JavaScript is the most widely used language for web programming, and now increasingly becoming popular for high performance computing, data-intensive applications, and deep learning. More recently, WebAssembly has been introduced as a typed low-level bytecode representation which promises to enable better performance. Sparse matrix-vector multiplication (SpMV) is an important kernel that is considered critical for the performance of compute-intensive applications. In SpMV, the optimal selection of storage format is one of the key aspects of enabling the best performance.
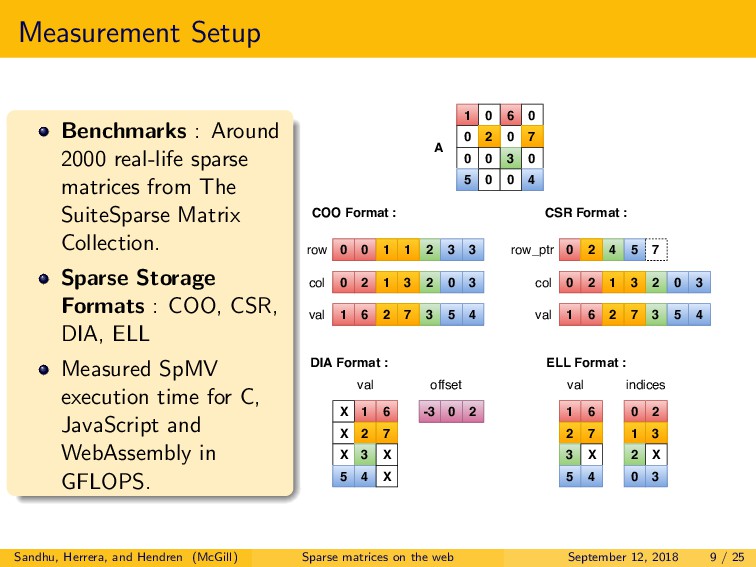
This paper describes the distinctive nature of the performance and choice of optimal sparse matrix storage format for sequential SpMV for the managed languages JavaScript and WebAssembly, as compared to native languages like C. We performed exhaustive experiments with 2000 real-life sparse matrices. To evaluate the experimental data in a rigorous manner we introduced the notion of x%-affinity which allows us to identify with certainty those storage formats that are at least x% better than all other formats.
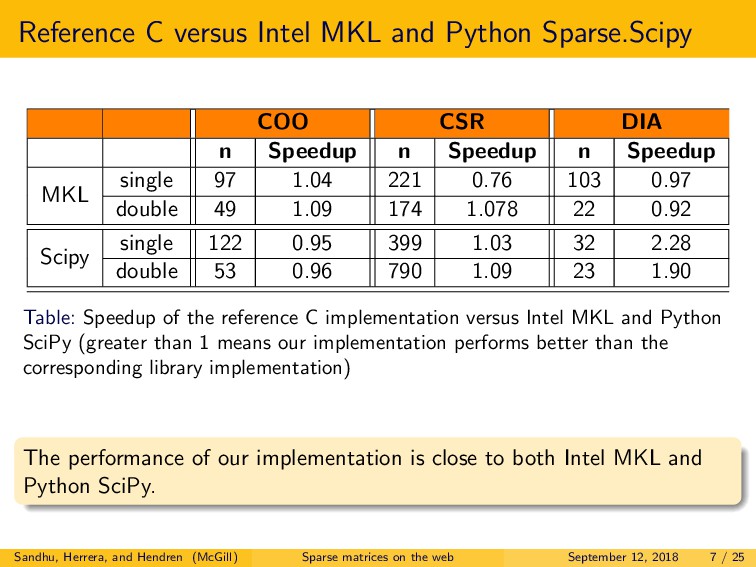
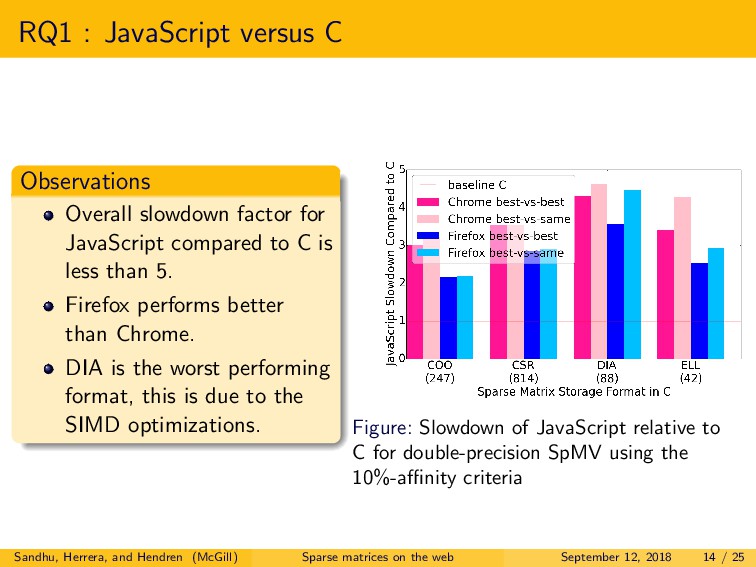
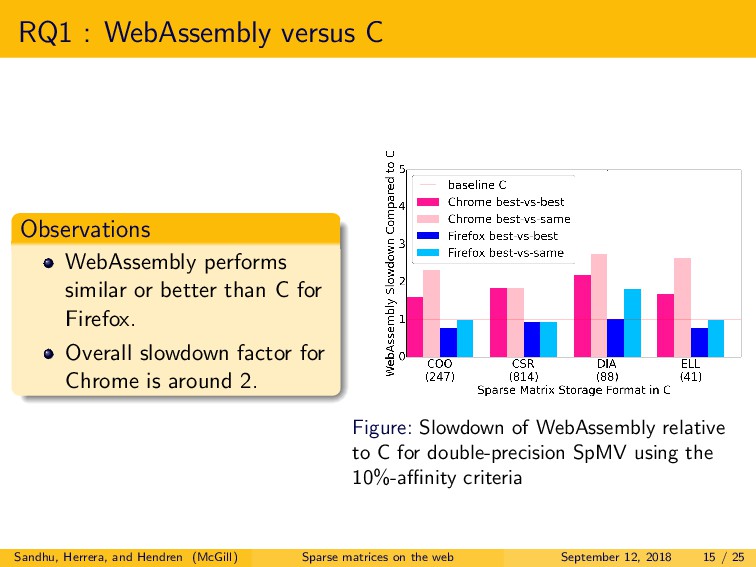
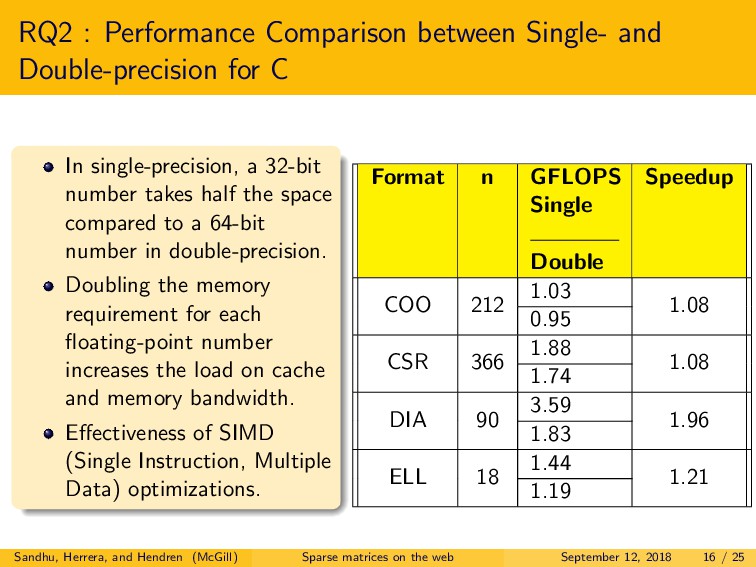
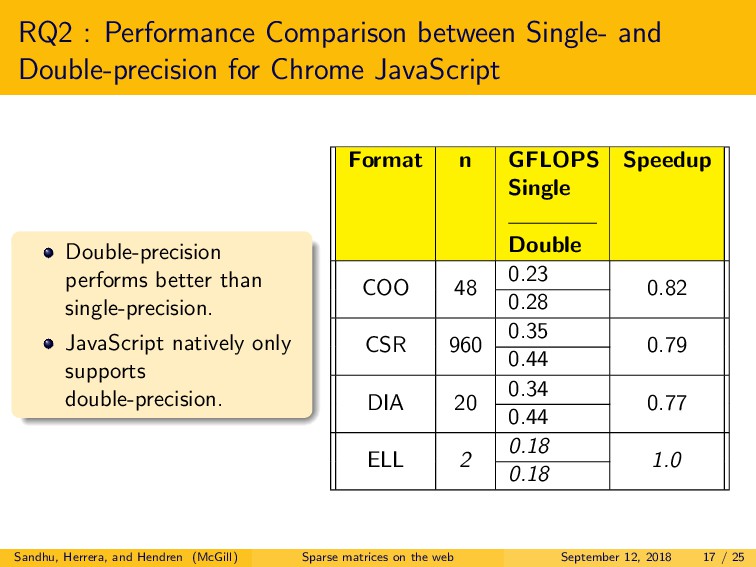
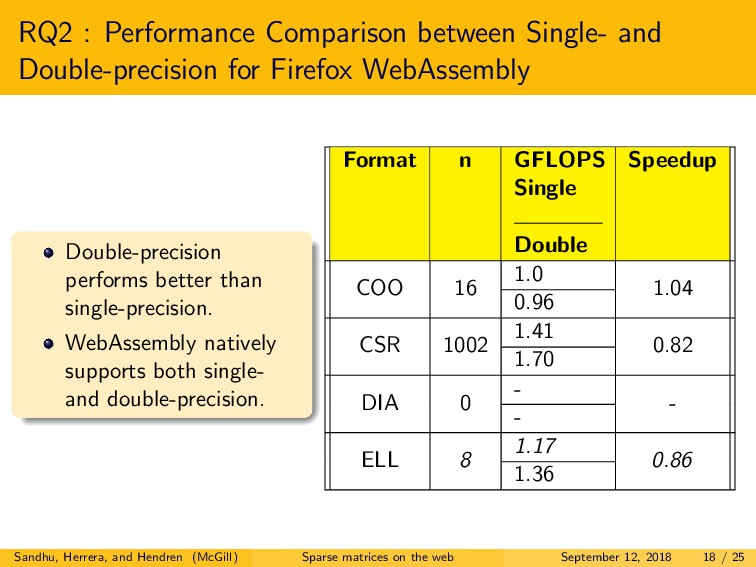
We explored three main research questions. First, we examined the difference in performance between native C and both JavaScript and WebAssembly, for two major browsers, Firefox and Chrome. For JavaScript, we observed that the best performing browser demonstrated a slowdown of only 2.2x to 5.8x versus C. Somewhat surprisingly, for WebAssembly, we observed similar or better performance as compared to C, for the best performing browser. Second, we explored the performance of single-precision versus double-precision SpMV. In contrast to C, in JavaScript and WebAssembly, we found that double-precision is often more efficient than single-precision. Lastly, we examined the choice of optimal storage format. Interestingly, the best format choices are very different for C as compared to both JavaScript and WebAssembly, and even quite different between the two browsers.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}