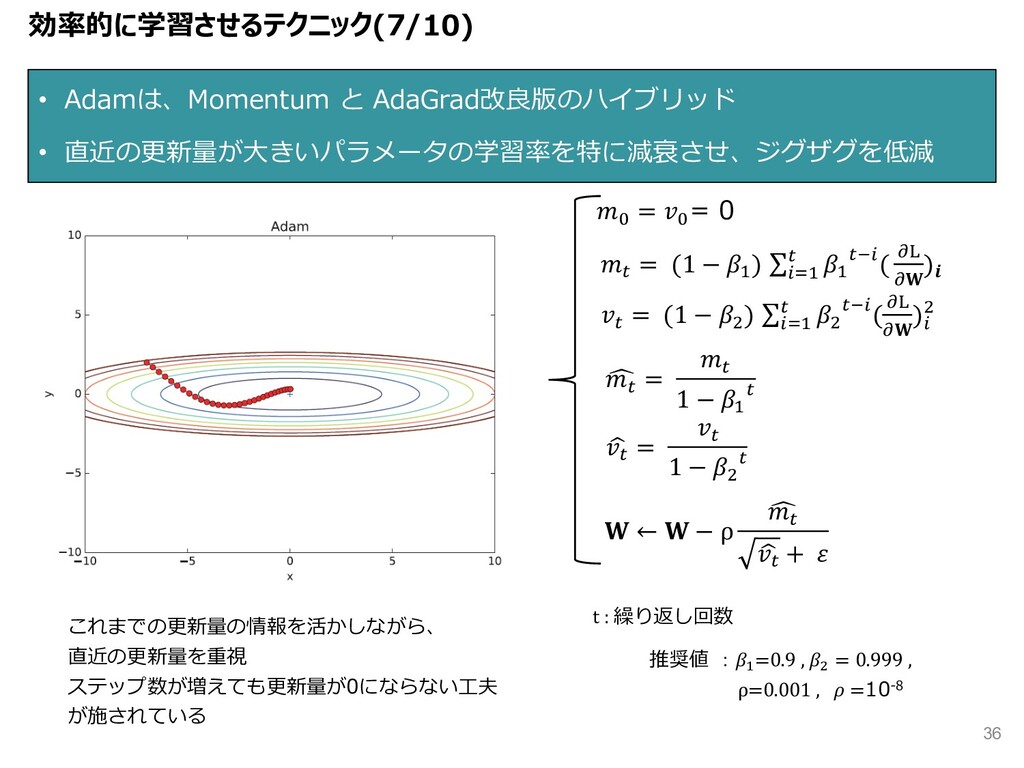
0 s = (1 − 8 ) ∑:-8 s 8 st:( bc b ) v s = s 1 − 8 s Z s = s 1 − V s ← − ρ v s Z s + 推奨値 :8 =0.9 , V = 0.999 , ρ=0.001 , =10-8 t : 繰り返し回数 s = (1 − V ) ∑:-8 s V st:(bc b ): V これまでの更新量の情報を活かしながら、 直近の更新量を重視 ステップ数が増えても更新量が0にならない⼯夫 が施されている 効率的に学習させるテクニック(7/10) 36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
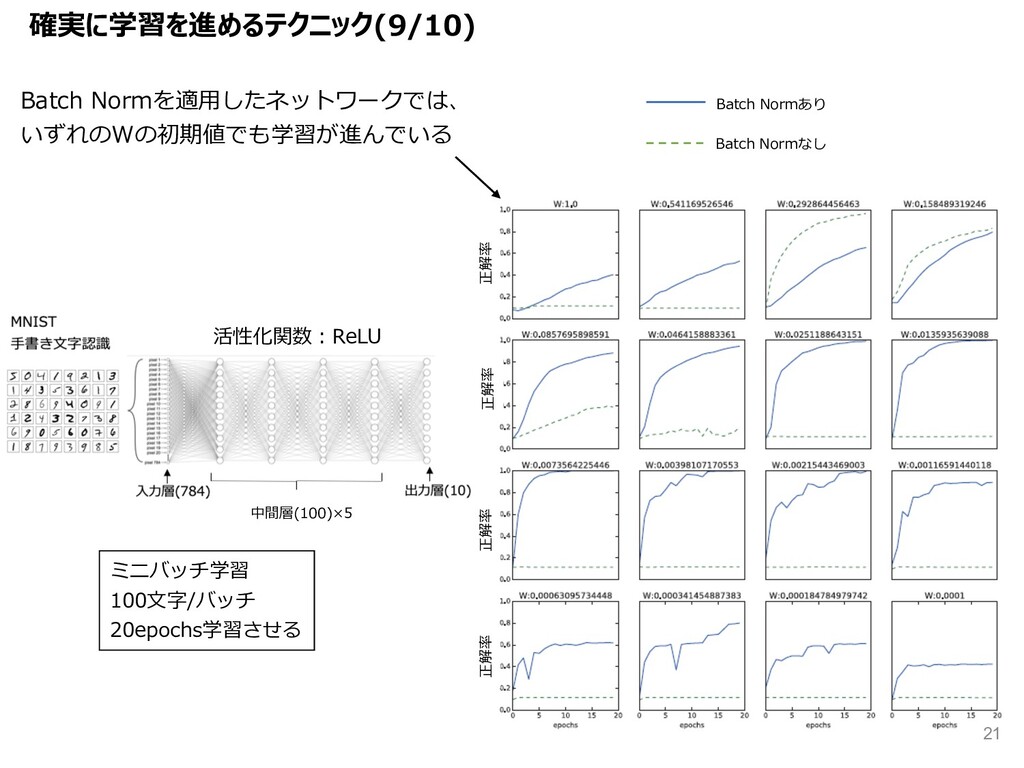{kind=link}
{kind=link}
{kind=link}
{kind=link}
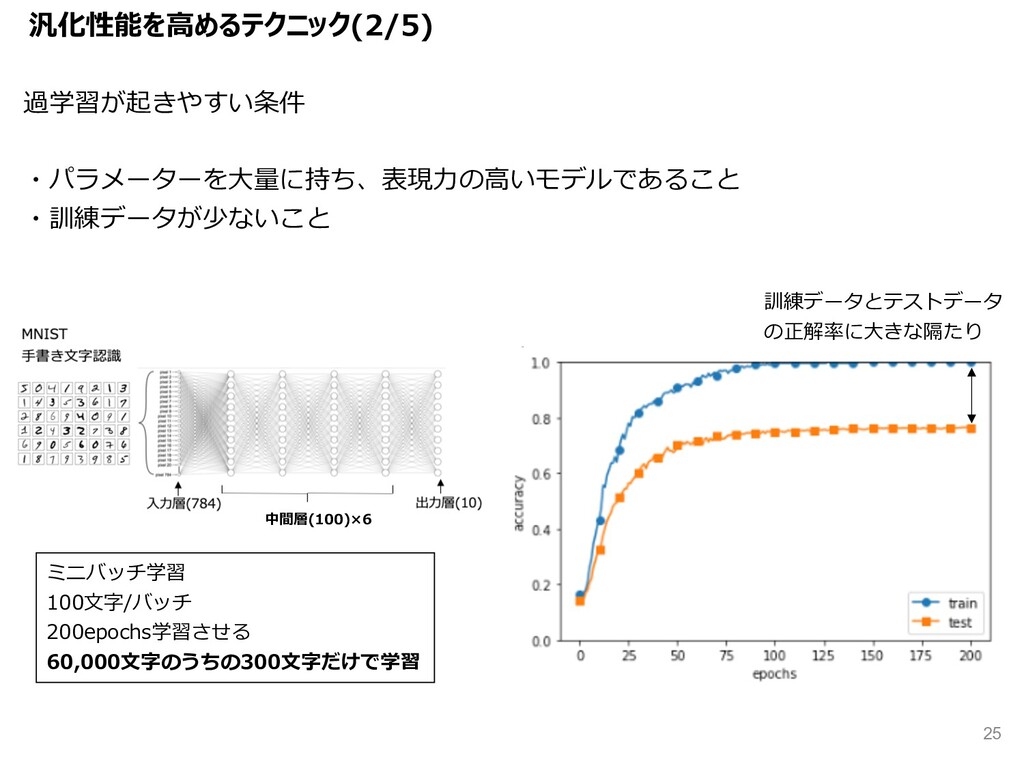{kind=link}
{kind=link}
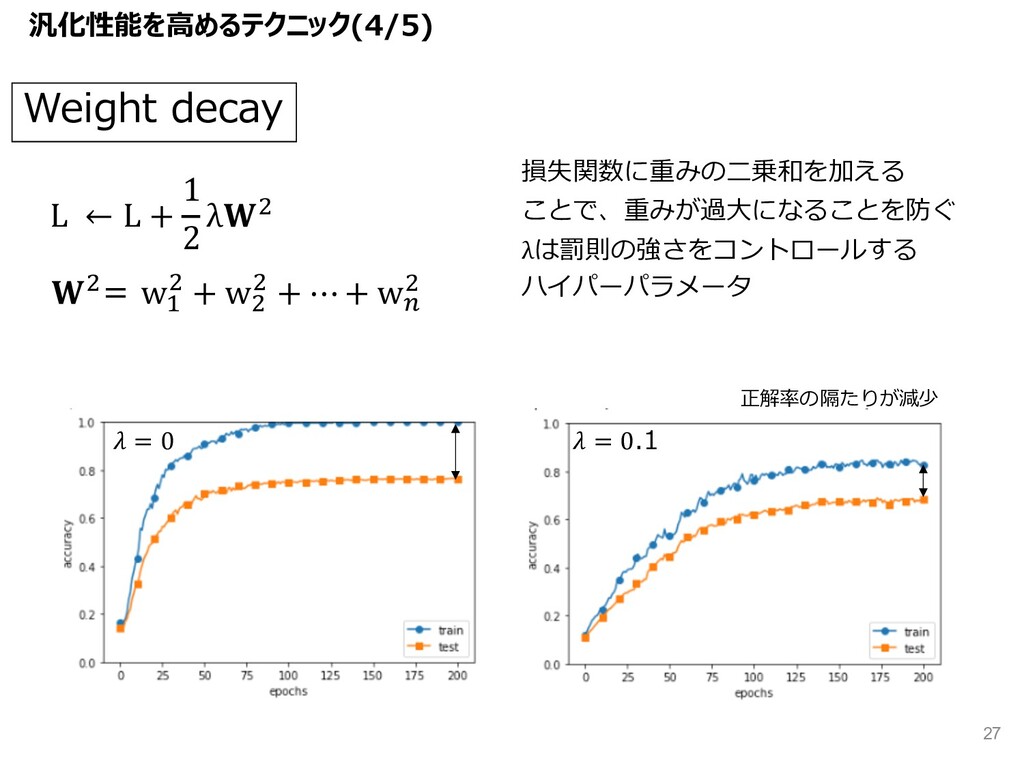{kind=link}
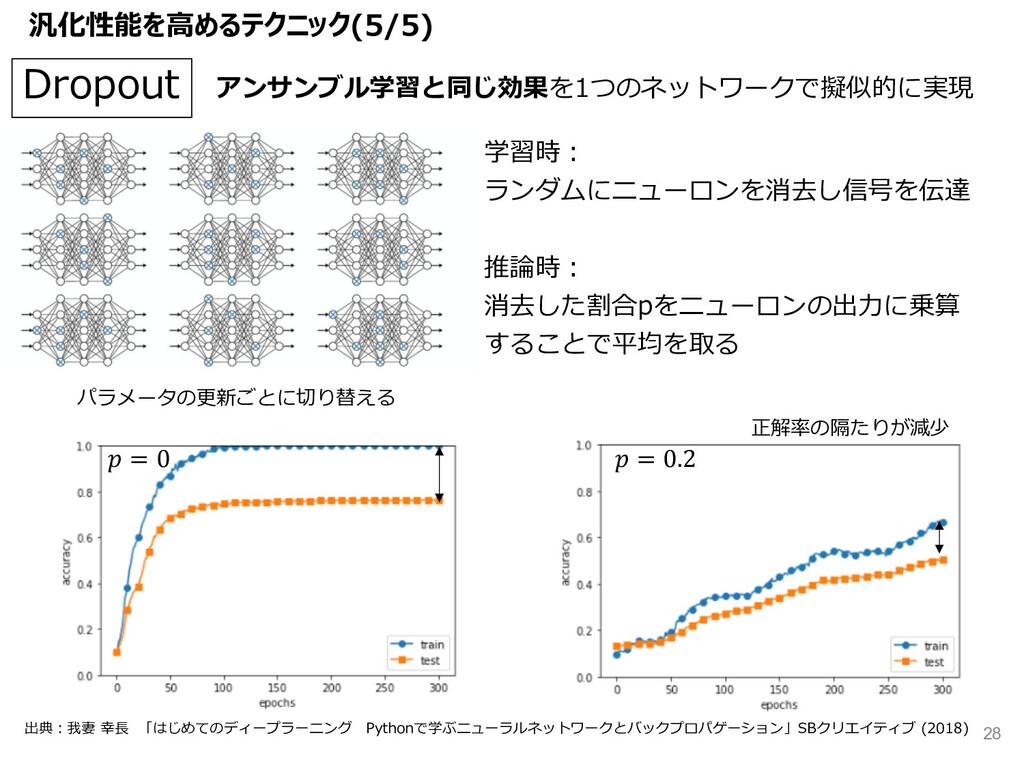{kind=link}
{kind=link}
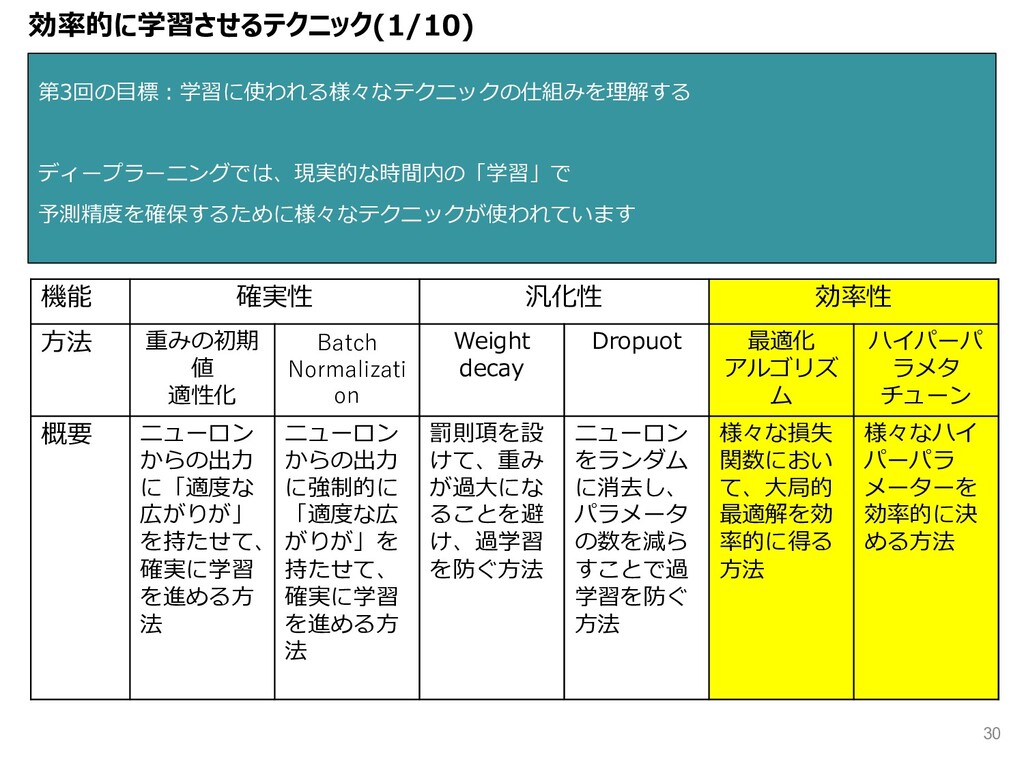{kind=link}
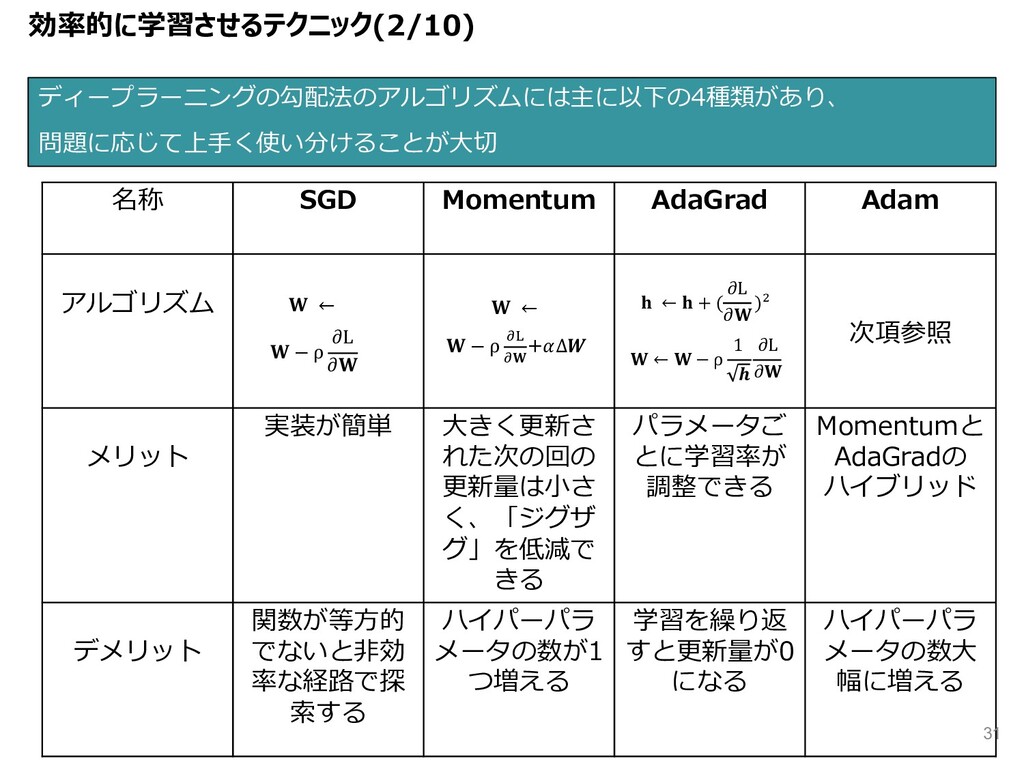{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}