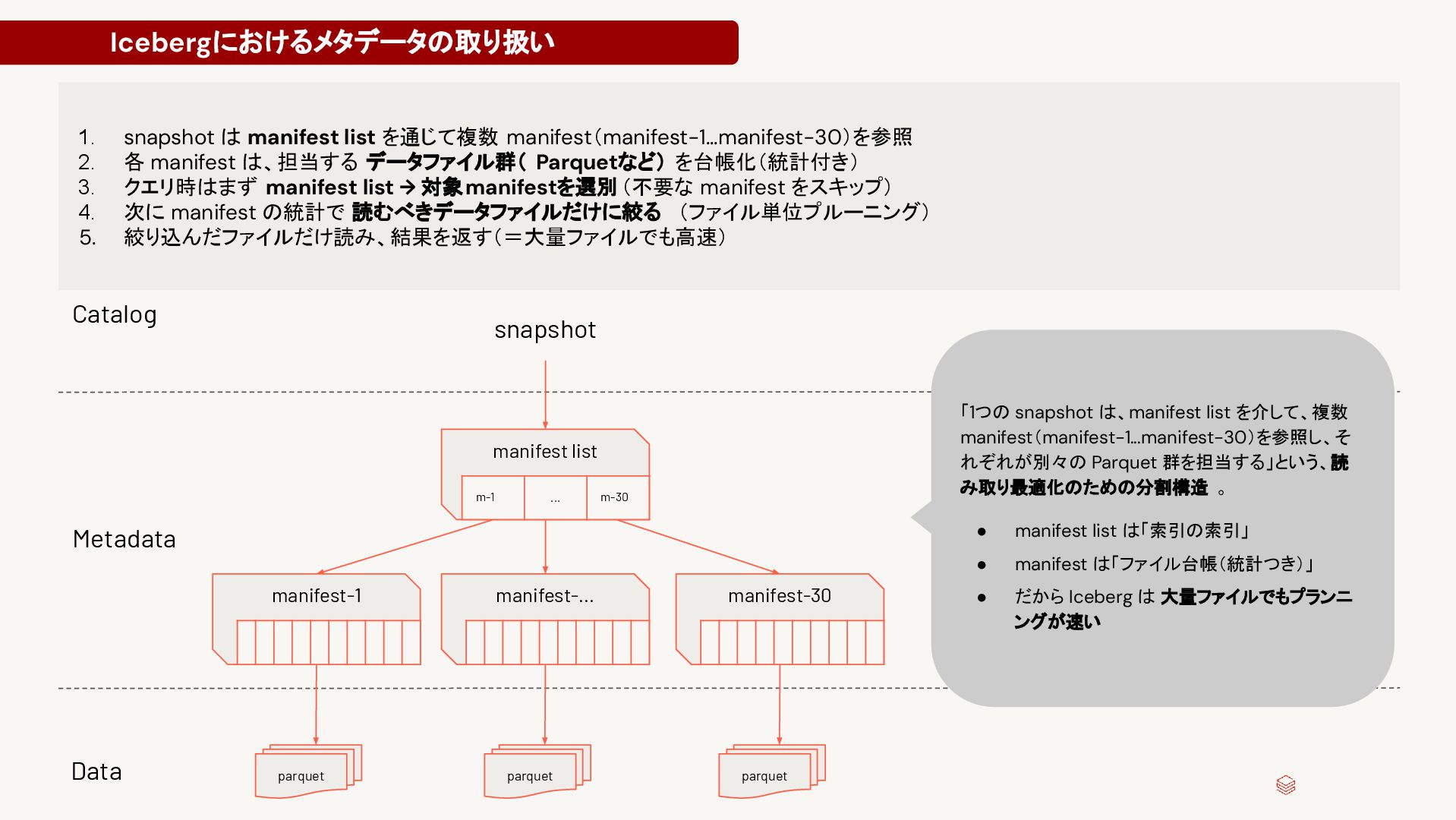
"added_data_files_count": 1, "added_rows_count": 1, "deleted_rows_count": 0, "partitions": { "array": [ { "contains_null": false, "lower_bound": { "bytes": "¹Ô\\u0006\\u0000" }, "upper_bound": { "bytes": "¹Ô\\u0006\\u0000" } } ] } } { "data_file" : { "file_path" : "s3://datalake/db1/orders/data/order_ts_hour=2023-03-07 -08/0_0_0.parquet", "file_format" : "PARQUET", "block_size_in_bytes" : 67108864, "null_value_counts" : [], "lower_bounds" : { "array": [{ "key": 1, "value": 123 }], } "upper_bounds" : { "array": [{ "key": 1, "value": 123 }], }, } } { "table-uuid" : "072db680-d810-49ac-935c-56e901cad686", "schema" : { "type" : "struct", "schema-id" : 0, "fields" : [ { "id" : 1, "name" : "order_id", "required" : false, "type" : "long" }, { "id" : 2, "name" : "customer_id", "required" : false, "type" : "long" }, { "id" : 3, "name" : "order_amount", "required" : false, "type" : "decimal(10, 2)" }, { "id" : 4, "name" : "order_ts", "required" : false, "type" : "timestamptz" } }, "partition-spec" : [ { "name" : "order_ts_hour", "transform" : "hour", "source-id" : 4, "field-id" : 1000 } ] } マニフェストファイル例 メタデータファイル例
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}