Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
評価駆動開発で不確実性を制御する - MLflow 3が支えるエージェント開発
Search
Databricks Japan
December 10, 2025
Technology
560
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
評価駆動開発で不確実性を制御する - MLflow 3が支えるエージェント開発
Databricks Japan
December 10, 2025
More Decks by Databricks Japan
See All by Databricks Japan
生成AIワークショップ / Custom-AI-Agents-workshop
databricksjapan
0
170
Lakeflow Designer ワークショップ / lakeflow-designer-workshop
databricksjapan
0
200
Databricks 生成AIガバナンス実践ワークショップ / LLMOps-workshop
databricksjapan
0
190
プラットフォームエンジニア ワークショップ/ platform-workshop
databricksjapan
2
1.3k
DatabricksにおけるIcebergとDelta Lakeの現在と未来 / The Present and Future of Iceberg and Delta Lake in Databricks
databricksjapan
0
850
Databricks Academic Series 〜 データアナリスト編 〜 / academic-series-data-analyst
databricksjapan
1
320
Databricks Academic Series 〜 データエンジニアリング編 〜 / academic-series-data-engineering
databricksjapan
1
450
Databricks Academic Series 〜 機械学習編 〜 / academic-series-ml
databricksjapan
1
180
Databricks Academic Series 〜 大規模言語モデル / エージェント編 〜 / academic-series-llm
databricksjapan
1
300
Other Decks in Technology
See All in Technology
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
160
クラウドセキュリティ入門 ~安全なクラウド利用のための基礎知識~
lhazy
0
290
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
340
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
320
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
150
ウォーターフォール開発案件のPMとしてAI活用を模索している話
hatahata021
2
230
LLMリーダーボードアップデートに向けたAgentic Math_SWEのトレースについて
nejumi
0
160
AIエージェントの知識表現と推論に なぜグラフが使われるのか - 記号的AIの復権とニューラルAIとの統合
yohei1126
1
230
「休む」重要さ
smt7174
7
1.8k
Escolhendo LLMs na Prática: Lições Reais em Busca Agêntica no Mercado Livre —TDC 2026 Floripa
jpbonson
0
110
AIエージェントに財布を渡す日 ― 承認付き"買い物エージェント"を作って実演
yama3133
0
110
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
720
Featured
See All Featured
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
550
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
420
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
670
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
160
Making the Leap to Tech Lead
cromwellryan
135
10k
Statistics for Hackers
jakevdp
799
230k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
The Limits of Empathy - UXLibs8
cassininazir
1
570
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
450
Are puppies a ranking factor?
jonoalderson
1
3.7k
Music & Morning Musume
bryan
47
7.3k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Transcript
評価駆動開発で不確実性を制御する MLflow 3 が⽀えるエージェント開発 渡辺祐貴 SWE / テックリード @ Databricks
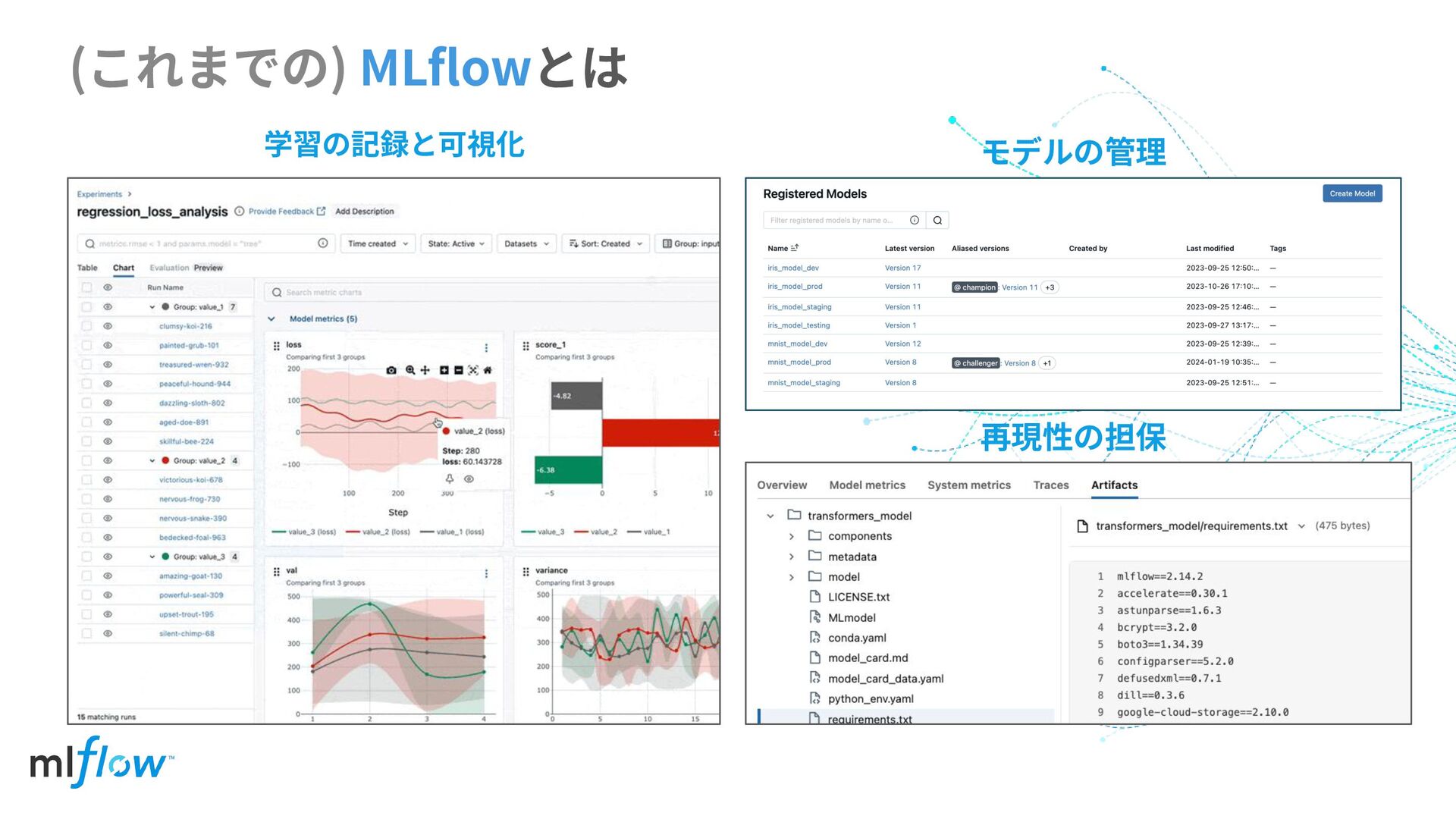
(これまでの) MLflowとは 学習の記録と可視化 再現性の担保 モデルの管理
Github Stars 22.3K PyPI Downloads >2500万 (月間) Contributors >900 Hosted
by
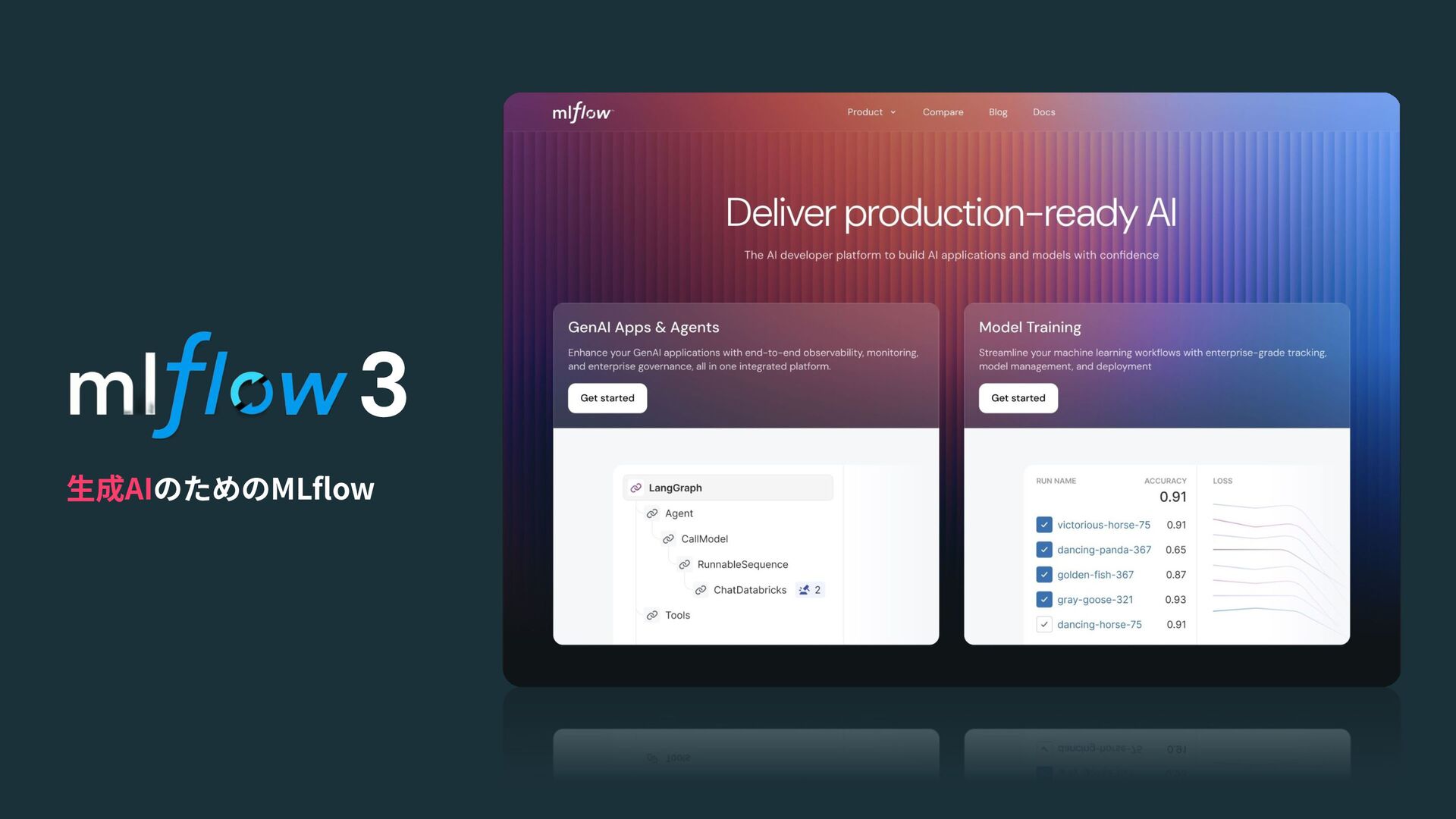
⽣成AIのためのMLflow 3
AIエージェント開発で最⼤の課題とは?
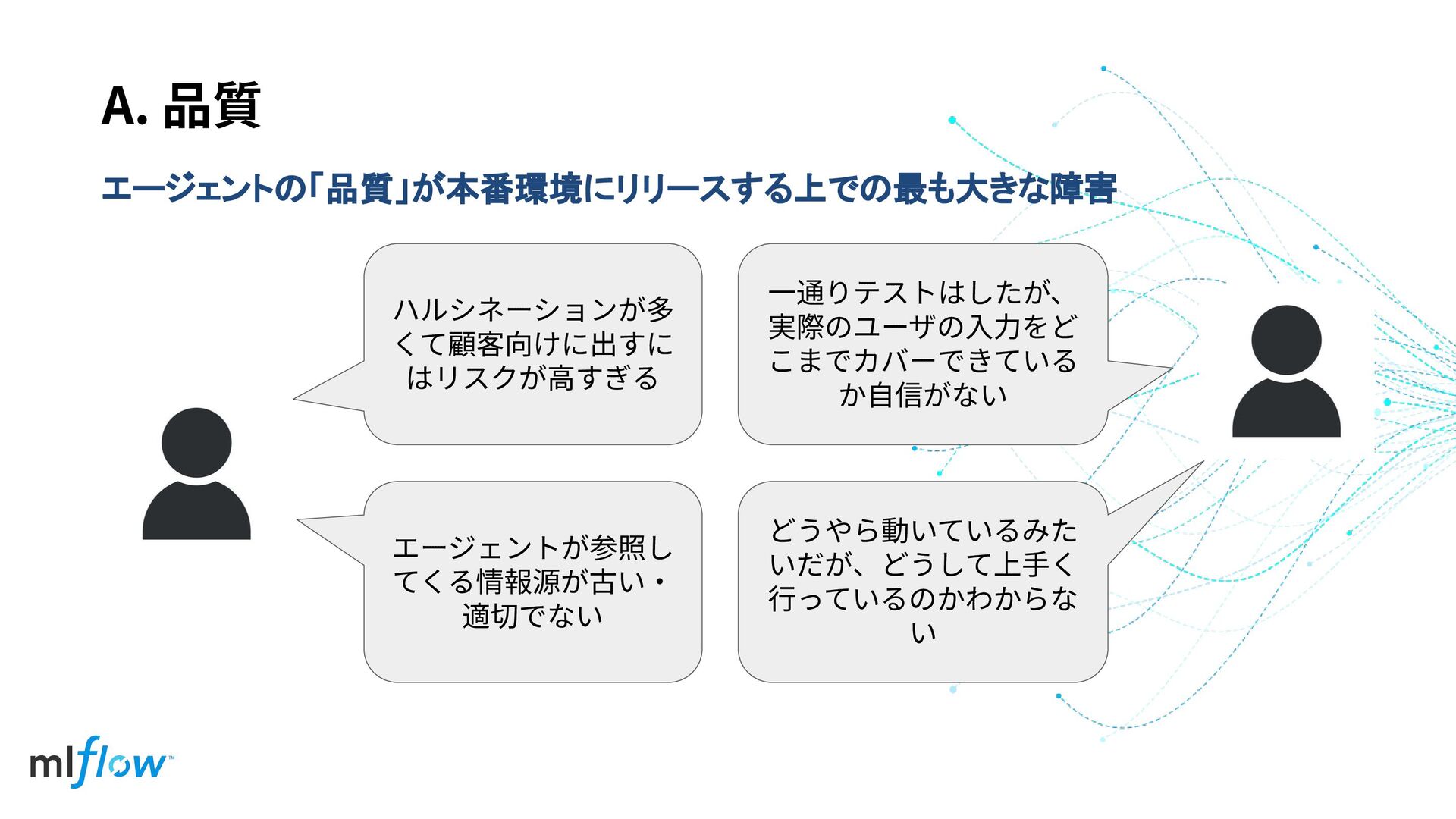
エージェントの「品質」が本番環境にリリースする上での最も大きな障害 A. 品質 ハルシネーションが多 くて顧客向けに出すに はリスクが⾼すぎる ⼀通りテストはしたが、 実際のユーザの⼊⼒をど こまでカバーできている か⾃信がない
エージェントが参照し てくる情報源が古い‧ 適切でない どうやら動いているみた いだが、どうして上⼿く ⾏っているのかわからな い
どうやって品質を上げるか • プロンプトの改善、ドキュメントの前後処理、クエリ⽅法、ツールの選定、コ ンテキストの圧縮. • 毎⽉のように新しいLLMが現れてベンチマークを更新していく.ただし実際の タスクで使えるかどうかは試してみないと分からない. • LLMは極めて不確実で、⼩さな変更が別の場所に及ぼす影響は未知. •
試せる⽅法は無数にあるが、全てを検証する時間はない. 品質を改善するものを選んで取り⼊れる必要がある
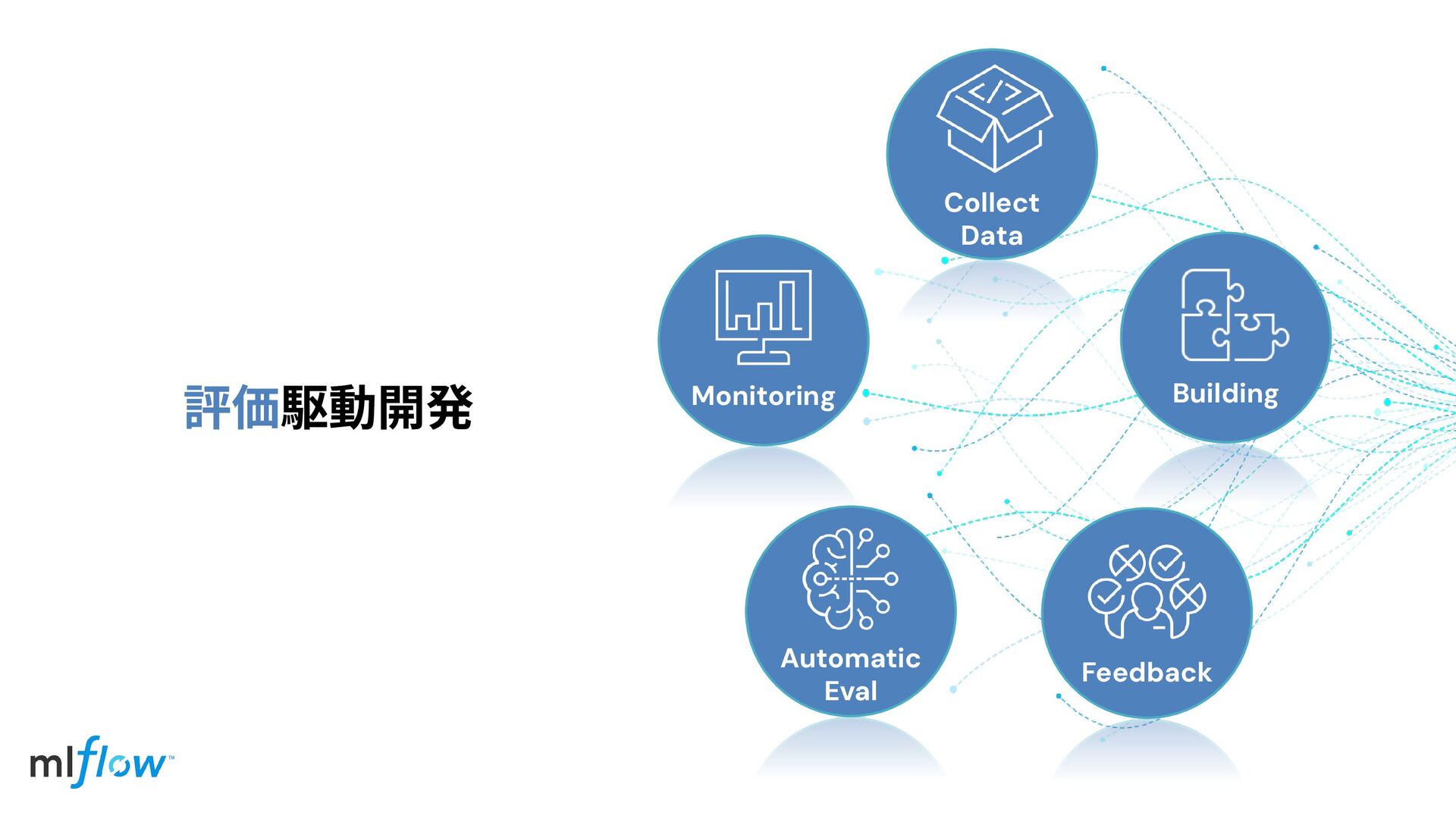
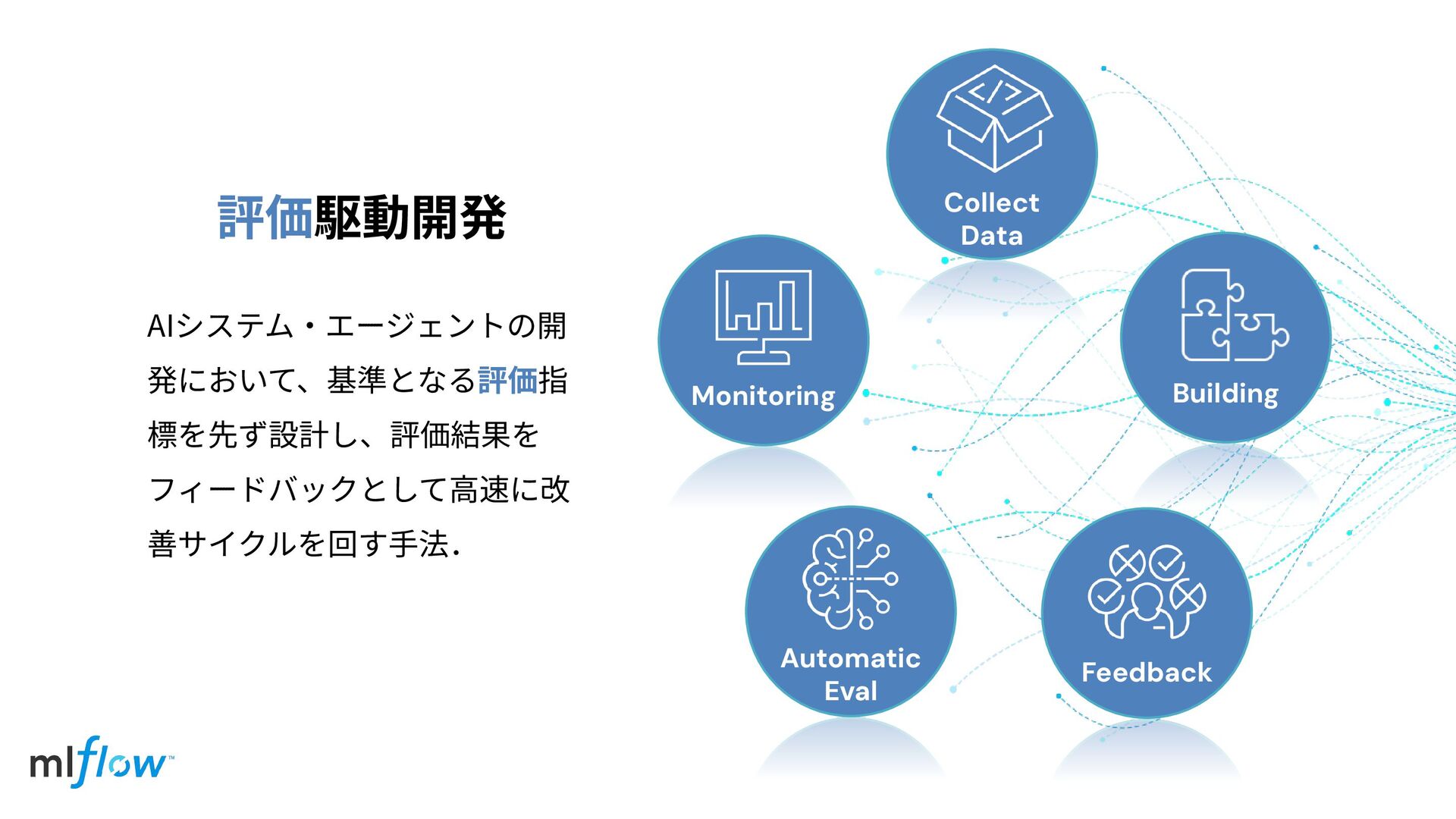
評価駆動開発 Collect Data Building Feedback Automatic Eval Monitoring
Collect Data Building Feedback Automatic Eval Monitoring 評価駆動開発 AIシステム‧エージェントの開 発において、基準となる評価指
標を先ず設計し、評価結果を フィードバックとして⾼速に改 善サイクルを回す⼿法.
評価駆動開発は〜〜ではない 🤔 「本番前に時間をかけて評価をすればよい?」 ◦ 素早くリリースして本番でのデータを得ることが最重要。 ◦ 「とりあえず動く」から「本番リリース」までの道を⾼速で駆け上がるためのテクニック。 🤔 「評価は最適化の段階になってからの話だよね」 ◦
従来の機械学習では、Accuracyを90%→95%にチューニングしていくイメージ. ◦ AIエージェント開発における評価は、どちらかというとソフトウェアのテストに近く、 ⾼速なフィードバックループを得るための仕組み。 🤔 「いきなり評価から始めないといけないの?」 ◦ 0→1の段階でいきなり評価を取り⼊れるのは難しい。 ◦ 評価駆動開発に移⾏できる状態にはしておく。(例:トレースの有効化)
None
基盤: トレース‧可観測性
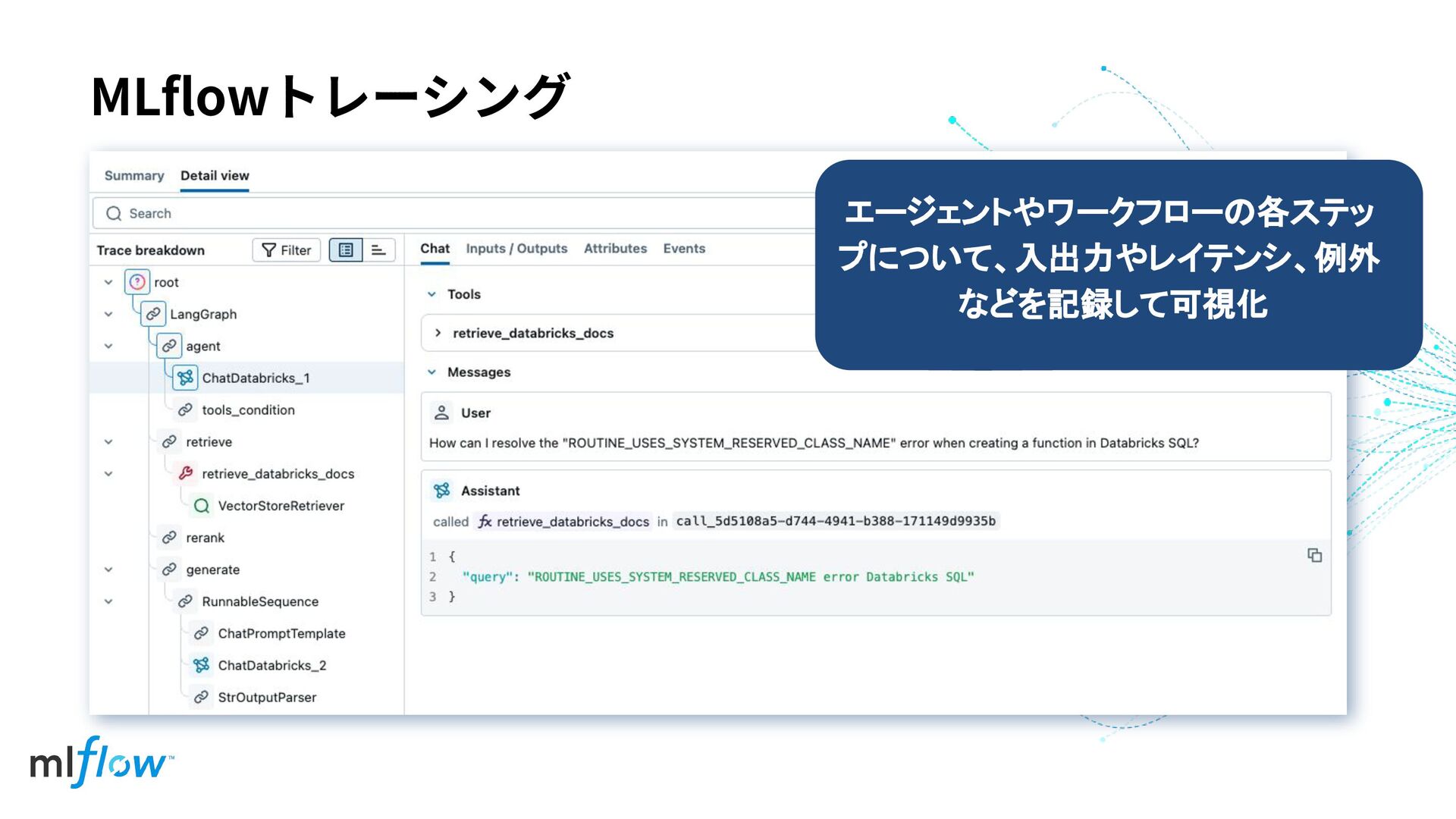
MLflowトレーシング エージェントやワークフローの各ステッ プについて、入出力やレイテンシ、例外 などを記録して可視化
mlflow.library.autolog() OpenTelemetry Traces MLflowトレーシング 既存のコードに1⾏⾜すだけで⾃動トレーシング
• ソフトウェアの可観測性における業界標準の仕様とSDK • MLflowのトレースはOpenTelemetry SDK上に構築されており、 データも仕様に準拠しているため、ベンダーや⾔語に⾮依存。 • 例えばMLflowのトレースをGrafanaやNew Relicに送ったり、 OpenTelemetryをサポートしているあらゆる⾔語(Java,
Go, Rust, …)のサービスから直接MLflowにトレースを記録できる。 OpenTelemetry準拠
評価駆動開発の流れ
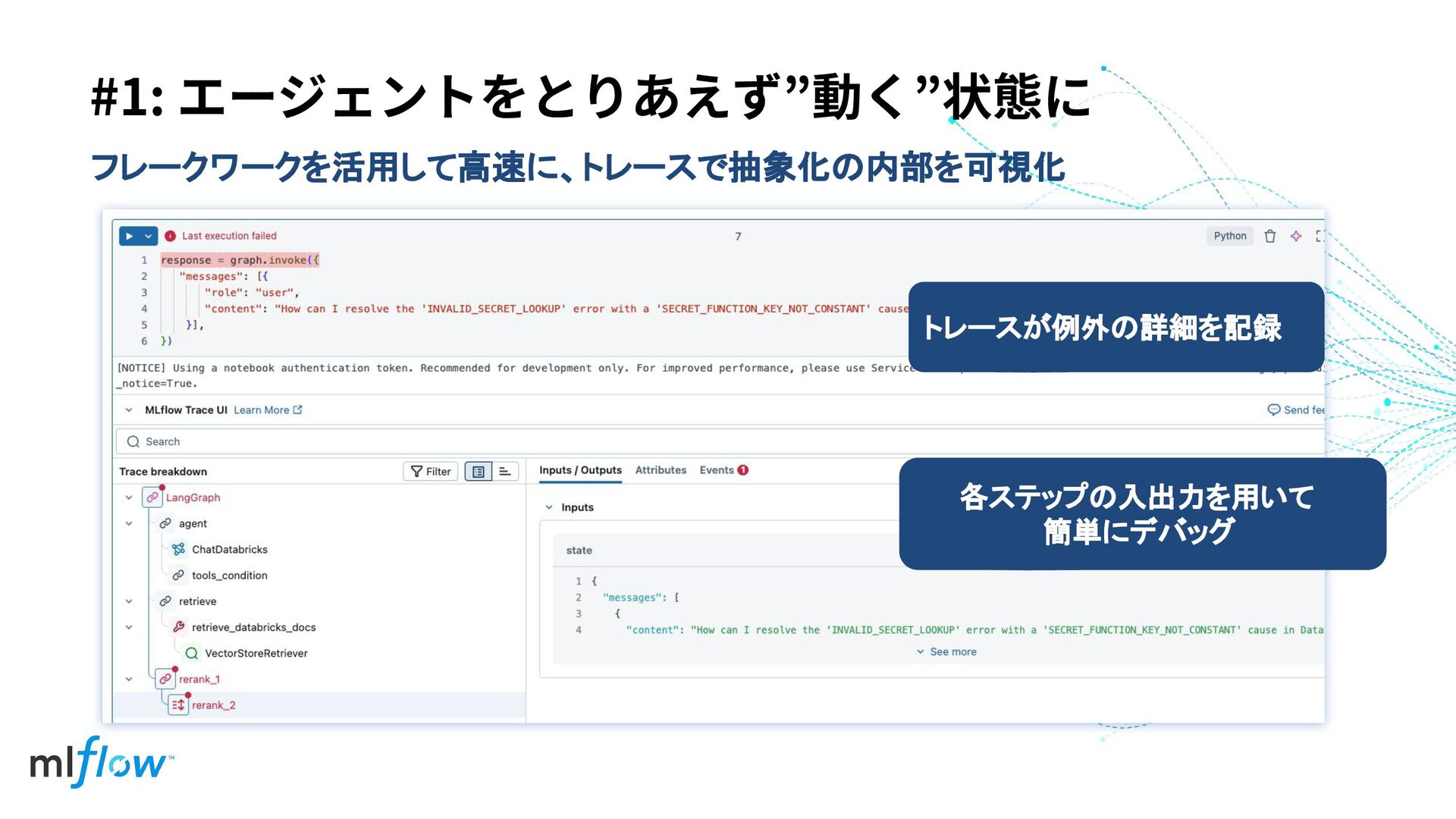
#1: エージェントをとりあえず”動く”状態に トレースが例外の詳細を記録 各ステップの入出力を用いて 簡単にデバッグ フレークワークを活用して高速に、トレースで抽象化の内部を可視化
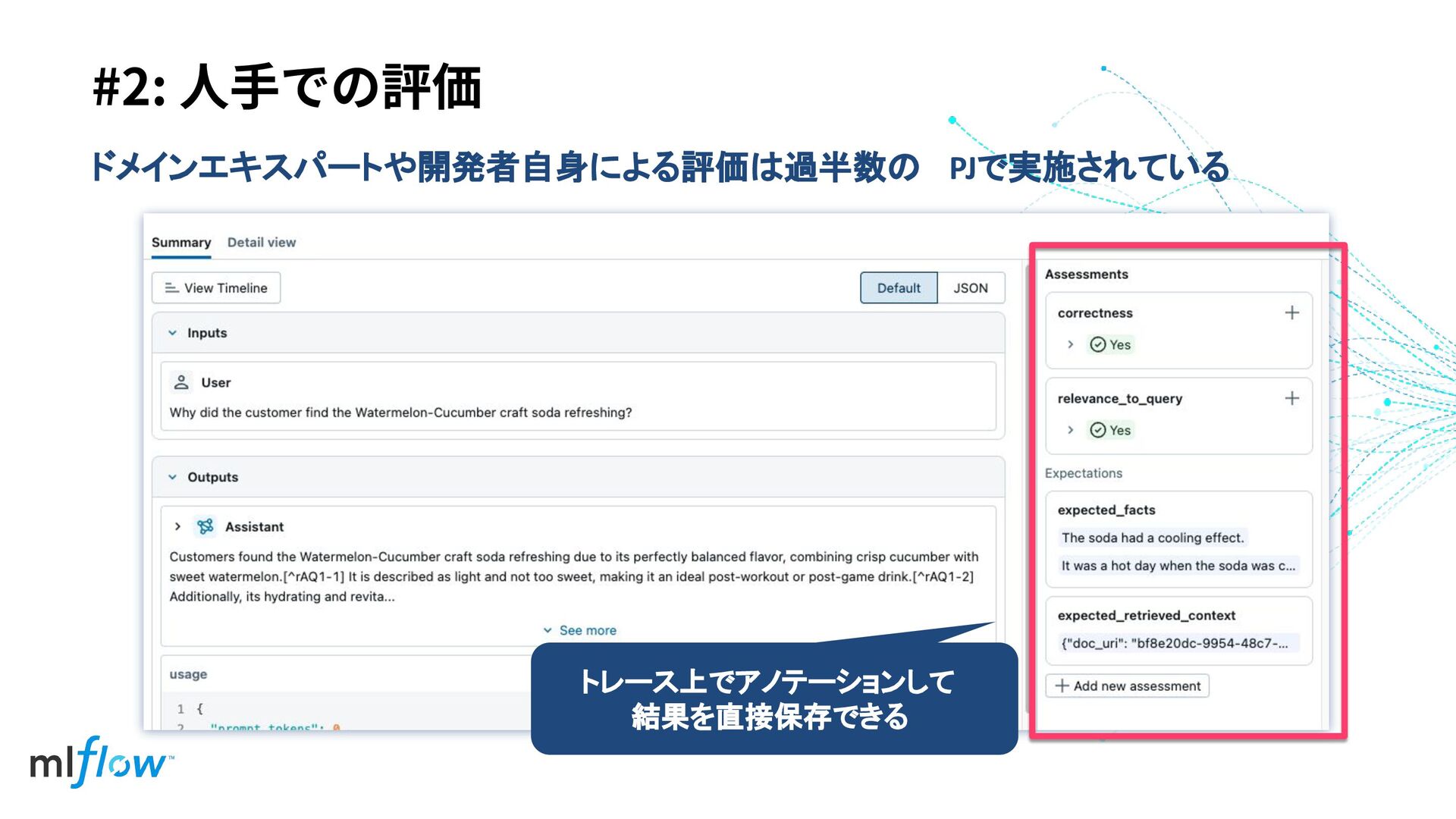
#2: ⼈⼿での評価 ドメインエキスパートや開発者自身による評価は過半数の PJで実施されている トレース上でアノテーションして 結果を直接保存できる
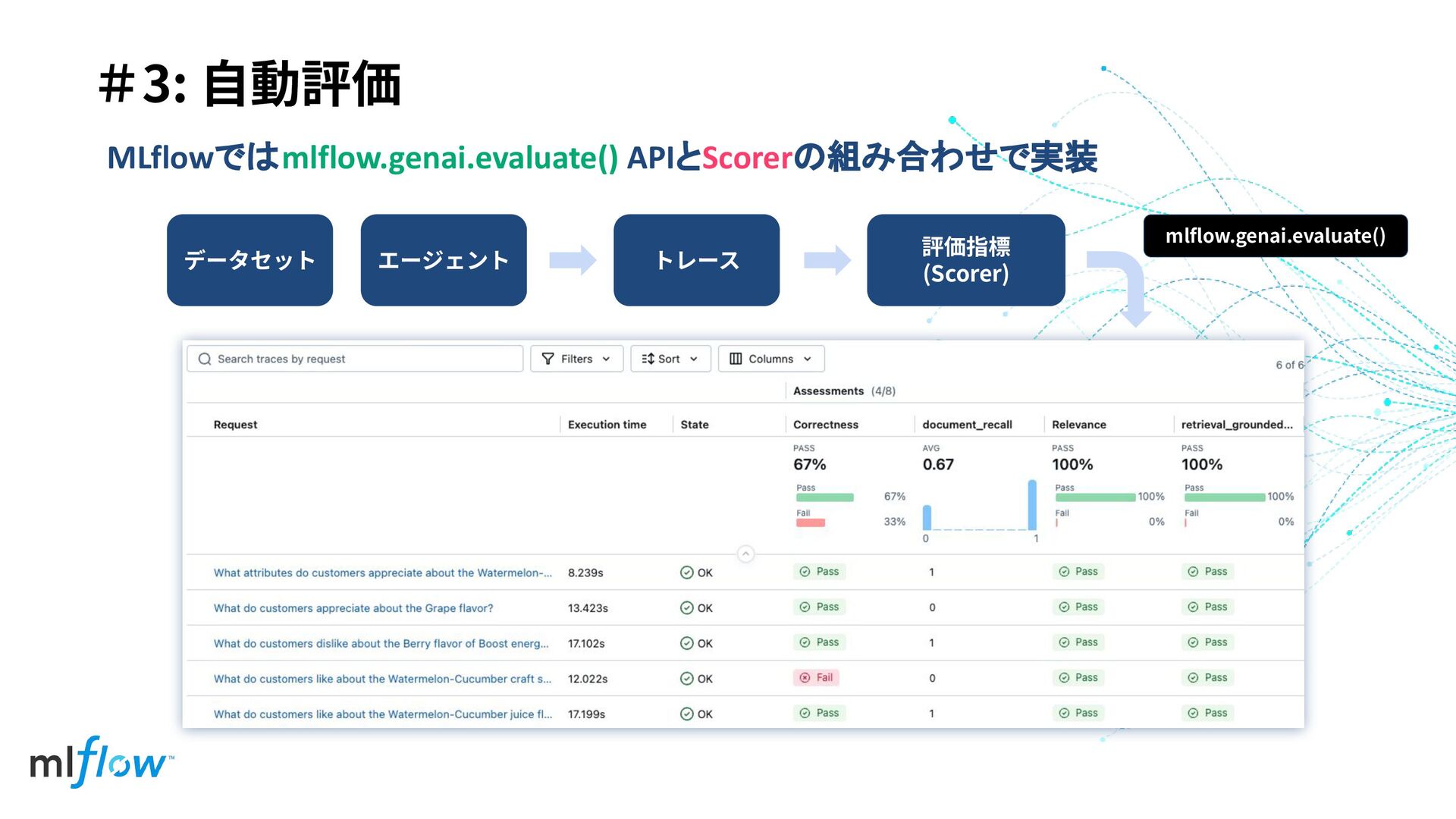
#3: ⾃動評価 評価指標 (Scorer) mlflow.genai.evaluate() MLflowではmlflow.genai.evaluate() APIとScorerの組み合わせで実装 データセット エージェント トレース
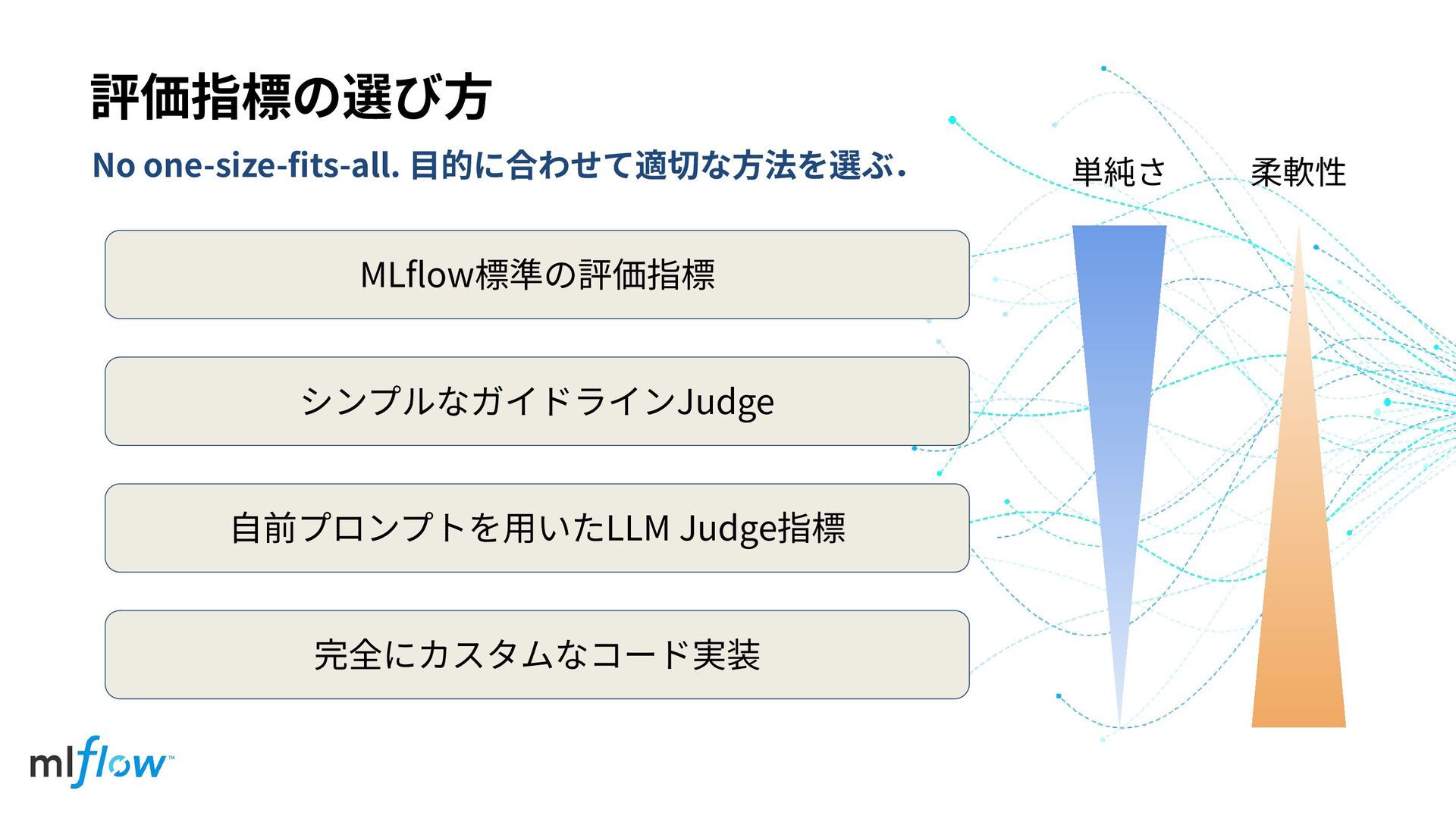
評価指標の選び⽅ No one-size-fits-all. ⽬的に合わせて適切な⽅法を選ぶ. MLflow標準の評価指標 シンプルなガイドラインJudge ⾃前プロンプトを⽤いたLLM Judge指標 完全にカスタムなコード実装 単純さ
柔軟性
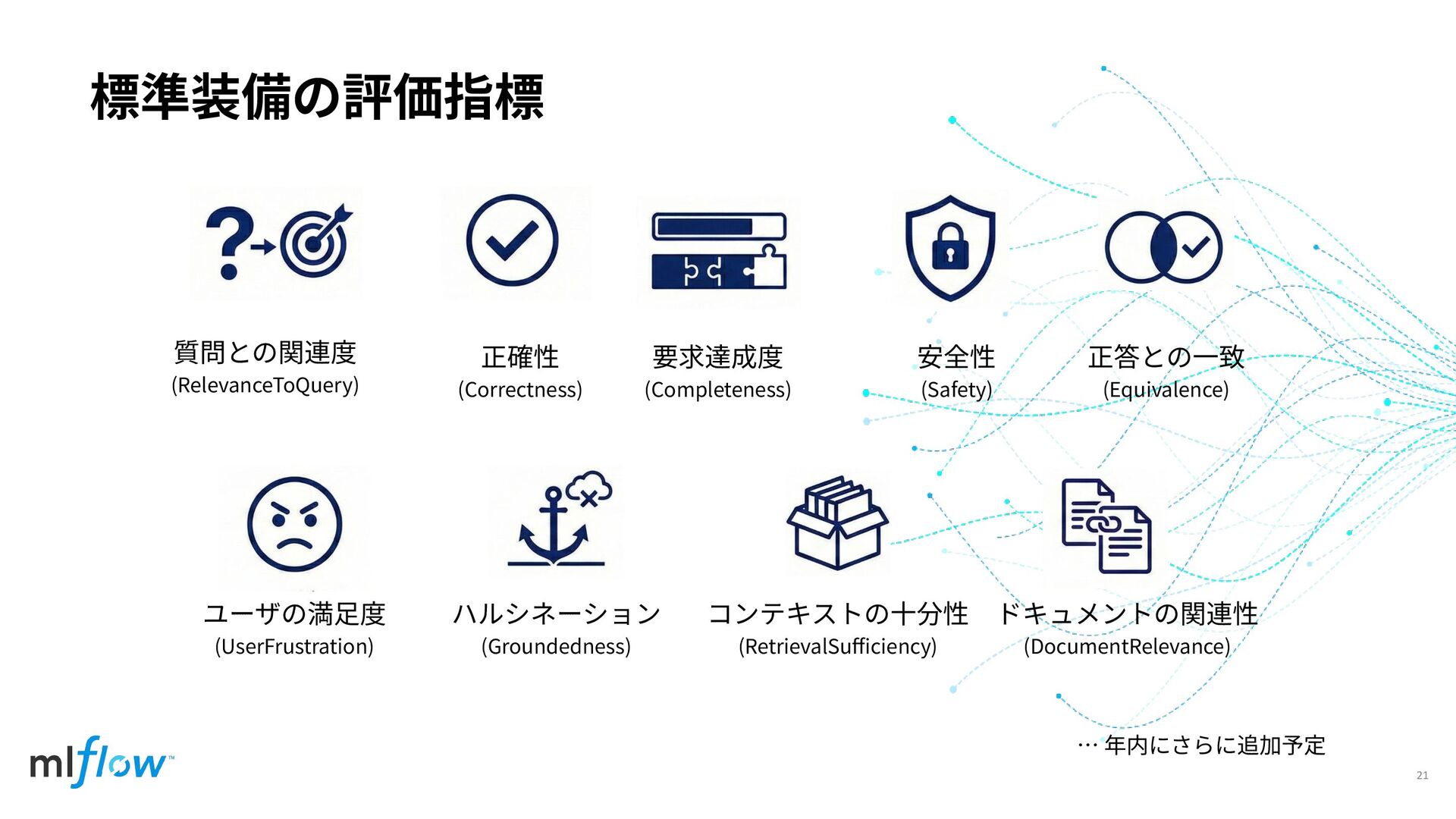
標準装備の評価指標 21 質問との関連度 (RelevanceToQuery) 正確性 (Correctness) 要求達成度 (Completeness) 安全性 (Safety)
正答との⼀致 (Equivalence) ユーザの満⾜度 (UserFrustration) ハルシネーション (Groundedness) コンテキストの⼗分性 (RetrievalSufficiency) ドキュメントの関連性 (DocumentRelevance) … 年内にさらに追加予定
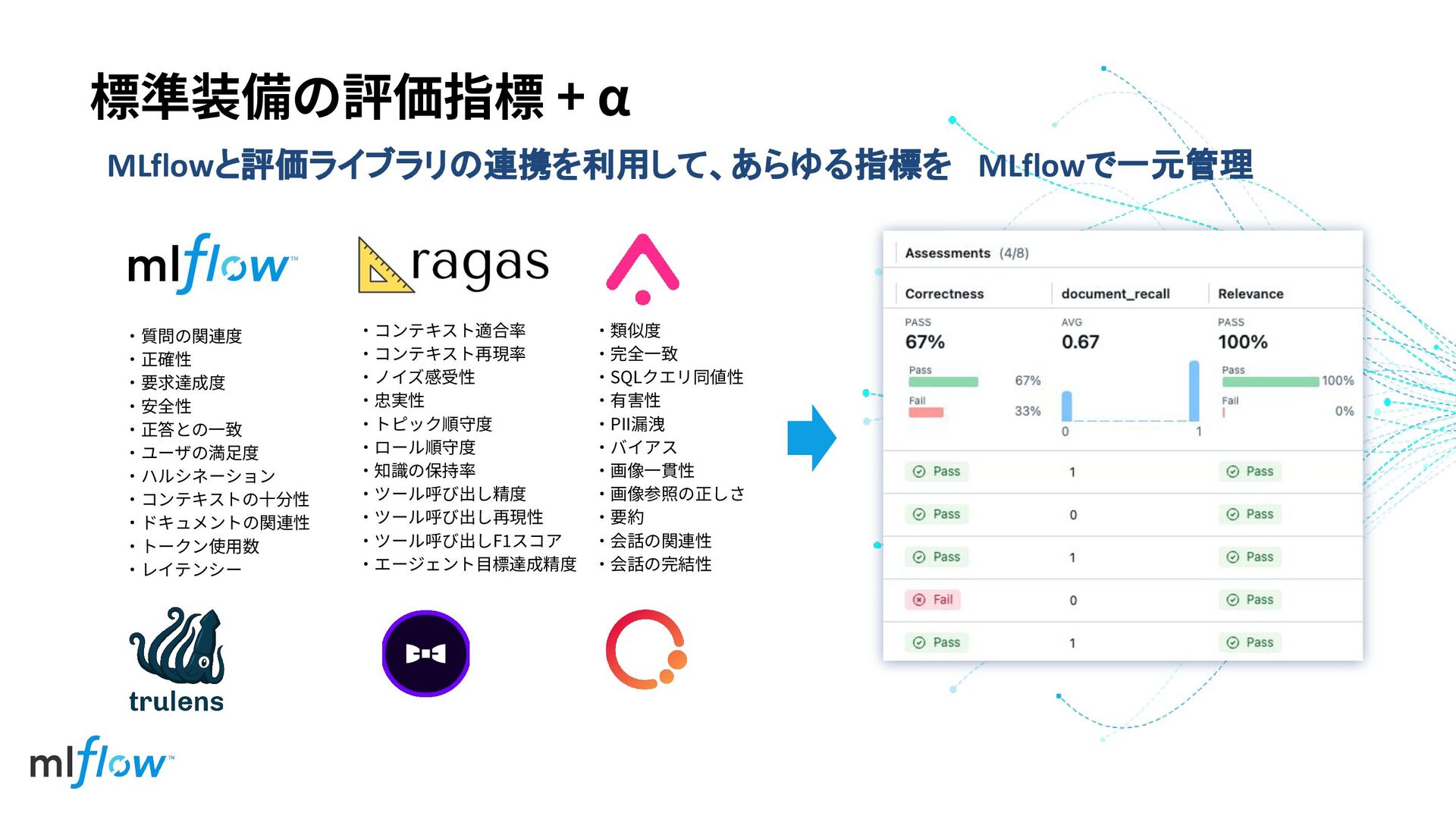
‧類似度 ‧完全⼀致 ‧SQLクエリ同値性 ‧有害性 ‧PII漏洩 ‧バイアス ‧画像⼀貫性 ‧画像参照の正しさ ‧要約 ‧会話の関連性
‧会話の完結性 標準装備の評価指標 + α MLflowと評価ライブラリの連携を利用して、あらゆる指標を MLflowで一元管理 ‧コンテキスト適合率 ‧コンテキスト再現率 ‧ノイズ感受性 ‧忠実性 ‧トピック順守度 ‧ロール順守度 ‧知識の保持率 ‧ツール呼び出し精度 ‧ツール呼び出し再現性 ‧ツール呼び出しF1スコア ‧エージェント⽬標達成精度 ‧質問の関連度 ‧正確性 ‧要求達成度 ‧安全性 ‧正答との⼀致 ‧ユーザの満⾜度 ‧ハルシネーション ‧コンテキストの⼗分性 ‧ドキュメントの関連性 ‧トークン使⽤数 ‧レイテンシー
coherence_judge = make_judge( name="coherence", instructions=( "Evaluate if the response is
coherent, maintaining a constant tone " "and following a clear flow of thoughts/concepts" "Question: {{ inputs }}\n\n Response: {{ outputs }}\n" ), feedback_value_type=Literal["coherent", "incoherent", “unsure”], model="anthropic:/claude-opus-4-1-20250805", ) カスタムのLLM Judge指標 23 is_english = Guidelines(“answer must be English”, name=) ⽅法1: ガイドラインAPIで 簡単にLLM Judgeを定義 ⽅法2: より複雑なケースでは make_judge() APIを利⽤
from mlflow.genai import scorer @scorer def tool_call_trajectory(trace, expectations) -> Feedback:
# 呼び出されたツールをトレースから取得 tool_call_spans = trace.search_spans(span_type=SpanType.TOOL) # ツールの実行履歴を期待した順番と比較 actual_trajectory = [span.name for span in tool_call_spans] expected_trajectory = expectations["tool_call_trajectory"] if actual_trajectory == expected_trajectory: return Feedback(value=1, rationale="The tool call trajectory is correct.") else: return Feedback(value=0, rationale="The tool call trajectory is incorrect.") コードで指標を実装する 24 例:ツール呼び出しの順番を評価する指標 トレース‧⼊⼒‧出⼒‧教師値の 任意の組み合わせを引数にとる @scorerデコレータをつけて あらゆる関数を評価指標に
⾃動評価の仕組み作り ビジネスゴールに沿った適切な指標の設計が重要 1. KPIや⼈⼿での評価結果に基づいて、重要な評価基準を決定 2. 想定される質問‧⼊⼒を収集 3. 標準の評価指標で⾜りない場合、カスタムの指標を実装‧テスト 4. ⾃動評価を実⾏、⼈⼿での評価とズレていないか確認
LLMによる評価を⼈間の評価にアラインする • ライブラリ標準の指標は便利だが、最適ではない. • しかし、評価指標を全てプロンプトエンジニアリングするのは⾮現実的 • → トレースに記録した⼈⼿評価をターゲットとしてプロンプト最適化 from mlflow.genai.judges.optimizers
import SIMBAAlignmentOptimizer judge = Guidelines(name="tone_judge”, guidelines=“The answer must be polite”) optimizer = SIMBAAlignmentOptimizer(model="anthropic:/claude-opus-4-1-20250805") aligned_judge = judge.align(traces, optimizer)
Agent-as-a-Judge 評価⽤のAgentがトレースを⾃ら⾛査して評価
ジャッジコストの可視化 プロンプト最適化で軽量モデルへの移行 でも、お⾼いんでしょう? 使⽤したLLMや評価の理由も記録
⾃動評価を⽤いた⾼速フィードバックループ 1. 実装やモデルを変更 2. 評価/テスト結果を元に実装の変更 3. 複数⼿法の結果を可視化‧⽐較 4. 新しい問題が⾒つかったら対応する Judgeを作成(テストケースの追加)
5. 1に戻る
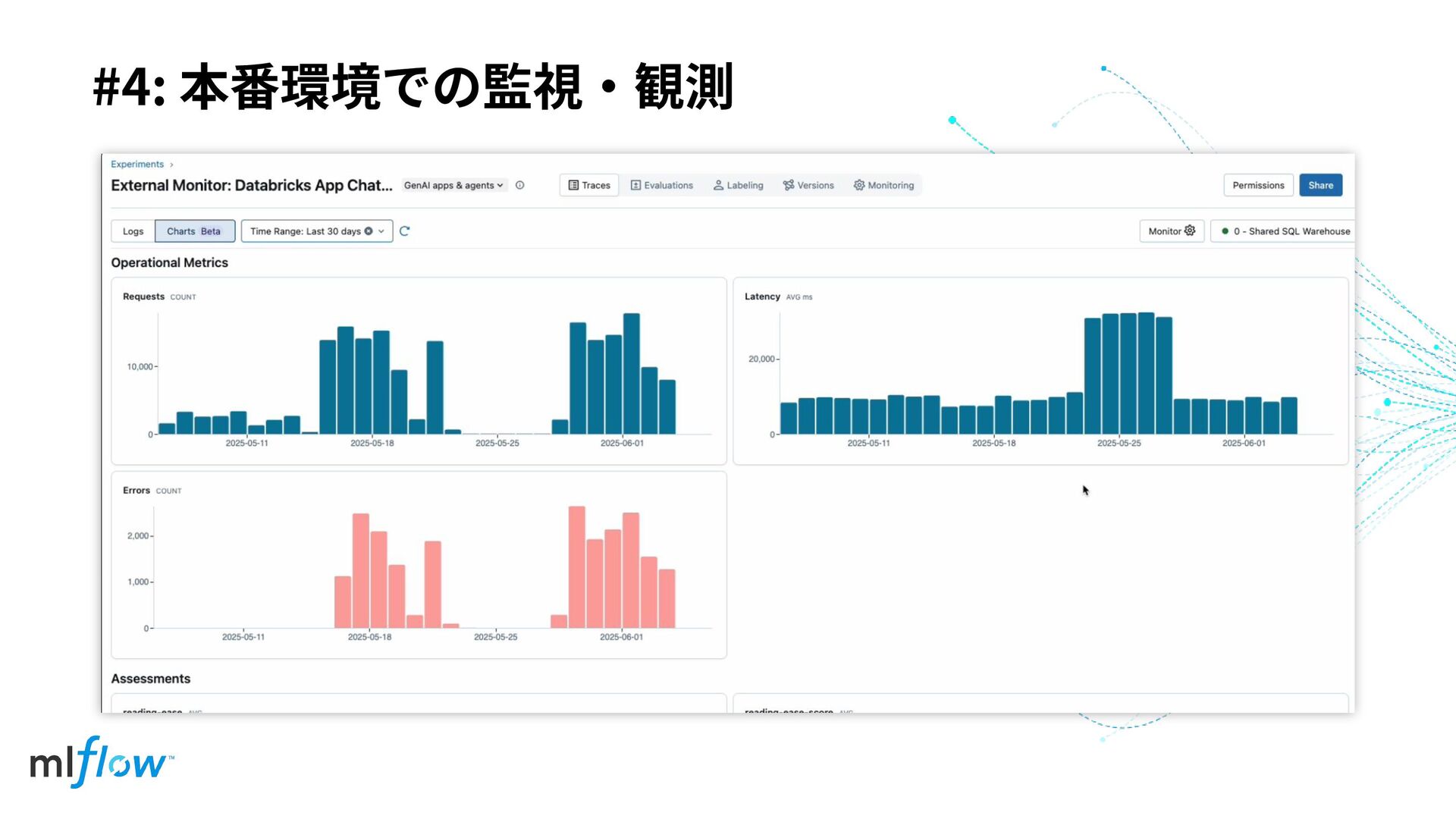
#4: 本番環境での監視‧観測
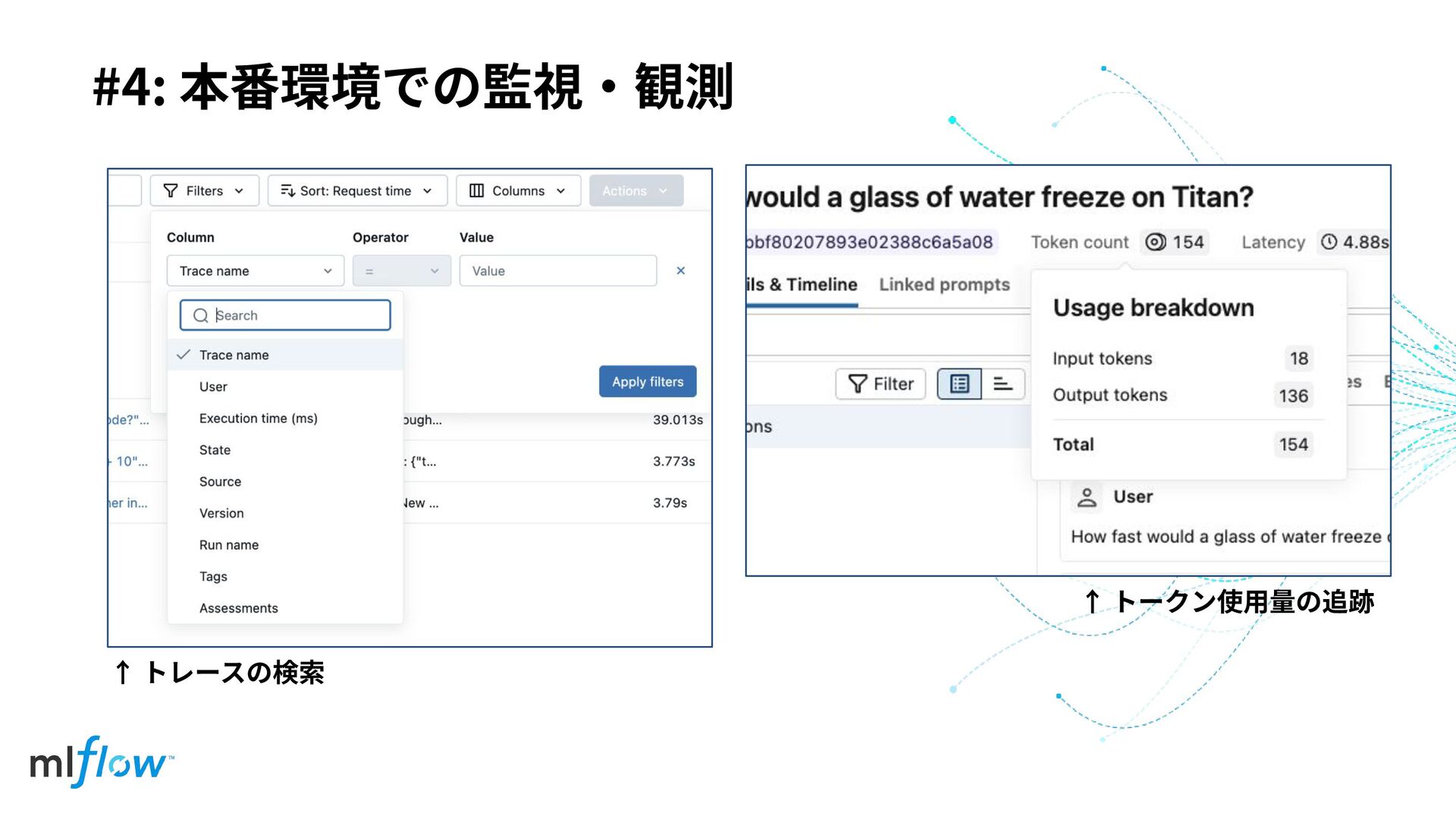
#4: 本番環境での監視‧観測 ↑ トレースの検索 ↑ トークン使⽤量の追跡
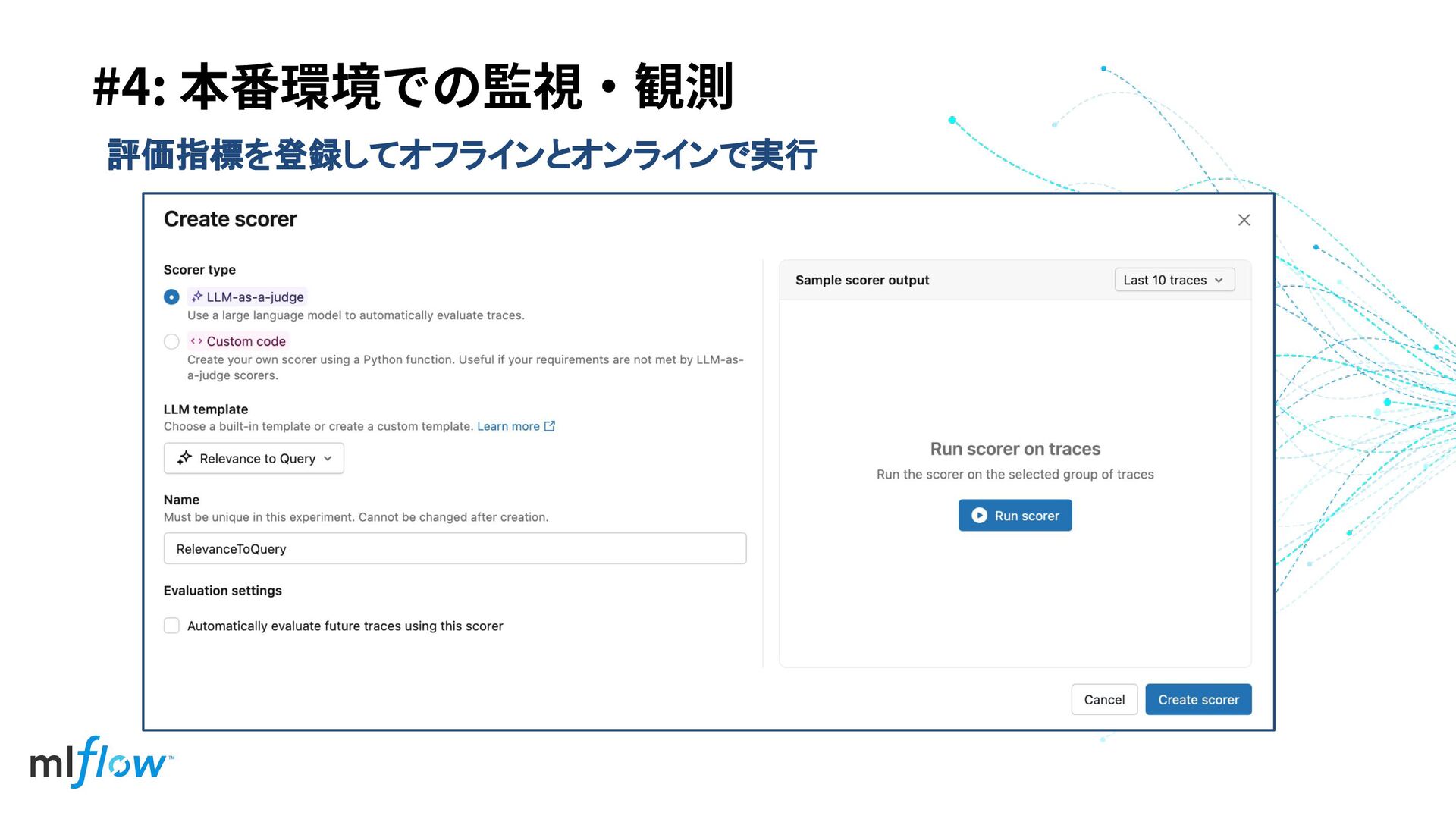
#4: 本番環境での監視‧観測 評価指標を登録してオフラインとオンラインで実行
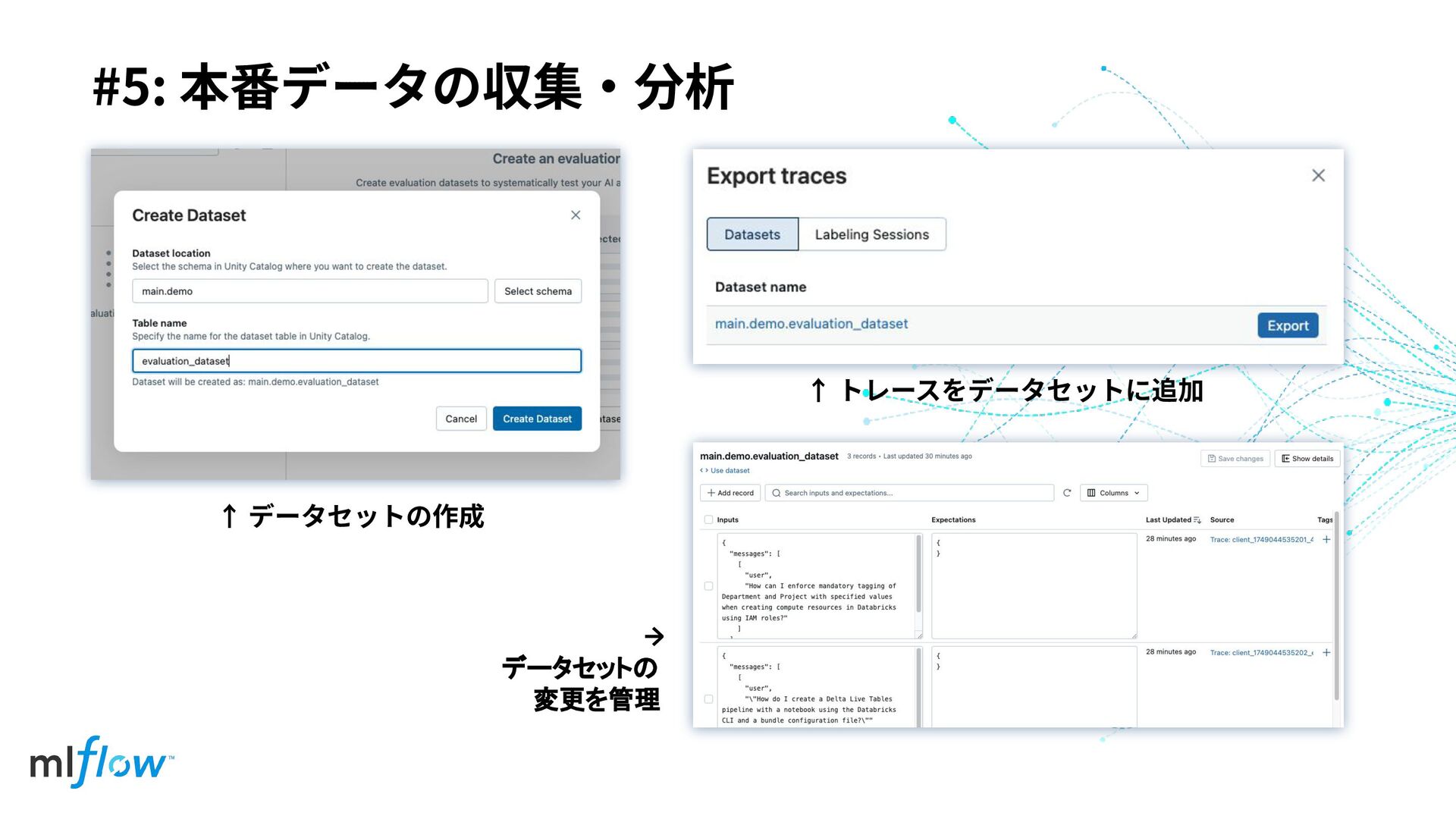
#5: 本番データの収集‧分析 ↑ データセットの作成 ↑ トレースをデータセットに追加 → データセットの 変更を管理
34 #5: 本番データの収集‧活⽤ Coding Agentでエラーや 低品質の回答の原因を分析 トレース分析エージェント (Coming soon!) プロンプトの自動最適化
MLflow 3をはじめる
36 💻 でインストール 📦 Python環境がなくてもDockerでデプロイできます 📚 詳しい機能はウェブサイトとDocもぜひ: https://mlflow.org/ 🚀
デモ⽤のプロジェクトを1⽉に追加予定 👕 何も設定したくない⼈はDatabricksの無料版もおすすめ MLflowのはじめ⽅ $pip install mlflow
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}