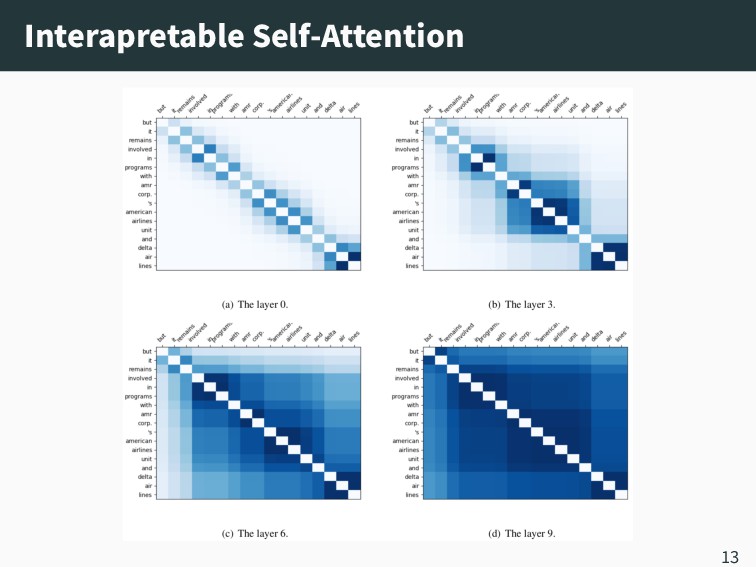
の Attention が Tree Transformer と全く異な る構造を学習していることを示唆 ▪ この 1 文がよくわからなかった • “In addition, with a well-trained Transformer, it is not necessary for the Constituency Attention module to induce reasonable tree structures, because the training loss decreases anyway.” 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Masked Language Modeling [MASK] トークンの perplexity を評価 ▪ perplexity は通常の](https://files.speakerdeck.com/presentations/964ceaac5a6b4b539762031f23c74de7/slide_14.jpg){kind=link}
{kind=link}
{kind=link}