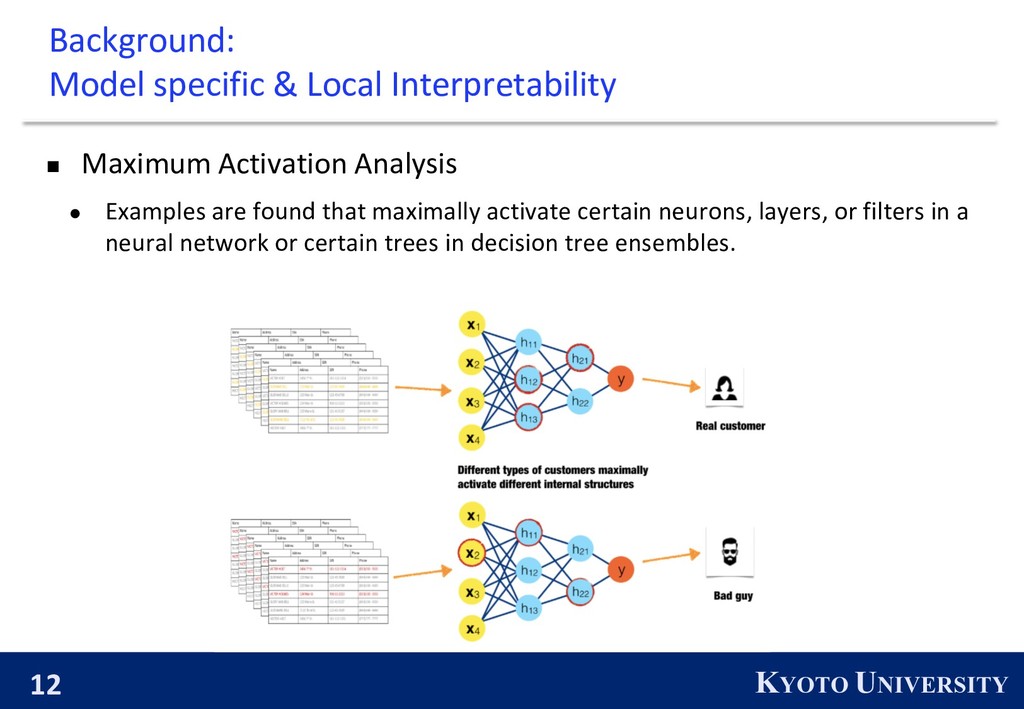
Maximum Activation Analysis l Examples are found that maximally activate certain neurons, layers, or filters in a neural network or certain trees in decision tree ensembles.
: “Why Should I Trust You?” Explaining the Predictions of Any Classifier (KDD ‘16) n Authors: Marco Tulio Ribeiro University of Washington Sameer Singh University of Washington Carlos Guestrin University of Washington
trust a model or a prediction, they will not use it.” n Determining trust in individual predictions is an important problem when the model is used for decision making. n By “explaining a prediction”, they mean presenting textual or visual artifacts that provide qualitative understanding of the relationship between the instance’s components (e.g. words in text, patches in an image) and the model’s prediction.
They must be interpretable : they provide good understanding between the input variables and the response. n Another essential criterion is local fidelity : explainers must correspond to how the model behaves around the instances being explained. n Explainers should be model-agnostic : treating the original model as a black box.
n ! ∈ ℝ$ : original representation of an instance being explained. l For text classification, ! is a feature like word embedding. l For image classification, ! is a tensor of with three color channels per pixel. n !′ ∈ {0, 1}$+ : a binary vector for its interpretable representation. l For text classification, !′ is a binary vector indicating the presence or absence of a word. l For image classification, !′ is a binary vector indicating the “presence” or “absence” of a contiguous patch of similar pixels (a super-pixel).
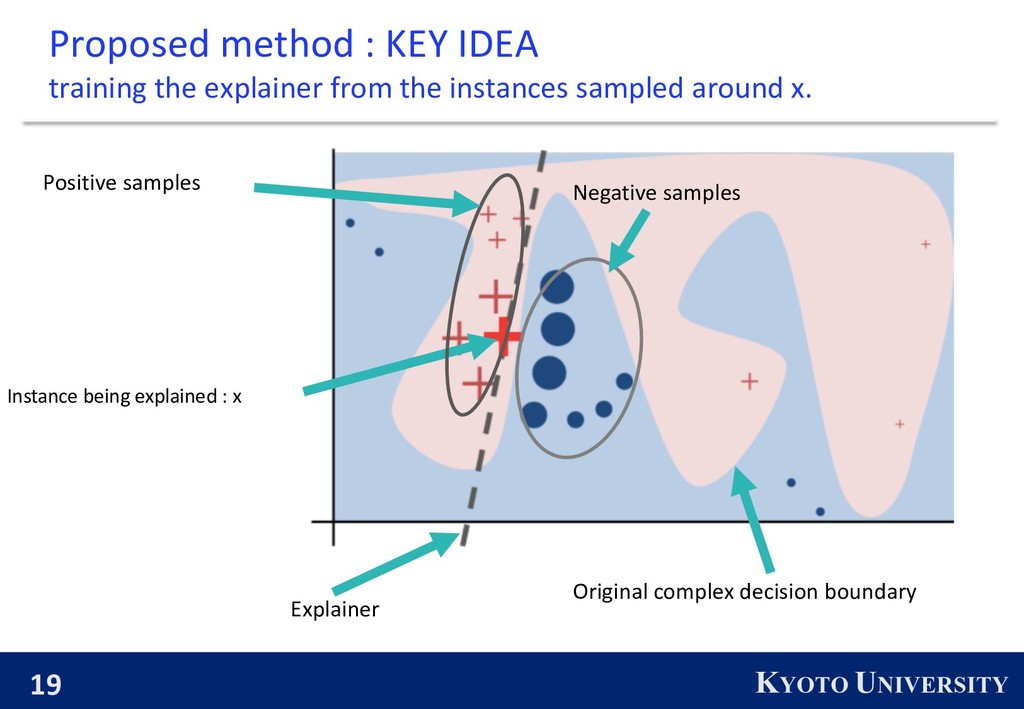
explainer from the instances sampled around x. Instance being explained : x Explainer Original complex decision boundary Negative samples Positive samples
sample around x? n They sample instances around x′ by drawing non-zero elements of x# uniformly at random. n Given a perturbed sample z# ∈ {0, 1}+, they recover the original representation z ∈ ℝ+ and obtain f z , which is used as a label for explanation model. Original representation: x Interpretable representation : x’ perturbed sample : z’ z Label of sample z : f(z) Drawing
complexity n ! : the instance being explained n $ : target model which we want to interpret. n % ∈ ' : an interpretable model such as linear models, decision trees. n () (+) : proximity measure between an instance + to !. n Ω(%) : a measure of complexity of the explanation g. n ℒ : locality loss
G be the class of linear models ; g z′ = w' ( z′ n Locality loss ℒ is weighted square loss: p *(,) : probability that z belongs to a certain class. p ./ (,) : sample weight that indicates the distance between x and z. n Sampling weight π1 (z) is defined as follows : π1 z = exp(− D x, z 8 σ8 )
When we want to get explanations for image classifiers, we wish to highlight the super-pixels with positive weight toward a specific class. n Classifier : Google’s Inception neural networks The reason why Acoustic guitar was classified as Electric guitar
model n Explaining a single prediction is not enough to evaluate and assess trust in the model as a whole. They propose to give a global understanding of the model by explaining a set of individual instances. Selecting a good set of instances to explain the whole model. n Problem is p Given : a set of instances X p Output : B instances for users to inspect.
cover as many important features as possible. the most important feature • c : coverage • !" : the global importance of feature j. • The goal of pick problem is to find a set of instances that maximizes coverage. • Due to submodularity, a greedy algorithm can be used to solve.
n They evaluate LIME and SP-LIME in the following settings: 1. Can users select the best classifier? 2. Can non-experts improve a classifier? 3. Do explanations lead to insights? n Dataset : l Training : “Christianity” and “Atheism” documents (including not generalizing features such as authors and headers.) l Testing : 819 webpages about each class (real-world data.) n Human subjects are recruited on Amazon Mechanical Turk.
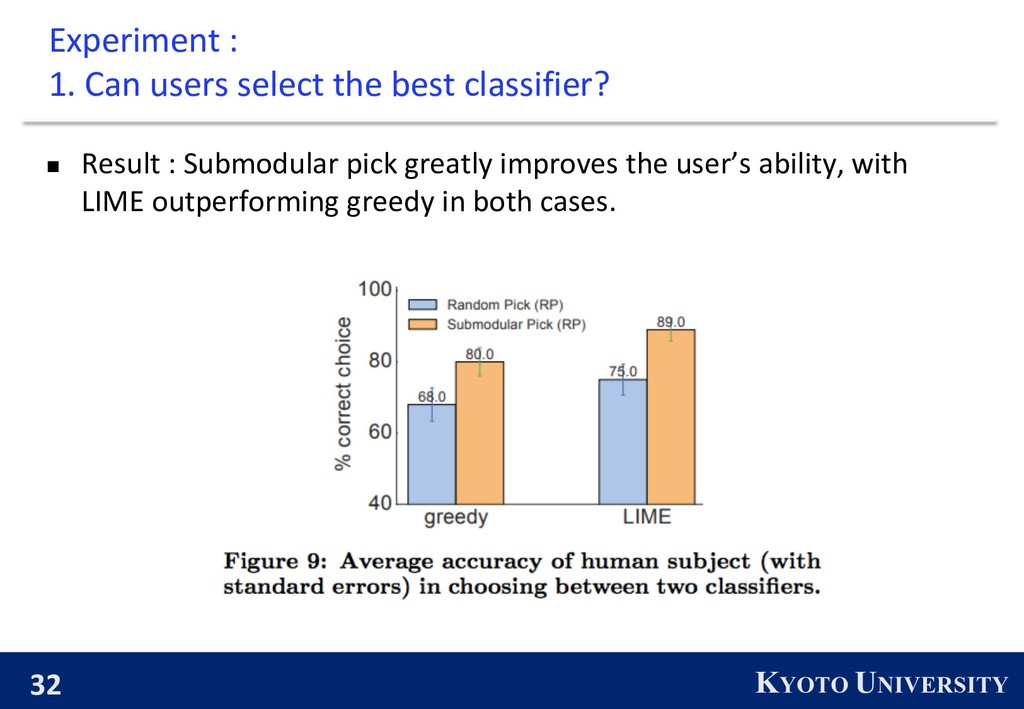
best classifier? n Evaluating whether explanations can help users decide which classifier is better. n Two classifiers : l SVM trained on the original 20 newsgroups dataset l SVM trained on a “cleaned” dataset. (authors and headers are removed) n Users are asked to select which classifier will perform best in the real world. n Explanations are produced by greedy or LIME. n Instances are selected either by random or Submodular Pick.
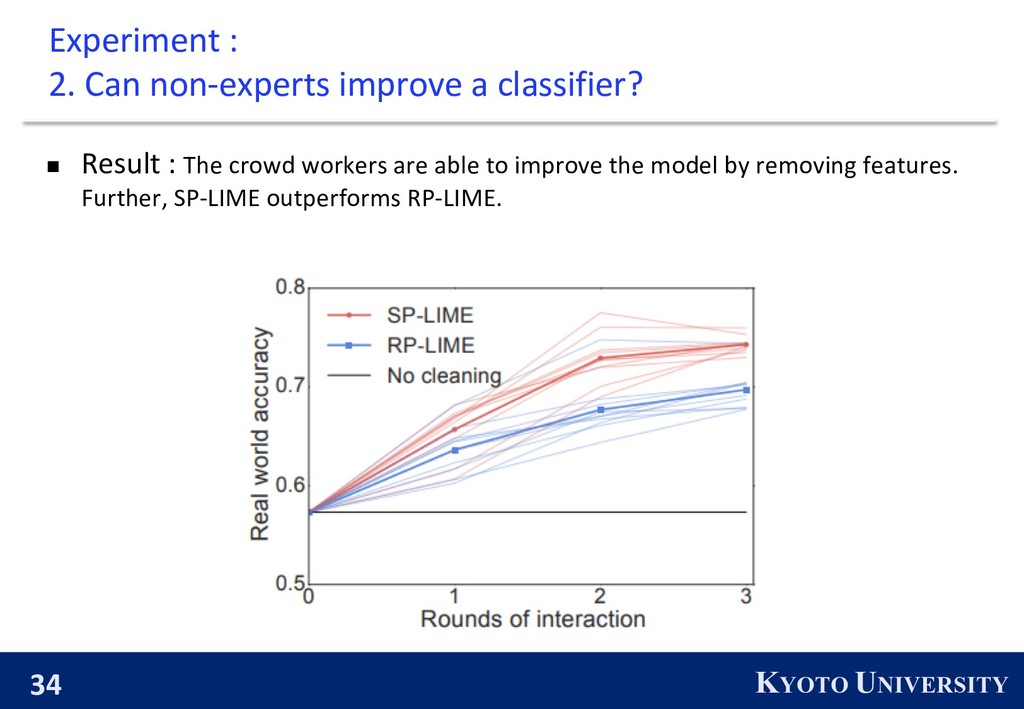
classifier? n Explanations can aid in feature engineering by presenting the important features and removing not generalizing features. n Users are asked to identify which words from the explanations should be removed from subsequent training, for the worse classifier from the previous experiment. n Explanations are produced by SP-LIME or RP-LIME. Original classifier ……. ……. …….
insights? n Task of distinguish Wolves and Huskies. n Train a logistic regression classifier on a training set of 20 images, in which all pictures of wolves had snow in the background, while huskies did not. → this classifier predicts “Wolf” if there is snow and “Huskey” otherwise. n Experiment proceeds as follows: 1. They present a balanced set of 10 test predictions without explanations, where one wolf is not in a snowy back (and thus is predicted as “Husky”) and one husky is in a snowy back (and is predicted as “Wolf”). The other 8 examples are classified correctly. 2. They show the same images with explanations.
insights? Ask the subjects, 1. Do you trust this algorithm to work well in the real world? 2. Why? 3. How do you think the algorithm is able to distinguish between these photos of wolves and huskies? n Result : Explaining individual predictions is effective for getting insights into classifiers. People who is not correct People who is correct
faithfully explain the predictions of any model in an interpretable way. n They also introduced SP-LIME, a method to select representative predictions to give global view of the model. n Their experiments show that explanations are useful. n Other explanation model, such as decision trees. n Other domain, such as speech, video, medical domains, and recommendation systems. Conclusion and future works: They proposed a novel interpreting method.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}