In this presentation, we’ll walk through the creation of a simple Python script that can learn to find malicious activity in your HTTP proxy logs. At the end of it all, you'll not only gain a useful tool to help you identify things that your IDS and SIEM might have missed, but you’ll also have the knowledge necessary to adapt that code to other uses as well.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
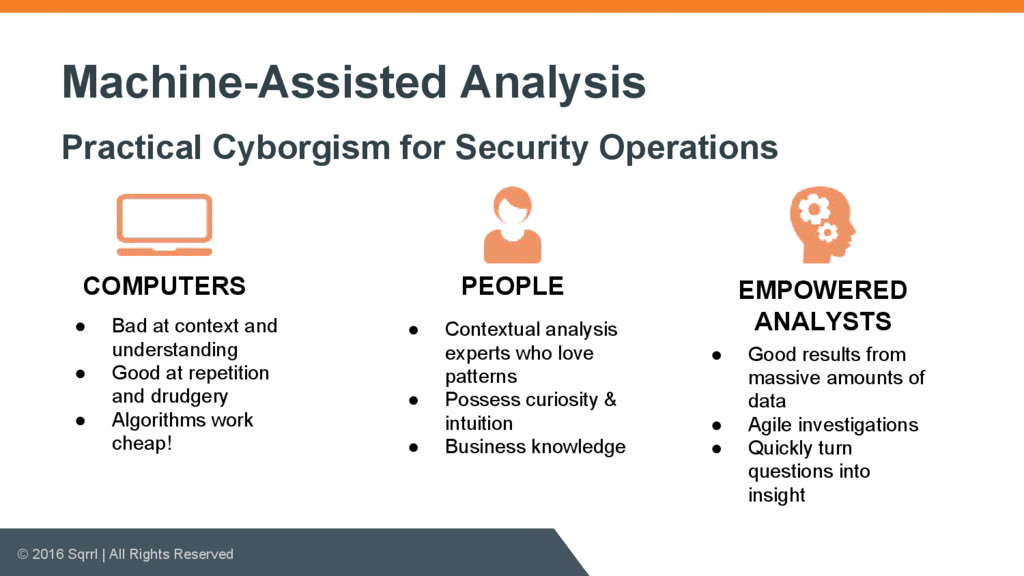{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
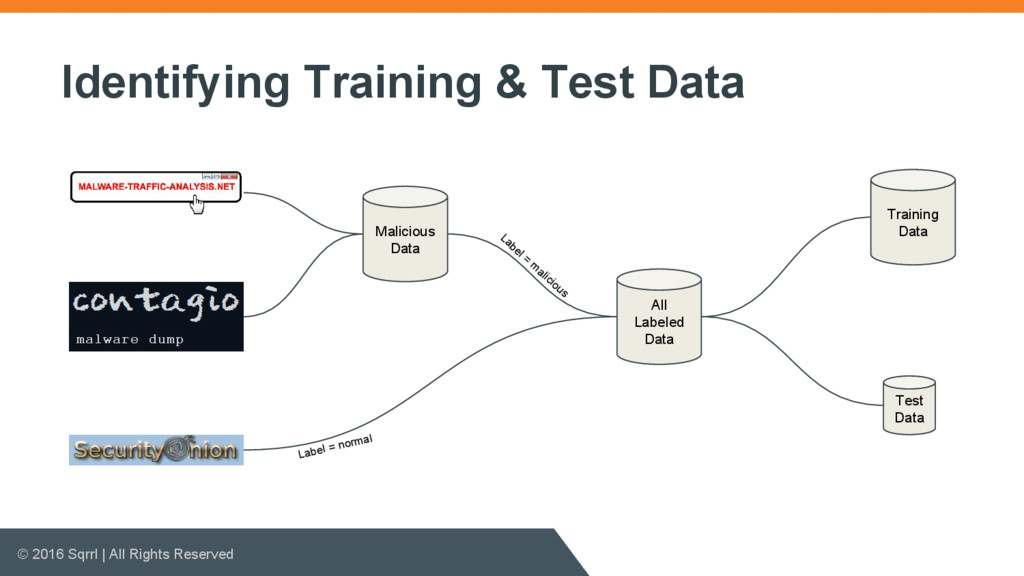{kind=link}
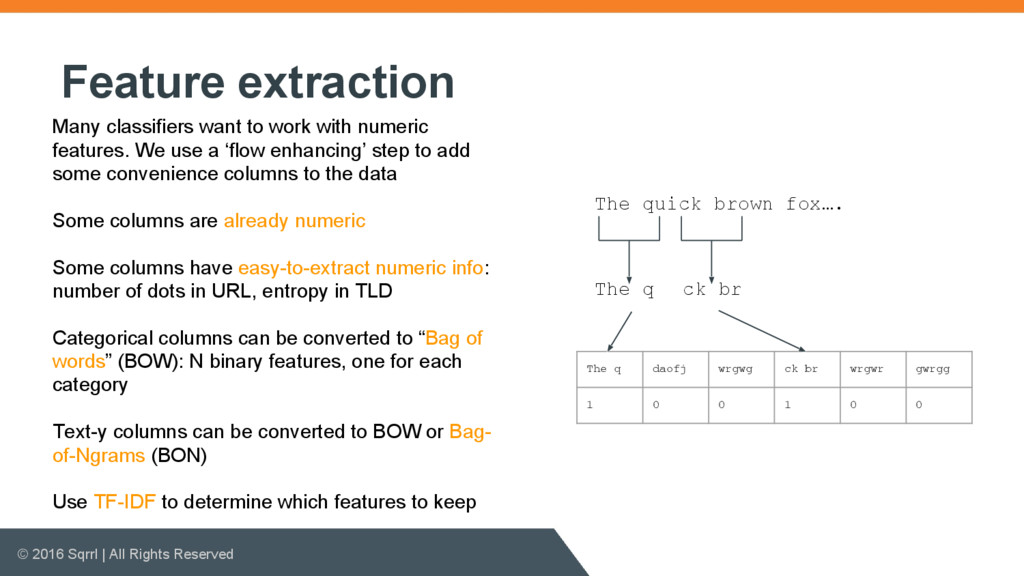{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
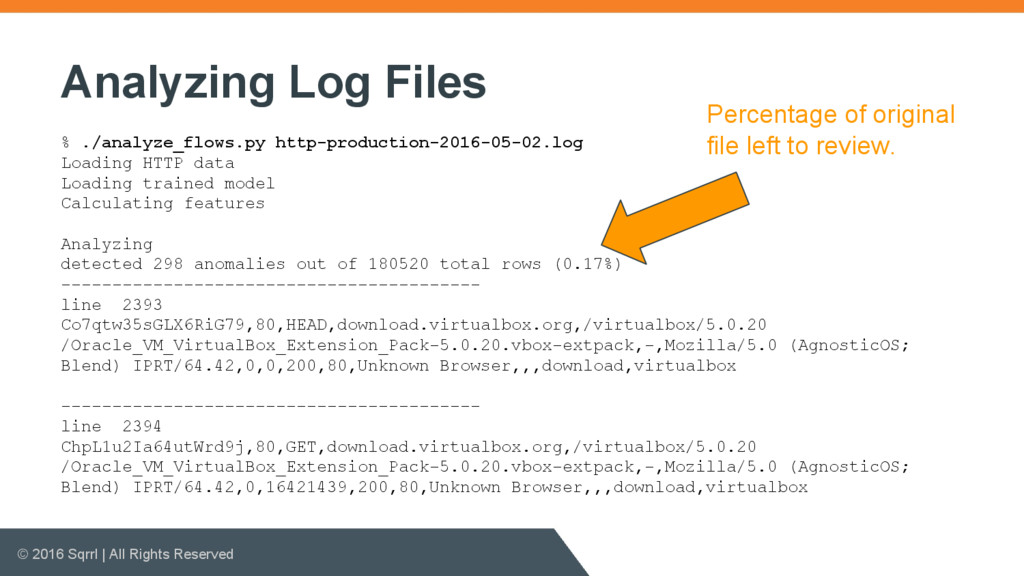{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}