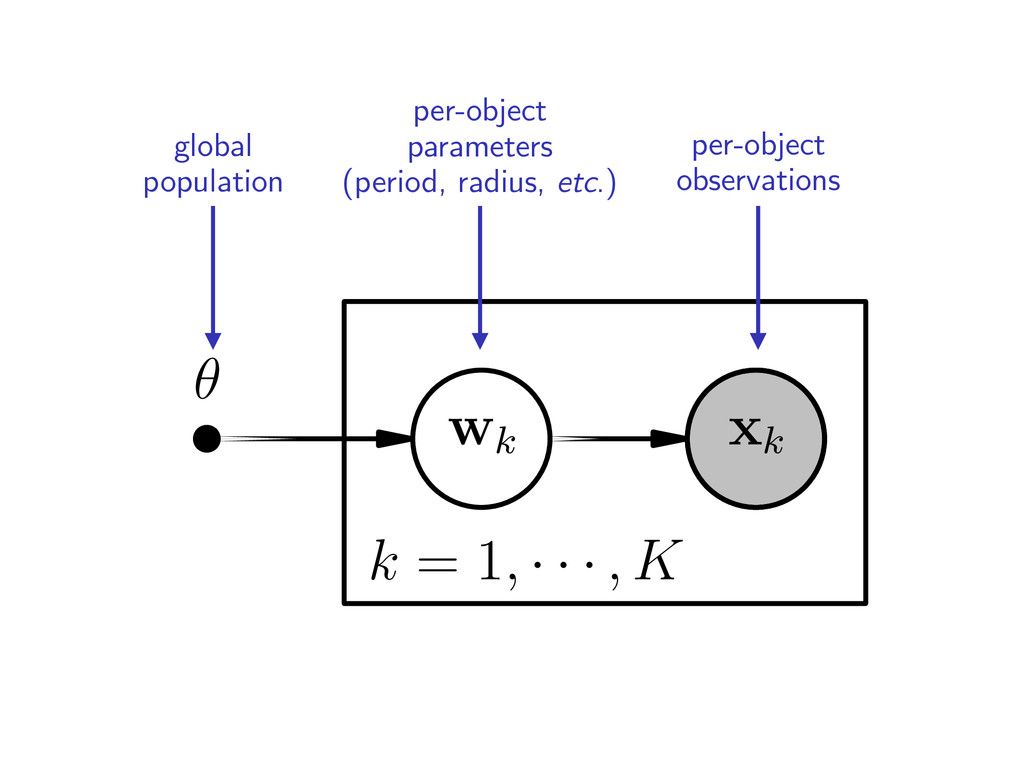
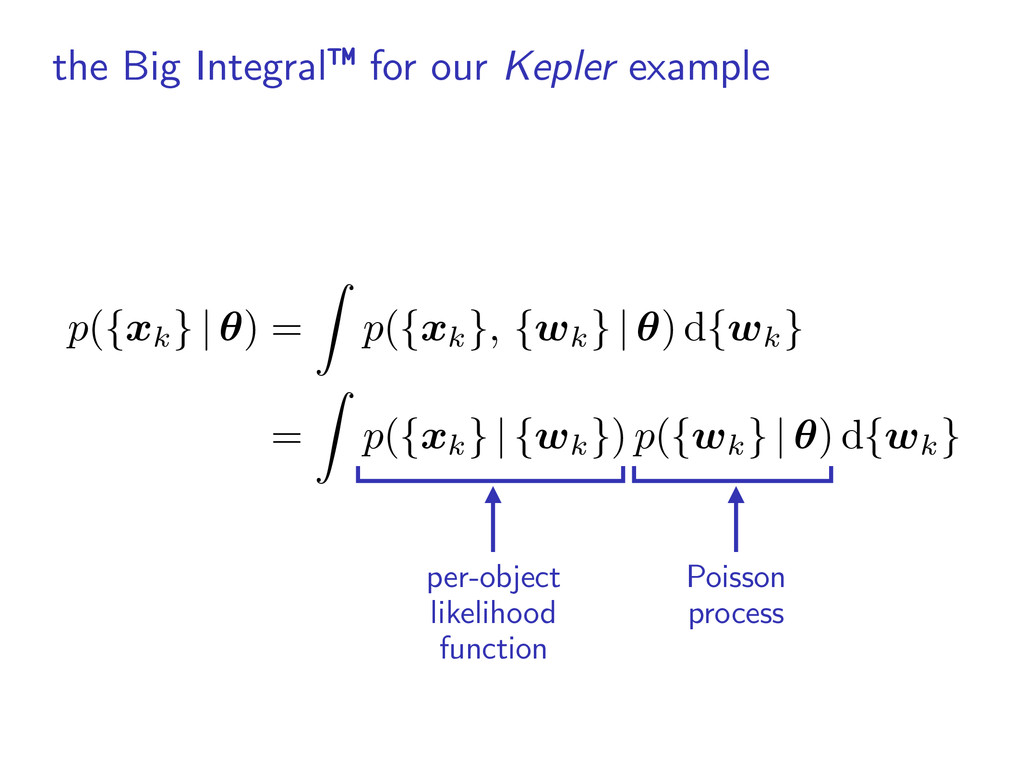
catalog ▶︎ the inhomogeneous Poisson process: equation for the likelihood of the catalog methods for population inference (occurrence rate calculations)
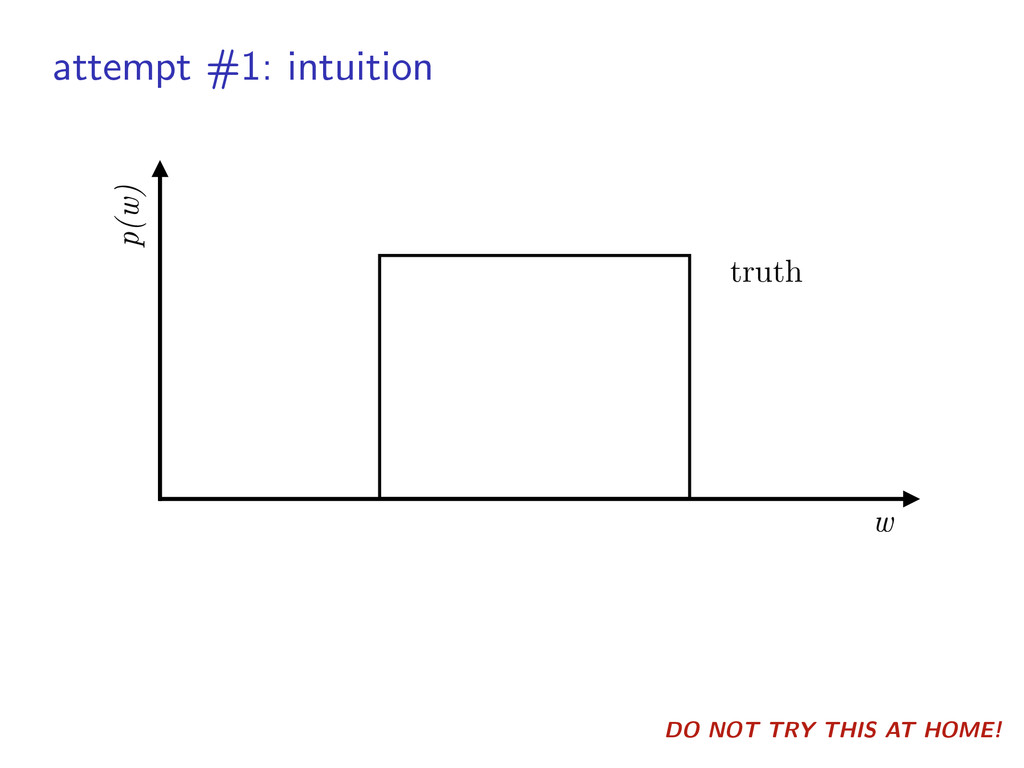
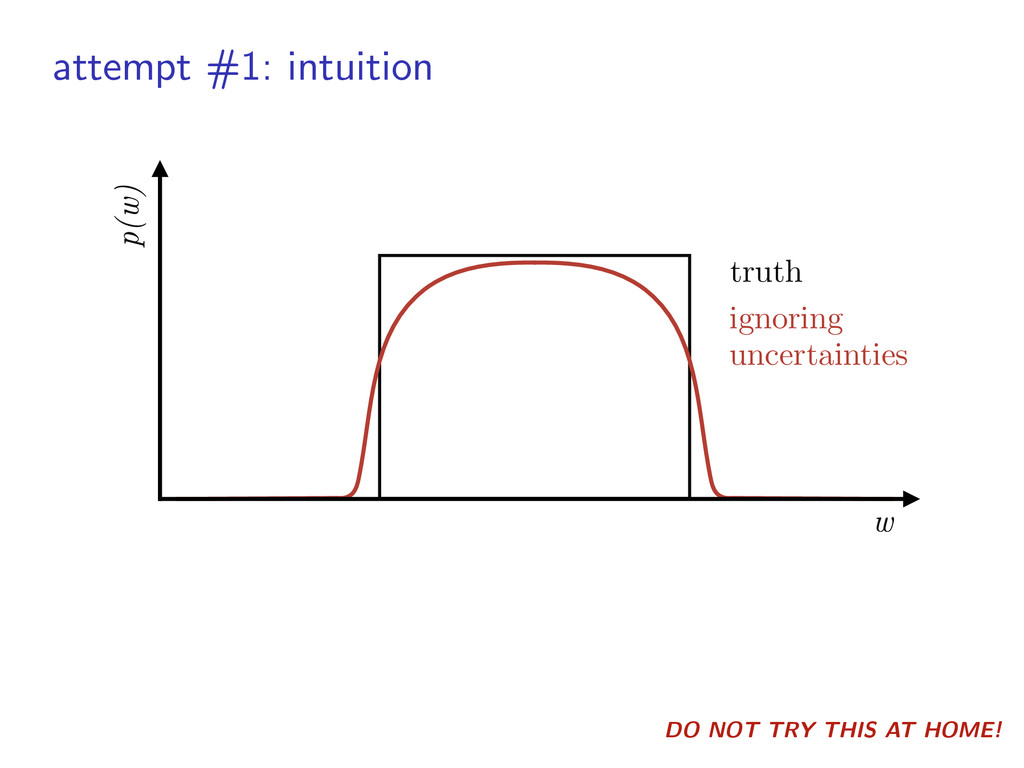
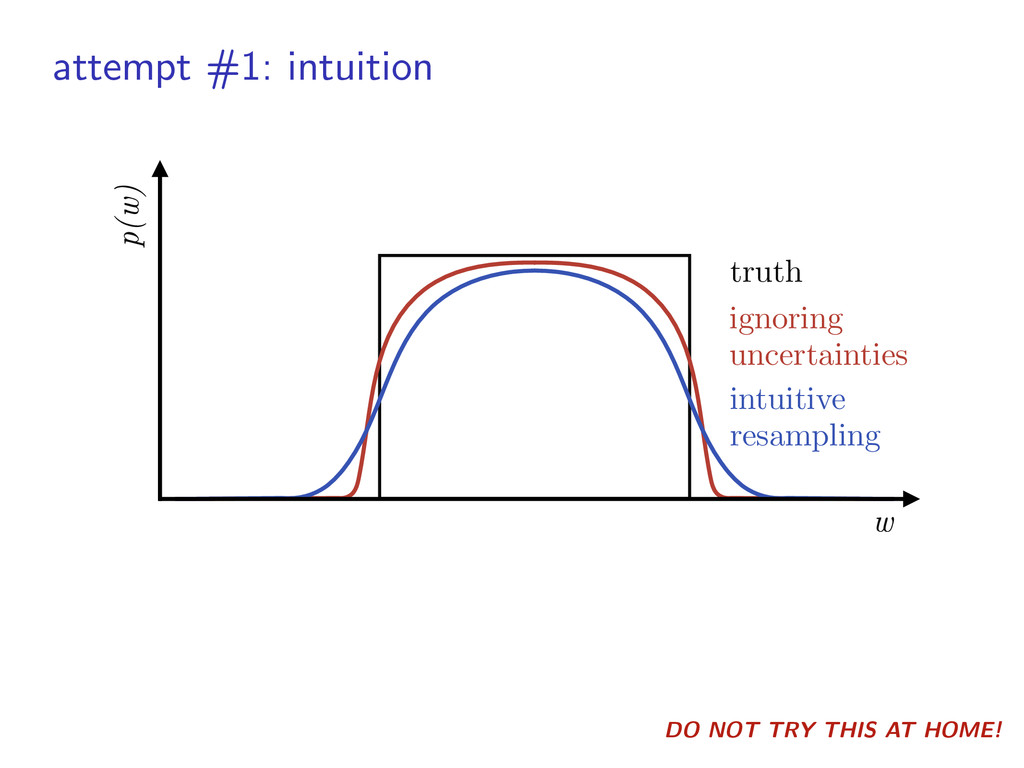
density: histogram, power law, physical model, etc. ▶︎ can include false positives/alarms ▶︎ multiple surveys? product of likelihoods ˆ ✓(w) = ✓(w) Q(w)
k ⇠ p( wk | xk, ↵ ) – 8 – we will reuse the hard work that went into building the ca ach entry in a catalog is a representation of the posterior p p( wk | xk , ↵ ) = p( xk | wk ) p( wk | ↵ ) p( xk | ↵ ) meters wk conditioned on the observations of that object nder that the catalog was produced under a specific cho ive”— interim prior p( wk | ↵ ). This prior was chosen by the di↵erent from the likelihood p( wk | ✓ ) from Equation (2). e can use these posterior measurements to simplify Equa
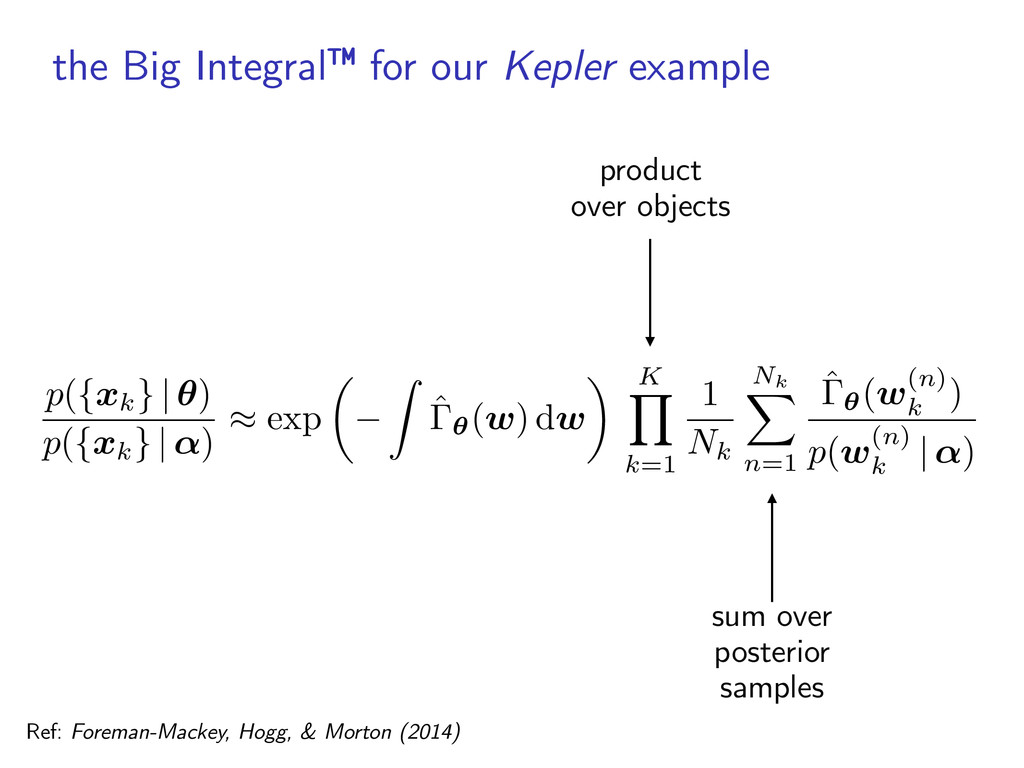
xk } | ✓) p ( { xk } | ↵) ⇡ exp ✓ Z ˆ✓(w) dw ◆ K Y k=1 1 Nk Nk X n=1 ˆ✓(w (n) k ) p (w (n) k | ↵) sum over posterior samples product over objects Ref: Foreman-Mackey, Hogg, & Morton (2014)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![101 102 orbital period [days] 100 101 planet radius [R](https://files.speakerdeck.com/presentations/58c73049d9b94585a049ac56bf038945/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
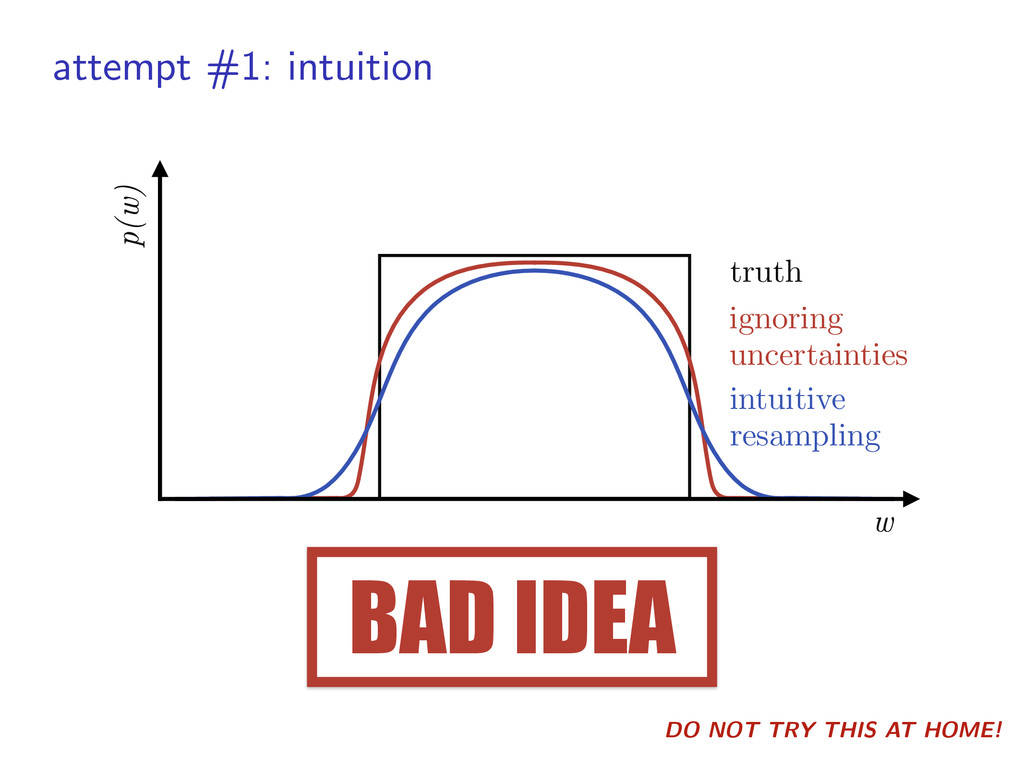{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}