• Generative Modelling is learning models of the form , given a dataset pθ (X) {X}D i=1 ∼ qdata (X) De f inition, Motiv a tion & Scope … (1) • Motivation 1: Veri fi cation (log-likelihood) • Motivation 2: Generation by sampling, i.e. • Motivation 3: Conditional models of the form Xnew ∼ pθ* (X) pθ (X|Y)
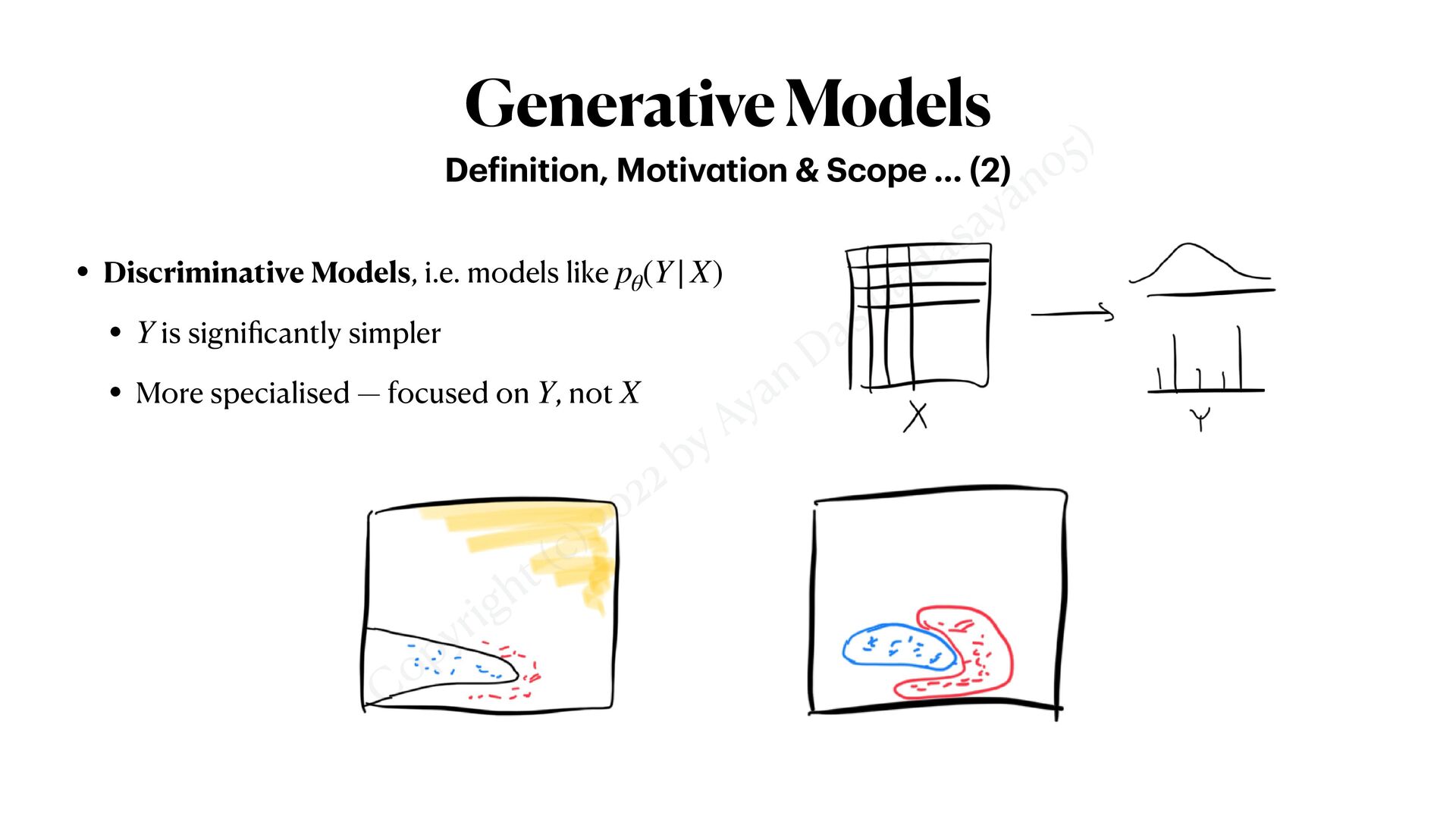
De f inition, Motiv a tion & Scope … (2) • Discriminative Models, i.e. models like • is signi fi cantly simpler • More specialised — focused on , not pθ (Y|X) Y Y X
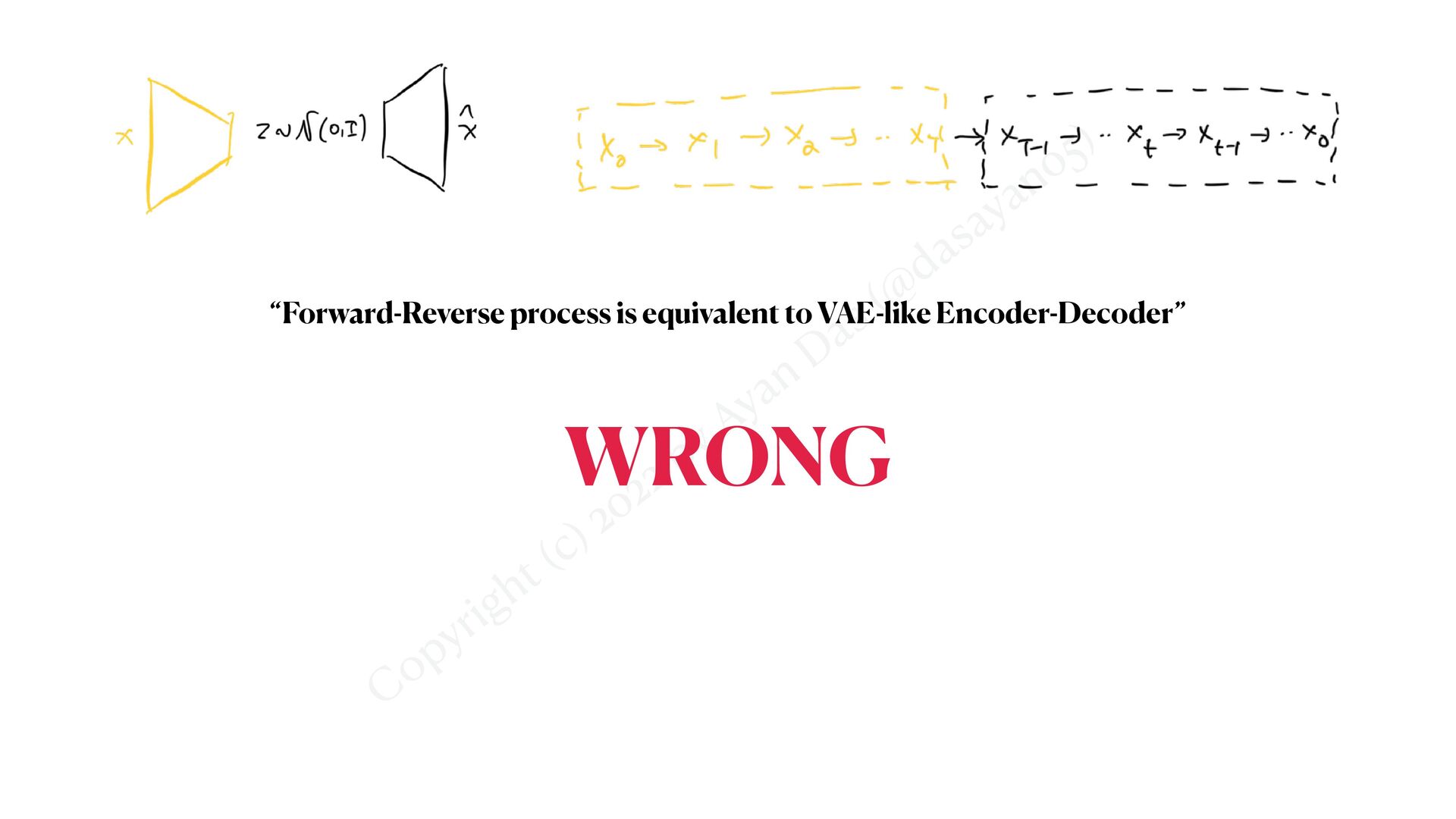
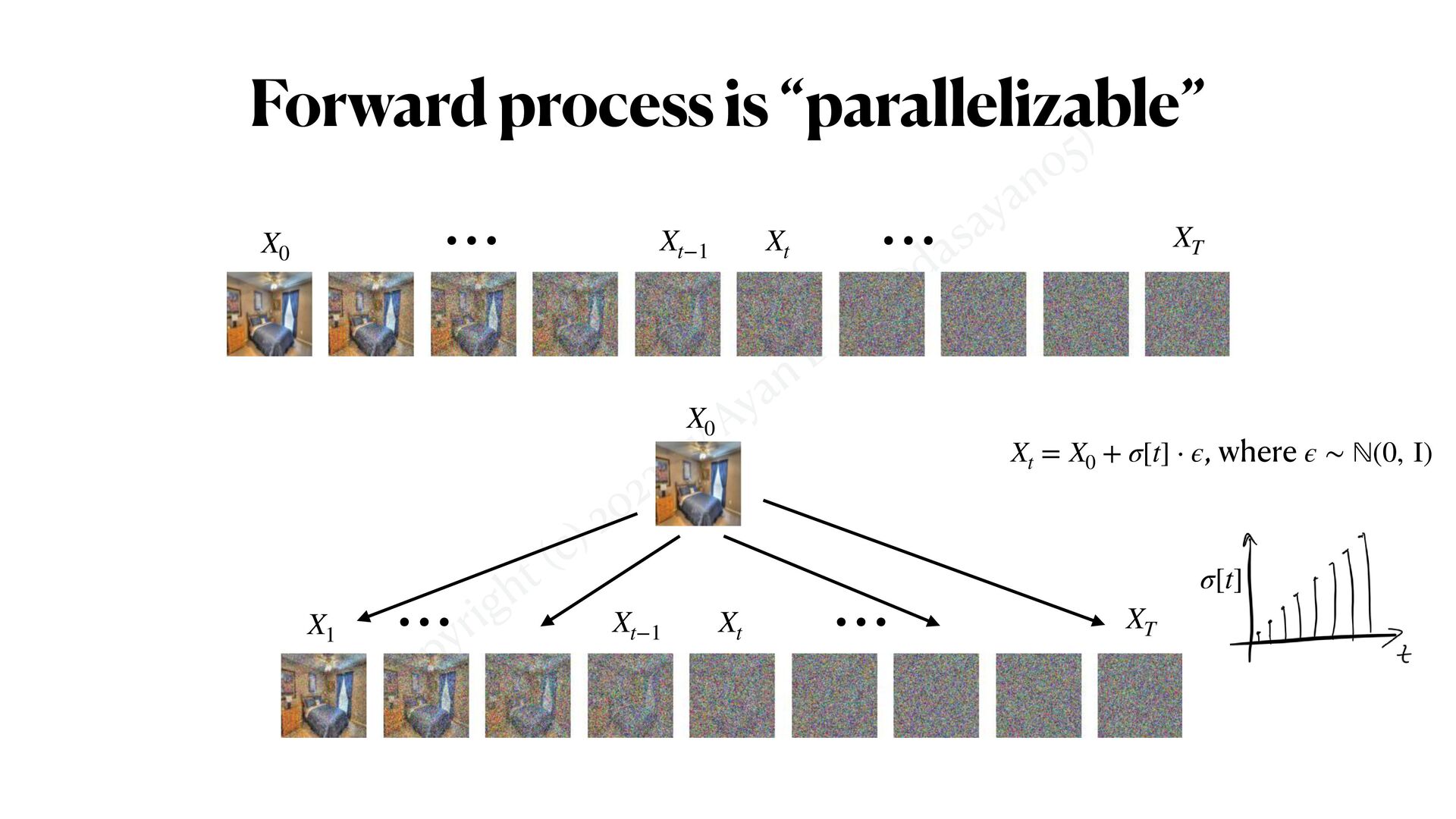
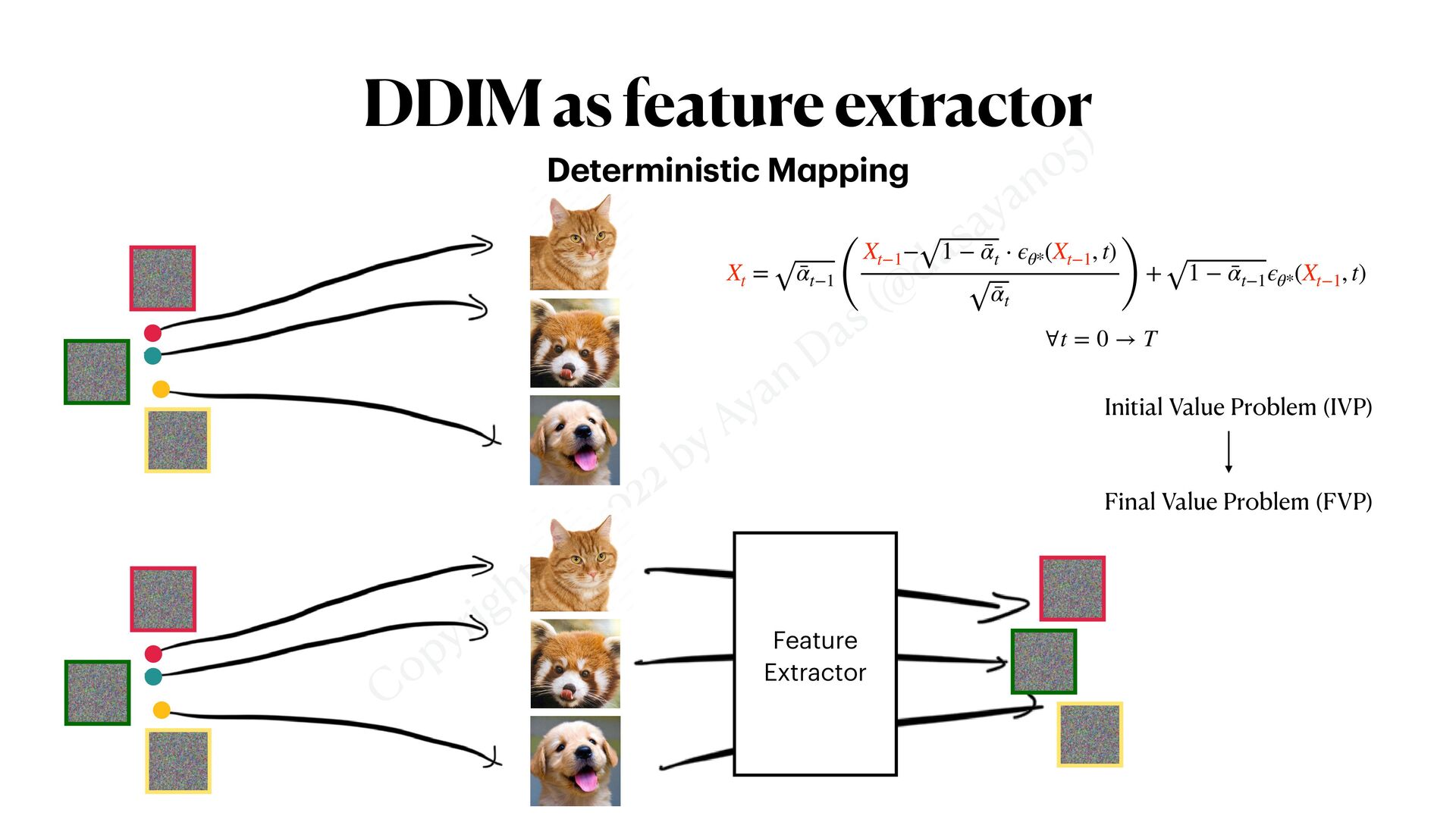
simpli f ied • Gaussian Di ff usion Model generates data by gradual gaussian de-noising • “Reverse process” is the real generative process • “Forward process” is just a way of simulating noisy training data for all t Intuitive Ide a XT Xt Xt−1 X0 ⋯ ⋯ 𝔼 X0 ∼qdata [ 1 T 1 ∑ t=T ||sθ (Xt ) − Xt−1 ||2 2 ] X0 ⋯ ⋯ Xt Xt−1 XT
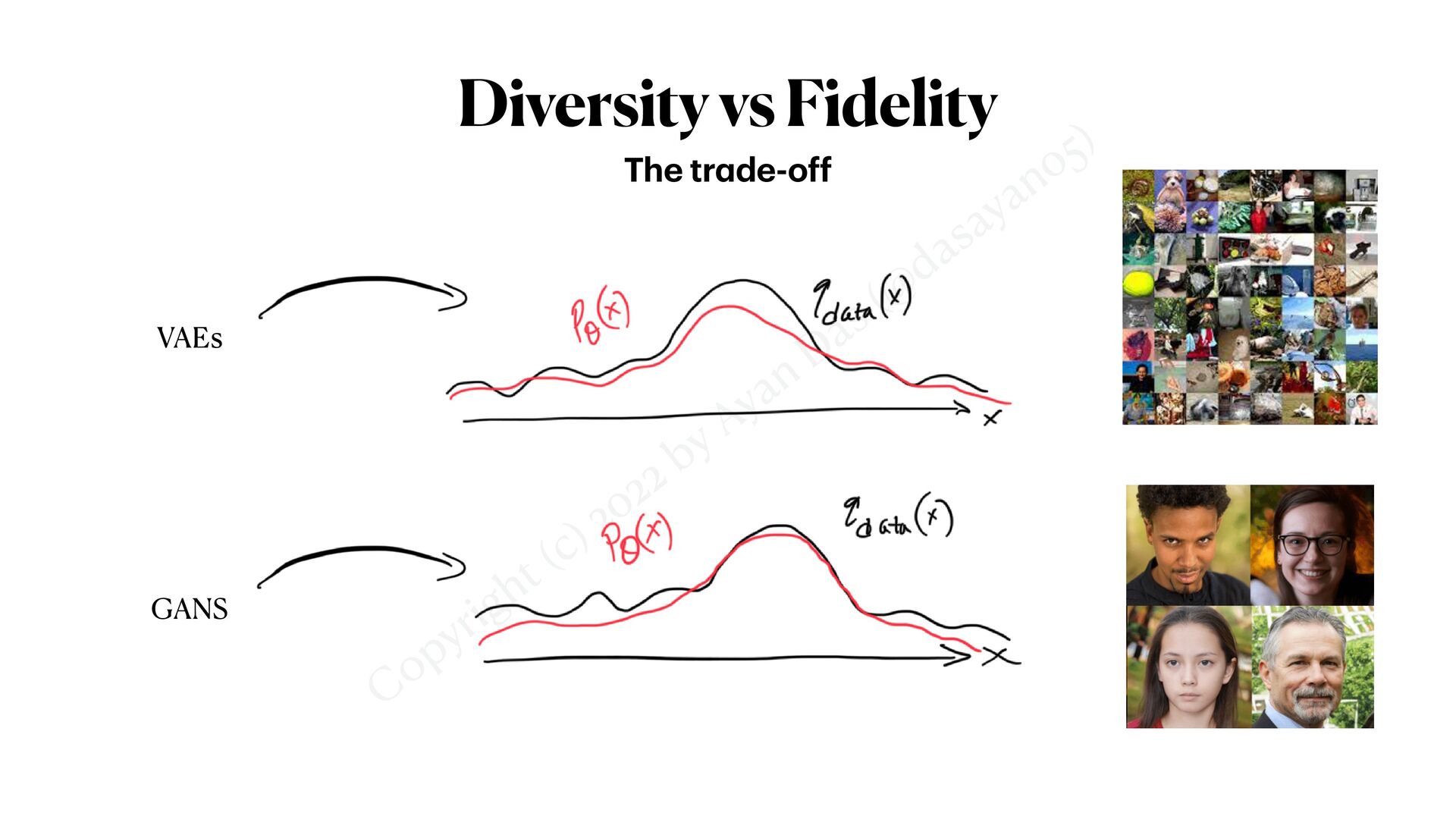
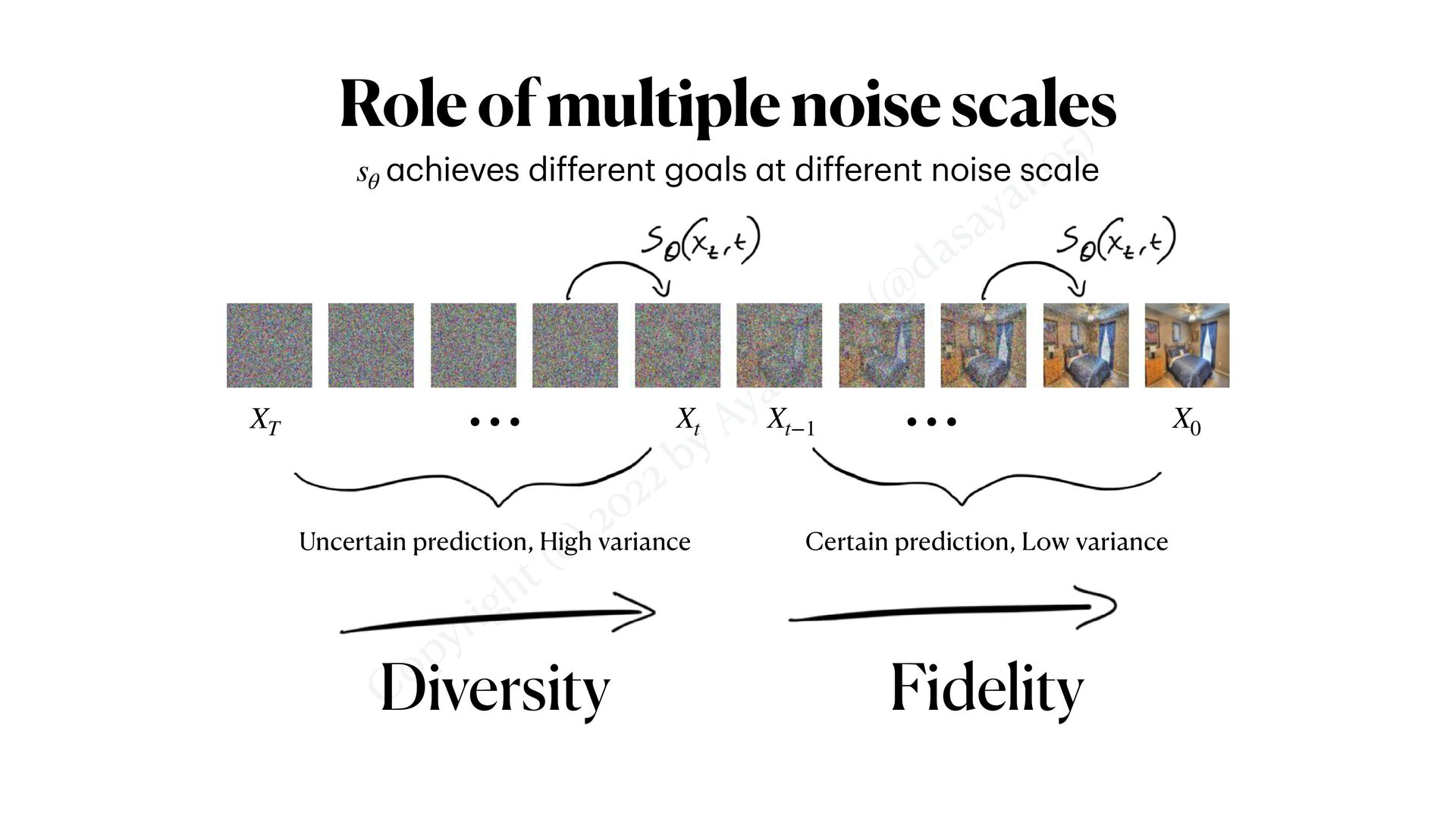
multiple noise scales a chieves different go a ls a t different noise sc a le sθ XT Xt Xt−1 X0 ⋯ ⋯ Uncertain prediction, High variance Certain prediction, Low variance Diversity Fidelity
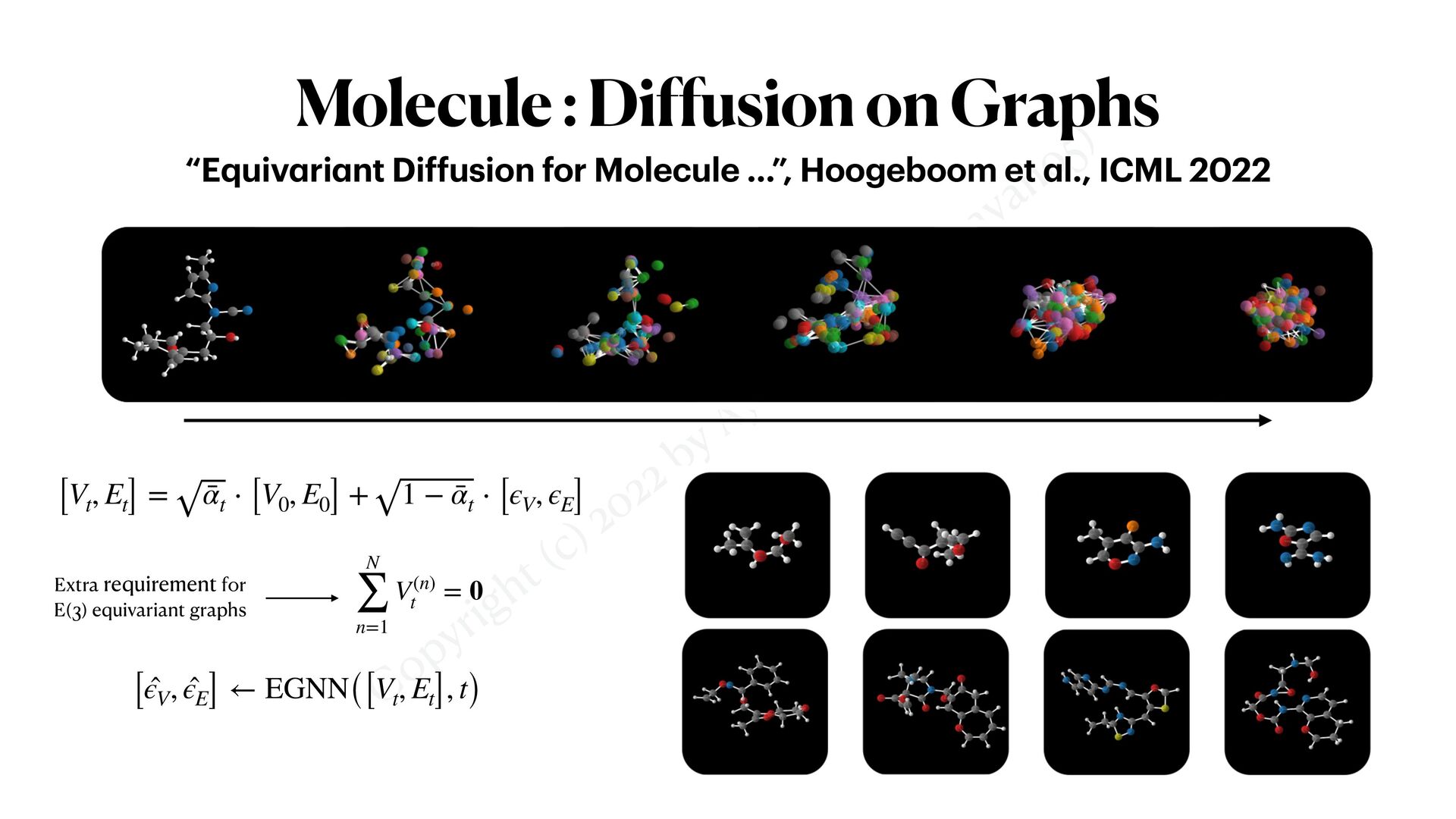
Diffusion on latent space • Embed dataset into latent space • Just as before, create di ff usion model • Decode them as • ( , ) are Auto-Encoder X0 ∼ q(X0 ) Z0 = ℰ(X0 ) ZT → ZT−1 → ⋯Z1 → Z0 X0 = 𝒟 (Z0 ) ℰ 𝒟 “High-Resolution Im a ge Synthesis with L a tent Diffusion Models”, Romb a ch et a l., CVPR 2022
an important role • Conditional models are di ff erent — they model conditions explicitly • generates cat images • generates dog images • … so on • Guidance is “in fl uencing the reverse process with condition info” • Using an external classi fi er —> “Classi fi er Guidance” • Using CLIP —> “CLIP guidance” • Using conditional model —> “Classi fi er-free Guidance” X ∼ pθ* (X|Y = CAT) X ∼ pθ* (X|Y = DOG) .. for incre a sing gener a tion qu a lity
ier Guidance • Require labels (or some conditioning info) • Train an external classi fi er — completely unrelated to the di ff usion model • Modify the unconditional noise-estimator with the classi fi er to yield a conditional noise-estimator pϕ (Y|X) Guiding the reverse process with extern a l cl a ssi f ier ̂ ϵθ*,ϕ*(Xt , t, Y) = ϵθ*(Xt , t)−λ ⋅ σ[t]∇Xt log pϕ*(Y|Xt)
• Guide reverse process with text condition • Instead of classi fi er gradient, maximise dot product of CLIP embeddings C Introduced in the “GLIDE: …” p a per from OpenAI ̂ ϵθ*,ϕ*(Xt , t, Y) = ϵθ*(Xt , t)−λ ⋅ σ[t]∇Xt log pϕ*(Y|Xt) ̂ ϵθ*,ϕ*(Xt , t, C) = ϵθ*(Xt , t)−λ ⋅ σ[t]∇Xt (ℰI (Xt ) ⋅ ℰT (C))
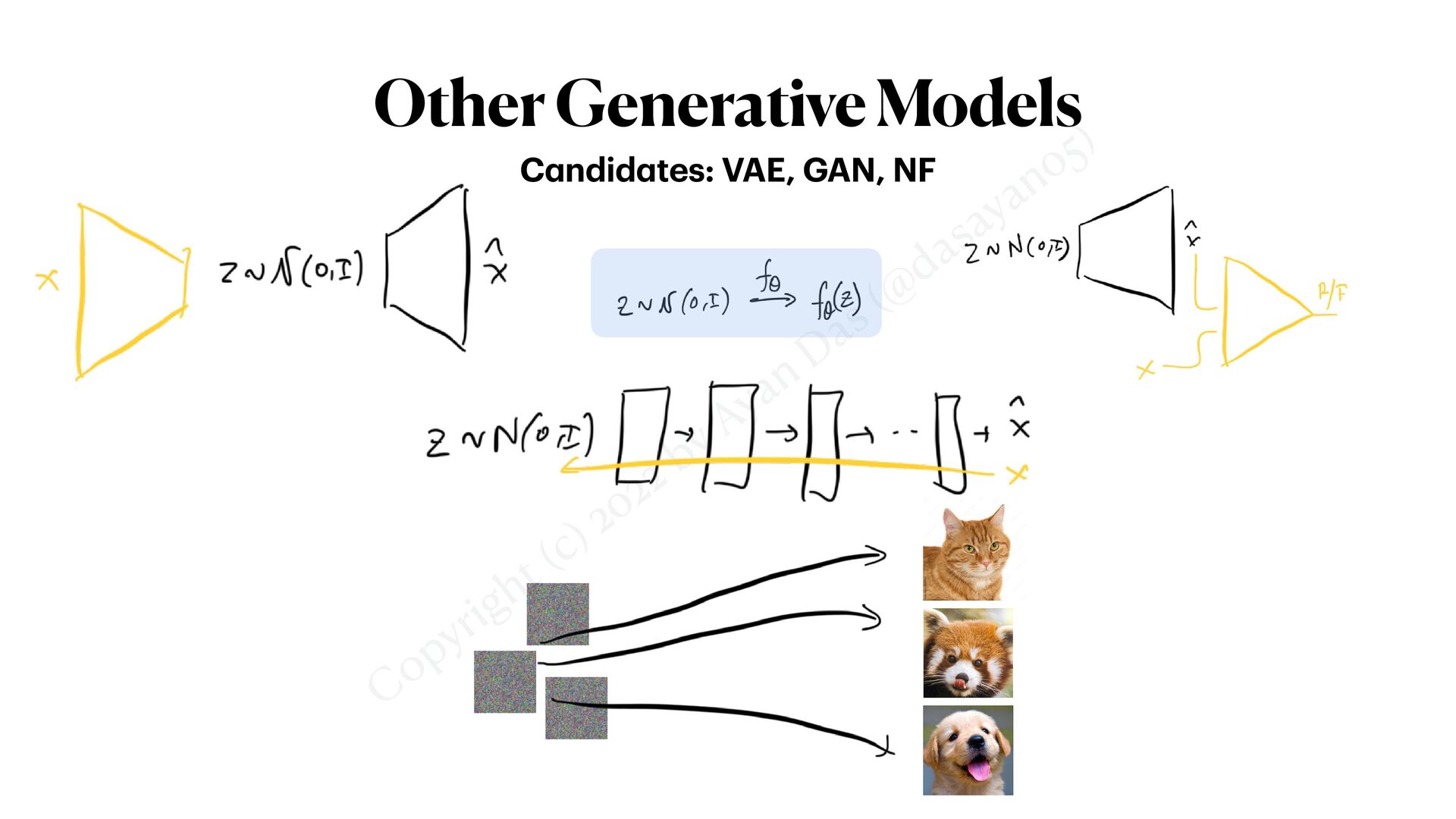
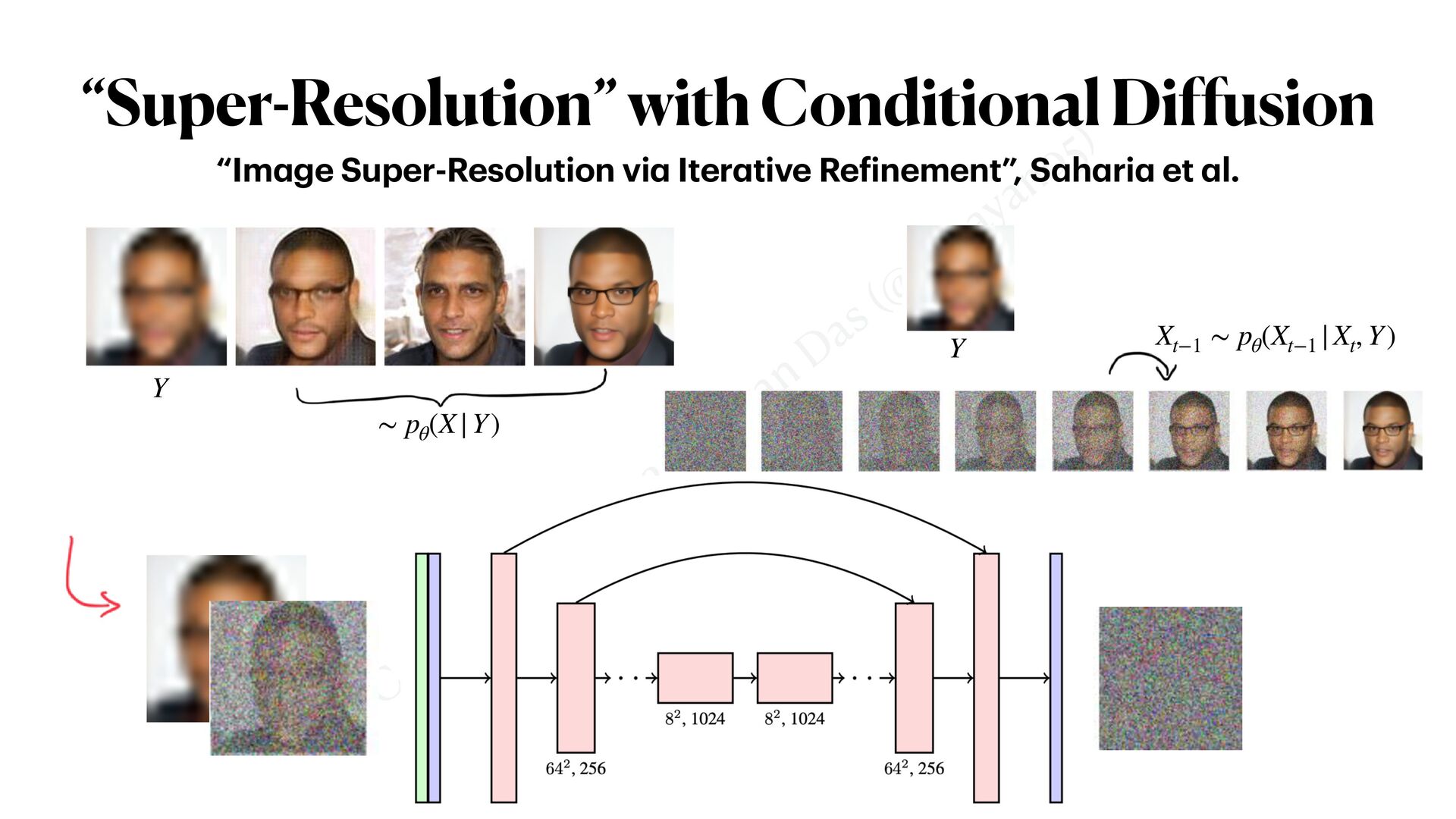
straightforward • Expose to the model, i.e. or • Encode into latent code; then or • Other clever ways too .. (next slide) • PS: The “forward di ff usion” does not change; “reverse di ff usion” has a conditional noise-estimator Y sθ (X, t, Y) ϵθ (X, t, Y) Y sθ (X, t, z = ℰ(Y)) ϵθ (X, t, z = ℰ(Y)) Just like other gener a tive models Xt−1 = 1 αt ( Xt − βt 1 − ¯ αt ⋅ ϵθ (Xt , t, Y) ) + σt ⋅ z
sampling process (1) “Iter a tive L a tent V a ri a ble Re f inement (ILVR)”, Jooyoung Choi et a l. Increasingly de-correlated samples —> Y0 Y1 Yt−1 YT Yt Xt−1 = X′  t−1 − LPFN (X′  t−1 ) + LPFN (Yt−1 ) XT Xt
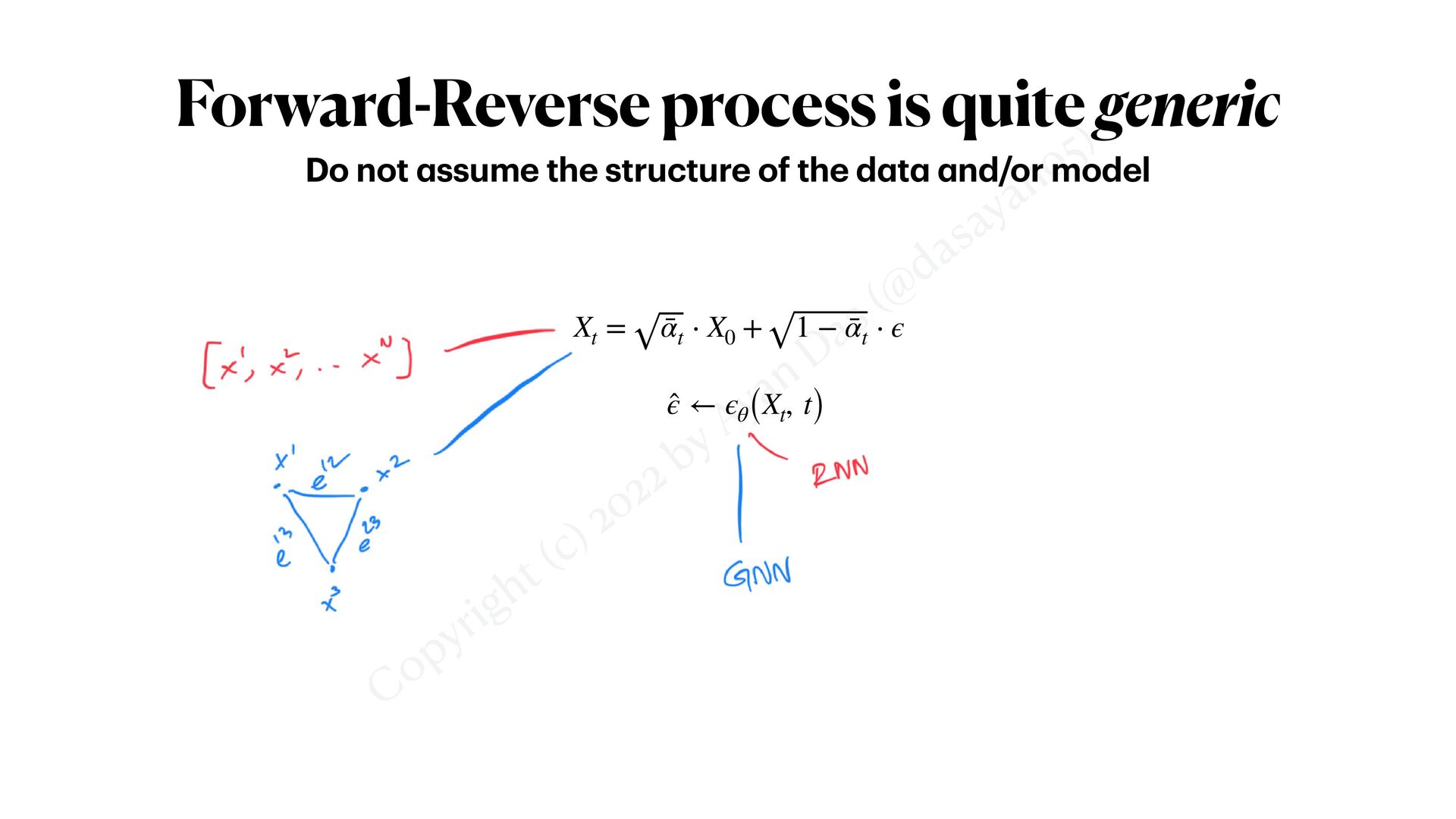
continuous sequences (1) My l a test work; <p a per under review> X0 := [x(0), x(1), ⋯, x(τ), ⋯] Xt = ¯ αt ⋅ X0 + 1 − ¯ αt ⋅ ϵ [ϵ(0) t , ϵ(1) t , ⋯, ϵ(τ) t , ⋯] ← BiRNN([X(0) t , X(1) t , ⋯, X(τ) t , ⋯], t)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}