Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Deep Learning 1 (Chapter 4 , Chapter 5)
Search
banquet.kuma
February 02, 2020
Technology
540
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Deep Learning 1 (Chapter 4 , Chapter 5)
自習のために「ゼロから作るDeepLearning 1巻」4,5章をまとめました
banquet.kuma
February 02, 2020
More Decks by banquet.kuma
See All by banquet.kuma
SaaS is dead. は本当か?
dar_kuma_san
0
25
学習への生成AI活用:「毒」にするか「薬」にするか? - エビデンスと実践知に基づく活用戦略
dar_kuma_san
1
79
転職時代の退職金戦略
dar_kuma_san
0
38
AI新時代の富の源泉
dar_kuma_san
0
36
AI時代のテック投資戦略 - 中島聡氏のインサイトに基づく「富の源泉」
dar_kuma_san
0
53
Amazon Q Developer CLIをClaude Codeから使うためのベストプラクティスを考えてみた
dar_kuma_san
0
940
彼女を励ますために、 Azure OpenAI Serviceを使って、 kmakici LINE bot を作った
dar_kuma_san
0
200
面倒なことは、 Azure OpenAI Service× Power Automateにやらせよう!
dar_kuma_san
0
320
データで振り返るデータラーニングギルド【基礎集計の部】
dar_kuma_san
0
2.7k
Other Decks in Technology
See All in Technology
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
180
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
2
180
Kaggleで成長するために意識したこと
prgckwb
2
330
シンガポールで登壇してきます
yama3133
0
120
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
0
120
Claude Code公式skillで 自分の仕事を少しずつ手放そう!(Claude Code開発ノウハウ大公開スペシャル by クラスメソッド)
kaym
1
330
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
120
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
3.6k
DatabricksにおけるMCPソリューション
taka_aki
1
250
Featured
See All Featured
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Producing Creativity
orderedlist
PRO
348
40k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
890
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Leo the Paperboy
mayatellez
8
1.9k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
330
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Transcript
「ゼロから作るDeepLearning」 4、5章まとめ Twitterアカウント : @dar_kuma_san 1
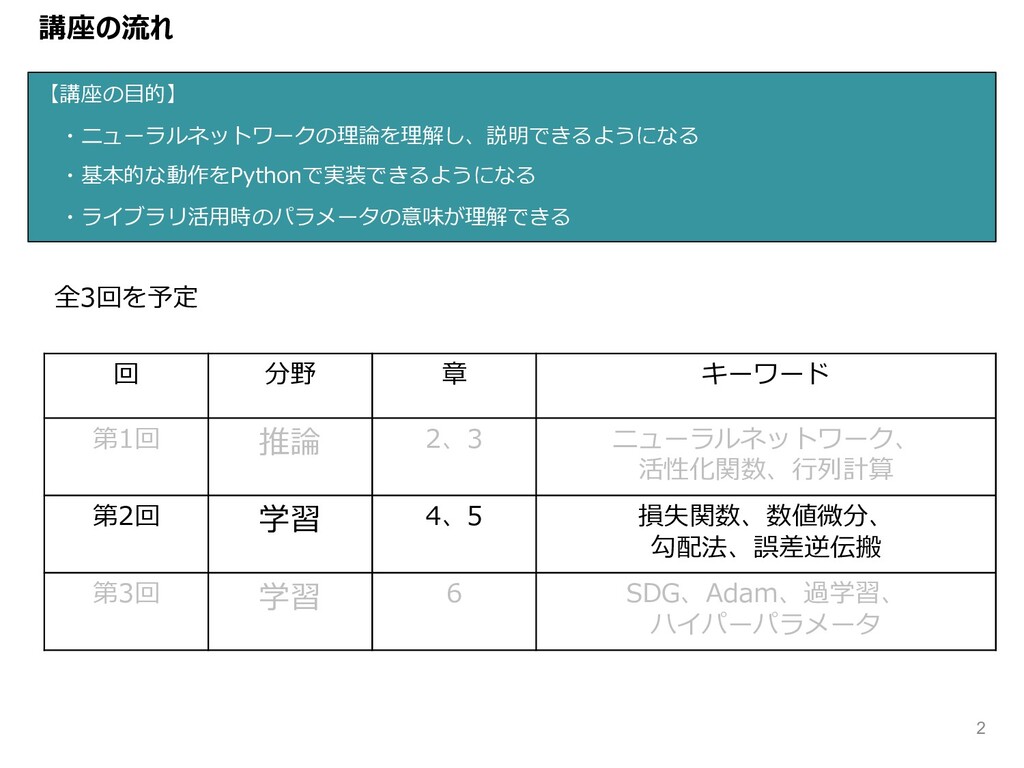
講座の流れ 【講座の⽬的】 ・ニューラルネットワークの理論を理解し、説明できるようになる ・基本的な動作をPythonで実装できるようになる ・ライブラリ活⽤時のパラメータの意味が理解できる 回 分野 章 キーワード 第1回
推論 2、3 ニューラルネットワーク、 活性化関数、⾏列計算 第2回 学習 4、5 損失関数、数値微分、 勾配法、誤差逆伝搬 第3回 学習 6 SDG、Adam、過学習、 ハイパーパラメータ 全3回を予定 2
1. 「学習」とは︖ ⇒推論と学習の違い 2. どうやって学習させるか︖ ⇒勾配法 3. 「傾き」の求め⽅ ⇒数値微分 4.
効率的な「傾き」の求め⽅ ⇒誤差逆伝播法 5. 学習⽅法について ⇒オンライン、ミニバッチ、バッチ 6. ⼿書き⽂字画像から学習 ⇒Pythonで実装 7. まとめ 第2回の⽬標 • 学習のアルゴリズム「勾配法」を理解する • 勾配の効率的な求め⽅「誤差逆伝播法」を理解する 講座の流れ 3
学習がなぜ必要か︖ 4
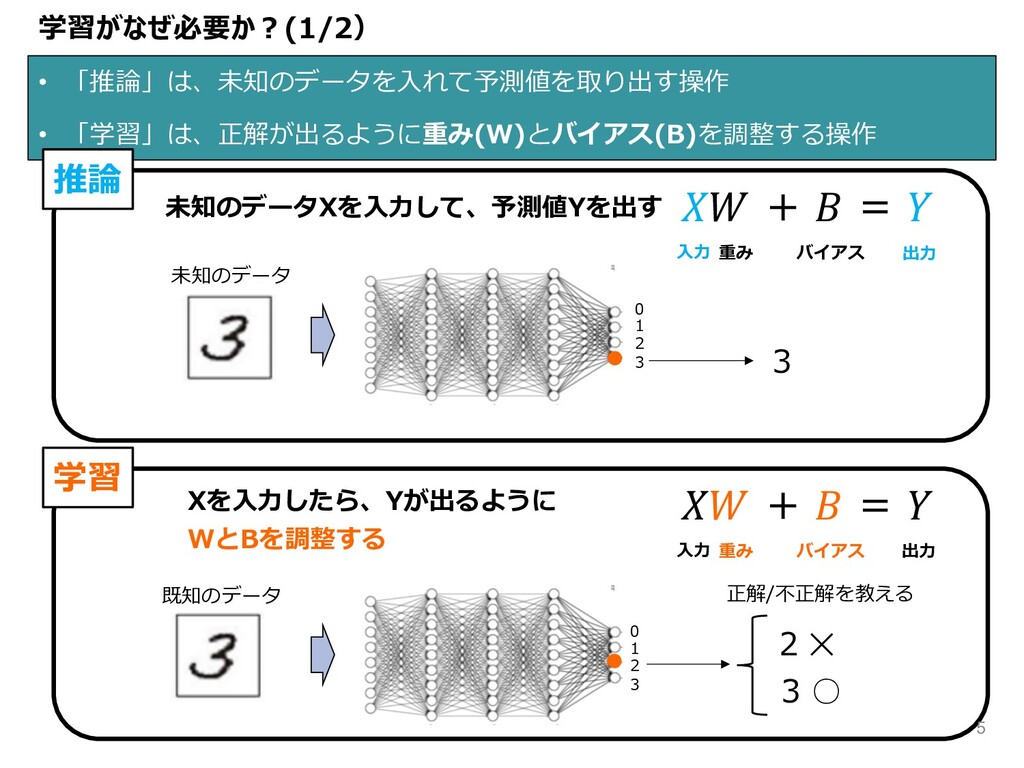
学習がなぜ必要か︖(1/2) • 「推論」は、未知のデータを⼊れて予測値を取り出す操作 • 「学習」は、正解が出るように重み(W)とバイアス(B)を調整する操作 推論 未知のデータXを⼊⼒して、予測値Yを出す 0 1 2
3 + = ⼊⼒ 出⼒ 重み バイアス 学習 + = ⼊⼒ 出⼒ 重み バイアス 0 1 2 3 3 2 ✕ 3 ◦ Xを⼊⼒したら、Yが出るように WとBを調整する 未知のデータ 既知のデータ 正解/不正解を教える 5
学習がなぜ必要か︖(2/2) 学習の簡単な例では、 パーセプトロンの重みとバイアスを機械に決めさせる ゲート AND OR NAND 式 閾値 真理値
(w& , w(, )=(0.5, 0.5, −0.7) (w&, w(,)=(−0.5, −0.5,0.7) (w&, w(,)=(0.5, 0.5, −0.2) 6
どうやって学習させるか︖ 7
どうやって学習させるか?(1/9) どのくらい正解から外れているかの指標︓損失関数 名称 2乗和誤差 交差エントロピー誤差 式 ⽤途 回帰問題 2クラス分類 多クラス分類
損失関数の種類 損失関数を最⼩にすることで、 「予測値」を「正解値」を近づける︕ & ( (y − t)( − t log y +(1 − t)log(1 − ) − ∑;<= > t; log y; y︓予測値、t︓正解値、k︓クラス数 8
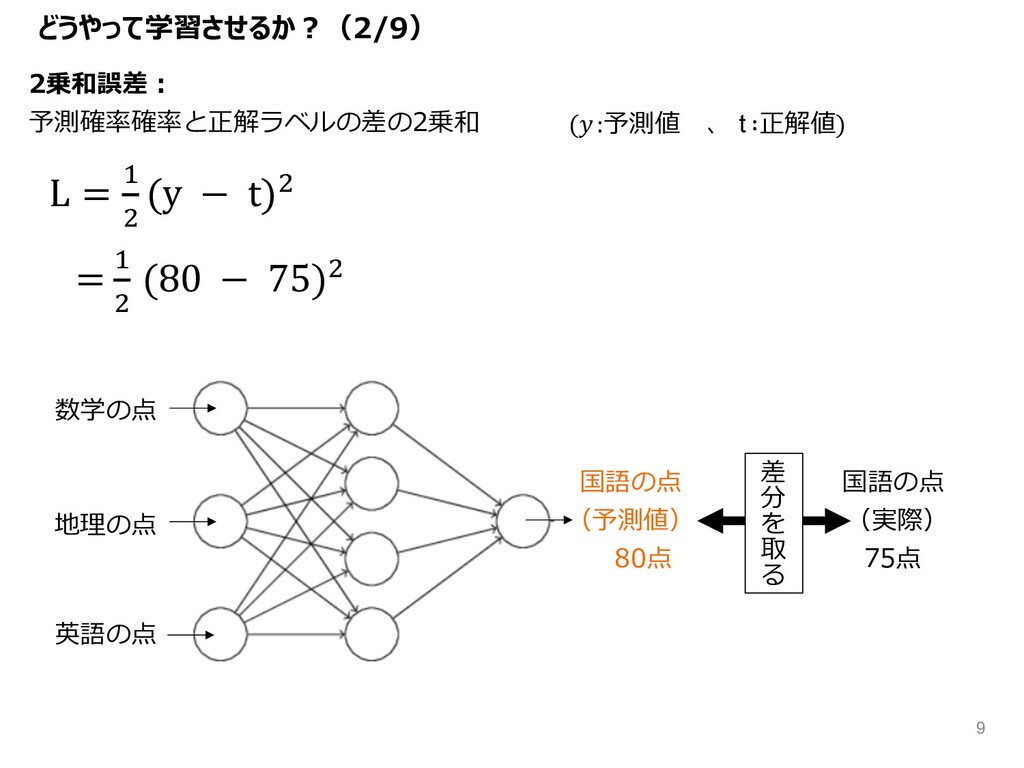
2乗和誤差︓ 予測確率確率と正解ラベルの差の2乗和 どうやって学習させるか︖(2/9) 国語の点 (予測値) 80点 数学の点 地理の点 英語の点 国語の点
(実際) 75点 差 分 を 取 る L = & ( (y − t)( = & ( (80 − 75)( (:予測値 、 t ∶正解値) 9
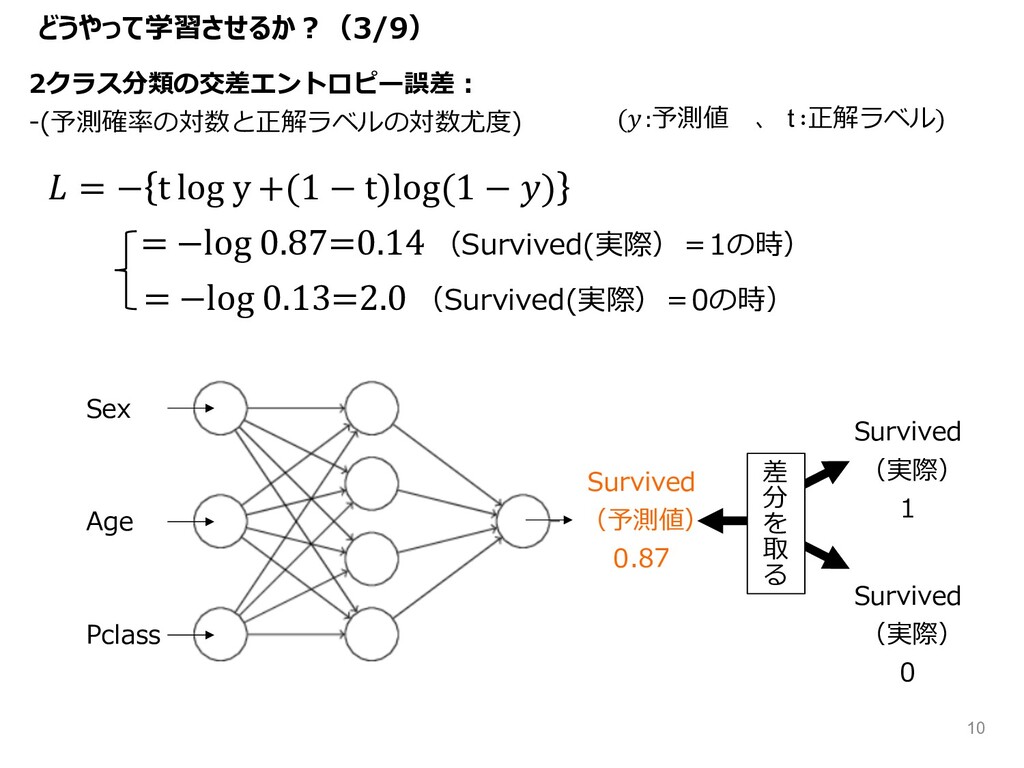
= − t log y +(1 − t)log(1 − )
= −log 0.87=0.14 (Survived(実際)=1の時) = −log 0.13=2.0 (Survived(実際)=0の時) 2クラス分類の交差エントロピー誤差︓ -(予測確率の対数と正解ラベルの対数尤度) どうやって学習させるか︖(3/9) Survived (予測値) 0.87 Sex Survived (実際) 1 差 分 を 取 る Age Pclass Survived (実際) 0 (:予測値 、 t ∶正解ラベル) 10
どうやって学習させるか︖(4/9) 「2クラス分類の交差エントロピー誤差」の性質 t(正解ラベル)、y(予測確率)の対数尤度にマイナスをかけたものに等しい つまり、「誤差を最⼩にする」 ≒ 「最⼤尤度になるyを求める」 = − t log
y +(1 − t)log(1 − ) H (1 − )(&IH) 対数を取って、マイナスをかける t : 0(失敗) or 1(成功) y︓成功確率 11
出典︓https://ml4a.github.io/ml4a/jp/looking_inside_neural_nets/ 28 28 L = − ∑;<= J t; log
y; = − log 0.6 0 100 200 0 120 255 0 89 180 正解 y= (0.1) y& (0.05) y( (0.0) yL (0.0) yM (0.05) yN (0.1) yO (0.0) yP (0.1) yQ (0.6) yJ (0.0) 0 1 2 3 4 5 6 7 8 9 (R :予測確率 、 R ∶正解ラベル) t= (0) t& (0) t( (0) tL (0) tM (0) tN (0) tO (0) tP (0) tQ (1) tJ (0) 交差エントロピー誤差 : 予測確率の対数と正解ラベルの積の和の符号を変えたもの どうやって学習させるか︖(5/9) one-hot label 12
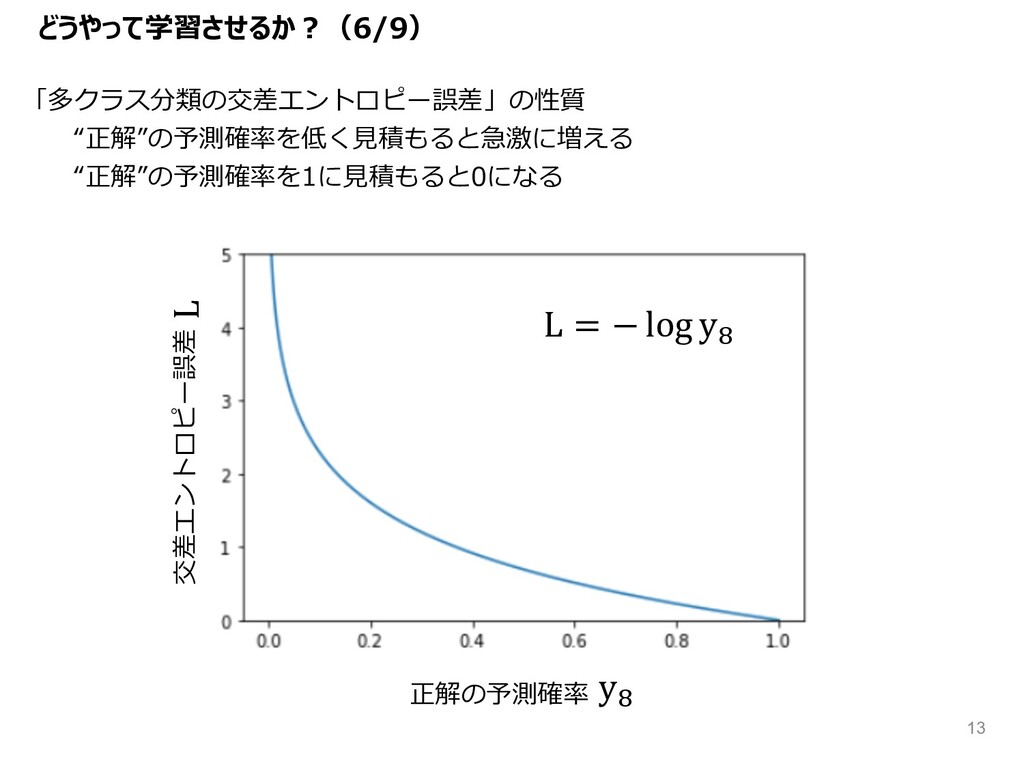
L = − log yQ L yQ 「多クラス分類の交差エントロピー誤差」の性質 “正解”の予測確率を低く⾒積もると急激に増える “正解”の予測確率を1に⾒積もると0になる
どうやって学習させるか︖(6/9) 正解の予測確率 交差エントロピー誤差 13
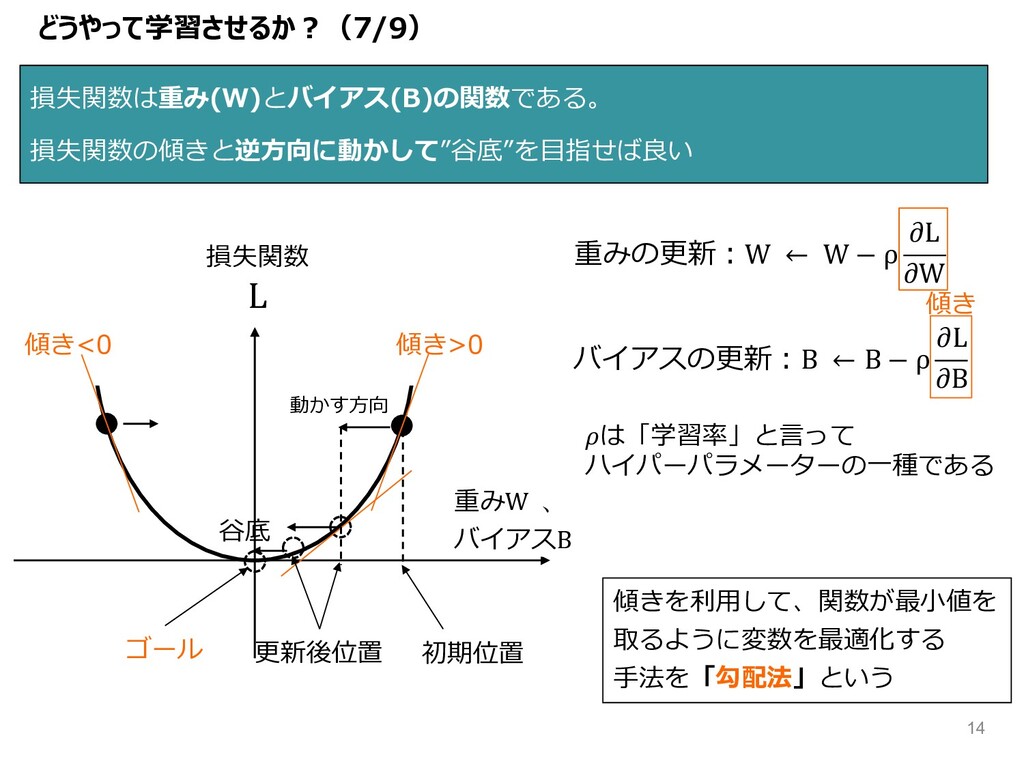
どうやって学習させるか︖(7/9) 損失関数は重み(W)とバイアス(B)の関数である。 損失関数の傾きと逆⽅向に動かして”⾕底”を⽬指せば良い L 重みW 、 バイアスB 損失関数 初期位置 ⾕底
傾き>0 傾き<0 動かす⽅向 重みの更新︓W ← W − ρ L W バイアスの更新︓B ← B − ρ L B 傾き は「学習率」と⾔って ハイパーパラメーターの⼀種である 傾きを利⽤して、関数が最⼩値を 取るように変数を最適化する ⼿法を「勾配法」という 更新後位置 ゴール 14
どうやって学習させるか︖(8/9) 1 . 重み(W)、バイアス(B)を”適当に”に決める 2. 訓練データを⼊れて、推論させる(誤差を求める) 3. 誤差から傾きを求める 4. 重み(W)、バイアス(B)を更新する
2〜4を繰り返す L W W ← W − ρ L W 学習の流れ ループ 15
この操作を全てのWとBについて、 繰り返し実施すれば、 いつか予測値と正解が⼀致するはず どうやって「傾き」を求めるか︖ どうやって学習させるか︖(9/9) 16
どうやって「傾き」を求めるか︖ 17
どうやって「傾き」を求めるか︖(1/5) 機械は解析的に傾きを求められないので、「数値微分」によって近似的に求める 重みW L(W) 損失関数 2h 現在位置 [\(]) [] ≅
\ ]_` I\(]I`) (` 傾き 前後に微⼩量 ℎ 移動させて変化を求める これが傾きの近似値 L W + h −L(W − h) 重みの更新︓W ← W − ρ L W 18
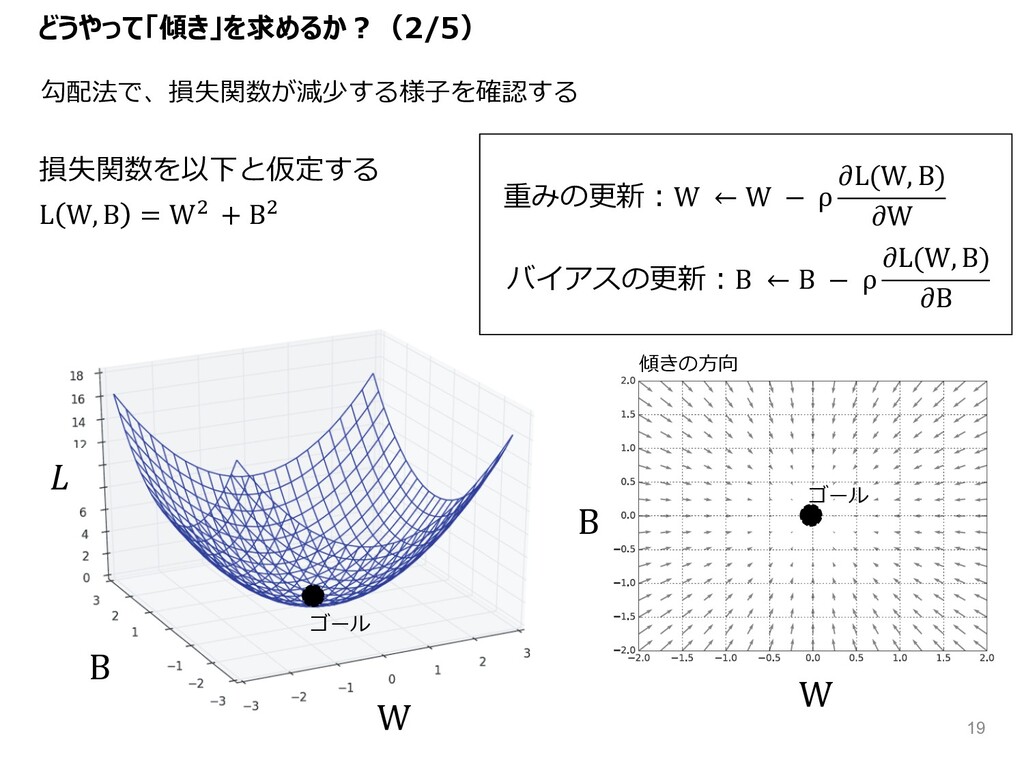
勾配法で、損失関数が減少する様⼦を確認する 重みの更新︓W ← W − ρ L(W, B) W バイアスの更新︓B
← B − ρ L(W, B) B W B W B 損失関数を以下と仮定する L W, B = W( + B( 傾きの⽅向 ゴール ゴール どうやって「傾き」を求めるか︖(2/5) 19
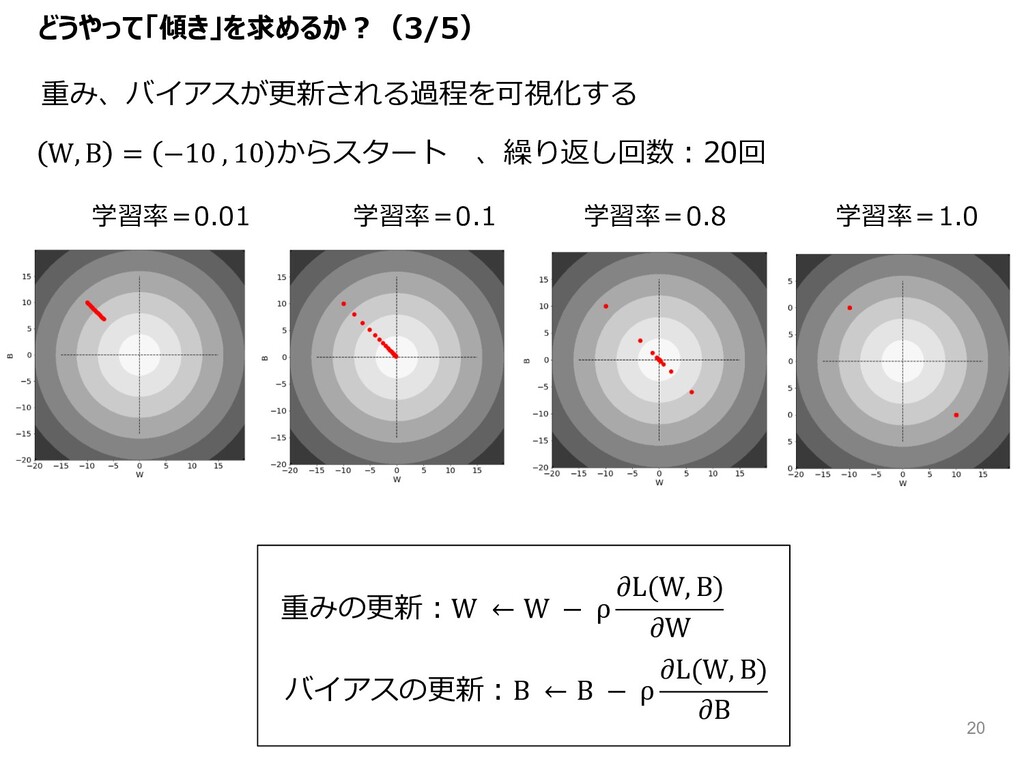
どうやって「傾き」を求めるか︖(3/5) 重み、バイアスが更新される過程を可視化する W, B = −10 , 10 からスタート 、繰り返し回数︓20回
学習率=0.01 学習率=0.1 学習率=0.8 学習率=1.0 重みの更新︓W ← W − ρ L(W, B) W バイアスの更新︓B ← B − ρ L(W, B) B 20
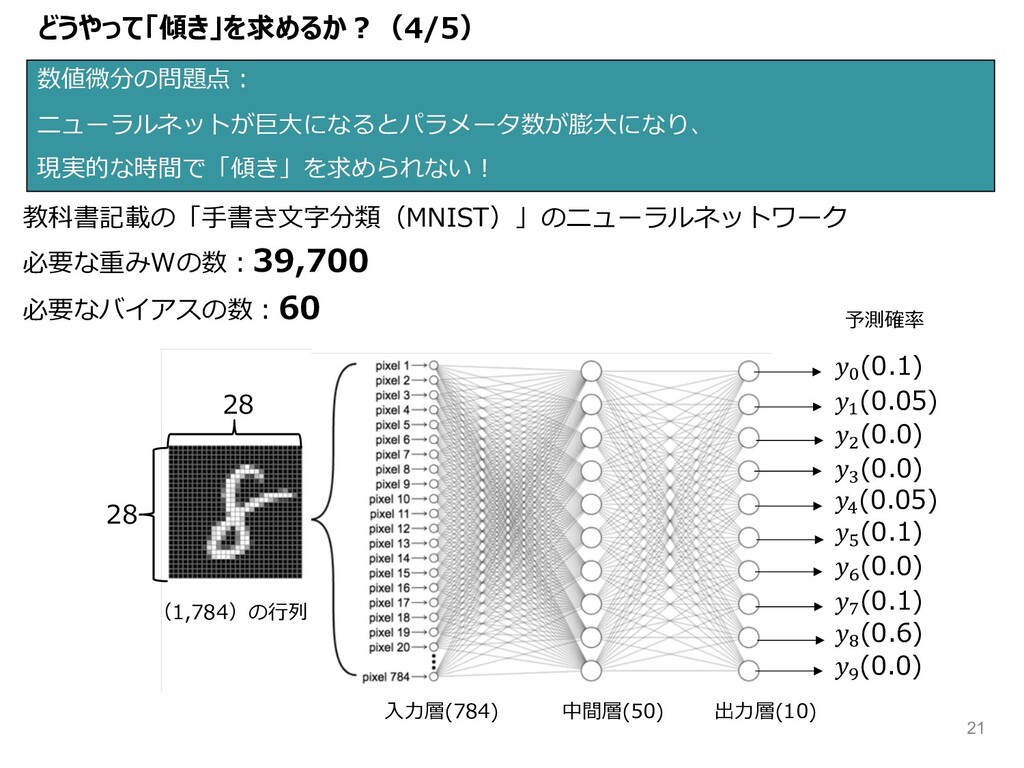
どうやって「傾き」を求めるか︖(4/5) 数値微分の問題点︓ ニューラルネットが巨⼤になるとパラメータ数が膨⼤になり、 現実的な時間で「傾き」を求められない︕ 28 28 予測確率 = (0.1) &
(0.05) ( (0.0) L (0.0) M (0.05) N (0.1) O (0.0) P (0.1) Q (0.6) J (0.0) ⼊⼒層(784) 中間層(50) 出⼒層(10) 教科書記載の「⼿書き⽂字分類(MNIST)」のニューラルネットワーク 必要な重みWの数︓39,700 必要なバイアスの数︓60 (1,784)の⾏列 21
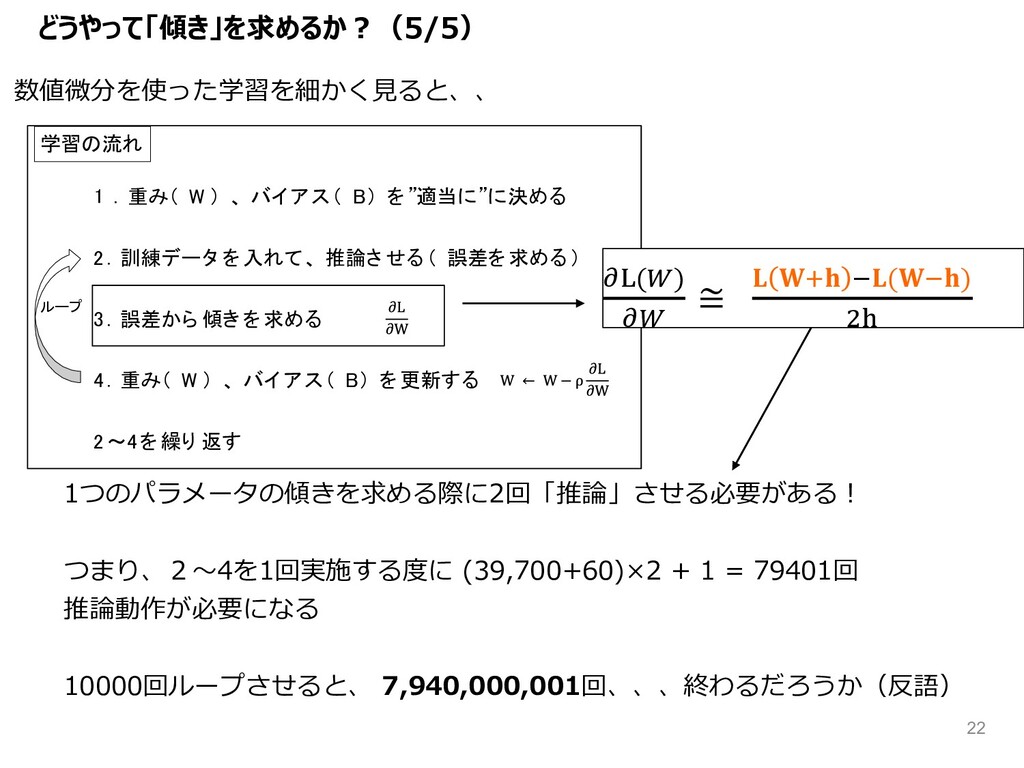
1 . 重み( W ) 、 バイ アス( B) を”適当に”に決める
2. 訓練データ を入れて、 推論さ せる( 誤差を求める) 3. 誤差から 傾き を求める 4. 重み( W ) 、 バイ アス( B) を更新する 2~4を繰り 返す 学習の流れ ループ 数値微分を使った学習を細かく⾒ると、、 [\(b) [b ≅ _ I(I) (` 1つのパラメータの傾きを求める際に2回「推論」させる必要がある︕ つまり、2〜4を1回実施する度に (39,700+60)×2 + 1 = 79401回 推論動作が必要になる 10000回ループさせると、 7,940,000,001回、、、終わるだろうか(反語) どうやって「傾き」を求めるか︖(5/5) 22
効率的に「傾き」を求める 23
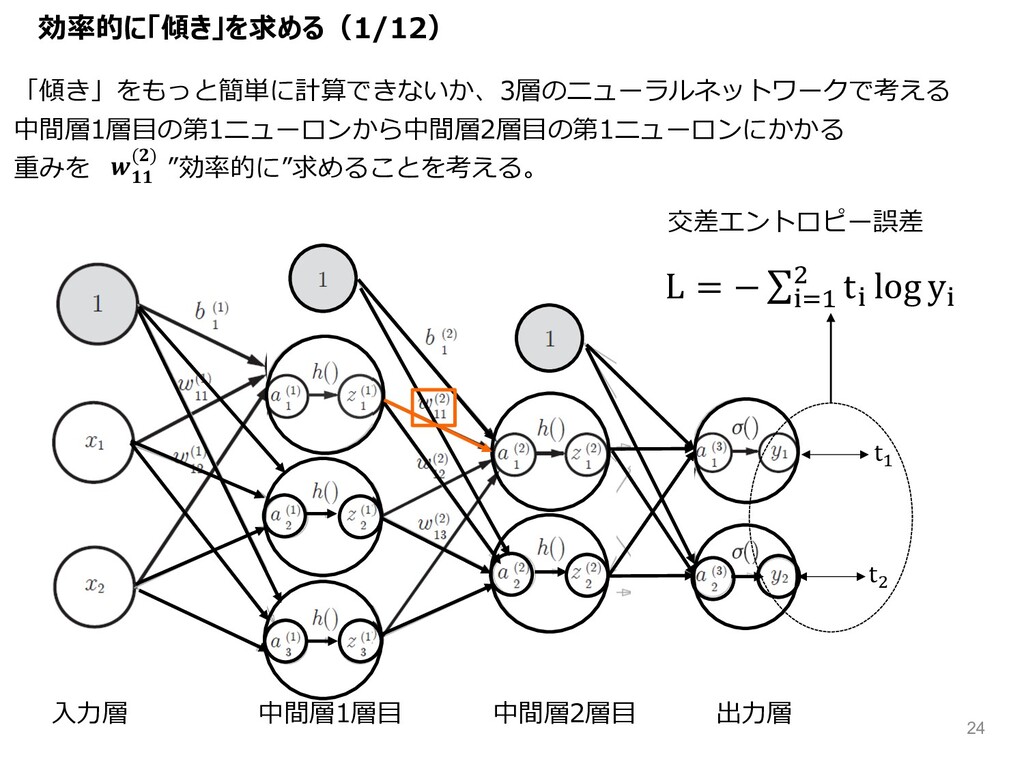
効率的に「傾き」を求める(1/12) t& t( L = − ∑;<& ( t; log
y; 交差エントロピー誤差 ⼊⼒層 中間層1層⽬ 中間層2層⽬ 出⼒層 「傾き」をもっと簡単に計算できないか、3層のニューラルネットワークで考える 中間層1層⽬の第1ニューロンから中間層2層⽬の第1ニューロンにかかる 重みを ”効率的に”求めることを考える。 () 24
微分の連鎖律 誤差逆伝播の説明で多⽤します 効率的に「傾き」を求める(2/12) = u =g(x) = = , u
=g(q,r) v =h(q,r) = + = + 25
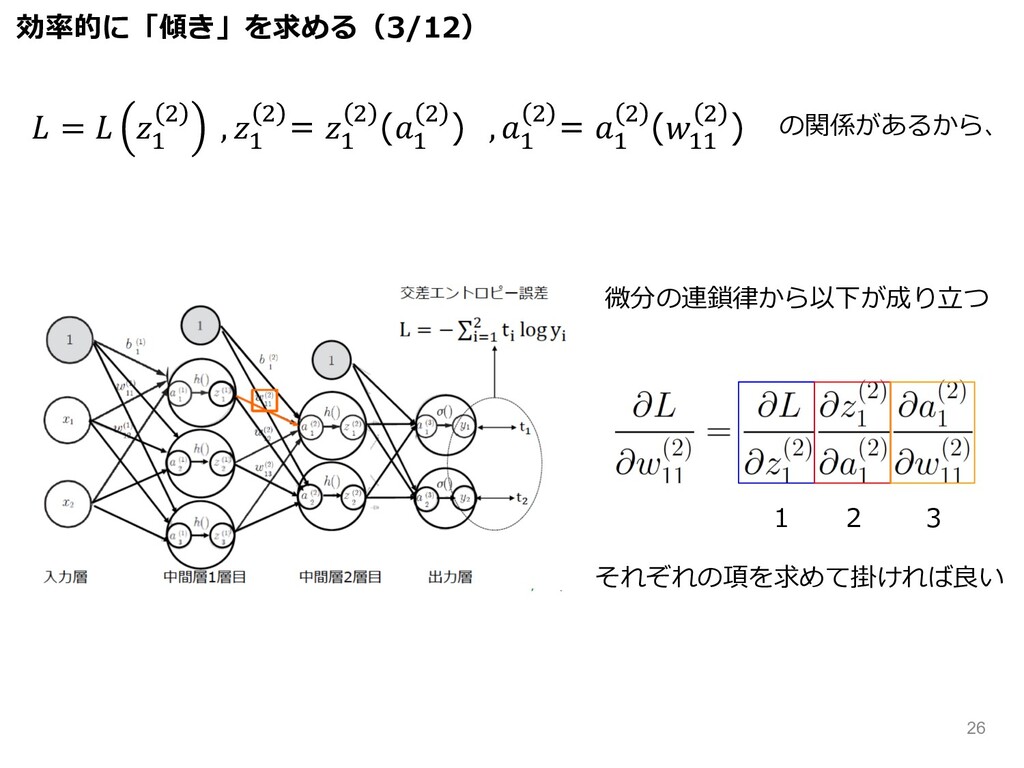
微分の連鎖律から以下が成り⽴つ の関係があるから、 1 2 3 それぞれの項を求めて掛ければ良い 効率的に「傾き」を求める(3/12) = & (
, & ( = & ( (& ( ) , & ( = & ( (&& ( ) 26
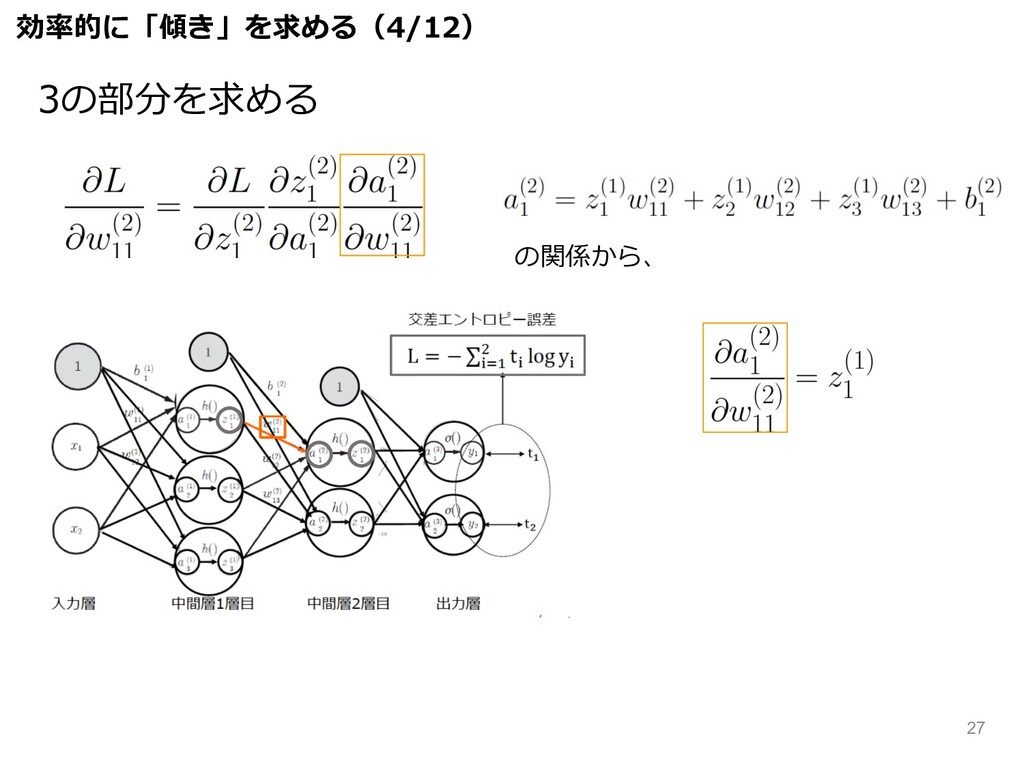
3の部分を求める の関係から、 効率的に「傾き」を求める(4/12) 27
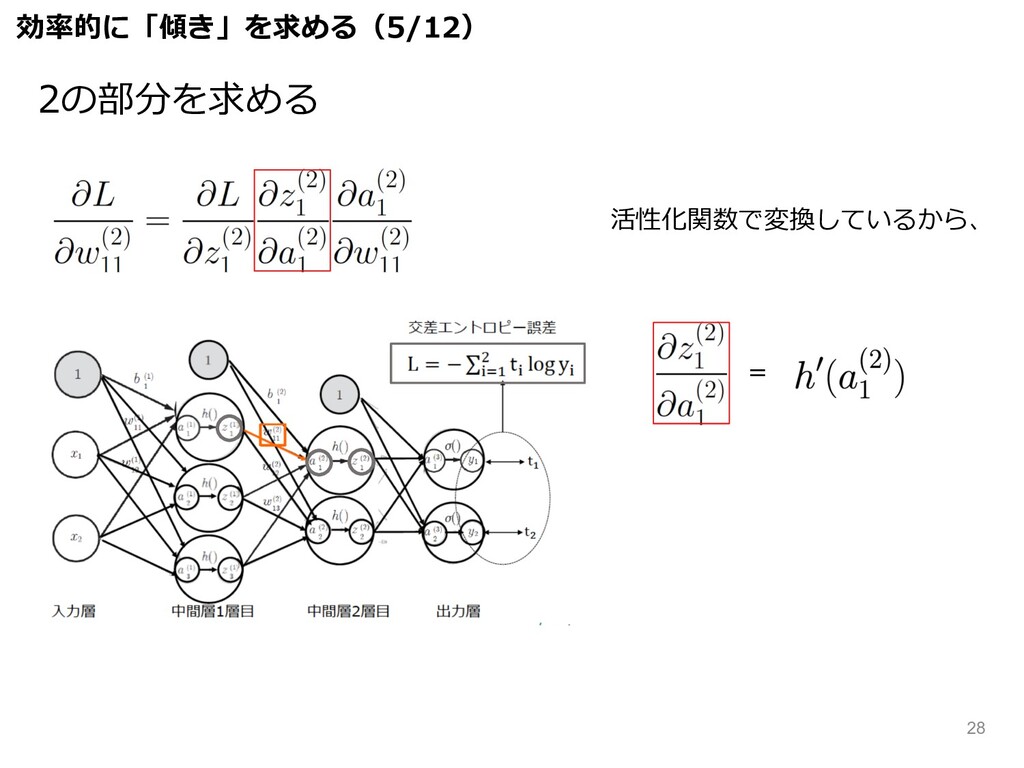
活性化関数で変換しているから、 = 効率的に「傾き」を求める(5/12) 2の部分を求める 28
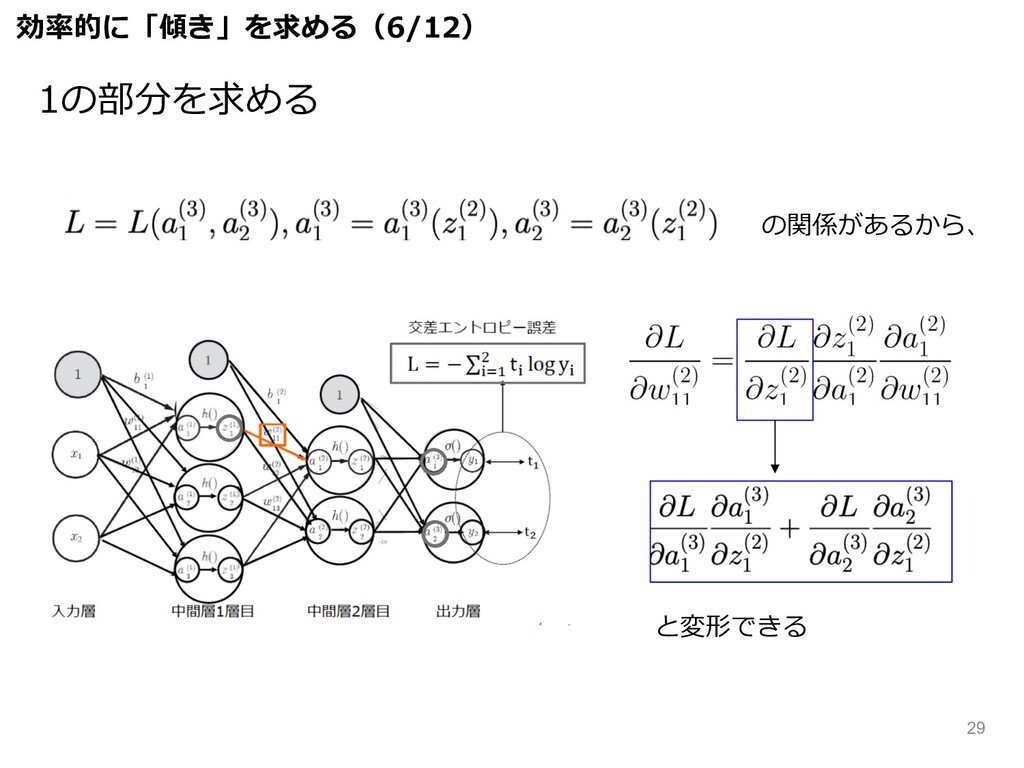
の関係があるから、 と変形できる 効率的に「傾き」を求める(6/12) 1の部分を求める 29
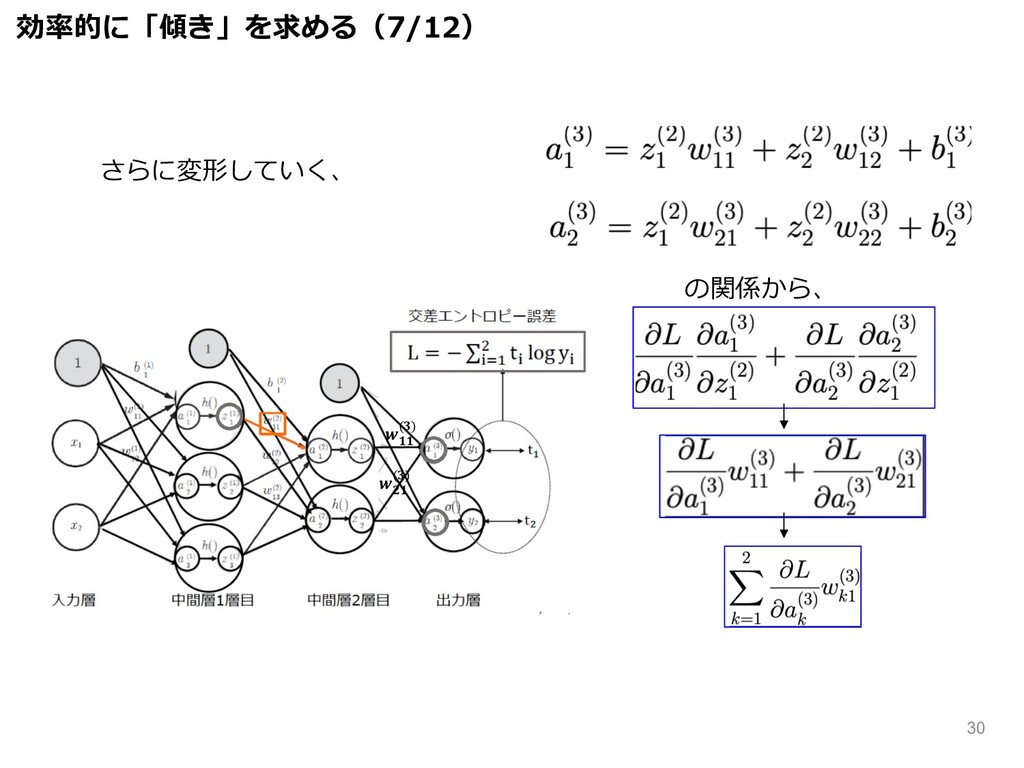
さらに変形していく、 の関係から、 効率的に「傾き」を求める(7/12) () () 30
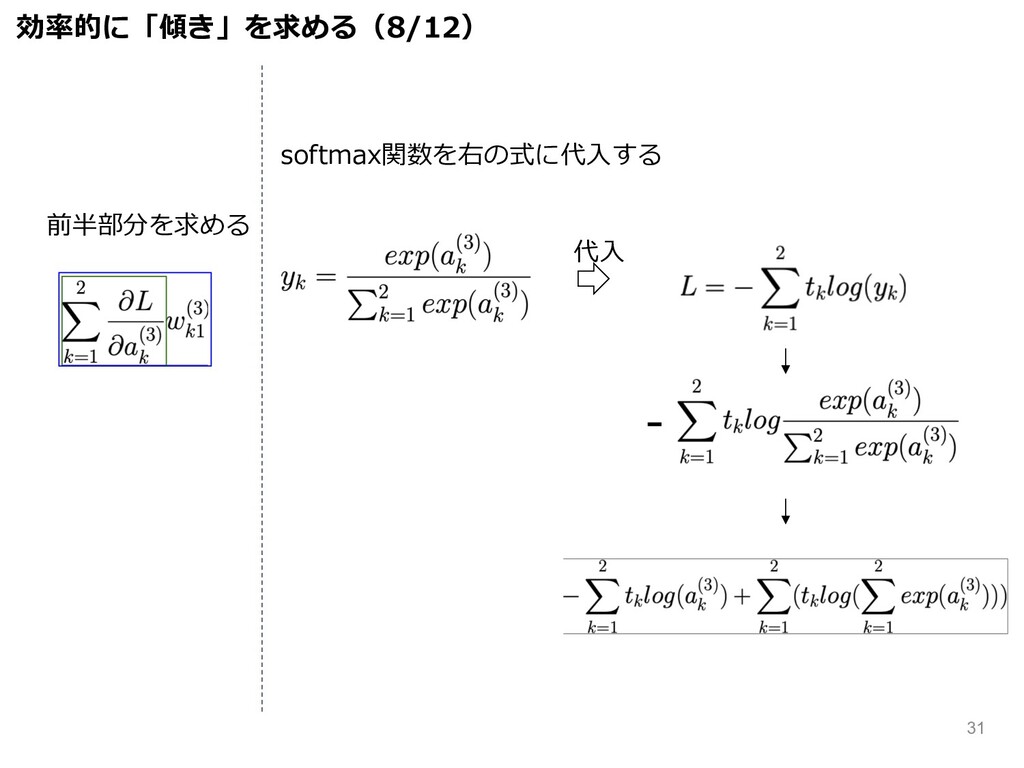
前半部分を求める softmax関数を右の式に代⼊する 代⼊ 効率的に「傾き」を求める(8/12) - 31
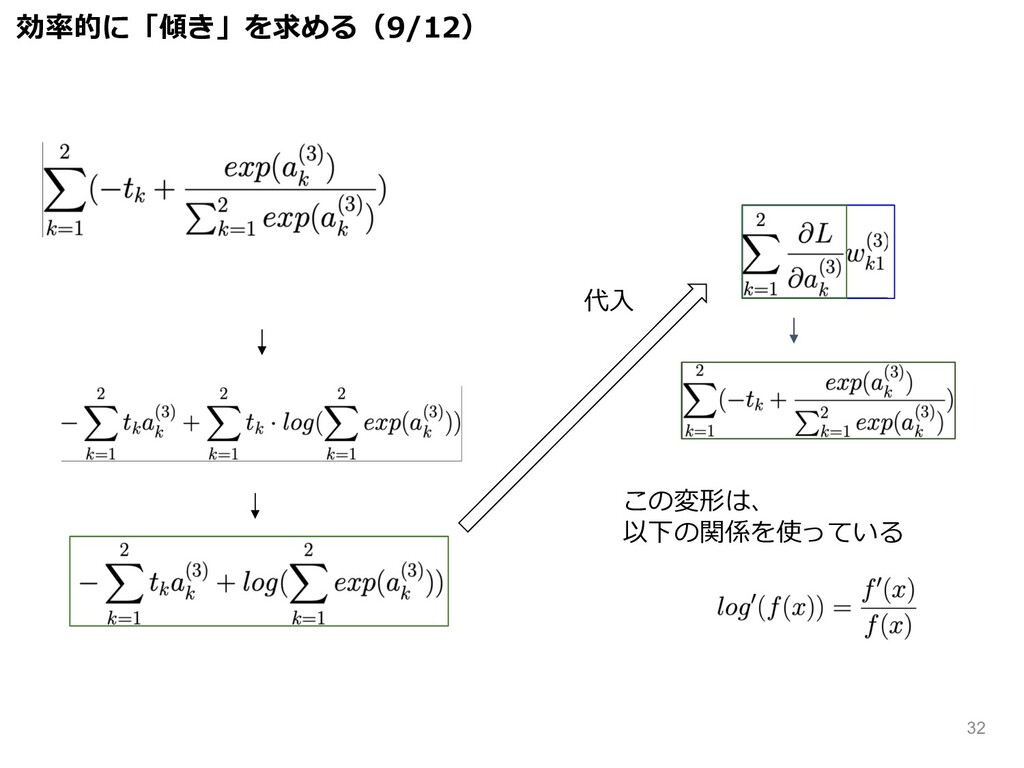
さらに変形していく、 代⼊ この変形は、 以下の関係を使っている 効率的に「傾き」を求める(9/12) 32
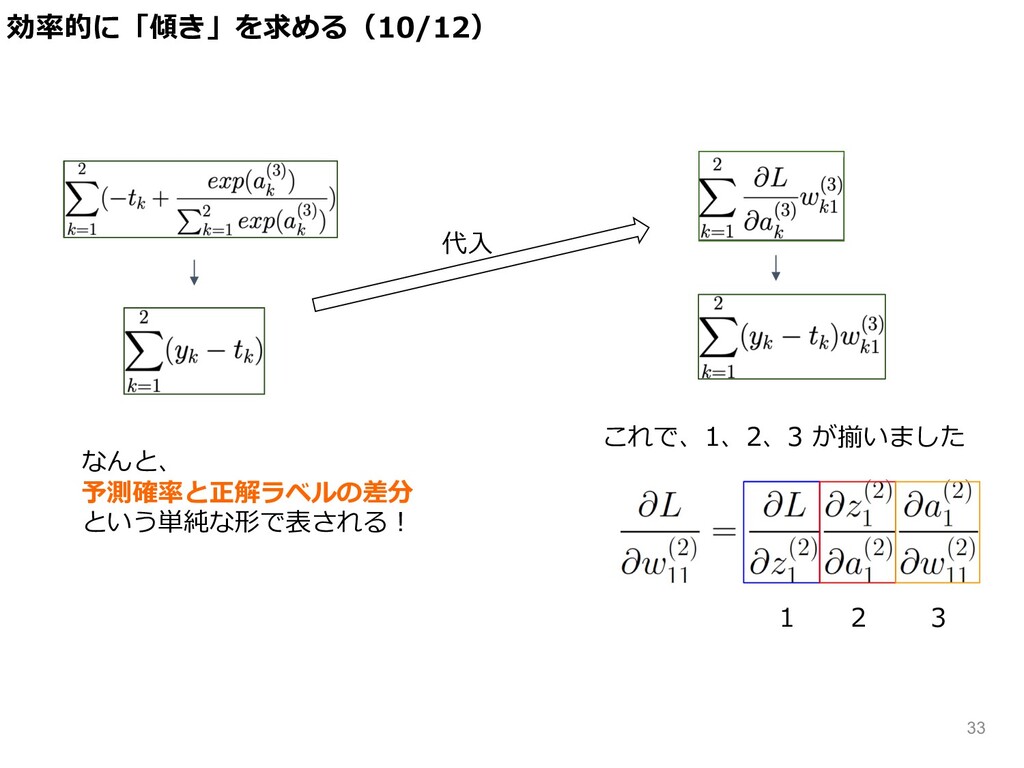
なんと、 予測確率と正解ラベルの差分 という単純な形で表される︕ 代⼊ 1 2 3 これで、1、2、3 が揃いました 効率的に「傾き」を求める(10/12)
33
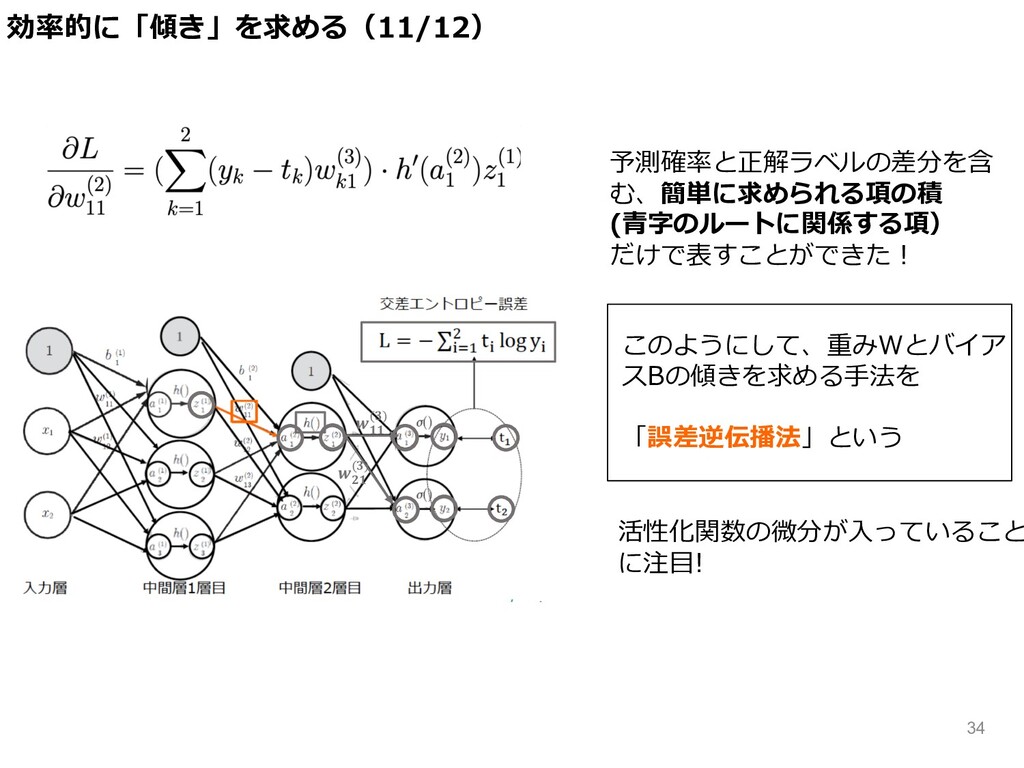
予測確率と正解ラベルの差分を含 む、簡単に求められる項の積 (⻘字のルートに関係する項) だけで表すことができた︕ このようにして、重みWとバイア スBの傾きを求める⼿法を 「誤差逆伝播法」という 活性化関数の微分が⼊っていること に注⽬! 効率的に「傾き」を求める(11/12)
() () 34
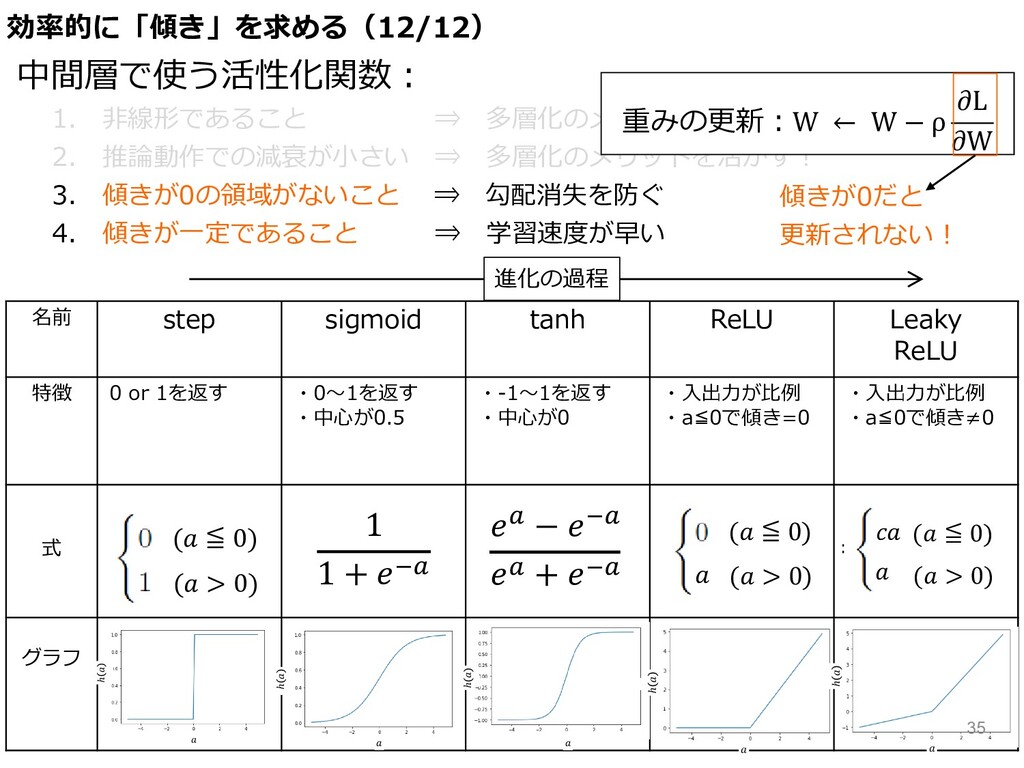
1. ⾮線形であること ⇒ 多層化のメリットを活かす︕ 2. 推論動作での減衰が⼩さい ⇒ 多層化のメリットを活かす︕ 3. 傾きが0の領域がないこと
⇒ 勾配消失を防ぐ 4. 傾きが⼀定であること ⇒ 学習速度が早い 名前 step sigmoid tanh ReLU Leaky ReLU 特徴 0 or 1を返す ・0〜1を返す ・中⼼が0.5 ・-1〜1を返す ・中⼼が0 ・⼊出⼒が⽐例 ・a≦0で傾き=0 ・⼊出⼒が⽐例 ・a≦0で傾き≠0 式 グラフ ℎ ℎ ℎ ℎ ( > 0) ( ≦ 0) 1 1 + Iz z − Iz z + Iz ( > 0) ( ≦ 0) ( > 0) ( ≦ 0) 進化の過程 ℎ 中間層で使う活性化関数︓ 重みの更新︓W ← W − ρ L W 傾きが0だと 更新されない ! 効率的に「傾き」を求める(12/12) 35
学習⽅法 36
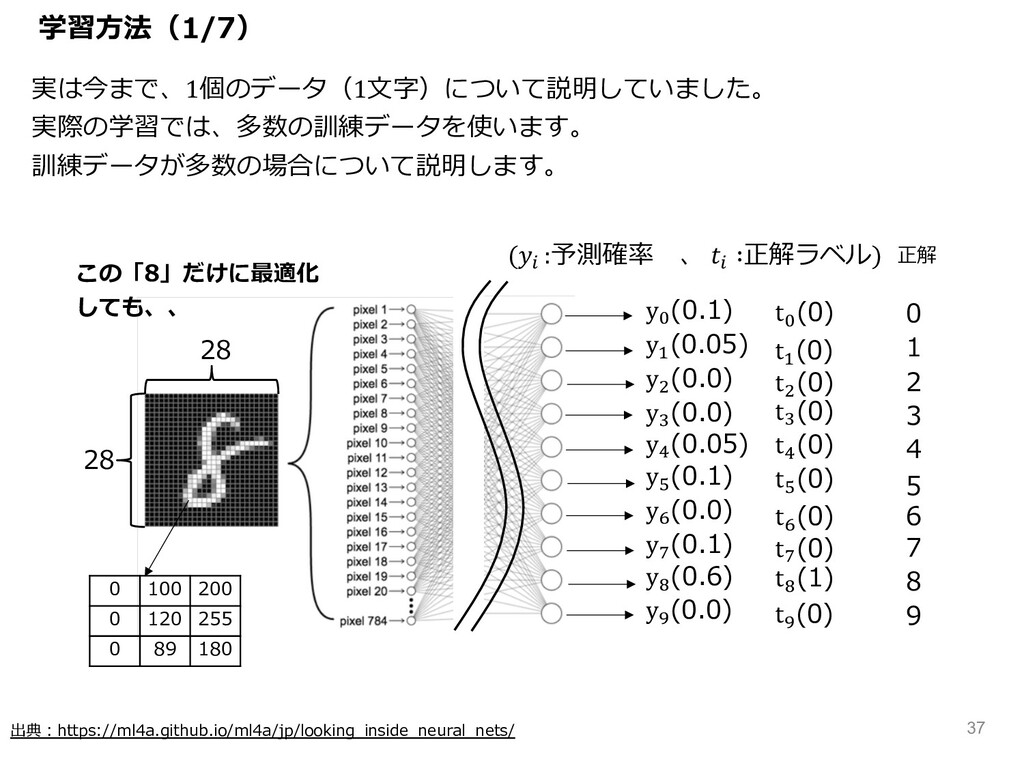
出典︓https://ml4a.github.io/ml4a/jp/looking_inside_neural_nets/ 28 28 実は今まで、1個のデータ(1⽂字)について説明していました。 実際の学習では、多数の訓練データを使います。 訓練データが多数の場合について説明します。 0 100 200 0
120 255 0 89 180 正解 y= (0.1) y& (0.05) y( (0.0) yL (0.0) yM (0.05) yN (0.1) yO (0.0) yP (0.1) yQ (0.6) yJ (0.0) 0 1 2 3 4 5 6 7 8 9 (R :予測確率 、 R ∶正解ラベル) t= (0) t& (0) t( (0) tL (0) tM (0) tN (0) tO (0) tP (0) tQ (1) tJ (0) 学習⽅法(1/7) この「8」だけに最適化 しても、、 37
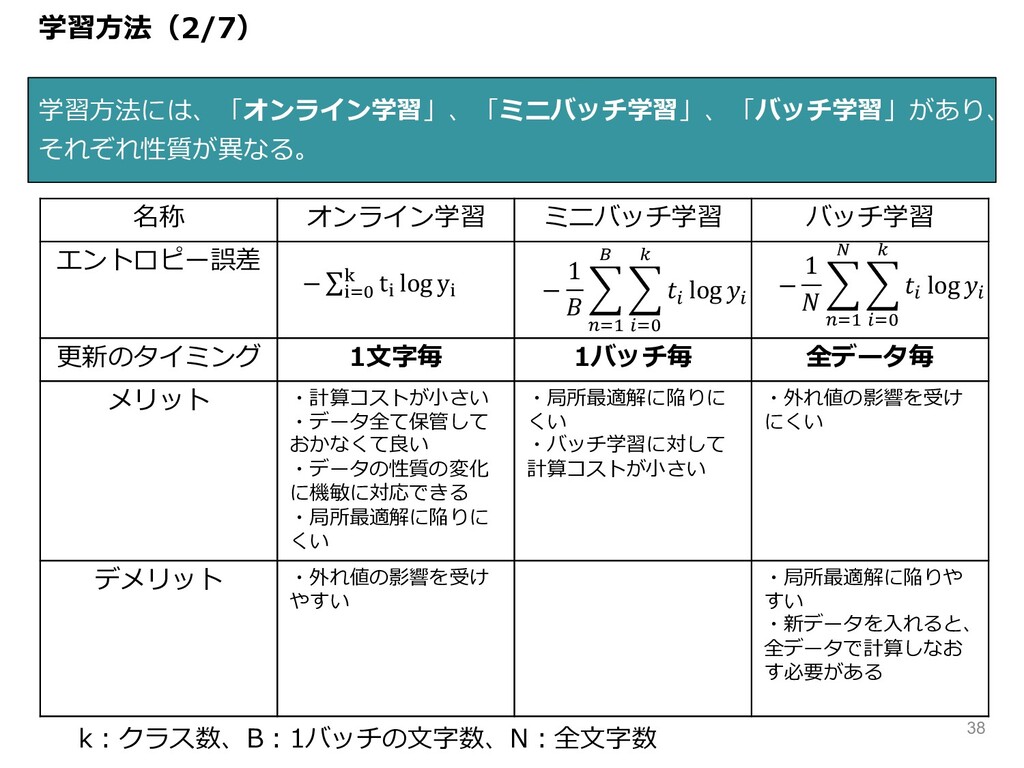
学習⽅法(2/7) 学習⽅法には、「オンライン学習」、「ミニバッチ学習」、「バッチ学習」があり、 それぞれ性質が異なる。 名称 オンライン学習 ミニバッチ学習 バッチ学習 エントロピー誤差 更新のタイミング 1⽂字毎
1バッチ毎 全データ毎 メリット ・計算コストが⼩さい ・データ全て保管して おかなくて良い ・データの性質の変化 に機敏に対応できる ・局所最適解に陥りに くい ・局所最適解に陥りに くい ・バッチ学習に対して 計算コストが⼩さい ・外れ値の影響を受け にくい デメリット ・外れ値の影響を受け やすい ・局所最適解に陥りや すい ・新データを⼊れると、 全データで計算しなお す必要がある − ∑;<= > t; log y; − 1 { |<& } { R<= ~ R log R − 1 { |<& € { R<= ~ R log R k︓クラス数、B︓1バッチの⽂字数、N︓全⽂字数 38
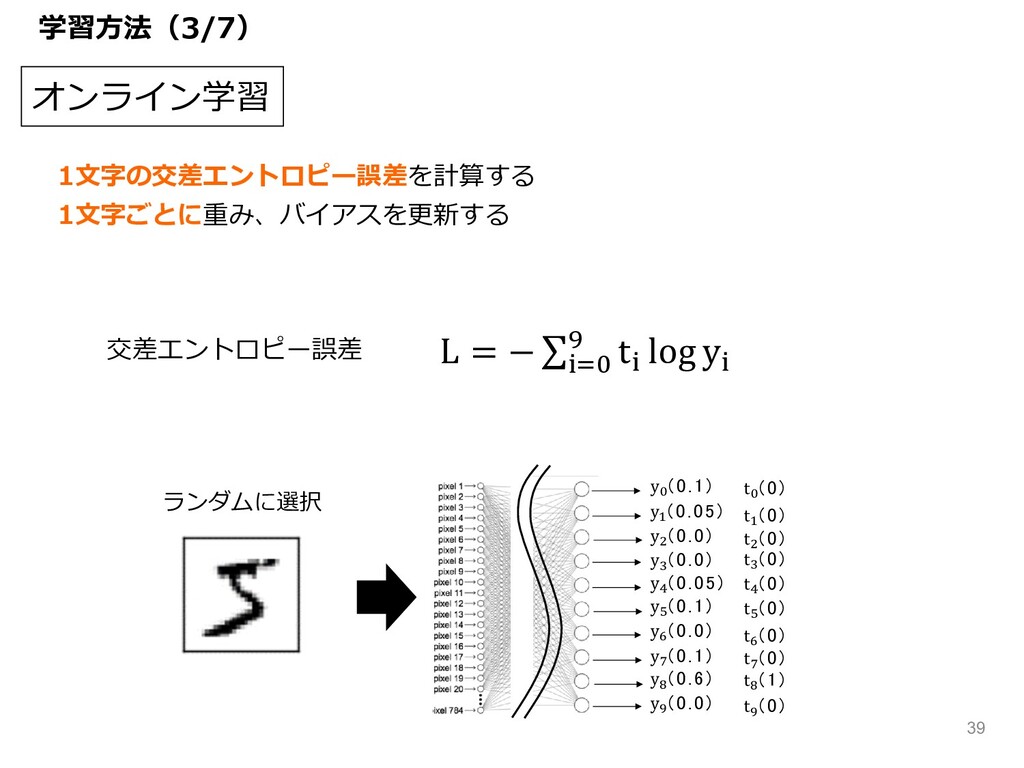
オンライン学習 1⽂字の交差エントロピー誤差を計算する 1⽂字ごとに重み、バイアスを更新する 正解 y" (0.1) y# (0.05) y$ (0.0)
y% (0.0) y& (0.05) y' (0.1) y( (0.0) y) (0.1) y* (0.6) y+ (0.0) 0 1 2 3 4 5 6 7 8 9 t" (0) t# (0) t$ (0) t% (0) t& (0) t' (0) t( (0) t) (0) t* (1) t+ (0) L = − ∑;<= J t; log y; 交差エントロピー誤差 ランダムに選択 学習⽅法(3/7) 39
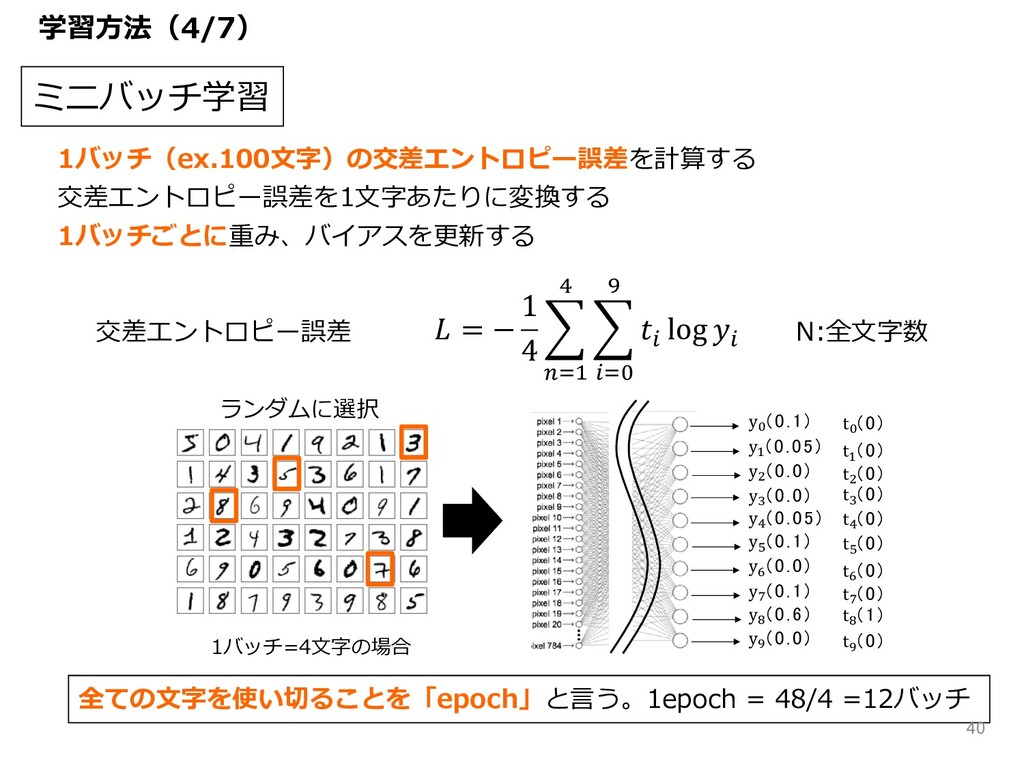
ミニバッチ学習 1バッチ(ex.100⽂字)の交差エントロピー誤差を計算する 交差エントロピー誤差を1⽂字あたりに変換する 1バッチごとに重み、バイアスを更新する 正解 y" (0.1) y# (0.05) y$
(0.0) y% (0.0) y& (0.05) y' (0.1) y( (0.0) y) (0.1) y* (0.6) y+ (0.0) 0 1 2 3 4 5 6 7 8 9 t" (0) t# (0) t$ (0) t% (0) t& (0) t' (0) t( (0) t) (0) t* (1) t+ (0) = − 1 4 { |<& M { R<= J R log R 交差エントロピー誤差 N:全⽂字数 1バッチ=4⽂字の場合 全ての⽂字を使い切ることを「epoch」と⾔う。1epoch = 48/4 =12バッチ ランダムに選択 学習⽅法(4/7) 40
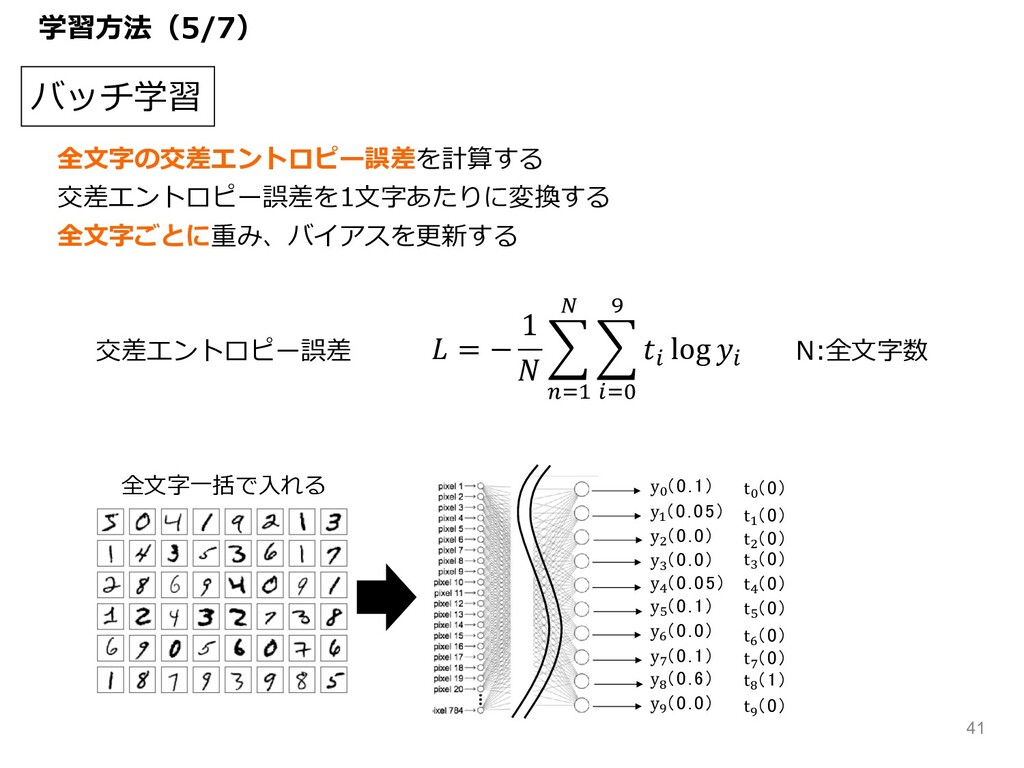
バッチ学習 全⽂字⼀括で⼊れる = − 1 { |<& € { R<=
J R log R 正解 y" (0.1) y# (0.05) y$ (0.0) y% (0.0) y& (0.05) y' (0.1) y( (0.0) y) (0.1) y* (0.6) y+ (0.0) 0 1 2 3 4 5 6 7 8 9 t" (0) t# (0) t$ (0) t% (0) t& (0) t' (0) t( (0) t) (0) t* (1) t+ (0) 全⽂字の交差エントロピー誤差を計算する 交差エントロピー誤差を1⽂字あたりに変換する 全⽂字ごとに重み、バイアスを更新する 交差エントロピー誤差 N:全⽂字数 学習⽅法(5/7) 41
さて、問題です 60,000個ある訓練データを、 1バッチ=100個として、 10,000バッチ学習させると、 何epochに相当するでしょうか︖ 学習⽅法(6/7) 【Answer】 全データは60,000/100 = 600バッチ
よって、全データは10,000/600 = 16.7 epochs になります 42
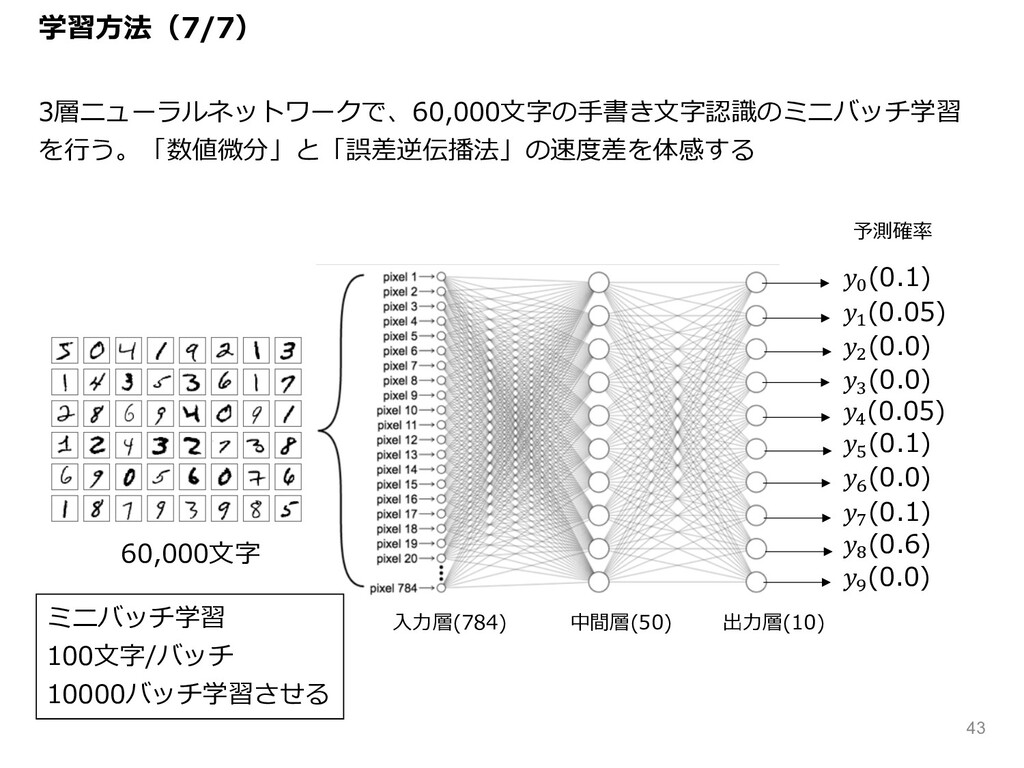
予測確率 = (0.1) & (0.05) ( (0.0) L (0.0) M
(0.05) N (0.1) O (0.0) P (0.1) Q (0.6) J (0.0) ⼊⼒層(784) 中間層(50) 出⼒層(10) 3層ニューラルネットワークで、60,000⽂字の⼿書き⽂字認識のミニバッチ学習 を⾏う。「数値微分」と「誤差逆伝播法」の速度差を体感する 60,000⽂字 ミニバッチ学習 100⽂字/バッチ 10000バッチ学習させる 学習⽅法(7/7) 43
第2回まとめ 44
第2回まとめ(1/2) • ディープラーニングの学習⽅法 傾きと逆⽅向にパラメータを更新して「⾕底」を⽬指す (勾配法) ・傾きの効率的な求め⽅ 推論で求めている値を使って、⾼速に傾きを求める (誤差逆伝播法) ・パラメータ更新のタイミング 学習法によってパラメーター更新のタイミングが異なる
(オンライン学習、ミニバッチ学習、バッチ学習) W ← W − ρ L W 45
第2回まとめ(2/2) 第3回は、以下を説明します 「第6章 学習に関するテクニック」 ・最適な重みパラメータを探索する⼿法(勾配⽅の進化形) ・パラメーターの初期値をどうするか︖ ・ハイパーパラメータの設定⽅法 ・過学習の対応策 局所最適解に陥ることがある 46
Appendix 47
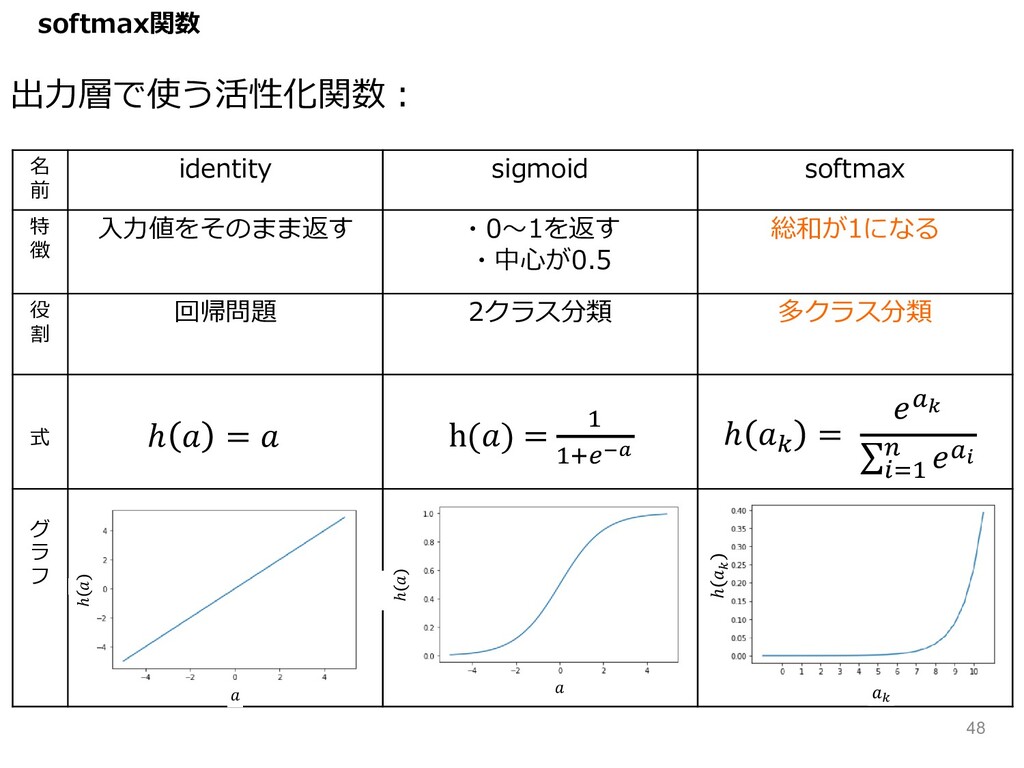
名 前 identity sigmoid softmax 特 徴 ⼊⼒値をそのまま返す ・0〜1を返す ・中⼼が0.5
総和が1になる 役 割 回帰問題 2クラス分類 多クラス分類 式 グ ラ フ ℎ = ℎ ~ = z• ∑R<& | z‚ ℎ ℎ h() = & &_ƒ„… 出⼒層で使う活性化関数︓ " ℎ " softmax関数 48
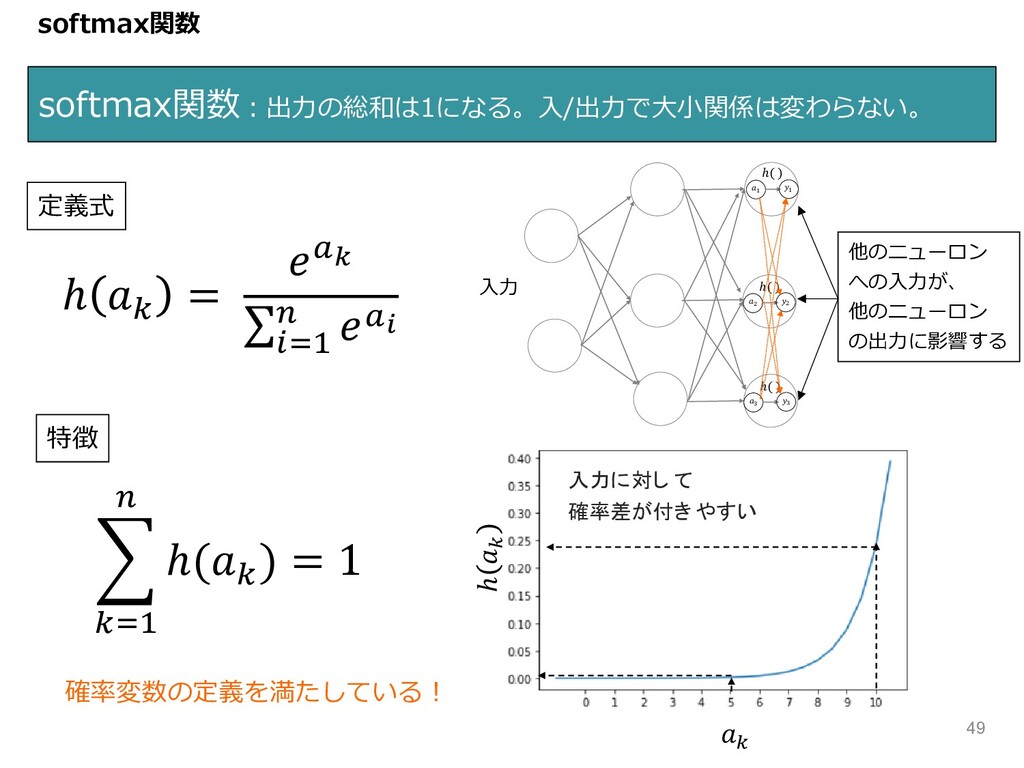
ℎ ~ = z• ∑ R<& | z‚ softmax関数 softmax関数︓出⼒の総和は1になる。⼊/出⼒で⼤⼩関係は変わらない。
{ ~<& | ℎ(~ ) = 1 定義式 特徴 確率変数の定義を満たしている︕ " " ℎ( ) ( ( ℎ( ) ) ) ℎ( ) " ℎ " 入力に対し て 確率差が付き やすい ⼊⼒ 他のニューロン への⼊⼒が、 他のニューロン の出⼒に影響する 49
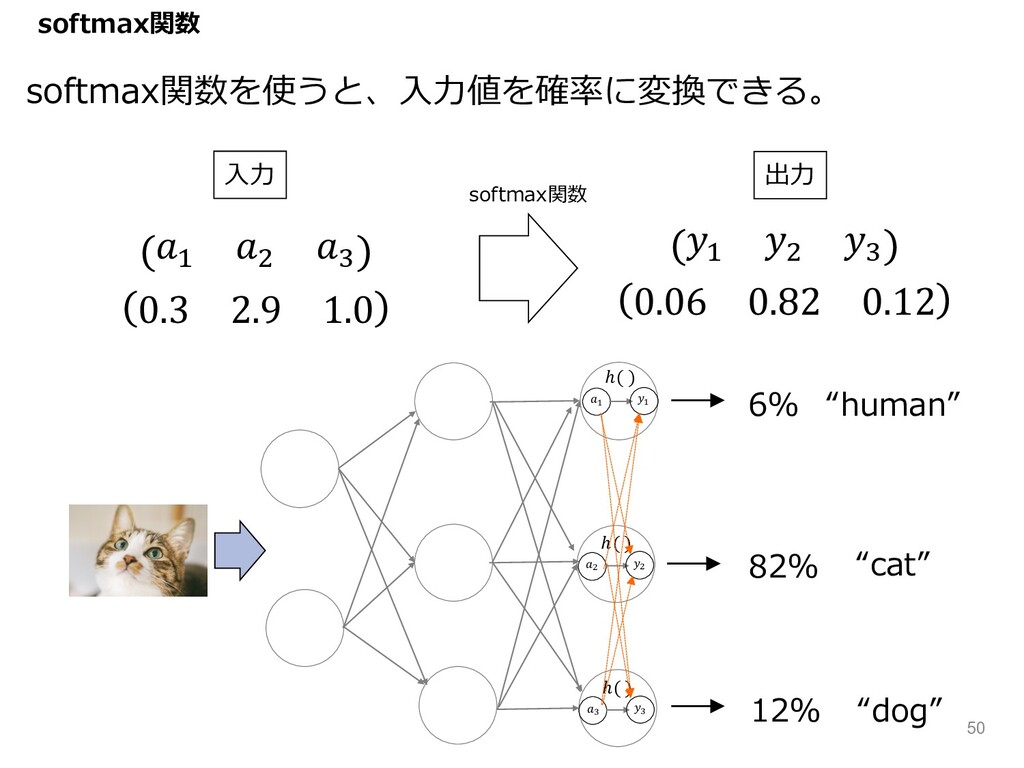
0.06 0.82 0.12 82% 6% “human” “cat” softmax関数を使うと、⼊⼒値を確率に変換できる。 " "
ℎ( ) ( ( ℎ( ) ) ) ℎ( ) 12% “dog” 0.3 2.9 1.0 & ( L & ( L ⼊⼒ 出⼒ softmax関数 softmax関数 50
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![どうやって「傾き」を求めるか︖(1/5) 機械は解析的に傾きを求められないので、「数値微分」によって近似的に求める 重みW L(W) 損失関数 2h 現在位置 [\(]) [] ≅](https://files.speakerdeck.com/presentations/a5659d7879fe455090134355fae303cf/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}