The presentation from SPb Python Interest Group community meetup.
The presentation tells about the dictionaries in Python, reviews the implementation of dictionary in CPython 2.x, dictionary in CPython 3.x, and also recent changes in CPython 3.6. In addition to CPython the dictionaries in alternative Python implementations such as PyPy, IronPython and Jython are reviewed.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
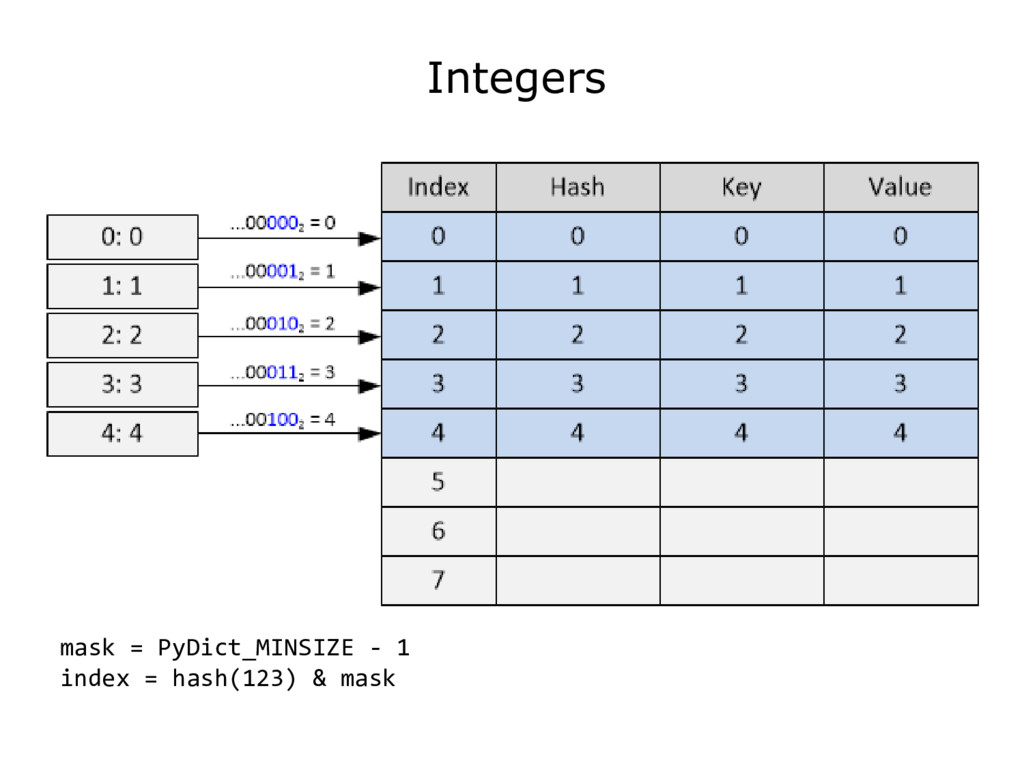{kind=link}
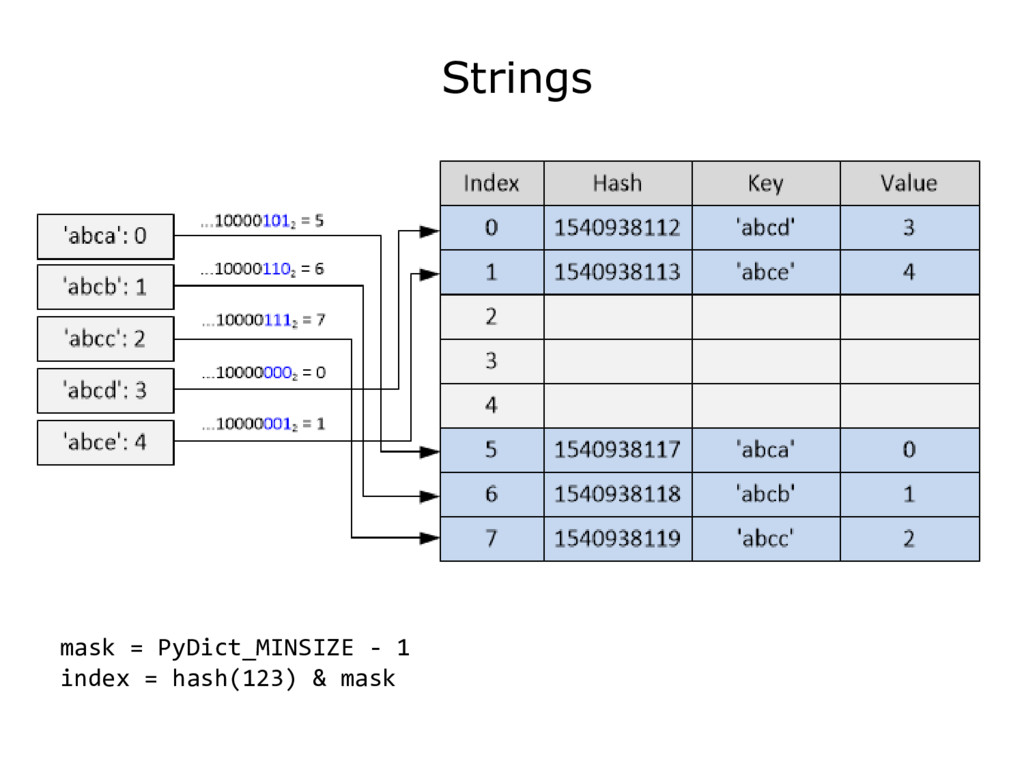{kind=link}
{kind=link}
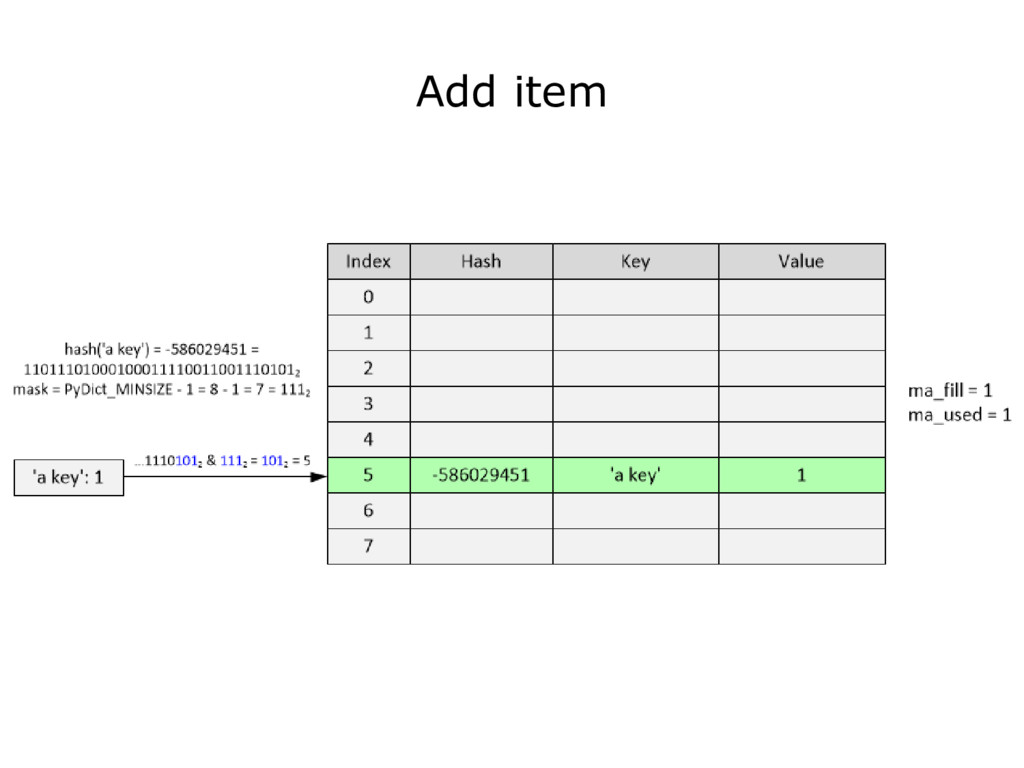{kind=link}
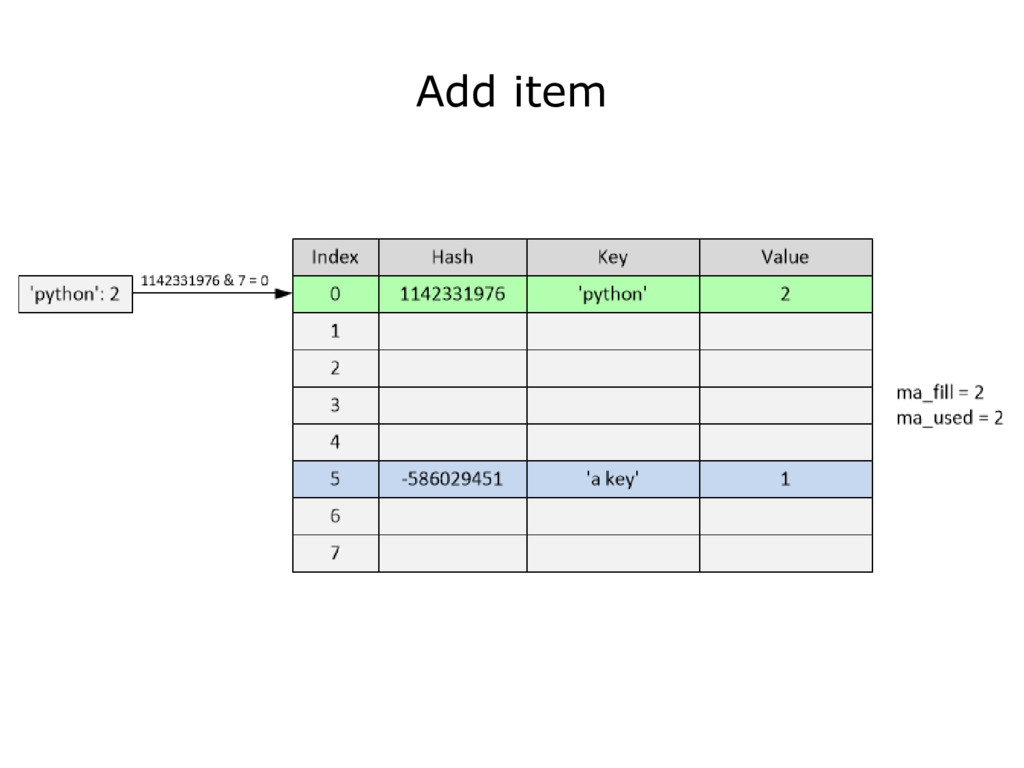{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cache PyDictEntry ma_smalltable[8]; On x86 with 64 bytes per cache](https://files.speakerdeck.com/presentations/e1471000177a4fe78dc42b05a5eaa02a/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
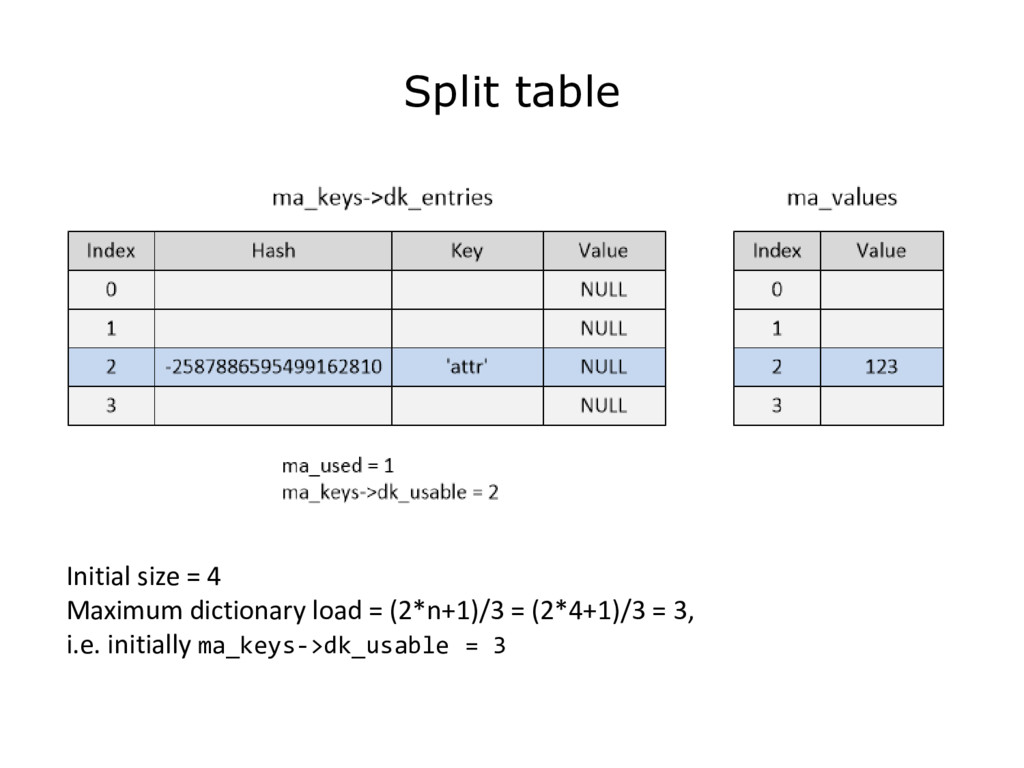{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
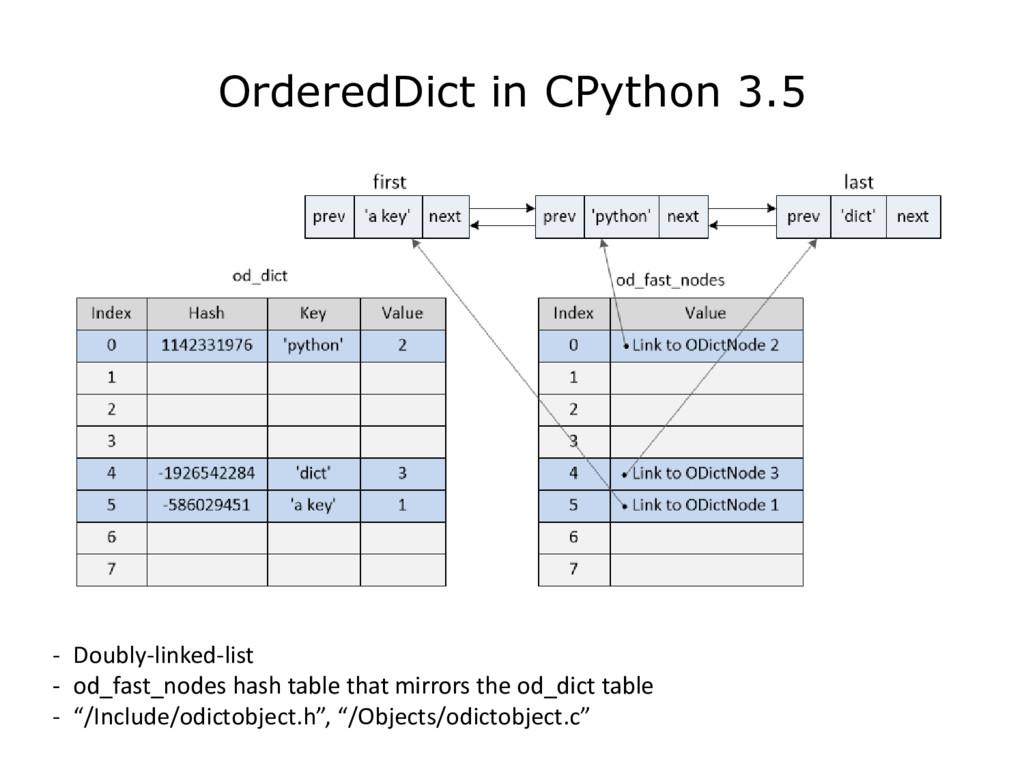{kind=link}
{kind=link}
{kind=link}
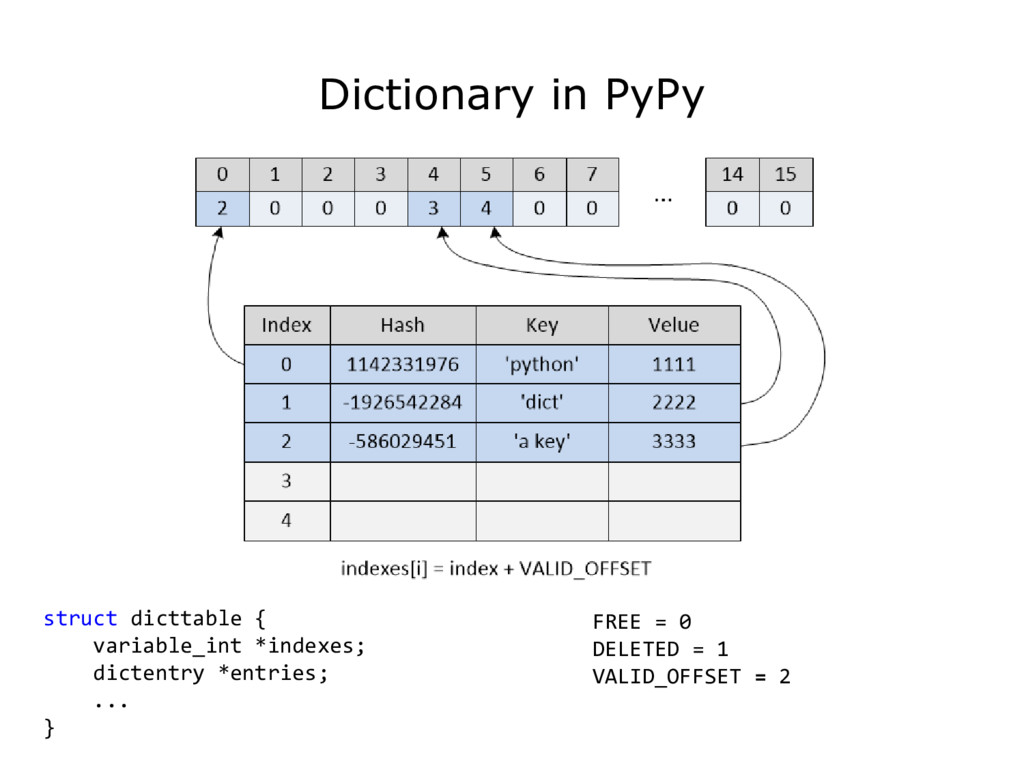{kind=link}
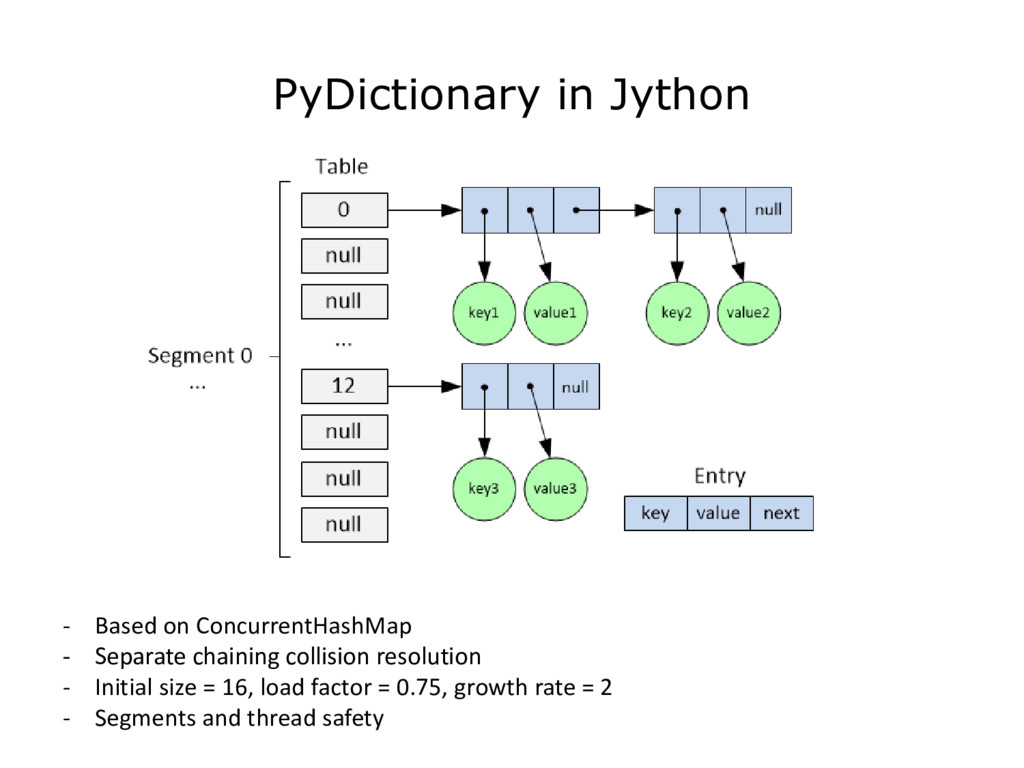{kind=link}
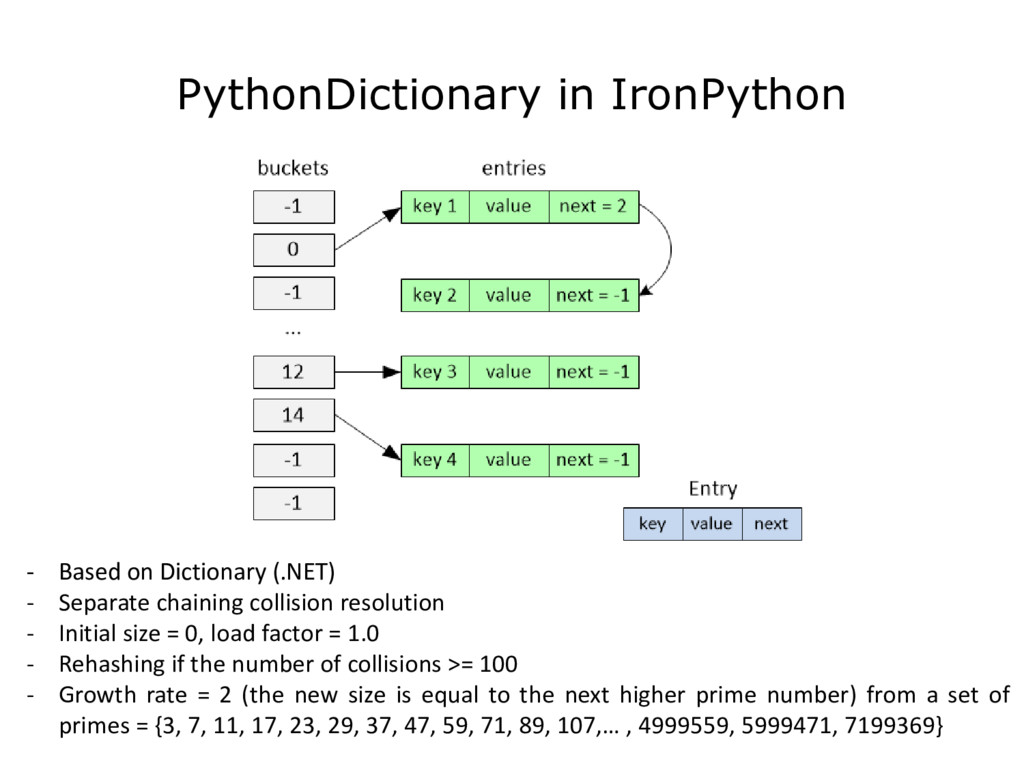{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
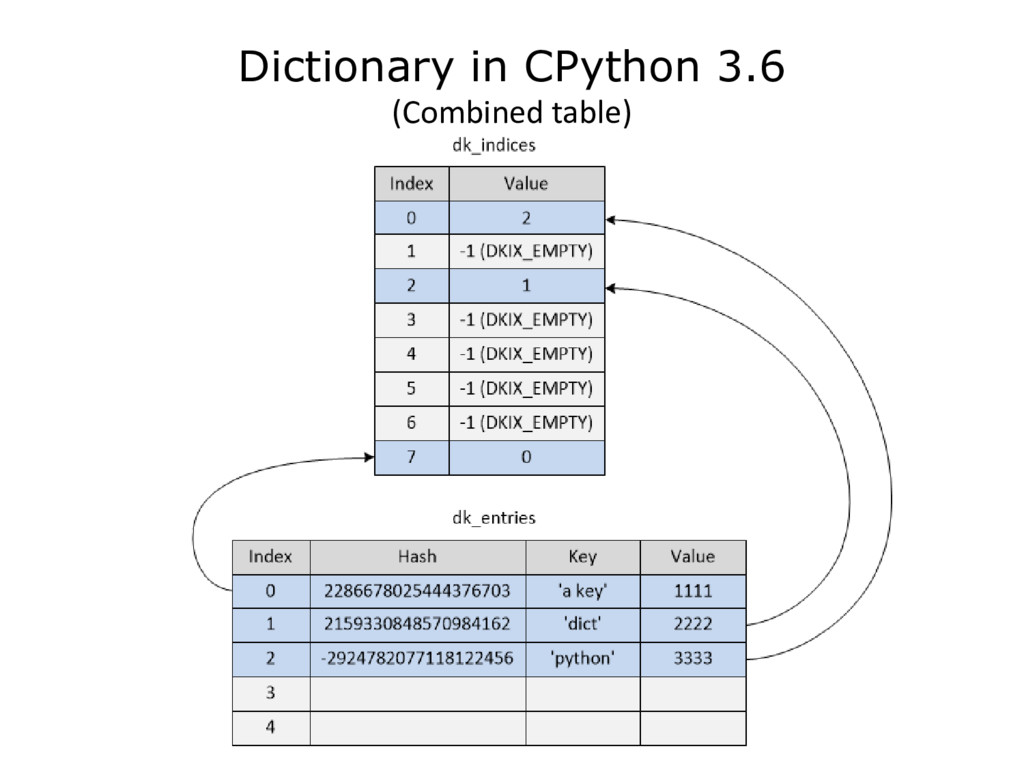{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
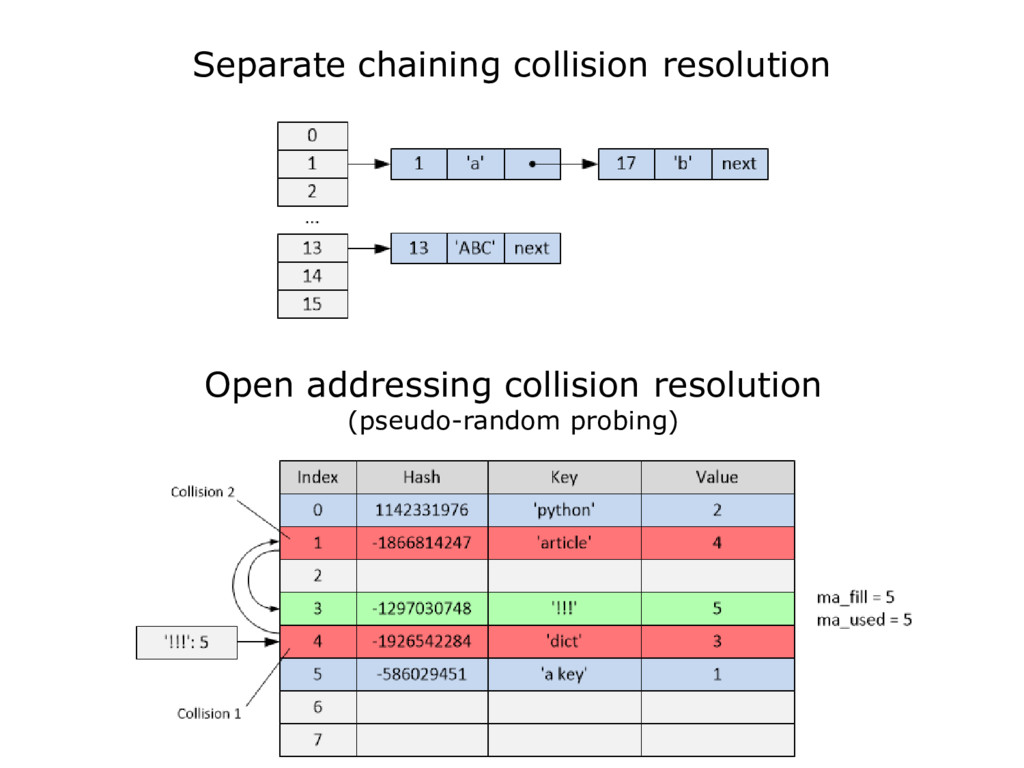{kind=link}