Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Deep Learning 1 (Chapter 2 , Chapter 3)
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
banquet.kuma
February 01, 2020
Technology
740
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Deep Learning 1 (Chapter 2 , Chapter 3)
発表用に「ゼロから作るディープラーニング1巻」(オライリー)の2,3章をまとめました。
banquet.kuma
February 01, 2020
More Decks by banquet.kuma
See All by banquet.kuma
SaaS is dead. は本当か?
dar_kuma_san
0
25
学習への生成AI活用:「毒」にするか「薬」にするか? - エビデンスと実践知に基づく活用戦略
dar_kuma_san
1
79
転職時代の退職金戦略
dar_kuma_san
0
38
AI新時代の富の源泉
dar_kuma_san
0
36
AI時代のテック投資戦略 - 中島聡氏のインサイトに基づく「富の源泉」
dar_kuma_san
0
53
Amazon Q Developer CLIをClaude Codeから使うためのベストプラクティスを考えてみた
dar_kuma_san
0
940
彼女を励ますために、 Azure OpenAI Serviceを使って、 kmakici LINE bot を作った
dar_kuma_san
0
200
面倒なことは、 Azure OpenAI Service× Power Automateにやらせよう!
dar_kuma_san
0
320
データで振り返るデータラーニングギルド【基礎集計の部】
dar_kuma_san
0
2.7k
Other Decks in Technology
See All in Technology
SRE Next 2026 何でも屋からの脱却
bto
0
690
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
1
110
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
1
4.5k
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
120
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
370
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
1
380
Claude Code 珍プレー好プレー
shinyasaita
0
330
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Genie Ontologyは銀の弾丸かを考える / Is Genie Ontology a Silver Bullet?
nttcom
0
260
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
160
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
6.1k
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
840
Featured
See All Featured
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
The Limits of Empathy - UXLibs8
cassininazir
1
460
KATA
mclloyd
PRO
35
15k
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Speed Design
sergeychernyshev
33
1.9k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
Writing Fast Ruby
sferik
630
63k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.5k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Scaling GitHub
holman
464
140k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Transcript
「ゼロから作るDeepLearning」 2、3章まとめ Twitterアカウント : @dar_kuma_san 1
なぜディープラーニングを学ぶ必要がある︖ 2
なぜディープラーニングを学ぶ必要がある︖(1/4) ⼈⼯知能における50年来のブレークスルーであり、 理論を理解し、実践することでビジネスへの応⽤が期待できる。 出典 https://www.slideshare.net/nlab_utokyo/deep-learning-40959442 3
なぜディープラーニングを学ぶ必要がある︖(2/4) • 2012年の画像認識コンペで、SVMなどの従来⼿法を抑えて優勝 • 「圧倒的性能」だったため、第3次AIブームの引き⾦に ILSVRC2012 1000種類、120万枚の学習⽤の画像データを使って、15万枚の画像を分類 ディープ ラーニング 従来
機械学習 出典 http://ymatsuo.com/DL.pdf 分類例 4
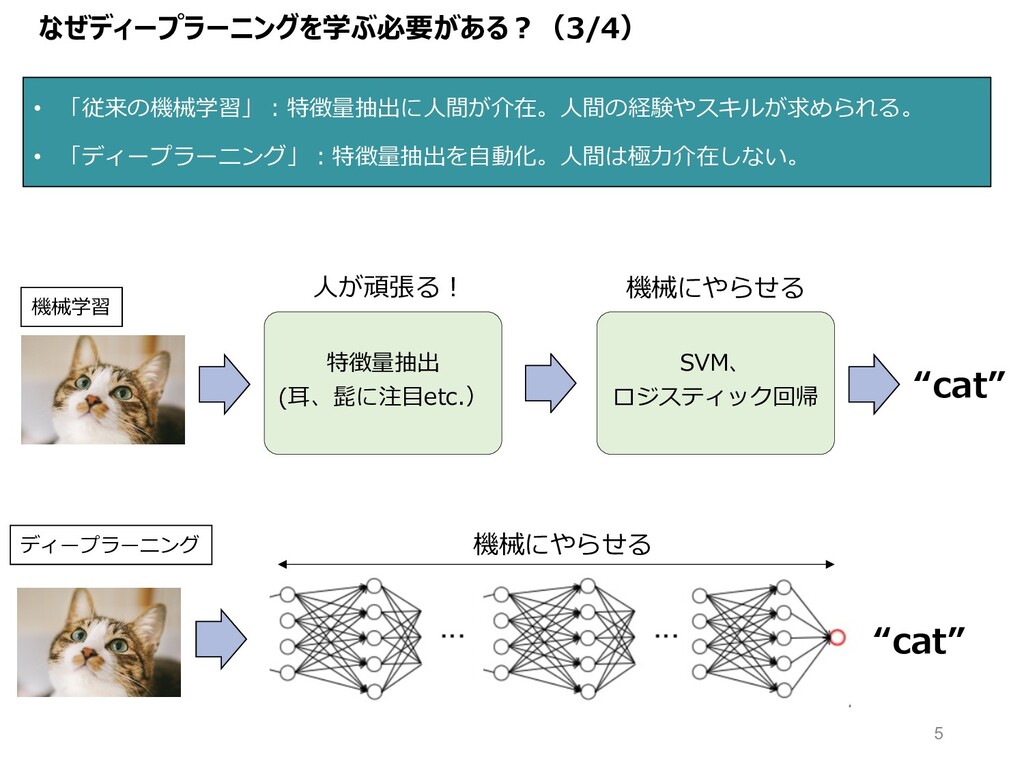
特徴量抽出 (⽿、髭に注⽬etc.) SVM、 ロジスティック回帰 なぜディープラーニングを学ぶ必要がある︖(3/4) • 「従来の機械学習」︓特徴量抽出に⼈間が介在。⼈間の経験やスキルが求められる。 • 「ディープラーニング」︓特徴量抽出を⾃動化。⼈間は極⼒介在しない。 “cat”
機械学習 ディープラーニング ⼈が頑張る︕ “cat” 機械にやらせる 機械にやらせる 5
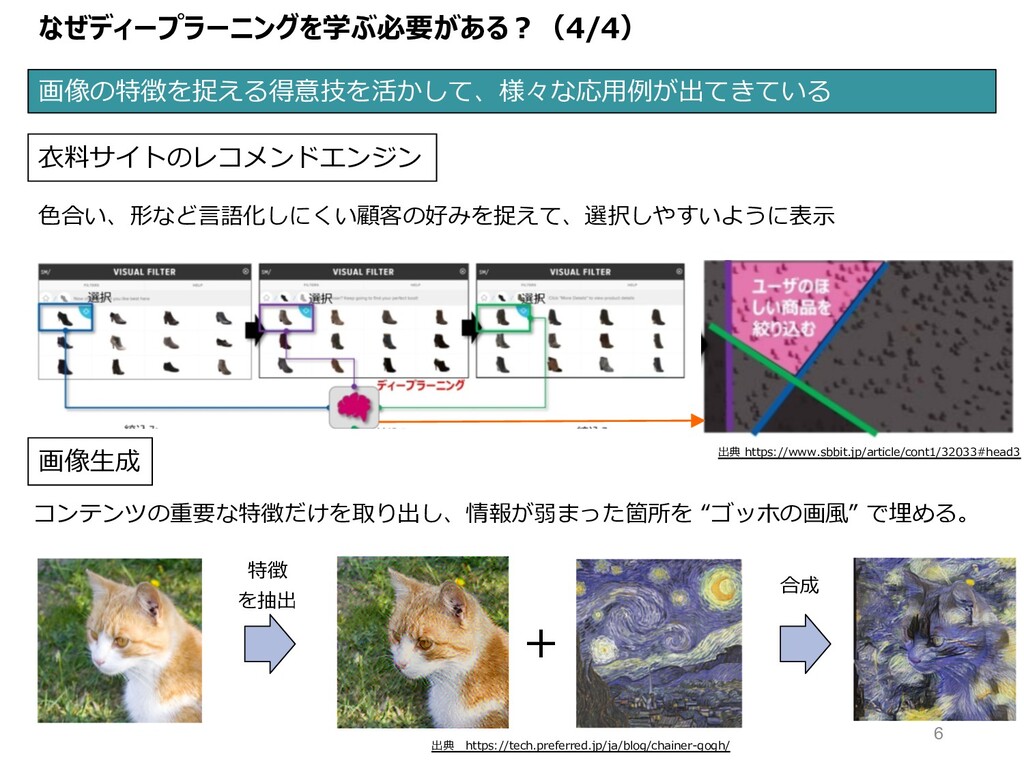
なぜディープラーニングを学ぶ必要がある︖(4/4) 画像の特徴を捉える得意技を活かして、様々な応⽤例が出てきている ⾐料サイトのレコメンドエンジン ⾊合い、形など⾔語化しにくい顧客の好みを捉えて、選択しやすいように表⽰ 出典 https://www.sbbit.jp/article/cont1/32033#head3 画像⽣成 特徴 を抽出 +
合成 コンテンツの重要な特徴だけを取り出し、情報が弱まった箇所を “ゴッホの画⾵” で埋める。 出典 https://tech.preferred.jp/ja/blog/chainer-gogh/ 6
ディープラーニングとは︖ 7
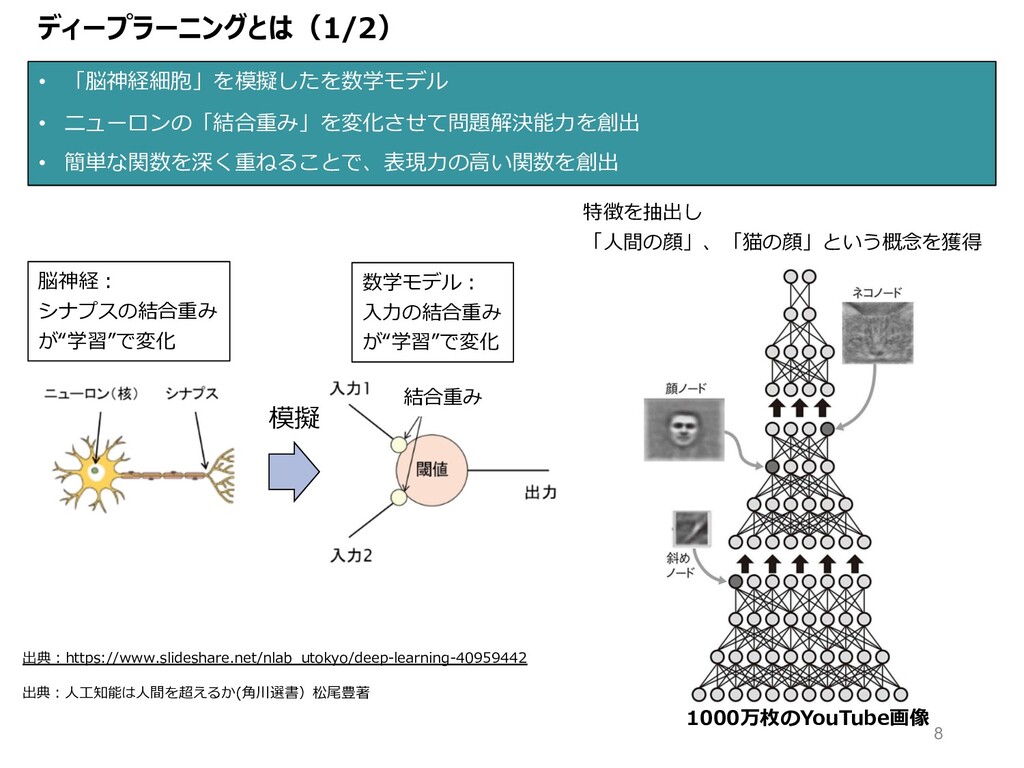
ディープラーニングとは(1/2) • 「脳神経細胞」を模擬したを数学モデル • ニューロンの「結合重み」を変化させて問題解決能⼒を創出 • 簡単な関数を深く重ねることで、表現⼒の⾼い関数を創出 模擬 特徴を抽出し 「⼈間の顔」、「猫の顔」という概念を獲得
出典︓https://www.slideshare.net/nlab_utokyo/deep-learning-40959442 結合重み 脳神経︓ シナプスの結合重み が“学習”で変化 数学モデル︓ ⼊⼒の結合重み が“学習”で変化 出典︓⼈⼯知能は⼈間を超えるか(⾓川選書)松尾豊著 1000万枚のYouTube画像 8
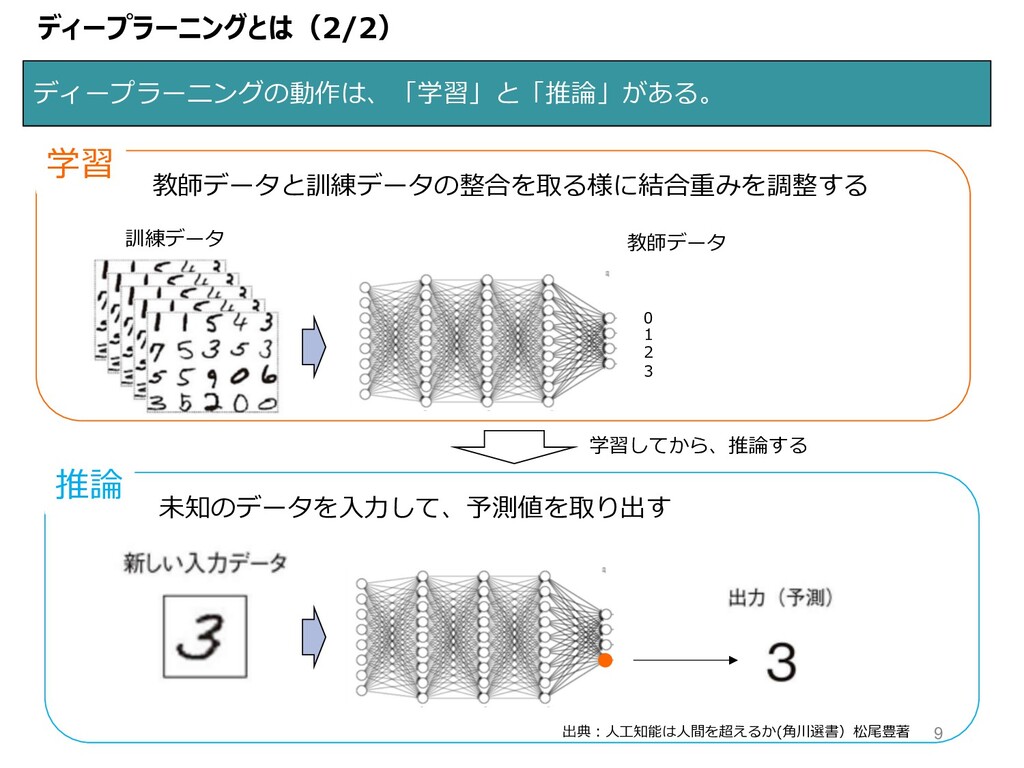
ディープラーニングとは(2/2) ディープラーニングの動作は、「学習」と「推論」がある。 教師データ 教師データと訓練データの整合を取る様に結合重みを調整する 学習 0 1 2 3 訓練データ
推論 未知のデータを⼊⼒して、予測値を取り出す 学習してから、推論する 出典︓⼈⼯知能は⼈間を超えるか(⾓川選書)松尾豊著 9
講座の流れ 10
講座の流れ(1/3) 特徴 ・動作をPythonを使って実装 ・ライブラリを使わないことで理解を促す 1章︓Python ⼊⾨ 2章︓パーセプトロン 3章︓ニューラルネットワーク 4章︓ニューラルネットワークの学習 5章︓誤差逆伝搬法
6章︓学習に関するテクニック 7章︓畳み込みニューラルネットワーク 8章︓ディープラーニング 11
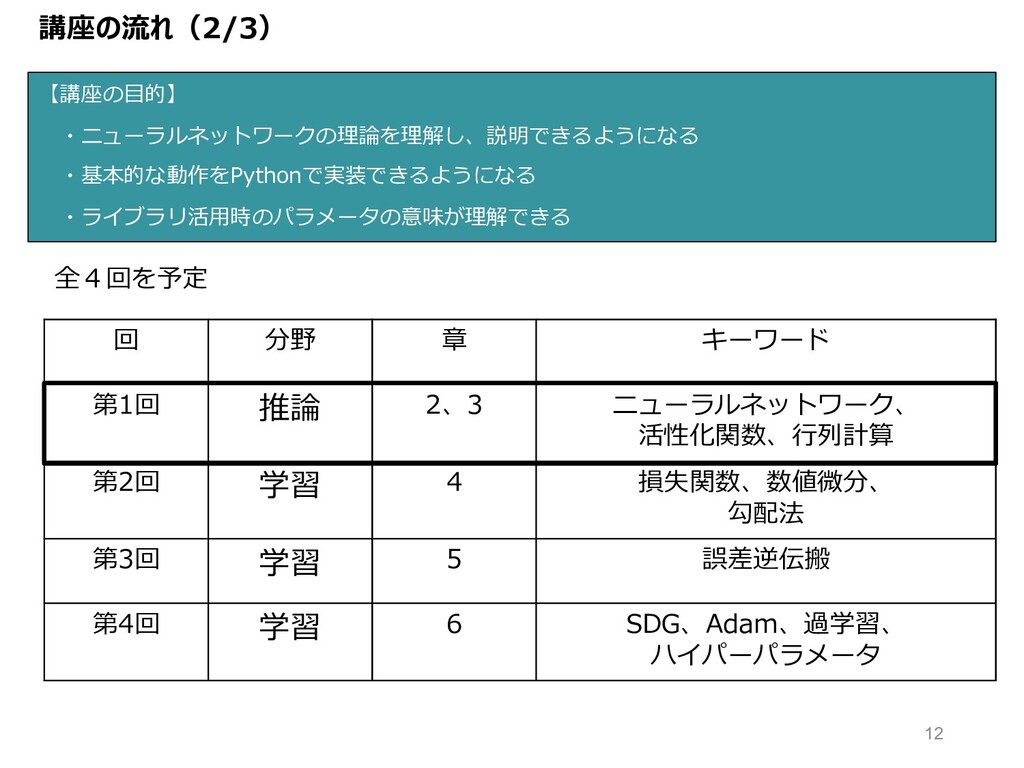
講座の流れ(2/3) 【講座の⽬的】 ・ニューラルネットワークの理論を理解し、説明できるようになる ・基本的な動作をPythonで実装できるようになる ・ライブラリ活⽤時のパラメータの意味が理解できる 回 分野 章 キーワード 第1回
推論 2、3 ニューラルネットワーク、 活性化関数、⾏列計算 第2回 学習 4 損失関数、数値微分、 勾配法 第3回 学習 5 誤差逆伝搬 第4回 学習 6 SDG、Adam、過学習、 ハイパーパラメータ 全4回を予定 12
1. パーセプトロン ⇒最⼩構成要素の動きを理解 2. ニューラルネットワーク ⇒多層化する 3. 活性化関数の導⼊ ⇒多層化のメリットを引き出す 4.
推論動作を紐解く ⇒推論動作を⼿計算する 5. まとめ 第1回の⽬標 • 推論動作が「⾏列の積と和」であることを理解する • 「活性化関数」の種類と役割を理解する 講座の流れ(3/3) 13
“単層パーセプトロン”の動きを理解する 14
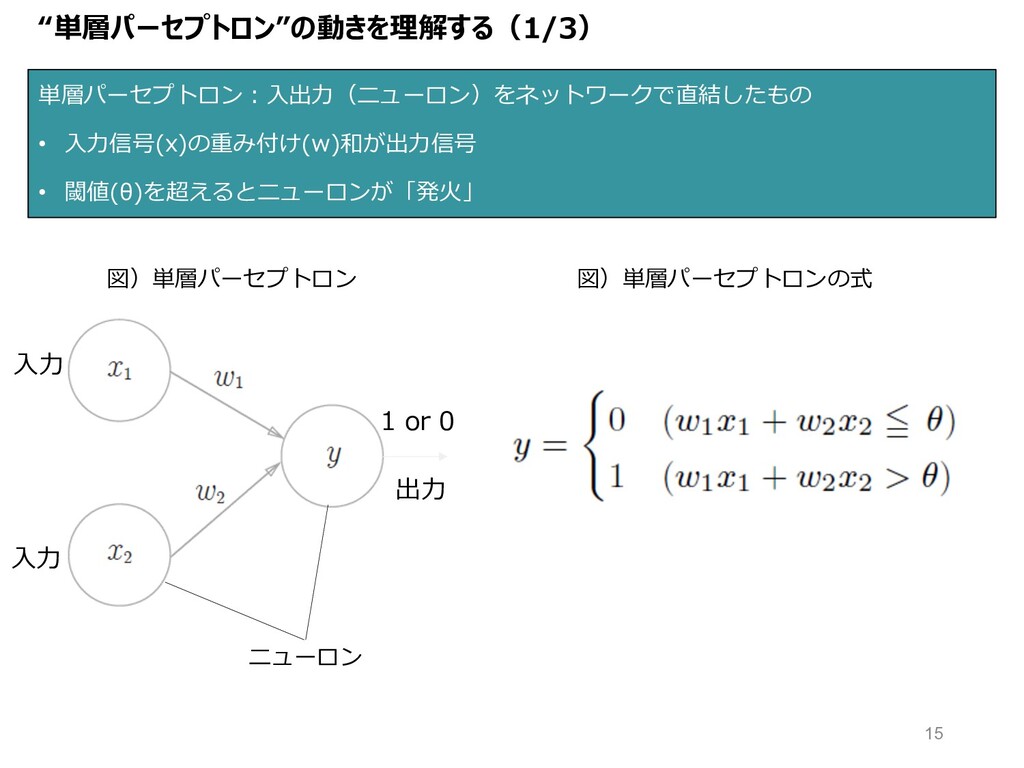
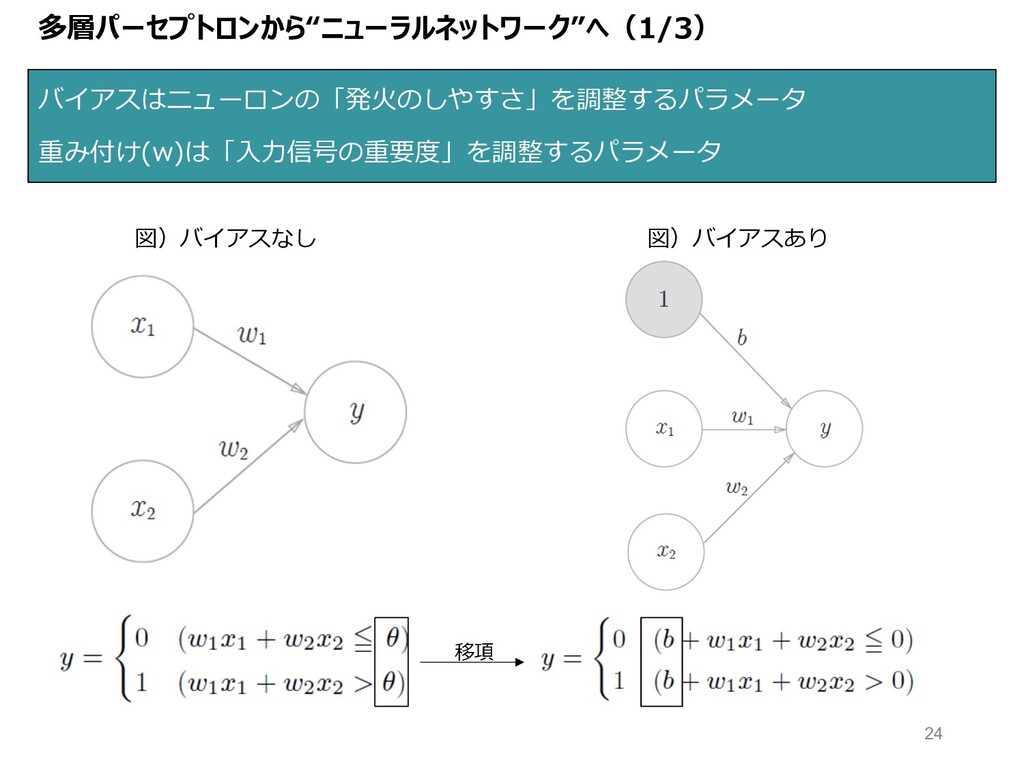
“単層パーセプトロン”の動きを理解する(1/3) 単層パーセプトロン︓⼊出⼒(ニューロン)をネットワークで直結したもの • ⼊⼒信号(x)の重み付け(w)和が出⼒信号 • 閾値(θ)を超えるとニューロンが「発⽕」 図)単層パーセプトロン 図)単層パーセプトロンの式 1 or
0 ニューロン ⼊⼒ ⼊⼒ 出⼒ 15
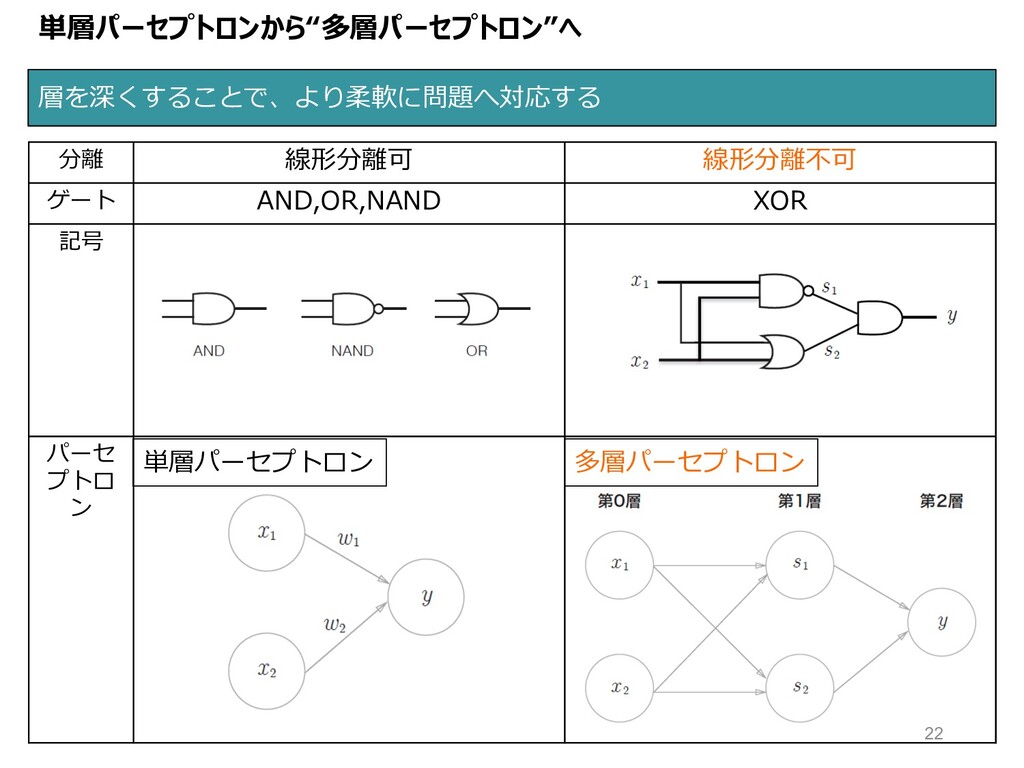
• AND, OR, NAND ゲートは全て単層パーセプトロンで表現可能 • 「適切に重み付け(w)と閾値(θ)を決めることが重要」 ゲート AND OR
NAND 式 閾値 真理値 (w" , w$, )=(0.5, 0.5,0.7) (w", w$,)=(−0.5, −0.5, −0.7) (w", w$,)=(0.5, 0.5,0.2) “単層パーセプトロン”の動きを理解する(2/3) 16
ゲート XOR 式 パラメタ 真理値 (w", w$,)=(︖, ︖, ︖) それでは、XOR(排他的論理和)はどのように表されるでしょう︖
“単層パーセプトロン”の動きを理解する(3/3) 17
“単層パーセプトロン”の限界 18
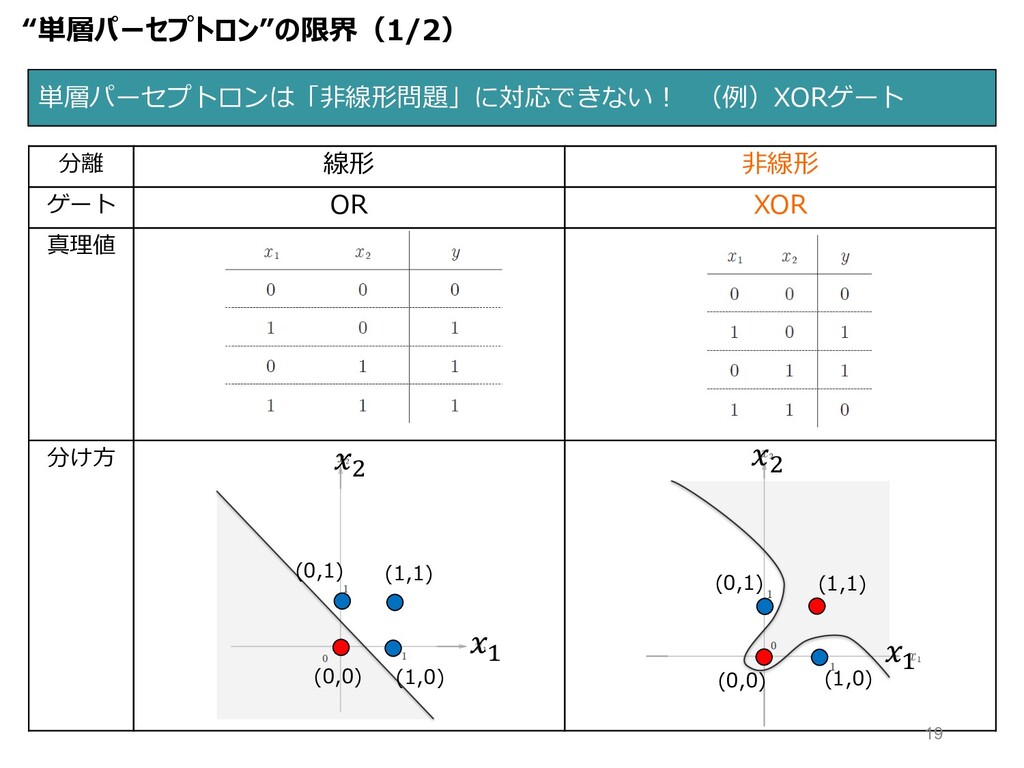
単層パーセプトロンは「⾮線形問題」に対応できない ! (例)XORゲート 分離 線形 ⾮線形 ゲート OR XOR 真理値
分け⽅ $ " (0,1) (1,1) (1,0) (0,0) " $ (1,1) (1,0) (0,1) (0,0) “単層パーセプトロン”の限界(1/2) 19
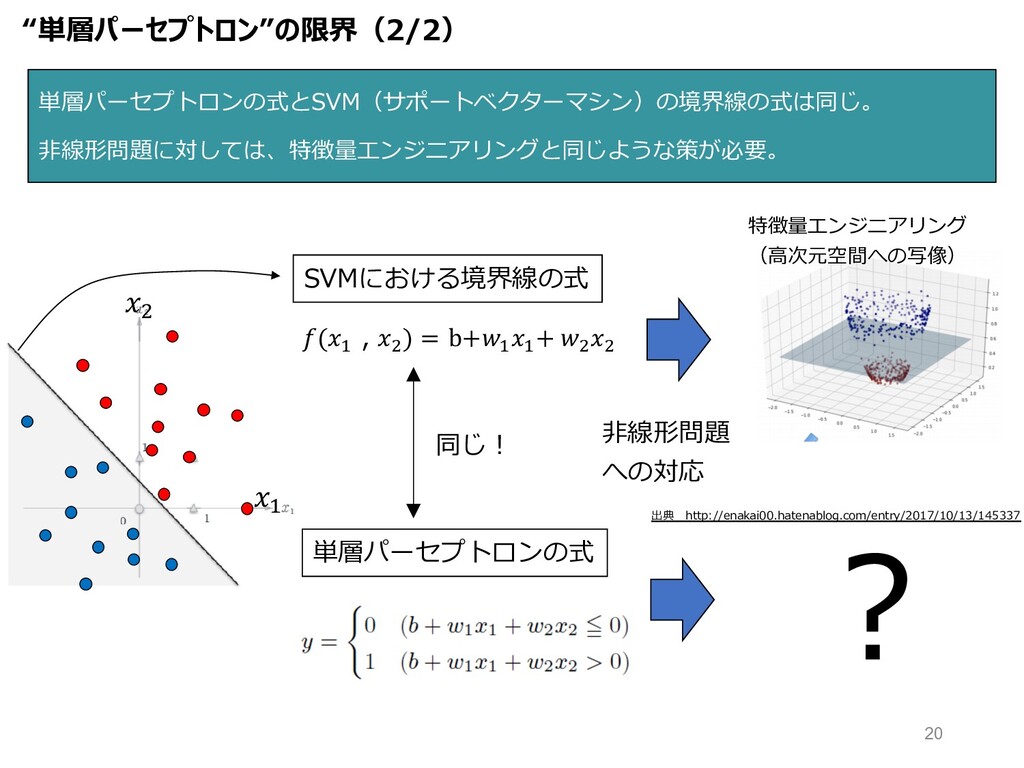
" # 単層パーセプトロンの式とSVM(サポートベクターマシン)の境界線の式は同じ。 ⾮線形問題に対しては、特徴量エンジニアリングと同じような策が必要。 単層パーセプトロンの式 SVMにおける境界線の式 (" , $ )
= b+" " + $ $ 同じ︕ ⾮線形問題 への対応 ? 特徴量エンジニアリング (⾼次元空間への写像) “単層パーセプトロン”の限界(2/2) 出典 http://enakai00.hatenablog.com/entry/2017/10/13/145337 20
単層パーセプトロンから“多層パーセプトロン”へ 21
単層パーセプトロンから“多層パーセプトロン”へ 層を深くすることで、より柔軟に問題へ対応する 分離 線形分離可 線形分離不可 ゲート AND,OR,NAND XOR 記号 パーセ
プトロ ン 単層パーセプトロン 多層パーセプトロン 22
多層パーセプトロンから “ニューラルネットワーク”へ 23
多層パーセプトロンから“ニューラルネットワーク”へ(1/3) バイアスはニューロンの「発⽕のしやすさ」を調整するパラメータ 重み付け(w)は「⼊⼒信号の重要度」を調整するパラメータ 図)バイアスなし 図)バイアスあり 移項 24
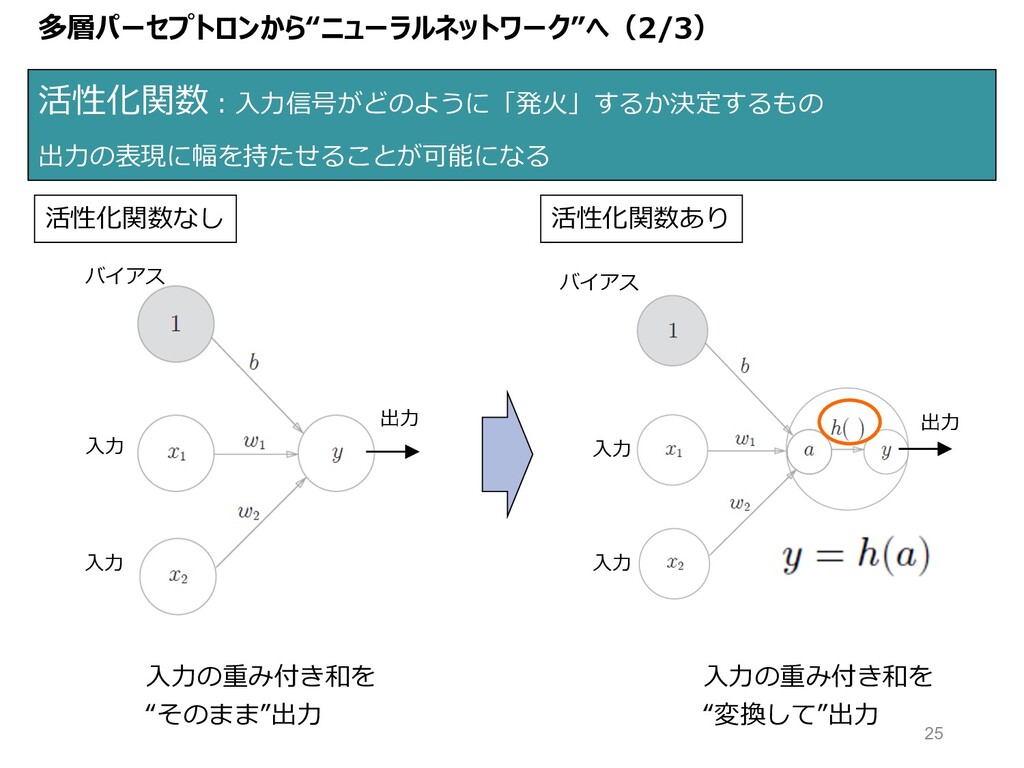
多層パーセプトロンから“ニューラルネットワーク”へ(2/3) 活性化関数︓⼊⼒信号がどのように「発⽕」するか決定するもの 出⼒の表現に幅を持たせることが可能になる ⼊⼒ ⼊⼒ バイアス バイアス ⼊⼒ ⼊⼒ 出⼒
出⼒ ⼊⼒の重み付き和を “そのまま”出⼒ ⼊⼒の重み付き和を “変換して”出⼒ 活性化関数なし 活性化関数あり 25
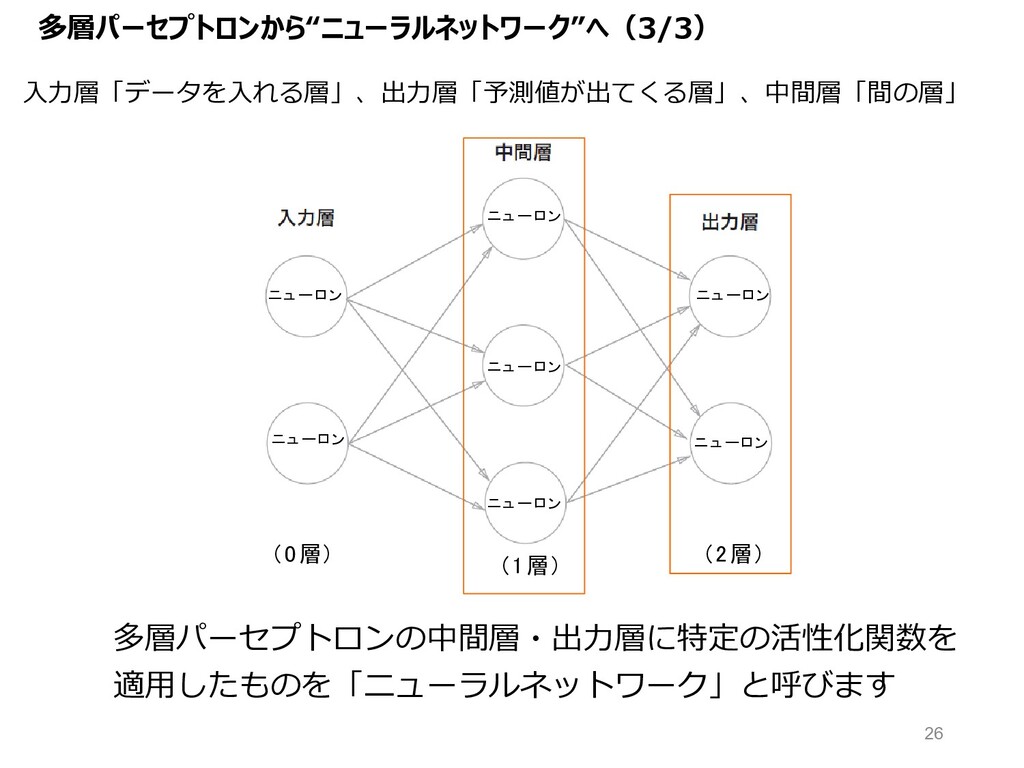
⼊⼒層「データを⼊れる層」、出⼒層「予測値が出てくる層」、中間層「間の層」 ニュ ーロン (0層) (2層) (1層) ニュ ーロン ニュ ーロン
ニュ ーロン ニュ ーロン ニュ ーロン ニュ ーロン 多層パーセプトロンの中間層・出⼒層に特定の活性化関数を 適⽤したものを「ニューラルネットワーク」と呼びます 多層パーセプトロンから“ニューラルネットワーク”へ(3/3) 26
活性化関数の種類と役割 27
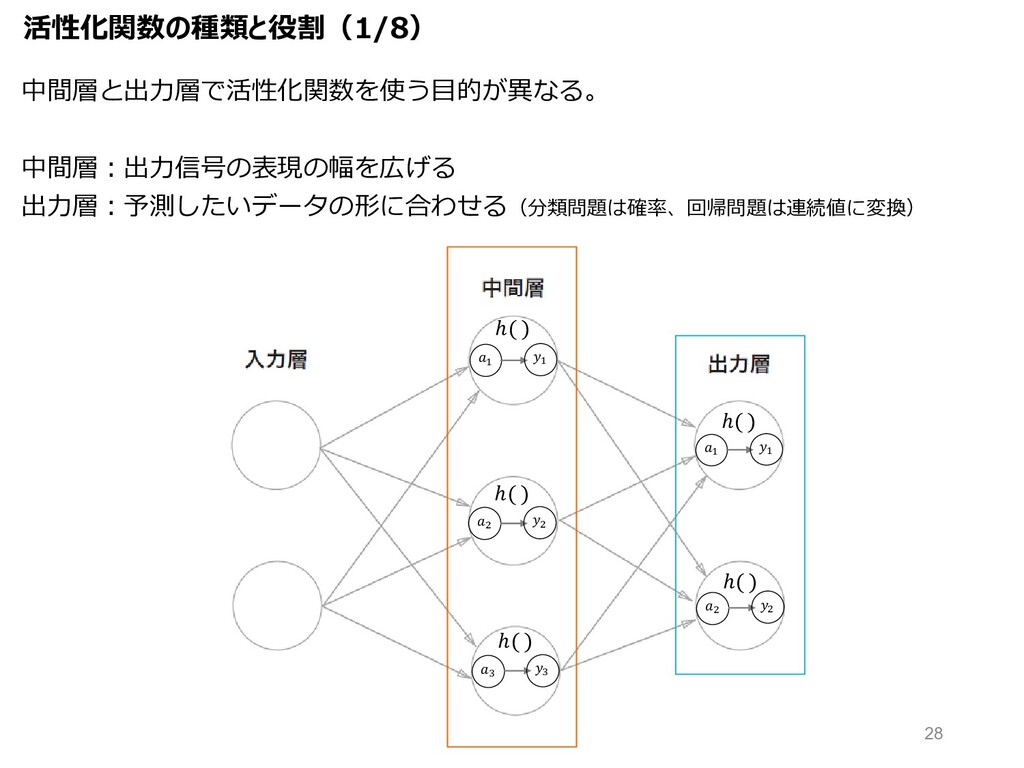
中間層と出⼒層で活性化関数を使う⽬的が異なる。 中間層︓出⼒信号の表現の幅を広げる 出⼒層︓予測したいデータの形に合わせる(分類問題は確率、回帰問題は連続値に変換) " # $ " # $ ℎ(
) ℎ( ) ℎ( ) " # " # ℎ( ) ℎ( ) 活性化関数の種類と役割(1/8) 28
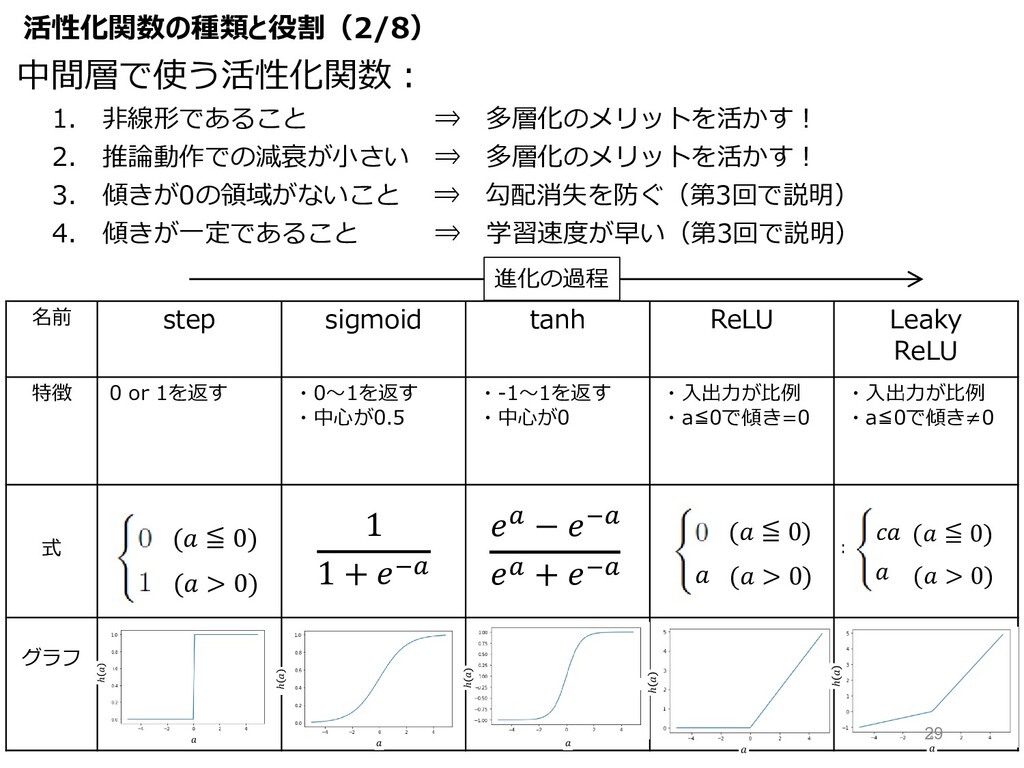
1. ⾮線形であること ⇒ 多層化のメリットを活かす︕ 2. 推論動作での減衰が⼩さい ⇒ 多層化のメリットを活かす︕ 3. 傾きが0の領域がないこと
⇒ 勾配消失を防ぐ(第3回で説明) 4. 傾きが⼀定であること ⇒ 学習速度が早い(第3回で説明) 名前 step sigmoid tanh ReLU Leaky ReLU 特徴 0 or 1を返す ・0〜1を返す ・中⼼が0.5 ・-1〜1を返す ・中⼼が0 ・⼊出⼒が⽐例 ・a≦0で傾き=0 ・⼊出⼒が⽐例 ・a≦0で傾き≠0 式 グラフ ℎ ℎ ℎ ℎ ( > 0) ( ≦ 0) 1 1 + 78 8 − 78 8 + 78 ( > 0) ( ≦ 0) ( > 0) ( ≦ 0) 進化の過程 ℎ 中間層で使う活性化関数︓ 活性化関数の種類と役割(2/8) 29
⾮線形関数 ・ステップ関数 h() = " ":;<=(7>) ・シグモイド関数 ・ReLU関数 線形関数 h(x)
=cx h(x) =cx h(h(x)) =$x h(h(h(x))) =Bx → h(x) =Ex と等価 1.⾮線形関数であること ⇒ 線形関数を使うと多層の利点を⽣かせない(= 中間層なしと同じ) ℎ c = 1と置くと、 活性化関数がない ことと同じ︕ 活性化関数の種類と役割(3/8) 30
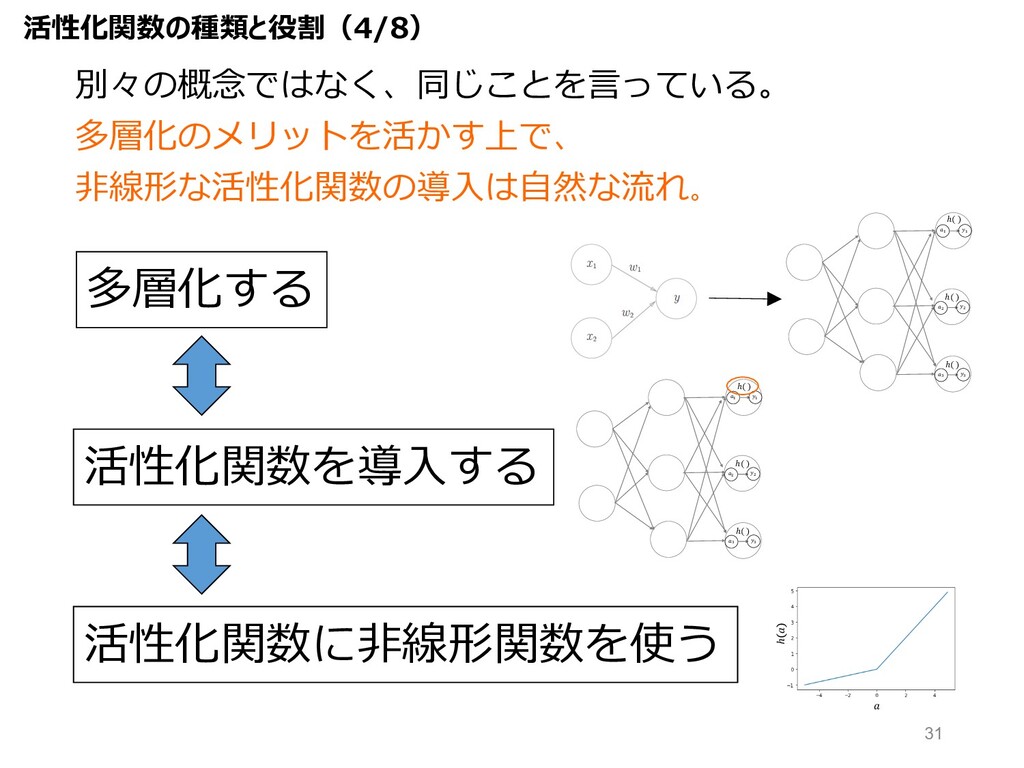
多層化する 活性化関数を導⼊する 活性化関数に⾮線形関数を使う 別々の概念ではなく、同じことを⾔っている。 多層化のメリットを活かす上で、 ⾮線形な活性化関数の導⼊は⾃然な流れ。 " " ℎ( )
( ( ℎ( ) ) ) ℎ( ) " " ℎ( ) ( ( ℎ( ) ) ) ℎ( ) ℎ 活性化関数の種類と役割(4/8) 31
ℎ( ) ℎ( ) ℎ( ) ℎ( ) ℎ( )
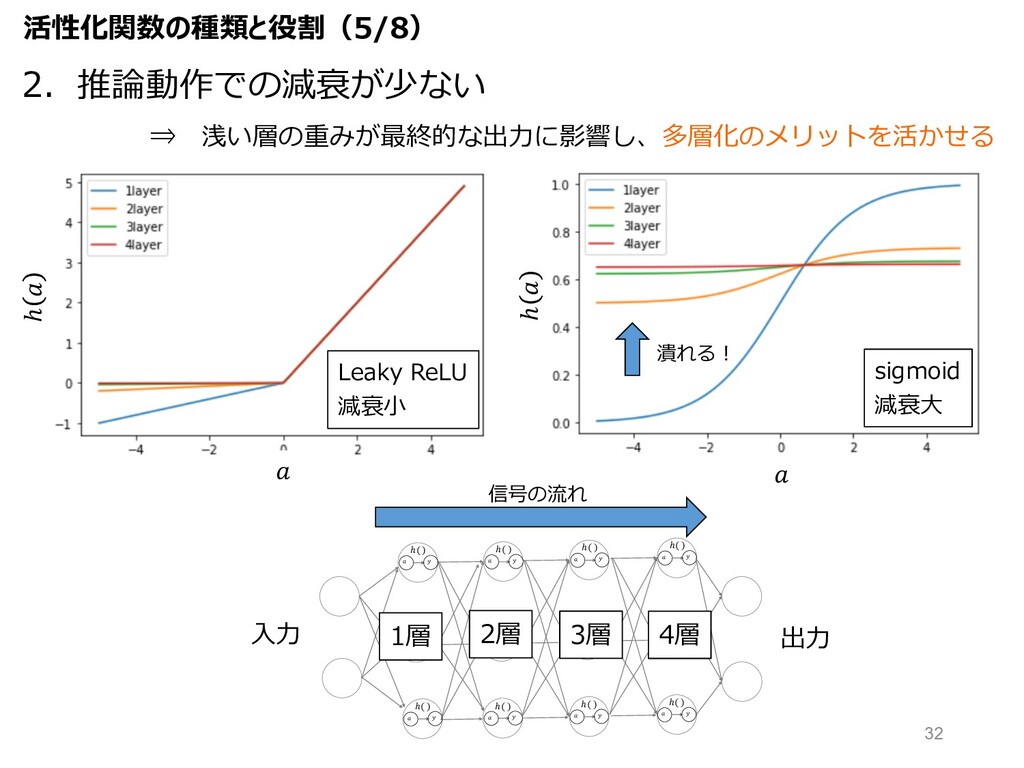
ℎ( ) ℎ( ) ℎ( ) ℎ( ) ℎ( ) ℎ( ) ℎ( ) sigmoid 減衰⼤ ⼊⼒ 出⼒ 1層 2層 3層 4層 ℎ ℎ 信号の流れ 活性化関数の種類と役割(5/8) 2.推論動作での減衰が少ない ⇒ 浅い層の重みが最終的な出⼒に影響し、多層化のメリットを活かせる Leaky ReLU 減衰⼩ 潰れる︕ 32
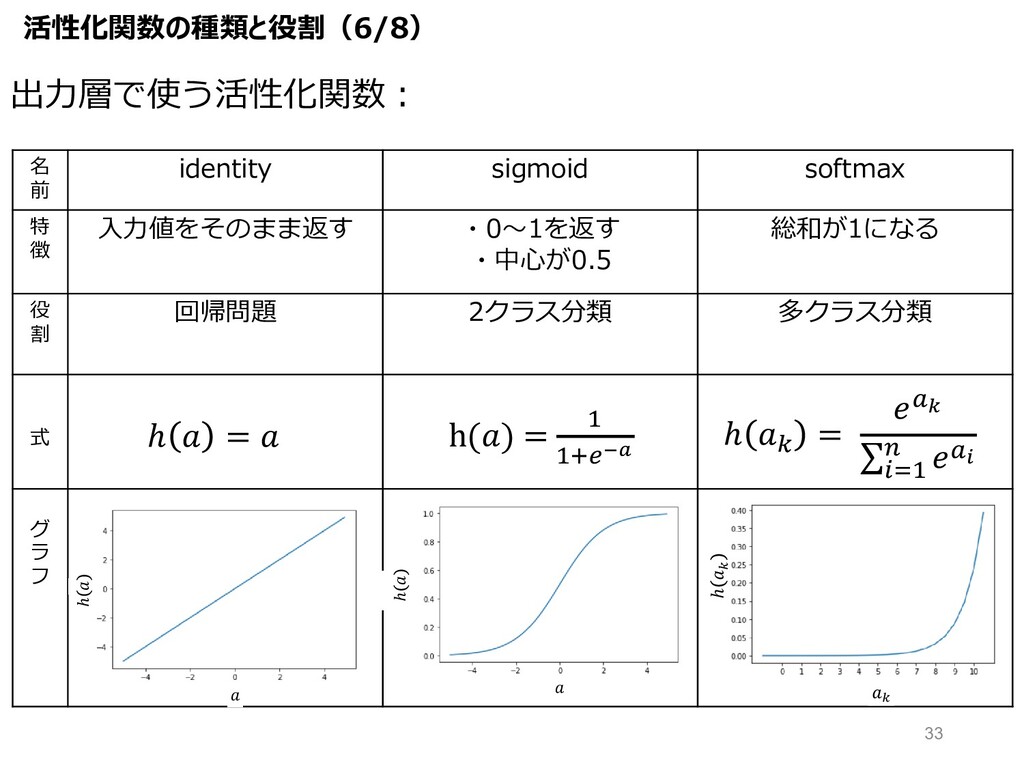
名 前 identity sigmoid softmax 特 徴 ⼊⼒値をそのまま返す ・0〜1を返す ・中⼼が0.5
総和が1になる 役 割 回帰問題 2クラス分類 多クラス分類 式 グ ラ フ ℎ = ℎ H = 8I ∑KL" M 8N ℎ ℎ h() = " ":OPQ 出⼒層で使う活性化関数︓ 活性化関数の種類と役割(6/8) " ℎ " 33
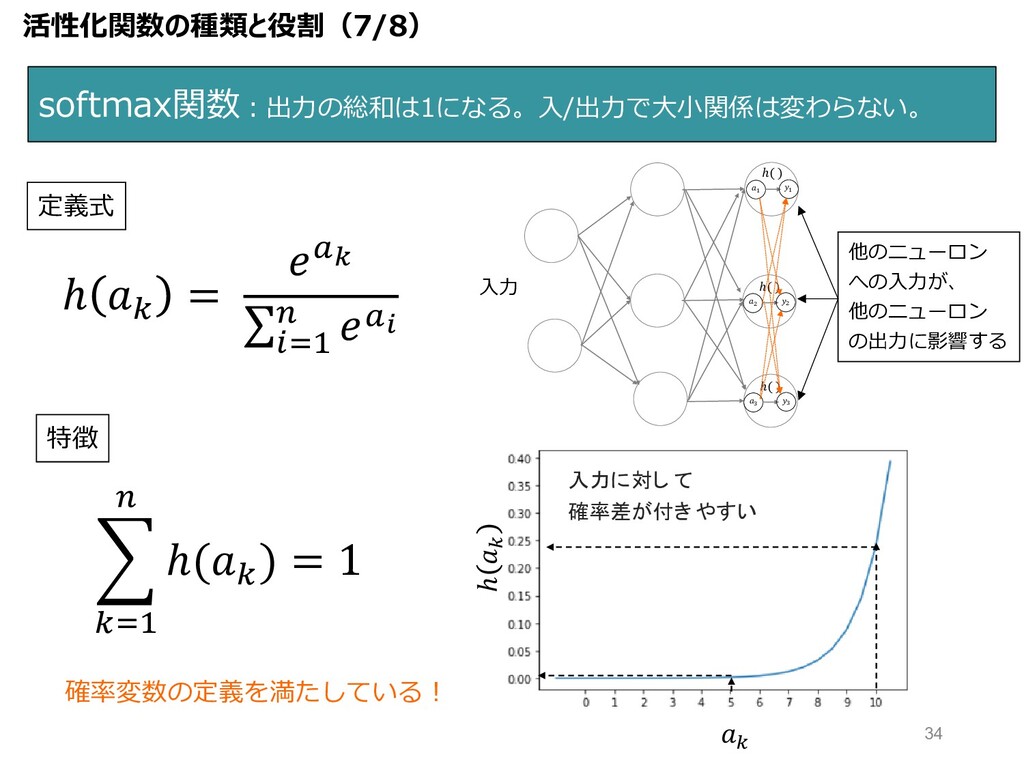
ℎ H = 8I ∑ KL" M 8N softmax関数︓出⼒の総和は1になる。⼊/出⼒で⼤⼩関係は変わらない。 R
HL" M ℎ(H ) = 1 定義式 特徴 確率変数の定義を満たしている︕ 活性化関数の種類と役割(7/8) " " ℎ( ) ( ( ℎ( ) ) ) ℎ( ) " ℎ " 入力に対し て 確率差が付き やすい ⼊⼒ 他のニューロン への⼊⼒が、 他のニューロン の出⼒に影響する 34
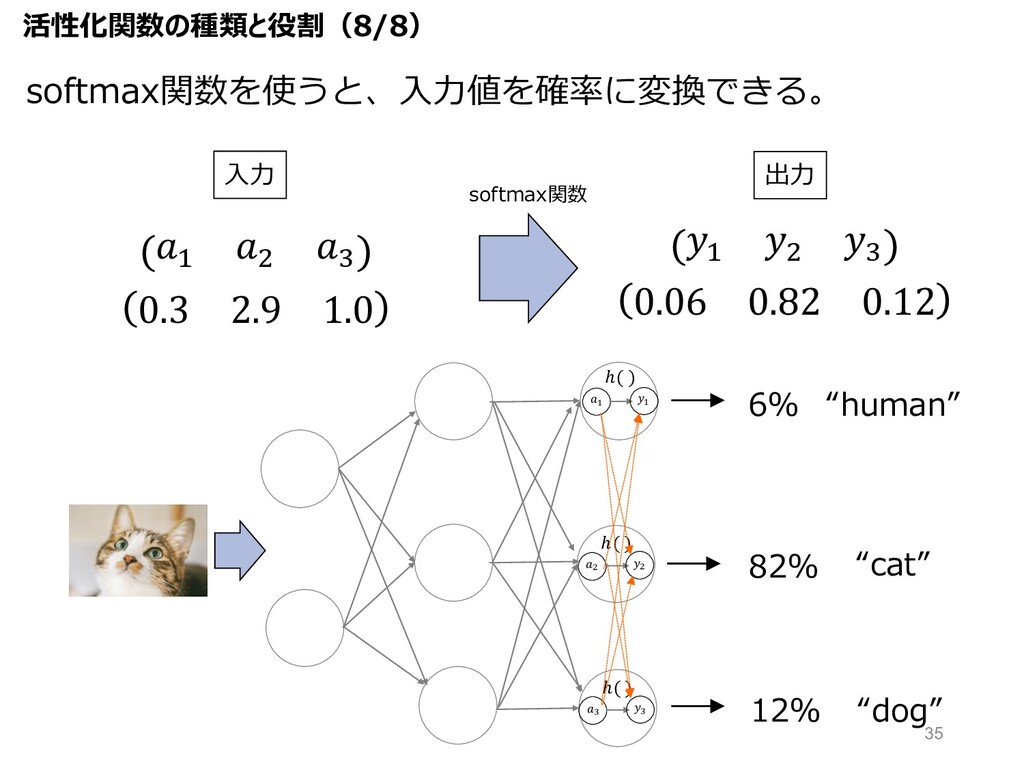
0.06 0.82 0.12 82% 6% “human” “cat” softmax関数を使うと、⼊⼒値を確率に変換できる。 " "
ℎ( ) ( ( ℎ( ) ) ) ℎ( ) 12% “dog” 0.3 2.9 1.0 " $ B " $ B ⼊⼒ 出⼒ 活性化関数の種類と役割(8/8) softmax関数 35
ニューラルネットワークの推論動作を紐解く 36
ニューラルネットワークの推論動作を紐解く(1/3) 結論、 ニューラルネットワーク(≒ディープラーニング) の推論動作(⼊⼒から出⼒への信号の流れ)は “⾏列の積と和” だけで表せます。 37
⾏列の積の復習 • 前の⾏列の列数と後ろの⾏列の⾏数が⼀致してれば掛けられる • 前の⾏列の⾏数と後ろの⾏列の列数ができる⾏列の⾏・列数に等しい " $ B " $
B " " $ $ B B = " " + $ $ + B B " " + $ $ + B B " " + $ $ + B B " " + $ $ + B B (2⾏,3列)×(3⾏,2列) (2⾏,2列) ⼀致 ニューラルネットワークの推論動作を紐解く(2/3) 38
" $ "" $" B" "$ $$ B$ + "
$ B = " $ B ⼊⼒ 重み 中間層への⼊⼒ 信号の流れ ⼊⼒層 中間層 " = "" " + "$ $ + " $ = $""+ $$$+ $ B = B""+ B$$+ B 以下の図にエッセンスが詰まっています。 層が深くなっても、⾏列の積と和を繰り返すだけ。 1 1 2 3 X 1 2 1 3 5 2 4 6 + 1 1 1 = 6 12 18 バイアス W b Y = ニューラルネットワークの推論動作を紐解く(3/3) 39
3層ニューラルネットワークの動きを理解する 40
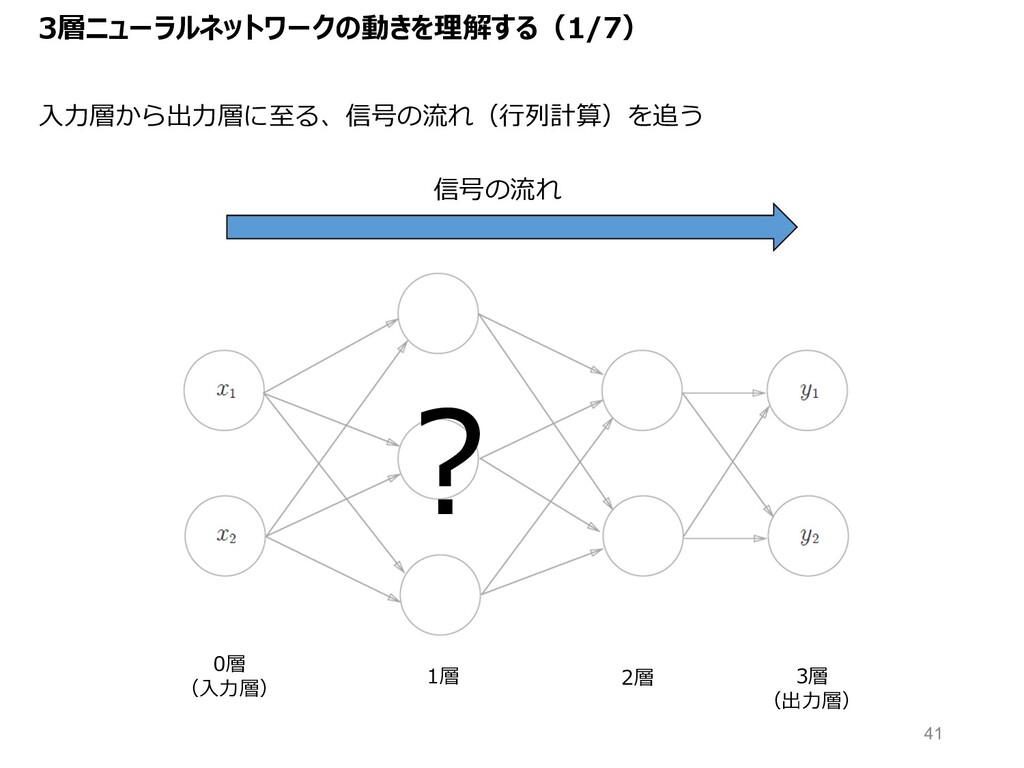
3層ニューラルネットワークの動きを理解する(1/7) ? 信号の流れ 0層 (⼊⼒層) 1層 2層 3層 (出⼒層) ⼊⼒層から出⼒層に⾄る、信号の流れ(⾏列計算)を追う
41
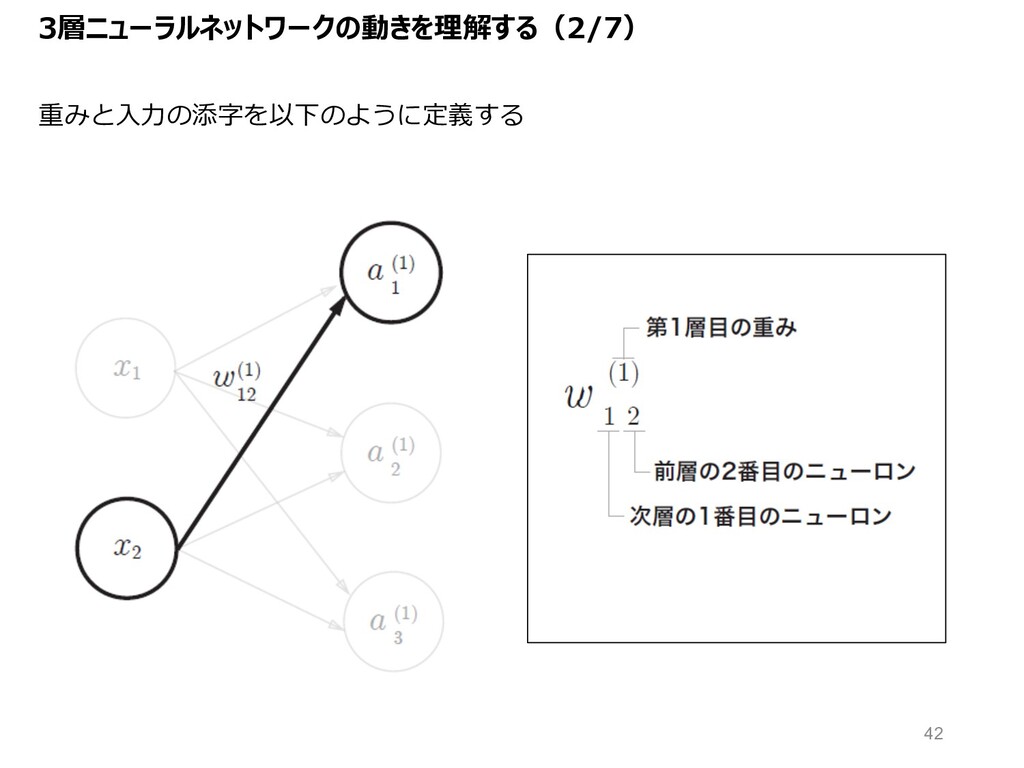
3層ニューラルネットワークの動きを理解する(2/7) 重みと⼊⼒の添字を以下のように定義する 42
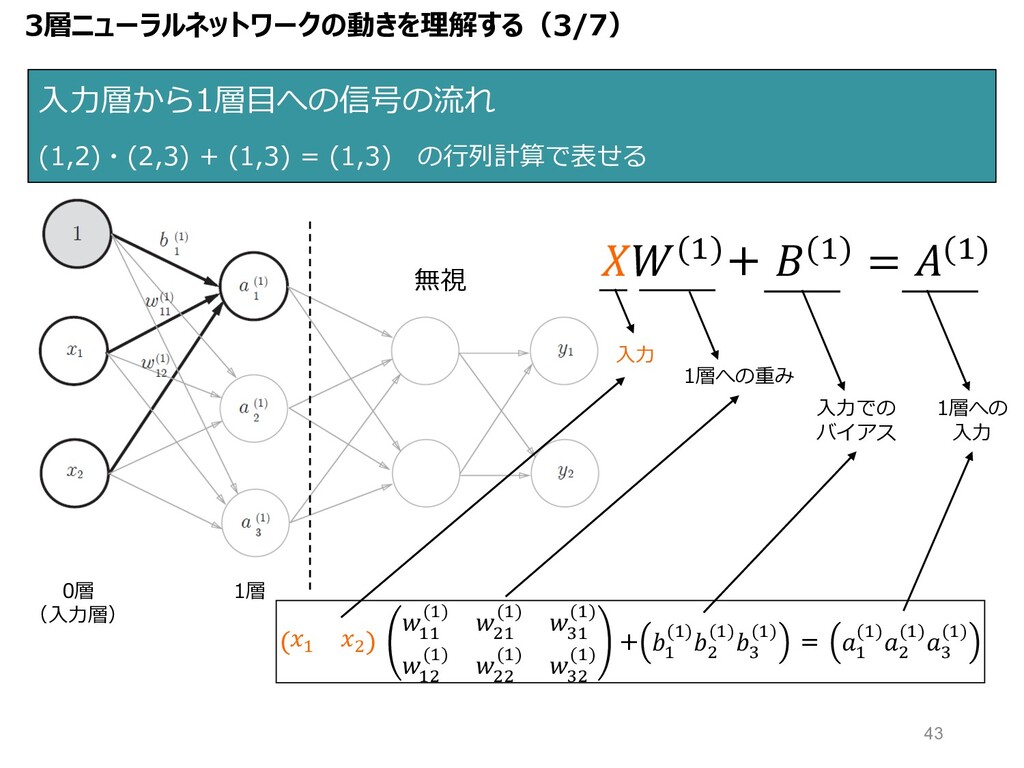
⼊⼒層から1層⽬への信号の流れ (1,2)・(2,3) + (1,3) = (1,3) の⾏列計算で表せる 0層 (⼊⼒層) 1層
" $ "" (") $" (") B" (") "$ (") $$ (") B$ (") + " (")$ (")B (") = " (")$ (")B (") 1層への重み ⼊⼒ (")+ (") = (") ⼊⼒での バイアス 1層への ⼊⼒ 無視 3層ニューラルネットワークの動きを理解する(3/7) 43
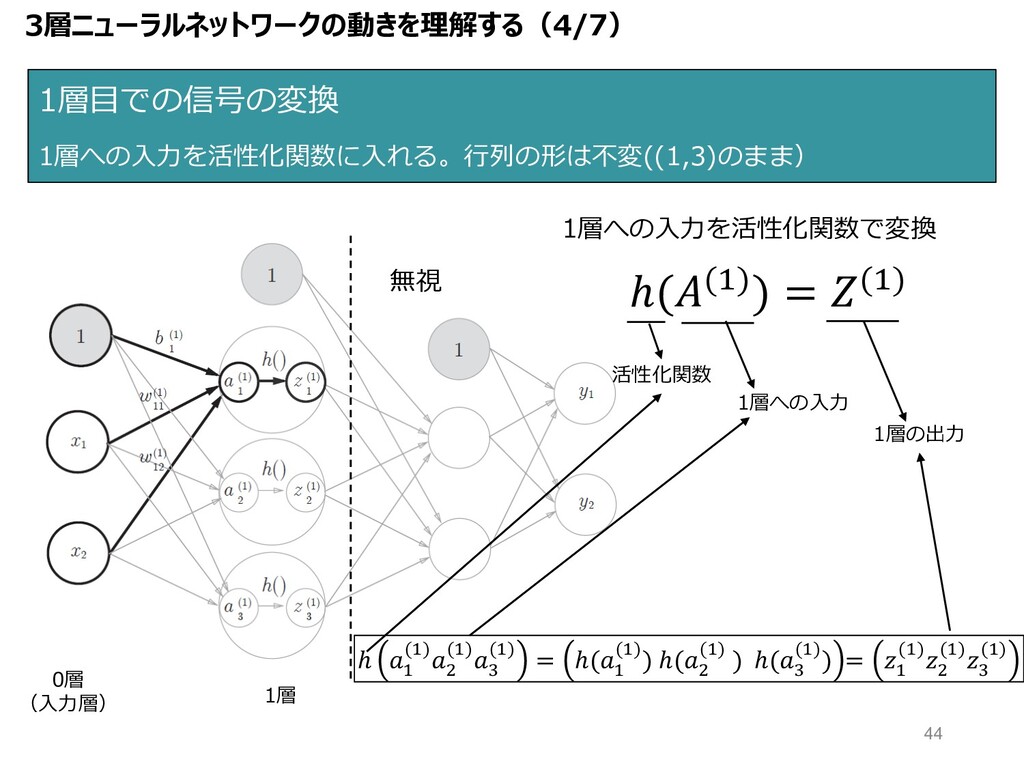
1層⽬での信号の変換 1層への⼊⼒を活性化関数に⼊れる。⾏列の形は不変((1,3)のまま) 無視 ℎ((")) = (") ℎ " (")$ (")B
(") = ℎ(" (")) ℎ($ (") ) ℎ(B (")) = " (")$ (")B (") 1層への⼊⼒を活性化関数で変換 1層の出⼒ 1層への⼊⼒ 活性化関数 1層 0層 (⼊⼒層) 3層ニューラルネットワークの動きを理解する(4/7) 44
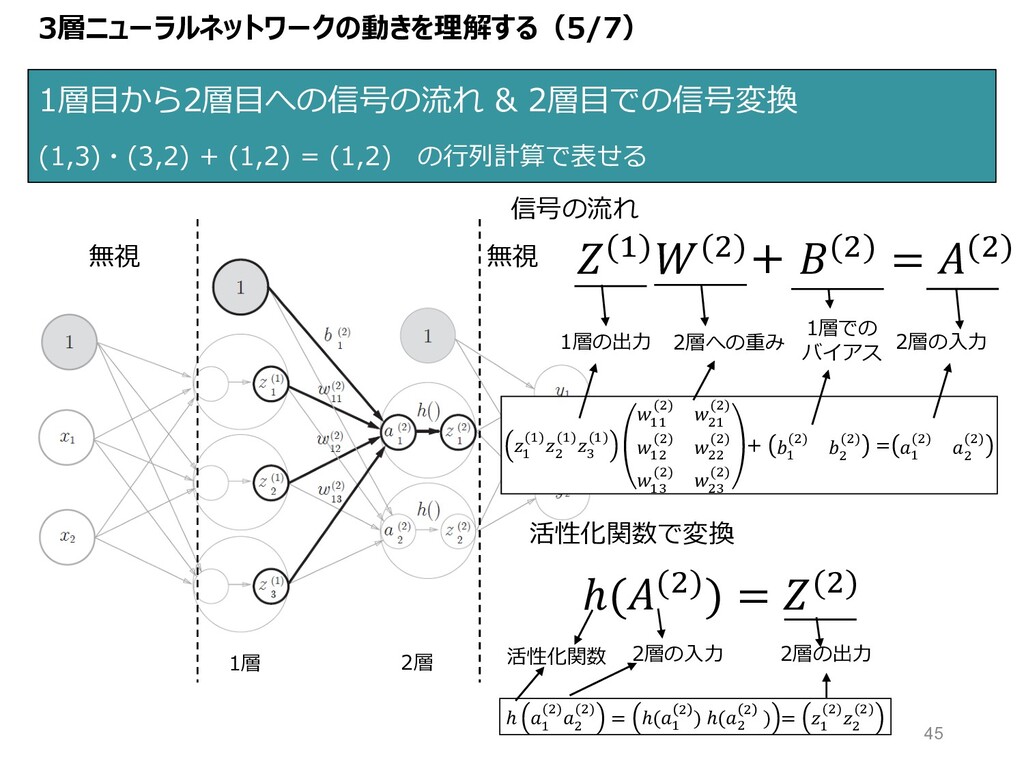
3層ニューラルネットワークの動きを理解する(5/7) 1層⽬から2層⽬への信号の流れ & 2層⽬での信号変換 (1,3)・(3,2) + (1,2) = (1,2) の⾏列計算で表せる
無視 (")($)+ ($) = ($) ℎ(($)) = ($) 1層 2層 " (")$ (")B (") "" ($) $" ($) "$ ($) $$ ($) "B ($) $B ($) + " ($) $ ($) = " ($) $ ($) 信号の流れ 活性化関数で変換 無視 1層の出⼒ ℎ " ($)$ ($) = ℎ(" $ ) ℎ($ $ ) = " ($)$ ($) 2層の⼊⼒ 2層への重み 1層での バイアス 2層の出⼒ 活性化関数 2層の⼊⼒ 45
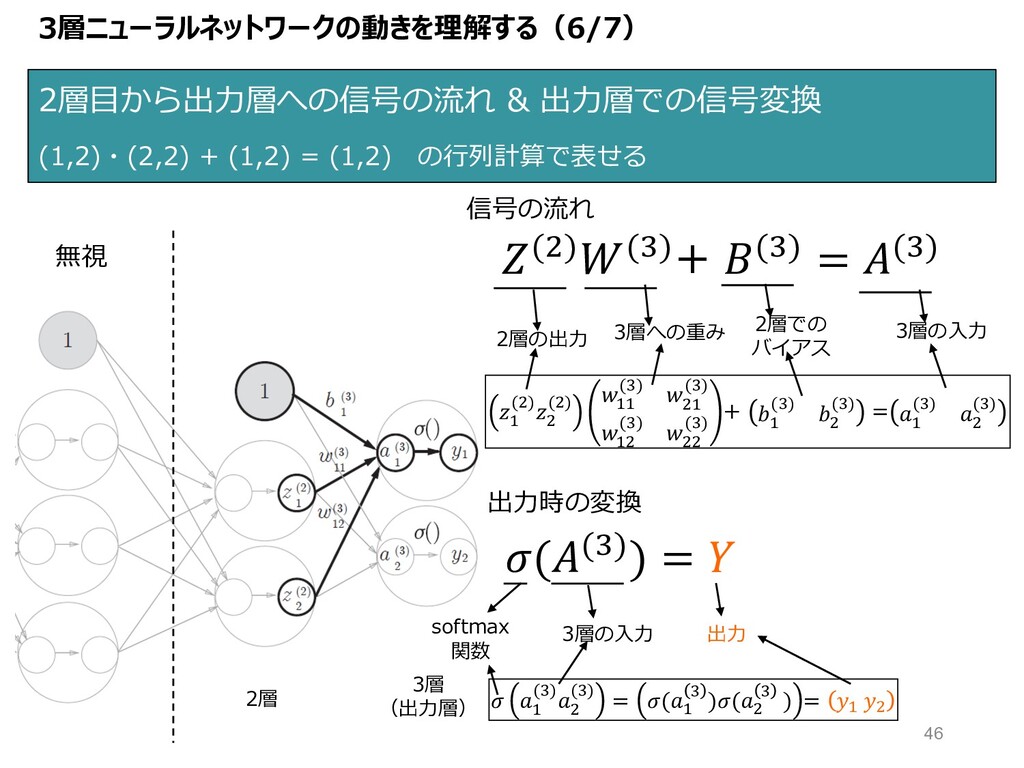
3層ニューラルネットワークの動きを理解する(6/7) 2層⽬から出⼒層への信号の流れ & 出⼒層での信号変換 (1,2)・(2,2) + (1,2) = (1,2) の⾏列計算で表せる
無視 2層 3層 (出⼒層) ($)(B)+ (B) = (B) 信号の流れ " ($)$ ($) "" (B) $" (B) "$ (B) $$ (B) + " (B) $ (B) = " (B) $ (B) 出⼒時の変換 ((B)) = " (B)$ (B) = (" B )($ B ) = " $ 2層の出⼒ 3層への重み 3層の⼊⼒ 2層での バイアス softmax 関数 3層の⼊⼒ 出⼒ 46
3層ニューラルネットワークの動きを理解する(7/7) ここまでが理解できれば、 推論はマスターできたと⾔って良いと思います。 https://ml4a.github.io/demos/simple_forward_pass/ 推論の流れを理解するのに便利なサイト 47
最後に、ニューラルネットワーク構成時の注意点 48
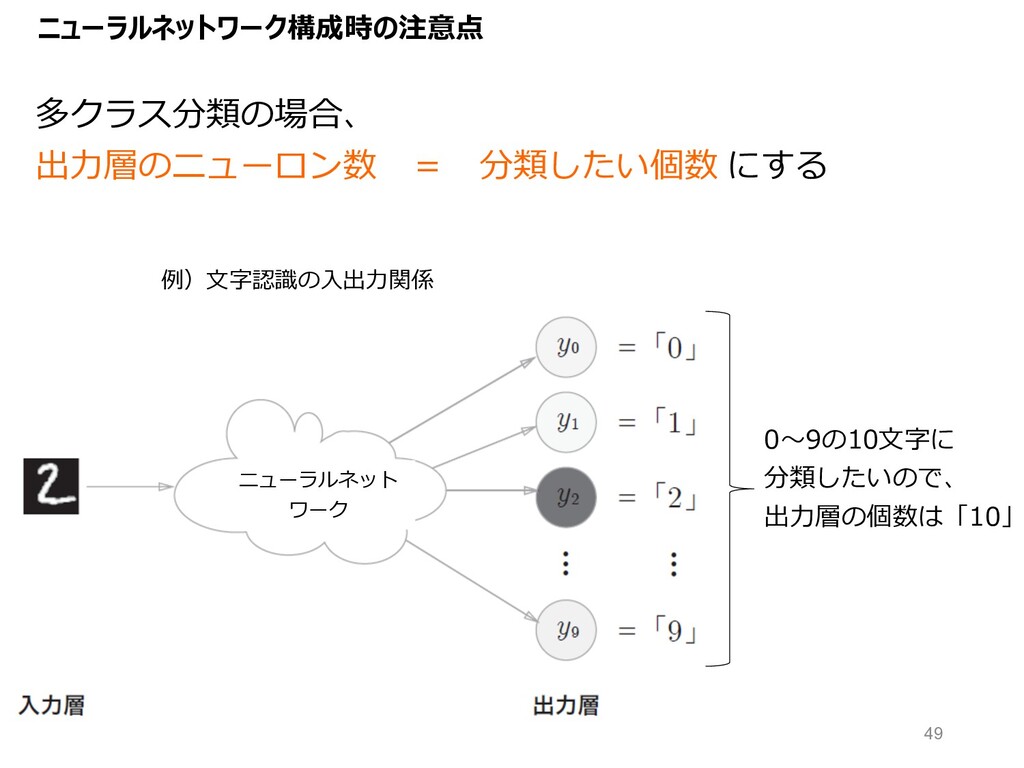
ニューラルネットワーク構成時の注意点 例)⽂字認識の⼊出⼒関係 0〜9の10⽂字に 分類したいので、 出⼒層の個数は「10」 多クラス分類の場合、 出⼒層のニューロン数 = 分類したい個数 にする
ニューラルネット ワーク 49
第1回発表のまとめ 50
第1回発表のまとめ • ディープラーニングの動作には「学習」と「推論」がある • 推論動作 = 「⾏列の積と和」 • 多層化することで⾮線形問題に対応(≒活性化関数の導⼊) 51
第2回発表の構想 52
第2回発表の構想 1. 損失関数の導⼊ 2乗和誤差、交差エントロピー誤差 2. 微分の復習 数値微分、偏微分 3. 勾配法による学習 4.
勾配法の実装 ディープラーニングの本丸「誤差逆伝播法」への導⼊として、 勾配法を使った学習を説明する。 53
Appendix 54
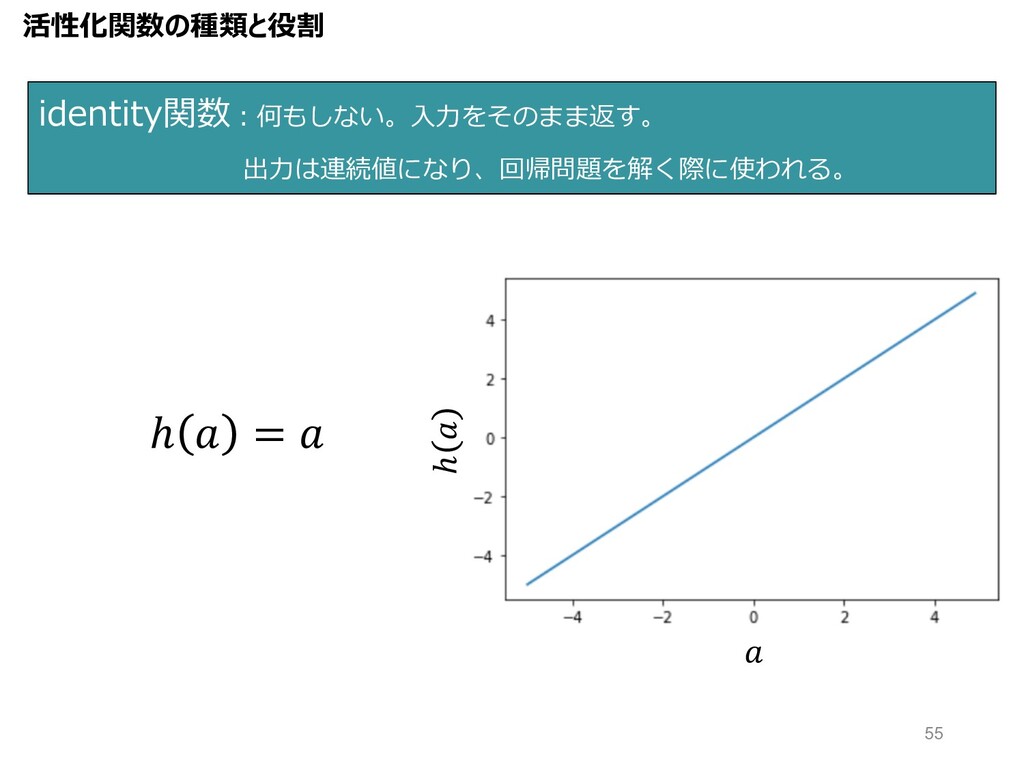
identity関数︓何もしない。⼊⼒をそのまま返す。 出⼒は連続値になり、回帰問題を解く際に使われる。 ℎ = ℎ 活性化関数の種類と役割 55
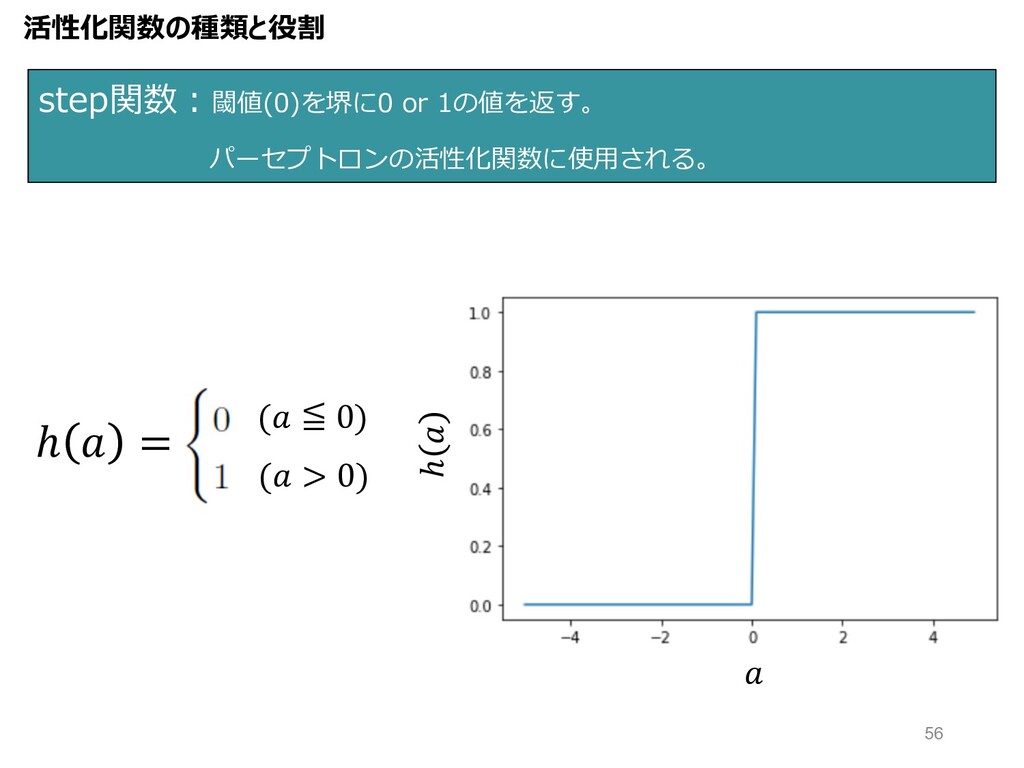
step関数︓閾値(0)を堺に0 or 1の値を返す。 パーセプトロンの活性化関数に使⽤される。 ℎ = ( > 0) (
≦ 0) ℎ 活性化関数の種類と役割 56
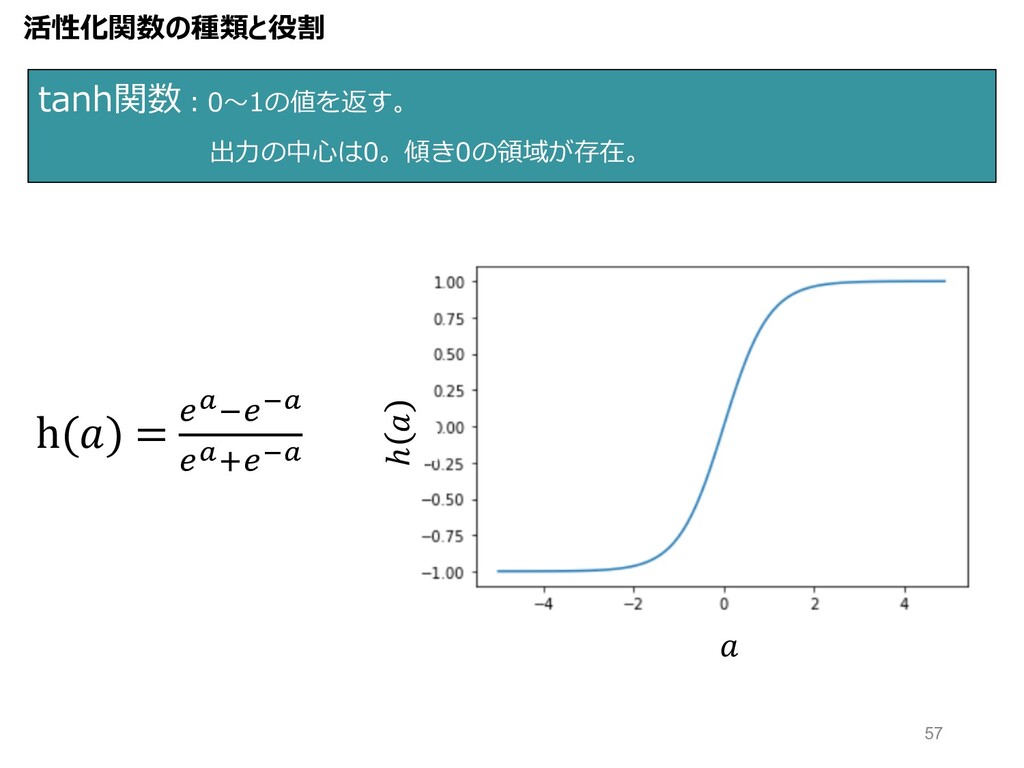
tanh関数︓0〜1の値を返す。 出⼒の中⼼は0。傾き0の領域が存在。 活性化関数の種類と役割 h() = OQ7OPQ OQ:OPQ ℎ 57
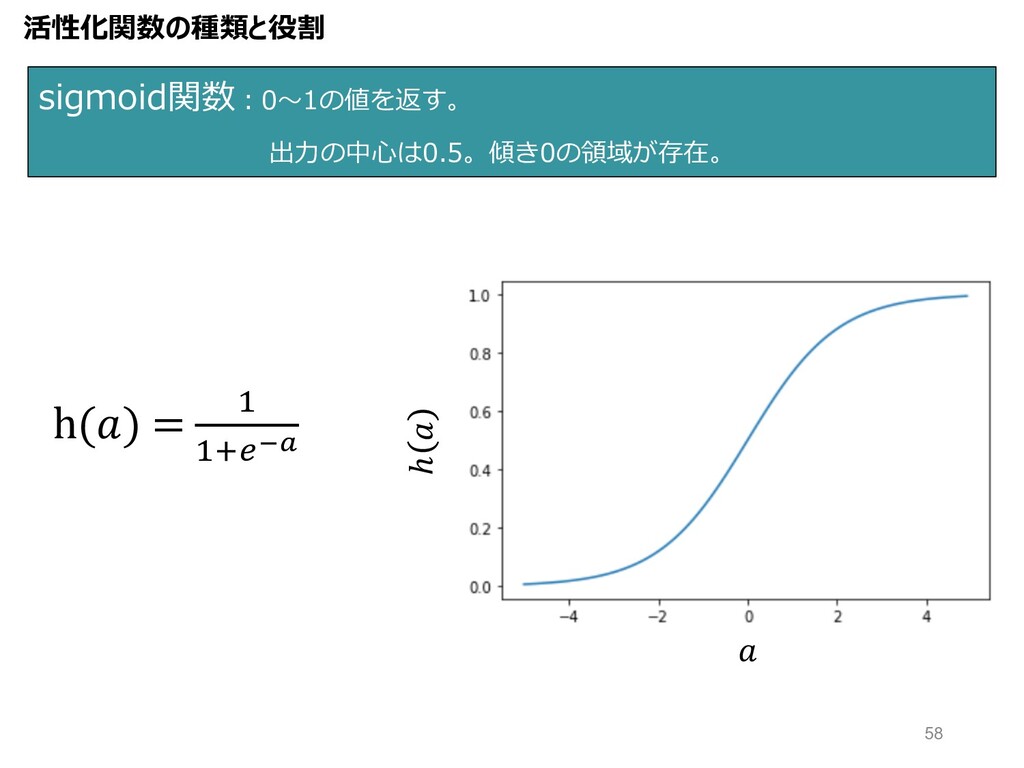
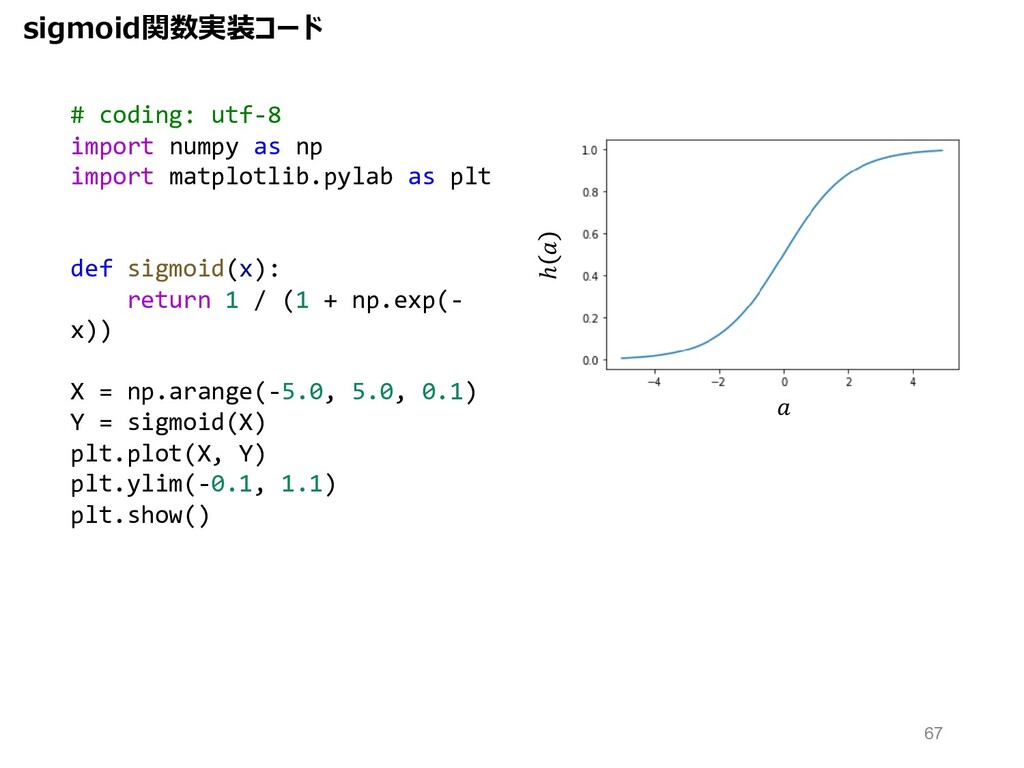
sigmoid関数︓0〜1の値を返す。 出⼒の中⼼は0.5。傾き0の領域が存在。 h() = " ":OPQ ℎ 活性化関数の種類と役割 58
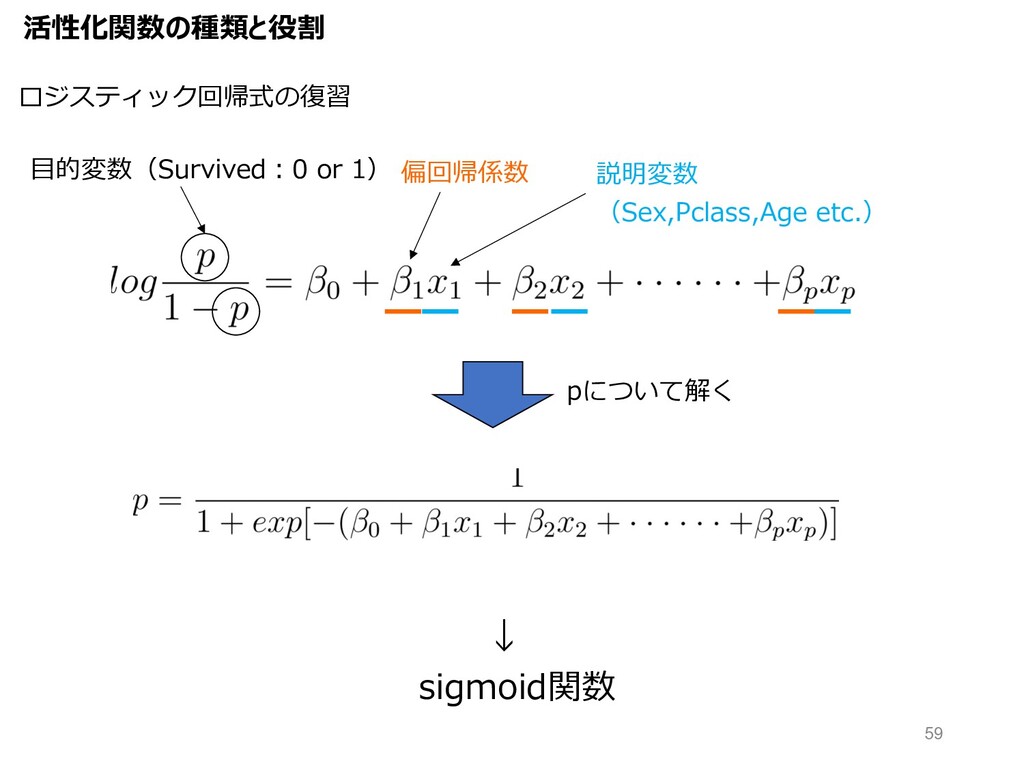
活性化関数の種類と役割 偏回帰係数 ロジスティック回帰式の復習 pについて解く ⽬的変数(Survived︓0 or 1) 説明変数 (Sex,Pclass,Age etc.)
↓ sigmoid関数 59
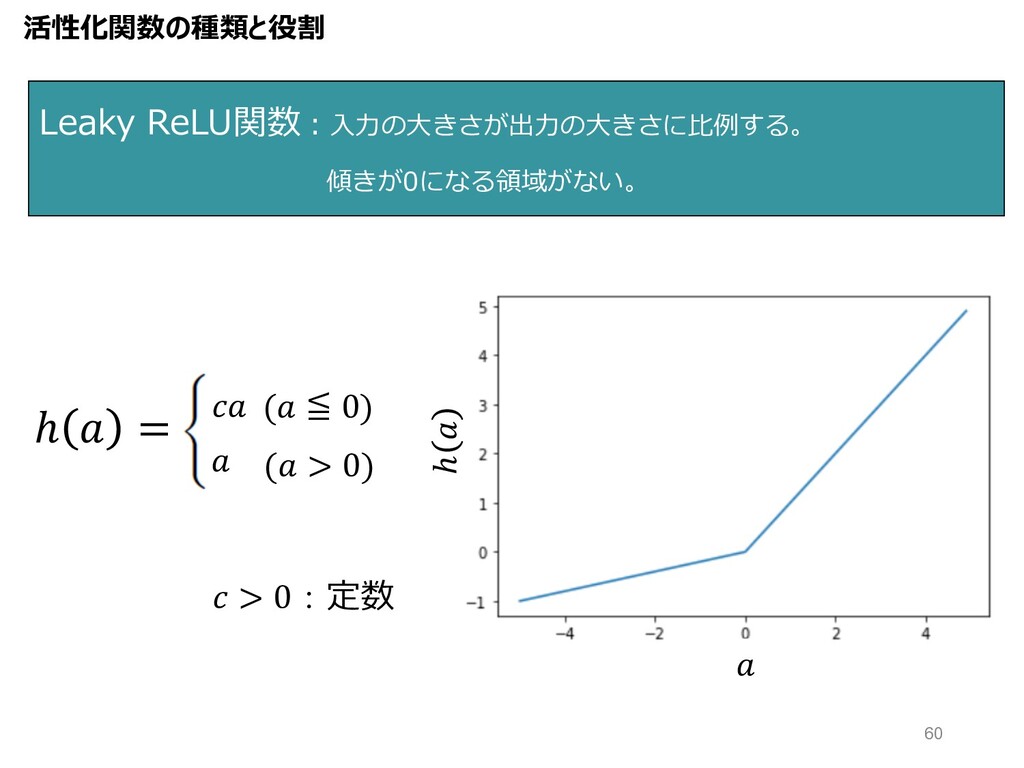
Leaky ReLU関数︓⼊⼒の⼤きさが出⼒の⼤きさに⽐例する。 傾きが0になる領域がない。 ℎ ℎ = ( > 0) (
≦ 0) > 0:定数 活性化関数の種類と役割 60
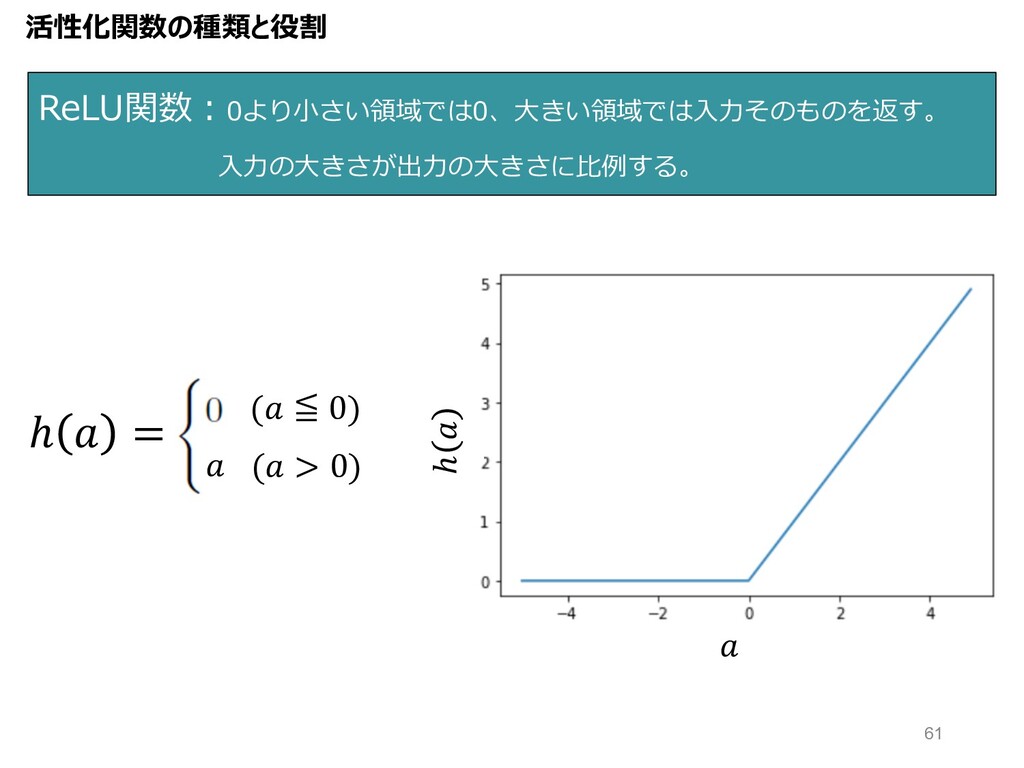
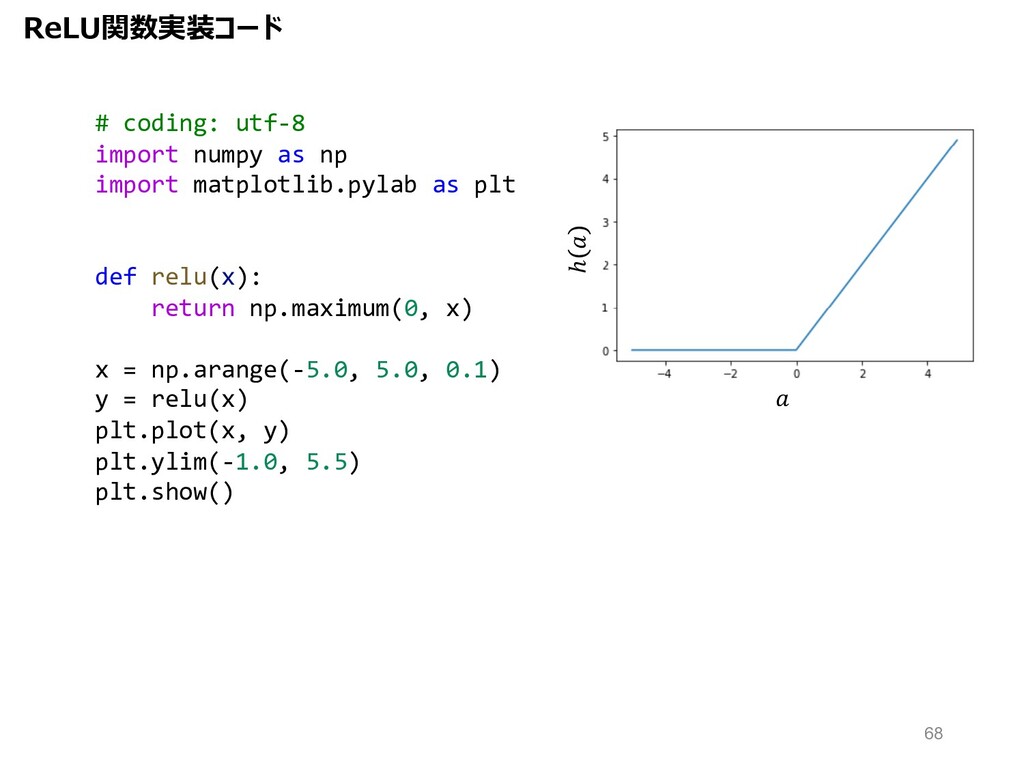
ReLU関数︓0より⼩さい領域では0、⼤きい領域では⼊⼒そのものを返す。 ⼊⼒の⼤きさが出⼒の⼤きさに⽐例する。 活性化関数の種類と役割 ℎ = ( > 0) ( ≦
0) ℎ 61
ANDゲート実装コード # coding: utf-8 import numpy as np def AND(x1,
x2): x = np.array([x1, x2]) #入力 w = np.array([0.5, 0.5]) #重み b = -0.7 #バイアス tmp = np.sum(w*x) + b if tmp <= 0: return 0 else: return 1 if __name__ == '__main__': for xs in [(0, 0), (1, 0), (0, 1), (1, 1)]: y = AND(xs[0], xs[1]) print(str(xs) + " -> " + str(y)) 62
ORゲート実装コード # coding: utf-8 import numpy as np def OR(x1,
x2): x = np.array([x1, x2]) #入力 w = np.array([0.5, 0.5]) #重み b = -0.2 #バイアス tmp = np.sum(w*x) + b if tmp <= 0: return 0 else: return 1 if __name__ == '__main__': for xs in [(0, 0), (1, 0), (0, 1), (1, 1)]: y = OR(xs[0], xs[1]) print(str(xs) + " -> " + str(y)) 63
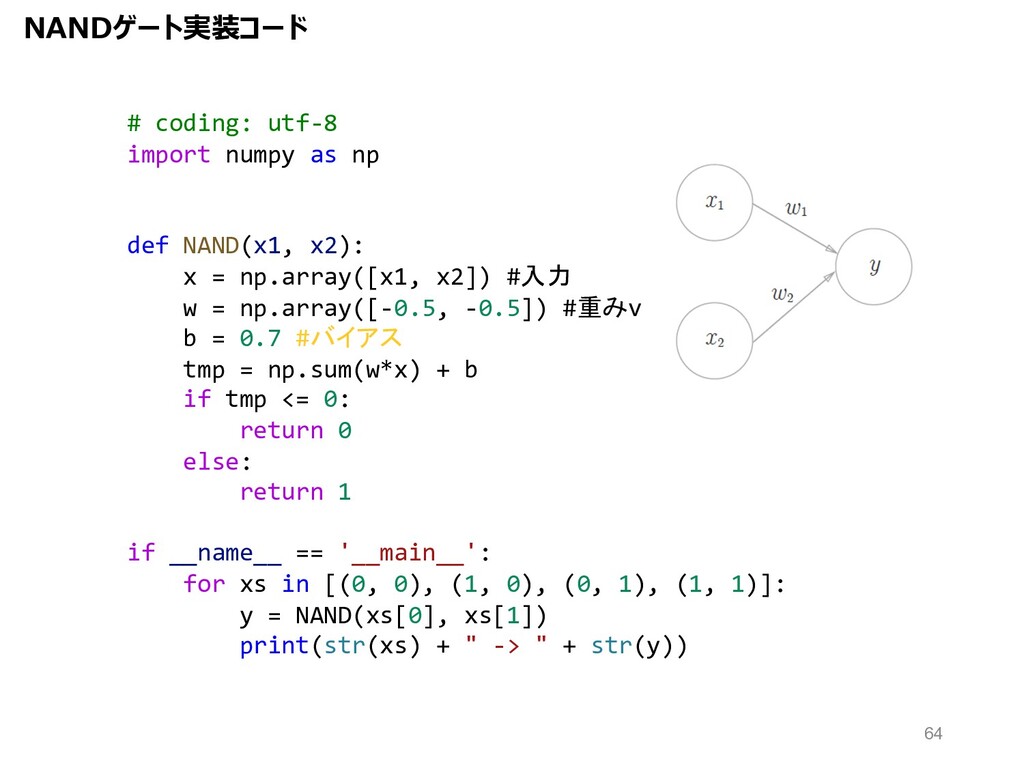
NANDゲート実装コード # coding: utf-8 import numpy as np def NAND(x1,
x2): x = np.array([x1, x2]) #入力 w = np.array([-0.5, -0.5]) #重みv b = 0.7 #バイアス tmp = np.sum(w*x) + b if tmp <= 0: return 0 else: return 1 if __name__ == '__main__': for xs in [(0, 0), (1, 0), (0, 1), (1, 1)]: y = NAND(xs[0], xs[1]) print(str(xs) + " -> " + str(y)) 64
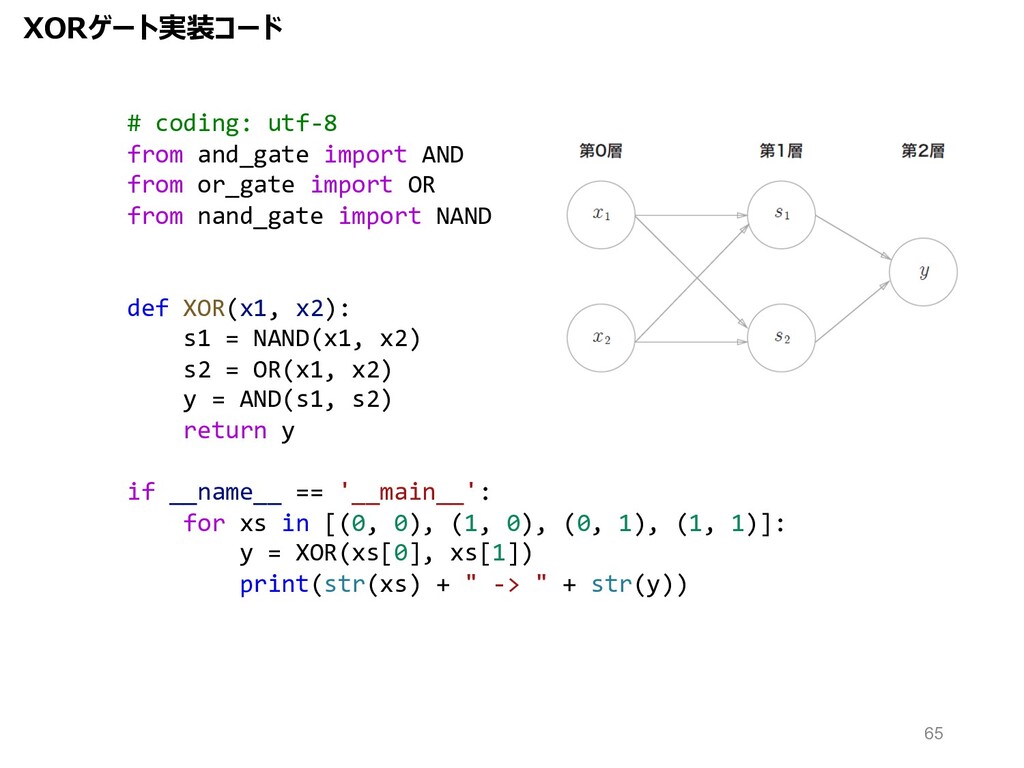
XORゲート実装コード # coding: utf-8 from and_gate import AND from or_gate
import OR from nand_gate import NAND def XOR(x1, x2): s1 = NAND(x1, x2) s2 = OR(x1, x2) y = AND(s1, s2) return y if __name__ == '__main__': for xs in [(0, 0), (1, 0), (0, 1), (1, 1)]: y = XOR(xs[0], xs[1]) print(str(xs) + " -> " + str(y)) 65
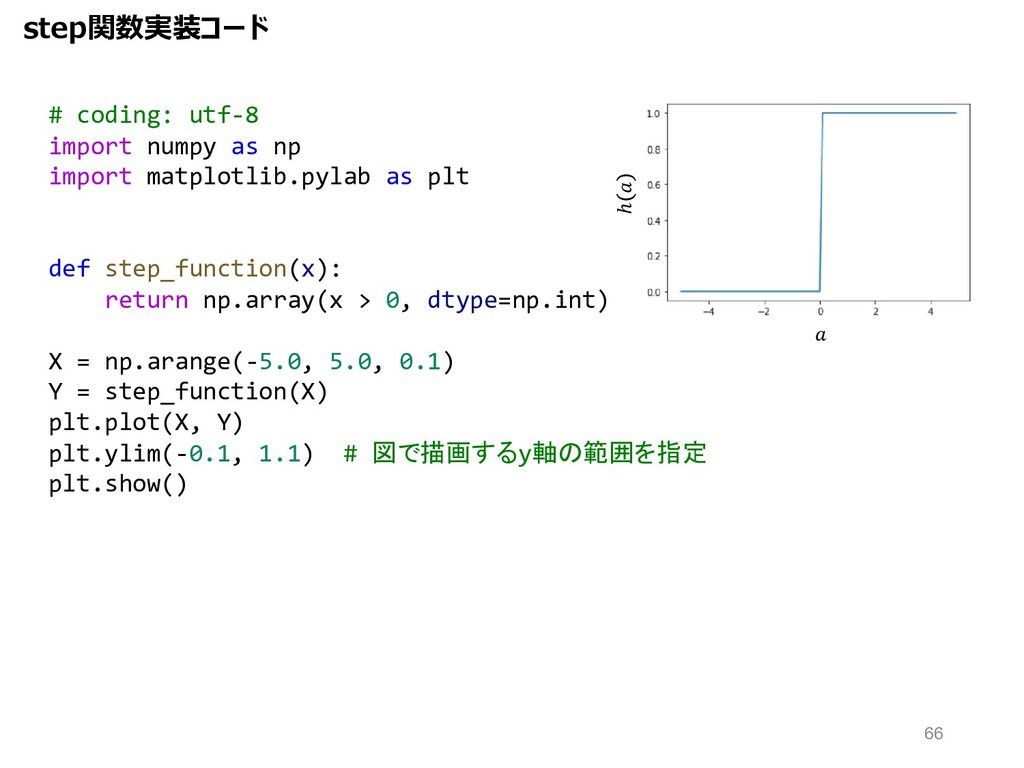
# coding: utf-8 import numpy as np import matplotlib.pylab as
plt def step_function(x): return np.array(x > 0, dtype=np.int) X = np.arange(-5.0, 5.0, 0.1) Y = step_function(X) plt.plot(X, Y) plt.ylim(-0.1, 1.1) # 図で描画するy軸の範囲を指定 plt.show() step関数実装コード ℎ 66
# coding: utf-8 import numpy as np import matplotlib.pylab as
plt def sigmoid(x): return 1 / (1 + np.exp(- x)) X = np.arange(-5.0, 5.0, 0.1) Y = sigmoid(X) plt.plot(X, Y) plt.ylim(-0.1, 1.1) plt.show() sigmoid関数実装コード ℎ 67
# coding: utf-8 import numpy as np import matplotlib.pylab as
plt def relu(x): return np.maximum(0, x) x = np.arange(-5.0, 5.0, 0.1) y = relu(x) plt.plot(x, y) plt.ylim(-1.0, 5.5) plt.show() ℎ ReLU関数実装コード 68
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}